
Gemini 3 Flash Preview モデルの呼び出し時にレスポンス時間が長くなることは、開発者がよく直面する課題です。この記事では、timeout、max_tokens、thinking_level などの主要なパラメータ設定のテクニックを紹介し、Gemini 3 Flash Preview のレスポンス速度を最適化するための実用的な方法を素早く習得できるようサポートします。
コアバリュー: この記事を読み終えることで、パラメータを適切に設定して Gemini 3 Flash Preview のレスポンス時間を制御する方法を学ぶことができます。出力品質を維持しながら、レスポンス速度を大幅に向上させることが可能です。

Gemini 3 Flash Preview のレスポンス時間が長い理由の分析
最適化テクニックを詳しく見る前に、なぜ Gemini 3 Flash Preview のレスポンス時間が長くなることがあるのかを理解する必要があります。
思考トークン(Thinking Tokens)メカニズム
Gemini 3 Flash Preview は動的な思考メカニズムを採用しており、これがレスポンス時間が長くなる主な原因です。
| 影響要因 | 説明 | レスポンス時間への影響 |
|---|---|---|
| 複雑な推論タスク | 論理的推論を伴う問題にはより多くの思考トークンが必要 | 著しく増加 |
| 動的な思考の深さ | モデルが問題の複雑さに応じて思考量を自動調整 | 簡潔な問題は速く、複雑な問題は遅い |
| 非ストリーミング出力 | 非ストリーミングモードでは生成がすべて完了するまで待機が必要 | 全体の待ち時間が長くなる |
| 出力トークン数 | 生成される内容が多いほど、生成時間も長くなる | 線形に増加 |
Artificial Analysis のテストデータによると、Gemini 3 Flash Preview が最高レベルの思考を行った際に使用するトークン量は約 1.6 億に達し、これは Gemini 2.5 Flash の 2 倍以上です。これは、複雑なタスクにおいてモデルが大量の「思考時間」を消費することを意味します。
実際のケース分析
ユーザーからのフィードバックに基づくと、レスポンス速度が求められる一方で正確性の優先度がそれほど高くないタスクでは、Gemini 3 Flash Preview のデフォルト設定は理想的ではない可能性があります。
「タスクのレスポンス時間に速度が求められ、正確性はそれほど高くなくても良いのですが、gemini-3-flash-preview の推論が非常に長いです」
このような状況の根本的な原因は以下の通りです:
- モデルがデフォルトで動的思考を使用し、自動的に深い推論を行う
- 生成されるトークン数が 7000+ に達することがある
- 推論プロセスで消費される思考トークンがさらなる遅延を招く
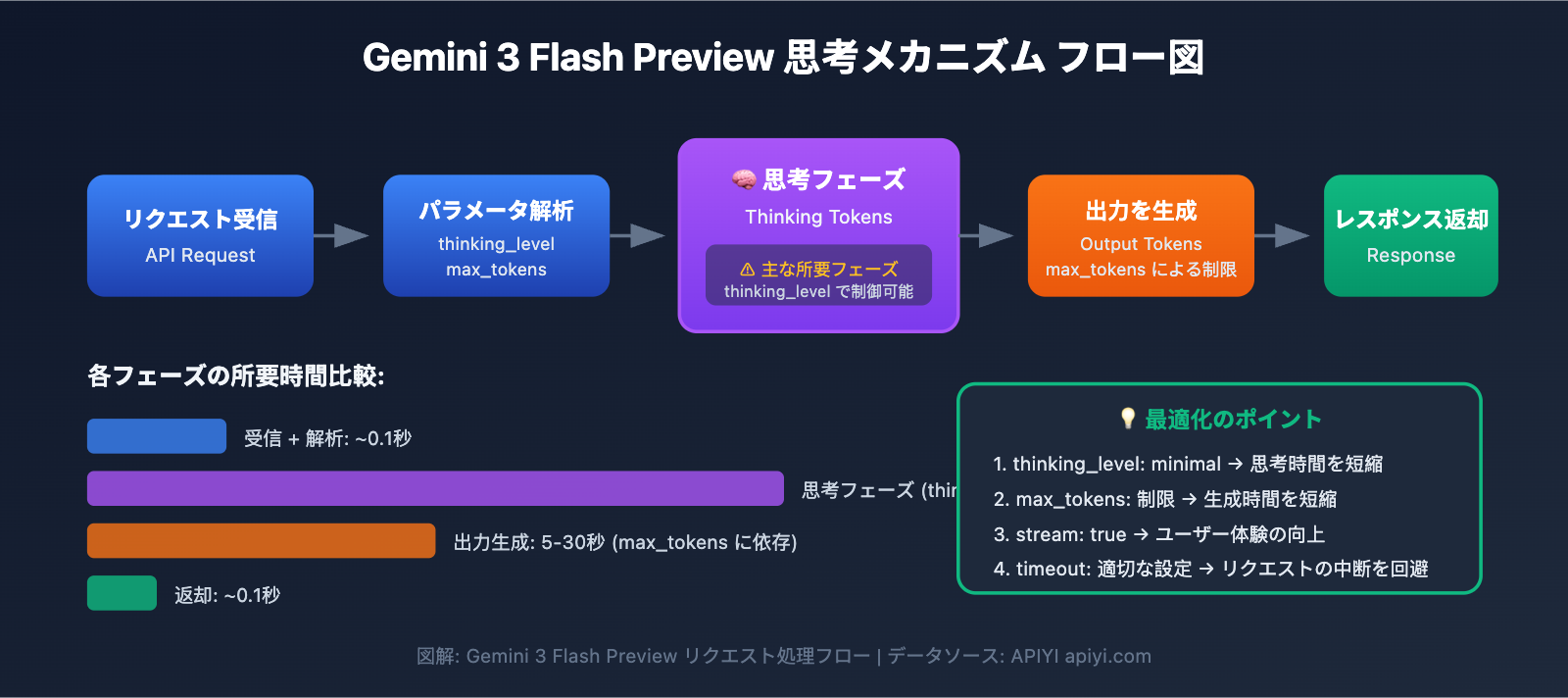
Gemini 3 Flash Preview 応答速度最適化の核心ポイント
| 最適化のポイント | 説明 | 期待される効果 |
|---|---|---|
| thinking_level の設定 | モデルの思考深度を制御 | 応答時間を 30-70% 短縮 |
| max_tokens の制限 | 出力長を制御 | 生成時間の削減 |
| timeout の調整 | 適切なタイムアウト時間を設定 | リクエストの切断を回避 |
| ストリーミング出力の使用 | 生成しながら順次返却 | ユーザーエクスペリエンスの向上 |
| 適切なシナリオの選択 | 単純なタスクには低い思考レベルを使用 | 全体的な効率の向上 |
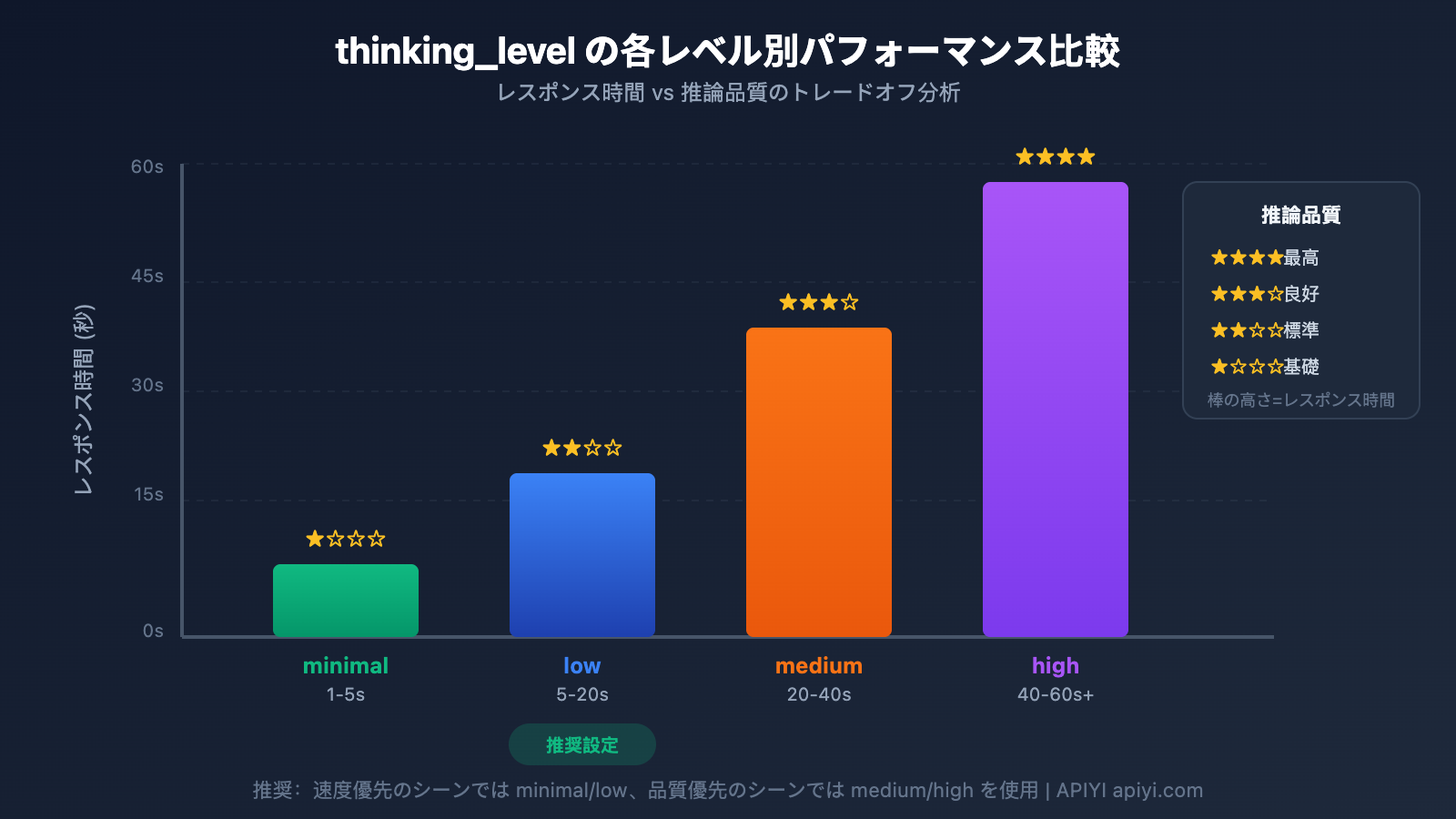
thinking_level パラメータ詳細
Gemini 3 では thinking_level パラメータが導入されました。これは応答速度を制御するための最も重要な設定です。
| thinking_level | 適用シナリオ | 応答速度 | 推論クオリティ |
|---|---|---|---|
| minimal | 簡単な会話、迅速な応答 | 最速 ⚡ | 基礎的 |
| low | 日常的なタスク、軽度の推論 | 速い | 良好 |
| medium | 中程度の複雑なタスク | 中程度 | より良い |
| high | 複雑な推論、深い分析 | 遅い | 最高 |
🎯 技術的なアドバイス: タスクにおいて正確性への要求がそれほど高くなく、迅速な応答が必要な場合は、
thinking_levelをminimalまたはlowに設定することをお勧めします。APIYI (apiyi.com) プラットフォームを通じて、異なるthinking_levelの比較テストを行い、ビジネスシーンに最適な設定を迅速に見つけることを推奨します。
max_tokens パラメータ設定戦略
max_tokens を制限することで、出力長を効果的に制御し、応答時間を短縮できます。
出力トークン数 → 生成時間に直接影響
トークン数が多いほど → 応答時間が長くなる
設定のアドバイス:
- 短い回答のシナリオ:
max_tokensを 500-1000 に設定 - 中程度のコンテンツ生成:
max_tokensを 2000-4000 に設定 - 完全なコンテンツ出力: 実際のニーズに応じて設定(ただし、タイムアウトのリスクに注意)
⚠️ 注意: max_tokens を短く設定しすぎると、出力が途中で切断され、回答の完全性に影響を与える可能性があります。実際のビジネスニーズに基づいて、速度と完全性のバランスをとる必要があります。
Gemini 3 Flash Preview 応答速度最適化クイックスタート
シンプルな例
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI の統合インターフェースを使用
)
# 速度優先設定
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": "人工知能について簡単に紹介してください"}],
max_tokens=1000, # 出力長を制限
extra_body={
"thinking_level": "minimal" # 最小の思考深度、最速の応答
},
timeout=30 # 30秒のタイムアウトを設定
)
print(response.choices[0].message.content)
詳細コードを表示 – 多様な設定シナリオを含む
import openai
from typing import Literal
def create_gemini_client(api_key: str):
"""Gemini 3 Flash クライアントを作成"""
return openai.OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # APIYI の統合インターフェースを使用
)
def call_gemini_optimized(
client: openai.OpenAI,
prompt: str,
thinking_level: Literal["minimal", "low", "medium", "high"] = "low",
max_tokens: int = 2000,
timeout: int = 60,
stream: bool = False
):
"""
最適化された Gemini 3 Flash 呼び出し
引数:
client: OpenAI クライアント
prompt: ユーザー入力
thinking_level: 思考の深さ (minimal/low/medium/high)
max_tokens: 最大出力トークン数
timeout: タイムアウト(秒)
stream: ストリーミング出力を使用するかどうか
"""
params = {
"model": "gemini-3-flash-preview",
"messages": [{"role": "user", "content": prompt}],
"max_tokens": max_tokens,
"stream": stream,
"extra_body": {
"thinking_level": thinking_level
},
"timeout": timeout
}
if stream:
# ストリーミング出力 - ユーザーエクスペリエンスの改善
response = client.chat.completions.create(**params)
full_content = ""
for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
print(content, end="", flush=True)
full_content += content
print() # 改行
return full_content
else:
# 非ストリーミング出力 - 一括返却
response = client.chat.completions.create(**params)
return response.choices[0].message.content
# 使用例
if __name__ == "__main__":
client = create_gemini_client("YOUR_API_KEY")
# シナリオ 1: 速度優先 - シンプルな質疑応答
print("=== 速度優先設定 ===")
result = call_gemini_optimized(
client,
prompt="機械学習とは何かを一行で説明してください",
thinking_level="minimal",
max_tokens=500,
timeout=15
)
print(f"回答: {result}\n")
# シナリオ 2: バランス設定 - 日常タスク
print("=== バランス設定 ===")
result = call_gemini_optimized(
client,
prompt="Pythonでのデータ処理に関するベストプラクティスを5つ挙げてください",
thinking_level="low",
max_tokens=1500,
timeout=30
)
print(f"回答: {result}\n")
# シナリオ 3: 品質優先 - 複雑な分析
print("=== 品質優先設定 ===")
result = call_gemini_optimized(
client,
prompt="Transformerアーキテクチャの核心的な革新点と、それがNLPに与えた影響を分析してください",
thinking_level="high",
max_tokens=4000,
timeout=120
)
print(f"回答: {result}\n")
# シナリオ 4: ストリーミング出力 - エクスペリエンスの改善
print("=== ストリーミング出力 ===")
result = call_gemini_optimized(
client,
prompt="Gemini 3 Flashの主な特徴を紹介してください",
thinking_level="low",
max_tokens=2000,
timeout=60,
stream=True
)
🚀 クイックスタート: APIYI (apiyi.com) プラットフォームを使用して、異なるパラメータ設定を迅速にテストすることをお勧めします。このプラットフォームはすぐに使える API インターフェースを提供しており、Gemini 3 Flash Preview などの主要な大規模言語モデルをサポートしているため、最適化効果を素早く検証できます。
Gemini 3 Flash Preview レスポンス速度最適化パラメータ設定詳解
timeout(タイムアウト)設定
Gemini 3 Flash Preview を使用して複雑な推論を行う場合、デフォルトのタイムアウト時間では不足することがあります。以下に推奨される timeout 設定戦略を示します。
| タスクの種類 | 推奨 timeout | 説明 |
|---|---|---|
| 簡単なQ&A | 15-30 秒 | minimal な thinking_level と組み合わせて使用 |
| 日常的なタスク | 30-60 秒 | low/medium な thinking_level と組み合わせて使用 |
| 複雑な分析 | 60-120 秒 | high な thinking_level と組み合わせて使用 |
| 長文生成 | 120-180 秒 | 大量のトークン出力が必要なシーン |
重要なヒント:
- 非ストリーミング出力モードでは、すべてのコンテンツの生成が完了するまでレスポンスが返されません。
- タイムアウト設定が短すぎると、リクエストが途中で切断される可能性があります。
- 実際の出力トークン量や thinking_level に応じて、動的に調整することをお勧めします。
thinking_level と旧版 thinking_budget の移行
Google は、旧版の thinking_budget パラメータから新版の thinking_level への移行を推奨しています。
| 旧版 thinking_budget | 新版 thinking_level | 移行の説明 |
|---|---|---|
| 0 | minimal | 最小限の思考。思考シグネチャの処理が必要な点に注意 |
| 1-1000 | low | 軽度の思考 |
| 1001-5000 | medium | 中程度の思考 |
| 5001+ | high | 深い思考 |
⚠️ 注意: 同一のリクエスト内で thinking_budget と thinking_level を同時に使用しないでください。予期しない動作を引き起こす可能性があります。
Gemini 3 Flash Preview レスポンス速度最適化 シーン別設定プラン
シーン 1: 高頻度の単純なタスク (速度優先)
チャットボット、迅速なQ&A、内容の要約など、遅延に敏感なシーンに適しています。
# 速度優先設定
config_speed_first = {
"thinking_level": "minimal",
"max_tokens": 500,
"timeout": 15,
"stream": True # ストリーミング出力でユーザー体験を向上
}
期待される効果:
- レスポンス時間: 1-5 秒
- シンプルな対話や迅速な返信に適しています
シーン 2: 日常的なビジネス業務 (バランス設定)
コンテンツ生成、コード補助、ドキュメント処理などの一般的なタスクに適しています。
# バランス設定
config_balanced = {
"thinking_level": "low",
"max_tokens": 2000,
"timeout": 45,
"stream": True
}
期待される効果:
- レスポンス時間: 5-20 秒
- 品質と速度の優れたバランス
シーン 3: 複雑な分析タスク (品質優先)
データ分析、技術設計、詳細なリサーチなど、深い推論が必要なシーンに適しています。
# 品質優先設定
config_quality_first = {
"thinking_level": "high",
"max_tokens": 8000,
"timeout": 180,
"stream": True # 長いタスクにはストリーミングを推奨
}
期待される効果:
- レスポンス時間: 30-120 秒
- 最高の推論品質
設定選択の意思決定表
| ニーズ | 推奨 thinking_level | 推奨 max_tokens | 推奨 timeout |
|---|---|---|---|
| 迅速な返信、簡単な質問 | minimal | 500-1000 | 15-30s |
| 日常タスク、標準的な品質 | low | 1500-2500 | 30-60s |
| 高い品質、待機可能 | medium | 2500-4000 | 60-90s |
| 最高の品質、複雑なタスク | high | 4000-8000 | 120-180s |
💡 選択のアドバイス: どの設定を選択するかは、具体的なユースケースと品質要件によって決まります。ご自身のニーズに最適な選択を行うために、APIYI (apiyi.com) プラットフォームで実際にテストすることをお勧めします。このプラットフォームは Gemini 3 Flash Preview の統合インターフェースを提供しており、異なる設定の効果を簡単に比較できます。
Gemini 3 Flash Preview 応答速度最適化のアドバンスド・テクニック
テクニック 1: ストリーミング出力を使用してユーザー体験を向上させる
たとえ合計のレスポンス時間が変わらなくても、ストリーミング出力はユーザーが体感する待ち時間を大幅に改善できます。
# ストリーミング出力の例
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": prompt}],
stream=True,
extra_body={"thinking_level": "low"}
)
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
メリット:
- ユーザーはすぐに結果の一部を確認できる
- 「待ち時間のストレス」を軽減
- 生成の途中で継続するかどうかを判断できる
テクニック 2: 入力の複雑さに応じてパラメータを動的に調整する
def estimate_complexity(prompt: str) -> str:
"""プロンプトの特徴からタスクの複雑さを推定する"""
indicators = {
"high": ["分析", "比較", "なぜ", "原理", "深く", "詳細な説明"],
"medium": ["どのように", "手順", "方法", "紹介"],
"low": ["とは何か", "簡単に", "素早く", "一言で"]
}
prompt_lower = prompt.lower()
for level, keywords in indicators.items():
if any(kw in prompt_lower for kw in keywords):
return level
return "low" # デフォルトは低複雑度
def get_optimized_config(prompt: str) -> dict:
"""プロンプトに基づいた最適化設定を取得する"""
complexity = estimate_complexity(prompt)
configs = {
"low": {"thinking_level": "minimal", "max_tokens": 1000, "timeout": 20},
"medium": {"thinking_level": "low", "max_tokens": 2500, "timeout": 45},
"high": {"thinking_level": "medium", "max_tokens": 4000, "timeout": 90}
}
return configs.get(complexity, configs["low"])
テクニック 3: リクエスト再試行メカニズムの実装
偶発的なタイムアウトの問題に対して、インテリジェントな再試行機能を実装できます。
import time
from typing import Optional
def call_with_retry(
client,
prompt: str,
max_retries: int = 3,
initial_timeout: int = 30
) -> Optional[str]:
"""再試行メカニズム付きの呼び出し"""
for attempt in range(max_retries):
try:
timeout = initial_timeout * (attempt + 1) # タイムアウトを段階的に増やす
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": prompt}],
max_tokens=2000,
timeout=timeout,
extra_body={"thinking_level": "low"}
)
return response.choices[0].message.content
except Exception as e:
print(f"試行 {attempt + 1} 失敗: {e}")
if attempt < max_retries - 1:
time.sleep(2 ** attempt) # 指数バックオフ
continue
return None

Gemini 3 Flash Preview 性能データリファレンス
Artificial Analysis のテストデータによると、Gemini 3 Flash Preview のパフォーマンスは以下の通りです。
| パフォーマンス指標 | 数値 | 説明 |
|---|---|---|
| 生のスループット | 218 トークン/秒 | 出力速度 |
| 2.5 Flash との比較 | 22% 低下 | 推論能力の強化による |
| GPT-5.1 high との比較 | 74% 高速 | 125 トークン/秒 |
| DeepSeek V3.2 との比較 | 627% 高速 | 30 トークン/秒 |
| 入力料金 | $0.50/1M トークン | |
| 出力料金 | $3.00/1M トークン |
パフォーマンスとコストのバランス
| 設定プラン | レスポンス速度 | トークン消費量 | コストパフォーマンス |
|---|---|---|---|
| minimal thinking | 最速 | 最小 | 最高 |
| low thinking | 速い | 比較的少ない | 高い |
| medium thinking | 中程度 | 中程度 | 中程度 |
| high thinking | 遅い | 比較的多い | 精度を重視する場合に選択 |
💰 コスト最適化: 予算を重視するプロジェクトでは、APIYI(apiyi.com)プラットフォーム経由で Gemini 3 Flash Preview API を呼び出すことを検討してください。このプラットフォームは柔軟な課金方式を提供しており、本記事で紹介する速度最適化テクニックと組み合わせることで、コストを抑えつつ最高のコストパフォーマンスを得ることができます。
Gemini 3 Flash Preview レスポンス速度最適化に関するよくある質問
Q1: なぜ max_tokens を制限したのに、レスポンスが遅いのですか?
max_tokens は出力の長さのみを制限し、モデルの思考プロセスには影響しません。レスポンスが遅い主な原因が思考時間の長さである場合は、同時に thinking_level パラメータを minimal または low に設定する必要があります。また、APIYI(apiyi.com)プラットフォームを利用することで安定した API サービスを利用でき、本記事のパラメータ設定テクニックと組み合わせることでレスポンス速度を効果的に改善できます。
Q2: thinking_level を minimal に設定すると回答の質に影響しますか?
一定の影響はありますが、単純なタスクであればそれほど大きくありません。minimal レベルは、迅速な Q&A や簡単な対話などのシナリオに適しています。タスクに複雑な論理推論が含まれる場合は、low または medium レベルの使用をお勧めします。APIYI(apiyi.com)プラットフォームで A/B テストを行い、異なる thinking_level での出力品質を比較して、ビジネスに最適なバランスポイントを見つけることをお勧めします。
Q3: ストリーミング出力と非ストリーミング出力、どちらが速いですか?
総生成時間は同じですが、ストリーミング出力の方がユーザーエクスペリエンスは向上します。ストリーミングモードでは、ユーザーはすぐに結果の一部を確認できますが、非ストリーミングモードでは生成がすべて完了するまで待つ必要があります。生成時間が長いタスクでは、ストリーミング出力を強くお勧めします。
Q4: タイムアウト(timeout)はどのくらいの長さに設定すべきですか?
timeout は、期待される出力長と thinking_level に基づいて設定する必要があります:
- minimal + 1000 tokens: 15-30 秒
- low + 2000 tokens: 30-60 秒
- medium + 4000 tokens: 60-90 秒
- high + 8000 tokens: 120-180 秒
まずは長めの timeout で実際のレスポンス時間をテストし、その結果に基づいて調整することをお勧めします。
Q5: 旧版の thinking_budget パラメータはまだ使えますか?
引き続き使用可能ですが、Google はより予測可能なパフォーマンスを得るために thinking_level パラメータへの移行を推奨しています。同一のリクエスト内で両方のパラメータを同時に使用しないよう注意してください。以前 thinking_budget=0 を使用していた場合は、移行時に thinking_level="minimal" を設定してください。
まとめ
Gemini 3 Flash Preview のレスポンス速度を最適化する鍵は、3つの主要なパラメータを適切に設定することにあります。
- thinking_level: タスクの複雑さに応じて、適切な思考の深さを選択します。
- max_tokens: 予想される出力の長さに合わせてトークン数を制限します。
- timeout: thinking_level と出力ボリュームに基づいて、適切なタイムアウト値を設定します。
「レスポンス速度が優先され、正確性はそこまで求められない」というタスクの場合は、以下の設定が推奨されます。
- thinking_level:
minimalまたはlow - max_tokens: 実際のニーズに合わせて設定し、長くなりすぎないように調整します
- timeout: 処理が途切れないよう、設定に合わせて適切に調整します
- stream:
True(ユーザー体験の向上につながります)
APIYI(apiyi.com)を通じて様々なパラメータの組み合わせを素早くテストし、あなたのビジネスシーンに最適な構成を見つけることをお勧めします。
キーワード: Gemini 3 Flash Preview, レスポンス速度の最適化, thinking_level, max_tokens, timeout 設定, API 呼び出しの最適化
参考資料:
- Google AI 公式ドキュメント: ai.google.dev/gemini-api/docs/gemini-3
- Google DeepMind: deepmind.google/models/gemini/flash/
- Artificial Analysis パフォーマンステスト: artificialanalysis.ai/articles/gemini-3-flash-everything-you-need-to-know
本記事は APIYI Team 技術チームによって執筆されました。AI モデルの活用テクニックについては help.apiyi.com をご覧ください。