
يعد طول وقت الاستجابة عند استدعاء نموذج Gemini 3 Flash Preview تحدياً شائعاً يواجهه المطورون. سيتناول هذا المقال تقنيات تهيئة المعلمات الأساسية مثل timeout، وmax_tokens، وthinking_level، لمساعدتك على إتقان الطرق العملية لتحسين سرعة استجابة Gemini 3 Flash Preview بسرعة.
القيمة الجوهرية: بعد قراءة هذا المقال، ستتعلم كيفية التحكم في وقت استجابة Gemini 3 Flash Preview من خلال تهيئة المعلمات بشكل معقول، مما يضمن جودة المخرجات مع تحقيق زيادة ملحوظة في سرعة الاستجابة.

تحليل أسباب طول وقت الاستجابة في Gemini 3 Flash Preview
قبل التعمق في تقنيات التحسين، نحتاج أولاً إلى فهم سبب طول وقت استجابة Gemini 3 Flash Preview في بعض الأحيان.
آلية رموز التفكير (Thinking Tokens)
يعتمد Gemini 3 Flash Preview آلية تفكير ديناميكية، وهي السبب الجذري وراء زيادة وقت الاستجابة:
| العامل المؤثر | التوضيح | التأثير على وقت الاستجابة |
|---|---|---|
| مهام الاستدلال المعقدة | تتطلب الأسئلة التي تنطوي على استدلال منطقي المزيد من رموز التفكير (Thinking Tokens) | زيادة ملحوظة في وقت الاستجابة |
| عمق التفكير الديناميكي | يقوم النموذج بتعديل كمية التفكير تلقائياً بناءً على تعقيد السؤال | الأسئلة البسيطة سريعة، والأسئلة المعقدة بطيئة |
| مخرجات غير متدفقة | في الوضع غير المتدفق، يجب انتظار اكتمال التوليد بالكامل | وقت انتظار إجمالي أطول |
| عدد رموز المخرجات | كلما زاد محتوى الإكمال، زاد وقت التوليد | زيادة خطية في وقت الاستجابة |
وفقاً لبيانات الاختبار من Artificial Analysis، يمكن لـ Gemini 3 Flash Preview استهلاك ما يصل إلى حوالي 160 مليون رمز (Token) عند أعلى مستوى تفكير، وهو أكثر من ضعف ما يستهلكه Gemini 2.5 Flash. وهذا يعني أنه في المهام المعقدة، سيستهلك النموذج قدراً كبيراً من "وقت التفكير".
تحليل حالة واقعية
من خلال ملاحظات المستخدمين، يتبين أن التكوين الافتراضي لـ Gemini 3 Flash Preview قد لا يكون مثالياً عندما تتطلب المهمة سرعة في العودة للنتائج دون التركيز العالي على الدقة:
"بما أن المهمة تتطلب سرعة في وقت العودة للنتائج والدقة ليست أولوية قصوى، إلا أن استدلال gemini-3-flash-preview يستغرق وقتاً طويلاً جداً"
السبب الجذري لهذه الحالة هو:
- يستخدم النموذج التفكير الديناميكي افتراضياً، وسيقوم بإجراء استدلال عميق تلقائياً.
- قد يصل عدد رموز الإكمال (Tokens) إلى أكثر من 7000.
- يجب أيضاً مراعاة رموز التفكير الإضافية التي تستهلكها عملية الاستدلال.
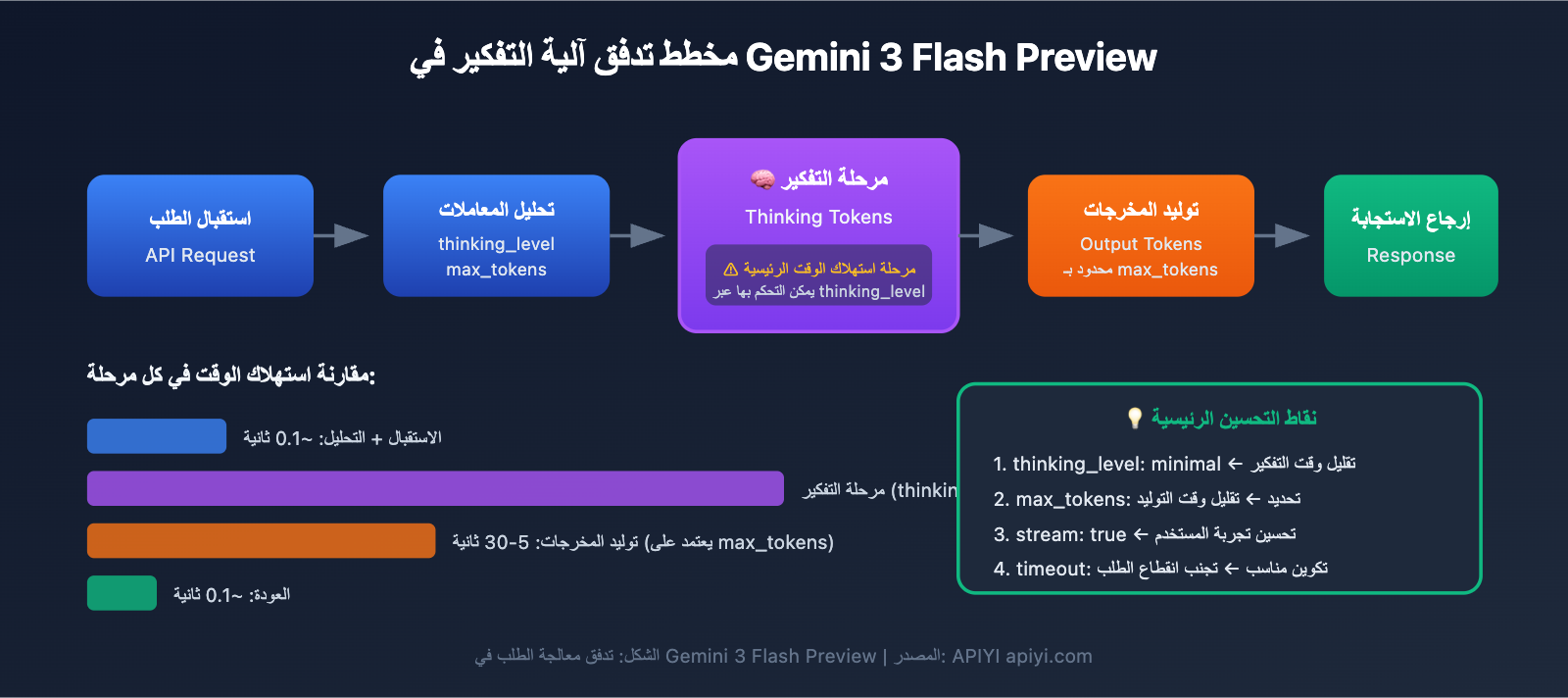
النقاط الأساسية لتحسين سرعة استجابة Gemini 3 Flash Preview
| نقطة التحسين | الشرح | التأثير المتوقع |
|---|---|---|
ضبط thinking_level |
التحكم في عمق تفكير النموذج | تقليل وقت الاستجابة بنسبة 30-70% |
تقييد max_tokens |
التحكم في طول المخرجات | تقليل وقت التوليد |
تعديل timeout |
تعيين وقت مهلة معقول | تجنب انقطاع الطلبات بشكل مفاجئ |
| استخدام مخرجات التدفق (Streaming) | الإرجاع أثناء التوليد | تحسين تجربة المستخدم |
| اختيار السيناريو المناسب | استخدام مستوى تفكير منخفض للمهام البسيطة | تحسين الكفاءة العامة |
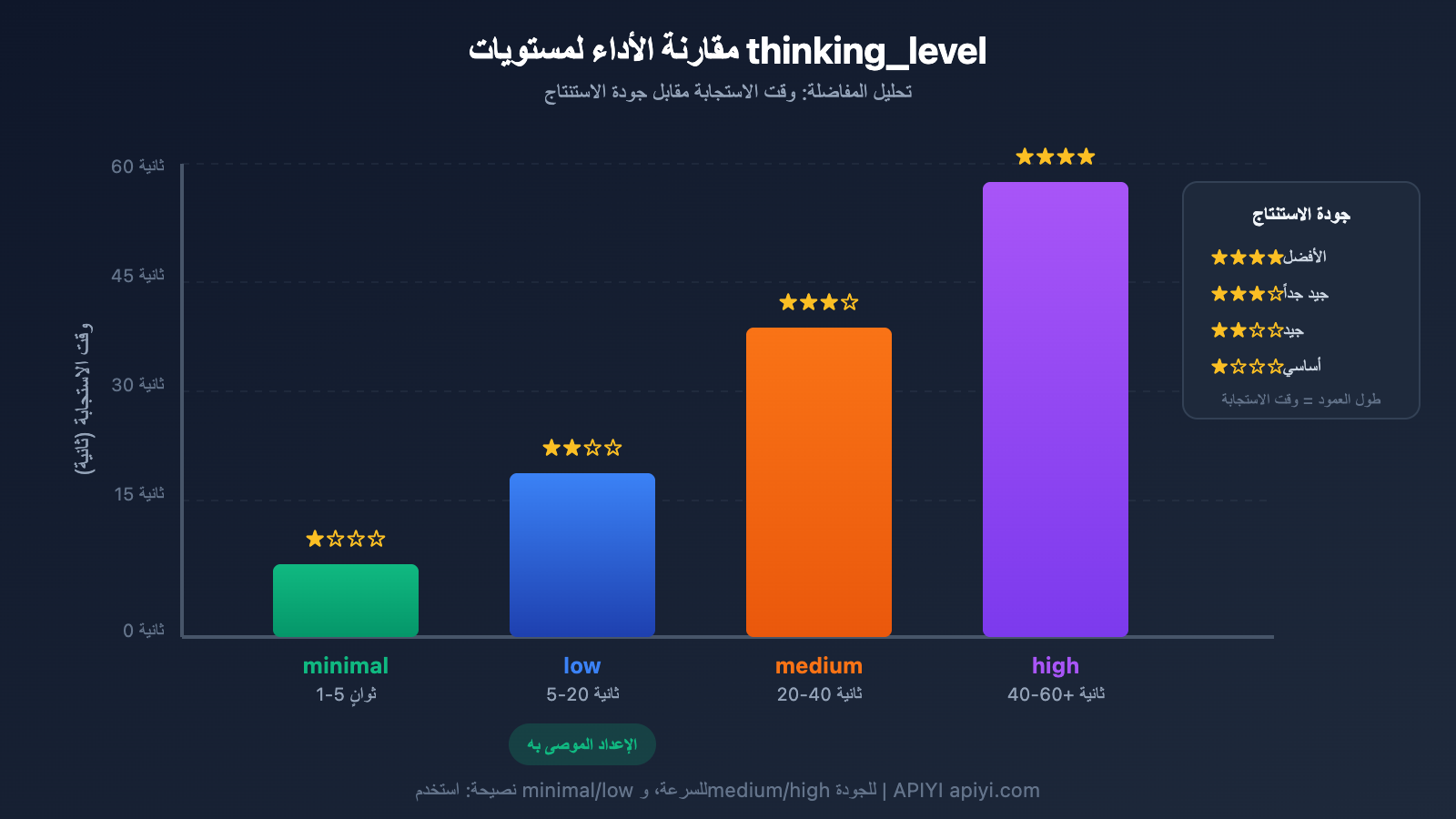
تفاصيل معيار thinking_level
قدم Gemini 3 معيار thinking_level (مستوى التفكير)، وهو الإعداد الأكثر أهمية للتحكم في سرعة الاستجابة:
| thinking_level | سيناريوهات الاستخدام | سرعة الاستجابة | جودة الاستنتاج |
|---|---|---|---|
| minimal | حوار بسيط، استجابة سريعة | الأسرع ⚡ | أساسي |
| low | مهام يومية، استنتاج خفيف | سريع | جيد |
| medium | مهام متوسطة التعقيد | متوسط | جيد جداً |
| high | استنتاج معقد، تحليل عميق | بطيء | الأفضل |
🎯 نصيحة تقنية: إذا كانت مهمتك لا تتطلب دقة عالية جداً ولكنها تحتاج إلى استجابة سريعة، فنحن نقترح ضبط
thinking_levelعلىminimalأوlow. نوصي بإجراء اختبارات مقارنة لمستوياتthinking_levelالمختلفة عبر منصة APIYI (apiyi.com) للعثور بسرعة على التكوين الأنسب لسيناريو عملك.
استراتيجية تكوين معيار max_tokens
يمكن لتقييد max_tokens التحكم بفعالية في طول المخرجات، وبالتالي تقليل وقت الاستجابة:
عدد رموز (Tokens) المخرجات ← يؤثر مباشرة على وقت التوليد
كلما زاد عدد الرموز ← زاد وقت الاستجابة
توصيات التكوين:
- سيناريوهات الإجابات القصيرة: ضبط
max_tokensبين 500-1000 - توليد المحتوى المتوسط: ضبط
max_tokensبين 2000-4000 - مخرجات المحتوى الكامل: الضبط حسب الحاجة الفعلية، ولكن مع الانتباه لمخاطر انتهاء المهلة (Timeout).
⚠️ ملاحظة: تعيين max_tokens بشكل قصير جداً قد يؤدي إلى قطع المخرجات، مما يؤثر على اكتمال الإجابة. يجب الموازنة بين السرعة والاكتمال بناءً على متطلبات العمل الفعلية.
البدء السريع لتحسين سرعة استجابة Gemini 3 Flash Preview
مثال بسيط
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # استخدام واجهة APIYI الموحدة
)
# تكوين يمنح الأولوية للسرعة
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": "تقديم مقدمة بسيطة عن الذكاء الاصطناعي"}],
max_tokens=1000, # تقييد طول المخرجات
extra_body={
"thinking_level": "minimal" # أقل عمق تفكير، أسرع استجابة
},
timeout=30 # تعيين مهلة 30 ثانية
)
print(response.choices[0].message.content)
عرض الكود الكامل – يشمل سيناريوهات تكوين متعددة
import openai
from typing import Literal
def create_gemini_client(api_key: str):
"""إنشاء عميل Gemini 3 Flash"""
return openai.OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # استخدام واجهة APIYI الموحدة
)
def call_gemini_optimized(
client: openai.OpenAI,
prompt: str,
thinking_level: Literal["minimal", "low", "medium", "high"] = "low",
max_tokens: int = 2000,
timeout: int = 60,
stream: bool = False
):
"""
استدعاء Gemini 3 Flash بتكوينات محسنة
المعاملات:
client: عميل OpenAI
prompt: موجه المستخدم
thinking_level: عمق التفكير (minimal/low/medium/high)
max_tokens: الحد الأقصى لعدد الرموز (Tokens) في المخرجات
timeout: وقت المهلة (بالثواني)
stream: ما إذا كان سيتم استخدام مخرجات التدفق
"""
params = {
"model": "gemini-3-flash-preview",
"messages": [{"role": "user", "content": prompt}],
"max_tokens": max_tokens,
"stream": stream,
"extra_body": {
"thinking_level": thinking_level
},
"timeout": timeout
}
if stream:
# مخرجات التدفق - لتحسين تجربة المستخدم
response = client.chat.completions.create(**params)
full_content = ""
for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
print(content, end="", flush=True)
full_content += content
print() # سطر جديد
return full_content
else:
# مخرجات عادية - العودة مرة واحدة
response = client.chat.completions.create(**params)
return response.choices[0].message.content
# أمثلة على الاستخدام
if __name__ == "__main__":
client = create_gemini_client("YOUR_API_KEY")
# السيناريو 1: أولوية السرعة - سؤال وجواب بسيط
print("=== تكوين أولوية السرعة ===")
result = call_gemini_optimized(
client,
prompt="اشرح ماهية تعلم الآلة في جملة واحدة",
thinking_level="minimal",
max_tokens=500,
timeout=15
)
print(f"الإجابة: {result}\n")
# السيناريو 2: تكوين متوازن - المهام اليومية
print("=== تكوين متوازن ===")
result = call_gemini_optimized(
client,
prompt="اذكر 5 من أفضل الممارسات لمعالجة البيانات في Python",
thinking_level="low",
max_tokens=1500,
timeout=30
)
print(f"الإجابة: {result}\n")
# السيناريو 3: أولوية الجودة - تحليل معقد
print("=== تكوين أولوية الجودة ===")
result = call_gemini_optimized(
client,
prompt="حلل الابتكارات الأساسية لمعمارية Transformer وتأثيرها على معالجة اللغات الطبيعية (NLP)",
thinking_level="high",
max_tokens=4000,
timeout=120
)
print(f"الإجابة: {result}\n")
# السيناريو 4: مخرجات التدفق - تحسين التجربة
print("=== مخرجات التدفق ===")
result = call_gemini_optimized(
client,
prompt="قدم الميزات الرئيسية لنموذج Gemini 3 Flash",
thinking_level="low",
max_tokens=2000,
timeout=60,
stream=True
)
🚀 ابدأ الآن: نوصي باستخدام منصة APIYI (apiyi.com) لاختبار تكوينات المعاملات المختلفة بسرعة. توفر المنصة واجهة برمجة تطبيقات (API) جاهزة للاستخدام، وتدعم النماذج الرائدة مثل Gemini 3 Flash Preview، مما يسهل التحقق السريع من نتائج التحسين.
تهيئة معلمات تحسين سرعة الاستجابة في Gemini 3 Flash Preview
تهيئة وقت الاستراحة (timeout)
عند استخدام Gemini 3 Flash Preview لإجراء عمليات استنتاج معقدة، قد لا يكون وقت الاستراحة الافتراضي كافياً. إليك استراتيجية تهيئة الـ timeout الموصى بها:
| نوع المهمة | الـ timeout الموصى به | التوضيح |
|---|---|---|
| سؤال وجواب بسيط | 15-30 ثانية | مع استخدام مستوى التفكير minimal |
| المهام اليومية | 30-60 ثانية | مع استخدام مستوى التفكير low/medium |
| التحليل المعقد | 60-120 ثانية | مع استخدام مستوى التفكير high |
| توليد النصوص الطويلة | 120-180 ثانية | في حالات مخرجات الـ Tokens الكثيفة |
تلميحات هامة:
- في وضع الإخراج غير المتدفق (Non-streaming)، يجب الانتظار حتى اكتمال توليد المحتوى بالكامل قبل الحصول على الرد.
- إذا تم ضبط الـ timeout لفترة قصيرة جداً، فقد يتم قطع الطلب قبل اكتماله.
- ننصح بتعديل الـ timeout ديناميكياً بناءً على كمية الـ Tokens المتوقعة ومستوى التفكير (
thinking_level).
الانتقال من thinking_budget القديم إلى thinking_level الجديد
توصي Google بالانتقال من المعلمة القديمة thinking_budget إلى المعلمة الجديدة thinking_level:
النسخة القديمة thinking_budget |
النسخة الجديدة thinking_level |
تعليمات الانتقال |
|---|---|---|
| 0 | minimal | أقل قدر من التفكير، ملاحظة: لا يزال يتعين التعامل مع توقيع التفكير (thinking signature). |
| 1-1000 | low | تفكير خفيف |
| 1001-5000 | medium | تفكير متوسط |
| 5001+ | high | تفكير عميق |
⚠️ ملاحظة: لا تستخدم thinking_budget وthinking_level في نفس الطلب، حيث سيؤدي ذلك إلى سلوك غير متوقع.
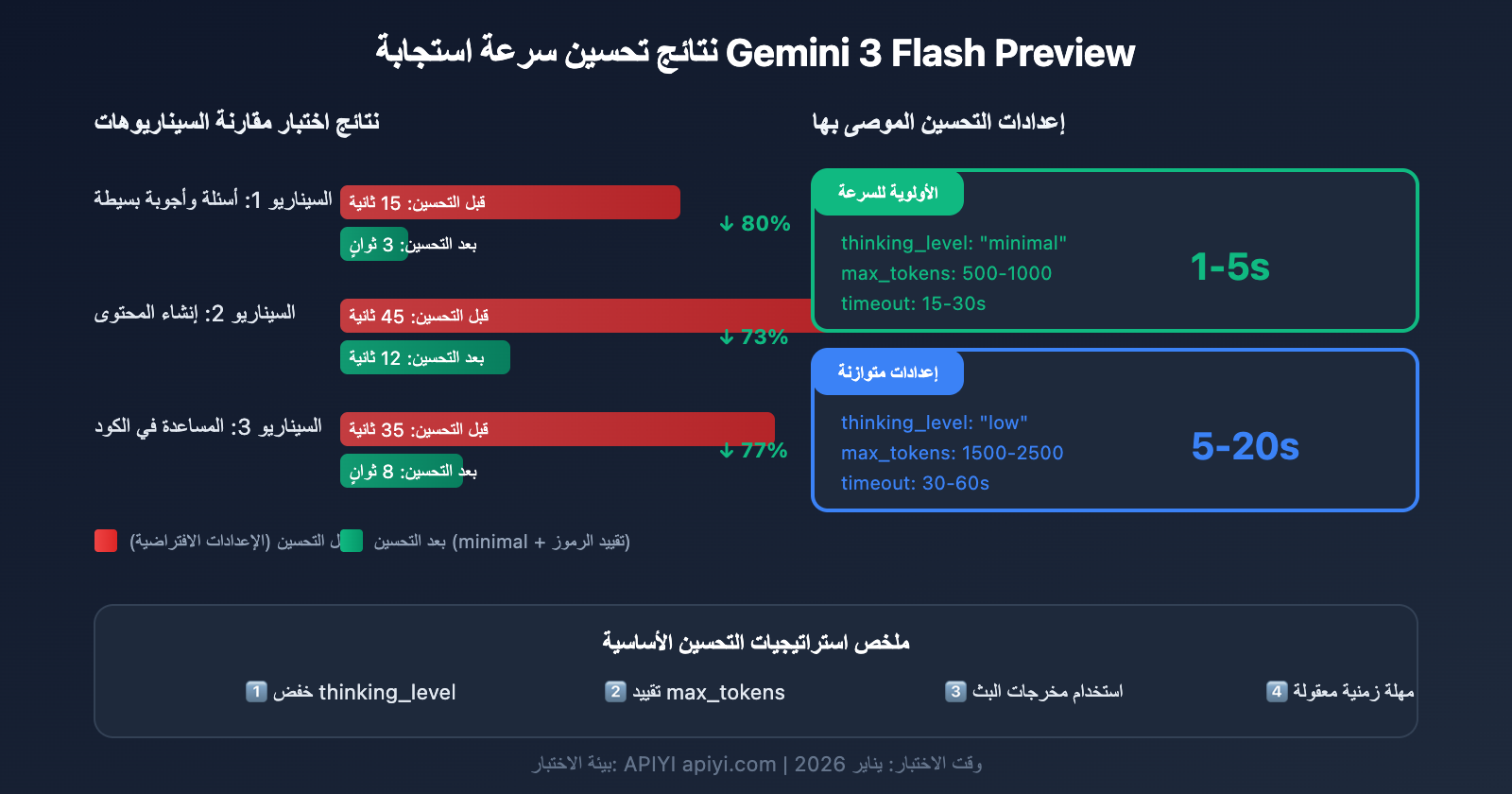
السيناريو 1: المهام البسيطة وعالية التكرار (الأولوية للسرعة)
مناسب لروبوتات الدردشة، والأسئلة والأجوبة السريعة، وتلخيص المحتوى، وغيرها من السيناريوهات الحساسة للتأخير:
# 速度优先配置
config_speed_first = {
"thinking_level": "minimal",
"max_tokens": 500,
"timeout": 15,
"stream": True # 流式输出改善体验
}
النتائج المتوقعة:
- وقت الاستجابة: 1-5 ثوانٍ
- مناسب للمحادثات البسيطة والردود السريعة
السيناريو 2: المهام التجارية اليومية (إعدادات متوازنة)
مناسب لإنشاء المحتوى، والمساعدة في كتابة الأكواد، ومعالجة المستندات، والمهام الروتينية الأخرى:
# 平衡配置
config_balanced = {
"thinking_level": "low",
"max_tokens": 2000,
"timeout": 45,
"stream": True
}
النتائج المتوقعة:
- وقت الاستجابة: 5-20 ثانية
- توازن جيد بين الجودة والسرعة
السيناريو 3: مهام التحليل المعقدة (الأولوية للجودة)
مناسب لتحليل البيانات، وتصميم الحلول التقنية، والبحث العميق، وغيرها من السيناريوهات التي تتطلب استدلالاً عميقاً:
# 质量优先配置
config_quality_first = {
"thinking_level": "high",
"max_tokens": 8000,
"timeout": 180,
"stream": True # 长任务建议用流式
}
النتائج المتوقعة:
- وقت الاستجابة: 30-120 ثانية
- أفضل جودة استدلال
جدول اتخاذ القرار لاختيار الإعدادات
| احتياجاتك | thinking_level الموصى به | max_tokens الموصى به | timeout الموصى بها |
|---|---|---|---|
| ردود سريعة، أسئلة بسيطة | minimal | 500-1000 | 15-30s |
| مهام يومية، جودة عادية | low | 1500-2500 | 30-60s |
| جودة أفضل، مع إمكانية الانتظار | medium | 2500-4000 | 60-90s |
| أفضل جودة، مهام معقدة | high | 4000-8000 | 120-180s |
💡 نصيحة للاختيار: يعتمد اختيار الإعداد بشكل أساسي على سيناريو التطبيق الخاص بك ومتطلبات الجودة. ننصحك بإجراء اختبارات فعلية عبر منصة APIYI (apiyi.com) لاتخاذ الخيار الأنسب لاحتياجاتك. تدعم هذه المنصة استدعاء واجهة برمجة تطبيقات موحدة لـ Gemini 3 Flash Preview، مما يسهل المقارنة السريعة بين تأثيرات الإعدادات المختلفة.
تقنيات متقدمة لتحسين سرعة استجابة Gemini 3 Flash Preview
التقنية 1: استخدام مخرجات البث (Streaming) لتحسين تجربة المستخدم
حتى لو ظل وقت الاستجابة الإجمالي كما هو، يمكن لمخرجات البث أن تحسن بشكل كبير تجربة المستخدم الملموسة:
# 流式输出示例
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": prompt}],
stream=True,
extra_body={"thinking_level": "low"}
)
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
المزايا:
- يمكن للمستخدم رؤية النتائج الجزئية فوراً
- تقليل "قلق الانتظار"
- إمكانية اتخاذ قرار بالاستمرار أو التوقف أثناء عملية التوليد
التقنية 2: تعديل المعلمات ديناميكياً بناءً على تعقيد المدخلات
def estimate_complexity(prompt: str) -> str:
"""根据 prompt 特征估算任务复杂度"""
indicators = {
"high": ["分析", "对比", "为什么", "原理", "深入", "详细解释"],
"medium": ["如何", "步骤", "方法", "介绍"],
"low": ["是什么", "简单", "快速", "一句话"]
}
prompt_lower = prompt.lower()
for level, keywords in indicators.items():
if any(kw in prompt_lower for kw in keywords):
return level
return "low" # 默认低复杂度
def get_optimized_config(prompt: str) -> dict:
"""根据 prompt 获取优化配置"""
complexity = estimate_complexity(prompt)
configs = {
"low": {"thinking_level": "minimal", "max_tokens": 1000, "timeout": 20},
"medium": {"thinking_level": "low", "max_tokens": 2500, "timeout": 45},
"high": {"thinking_level": "medium", "max_tokens": 4000, "timeout": 90}
}
return configs.get(complexity, configs["low"])
التقنية 3: تنفيذ آلية إعادة محاولة الطلب
بالنسبة لمشاكل المهلة العرضية، يمكن تنفيذ إعادة محاولة ذكية:
import time
from typing import Optional
def call_with_retry(
client,
prompt: str,
max_retries: int = 3,
initial_timeout: int = 30
) -> Optional[str]:
"""带重试机制的调用"""
for attempt in range(max_retries):
try:
timeout = initial_timeout * (attempt + 1) # 递增超时
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": prompt}],
max_tokens=2000,
timeout=timeout,
extra_body={"thinking_level": "low"}
)
return response.choices[0].message.content
except Exception as e:
print(f"尝试 {attempt + 1} 失败: {e}")
if attempt < max_retries - 1:
time.sleep(2 ** attempt) # 指数退避
continue
return None
بيانات أداء Gemini 3 Flash Preview المرجعية
بناءً على بيانات الاختبار من Artificial Analysis، إليك أداء Gemini 3 Flash Preview:
| مؤشر الأداء | القيمة | الوصف |
|---|---|---|
| الإنتاجية الخام | 218 توكن/ثانية | سرعة الإخراج |
| مقارنة بـ 2.5 Flash | أبطأ بنسبة 22% | بسبب إضافة قدرات التفكير (Reasoning) |
| مقارنة بـ GPT-5.1 high | أسرع بنسبة 74% | 125 توكن/ثانية |
| مقارنة بـ DeepSeek V3.2 | أسرع بنسبة 627% | 30 توكن/ثانية |
| سعر المدخلات | $0.50 لكل مليون توكن | |
| سعر المخرجات | $3.00 لكل مليون توكن |
التوازن بين الأداء والتكلفة
| مخطط التكوين | سرعة الاستجابة | استهلاك التوكن | كفاءة التكلفة |
|---|---|---|---|
| minimal thinking | الأسرع | الأقل | الأعلى |
| low thinking | سريع | منخفض | مرتفع |
| medium thinking | متوسط | متوسط | متوسط |
| high thinking | بطيء | مرتفع نسبياً | يُختار عند السعي وراء الجودة |
💰 تحسين التكلفة: بالنسبة للمشاريع ذات الميزانية المحدودة، يمكنك التفكير في استدعاء واجهة برمجة تطبيقات Gemini 3 Flash Preview عبر منصة APIYI apiyi.com. توفر هذه المنصة طرق فوترة مرنة، وبالتكامل مع تقنيات تحسين السرعة المذكورة في هذا المقال، يمكنك الحصول على أفضل قيمة مقابل السعر مع التحكم في التكاليف.
الأسئلة الشائعة حول تحسين سرعة استجابة Gemini 3 Flash Preview
س1: لماذا لا تزال الاستجابة بطيئة رغم تعيين حد لـ max_tokens؟
يتحكم max_tokens فقط في طول المخرجات، ولا يؤثر على عملية تفكير النموذج. إذا كانت الاستجابة بطيئة بسبب طول وقت التفكير، فأنت بحاجة إلى ضبط معامل thinking_level على minimal أو low. بالإضافة إلى ذلك، يمكنك الحصول على خدمات API مستقرة عبر منصة APIYI apiyi.com، والتي تساعد مع تقنيات ضبط المعلمات المذكورة في المقال على تحسين سرعة الاستجابة بشكل فعال.
س2: هل سيؤثر ضبط thinking_level على minimal على جودة الإجابة؟
سيكون هناك بعض التأثير، لكنه ليس كبيراً بالنسبة للمهام البسيطة. مستوى minimal مناسب لسيناريوهات مثل الأسئلة والأجوبة السريعة والمحادثات البسيطة. أما إذا كانت المهمة تتضمن استنتاجاً منطقياً معقداً، فنوصي باستخدام مستوى low أو medium. نقترح إجراء اختبارات A/B عبر منصة APIYI apiyi.com لمقارنة جودة المخرجات تحت مستويات thinking_level المختلفة للعثور على نقطة التوازن الأنسب لعملك.
س3: أيهما أسرع: مخرجات البث (Streaming) أم المخرجات العادية؟
إجمالي وقت التوليد هو نفسه، لكن تجربة المستخدم في مخرجات البث (Streaming) أفضل بكثير. في وضع البث، يمكن للمستخدم رؤية النتائج الجزئية على الفور، بينما يتطلب الوضع العادي انتظار اكتمال التوليد بالكامل. بالنسبة للمهام التي تستغرق وقتاً طويلاً في التوليد، نوصي بشدة باستخدام مخرجات البث.
س4: كيف أحدد المدة المناسبة لمهلة الانتظار (timeout)؟
يجب ضبط الـ timeout بناءً على طول المخرجات المتوقع ومستوى thinking_level:
- minimal + 1000 توكن: 15-30 ثانية
- low + 2000 توكن: 30-60 ثانية
- medium + 4000 توكن: 60-90 ثانية
- high + 8000 توكن: 120-180 ثانية
نوصي باختبار وقت الاستجابة الفعلي باستخدام مهلة انتظار طويلة أولاً، ثم التعديل بناءً على ذلك.
س5: هل لا يزال بإمكاني استخدام معامل thinking_budget القديم؟
نعم، يمكنك الاستمرار في استخدامه، ولكن جوجل توصي بالانتقال إلى معامل thinking_level للحصول على أداء أكثر قابلية للتوقع. يرجى ملاحظة عدم استخدام كلا المعاملين في نفس الطلب. إذا كنت تستخدم سابقاً thinking_budget=0، فيجب عليك ضبط thinking_level="minimal" عند الانتقال.
ملخص
يكمن جوهر تحسين سرعة استجابة Gemini 3 Flash Preview في التكوين الصحيح لثلاثة معاملات رئيسية:
- thinking_level: اختر عمق التفكير المناسب بناءً على تعقيد المهمة.
- max_tokens: قم بتقييد عدد الـ Tokens بناءً على طول المخرجات المتوقع.
- timeout: اضبط وقت مهلة معقول بناءً على مستوى التفكير (thinking_level) وحجم المخرجات.
بالنسبة للسيناريوهات التي "تتطلب سرعة في وقت الاستجابة مع متطلبات دقة غير عالية"، نوصي بالإعدادات التالية:
- thinking_level:
minimalأوlow - max_tokens: قم بضبطه وفقًا للاحتياجات الفعلية لتجنب الطول المفرط.
- timeout: قم بالتعديل وفقًا لذلك لتجنب انقطاع الاستجابة.
- stream:
True(لتحسين تجربة المستخدم).
نوصي باستخدام APIYI (apiyi.com) لاختبار مجموعات المعلمات المختلفة بسرعة، والعثور على أفضل تكوين يناسب سيناريو عملك.
الكلمات المفتاحية: Gemini 3 Flash Preview، تحسين سرعة الاستجابة، thinking_level، max_tokens، تكوين timeout، تحسين استدعاء API.
المراجع:
- وثائق Google AI الرسمية: ai.google.dev/gemini-api/docs/gemini-3
- Google DeepMind: deepmind.google/models/gemini/flash/
- اختبار أداء Artificial Analysis: artificialanalysis.ai/articles/gemini-3-flash-everything-you-need-to-know
تم إعداد هذا المقال بواسطة الفريق التقني في APIYI Team. لمزيد من النصائح حول استخدام نماذج الذكاء الاصطناعي، يرجى زيارة help.apiyi.com