
Waktu respons yang lama saat memanggil model Gemini 3 Flash Preview adalah tantangan yang sering dihadapi oleh para pengembang. Artikel ini akan membahas teknik konfigurasi parameter kunci seperti timeout, max_tokens, dan thinking_level untuk membantu Anda menguasai metode praktis dalam mengoptimalkan kecepatan respons Gemini 3 Flash Preview.
Nilai Inti: Setelah membaca artikel ini, Anda akan belajar cara mengontrol waktu respons Gemini 3 Flash Preview melalui konfigurasi parameter yang tepat, sehingga kecepatan respons meningkat secara signifikan sambil tetap menjaga kualitas output.

Analisis Penyebab Lamanya Waktu Respons Gemini 3 Flash Preview
Sebelum mendalami teknik optimasi, kita perlu memahami mengapa Gemini 3 Flash Preview terkadang membutuhkan waktu respons yang cukup lama.
Mekanisme Thinking Token (Token Berpikir)
Gemini 3 Flash Preview mengadopsi mekanisme berpikir dinamis, yang merupakan alasan utama di balik lamanya waktu respons:
| Faktor Pengaruh | Penjelasan | Dampak pada Waktu Respons |
|---|---|---|
| Tugas Penalaran Kompleks | Pertanyaan yang melibatkan penalaran logika membutuhkan lebih banyak Thinking Token | Meningkatkan waktu respons secara signifikan |
| Kedalaman Berpikir Dinamis | Model menyesuaikan jumlah pemikiran secara otomatis berdasarkan kompleksitas pertanyaan | Cepat untuk masalah sederhana, lambat untuk masalah kompleks |
| Output Non-Streaming | Dalam mode non-streaming, harus menunggu seluruh pembuatan selesai | Waktu tunggu keseluruhan lebih lama |
| Jumlah Token Output | Semakin banyak konten pelengkap, semakin lama waktu pembuatan | Meningkatkan waktu respons secara linear |
Berdasarkan data pengujian dari Artificial Analysis, jumlah token yang digunakan Gemini 3 Flash Preview pada tingkat pemikiran tertinggi bisa mencapai sekitar 160 juta, lebih dari dua kali lipat Gemini 2.5 Flash. Ini berarti pada tugas-tugas kompleks, model akan mengonsumsi banyak "waktu berpikir".
Analisis Kasus Nyata
Dari umpan balik pengguna, ketika tugas memerlukan kecepatan respons namun tidak memerlukan akurasi yang terlalu tinggi, konfigurasi default Gemini 3 Flash Preview mungkin tidak ideal:
"Karena tugas memerlukan kecepatan respons, dan akurasi tidak terlalu menjadi prioritas, namun penalaran gemini-3-flash-preview sangat lama."
Akar penyebab dari situasi ini adalah:
- Model secara default menggunakan pemikiran dinamis dan akan melakukan penalaran mendalam secara otomatis.
- Jumlah token pelengkap (completion) mungkin mencapai 7000+.
- Masih perlu mempertimbangkan tambahan Thinking Token yang dikonsumsi selama proses penalaran.

Poin Penting Optimasi Kecepatan Respons Gemini 3 Flash Preview
| Poin Optimasi | Penjelasan | Efek yang Diharapkan |
|---|---|---|
| Mengatur thinking_level | Mengontrol kedalaman berpikir model | Mengurangi waktu respons sebesar 30-70% |
| Membatasi max_tokens | Mengontrol panjang output | Mengurangi waktu pembuatan (generasi) |
| Menyesuaikan timeout | Mengatur waktu timeout yang masuk akal | Menghindari permintaan terpotong |
| Menggunakan output streaming | Mengembalikan hasil saat sedang dibuat | Meningkatkan pengalaman pengguna |
| Memilih skenario yang tepat | Gunakan tingkat pemikiran rendah untuk tugas sederhana | Peningkatan efisiensi secara keseluruhan |
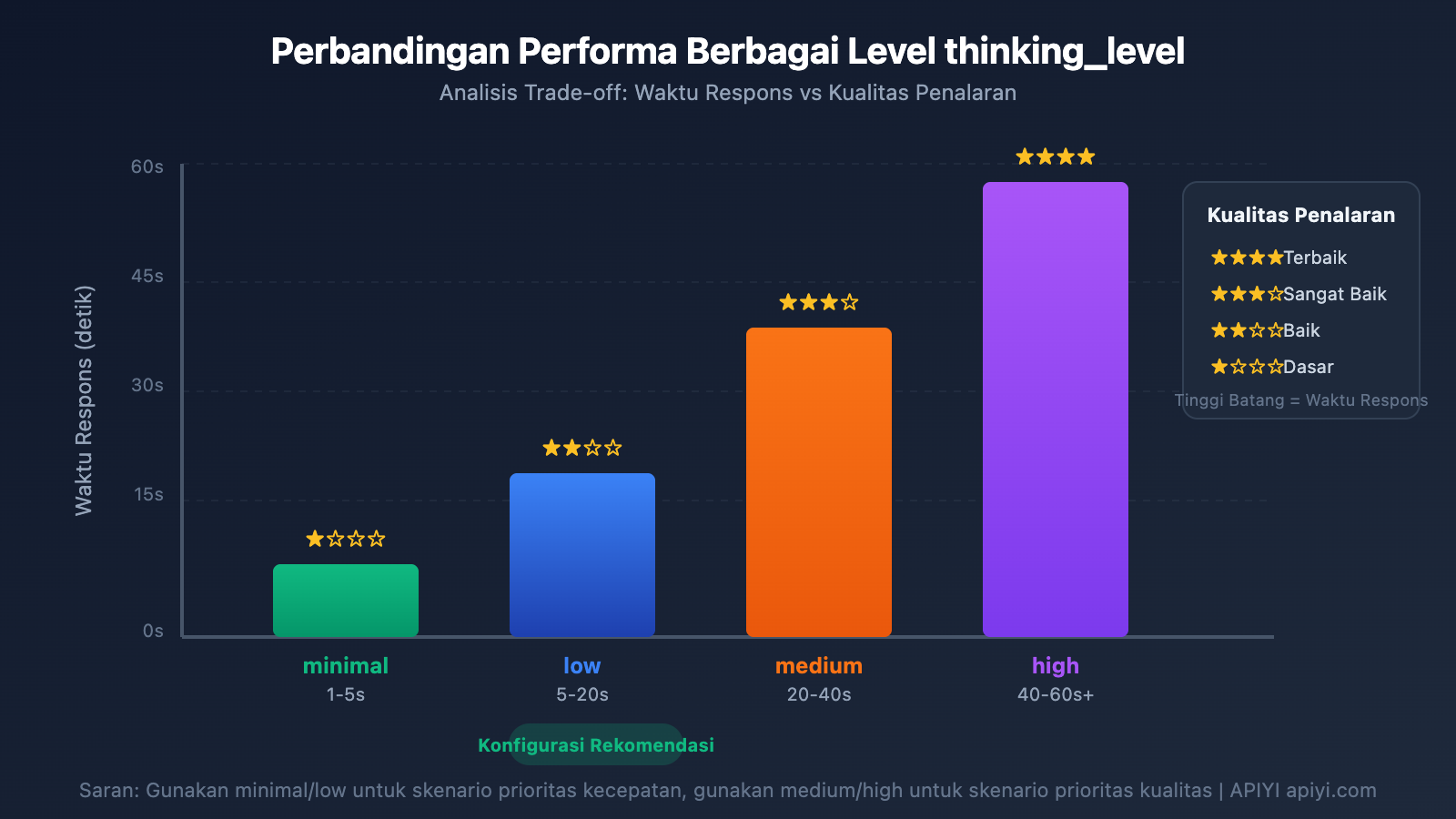
Detail Parameter thinking_level
Gemini 3 memperkenalkan parameter thinking_level, yang merupakan konfigurasi paling krusial untuk mengontrol kecepatan respons:
| thinking_level | Skenario Penggunaan | Kecepatan Respons | Kualitas Penalaran |
|---|---|---|---|
| minimal | Percakapan sederhana, respons cepat | Paling cepat ⚡ | Dasar |
| low | Tugas harian, penalaran ringan | Cepat | Baik |
| medium | Tugas dengan kompleksitas menengah | Menengah | Lebih baik |
| high | Penalaran kompleks, analisis mendalam | Lambat | Terbaik |
🎯 Saran Teknis: Jika tugas Anda tidak memerlukan akurasi tinggi namun butuh respons cepat, disarankan untuk mengatur thinking_level ke
minimalataulow. Kami menyarankan untuk melakukan pengujian perbandingan berbagai thinking_level melalui platform APIYI apiyi.com untuk menemukan konfigurasi yang paling cocok dengan skenario bisnis Anda.
Strategi Konfigurasi Parameter max_tokens
Membatasi max_tokens dapat secara efektif mengontrol panjang output, sehingga mengurangi waktu respons:
Jumlah Token Output → Berpengaruh langsung pada waktu generasi
Semakin banyak jumlah Token → Semakin lama waktu respons
Saran Konfigurasi:
- Skenario jawaban sederhana: Atur max_tokens ke 500-1000
- Pembuatan konten menengah: Atur max_tokens ke 2000-4000
- Output konten lengkap: Atur sesuai kebutuhan, namun perhatikan risiko timeout
⚠️ Catatan: Pengaturan max_tokens yang terlalu pendek akan menyebabkan output terpotong dan memengaruhi kelengkapan jawaban. Anda perlu menyeimbangkan antara kecepatan dan kelengkapan berdasarkan kebutuhan bisnis yang sebenarnya.
Panduan Cepat Optimasi Kecepatan Respons Gemini 3 Flash Preview
Contoh Sederhana
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Menggunakan antarmuka terpadu APIYI
)
# Konfigurasi prioritas kecepatan
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": "简单介绍一下人工智能"}],
max_tokens=1000, # Membatasi panjang output
extra_body={
"thinking_level": "minimal" # Kedalaman berpikir minimal, respons paling cepat
},
timeout=30 # Mengatur timeout 30 detik
)
print(response.choices[0].message.content)
Lihat Kode Lengkap – Termasuk Berbagai Skenario Konfigurasi
import openai
from typing import Literal
def create_gemini_client(api_key: str):
"""Membuat klien Gemini 3 Flash"""
return openai.OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # Menggunakan antarmuka terpadu APIYI
)
def call_gemini_optimized(
client: openai.OpenAI,
prompt: str,
thinking_level: Literal["minimal", "low", "medium", "high"] = "low",
max_tokens: int = 2000,
timeout: int = 60,
stream: bool = False
):
"""
Pemanggilan Gemini 3 Flash dengan konfigurasi yang dioptimalkan
Parameter:
client: Klien OpenAI
prompt: Input pengguna
thinking_level: Kedalaman berpikir (minimal/low/medium/high)
max_tokens: Jumlah Token output maksimum
timeout: Waktu timeout (detik)
stream: Apakah menggunakan output streaming
"""
params = {
"model": "gemini-3-flash-preview",
"messages": [{"role": "user", "content": prompt}],
"max_tokens": max_tokens,
"stream": stream,
"extra_body": {
"thinking_level": thinking_level
},
"timeout": timeout
}
if stream:
# Output streaming - Meningkatkan pengalaman pengguna
response = client.chat.completions.create(**params)
full_content = ""
for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
print(content, end="", flush=True)
full_content += content
print() # Baris baru
return full_content
else:
# Output non-streaming - Mengembalikan hasil sekaligus
response = client.chat.completions.create(**params)
return response.choices[0].message.content
# Contoh penggunaan
if __name__ == "__main__":
client = create_gemini_client("YOUR_API_KEY")
# Skenario 1: Prioritas kecepatan - Tanya jawab sederhana
print("=== Konfigurasi Prioritas Kecepatan ===")
result = call_gemini_optimized(
client,
prompt="用一句话解释什么是机器学习",
thinking_level="minimal",
max_tokens=500,
timeout=15
)
print(f"Jawaban: {result}\n")
# Skenario 2: Konfigurasi seimbang - Tugas harian
print("=== Konfigurasi Seimbang ===")
result = call_gemini_optimized(
client,
prompt="列出 5 个 Python 数据处理的最佳实践",
thinking_level="low",
max_tokens=1500,
timeout=30
)
print(f"Jawaban: {result}\n")
# Skenario 3: Prioritas kualitas - Analisis kompleks
print("=== Konfigurasi Prioritas Kualitas ===")
result = call_gemini_optimized(
client,
prompt="分析 Transformer 架构的核心创新点及其对 NLP 的影响",
thinking_level="high",
max_tokens=4000,
timeout=120
)
print(f"Jawaban: {result}\n")
# Skenario 4: Output streaming - Meningkatkan pengalaman
print("=== Output Streaming ===")
result = call_gemini_optimized(
client,
prompt="介绍 Gemini 3 Flash 的主要特点",
thinking_level="low",
max_tokens=2000,
timeout=60,
stream=True
)
🚀 Mulai Cepat: Direkomendasikan menggunakan platform APIYI apiyi.com untuk menguji berbagai konfigurasi parameter dengan cepat. Platform ini menyediakan antarmuka API yang siap pakai, mendukung model-model populer seperti Gemini 3 Flash Preview, memudahkan verifikasi hasil optimasi dengan cepat.
Detail Konfigurasi Parameter Optimasi Kecepatan Respons Gemini 3 Flash Preview
Konfigurasi timeout (Waktu Habis)
Saat menggunakan Gemini 3 Flash Preview untuk penalaran yang kompleks, waktu habis (timeout) default mungkin tidak cukup. Berikut adalah strategi konfigurasi timeout yang direkomendasikan:
| Tipe Tugas | Rekomendasi timeout | Penjelasan |
|---|---|---|
| Tanya Jawab Sederhana | 15-30 detik | Dipadukan dengan thinking_level minimal |
| Tugas Harian | 30-60 detik | Dipadukan dengan thinking_level low/medium |
| Analisis Kompleks | 60-120 detik | Dipadukan dengan thinking_level high |
| Generasi Teks Panjang | 120-180 detik | Skenario dengan output Token dalam jumlah besar |
Tip Kunci:
- Dalam mode output non-streaming, Anda harus menunggu seluruh konten selesai dibuat sebelum hasilnya dikembalikan.
- Jika timeout diatur terlalu singkat, permintaan mungkin akan terputus.
- Disarankan untuk menyesuaikan secara dinamis berdasarkan jumlah output Token aktual dan thinking_level.
Migrasi thinking_level dari thinking_budget Versi Lama
Google merekomendasikan migrasi dari parameter thinking_budget versi lama ke thinking_level versi baru:
| thinking_budget Versi Lama | thinking_level Versi Baru | Penjelasan Migrasi |
|---|---|---|
| 0 | minimal | Pemikiran minimal, perhatikan masih perlu menangani tanda tangan pemikiran |
| 1-1000 | low | Pemikiran ringan |
| 1001-5000 | medium | Pemikiran sedang |
| 5001+ | high | Pemikiran mendalam |
⚠️ Perhatian: Jangan gunakan thinking_budget dan thinking_level secara bersamaan dalam satu permintaan, karena ini akan menyebabkan perilaku yang tidak terduga.
Solusi Konfigurasi Berdasarkan Skenario Optimasi Kecepatan Respons Gemini 3 Flash Preview
Skenario 1: Tugas Sederhana Frekuensi Tinggi (Prioritas Kecepatan)
Cocok untuk chatbot, tanya jawab cepat, ringkasan konten, dan skenario lain yang sensitif terhadap latensi:
# Konfigurasi prioritas kecepatan
config_speed_first = {
"thinking_level": "minimal",
"max_tokens": 500,
"timeout": 15,
"stream": True # Output streaming untuk meningkatkan pengalaman
}
Efek yang Diharapkan:
- Waktu respons: 1-5 detik
- Cocok untuk percakapan sederhana dan balasan cepat
Skenario 2: Tugas Bisnis Harian (Konfigurasi Seimbang)
Cocok untuk pembuatan konten, bantuan kode, pemrosesan dokumen, dan tugas rutin lainnya:
# Konfigurasi seimbang
config_balanced = {
"thinking_level": "low",
"max_tokens": 2000,
"timeout": 45,
"stream": True
}
Efek yang Diharapkan:
- Waktu respons: 5-20 detik
- Keseimbangan yang baik antara kualitas dan kecepatan
Skenario 3: Tugas Analisis Kompleks (Prioritas Kualitas)
Cocok untuk analisis data, desain solusi teknis, penelitian mendalam, dan skenario lain yang memerlukan penalaran mendalam:
# Konfigurasi prioritas kualitas
config_quality_first = {
"thinking_level": "high",
"max_tokens": 8000,
"timeout": 180,
"stream": True # Disarankan menggunakan streaming untuk tugas panjang
}
Efek yang Diharapkan:
- Waktu respons: 30-120 detik
- Kualitas penalaran terbaik
Tabel Keputusan Pemilihan Konfigurasi
| Kebutuhan Anda | thinking_level Rekomendasi | max_tokens Rekomendasi | timeout Rekomendasi |
|---|---|---|---|
| Balasan cepat, pertanyaan sederhana | minimal | 500-1000 | 15-30s |
| Tugas harian, kualitas umum | low | 1500-2500 | 30-60s |
| Kualitas sangat baik, bisa menunggu | medium | 2500-4000 | 60-90s |
| Kualitas terbaik, tugas kompleks | high | 4000-8000 | 120-180s |
💡 Saran Pemilihan: Pilihan konfigurasi mana yang akan digunakan sangat bergantung pada skenario aplikasi spesifik dan persyaratan kualitas Anda. Kami menyarankan untuk melakukan pengujian aktual melalui platform APIYI apiyi.com untuk membuat pilihan yang paling sesuai dengan kebutuhan Anda. Platform ini mendukung panggilan antarmuka terpadu untuk Gemini 3 Flash Preview, memudahkan perbandingan cepat efek dari berbagai konfigurasi.
Teknik Lanjutan Optimasi Kecepatan Respons Gemini 3 Flash Preview
Teknik 1: Gunakan Output Streaming untuk Meningkatkan Pengalaman Pengguna
Meskipun total waktu respons tidak berubah, output streaming dapat secara signifikan meningkatkan pengalaman yang dirasakan pengguna:
# 流式输出示例
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": prompt}],
stream=True,
extra_body={"thinking_level": "low"}
)
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
Keunggulan:
- Pengguna dapat segera melihat hasil sebagian.
- Mengurangi "kecemasan saat menunggu".
- Dapat memutuskan apakah akan melanjutkan selama proses pembuatan.
Teknik 2: Sesuaikan Parameter Secara Dinamis Berdasarkan Kompleksitas Input
def estimate_complexity(prompt: str) -> str:
"""根据 prompt 特征估算任务复杂度"""
indicators = {
"high": ["分析", "对比", "为什么", "原理", "深入", "详细解释"],
"medium": ["如何", "步骤", "方法", "介绍"],
"low": ["是什么", "简单", "快速", "一句话"]
}
prompt_lower = prompt.lower()
for level, keywords in indicators.items():
if any(kw in prompt_lower for kw in keywords):
return level
return "low" # 默认低复杂度
def get_optimized_config(prompt: str) -> dict:
"""根据 prompt 获取优化配置"""
complexity = estimate_complexity(prompt)
configs = {
"low": {"thinking_level": "minimal", "max_tokens": 1000, "timeout": 20},
"medium": {"thinking_level": "low", "max_tokens": 2500, "timeout": 45},
"high": {"thinking_level": "medium", "max_tokens": 4000, "timeout": 90}
}
return configs.get(complexity, configs["low"])
Teknik 3: Implementasi Mekanisme Retry Permintaan
Untuk masalah timeout yang jarang terjadi, Anda dapat mengimplementasikan retry yang cerdas:
import time
from typing import Optional
def call_with_retry(
client,
prompt: str,
max_retries: int = 3,
initial_timeout: int = 30
) -> Optional[str]:
"""带重试机制的调用"""
for attempt in range(max_retries):
try:
timeout = initial_timeout * (attempt + 1) # 递增超时
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": prompt}],
max_tokens=2000,
timeout=timeout,
extra_body={"thinking_level": "low"}
)
return response.choices[0].message.content
except Exception as e:
print(f"尝试 {attempt + 1} 失败: {e}")
if attempt < max_retries - 1:
time.sleep(2 ** attempt) # 指数退避
continue
return None

Data Referensi Performa Gemini 3 Flash Preview
Berdasarkan data pengujian dari Artificial Analysis, performa Gemini 3 Flash Preview adalah sebagai berikut:
| Metrik Performa | Nilai | Penjelasan |
|---|---|---|
| Throughput Mentah | 218 token/detik | Kecepatan output |
| Dibandingkan dengan 2.5 Flash | Lebih lambat 22% | Karena adanya penambahan kemampuan penalaran |
| Dibandingkan dengan GPT-5.1 high | Lebih cepat 74% | 125 token/detik |
| Dibandingkan dengan DeepSeek V3.2 | Lebih cepat 627% | 30 token/detik |
| Harga Input | $0.50/1 jt token | |
| Harga Output | $3.00/1 jt token |
Keseimbangan Performa dan Biaya
| Skema Konfigurasi | Kecepatan Respons | Konsumsi Token | Efektivitas Biaya |
|---|---|---|---|
| minimal thinking | Tercepat | Terendah | Tertinggi |
| low thinking | Cepat | Rendah | Tinggi |
| medium thinking | Sedang | Sedang | Sedang |
| high thinking | Lambat | Tinggi | Pilih saat mengutamakan kualitas |
💰 Optimasi Biaya: Untuk proyek yang sensitif terhadap anggaran, kamu bisa mempertimbangkan untuk memanggil Gemini 3 Flash Preview API melalui platform APIYI apiyi.com. Platform ini menawarkan metode penagihan yang fleksibel, dan jika dikombinasikan dengan teknik optimasi kecepatan dalam artikel ini, kamu bisa mendapatkan rasio performa-biaya (value for money) terbaik sambil tetap mengontrol pengeluaran.
Tanya Jawab Umum Optimasi Kecepatan Respons Gemini 3 Flash Preview
Q1: Mengapa respons masih lambat padahal sudah mengatur batasan max_tokens?
max_tokens hanya membatasi panjang output, bukan proses berpikir model. Jika respons lambat terutama karena waktu berpikir yang lama, kamu perlu mengatur parameter thinking_level ke minimal atau low. Selain itu, melalui platform APIYI apiyi.com, kamu bisa mendapatkan layanan API yang stabil, yang jika dipadukan dengan teknik konfigurasi parameter di artikel ini, akan efektif meningkatkan kecepatan respons.
Q2: Apakah mengatur thinking_level ke minimal akan memengaruhi kualitas jawaban?
Akan ada sedikit pengaruh, tetapi untuk tugas-tugas sederhana dampaknya tidak besar. Level minimal cocok untuk skenario seperti tanya jawab cepat atau percakapan sederhana. Jika tugas melibatkan penalaran logika yang kompleks, disarankan untuk menggunakan level low atau medium. Kamu bisa melakukan pengujian A/B melalui platform APIYI apiyi.com untuk membandingkan kualitas output pada berbagai thinking_level guna menemukan titik keseimbangan yang paling sesuai dengan kebutuhan bisnismu.
Q3: Mana yang lebih cepat, output streaming atau non-streaming?
Total waktu pembuatan (generation time) sebenarnya sama, tetapi output streaming memberikan pengalaman pengguna yang lebih baik. Dalam mode streaming, pengguna bisa langsung melihat sebagian hasil, sementara mode non-streaming mengharuskan pengguna menunggu sampai seluruh teks selesai dibuat. Untuk tugas dengan waktu pembuatan yang lama, sangat direkomendasikan untuk menggunakan output streaming.
Q4: Bagaimana cara menentukan berapa lama timeout harus diatur?
Timeout sebaiknya diatur berdasarkan estimasi panjang output dan thinking_level:
- minimal + 1000 token: 15-30 detik
- low + 2000 token: 30-60 detik
- medium + 4000 token: 60-90 detik
- high + 8000 token: 120-180 detik
Disarankan untuk menguji waktu respons aktual dengan timeout yang lebih panjang terlebih dahulu, lalu sesuaikan berdasarkan hasil tersebut.
Q5: Apakah parameter lama thinking_budget masih bisa digunakan?
Masih bisa digunakan, tetapi Google merekomendasikan migrasi ke parameter thinking_level untuk mendapatkan performa yang lebih terprediksi. Perlu diingat untuk tidak menggunakan kedua parameter tersebut secara bersamaan dalam satu permintaan. Jika sebelumnya kamu menggunakan thinking_budget=0, saat migrasi sebaiknya atur thinking_level="minimal".
Kesimpulan
Inti dari optimalisasi kecepatan respons Gemini 3 Flash Preview terletak pada konfigurasi yang tepat dari tiga parameter kunci:
- thinking_level: Pilih kedalaman berpikir yang sesuai berdasarkan kompleksitas tugas.
- max_tokens: Batasi jumlah Token berdasarkan panjang output yang diharapkan.
- timeout: Atur timeout yang masuk akal berdasarkan
thinking_leveldan volume output.
Untuk skenario di mana "tugas memiliki tuntutan kecepatan waktu respons yang tinggi, namun tidak memerlukan akurasi yang terlalu tinggi", konfigurasi yang direkomendasikan adalah:
- thinking_level:
minimalataulow - max_tokens: Atur sesuai kebutuhan aktual, hindari pengaturan yang terlalu panjang.
- timeout: Sesuaikan sebagaimana mestinya untuk menghindari pemutusan (truncated).
- stream:
True(meningkatkan pengalaman pengguna).
Direkomendasikan untuk menggunakan APIYI apiyi.com guna menguji berbagai kombinasi parameter dengan cepat dan menemukan solusi konfigurasi yang paling sesuai untuk skenario bisnis Anda.
Kata Kunci: Gemini 3 Flash Preview, optimalisasi kecepatan respons, thinking_level, max_tokens, konfigurasi timeout, optimalisasi panggilan API
Referensi:
- Dokumentasi Resmi Google AI: ai.google.dev/gemini-api/docs/gemini-3
- Google DeepMind: deepmind.google/models/gemini/flash/
- Uji Performa Artificial Analysis: artificialanalysis.ai/articles/gemini-3-flash-everything-you-need-to-know
Artikel ini ditulis oleh tim teknis APIYI Team. Untuk tips penggunaan model AI lainnya, silakan kunjungi help.apiyi.com