
Le temps de réponse excessif lors de l'appel au modèle Gemini 3 Flash Preview est un défi courant pour les développeurs. Cet article présente les astuces de configuration des paramètres clés tels que timeout, max_tokens et thinking_level, pour vous aider à maîtriser rapidement les méthodes d'optimisation de la vitesse de réponse de Gemini 3 Flash Preview.
Valeur ajoutée : Après avoir lu cet article, vous saurez comment contrôler le temps de réponse de Gemini 3 Flash Preview via une configuration judicieuse des paramètres, afin d'obtenir une amélioration significative de la vitesse tout en garantissant la qualité de la sortie.

Analyse des causes des temps de réponse longs de Gemini 3 Flash Preview
Avant de plonger dans les techniques d'optimisation, nous devons comprendre pourquoi Gemini 3 Flash Preview peut parfois mettre du temps à répondre.
Le mécanisme des Thinking Tokens (Jetons de réflexion)
Gemini 3 Flash Preview utilise un mécanisme de réflexion dynamique, qui est la cause principale de l'allongement du temps de réponse :
| Facteurs d'influence | Description | Impact sur le temps de réponse |
|---|---|---|
| Tâches de raisonnement complexe | Les questions impliquant un raisonnement logique nécessitent plus de jetons de réflexion | Augmentation significative |
| Profondeur de réflexion dynamique | Le modèle ajuste automatiquement la quantité de réflexion selon la complexité | Rapide pour le simple, lent pour le complexe |
| Sortie non-streaming | En mode classique, il faut attendre la fin de toute la génération | Temps d'attente global plus long |
| Nombre de jetons de sortie | Plus le contenu généré est long, plus le temps de création est élevé | Augmentation linéaire |
Selon les données de tests d'Artificial Analysis, la quantité de jetons utilisée par Gemini 3 Flash Preview au niveau de réflexion maximal peut atteindre environ 160 millions, soit plus du double de Gemini 2.5 Flash. Cela signifie que sur des tâches complexes, le modèle consomme énormément de "temps de réflexion".
Analyse de cas réel
D'après les retours utilisateurs, lorsque la tâche exige de la rapidité mais ne nécessite pas une précision absolue, la configuration par défaut de Gemini 3 Flash Preview peut s'avérer sous-optimale :
"Parce que ma tâche nécessite une réponse rapide et que la précision n'est pas critique, mais le raisonnement de gemini-3-flash-preview est interminable."
La cause profonde de cette situation est :
- Le modèle utilise par défaut la réflexion dynamique et effectue automatiquement un raisonnement approfondi.
- Le nombre de jetons de complétion peut dépasser les 7000+.
- Il faut également prendre en compte les jetons de réflexion consommés pendant le processus de raisonnement.
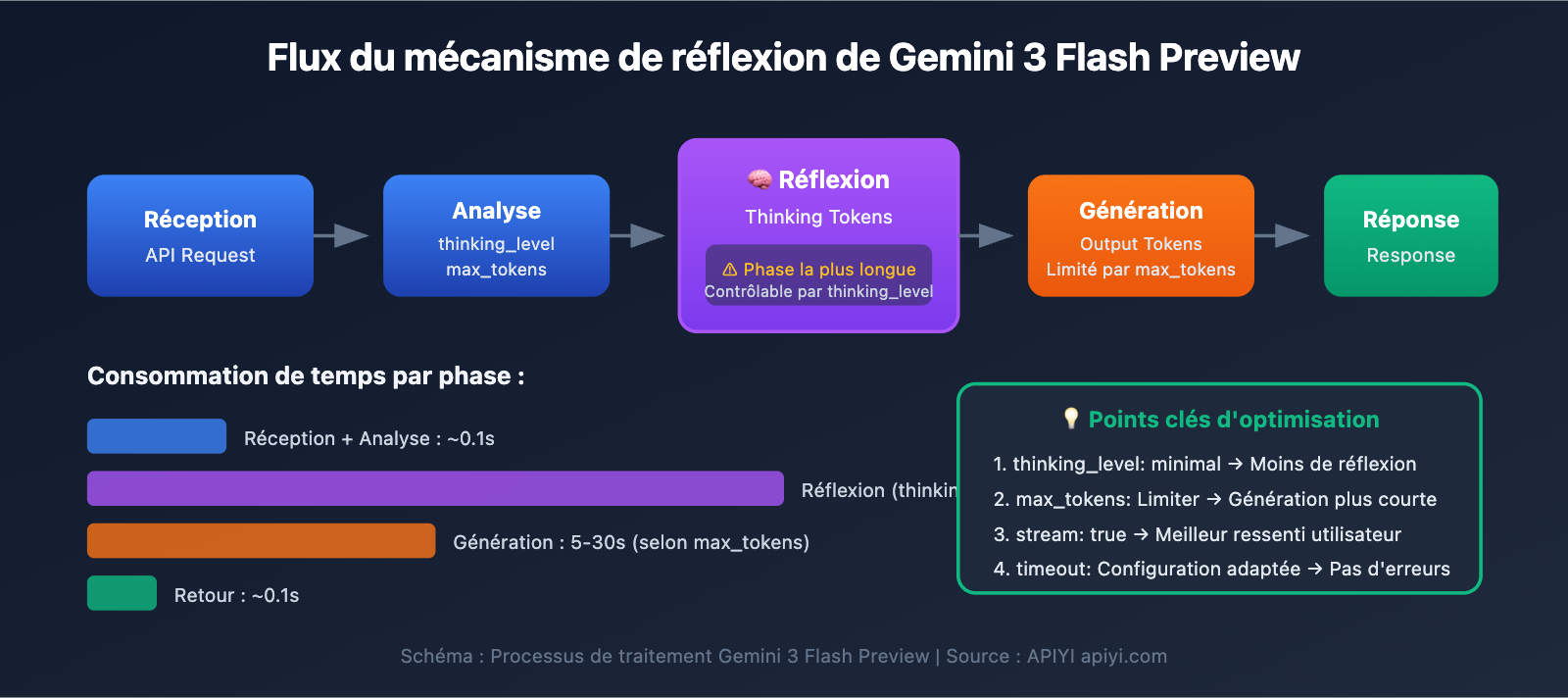
Points clés d'optimisation de la vitesse de réponse pour Gemini 3 Flash Preview
| Point d'optimisation | Description | Effet attendu |
|---|---|---|
| Configurer le thinking_level | Contrôle la profondeur de réflexion du modèle | Réduction de 30 à 70 % du temps de réponse |
| Limiter les max_tokens | Contrôle la longueur de la sortie | Réduit le temps de génération |
| Ajuster le timeout | Définit un délai d'expiration raisonnable | Évite que la requête ne soit interrompue |
| Utiliser le streaming | Retourne les données au fur et à mesure | Améliore l'expérience utilisateur |
| Choisir le scénario approprié | Niveau de réflexion bas pour les tâches simples | Amélioration globale de l'efficacité |
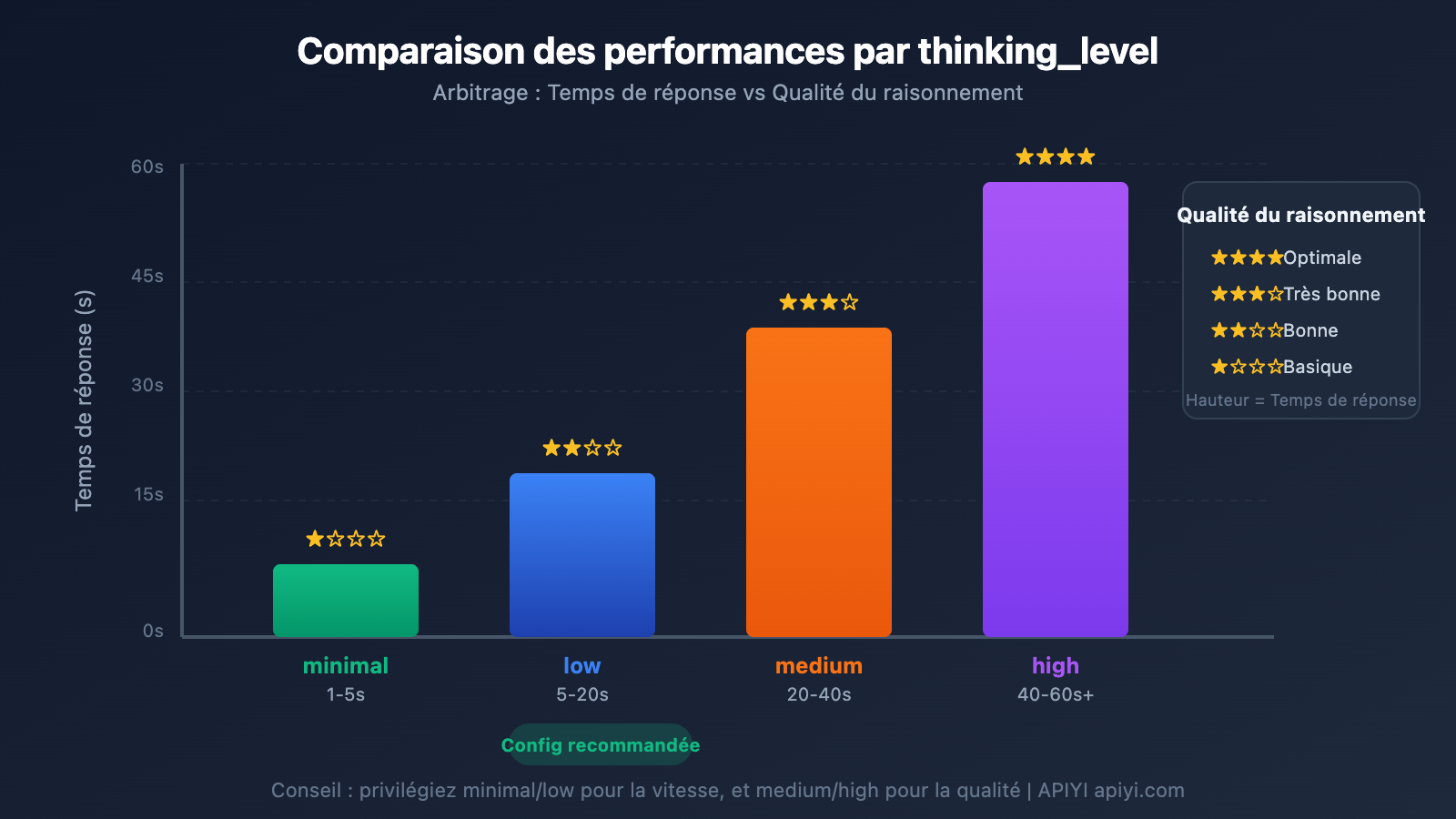
Détails du paramètre thinking_level
Gemini 3 introduit le paramètre thinking_level, qui est la configuration la plus cruciale pour contrôler la vitesse de réponse :
| thinking_level | Cas d'utilisation | Vitesse de réponse | Qualité du raisonnement |
|---|---|---|---|
| minimal | Conversations simples, réponses rapides | La plus rapide ⚡ | Basique |
| low | Tâches quotidiennes, raisonnement léger | Rapide | Bonne |
| medium | Tâches de complexité moyenne | Moyenne | Très bonne |
| high | Raisonnement complexe, analyse approfondie | Lente | Optimale |
🎯 Conseil technique : Si votre tâche ne nécessite pas une précision extrême mais requiert une réponse rapide, nous vous suggérons de régler le
thinking_levelsurminimaloulow. Nous vous recommandons d'effectuer des tests comparatifs entre les différents niveaux via la plateforme APIYI (apiyi.com) afin de trouver rapidement la configuration la mieux adaptée à votre scénario métier.
Stratégie de configuration du paramètre max_tokens
Limiter les max_tokens permet de contrôler efficacement la longueur de la sortie, réduisant ainsi le temps de réponse :
Nombre de tokens en sortie → Influence directe sur le temps de génération
Plus le nombre de tokens est élevé → Plus le temps de réponse est long
Conseils de configuration :
- Scénarios de réponses simples : réglez
max_tokensentre 500 et 1000. - Génération de contenu moyen : réglez
max_tokensentre 2000 et 4000. - Sortie de contenu complet : à définir selon les besoins réels, mais attention au risque de timeout.
⚠️ Attention : Un réglage trop court des max_tokens entraînera une coupure de la réponse, affectant son exhaustivité. Il est nécessaire de trouver un équilibre entre vitesse et complétude selon vos besoins métier.
Prise en main rapide pour l'optimisation de la vitesse de réponse de Gemini 3 Flash Preview
Exemple minimaliste
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Utilisation de l'interface unifiée d'APIYI
)
# Configuration orientée vitesse
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": "Présente brièvement l'intelligence artificielle"}],
max_tokens=1000, # Limiter la longueur de la sortie
extra_body={
"thinking_level": "minimal" # Profondeur de réflexion minimale, réponse la plus rapide
},
timeout=30 # Définir un timeout de 30 secondes
)
print(response.choices[0].message.content)
Voir le code complet – Inclut plusieurs scénarios de configuration
import openai
from typing import Literal
def create_gemini_client(api_key: str):
"""Création du client Gemini 3 Flash"""
return openai.OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # Utilisation de l'interface unifiée d'APIYI
)
def call_gemini_optimized(
client: openai.OpenAI,
prompt: str,
thinking_level: Literal["minimal", "low", "medium", "high"] = "low",
max_tokens: int = 2000,
timeout: int = 60,
stream: bool = False
):
"""
Appel Gemini 3 Flash avec configuration optimisée
Paramètres :
client: Client OpenAI
prompt: Entrée utilisateur (invite)
thinking_level: Profondeur de réflexion (minimal/low/medium/high)
max_tokens: Nombre maximum de tokens en sortie
timeout: Délai d'expiration (secondes)
stream: Utiliser ou non le streaming
"""
params = {
"model": "gemini-3-flash-preview",
"messages": [{"role": "user", "content": prompt}],
"max_tokens": max_tokens,
"stream": stream,
"extra_body": {
"thinking_level": thinking_level
},
"timeout": timeout
}
if stream:
# Streaming - Améliore l'expérience utilisateur
response = client.chat.completions.create(**params)
full_content = ""
for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
print(content, end="", flush=True)
full_content += content
print() # Nouvelle ligne
return full_content
else:
# Sans streaming - Retourne tout d'un coup
response = client.chat.completions.create(**params)
return response.choices[0].message.content
# Exemple d'utilisation
if __name__ == "__main__":
client = create_gemini_client("YOUR_API_KEY")
# Scénario 1 : Priorité à la vitesse - Questions/réponses simples
print("=== Configuration Priorité Vitesse ===")
result = call_gemini_optimized(
client,
prompt="Explique ce qu'est le machine learning en une phrase",
thinking_level="minimal",
max_tokens=500,
timeout=15
)
print(f"Réponse : {result}\n")
# Scénario 2 : Configuration équilibrée - Tâches quotidiennes
print("=== Configuration Équilibrée ===")
result = call_gemini_optimized(
client,
prompt="Liste 5 meilleures pratiques pour le traitement de données en Python",
thinking_level="low",
max_tokens=1500,
timeout=30
)
print(f"Réponse : {result}\n")
# Scénario 3 : Priorité à la qualité - Analyse complexe
print("=== Configuration Priorité Qualité ===")
result = call_gemini_optimized(
client,
prompt="Analyser les innovations clés de l'architecture Transformer et son impact sur le NLP",
thinking_level="high",
max_tokens=4000,
timeout=120
)
print(f"Réponse : {result}\n")
# Scénario 4 : Streaming - Amélioration de l'expérience
print("=== Flux de sortie (Streaming) ===")
result = call_gemini_optimized(
client,
prompt="Présenter les caractéristiques principales de Gemini 3 Flash",
thinking_level="low",
max_tokens=2000,
timeout=60,
stream=True
)
🚀 Démarrage rapide : Il est recommandé d'utiliser la plateforme APIYI (apiyi.com) pour tester rapidement différentes configurations de paramètres. La plateforme propose des interfaces API prêtes à l'emploi, supportant les grands modèles de langage phares comme Gemini 3 Flash Preview, facilitant ainsi la validation rapide des optimisations.
Détails de la configuration des paramètres d'optimisation de la vitesse de réponse pour Gemini 3 Flash Preview
Configuration du timeout (délai d'expiration)
Lors de l'utilisation de Gemini 3 Flash Preview pour des raisonnements complexes, le timeout par défaut peut s'avérer insuffisant. Voici une stratégie de configuration recommandée pour le timeout :
| Type de tâche | Timeout recommandé | Explication |
|---|---|---|
| Questions-réponses simples | 15-30 secondes | À utiliser avec thinking_level minimal |
| Tâches quotidiennes | 30-60 secondes | À utiliser avec thinking_level low/medium |
| Analyse complexe | 60-120 secondes | À utiliser avec thinking_level high |
| Génération de texte long | 120-180 secondes | Scénarios avec un volume important de tokens en sortie |
Conseils clés :
- En mode de sortie non-streaming (non flux), il faut attendre que l'intégralité du contenu soit générée avant de recevoir une réponse.
- Si le timeout est trop court, la requête risque d'être interrompue prématurément.
- Il est conseillé d'ajuster dynamiquement le timeout en fonction du volume de tokens attendu et du
thinking_levelchoisi.
Migration de l'ancien thinking_budget vers le nouveau thinking_level
Google recommande de passer de l'ancien paramètre thinking_budget au nouveau thinking_level :
| Ancien thinking_budget | Nouveau thinking_level | Note de migration |
|---|---|---|
| 0 | minimal | Réflexion minimale (attention, il faut toujours gérer la signature de réflexion) |
| 1-1000 | low | Réflexion légère |
| 1001-5000 | medium | Réflexion modérée |
| 5001+ | high | Réflexion profonde |
⚠️ Attention : N'utilisez pas simultanément thinking_budget et thinking_level dans la même requête, cela pourrait provoquer des comportements imprévisibles.
Solutions de configuration par scénario pour l'optimisation de la vitesse de réponse de Gemini 3 Flash Preview
Scénario 1 : Tâches simples à haute fréquence (Priorité à la vitesse)
Adapté aux chatbots, aux questions-réponses rapides, aux résumés de contenu et autres scénarios sensibles à la latence :
# Configuration priorité vitesse
config_speed_first = {
"thinking_level": "minimal",
"max_tokens": 500,
"timeout": 15,
"stream": True # L'affichage en streaming améliore l'expérience
}
Effet attendu :
- Temps de réponse : 1 à 5 secondes
- Idéal pour les conversations simples et les réponses rapides
Scénario 2 : Tâches professionnelles quotidiennes (Configuration équilibrée)
Adapté à la génération de contenu, l'assistance au code, le traitement de documents et autres tâches courantes :
# Configuration équilibrée
config_balanced = {
"thinking_level": "low",
"max_tokens": 2000,
"timeout": 45,
"stream": True
}
Effet attendu :
- Temps de réponse : 5 à 20 secondes
- Un bon équilibre entre qualité et vitesse
Scénario 3 : Tâches d'analyse complexes (Priorité à la qualité)
Adapté à l'analyse de données, la conception de solutions techniques, la recherche approfondie et tout scénario nécessitant un raisonnement poussé :
# Configuration priorité qualité
config_quality_first = {
"thinking_level": "high",
"max_tokens": 8000,
"timeout": 180,
"stream": True # Streaming recommandé pour les tâches longues
}
Effet attendu :
- Temps de réponse : 30 à 120 secondes
- Meilleure qualité de raisonnement
Tableau de décision pour le choix de la configuration
| Votre besoin | thinking_level recommandé | max_tokens recommandé | timeout recommandé |
|---|---|---|---|
| Réponses rapides, questions simples | minimal | 500-1000 | 15-30s |
| Tâches quotidiennes, qualité standard | low | 1500-2500 | 30-60s |
| Bonne qualité, attente acceptable | medium | 2500-4000 | 60-90s |
| Qualité optimale, tâches complexes | high | 4000-8000 | 120-180s |
💡 Conseil de sélection : Le choix de la configuration dépend principalement de votre cas d'utilisation spécifique et de vos exigences de qualité. Nous vous recommandons d'effectuer des tests réels via la plateforme APIYI (apiyi.com) afin de choisir l'option la plus adaptée à vos besoins. Cette plateforme permet d'appeler Gemini 3 Flash Preview via une interface unifiée, ce qui facilite la comparaison rapide des effets de différentes configurations.
Astuces avancées pour optimiser la vitesse de réponse de Gemini 3 Flash Preview
Astuce 1 : Utiliser le streaming pour améliorer l'expérience utilisateur
Même si le temps de réponse total reste le même, le streaming améliore considérablement la perception de la vitesse par l'utilisateur :
# Exemple de sortie en streaming
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": prompt}],
stream=True,
extra_body={"thinking_level": "low"}
)
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
Avantages :
- L'utilisateur voit immédiatement les premiers résultats
- Réduit l'« anxiété liée à l'attente »
- Permet de décider d'interrompre ou non la génération en cours de route
Astuce 2 : Ajuster dynamiquement les paramètres selon la complexité de l'entrée
def estimate_complexity(prompt: str) -> str:
"""Estime la complexité de la tâche selon les caractéristiques de l'invite"""
indicators = {
"high": ["analyser", "comparer", "pourquoi", "principe", "approfondi", "explication détaillée"],
"medium": ["comment", "étapes", "méthode", "présenter"],
"low": ["c'est quoi", "simple", "rapide", "en une phrase"]
}
prompt_lower = prompt.lower()
for level, keywords in indicators.items():
if any(kw in prompt_lower for kw in keywords):
return level
return "low" # Basse complexité par défaut
def get_optimized_config(prompt: str) -> dict:
"""Récupère la configuration optimisée selon l'invite"""
complexity = estimate_complexity(prompt)
configs = {
"low": {"thinking_level": "minimal", "max_tokens": 1000, "timeout": 20},
"medium": {"thinking_level": "low", "max_tokens": 2500, "timeout": 45},
"high": {"thinking_level": "medium", "max_tokens": 4000, "timeout": 90}
}
return configs.get(complexity, configs["low"])
Astuce 3 : Implémenter un mécanisme de tentative (retry)
Pour les problèmes de timeout occasionnels, vous pouvez implémenter un retry intelligent :
import time
from typing import Optional
def call_with_retry(
client,
prompt: str,
max_retries: int = 3,
initial_timeout: int = 30
) -> Optional[str]:
"""Appel avec mécanisme de tentative"""
for attempt in range(max_retries):
try:
timeout = initial_timeout * (attempt + 1) # Timeout incrémental
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": prompt}],
max_tokens=2000,
timeout=timeout,
extra_body={"thinking_level": "low"}
)
return response.choices[0].message.content
except Exception as e:
print(f"Tentative {attempt + 1} échouée : {e}")
if attempt < max_retries - 1:
time.sleep(2 ** attempt) # Backoff exponentiel
continue
return None

Données de performance de Gemini 3 Flash Preview
Selon les données de test d'Artificial Analysis, les performances de Gemini 3 Flash Preview sont les suivantes :
| Indicateur de performance | Valeur | Description |
|---|---|---|
| Débit brut | 218 tokens/seconde | Vitesse de sortie |
| Comparé au 2.5 Flash | 22 % plus lent | En raison de l'ajout des capacités de raisonnement |
| Comparé à GPT-5.1 high | 74 % plus rapide | 125 tokens/seconde |
| Comparé à DeepSeek V3.2 | 627 % plus rapide | 30 tokens/seconde |
| Prix d'entrée (Input) | 0,50 $ / 1M tokens | |
| Prix de sortie (Output) | 3,00 $ / 1M tokens |
Équilibre entre performance et coût
| Configuration | Vitesse de réponse | Consommation de tokens | Rentabilité |
|---|---|---|---|
| minimal thinking | La plus rapide | Minimale | Maximale |
| low thinking | Rapide | Faible | Élevée |
| medium thinking | Moyenne | Moyenne | Moyenne |
| high thinking | Lente | Élevée | À choisir lorsque la priorité est la qualité |
💰 Optimisation des coûts : Pour les projets sensibles au budget, vous pouvez envisager d'appeler l'API Gemini 3 Flash Preview via la plateforme APIYI (apiyi.com). Cette plateforme offre une facturation flexible qui, combinée aux astuces d'optimisation de vitesse de cet article, permet d'obtenir le meilleur rapport qualité-prix tout en contrôlant les coûts.
FAQ sur l'optimisation de la vitesse de réponse de Gemini 3 Flash Preview
Q1 : Pourquoi la réponse est-elle toujours lente malgré la limite max_tokens ?
Le paramètre max_tokens limite uniquement la longueur de la sortie, il n'influence pas le processus de réflexion du modèle. Si la lenteur de la réponse est principalement due au temps de réflexion, vous devez également régler le paramètre thinking_level sur minimal ou low. De plus, passer par la plateforme APIYI (apiyi.com) permet d'accéder à un service API stable qui, couplé aux techniques de configuration des paramètres de cet article, améliore efficacement la vitesse de réponse.
Q2 : Est-ce que régler le thinking_level sur « minimal » affecte la qualité des réponses ?
Il y aura un certain impact, mais il reste minime pour les tâches simples. Le niveau minimal est idéal pour les questions-réponses rapides ou les conversations simples. Si la tâche implique un raisonnement logique complexe, il est recommandé d'utiliser les niveaux low ou medium. Nous vous suggérons d'effectuer des tests A/B via la plateforme APIYI (apiyi.com) pour comparer la qualité de sortie selon les différents thinking_level et trouver l'équilibre idéal pour vos besoins.
Q3 : Qu’est-ce qui est le plus rapide : le mode « streaming » ou le mode classique ?
Le temps total de génération est identique, mais l'expérience utilisateur est bien meilleure avec le mode streaming (flux). En mode streaming, l'utilisateur voit les résultats s'afficher immédiatement, tandis que le mode classique nécessite d'attendre la fin complète de la génération. Pour les tâches dont le temps de génération est long, nous recommandons vivement d'utiliser la sortie en streaming.
Q4 : Comment déterminer la durée idéale du timeout ?
Le timeout doit être configuré en fonction de la longueur de sortie attendue et du thinking_level choisi :
- minimal + 1000 tokens : 15-30 secondes
- low + 2000 tokens : 30-60 secondes
- medium + 4000 tokens : 60-90 secondes
- high + 8000 tokens : 120-180 secondes
L'astuce est de tester d'abord avec un timeout assez long pour mesurer le temps de réponse réel, puis d'ajuster en conséquence.
Q5 : Est-ce que l’ancien paramètre thinking_budget fonctionne toujours ?
Oui, vous pouvez continuer à l'utiliser, mais Google recommande de migrer vers le paramètre thinking_level pour obtenir des performances plus prévisibles. Attention à ne pas utiliser les deux paramètres dans la même requête. Si vous utilisiez auparavant thinking_budget=0, vous devriez régler thinking_level="minimal" lors de votre migration.
Résumé
L'optimisation de la vitesse de réponse du Gemini 3 Flash Preview repose principalement sur la configuration de trois paramètres clés :
- thinking_level : choisir la profondeur de réflexion appropriée en fonction de la complexité de la tâche.
- max_tokens : limiter le nombre de tokens selon la longueur de sortie attendue.
- timeout : définir un délai d'expiration raisonnable en fonction du
thinking_levelet du volume de sortie.
Pour les scénarios où « la vitesse de réponse est prioritaire sur la précision », voici la configuration recommandée :
- thinking_level :
minimaloulow - max_tokens : à définir selon vos besoins réels pour éviter des sorties trop longues.
- timeout : à ajuster en conséquence pour éviter que la réponse ne soit tronquée.
- stream :
True(pour améliorer l'expérience utilisateur).
Nous vous recommandons d'utiliser APIYI (apiyi.com) pour tester rapidement différentes combinaisons de paramètres et trouver la configuration idéale pour votre cas d'usage.
Mots-clés : Gemini 3 Flash Preview, optimisation de la vitesse de réponse, configuration thinking_level, max_tokens, timeout, optimisation d'appels API
Références :
- Documentation officielle Google AI : ai.google.dev/gemini-api/docs/gemini-3
- Google DeepMind : deepmind.google/models/gemini/flash/
- Tests de performance Artificial Analysis : artificialanalysis.ai/articles/gemini-3-flash-everything-you-need-to-know
Cet article a été rédigé par l'équipe technique d'APIYI. Pour plus d'astuces sur l'utilisation des grands modèles de langage, rendez-vous sur help.apiyi.com