
調用 Gemini 3 Flash Preview 模型時響應時間過長是開發者常遇到的挑戰。本文將介紹 timeout、max_tokens、thinking_level 等關鍵參數配置技巧,幫助你快速掌握 Gemini 3 Flash Preview 響應速度優化的實用方法。
核心價值: 讀完本文,你將學會通過合理配置參數來控制 Gemini 3 Flash Preview 的響應時間,在保證輸出質量的同時實現響應速度顯著提升。

Gemini 3 Flash Preview 響應時間長的原因分析
在深入瞭解優化技巧之前,我們需要先理解爲什麼 Gemini 3 Flash Preview 有時候響應時間會比較長。
思考 Token (Thinking Tokens) 機制
Gemini 3 Flash Preview 採用了動態思考機制,這是導致響應時間變長的核心原因:
| 影響因素 | 說明 | 對響應時間的影響 |
|---|---|---|
| 複雜推理任務 | 涉及邏輯推理的問題需要更多思考 Token | 顯著增加響應時間 |
| 動態思考深度 | 模型會根據問題複雜度自動調整思考量 | 簡單問題快,複雜問題慢 |
| 非流式輸出 | 非流式模式下需等待全部生成完成 | 整體等待時間更長 |
| 輸出 Token 數量 | 補全內容越多,生成時間越長 | 線性增加響應時間 |
根據 Artificial Analysis 的測試數據,Gemini 3 Flash Preview 在最高思考級別時使用的 Token 量可達約 1.6 億,是 Gemini 2.5 Flash 的兩倍以上。這意味着在複雜任務上,模型會消耗大量的"思考時間"。
實際案例分析
從用戶反饋來看,當任務對返回時間有速度要求但對準確度要求不高時,Gemini 3 Flash Preview 的默認配置可能並不理想:
"因爲任務對返回時間有速度要求,對準確度要求不高,但 gemini-3-flash-preview 推理很長"
這種情況的根本原因是:
- 模型默認使用動態思考,會自動進行深度推理
- 補全的 Token 數量可能達到 7000+
- 還需要額外考慮推理過程消耗的思考 Token
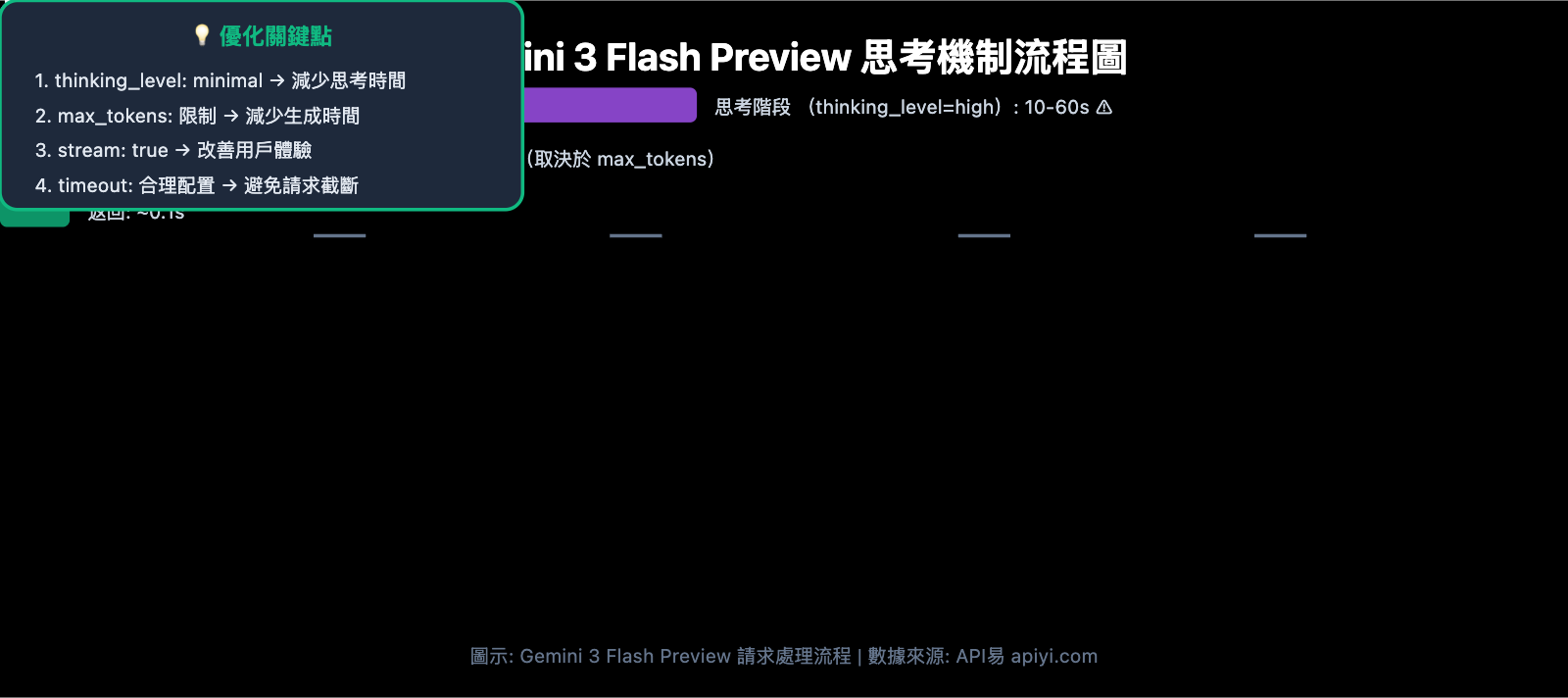
Gemini 3 Flash Preview 響應速度優化核心要點
| 優化要點 | 說明 | 預期效果 |
|---|---|---|
| 設置 thinking_level | 控制模型思考深度 | 降低 30-70% 響應時間 |
| 限制 max_tokens | 控制輸出長度 | 減少生成時間 |
| 調整 timeout | 設置合理超時時間 | 避免請求被截斷 |
| 使用流式輸出 | 邊生成邊返回 | 改善用戶體驗 |
| 選擇合適場景 | 簡單任務用低思考級別 | 整體效率提升 |
thinking_level 參數詳解
Gemini 3 引入了 thinking_level 參數,這是控制響應速度的最關鍵配置:
| thinking_level | 適用場景 | 響應速度 | 推理質量 |
|---|---|---|---|
| minimal | 簡單對話、快速響應 | 最快 ⚡ | 基礎 |
| low | 日常任務、輕度推理 | 快 | 良好 |
| medium | 中等複雜度任務 | 中等 | 較好 |
| high | 複雜推理、深度分析 | 慢 | 最佳 |
🎯 技術建議: 如果你的任務對準確度要求不高但需要快速響應,建議將 thinking_level 設置爲
minimal或low。我們建議通過 API易 apiyi.com 平臺進行不同 thinking_level 的對比測試,快速找到最適合你業務場景的配置。
max_tokens 參數配置策略
限制 max_tokens 可以有效控制輸出長度,從而減少響應時間:
輸出 Token 數量 → 直接影響生成時間
Token 數量越多 → 響應時間越長
配置建議:
- 簡單回答場景: 設置 max_tokens 爲 500-1000
- 中等內容生成: 設置 max_tokens 爲 2000-4000
- 完整內容輸出: 根據實際需求設置,但注意超時風險
⚠️ 注意: max_tokens 設置過短會導致輸出被截斷,影響回答完整性。需要根據實際業務需求平衡速度和完整性。
Gemini 3 Flash Preview 響應速度優化快速上手
極簡示例
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # 使用 API易 統一接口
)
# 速度優先配置
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": "簡單介紹一下人工智能"}],
max_tokens=1000, # 限制輸出長度
extra_body={
"thinking_level": "minimal" # 最小思考深度,最快響應
},
timeout=30 # 設置 30 秒超時
)
print(response.choices[0].message.content)
查看完整代碼 – 包含多種配置場景
import openai
from typing import Literal
def create_gemini_client(api_key: str):
"""創建 Gemini 3 Flash 客戶端"""
return openai.OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # 使用 API易 統一接口
)
def call_gemini_optimized(
client: openai.OpenAI,
prompt: str,
thinking_level: Literal["minimal", "low", "medium", "high"] = "low",
max_tokens: int = 2000,
timeout: int = 60,
stream: bool = False
):
"""
優化配置的 Gemini 3 Flash 調用
參數:
client: OpenAI 客戶端
prompt: 用戶輸入
thinking_level: 思考深度 (minimal/low/medium/high)
max_tokens: 最大輸出 Token 數
timeout: 超時時間(秒)
stream: 是否使用流式輸出
"""
params = {
"model": "gemini-3-flash-preview",
"messages": [{"role": "user", "content": prompt}],
"max_tokens": max_tokens,
"stream": stream,
"extra_body": {
"thinking_level": thinking_level
},
"timeout": timeout
}
if stream:
# 流式輸出 - 改善用戶體驗
response = client.chat.completions.create(**params)
full_content = ""
for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
print(content, end="", flush=True)
full_content += content
print() # 換行
return full_content
else:
# 非流式輸出 - 一次性返回
response = client.chat.completions.create(**params)
return response.choices[0].message.content
# 使用示例
if __name__ == "__main__":
client = create_gemini_client("YOUR_API_KEY")
# 場景 1: 速度優先 - 簡單問答
print("=== 速度優先配置 ===")
result = call_gemini_optimized(
client,
prompt="用一句話解釋什麼是機器學習",
thinking_level="minimal",
max_tokens=500,
timeout=15
)
print(f"回答: {result}\n")
# 場景 2: 平衡配置 - 日常任務
print("=== 平衡配置 ===")
result = call_gemini_optimized(
client,
prompt="列出 5 個 Python 數據處理的最佳實踐",
thinking_level="low",
max_tokens=1500,
timeout=30
)
print(f"回答: {result}\n")
# 場景 3: 質量優先 - 複雜分析
print("=== 質量優先配置 ===")
result = call_gemini_optimized(
client,
prompt="分析 Transformer 架構的核心創新點及其對 NLP 的影響",
thinking_level="high",
max_tokens=4000,
timeout=120
)
print(f"回答: {result}\n")
# 場景 4: 流式輸出 - 改善體驗
print("=== 流式輸出 ===")
result = call_gemini_optimized(
client,
prompt="介紹 Gemini 3 Flash 的主要特點",
thinking_level="low",
max_tokens=2000,
timeout=60,
stream=True
)
🚀 快速開始: 推薦使用 API易 apiyi.com 平臺快速測試不同參數配置。該平臺提供開箱即用的 API 接口,支持 Gemini 3 Flash Preview 等主流模型,便於快速驗證優化效果。
Gemini 3 Flash Preview 響應速度優化參數配置詳解
timeout 超時時間配置
當使用 Gemini 3 Flash Preview 進行復雜推理時,默認的超時時間可能不夠用。以下是推薦的 timeout 配置策略:
| 任務類型 | 推薦 timeout | 說明 |
|---|---|---|
| 簡單問答 | 15-30 秒 | 配合 minimal thinking_level |
| 日常任務 | 30-60 秒 | 配合 low/medium thinking_level |
| 複雜分析 | 60-120 秒 | 配合 high thinking_level |
| 長文本生成 | 120-180 秒 | 大量輸出 Token 場景 |
關鍵提示:
- 非流式輸出模式下,需要等待全部內容生成完成才返回
- 如果 timeout 設置過短,請求可能被截斷
- 建議根據實際輸出 Token 量和 thinking_level 動態調整
thinking_level 與舊版 thinking_budget 的遷移
Google 推薦從舊版 thinking_budget 參數遷移到新版 thinking_level:
| 舊版 thinking_budget | 新版 thinking_level | 遷移說明 |
|---|---|---|
| 0 | minimal | 最小思考,注意仍需處理思考簽名 |
| 1-1000 | low | 輕度思考 |
| 1001-5000 | medium | 中度思考 |
| 5001+ | high | 深度思考 |
⚠️ 注意: 不要在同一請求中同時使用 thinking_budget 和 thinking_level,這會導致不可預期的行爲。

Gemini 3 Flash Preview 響應速度優化場景化配置方案
場景 1: 高頻簡單任務 (速度優先)
適用於聊天機器人、快速問答、內容摘要等對延遲敏感的場景:
# 速度優先配置
config_speed_first = {
"thinking_level": "minimal",
"max_tokens": 500,
"timeout": 15,
"stream": True # 流式輸出改善體驗
}
預期效果:
- 響應時間: 1-5 秒
- 適合簡單對話和快速回復
場景 2: 日常業務任務 (平衡配置)
適用於內容生成、代碼輔助、文檔處理等常規任務:
# 平衡配置
config_balanced = {
"thinking_level": "low",
"max_tokens": 2000,
"timeout": 45,
"stream": True
}
預期效果:
- 響應時間: 5-20 秒
- 質量和速度的良好平衡
場景 3: 複雜分析任務 (質量優先)
適用於數據分析、技術方案設計、深度研究等需要深度推理的場景:
# 質量優先配置
config_quality_first = {
"thinking_level": "high",
"max_tokens": 8000,
"timeout": 180,
"stream": True # 長任務建議用流式
}
預期效果:
- 響應時間: 30-120 秒
- 最佳推理質量
配置選擇決策表
| 你的需求 | 推薦 thinking_level | 推薦 max_tokens | 推薦 timeout |
|---|---|---|---|
| 快速回復,簡單問題 | minimal | 500-1000 | 15-30s |
| 日常任務,一般質量 | low | 1500-2500 | 30-60s |
| 較好質量,可等待 | medium | 2500-4000 | 60-90s |
| 最佳質量,複雜任務 | high | 4000-8000 | 120-180s |
💡 選擇建議: 選擇哪種配置主要取決於您的具體應用場景和質量要求。我們建議通過 API易 apiyi.com 平臺進行實際測試,以便做出最適合您需求的選擇。該平臺支持 Gemini 3 Flash Preview 的統一接口調用,便於快速對比不同配置的效果。
Gemini 3 Flash Preview 響應速度優化進階技巧
技巧 1: 使用流式輸出改善用戶體驗
即使總響應時間不變,流式輸出也能顯著改善用戶感知體驗:
# 流式輸出示例
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": prompt}],
stream=True,
extra_body={"thinking_level": "low"}
)
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
優勢:
- 用戶可以立即看到部分結果
- 減少"等待焦慮"
- 可以在生成過程中決定是否繼續
技巧 2: 根據輸入複雜度動態調整參數
def estimate_complexity(prompt: str) -> str:
"""根據 prompt 特徵估算任務複雜度"""
indicators = {
"high": ["分析", "對比", "爲什麼", "原理", "深入", "詳細解釋"],
"medium": ["如何", "步驟", "方法", "介紹"],
"low": ["是什麼", "簡單", "快速", "一句話"]
}
prompt_lower = prompt.lower()
for level, keywords in indicators.items():
if any(kw in prompt_lower for kw in keywords):
return level
return "low" # 默認低複雜度
def get_optimized_config(prompt: str) -> dict:
"""根據 prompt 獲取優化配置"""
complexity = estimate_complexity(prompt)
configs = {
"low": {"thinking_level": "minimal", "max_tokens": 1000, "timeout": 20},
"medium": {"thinking_level": "low", "max_tokens": 2500, "timeout": 45},
"high": {"thinking_level": "medium", "max_tokens": 4000, "timeout": 90}
}
return configs.get(complexity, configs["low"])
技巧 3: 實現請求重試機制
對於偶發的超時問題,可以實現智能重試:
import time
from typing import Optional
def call_with_retry(
client,
prompt: str,
max_retries: int = 3,
initial_timeout: int = 30
) -> Optional[str]:
"""帶重試機制的調用"""
for attempt in range(max_retries):
try:
timeout = initial_timeout * (attempt + 1) # 遞增超時
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": prompt}],
max_tokens=2000,
timeout=timeout,
extra_body={"thinking_level": "low"}
)
return response.choices[0].message.content
except Exception as e:
print(f"嘗試 {attempt + 1} 失敗: {e}")
if attempt < max_retries - 1:
time.sleep(2 ** attempt) # 指數退避
continue
return None
Gemini 3 Flash Preview 性能數據參考
根據 Artificial Analysis 的測試數據,Gemini 3 Flash Preview 的性能表現如下:
| 性能指標 | 數值 | 說明 |
|---|---|---|
| 原始吞吐量 | 218 tokens/秒 | 輸出速度 |
| 對比 2.5 Flash | 慢 22% | 因爲增加了推理能力 |
| 對比 GPT-5.1 high | 快 74% | 125 tokens/秒 |
| 對比 DeepSeek V3.2 | 快 627% | 30 tokens/秒 |
| 輸入價格 | $0.50/1M tokens | |
| 輸出價格 | $3.00/1M tokens |
性能與成本平衡
| 配置方案 | 響應速度 | Token 消耗 | 成本效益 |
|---|---|---|---|
| minimal thinking | 最快 | 最低 | 最高 |
| low thinking | 快 | 較低 | 高 |
| medium thinking | 中等 | 中等 | 中等 |
| high thinking | 慢 | 較高 | 追求質量時選擇 |
💰 成本優化: 對於預算敏感的項目,可以考慮通過 API易 apiyi.com 平臺調用 Gemini 3 Flash Preview API。該平臺提供靈活的計費方式,結合本文的速度優化技巧,可以在控制成本的同時獲得最佳性價比。
Gemini 3 Flash Preview 響應速度優化常見問題
Q1: 爲什麼設置了 max_tokens 限制,響應還是很慢?
max_tokens 只限制輸出長度,不影響模型的思考過程。如果響應慢主要是因爲思考時間長,需要同時設置 thinking_level 參數爲 minimal 或 low。另外,通過 API易 apiyi.com 平臺可以獲取穩定的 API 服務,配合本文的參數配置技巧能有效改善響應速度。
Q2: thinking_level 設置爲 minimal 會影響回答質量嗎?
會有一定影響,但對於簡單任務影響不大。minimal 級別適合快速問答、簡單對話等場景。如果任務涉及複雜邏輯推理,建議使用 low 或 medium 級別。建議通過 API易 apiyi.com 平臺進行 A/B 測試,對比不同 thinking_level 下的輸出質量,找到最適合你業務的平衡點。
Q3: 流式輸出和非流式輸出哪個更快?
總生成時間相同,但流式輸出的用戶體驗更好。流式模式下,用戶可以立即看到部分結果,而非流式模式需要等待全部生成完成。對於生成時間較長的任務,強烈推薦使用流式輸出。
Q4: 如何判斷 timeout 應該設置多長?
timeout 應根據預期的輸出長度和 thinking_level 來設置:
- minimal + 1000 tokens: 15-30 秒
- low + 2000 tokens: 30-60 秒
- medium + 4000 tokens: 60-90 秒
- high + 8000 tokens: 120-180 秒
建議先用較長的 timeout 測試實際響應時間,再據此調整。
Q5: 舊版 thinking_budget 參數還能用嗎?
可以繼續使用,但 Google 推薦遷移到 thinking_level 參數以獲得更可預測的性能。注意不要在同一請求中同時使用兩個參數。如果之前使用 thinking_budget=0,遷移時應設置 thinking_level="minimal"。
總結
Gemini 3 Flash Preview 響應速度優化的核心在於合理配置三個關鍵參數:
- thinking_level: 根據任務複雜度選擇合適的思考深度
- max_tokens: 根據預期輸出長度限制 Token 數量
- timeout: 根據 thinking_level 和輸出量設置合理超時
對於"任務對返回時間有速度要求,對準確度要求不高"的場景,推薦配置:
- thinking_level:
minimal或low - max_tokens: 根據實際需求設置,避免過長
- timeout: 相應調整,避免被截斷
- stream:
True(改善用戶體驗)
推薦通過 API易 apiyi.com 快速測試不同參數組合,找到最適合你業務場景的配置方案。
關鍵詞: Gemini 3 Flash Preview, 響應速度優化, thinking_level, max_tokens, timeout 配置, API 調用優化
參考資料:
- Google AI 官方文檔: ai.google.dev/gemini-api/docs/gemini-3
- Google DeepMind: deepmind.google/models/gemini/flash/
- Artificial Analysis 性能測試: artificialanalysis.ai/articles/gemini-3-flash-everything-you-need-to-know
本文由 APIYI Team 技術團隊撰寫,更多 AI 模型使用技巧請訪問 help.apiyi.com