
Длительное время отклика при вызове модели Gemini 3 Flash Preview — это вызов, с которым часто сталкиваются разработчики. В этой статье мы разберем приемы настройки ключевых параметров, таких как timeout, max_tokens и thinking_level, которые помогут вам быстро оптимизировать скорость работы Gemini 3 Flash Preview.
Основная ценность: Прочитав этот материал, вы научитесь управлять временем отклика Gemini 3 Flash Preview через грамотную конфигурацию параметров, добиваясь значительного ускорения без потери качества ответов.

Почему Gemini 3 Flash Preview может отвечать долго?
Прежде чем переходить к советам по оптимизации, давайте разберемся, почему Gemini 3 Flash Preview иногда заставляет нас ждать.
Механизм токенов размышления (Thinking Tokens)
В Gemini 3 Flash Preview реализован механизм динамического размышления — это и есть главная причина задержек:
| Фактор влияния | Описание | Влияние на время отклика |
|---|---|---|
| Сложные логические задачи | Задачи, требующие рассуждений, потребляют больше токенов размышления | Значительно увеличивает время |
| Динамическая глубина | Модель автоматически регулирует объем размышлений в зависимости от сложности | Простые задачи — быстро, сложные — медленно |
| Непотоковый вывод | В обычном режиме нужно ждать завершения всей генерации | Субъективно долгое ожидание |
| Количество выходных токенов | Чем длиннее ответ, тем больше времени требуется на генерацию | Линейный рост времени |
Согласно данным тестов Artificial Analysis, при максимальном уровне размышления Gemini 3 Flash Preview может использовать до 160 миллионов токенов — это в два раза больше, чем у Gemini 2.5 Flash. Это означает, что на сложных задачах модель тратит огромное количество времени именно на «обдумывание».
Анализ реального кейса
Судя по отзывам пользователей, когда важна скорость, а идеальная точность второстепенна, стандартные настройки Gemini 3 Flash Preview могут оказаться неэффективными:
«Моя задача требует быстрого ответа, точность не так критична, но gemini-3-flash-preview рассуждает слишком долго».
Причины такой ситуации кроются в следующем:
- По умолчанию включено динамическое размышление, и модель сама решает «копать глубоко».
- Объем достраиваемого текста (completion tokens) может превышать 7000+.
- Добавьте к этому время на генерацию самих токенов размышления.
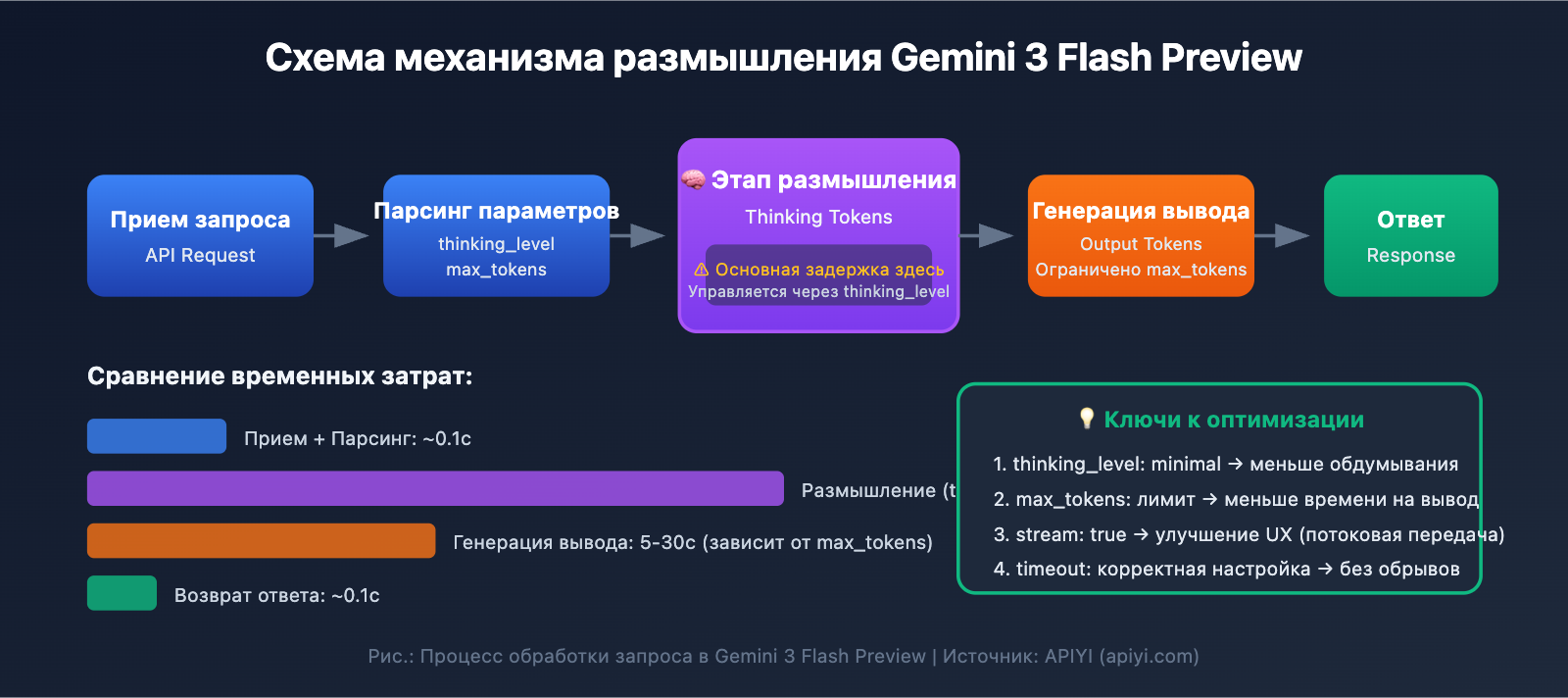
Основные моменты по оптимизации скорости ответа Gemini 3 Flash Preview
| Что оптимизируем | Описание | Ожидаемый эффект |
|---|---|---|
| Настройка thinking_level | Управление глубиной размышления модели | Сокращение времени ответа на 30–70% |
| Ограничение max_tokens | Контроль длины вывода | Уменьшение времени генерации |
| Настройка timeout | Установка разумного времени ожидания | Предотвращение обрыва запросов |
| Потоковая передача (streaming) | Возврат ответа по мере генерации | Улучшение пользовательского опыта |
| Выбор сценария | Использование низкого уровня мышления для простых задач | Повышение общей эффективности |
Подробно о параметре thinking_level
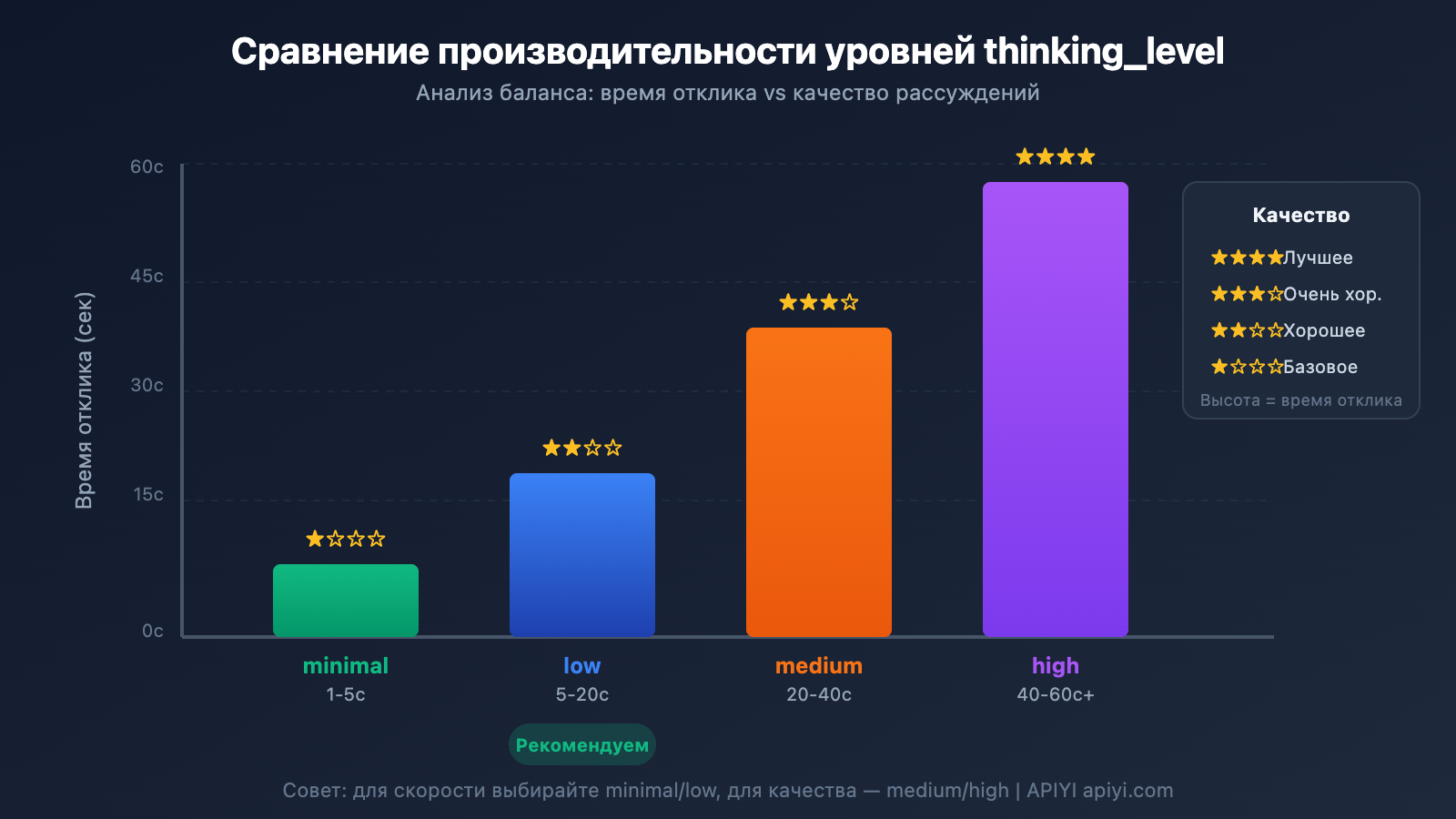
В Gemini 3 появился параметр thinking_level — это самый важный рычаг для управления скоростью ответа:
| thinking_level | Сценарии использования | Скорость ответа | Качество рассуждений |
|---|---|---|---|
| minimal | Простые диалоги, мгновенные ответы | Самая высокая ⚡ | Базовое |
| low | Повседневные задачи, легкие рассуждения | Высокая | Хорошее |
| medium | Задачи средней сложности | Средняя | Улучшенное |
| high | Сложные рассуждения, глубокий анализ | Низкая | Лучшее |
🎯 Технический совет: Если для вашей задачи точность не критична, но важна скорость, попробуйте выставить
thinking_levelнаminimalилиlow. Рекомендуем провести сравнительные тесты с разными уровнямиthinking_levelна платформе APIYI (apiyi.com), чтобы быстро найти идеальный конфиг под ваш бизнес-кейс.
Стратегия настройки параметра max_tokens
Ограничение max_tokens эффективно контролирует длину вывода, что напрямую сокращает время ожидания:
Количество выходных токенов → Напрямую влияет на время генерации
Больше токенов → Дольше ответ
Рекомендации по настройке:
- Для простых ответов: установите
max_tokensв пределах 500–1000. - Для генерации контента среднего объема: 2000–4000.
- Для объемных текстов: настраивайте по необходимости, но помните о рисках таймаута.
⚠️ Внимание: Если установить слишком низкое значение max_tokens, ответ может оборваться на полуслове. Нужно искать баланс между скоростью и полнотой ответа в зависимости от ваших задач.
Быстрый старт: оптимизация скорости Gemini 3 Flash Preview
Минималистичный пример
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Используем единый интерфейс APIYI
)
# Конфигурация с приоритетом скорости
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": "Коротко расскажи об искусственном интеллекте"}],
max_tokens=1000, # Ограничиваем длину вывода
extra_body={
"thinking_level": "minimal" # Минимальная глубина размышления, самый быстрый ответ
},
timeout=30 # Тайм-аут 30 секунд
)
print(response.choices[0].message.content)
Посмотреть полный код (разные сценарии настройки)
import openai
from typing import Literal
def create_gemini_client(api_key: str):
"""Создание клиента Gemini 3 Flash"""
return openai.OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # Используем единый интерфейс APIYI
)
def call_gemini_optimized(
client: openai.OpenAI,
prompt: str,
thinking_level: Literal["minimal", "low", "medium", "high"] = "low",
max_tokens: int = 2000,
timeout: int = 60,
stream: bool = False
):
"""
Вызов Gemini 3 Flash с оптимизированными настройками
Параметры:
client: Клиент OpenAI
prompt: Ввод пользователя
thinking_level: Глубина размышления (minimal/low/medium/high)
max_tokens: Максимальное количество токенов в ответе
timeout: Время ожидания (сек)
stream: Использовать ли потоковую передачу
"""
params = {
"model": "gemini-3-flash-preview",
"messages": [{"role": "user", "content": prompt}],
"max_tokens": max_tokens,
"stream": stream,
"extra_body": {
"thinking_level": thinking_level
},
"timeout": timeout
}
if stream:
# Потоковый вывод - для лучшего UX
response = client.chat.completions.create(**params)
full_content = ""
for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
print(content, end="", flush=True)
full_content += content
print() # Перенос строки
return full_content
else:
# Обычный вывод - возврат всего ответа целиком
response = client.chat.completions.create(**params)
return response.choices[0].message.content
# Примеры использования
if __name__ == "__main__":
client = create_gemini_client("YOUR_API_KEY")
# Сценарий 1: Приоритет скорости - простой вопрос
print("=== Конфигурация: Скорость в приоритете ===")
result = call_gemini_optimized(
client,
prompt="Объясни одним предложением, что такое машинное обучение",
thinking_level="minimal",
max_tokens=500,
timeout=15
)
print(f"Ответ: {result}\n")
# Сценарий 2: Сбалансированный режим - повседневные задачи
print("=== Конфигурация: Баланс ===")
result = call_gemini_optimized(
client,
prompt="Напиши 5 лучших практик обработки данных на Python",
thinking_level="low",
max_tokens=1500,
timeout=30
)
print(f"Ответ: {result}\n")
# Сценарий 3: Приоритет качества - сложный анализ
print("=== Конфигурация: Качество в приоритете ===")
result = call_gemini_optimized(
client,
prompt="Проанализируй ключевые инновации архитектуры Transformer и их влияние на NLP",
thinking_level="high",
max_tokens=4000,
timeout=120
)
print(f"Ответ: {result}\n")
# Сценарий 4: Потоковый вывод - для удобства пользователя
print("=== Потоковый вывод ===")
result = call_gemini_optimized(
client,
prompt="Расскажи об основных особенностях Gemini 3 Flash",
thinking_level="low",
max_tokens=2000,
timeout=60,
stream=True
)
🚀 Как начать: Рекомендуем использовать платформу APIYI (apiyi.com) для быстрого тестирования различных конфигураций. Сервис предоставляет готовый API с поддержкой топовых моделей, включая Gemini 3 Flash Preview, что позволяет мгновенно проверить эффект от оптимизации.
Подробное руководство по настройке параметров оптимизации скорости отклика Gemini 3 Flash Preview
Настройка таймаута (timeout)
При использовании Gemini 3 Flash Preview для сложных рассуждений стандартного времени ожидания может не хватить. Вот рекомендуемые стратегии настройки timeout:
| Тип задачи | Рекомендуемый таймаут | Описание |
|---|---|---|
| Простые ответы | 15–30 сек | В связке с minimal thinking_level |
| Повседневные задачи | 30–60 сек | В связке с low/medium thinking_level |
| Сложный анализ | 60–120 сек | В связке с high thinking_level |
| Генерация длинных текстов | 120–180 сек | Сценарии с большим количеством выходных токенов |
Важные нюансы:
- В режиме без потоковой передачи (non-streaming) нужно дождаться полной генерации контента, прежде чем придет ответ.
- Если установить слишком короткий
timeout, запрос может быть прерван на полуслове. - Рекомендуется подстраивать таймаут динамически, исходя из ожидаемого количества токенов и уровня
thinking_level.
Миграция с thinking_budget на новый параметр thinking_level
Google рекомендует переходить с устаревшего параметра thinking_budget на новый thinking_level:
| Старый thinking_budget | Новый thinking_level | Примечания по миграции |
|---|---|---|
| 0 | minimal | Минимальное размышление; учтите, что подпись размышления всё равно нужно обрабатывать |
| 1–1000 | low | Легкое размышление |
| 1001–5000 | medium | Среднее размышление |
| 5001+ | high | Глубокое размышление |
⚠️ Внимание: не используйте thinking_budget и thinking_level в одном и том же запросе — это может привести к непредсказуемому поведению модели.
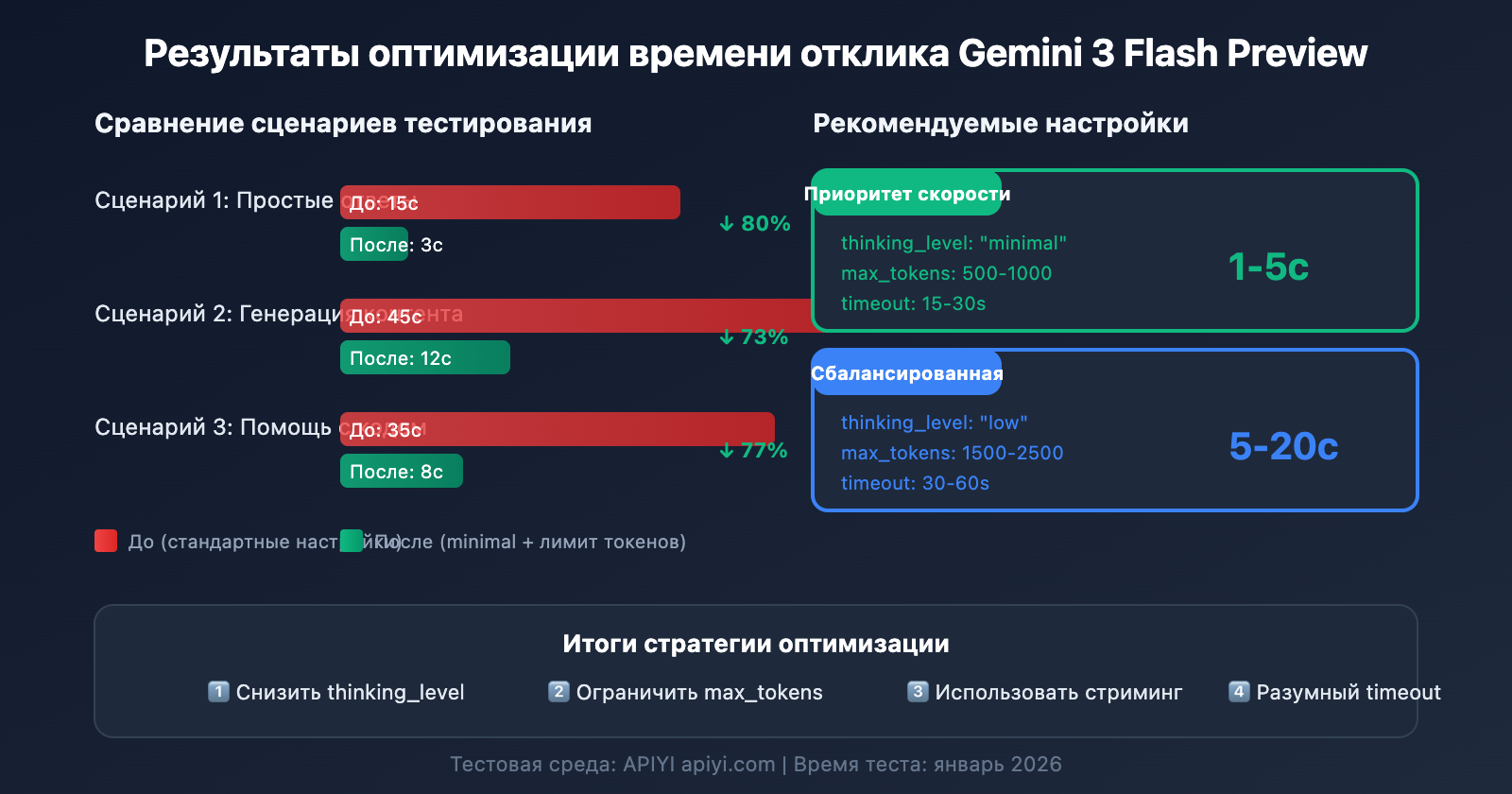
Сценарий 1: Высокочастотные простые задачи (приоритет скорости)
Подходит для чат-ботов, быстрых ответов на вопросы, суммаризации контента и других сценариев, чувствительных к задержке:
# Конфигурация с приоритетом скорости
config_speed_first = {
"thinking_level": "minimal",
"max_tokens": 500,
"timeout": 15,
"stream": True # Стриминг улучшает пользовательский опыт
}
Ожидаемый результат:
- Время отклика: 1–5 секунд
- Подходит для простых диалогов и быстрых ответов
Сценарий 2: Повседневные рабочие задачи (сбалансированная конфигурация)
Подходит для генерации контента, помощи в написании кода, обработки документов и других типичных задач:
# Сбалансированная конфигурация
config_balanced = {
"thinking_level": "low",
"max_tokens": 2000,
"timeout": 45,
"stream": True
}
Ожидаемый результат:
- Время отклика: 5–20 секунд
- Хороший баланс между качеством и скоростью
Сценарий 3: Сложные аналитические задачи (приоритет качества)
Подходит для анализа данных, проектирования технических решений, глубоких исследований и других задач, требующих серьезных логических рассуждений:
# Конфигурация с приоритетом качества
config_quality_first = {
"thinking_level": "high",
"max_tokens": 8000,
"timeout": 180,
"stream": True # Для длительных задач рекомендуется использовать стриминг
}
Ожидаемый результат:
- Время отклика: 30–120 секунд
- Максимальное качество рассуждений
Таблица для выбора конфигурации
| Ваши потребности | Рекомендуемый thinking_level | Рекомендуемый max_tokens | Рекомендуемый timeout |
|---|---|---|---|
| Быстрые ответы, простые вопросы | minimal | 500-1000 | 15-30s |
| Повседневные задачи, обычное качество | low | 1500-2500 | 30-60s |
| Хорошее качество, можно подождать | medium | 2500-4000 | 60-90s |
| Лучшее качество, сложные задачи | high | 4000-8000 | 120-180s |
💡 Совет по выбору: Выбор конфигурации зависит в первую очередь от вашего конкретного сценария использования и требований к качеству. Мы рекомендуем провести реальное тестирование на платформе APIYI (apiyi.com), чтобы найти оптимальный вариант. Платформа поддерживает единый интерфейс вызова Gemini 3 Flash Preview, что позволяет быстро сравнивать результаты разных настроек.
Продвинутые техники оптимизации времени отклика Gemini 3 Flash Preview
Техника 1: Использование стриминга для улучшения пользовательского опыта
Даже если общее время генерации не изменится, потоковый вывод (стриминг) значительно улучшает восприятие скорости работы пользователем:
# Пример использования стриминга
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": prompt}],
stream=True,
extra_body={"thinking_level": "low"}
)
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
Преимущества:
- Пользователь сразу видит начало ответа.
- Снижается «тревога ожидания».
- Можно прервать генерацию на полпути, если ответ не подходит.
Техника 2: Динамическая настройка параметров в зависимости от сложности ввода
def estimate_complexity(prompt: str) -> str:
"""Оценка сложности задачи на основе характеристик промпта"""
indicators = {
"high": ["анализ", "сравнение", "почему", "принцип", "глубокий", "подробно объясни"],
"medium": ["как", "шаги", "метод", "описание"],
"low": ["что это", "просто", "быстро", "в двух словах"]
}
prompt_lower = prompt.lower()
for level, keywords in indicators.items():
if any(kw in prompt_lower for kw in keywords):
return level
return "low" # По умолчанию низкая сложность
def get_optimized_config(prompt: str) -> dict:
"""Получение оптимизированной конфигурации на основе промпта"""
complexity = estimate_complexity(prompt)
configs = {
"low": {"thinking_level": "minimal", "max_tokens": 1000, "timeout": 20},
"medium": {"thinking_level": "low", "max_tokens": 2500, "timeout": 45},
"high": {"thinking_level": "medium", "max_tokens": 4000, "timeout": 90}
}
return configs.get(complexity, configs["low"])
Техника 3: Реализация механизма повторных запросов (retry)
Для обработки случайных таймаутов можно реализовать умную систему повторов:
import time
from typing import Optional
def call_with_retry(
client,
prompt: str,
max_retries: int = 3,
initial_timeout: int = 30
) -> Optional[str]:
"""Вызов с механизмом повторных попыток"""
for attempt in range(max_retries):
try:
timeout = initial_timeout * (attempt + 1) # Увеличиваем таймаут при каждой попытке
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": prompt}],
max_tokens=2000,
timeout=timeout,
extra_body={"thinking_level": "low"}
)
return response.choices[0].message.content
except Exception as e:
print(f"Попытка {attempt + 1} не удалась: {e}")
if attempt < max_retries - 1:
time.sleep(2 ** attempt) # Экспоненциальная задержка
continue
return None
Справочные данные о производительности Gemini 3 Flash Preview
Согласно результатам тестирования Artificial Analysis, производительность Gemini 3 Flash Preview выглядит следующим образом:
| Показатель производительности | Значение | Описание |
|---|---|---|
| Чистая пропускная способность | 218 токенов/сек | Скорость генерации |
| В сравнении с 2.5 Flash | На 22% медленнее | Из-за добавленных возможностей рассуждения (reasoning) |
| В сравнении с GPT-5.1 high | На 74% быстрее | 125 токенов/сек |
| В сравнении с DeepSeek V3.2 | На 627% быстрее | 30 токенов/сек |
| Цена за вход (Input) | $0.50/1 млн токенов | |
| Цена за выход (Output) | $3.00/1 млн токенов |
Баланс производительности и стоимости
| Вариант конфигурации | Скорость ответа | Потребление токенов | Эффективность затрат |
|---|---|---|---|
| minimal thinking | Самая высокая | Минимальное | Максимальная |
| low thinking | Высокая | Низкое | Высокая |
| medium thinking | Средняя | Среднее | Средняя |
| high thinking | Низкая | Высокое | Выбор для максимального качества |
💰 Оптимизация затрат: Для проектов с ограниченным бюджетом стоит рассмотреть возможность вызова Gemini 3 Flash Preview API через платформу APIYI (apiyi.com). Эта платформа предлагает гибкие тарифы, что в сочетании с приемами оптимизации скорости из этой статьи позволит получить лучшее соотношение цены и качества при полном контроле над расходами.
Часто задаваемые вопросы по оптимизации скорости Gemini 3 Flash Preview
Q1: Почему я установил ограничение max_tokens, но ответ все равно приходит медленно?
Параметр max_tokens ограничивает только длину вывода, но не влияет на процесс «размышления» модели. Если задержка вызвана длительным этапом рассуждений, нужно дополнительно настроить параметр thinking_level, установив его на minimal или low. Кроме того, использование платформы APIYI (apiyi.com) обеспечивает стабильный доступ к API, что вместе с правильной настройкой параметров заметно ускоряет работу.
Q2: Повлияет ли установка thinking_level на minimal на качество ответов?
Определенное влияние будет, но для простых задач оно незначительно. Уровень minimal отлично подходит для быстрых ответов и несложных диалогов. Если же задача требует сложной логики и глубоких рассуждений, лучше выбрать low или medium. Рекомендуем провести A/B тестирование через платформу APIYI (apiyi.com), чтобы сравнить качество вывода на разных уровнях thinking_level и найти идеальный баланс для вашего продукта.
Q3: Что быстрее: потоковый (streaming) или обычный вывод?
Общее время генерации одинаково, но потоковый вывод гораздо лучше с точки зрения пользовательского опыта (UX). В потоковом режиме пользователь сразу видит начало ответа, тогда как в обычном приходится ждать завершения всей генерации. Для задач с длинными ответами мы настоятельно рекомендуем использовать именно потоковую передачу.
Q4: Как понять, какое время ожидания (timeout) нужно установить?
Тайм-аут следует настраивать исходя из ожидаемой длины ответа и уровня thinking_level:
- minimal + 1000 токенов: 15–30 секунд
- low + 2000 токенов: 30–60 секунд
- medium + 4000 токенов: 60–90 секунд
- high + 8000 токенов: 120–180 секунд
Советуем сначала протестировать реальное время ответа с большим запасом по тайм-ауту и затем скорректировать его.
Q5: Можно ли по-прежнему использовать старый параметр thinking_budget?
Его можно использовать, но Google рекомендует переходить на thinking_level для получения более предсказуемых результатов производительности. Важно: не используйте оба параметра в одном запросе одновременно. Если раньше вы использовали thinking_budget=0, то при миграции установите thinking_level="minimal".
Итоги
Ключ к оптимизации скорости отклика Gemini 3 Flash Preview заключается в правильной настройке трех основных параметров:
- thinking_level: выбор подходящей глубины рассуждений в зависимости от сложности задачи.
- max_tokens: ограничение количества токенов в соответствии с ожидаемой длиной ответа.
- timeout: установка разумного таймаута с учетом выбранного уровня
thinking_levelи объема вывода.
Для сценариев, где «скорость ответа критична, а высочайшая точность не является приоритетом», рекомендуем следующую конфигурацию:
- thinking_level:
minimalилиlow - max_tokens: устанавливайте исходя из реальных потребностей, чтобы избежать избыточной генерации.
- timeout: настройте соответствующим образом, чтобы предотвратить обрыв соединения при длительной генерации.
- stream:
True(значительно улучшает восприятие скорости для пользователя).
Рекомендуем использовать APIYI (apiyi.com) для быстрого тестирования различных комбинаций параметров. Это поможет найти конфигурацию, идеально подходящую именно для вашего бизнес-кейса.
Ключевые слова: Gemini 3 Flash Preview, оптимизация скорости отклика, thinking_level, max_tokens, настройка timeout, оптимизация вызовов API
Источники:
- Официальная документация Google AI: ai.google.dev/gemini-api/docs/gemini-3
- Google DeepMind: deepmind.google/models/gemini/flash/
- Тесты производительности от Artificial Analysis: artificialanalysis.ai/articles/gemini-3-flash-everything-you-need-to-know
Статья подготовлена технической командой APIYI Team. Больше советов по работе с AI-моделями — на help.apiyi.com