
Anmerkung des Autors: Eine detaillierte Analyse zur Unterstützung von PDF-Eingaben durch APIs großer Sprachmodelle wie GPT-4o, Claude, Gemini und DeepSeek sowie drei Verarbeitungsansätze: Textextraktion, Bildverständnis und clientseitige Verarbeitung.
„Kann ich ein PDF direkt an die API eines großen Sprachmodells senden?“ Das ist eine der am häufigsten gestellten Fragen von Entwicklern. Die Antwort ist komplexer, als man denkt – einige Modelle unterstützen PDF-Eingaben nativ (Claude, Gemini, GPT-4o), während andere, wie DeepSeek, dies noch nicht tun. Zudem sind die Token-Kosten bei nativer Unterstützung deutlich höher als bei einer Textextraktion.
In diesem Artikel beleuchten wir aus der Perspektive der Softwareentwicklung den aktuellen Stand der PDF-Unterstützung bei gängigen APIs für große Sprachmodelle. Wir stellen 3 Ansätze zur PDF-Verarbeitung mit einem vollständigen Vergleich und Codebeispielen vor, damit Sie die für Ihr Szenario am besten geeignete Methode auswählen können.
Kernnutzen: Nach dem Lesen dieses Artikels wissen Sie genau, wie die PDF-Unterstützung der einzelnen Modelle aussieht, und beherrschen drei Verarbeitungsstrategien – von der kostengünstigsten bis zur komfortabelsten.

Kernpunkte zur PDF-Eingabeunterstützung bei Großsprachmodellen
| Punkt | Beschreibung | Wert |
|---|---|---|
| 3 Anbieter mit nativem PDF-Support | Claude (600 Seiten), Gemini (1000 Seiten), GPT-4o (100 Seiten) unterstützen dies bereits | Keine Vorverarbeitung nötig, direkter API-Upload |
| DeepSeek u. a. noch ohne Support | Erfordern textbasierte Extraktion oder Bildkonvertierung vorab | Aufbau einer Vorverarbeitungspipeline nötig |
| Große Kostenunterschiede | Natives PDF: 258-3000 Token/Seite; reine Textextraktion: nur 300-1500 | Bei großen Mengen kann die richtige Wahl die Kosten um das 10-fache senken |
| 3 Ansätze für verschiedene Szenarien | Textextraktion, Bildverständnis, Client-seitige Verarbeitung | Wahl je nach Bedarf, keine Einheitslösung erforderlich |
Status quo der nativen PDF-Unterstützung durch API-Modelle
Die gute Nachricht: Seit 2025 unterstützen die gängigsten Großsprachmodelle den direkten PDF-Upload via API. Die Implementierung ist weitgehend einheitlich – das PDF wird in Text extrahiert und gleichzeitig wird jede Seite als Bild gerendert, damit das Modell sowohl den Textinhalt als auch visuelle Elemente (Diagramme, Layouts usw.) verstehen kann.
Die schlechte Nachricht: Dieser "Text + Bild"-Verarbeitungsansatz verbraucht deutlich mehr Token als eine reine Texteingabe. Ein 50-seitiger Bericht, der direkt als PDF übertragen wird, kann über 100.000 Token verbrauchen, während eine vorherige Textextraktion nur etwa 30.000 Token erfordern würde.
Detaillierter Vergleich der PDF-Unterstützung nach Modell
| Modell | PDF-Support | Max. Seiten | Max. Datei | Übertragung | Token-Kosten/Seite |
|---|---|---|---|---|---|
| Claude | Unterstützt (GA) | 600 Seiten | 32 MB | Base64 / URL / Files API | 1500-3000 |
| Gemini | Unterstützt | 1000 Seiten | 2 GB (Files API) | Inline / Files API / URL | ~258 (am günstigsten) |
| GPT-4o | Unterstützt | 100 Seiten | 32 MB | Base64 / File Upload | ~765 (Bild) + Text |
| DeepSeek | Nicht unterstützt | — | — | Vorverarbeitung nötig | — |
| Llama / Qwen | Nicht unterstützt | — | — | Vorverarbeitung nötig | — |
🎯 Empfehlung: Wenn Sie große Mengen an PDFs verarbeiten müssen, bietet Gemini die niedrigsten Kosten (ca. 258 Token pro Seite, native Textextraktion ist kostenlos). Wenn Sie Unterstützung für die längsten Dokumente benötigen, ist Gemini ebenfalls führend (1000 Seiten). Claude überzeugt durch eine hohe Genauigkeit beim Verständnis und eignet sich für anspruchsvolle Szenarien. Alle diese Modelle können über die Plattform APIYI (apiyi.com) einheitlich aufgerufen werden.
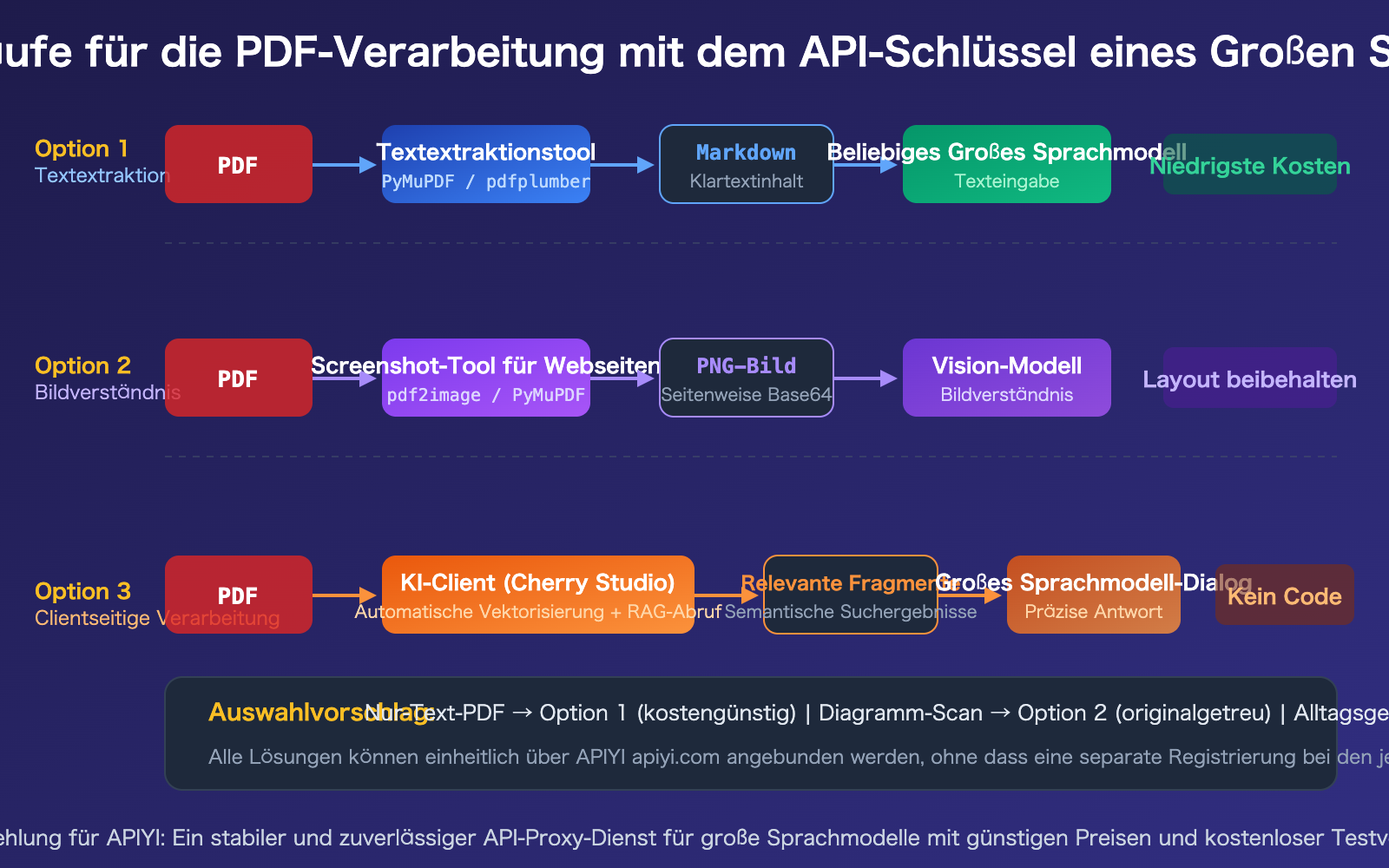
PDF-Verarbeitung mit Großem Sprachmodell-APIs, Ansatz 1: Textbasierte Extraktion
Dies ist die gängigste und kostengünstigste Methode. Zuerst wird das PDF mithilfe einer Python-Bibliothek in Markdown oder reinen Text umgewandelt, anschließend wird dieser Text als Eingabeaufforderung an eine beliebige API für ein Großes Sprachmodell übergeben.
Vergleich der Tools zur textbasierten PDF-Extraktion
| Tool | Geschwindigkeit | Bestes Einsatzgebiet | Besonderheiten |
|---|---|---|---|
| PyMuPDF4LLM | ~0,14s/Dokument | Allgemeiner Text + Tabellenextraktion | Beste Balance zwischen Geschwindigkeit und Qualität, Markdown-Ausgabe |
| pdfplumber | Mittel | Tabellendaten-Extraktion | Koordinatenbasierte Tabellenextraktion, hohe Präzision |
| Marker-PDF | ~11s/Dokument | Treue Konvertierung komplexer Layouts | Beste Strukturerhaltung, jedoch langsamer |
| PyPDF2 | Schnell | Einfache reine Text-PDFs | Leichtgewichtig, geeignet für einfache Textextraktion |
Codebeispiel für die textbasierte PDF-Extraktion
import pymupdf4llm
import openai
# Schritt 1: PDF in Markdown umwandeln
md_text = pymupdf4llm.to_markdown("report.pdf")
# Schritt 2: An die API des Großen Sprachmodells übergeben
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": f"Bitte fasse die Kernpunkte dieses Berichts zusammen:\n\n{md_text}"}]
)
print(response.choices[0].message.content)
Vollständigen Code für die PDF-Verarbeitung mit Bildern anzeigen (Bildverständnis-Ansatz)
import fitz # PyMuPDF
import base64
import openai
def pdf_pages_to_images(pdf_path, dpi=200):
"""Konvertiert jede PDF-Seite in ein Base64-Bild"""
doc = fitz.open(pdf_path)
images = []
for page in doc:
pix = page.get_pixmap(dpi=dpi)
img_bytes = pix.tobytes("png")
b64 = base64.b64encode(img_bytes).decode()
images.append(b64)
return images
# PDF in Bilder umwandeln
images = pdf_pages_to_images("report.pdf")
# Nachricht mit mehreren Bildern erstellen
content = [{"type": "text", "text": "Bitte analysiere die Diagramme und Daten in diesem PDF-Dokument:"}]
for img_b64 in images[:10]: # Achte auf die Seitenzahl, um Token-Limits zu vermeiden
content.append({
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{img_b64}"}
})
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": content}]
)
print(response.choices[0].message.content)
Empfehlung: Die textbasierte Extraktion ist mit allen Großen Sprachmodellen kompatibel (einschließlich DeepSeek, Llama usw., die kein natives PDF unterstützen). Über APIYI (apiyi.com) können Sie mit demselben API-Schlüssel jedes beliebige Modell zu Testzwecken aufrufen.
PDF-Verarbeitung mit Großem Sprachmodell-APIs, Ansatz 2: Native PDF-Eingabe
Wenn Sie Claude, Gemini oder GPT-4o verwenden, können Sie das PDF direkt über die API übergeben, ohne dass eine Vorverarbeitung erforderlich ist.
Beispiel für native PDF-Eingabe mit der Claude API
import anthropic
import base64
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com" # Claude verwendet die Stamm-Domain
)
with open("report.pdf", "rb") as f:
pdf_data = base64.standard_b64encode(f.read()).decode()
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=4096,
messages=[{
"role": "user",
"content": [
{"type": "document", "source": {"type": "base64", "media_type": "application/pdf", "data": pdf_data}},
{"type": "text", "text": "Bitte fasse die Kernpunkte dieses Dokuments zusammen"}
]
}]
)
print(message.content[0].text)
Beispiel für native PDF-Eingabe mit der Gemini API
from google import genai
client = genai.Client(
api_key="YOUR_API_KEY",
http_options={"api_version": "v1beta", "base_url": "https://api.apiyi.com"}
)
with open("report.pdf", "rb") as f:
pdf_bytes = f.read()
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=[
genai.types.Part.from_bytes(data=pdf_bytes, mime_type="application/pdf"),
"Bitte fasse die Kernpunkte dieses Dokuments zusammen"
]
)
print(response.text)
🎯 Kostenhinweis: Die native PDF-Eingabe ist zwar am bequemsten, aber die Token-Kosten sind deutlich höher als bei der reinen Textlösung. Beispiel für ein 50-seitiges PDF: Gemini verbraucht ca. 12.900 Token (am günstigsten), Claude ca. 75.000–150.000 Token und GPT-4o ca. 40.000+ Token. Bei großen Mengen sollten Sie die Kosten unbedingt evaluieren und die Nutzungsstatistik-Funktion von APIYI (apiyi.com) zur Überwachung des Verbrauchs nutzen.
Großes Sprachmodell API PDF-Verarbeitung Teil 3: Client-basierte Verarbeitung
Für den täglichen Gebrauch (außerhalb der Softwareentwicklung) ist die Nutzung eines KI-Clients der einfachste Weg. Am Beispiel von Cherry Studio: Es unterstützt das direkte Hineinziehen von PDF-Anhängen, führt automatisch eine Vektorisierung sowie semantische Suche durch und sendet nur die relevanten Textabschnitte an das Große Sprachmodell.
Vorteile der Client-Lösung
- Kein Programmieren: PDF per Drag-and-Drop einfügen und sofort chatten
- Token-Einsparung: Dank RAG-Suche werden nur relevante Fragmente statt des gesamten Dokuments gesendet
- Modellwechsel: Unterstützt die Konfiguration verschiedener API-Plattformen wie APIYI
- Lokale Wissensdatenbank: Mehrere PDFs können zu einer Wissensdatenbank zusammengefasst und wiederholt abgefragt werden
Wichtige Hinweise zur PDF-Verarbeitung via Client
- Dateigröße kontrollieren: Zu viele PDF-Seiten führen zu langen Vektorisierungszeiten
- Token-Kosten beachten: Obwohl RAG den Inhalt komprimiert, können bei langen Dokumenten dennoch höhere Kosten anfallen
- Passendes Modell wählen: Für einfache Fragen reichen günstige Modelle (z. B. GPT-4o-mini), für komplexe Analysen sollten Flaggschiff-Modelle genutzt werden
Empfehlung: Konfigurieren Sie in Clients wie Cherry Studio APIYI (apiyi.com) als API-Anbieter, um mit einem einzigen Schlüssel auf alle Modelle wie Claude, Gemini oder GPT zuzugreifen.

Häufig gestellte Fragen
F1: Welche Lösung sollte ich für die PDF-Verarbeitung mit DeepSeek verwenden?
Die DeepSeek-API unterstützt derzeit keine direkte PDF-Eingabe. Wir empfehlen Lösung 1 (textbasierte Extraktion): Konvertieren Sie das PDF zunächst mit PyMuPDF4LLM in Markdown-Text und nutzen Sie dann APIYI (apiyi.com), um die DeepSeek-API für die Analyse aufzurufen. Wenn das PDF Diagramme enthält, können Sie die Seiten vorab in Bilder umwandeln und ein Modell mit Vision-Unterstützung (wie GPT-4o) für die Analyse verwenden.
F2: Was funktioniert besser: native PDF-Eingabe oder textbasierte Extraktion?
Das hängt vom Inhalt des PDFs ab. Bei reinen Text-PDFs (Verträge, Berichte) sind die Ergebnisse ähnlich, wobei die textbasierte Extraktion kostengünstiger ist. Bei PDFs mit Diagrammen, komplexen Layouts oder Scans ist die native Eingabe deutlich überlegen, da das Modell Text und visuelle Elemente gleichzeitig erfassen kann. Wir empfehlen, zunächst die textbasierte Lösung zu testen und bei unzureichenden Ergebnissen auf die native Eingabe umzusteigen.
F3: Wie lassen sich die Token-Kosten bei der PDF-Verarbeitung kontrollieren?
Hier sind einige praktische Tipps:
- Bei großen Mengen bevorzugen Sie Gemini (nur 258 Token pro Seite, geringste Kosten).
- Extrahieren Sie nur die benötigten Seiten, anstatt das gesamte Dokument auf einmal zu übertragen.
- Erstellen Sie nach der textbasierten Extraktion eine Zusammenfassung oder teilen Sie den Text in Blöcke auf, um die Übertragung zu langer Texte zu vermeiden.
- Überwachen Sie den tatsächlichen Verbrauch über das Nutzungs-Dashboard von APIYI (apiyi.com).
Zusammenfassung
Die wichtigsten Punkte zur PDF-Unterstützung bei API-Modellen:
- Native Unterstützung bei einigen Modellen: Claude (600 Seiten), Gemini (1000 Seiten) und GPT-4o (100 Seiten) unterstützen den direkten PDF-Upload; DeepSeek und andere derzeit noch nicht.
- Wahl der Lösung je nach Bedarf: Die textbasierte Extraktion ist am kostengünstigsten und mit allen Modellen kompatibel; die native Eingabe ist am bequemsten, aber teurer; die clientseitige Verarbeitung eignet sich für tägliche Dialoge.
- Erhebliche Kostenunterschiede: Bei demselben PDF ist die native Gemini-Eingabe am günstigsten (~258 Token/Seite), während reine Text-Extraktionslösungen die Kosten um weitere 50 % senken können.
Wenn Sie die richtige Lösung für Ihr Szenario wählen, können Sie PDFs effizient verarbeiten, ohne von hohen Token-Kosten überrascht zu werden.
Wir empfehlen die zentrale Anbindung der verschiedenen Modelle über APIYI (apiyi.com). Die Plattform bietet kostenlose Kontingente und unterstützt API-Modellaufrufe für alle gängigen Modelle wie Claude, Gemini, GPT und DeepSeek.
📚 Referenzmaterialien
-
OpenAI PDF-Eingabe-Leitfaden: Offizielle Dokumentation für den direkten PDF-Upload via API
- Link:
platform.openai.com/docs/guides/pdf-files - Beschreibung: Detaillierte Spezifikationen und Einschränkungen für die PDF-Eingabe bei GPT-4o
- Link:
-
Claude PDF-Support-Dokumentation: Offizieller Leitfaden von Anthropic zur PDF-Verarbeitung
- Link:
docs.anthropic.com/en/docs/build-with-claude/pdf-support - Beschreibung: Die 3 Methoden und Best Practices für die PDF-Eingabe bei Claude
- Link:
-
Gemini Dokumentenverarbeitung: Erläuterung der offiziellen Dokumentenverständnis-Fähigkeiten von Google
- Link:
ai.google.dev/gemini-api/docs/document-processing - Beschreibung: Einschränkungen und Preisgestaltung bei der PDF-Verarbeitung mit Gemini
- Link:
-
PyMuPDF4LLM-Dokumentation: Werkzeug zur Textextraktion aus PDFs
- Link:
pymupdf.readthedocs.io/en/latest/pymupdf4llm - Beschreibung: Das schnellste Tool zur Konvertierung von PDFs in Markdown
- Link:
-
APIYI-Plattformdokumentation: Einheitliche Anbindung der APIs großer Sprachmodelle
- Link:
docs.apiyi.com - Beschreibung: Abruf von API-Schlüsseln, Modelllisten und Aufrufbeispiele
- Link:
Autor: Technisches Team von APIYI
Technischer Austausch: Diskutieren Sie gerne in den Kommentaren. Weitere Informationen finden Sie im APIYI-Dokumentationszentrum unter docs.apiyi.com