
Note de l'auteur : Analyse détaillée des causes profondes des problèmes de limitation de débit 429 lors de la génération d'images avec Gemini 3.1 Flash Image Preview. Comparaison des stratégies de limitation d'AI Studio, Vertex AI et des plateformes tierces, avec 4 solutions testées et efficaces.
Lorsqu'on utilise Gemini 3.1 Flash Image Preview pour générer des images, le plus frustrant n'est pas la qualité, mais de se faire bloquer par une erreur 429 dès qu'on commence. Que ce soit avec AI Studio ou Vertex AI, les limites de RPD (Requêtes par jour) et RPM (Requêtes par minute) sont très strictes, rendant la génération en lot quasi impossible.
Cet article, basé sur une expérience pratique, analyse en détail les causes profondes de l'erreur 429, compare les différences de stratégies de limitation entre les plateformes, et propose 4 solutions éprouvées — dont une sans limite de concurrence et au prix de seulement 0,045 $ par image.
Valeur clé : Après avoir lu cet article, vous comprendrez parfaitement la logique sous-jacente de l'erreur 429 dans la génération d'images Gemini et trouverez la solution la mieux adaptée à votre cas d'usage.
Qu'est-ce que l'erreur 429 de Gemini 3.1 Flash Image Preview ?
Voyons d'abord à quoi ressemble cette erreur :
{
"error": {
"code": 429,
"message": "Resource has been exhausted (e.g. check quota).",
"status": "RESOURCE_EXHAUSTED",
"details": [
{
"reason": "RATE_LIMIT_EXCEEDED",
"metadata": {
"quota_limit": "GenerateContentRequestsPerDayPerProjectPerModel",
"quota_limit_value": "1500"
}
}
]
}
}
En langage clair : Vous avez épuisé votre nombre de requêtes pour aujourd'hui, ou vous en faites trop par minute.
Contrairement à l'erreur 503, le 429 n'est pas dû à un serveur surchargé, mais à une limite de quota que Google vous impose activement. Peu importe si le serveur a de la capacité disponible, une fois la limite atteinte, la requête est simplement rejetée.
Différence entre les erreurs 429 et 503 pour la génération d'images Gemini
| Point de comparaison | 429 RESOURCE_EXHAUSTED | 503 UNAVAILABLE |
|---|---|---|
| Cause fondamentale | Vos quotas sont épuisés | Capacité de calcul du serveur insuffisante |
| Condition de déclenchement | Dépassement des limites RPD/RPM/TPM | Charge globale élevée |
| Portée de l'impact | Limité à votre projet | Tous les utilisateurs |
| Résolution par attente | RPM : attendre 1 min, RPD : attendre le lendemain | Généralement quelques minutes à quelques heures |
| Résolution par paiement | Vertex AI permet d'augmenter les quotas | Pas de solution directe |
| Solution fondamentale | Changer de plateforme / Augmenter les quotas | Attendre ou changer de plateforme |
Comparaison des stratégies de limitation de débit pour Gemini 3.1 Flash Image Preview sur différentes plateformes
Voilà le cœur du problème – les différences de limitation de débit entre les plateformes sont énormes.
Paramètres de limitation pour la génération d'images Gemini dans AI Studio
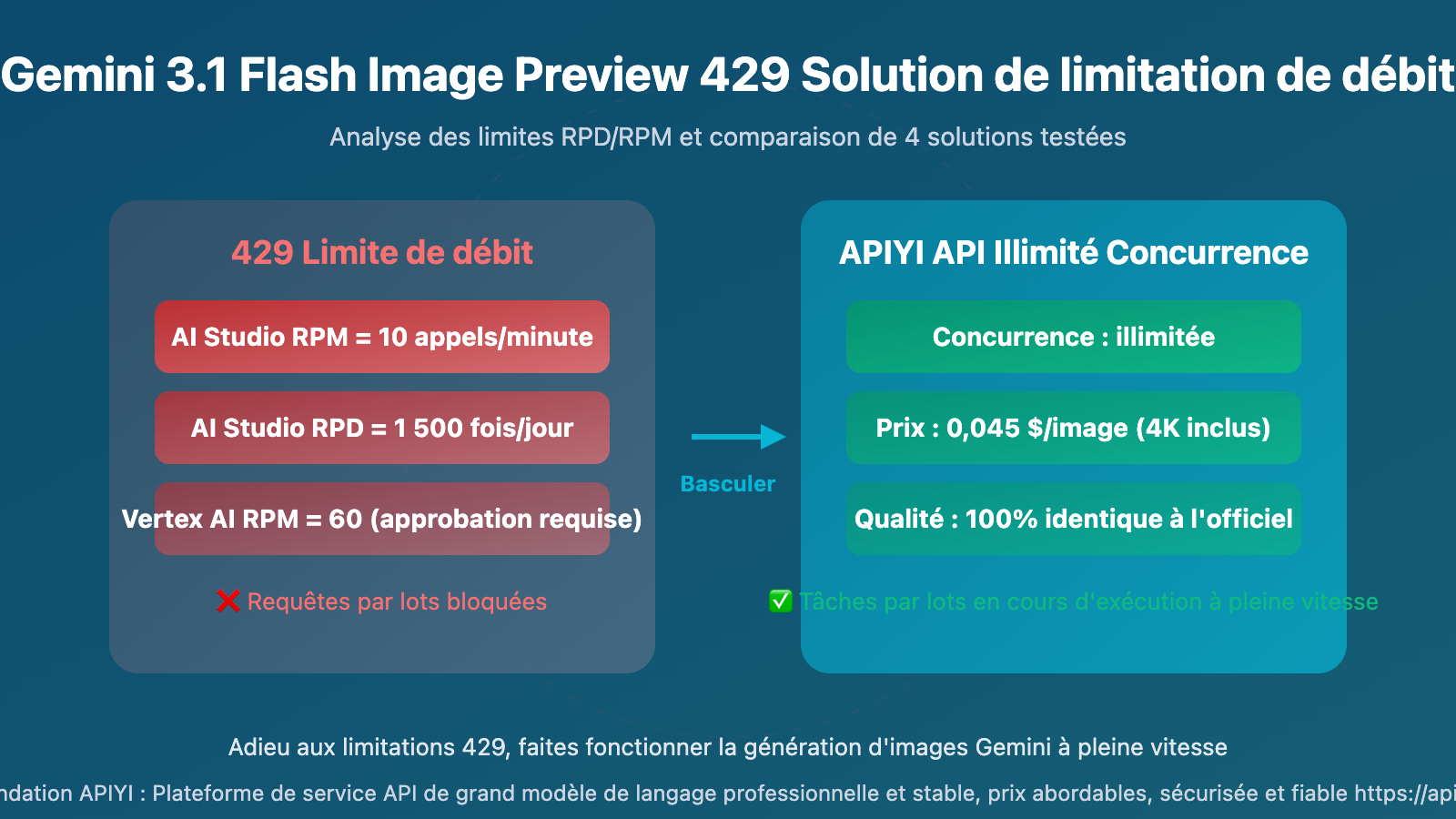
AI Studio est le premier choix pour la plupart des développeurs, gratuit et pratique. Mais la limitation pour la génération d'images est extrêmement stricte :
| Dimension de limitation | Valeur limite | Conversion |
|---|---|---|
| RPM (requêtes par minute) | 10 requêtes | 1 requête toutes les 6 secondes |
| RPD (requêtes par jour) | 1 500 requêtes | Limite atteinte en ~2,5 heures |
| TPM (tokens par minute) | 4 000 000 | Généralement pas un goulot d'étranglement |
| TPM de sortie d'image | 12 000 tokens/min | ~10 images/minute |
Expérience pratique : Si vous avez besoin de générer 500 images par lot, avec un RPM=10, le temps théorique minimum est de 50 minutes. Mais en tenant compte de la latence réseau, des nouvelles tentatives, etc., il faut en réalité 1 à 2 heures. Si vous avez besoin de générer plus de 1 500 images par jour, vous serez bloqué par la limite RPD.
Paramètres de limitation pour la génération d'images Gemini dans Vertex AI
Vertex AI est la solution d'entreprise de Google Cloud, avec des quotas plus élevés mais toujours des limites :
| Dimension de limitation | Valeur par défaut | Peut être augmentée |
|---|---|---|
| RPM | 60 requêtes | Oui, nécessite approbation |
| RPD | Pas de limite fixe | Mais contrainte par RPM et TPM |
| TPM | 4 000 000 | Peut être demandé |
| TPM de sortie d'image | 24 000 tokens/min | Peut être demandé |
Expérience pratique : Le RPM passe de 10 à 60, ce qui semble bien mieux, mais la demande d'augmentation nécessite de passer par le processus de ticket de Google Cloud, généralement 1 à 3 jours ouvrés. De plus, la configuration de Vertex AI est bien plus complexe que celle d'AI Studio (création de projet GCP, configuration de compte de service, permissions IAM, etc.), ce qui décourage de nombreux développeurs individuels et petites équipes.
Comparaison des limitations pour la génération d'images Gemini sur des plateformes tierces
| Plateforme | Limite de concurrence | Limite RPD | Prix par image (1K) | Remarques |
|---|---|---|---|---|
| AI Studio | RPM=10 | 1 500/jour | Gratuit (avec quota) | La plus stricte |
| Vertex AI | RPM=60 | Pas de limite fixe | ~0,067 $ | Nécessite configuration GCP |
| OpenRouter | Dépend de l'offre | Dépend de l'offre | ~0,06-0,08 $ | Plateforme générique |
| APIYI | Concurrence illimitée | Illimitée | 0,045 $ | Facturation à l'usage, résolution illimitée |
4 solutions pour résoudre les limitations 429 de Gemini 3.1 Flash Image Preview
Solution 1 : Limitation des requêtes de génération d'images Gemini + nouvelle tentative automatique
La solution la plus basique, ne nécessite pas de changer de plateforme, mais est inefficace.
import time
import random
import requests
def generate_with_retry(prompt, max_retries=5):
"""Requête de génération d'image avec nouvelle tentative et backoff"""
for attempt in range(max_retries):
try:
response = requests.post(endpoint, json=payload, headers=headers, timeout=120)
if response.status_code == 200:
return response.json()
elif response.status_code == 429:
# Backoff exponentiel + jitter aléatoire
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"Limitation 429, attente de {wait_time:.1f}s avant nouvelle tentative ({attempt+1}/{max_retries})")
time.sleep(wait_time)
else:
response.raise_for_status()
except Exception as e:
print(f"Exception de requête : {e}")
time.sleep(2)
raise Exception("Nombre maximum de nouvelles tentatives dépassé")
Voir le script complet de génération par lot (avec contrôle du débit)
import time
import random
import requests
import base64
from pathlib import Path
from concurrent.futures import ThreadPoolExecutor
class RateLimitedGenerator:
"""Générateur par lot respectant la limite RPM=10 d'AI Studio"""
def __init__(self, api_key, rpm_limit=10):
self.api_key = api_key
self.interval = 60.0 / rpm_limit # Intervalle minimum entre les requêtes
self.last_request_time = 0
self.endpoint = "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent"
def _wait_for_rate_limit(self):
elapsed = time.time() - self.last_request_time
if elapsed < self.interval:
time.sleep(self.interval - elapsed)
self.last_request_time = time.time()
def generate(self, prompt, output_path, retries=3):
for attempt in range(retries):
self._wait_for_rate_limit()
try:
response = requests.post(
f"{self.endpoint}?key={self.api_key}",
json={
"contents": [{"parts": [{"text": prompt}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"imageConfig": {"aspectRatio": "1:1", "imageSize": "1K"}
}
},
timeout=120
)
if response.status_code == 200:
data = response.json()
img = data["candidates"][0]["content"]["parts"][0]["inlineData"]["data"]
Path(output_path).write_bytes(base64.b64decode(img))
return True
elif response.status_code == 429:
wait = (2 ** attempt) + random.uniform(0, 2)
print(f"[429] Attente de {wait:.1f}s ...")
time.sleep(wait)
except Exception as e:
print(f"Exception : {e}")
time.sleep(2)
return False
# Exemple d'utilisation
gen = RateLimitedGenerator("VOTRE_CLE_AISTUDIO", rpm_limit=10)
prompts = ["un coucher de soleil sur les montagnes", "un chat dans l'espace", "ville futuriste"]
for i, p in enumerate(prompts):
success = gen.generate(p, f"output_{i}.png")
print(f"{'✅' if success else '❌'} {p}")
Avantages : Coût nul, adapté pour un petit nombre de requêtes
Inconvénients : Lent, la limite dure de RPD=1 500 ne peut pas être dépassée
Solution 2 : Migrer la génération d'images Gemini vers Vertex AI pour augmenter les quotas
Adaptée aux utilisateurs professionnels disposant d'un compte Google Cloud.
Étapes d'opération :
- Créer un projet GCP et activer l'API Vertex AI
- Configurer un compte de service et les permissions IAM
- Dans Google Cloud Console → IAM → Quotas, demander une augmentation du RPM
- Changer le point de terminaison dans le code d'AI Studio vers Vertex AI
Avantages : RPM passe de 10 à 60+, utilisable en contexte professionnel
Inconvénients : Configuration complexe, délai d'approbation de 1 à 3 jours, facturation aux tarifs standards de Google Cloud
Solution 3 : Interrogation de plusieurs projets pour la génération d'images Gemini
En créant plusieurs projets GCP ou clés API AI Studio, on alterne les requêtes pour contourner les limites RPD/RPM d'un seul projet.
import itertools
api_keys = ["CLE_1", "CLE_2", "CLE_3", "CLE_4", "CLE_5"]
key_pool = itertools.cycle(api_keys)
def generate_with_rotation(prompt):
"""Génère une image en alternant les clés"""
key = next(key_pool)
# ... Envoyer la requête avec la clé actuelle
return send_request(prompt, api_key=key)
Avantages : En théorie, N clés donnent un débit N fois supérieur
Inconvénients : Violation des conditions d'utilisation (TOS) de Google, risque de suspension de compte ; gestion de plusieurs clés accroît la complexité
Solution 4 : Utiliser une plateforme tierce sans limite de concurrence pour la génération d'images Gemini
C'est la solution que j'ai finalement adoptée. Après avoir comparé plusieurs plateformes tierces, j'ai choisi APIYI wentuo.ai, pour une raison simple :
| Dimension de comparaison | AI Studio | Vertex AI | APIYI |
|---|---|---|---|
| Limite de concurrence | RPM=10 | RPM=60 | Illimitée |
| Limite quotidienne | 1 500/jour | Contrainte par RPM | Illimitée |
| Prix par image (incluant 4K) | Gratuit mais limité | 0,067-0,151 $ | 0,045 $ |
| Facturation à l'usage (1K) | – | 0,067 $ | ~0,025 $ |
| Complexité de configuration | Simple | Complexe | Simple |
| Nécessite-t-il un VPN ? | Oui | Oui | Non |
En pratique, la facturation à l'usage à 0,045 $ par image inclut la résolution 4K. Avec la facturation par tokens, le coût est d'environ 0,02-0,05 $, selon la résolution. Le plus important est l'absence de limite de concurrence, les tâches par lot peuvent s'exécuter à pleine vitesse, sans être bloquées par l'erreur 429.
La méthode d'appel est également simple, il suffit de changer le point de terminaison :
import requests
import base64
API_KEY = "votre-cle-api-wentuo"
ENDPOINT = "https://api.wentuo.ai/v1beta/models/gemini-3.1-flash-image-preview:generateContent"
headers = {
"Content-Type": "application/json",
"x-goog-api-key": API_KEY
}
payload = {
"contents": [{"parts": [{"text": "Un chat mignon portant un casque spatial"}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"imageConfig": {"aspectRatio": "1:1", "imageSize": "2K"}
}
}
response = requests.post(ENDPOINT, headers=headers, json=payload, timeout=120)
result = response.json()
image_data = result["candidates"][0]["content"]["parts"][0]["inlineData"]["data"]
with open("output.png", "wb") as f:
f.write(base64.b64decode(image_data))
💡 Conseil d'utilisation : Si votre volume de génération quotidien dépasse 500 images, ou si vous avez des exigences de vitesse de concurrence, il est recommandé d'utiliser directement la solution sans limite de concurrence d'APIYI wentuo.ai. La facturation à l'usage à 0,045 $/image (résolution illimitée) ou la facturation par volume à partir de 0,018 $/image (512px) permet d'économiser 33 % à 70 % par rapport aux tarifs officiels de Google.

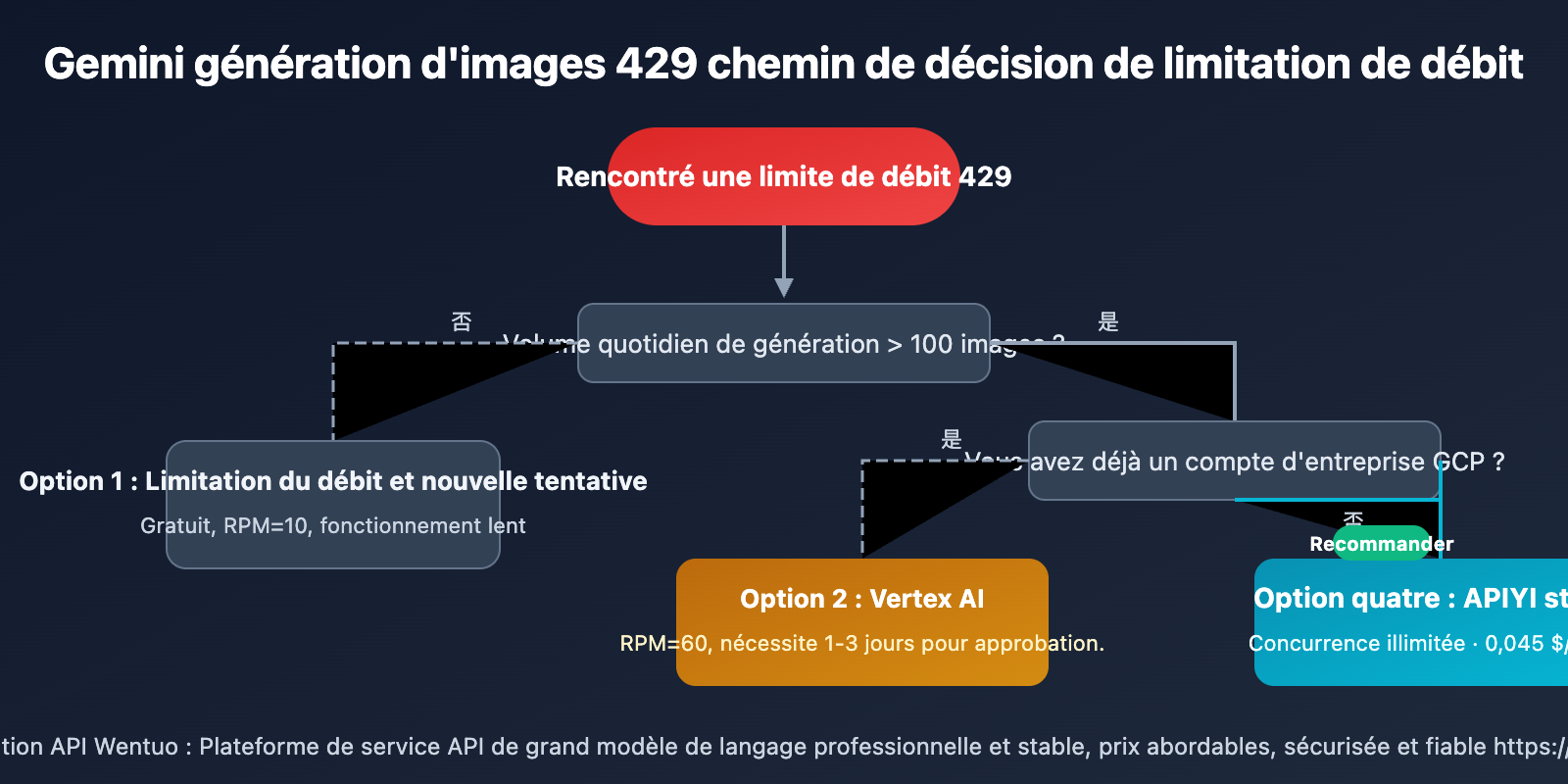
Recommandations pour 4 solutions face à la limitation 429 de Gemini 3.1 Flash Image Preview
Différents scénarios conviennent à différentes solutions :
| Scénario d'utilisation | Solution recommandée | Raison |
|---|---|---|
| 🎨 Apprentissage personnel / Expérimentation | Solution 1 (Réessai avec temporisation) | Gratuit, faible volume sans impact |
| 🏢 Entreprise disposant déjà de GCP | Solution 2 (Vertex AI) | Conforme, possibilité de demander un quota élevé |
| 🔬 Tests intensifs temporaires | Solution 3 (Multi-clés) | Utilisable à court terme, attention aux risques |
| 🚀 Environnement de production / Génération par lots | Solution 4 (API Wentuo) | Concurrence illimitée, coût le plus bas |
Comparaison du débit des différentes solutions de génération d'images Gemini
Hypothèse : génération de 1 000 images en 1K :
| Solution | Temps estimé | Coût total | Faisabilité |
|---|---|---|---|
| AI Studio (RPM=10) | ~100 minutes + limitation RPD pouvant nécessiter le lendemain | Gratuit | ⚠️ Soumis à la limite RPD |
| Vertex AI (RPM=60) | ~17 minutes | ~67 $ | ✅ Nécessite GCP |
| Rotation multi-clés (5 clés) | ~20 minutes | Gratuit | ⚠️ Risque de suspension de compte |
| API Wentuo (concurrence illimitée) | ~10-15 minutes | 45 $ (à l'acte) / ~25 $ (à la consommation) | ✅ Recommandé |
Questions fréquentes
Q1 : Combien de temps faut-il pour récupérer après une erreur 429 de Gemini 3.1 Flash Image Preview ?
Cela dépend du type de limitation déclenché :
- Limitation RPM : Récupération automatique après 1 minute d'attente.
- Limitation RPD : Nécessite d'attendre la réinitialisation le lendemain (à 0h UTC).
- Limitation TPM : Récupération après 1 minute d'attente.
Il est recommandé, dans le code, de déterminer le type de limitation spécifique en fonction de la valeur du champ quota_limit dans details, et d'adopter la stratégie correspondante.
Q2 : La qualité de génération d’images de l’API Wentuo est-elle identique à celle de Google officiel ?
Oui, l'API Wentuo (wentuo.ai) appelle directement le modèle officiel Google Gemini 3.1 Flash Image Preview. La qualité de génération est donc exactement la même que l'officiel. La différence réside uniquement dans :
- La suppression des limites RPD/RPM.
- La prise en charge d'une concurrence illimitée.
- Un prix plus avantageux (0,045 $/image vs 0,067 $/image officiel @1K).
Q3 : Comment choisir entre la facturation à l’acte et à la consommation ?
Logique de choix simple :
- Utilisation fixe en résolution 2K/4K → Choisir la facturation à l'acte (0,045 $/acte, le plus économique sans limite de résolution).
- Utilisation principale en 512px/1K → Choisir la facturation à la consommation (512px à seulement 0,018 $/acte, 60 % d'économie par rapport à l'acte).
- Résolutions mixtes → Calculer le coût moyen, généralement la facturation à la consommation est plus économique.
L'API Wentuo (wentuo.ai) prend en charge les deux modes de facturation avec une flexibilité de changement.
🎯 Résumé
Le problème de limitation de débit 429 de Gemini 3.1 Flash Image Preview est essentiellement dû aux quotas stricts (RPD/RPM) définis par Google pour AI Studio et Vertex AI. Points clés :
- Comprendre le type de limitation : Le code 429 correspond à une limite de quota (votre problème), tandis que le 503 indique un serveur surchargé (problème de Google). Les solutions sont totalement différentes.
- Évaluer votre volume d'utilisation : AI Studio suffit pour moins de 100 images par jour. Au-delà de 500 images, envisagez une plateforme tierce.
- Choisir la solution adaptée : Pour un environnement de production, privilégiez une solution sans limite de concurrence pour éviter l'impact des limitations sur votre activité.
- La comparaison des coûts est cruciale : APIYI propose des tarifs à l'usage à 0,045 $/image (incluant 4K), pouvant descendre à 0,018 $/image en volume, soit une économie de 33 % à 70 % par rapport aux tarifs officiels.
Pour les développeurs ayant besoin de générer des images en masse, APIYI (wentuo.ai) est actuellement le choix offrant la meilleure expérience globale — pas de limite de concurrence, tarifs plus bas, pas besoin de VPN, et une interface entièrement compatible.
📚 Références
-
Documentation officielle de l'API Google Gemini : Explications sur les quotas et limitations pour la génération d'images
- Lien :
ai.google.dev/gemini-api/docs/image-generation - Description : Paramètres de quota officiels et bonnes pratiques
- Lien :
-
Gestion des quotas Google Cloud : Processus de demande d'augmentation de quota pour Vertex AI
- Lien :
cloud.google.com/vertex-ai/docs/quotas - Description : Procédure officielle pour les utilisateurs professionnels souhaitant augmenter leurs quotas
- Lien :
-
Documentation APIYI Nano Banana 2 : Guide d'intégration pour la génération d'images sans limite de concurrence
- Lien :
docs.wentuo.ai - Description : Explications détaillées et exemples de code pour les deux modes de facturation (à l'usage et au volume)
- Lien :
📝 À propos de l'auteur : Équipe de création de contenu technique, spécialisée dans la génération d'images IA et le partage de connaissances sur les API. Pour plus de contenu technique et de ressources, visitez APIYI wentuo.ai.
📋 Note sur le contenu : Cet article est basé sur une expérience d'utilisation réelle. Les paramètres de limitation peuvent évoluer avec les politiques de Google. Pour une assistance technique, contactez APIYI wentuo.ai.