
Nota do autor: Análise detalhada da causa raiz do problema de limitação 429 na geração de imagens do Gemini 3.1 Flash Image Preview, comparando as políticas de limitação do AI Studio, Vertex AI e plataformas de terceiros, fornecendo 4 soluções comprovadamente eficazes.
Ao usar o Gemini 3.1 Flash Image Preview para gerar imagens, o que mais incomoda não é a qualidade da geração, mas ser bloqueado pela limitação 429 logo no início. Seja usando o AI Studio ou o Vertex AI, as restrições de RPD (Requests Per Day) e RPM (Requests Per Minute) são muito rigorosas, tornando praticamente impossível executar geração de imagens em lote.
Este artigo partirá da experiência prática de uso para analisar detalhadamente a causa raiz da limitação 429, comparar as diferenças nas políticas de limitação entre plataformas e oferecer 4 soluções validadas — incluindo uma opção sem limitação de concorrência e com preço baixo de US$ 0,045 por imagem.
Valor principal: Após ler este artigo, você entenderá completamente a lógica por trás do erro 429 na geração de imagens do Gemini e encontrará a solução mais adequada para o seu cenário.

O que é o erro 429 no Gemini 3.1 Flash Image Preview
Primeiro, vamos ver como é esse erro:
{
"error": {
"code": 429,
"message": "Resource has been exhausted (e.g. check quota).",
"status": "RESOURCE_EXHAUSTED",
"details": [
{
"reason": "RATE_LIMIT_EXCEEDED",
"metadata": {
"quota_limit": "GenerateContentRequestsPerDayPerProjectPerModel",
"quota_limit_value": "1500"
}
}
]
}
}
Traduzindo para linguagem simples: você esgotou suas requisições diárias ou está fazendo requisições com muita frequência por minuto.
Diferente do erro 503, o 429 não é o servidor não aguentando, mas sim um limite de cota que o Google define ativamente para você. Independentemente de haver capacidade de processamento ociosa no servidor, ao atingir o limite, a requisição é simplesmente rejeitada.
Diferença entre os erros 429 e 503 na geração de imagens do Gemini
| Item de comparação | 429 RESOURCE_EXHAUSTED | 503 UNAVAILABLE |
|---|---|---|
| Causa raiz | Sua cota foi esgotada | Capacidade de processamento do servidor insuficiente |
| Condição de acionamento | Exceder limites de RPD/RPM/TPM | Carga global alta |
| Escopo de impacto | Apenas seu projeto | Todos os usuários |
| Pode ser resolvido aguardando? | RPM: aguarde 1 minuto, RPD: aguarde até o dia seguinte | Normalmente de minutos a horas |
| Pode ser resolvido pagando? | Vertex AI permite aumentar a cota | Não pode ser resolvido diretamente |
| Solução definitiva | Trocar de plataforma / Aumentar cota | Aguardar ou trocar de plataforma |
Comparativo de Estratégias de Limitação de Taxa do Gemini 3.1 Flash Image Preview em Diferentes Plataformas
Este é o cerne da questão — as diferenças nas limitações de taxa entre as plataformas são enormes.
Parâmetros de Limitação do Gemini Image Generation no AI Studio
O AI Studio é a primeira escolha para a maioria dos desenvolvedores, gratuito e fácil de usar. No entanto, a limitação para geração de imagens é extremamente rigorosa:
| Dimensão da Limitação | Valor Limite | Conversão |
|---|---|---|
| RPM (Requisições por Minuto) | 10 requisições | 1 requisição a cada 6 segundos |
| RPD (Requisições por Dia) | 1.500 requisições | Atinge o limite em ~2,5 horas de uso contínuo |
| TPM (Tokens por Minuto) | 4.000.000 | Geralmente não é o gargalo |
| TPM de Saída de Imagem | 12.000 tokens/min | ~10 imagens/minuto |
Experiência prática: Se você precisa gerar 500 imagens em lote, com RPM=10, o tempo teórico mínimo é de 50 minutos. Considerando latência de rede, novas tentativas, etc., na prática leva 1-2 horas. Se você precisa gerar mais de 1.500 imagens por dia, será bloqueado pelo limite RPD.
Parâmetros de Limitação do Gemini Image Generation no Vertex AI
O Vertex AI é a solução corporativa do Google Cloud, com cotas mais altas, mas ainda com limites:
| Dimensão da Limitação | Valor Padrão | Pode Solicitar Aumento |
|---|---|---|
| RPM | 60 requisições | Sim, requer aprovação |
| RPD | Sem limite fixo | Mas restrito por RPM e TPM |
| TPM | 4.000.000 | Pode solicitar |
| TPM de Saída de Imagem | 24.000 tokens/min | Pode solicitar |
Experiência prática: O RPM aumenta de 10 para 60, o que parece muito melhor, mas solicitar o aumento requer um processo de ticket no Google Cloud, geralmente de 1 a 3 dias úteis. Além disso, a configuração do Vertex AI é muito mais complexa do que a do AI Studio (precisa criar um projeto GCP, configurar conta de serviço, permissões IAM, etc.), fazendo com que muitos desenvolvedores individuais e pequenas equipes desistam.
Comparativo de Limitação do Gemini Image Generation em Plataformas de Terceiros
| Plataforma | Limite de Concorrência | Limite RPD | Preço por Imagem (1K) | Observação |
|---|---|---|---|---|
| AI Studio | RPM=10 | 1.500/dia | Grátis (cota limitada) | Mais restritivo |
| Vertex AI | RPM=60 | Sem limite fixo | ~$0,067 | Requer configuração GCP |
| OpenRouter | Depende do plano | Depende do plano | ~$0,06-$0,08 | Plataforma genérica |
| Wentuo AI | Concorrência Ilimitada | Ilimitado | $0,045 | Cobrança por uso, resolução ilimitada |
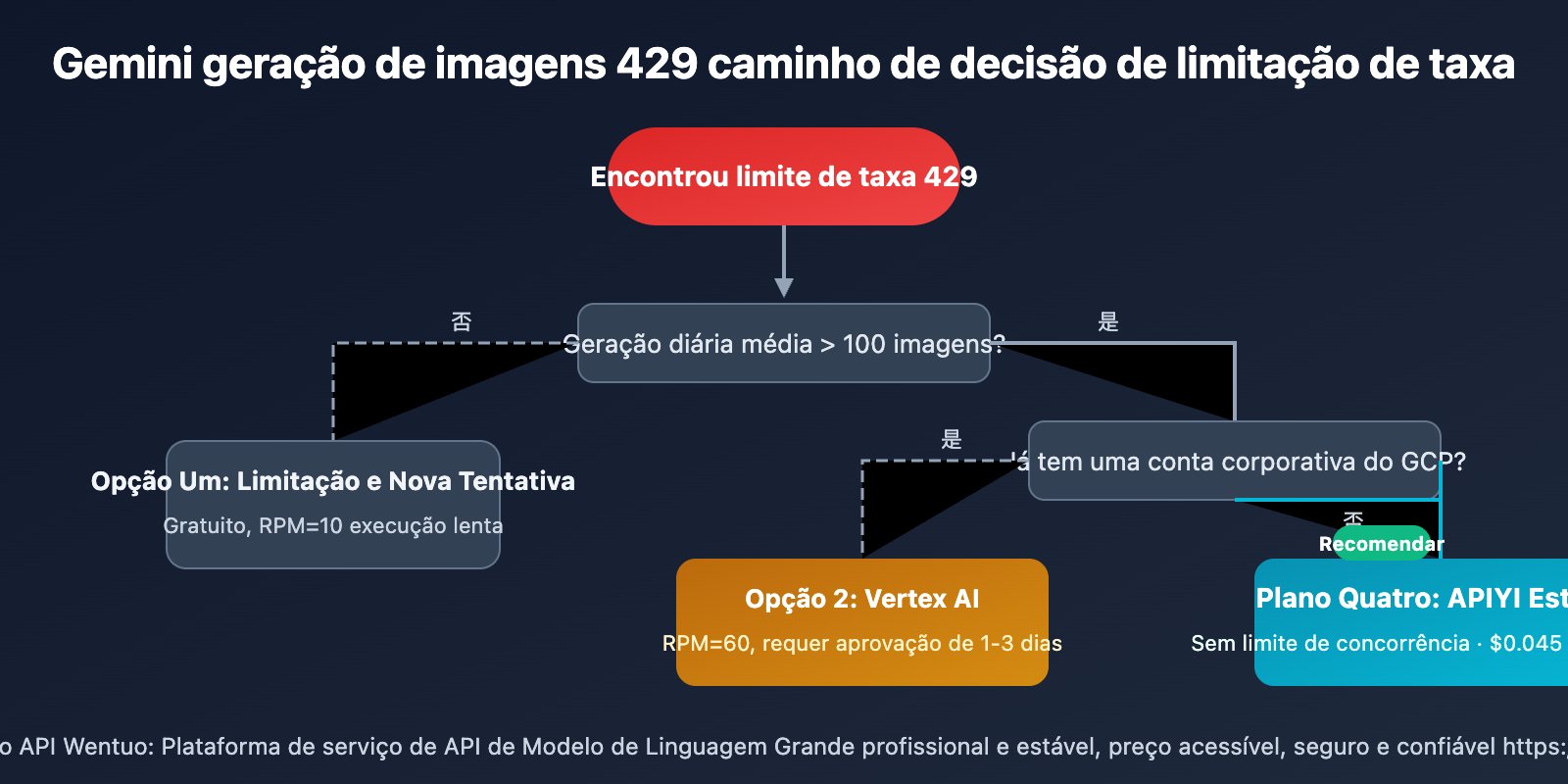
4 Soluções para Resolver a Limitação 429 do Gemini 3.1 Flash Image Preview
Solução 1: Limitação de Taxa + Nova Tentativa Automática para Geração de Imagens Gemini
A solução mais básica, não requer troca de plataforma, mas é ineficiente.
import time
import random
import requests
def generate_with_retry(prompt, max_retries=5):
"""Requisição de geração de imagem com nova tentativa e backoff"""
for attempt in range(max_retries):
try:
response = requests.post(endpoint, json=payload, headers=headers, timeout=120)
if response.status_code == 200:
return response.json()
elif response.status_code == 429:
# Backoff exponencial + jitter aleatório
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"Limitação 429, aguardando {wait_time:.1f}s antes de tentar novamente ({attempt+1}/{max_retries})")
time.sleep(wait_time)
else:
response.raise_for_status()
except Exception as e:
print(f"Exceção na requisição: {e}")
time.sleep(2)
raise Exception("Número máximo de tentativas excedido")
Ver script completo de geração em lote (com controle de taxa)
import time
import random
import requests
import base64
from pathlib import Path
from concurrent.futures import ThreadPoolExecutor
class RateLimitedGenerator:
"""Gerador em lote que respeita o limite RPM=10 do AI Studio"""
def __init__(self, api_key, rpm_limit=10):
self.api_key = api_key
self.interval = 60.0 / rpm_limit # Intervalo mínimo entre requisições
self.last_request_time = 0
self.endpoint = "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent"
def _wait_for_rate_limit(self):
elapsed = time.time() - self.last_request_time
if elapsed < self.interval:
time.sleep(self.interval - elapsed)
self.last_request_time = time.time()
def generate(self, prompt, output_path, retries=3):
for attempt in range(retries):
self._wait_for_rate_limit()
try:
response = requests.post(
f"{self.endpoint}?key={self.api_key}",
json={
"contents": [{"parts": [{"text": prompt}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"imageConfig": {"aspectRatio": "1:1", "imageSize": "1K"}
}
},
timeout=120
)
if response.status_code == 200:
data = response.json()
img = data["candidates"][0]["content"]["parts"][0]["inlineData"]["data"]
Path(output_path).write_bytes(base64.b64decode(img))
return True
elif response.status_code == 429:
wait = (2 ** attempt) + random.uniform(0, 2)
print(f"[429] Aguardando {wait:.1f}s ...")
time.sleep(wait)
except Exception as e:
print(f"Exceção: {e}")
time.sleep(2)
return False
# Exemplo de uso
gen = RateLimitedGenerator("SUA_CHAVE_AISTUDIO", rpm_limit=10)
prompts = ["um pôr do sol sobre montanhas", "um gato no espaço", "cidade futurista"]
for i, p in enumerate(prompts):
success = gen.generate(p, f"output_{i}.png")
print(f"{'✅' if success else '❌'} {p}")
Vantagens: Custo zero, adequado para pequenos volumes de requisições.
Desvantagens: Lento, o limite rígido de RPD=1.500 não pode ser ultrapassado.
Solução 2: Migrar a Geração de Imagens Gemini para o Vertex AI para Aumentar a Cota
Adequado para usuários corporativos com conta no Google Cloud.
Passos:
- Criar um projeto GCP e ativar a API Vertex AI
- Configurar conta de serviço e permissões IAM
- Solicitar aumento do RPM em Google Cloud Console → IAM → Quotas
- Alterar o endpoint no código de AI Studio para Vertex AI
Vantagens: RPM aumenta de 10 para 60+, utilizável em cenários corporativos.
Desvantagens: Configuração complexa, ciclo de aprovação de 1-3 dias, cobrança conforme tarifação padrão do Google Cloud.
Solução 3: Rotação de Múltiplos Projetos para Geração de Imagens Gemini
Criar múltiplos projetos GCP ou chaves de API do AI Studio para fazer requisições rotativas e contornar os limites RPD/RPM de um único projeto.
import itertools
api_keys = ["CHAVE_1", "CHAVE_2", "CHAVE_3", "CHAVE_4", "CHAVE_5"]
key_pool = itertools.cycle(api_keys)
def generate_with_rotation(prompt):
"""Gera imagem usando rotação de chaves"""
key = next(key_pool)
# ... Envia requisição usando a chave atual
return send_request(prompt, api_key=key)
Vantagens: Teoricamente, N chaves fornecem N vezes a taxa de transferência.
Desvantagens: Viola os Termos de Serviço (TOS) do Google, risco de suspensão da conta; gerenciar múltiplas chaves aumenta a complexidade.
Solução 4: Usar uma Plataforma de Terceiros com Concorrência Ilimitada para Geração de Imagens Gemini
Esta é a solução que acabei adotando. Após comparar várias plataformas de terceiros, escolhi o Wentuo AI wentuo.ai, a razão é direta:
| Dimensão de Comparação | AI Studio | Vertex AI | Wentuo AI |
|---|---|---|---|
| Limite de Concorrência | RPM=10 | RPM=60 | Ilimitado |
| Limite Diário | 1.500/dia | Restrito por RPM | Ilimitado |
| Preço por Imagem (inclui 4K) | Grátis mas com cota | $0,067-$0,151 | $0,045 |
| Cobrança por Uso (1K) | – | $0,067 | ~$0,025 |
| Complexidade de Configuração | Simples | Complexa | Simples |
| Precisa de VPN? | Sim | Sim | Não |
Na prática, a cobrança por uso é de $0,045 por imagem, incluindo resolução 4K. Se for por Tokens, fica entre $0,02 e $0,05, dependendo da resolução. O mais importante é a concorrência ilimitada, permitindo que tarefas em lote rodem em velocidade máxima, sem ser bloqueadas pelo erro 429.
A forma de chamada também é simples, basta trocar o endpoint:
import requests
import base64
API_KEY = "sua-chave-api-wentuo"
ENDPOINT = "https://api.wentuo.ai/v1beta/models/gemini-3.1-flash-image-preview:generateContent"
headers = {
"Content-Type": "application/json",
"x-goog-api-key": API_KEY
}
payload = {
"contents": [{"parts": [{"text": "Um gato fofo usando capacete espacial"}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"imageConfig": {"aspectRatio": "1:1", "imageSize": "2K"}
}
}
response = requests.post(ENDPOINT, headers=headers, json=payload, timeout=120)
result = response.json()
image_data = result["candidates"][0]["content"]["parts"][0]["inlineData"]["data"]
with open("output.png", "wb") as f:
f.write(base64.b64decode(image_data))
💡 Recomendação de uso: Se o seu volume diário de geração for superior a 500 imagens, ou se você tiver requisitos de velocidade de concorrência, recomendo usar diretamente a solução de concorrência ilimitada do Wentuo AI wentuo.ai. A cobrança por uso é de $0,045/imagem (resolução ilimitada), e a cobrança por volume pode chegar a $0,018/imagem (512px), economizando 33%-70% em comparação com o Google oficial.
Recomendações de 4 Opções para Lidar com o Erro 429 (Rate Limit) do Gemini 3.1 Flash Image Preview
Diferentes cenários se adequam a diferentes soluções:
| Cenário de Uso | Solução Recomendada | Motivo |
|---|---|---|
| 🎨 Aprendizado/Experiência Pessoal | Opção 1 (Retry com Throttle) | Gratuita, volume pequeno não afeta |
| 🏢 Empresa com GCP Existente | Opção 2 (Vertex AI) | Conformidade, pode solicitar cota alta |
| 🔬 Testes Temporários em Grande Volume | Opção 3 (Múltiplas Chaves) | Viável a curto prazo, atenção ao risco |
| 🚀 Ambiente de Produção/Geração em Lote | Opção 4 (API Estável) | Sem limite de concorrência, custo mais baixo |
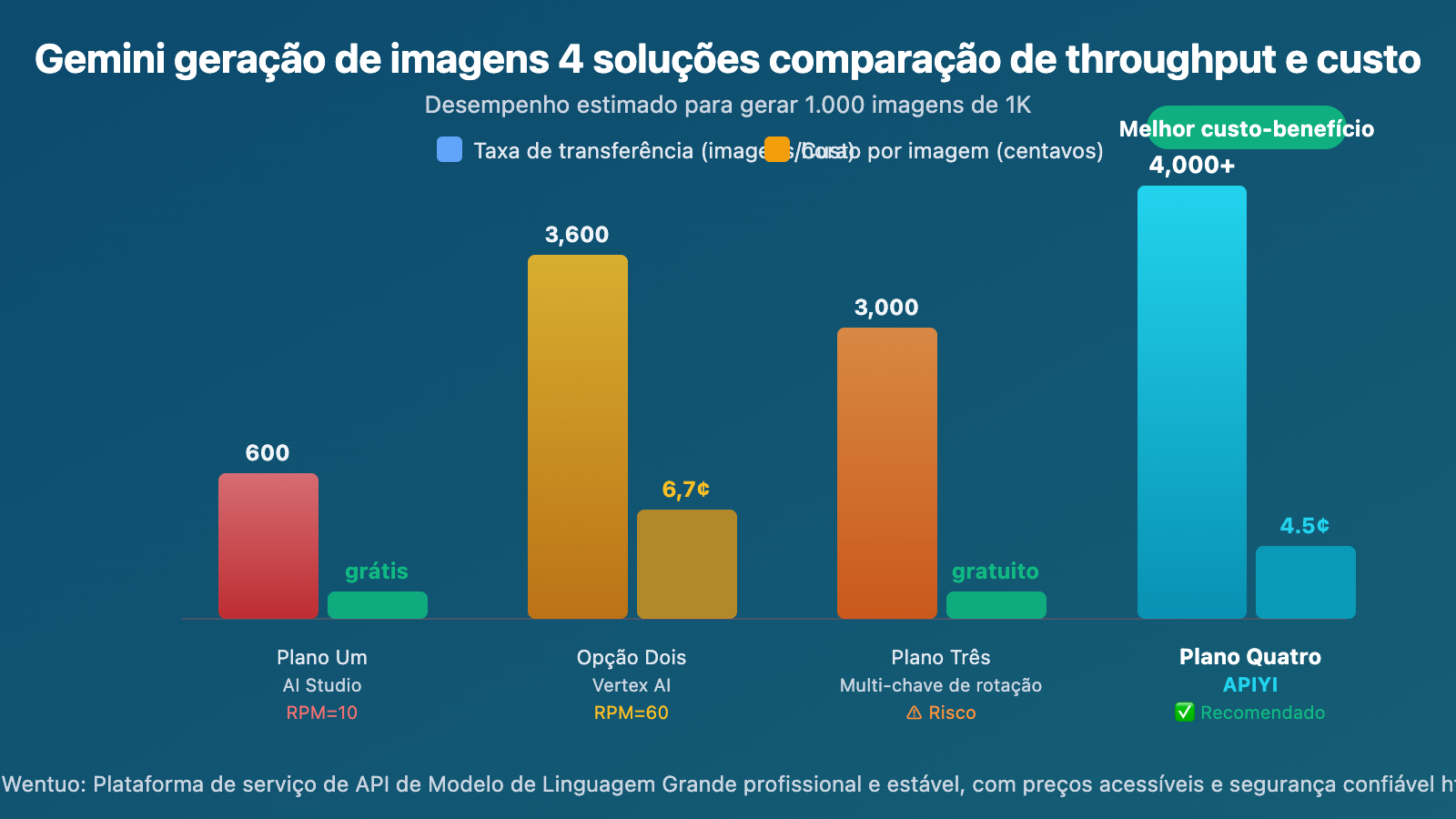
Comparação de Taxa de Transferência para Geração de Imagens do Gemini
Supondo a geração de 1.000 imagens em 1K:
| Solução | Tempo Estimado | Custo Total | Viabilidade |
|---|---|---|---|
| AI Studio (RPM=10) | ~100 minutos + limite RPD pode exigir esperar até o dia seguinte | Gratuito | ⚠️ Sujeito ao limite RPD |
| Vertex AI (RPM=60) | ~17 minutos | ~US$ 67 | ✅ Requer GCP |
| Rotação com Múltiplas Chaves (5 chaves) | ~20 minutos | Gratuito | ⚠️ Risco de suspensão da conta |
| API Estável (sem limite de concorrência) | ~10-15 minutos | US$ 45 (por chamada) / ~US$ 25 (por volume) | ✅ Recomendado |
Perguntas Frequentes
Q1: Quanto tempo leva para o serviço do Gemini 3.1 Flash Image Preview se recuperar após o erro 429?
Depende de qual limite de taxa foi atingido:
- Limite RPM: Recuperação automática após 1 minuto de espera.
- Limite RPD: É necessário aguardar até o reset no dia seguinte (horário UTC 0).
- Limite TPM: Recuperação automática após 1 minuto de espera.
Recomenda-se implementar na lógica do código uma verificação do valor quota_limit no campo details da resposta de erro para identificar o tipo específico de limite e adotar a estratégia correspondente.
Q2: A qualidade da geração de imagens da API Estável é a mesma da API oficial do Google?
Sim, a API Estável do wentuo.ai faz chamadas diretas ao modelo oficial do Google, Gemini 3.1 Flash Image Preview. A qualidade da geração é exatamente a mesma. As diferenças são apenas:
- Remoção dos limites RPD/RPM.
- Suporte a concorrência ilimitada.
- Preço mais vantajoso (US$ 0,045/imagem vs US$ 0,067/imagem oficial @1K).
Q3: Como escolher entre cobrança por chamada e cobrança por volume?
Lógica simples de escolha:
- Uso fixo de resolução 2K/4K → Escolha cobrança por chamada (US$ 0,045/chamada, mais vantajoso para qualquer resolução).
- Uso principal de 512px/1K → Escolha cobrança por volume (512px custa apenas US$ 0,018/chamada, 60% mais barato que por chamada).
- Resoluções mistas → Calcule o custo médio; geralmente a cobrança por volume é mais econômica.
A API Estável do wentuo.ai suporta alternar flexivelmente entre os dois modos de cobrança.
🎯 Resumo
O problema de limitação de taxa 429 do Gemini 3.1 Flash Image Preview é essencialmente devido às cotas rigorosas (RPD/RPM) estabelecidas pelo Google para o AI Studio e o Vertex AI. Os pontos principais são:
- Entenda o tipo de limitação: 429 é uma limitação de cota (seu problema), 503 é sobrecarga do servidor (problema do Google). As soluções são completamente diferentes.
- Avalie seu uso: O AI Studio é suficiente para menos de 100 imagens por dia. Para mais de 500 imagens por dia, considere uma plataforma de terceiros.
- Escolha a solução adequada: Para ambientes de produção, recomenda-se uma solução sem limitação de concorrência para evitar que a limitação de taxa afete seus negócios.
- A comparação de custos é importante: A APIYI cobra $0.045 por imagem (incluindo 4K) no plano por uso, podendo chegar a $0.018 por imagem no plano por volume, economizando de 33% a 70% em comparação com a solução oficial.
Para desenvolvedores que precisam gerar imagens em lote, a APIYI (wentuo.ai) é atualmente a melhor escolha em termos de experiência geral — sem limitação de concorrência, preços mais baixos, sem necessidade de VPN e interface totalmente compatível.
📚 Referências
-
Documentação oficial da API Gemini do Google: Explicação sobre cotas e limitação de taxa para geração de imagens
- Link:
ai.google.dev/gemini-api/docs/image-generation - Descrição: Parâmetros de cota oficiais e melhores práticas
- Link:
-
Gerenciamento de cotas do Google Cloud: Processo para solicitar aumento de cotas no Vertex AI
- Link:
cloud.google.com/vertex-ai/docs/quotas - Descrição: Caminho oficial para usuários empresariais aumentarem suas cotas
- Link:
-
Documentação da APIYI Nano Banana 2: Guia de integração para geração de imagens sem limitação de concorrência
- Link:
docs.wentuo.ai - Descrição: Explicação detalhada e exemplos de código para os dois planos de cobrança (por uso e por volume)
- Link:
📝 Sobre o autor: Equipe de criação de conteúdo técnico, focada em geração de imagens com IA e compartilhamento de tecnologias de API. Para mais conteúdo técnico e recursos, visite a APIYI em wentuo.ai.
📋 Nota sobre o conteúdo: Este artigo foi compilado com base em experiências práticas. Os parâmetros específicos de limitação de taxa podem mudar conforme as políticas do Google. Para suporte técnico, você pode obter ajuda através da APIYI em wentuo.ai.