
Catatan Penulis: Analisis mendalam tentang akar penyebab masalah pembatasan 429 pada pembuatan gambar Gemini 3.1 Flash Image Preview, perbandingan kebijakan pembatasan di AI Studio, Vertex AI, dan platform pihak ketiga, serta 4 solusi yang terbukti efektif berdasarkan pengujian.
Saat menggunakan Gemini 3.1 Flash Image Preview untuk membuat gambar, masalah yang paling menjengkelkan bukanlah kualitas hasilnya, tetapi justru pembatasan 429 yang langsung muncul saat proses baru berjalan. Baik menggunakan AI Studio maupun Vertex AI, batasan RPD (Permintaan per Hari) dan RPM (Permintaan per Menit) sangat ketat, sehingga pembuatan gambar dalam jumlah besar hampir tidak mungkin dilakukan.
Artikel ini akan berangkat dari pengalaman penggunaan praktis, menganalisis secara detail akar penyebab pembatasan 429, membandingkan perbedaan kebijakan pembatasan di berbagai platform, dan memberikan 4 solusi yang telah teruji—termasuk satu solusi tanpa batas konkurensi dengan harga serendah $0.045 per gambar.
Nilai Inti: Setelah membaca artikel ini, Anda akan benar-benar memahami logika dasar di balik error 429 pada pembuatan gambar Gemini, dan menemukan solusi yang paling cocok untuk skenario Anda.

Apa Itu Error 429 pada Gemini 3.1 Flash Image Preview
Mari kita lihat dulu seperti apa bentuk error ini:
{
"error": {
"code": 429,
"message": "Resource has been exhausted (e.g. check quota).",
"status": "RESOURCE_EXHAUSTED",
"details": [
{
"reason": "RATE_LIMIT_EXCEEDED",
"metadata": {
"quota_limit": "GenerateContentRequestsPerDayPerProjectPerModel",
"quota_limit_value": "1500"
}
}
]
}
}
Diterjemahkan ke bahasa sederhana: Jumlah permintaan Anda hari ini sudah habis, atau permintaan Anda terlalu sering dalam satu menit.
Berbeda dengan error 503, error 429 bukan karena server tidak mampu menangani, melainkan Google secara aktif menetapkan batas kuota untuk Anda. Terlepas dari apakah server memiliki daya komputasi yang tersedia atau tidak, begitu mencapai batas, permintaan akan langsung ditolak.
Perbedaan Error 429 dan 503 pada Pembuatan Gambar Gemini
| Aspek Perbandingan | 429 RESOURCE_EXHAUSTED | 503 UNAVAILABLE |
|---|---|---|
| Penyebab Dasar | Kuota Anda habis | Daya komputasi server tidak mencukupi |
| Kondisi Pemicu | Melebihi batas RPD/RPM/TPM | Beban global yang tinggi |
| Cakupan Dampak | Hanya terbatas pada proyek Anda | Semua pengguna |
| Bisa Diselesaikan dengan Menunggu? | RPM tunggu 1 menit, RPD tunggu hingga hari berikutnya | Biasanya beberapa menit hingga beberapa jam |
| Bisa Diselesaikan dengan Bayar? | Vertex AI dapat meningkatkan kuota | Tidak bisa diselesaikan secara langsung |
| Solusi Mendasar | Ganti platform/tingkatkan kuota | Tunggu atau ganti platform |
Perbandingan Kebijakan Pembatasan Lalu Lintas Gemini 3.1 Flash Image Preview di Berbagai Platform
Inilah inti permasalahannya — perbedaan kebijakan pembatasan di setiap platform sangat besar.
Parameter Pembatasan Gemini Image Generation di AI Studio
AI Studio adalah pilihan pertama bagi kebanyakan pengembang, gratis dan mudah digunakan. Namun, pembatasan untuk pembuatan gambar sangat ketat:
| Dimensi Pembatasan | Nilai Batas | Konversi |
|---|---|---|
| RPM (Permintaan per Menit) | 10 kali | Hanya bisa 1 permintaan setiap 6 detik |
| RPD (Permintaan per Hari) | 1,500 kali | Hanya sekitar 2.5 jam untuk mencapai batas |
| TPM (Token per Menit) | 4,000,000 | Biasanya bukan hambatan |
| TPM Output Gambar | 12,000 tokens/menit | Sekitar 10 gambar/menit |
Pengalaman nyata: Jika kamu perlu membuat 500 gambar secara batch, dengan RPM=10, secara teori paling cepat butuh 50 menit. Tapi dengan mempertimbangkan latensi jaringan, percobaan ulang, dan faktor lainnya, kenyataannya butuh 1-2 jam. Jika dalam sehari perlu membuat lebih dari 1,500 gambar, langsung terhambat oleh batas RPD.
Parameter Pembatasan Gemini Image Generation di Vertex AI
Vertex AI adalah solusi tingkat perusahaan dari Google Cloud, dengan kuota lebih tinggi tetapi tetap ada batasnya:
| Dimensi Pembatasan | Nilai Default | Dapat Diajukan Peningkatan |
|---|---|---|
| RPM | 60 kali | Bisa, perlu persetujuan |
| RPD | Tidak ada batas tetap | Namun dibatasi oleh RPM dan TPM |
| TPM | 4,000,000 | Bisa diajukan |
| TPM Output Gambar | 24,000 tokens/menit | Bisa diajukan |
Pengalaman nyata: RPM naik dari 10 ke 60, terlihat jauh lebih baik, tetapi mengajukan peningkatan perlu melalui proses tiket Google Cloud, biasanya 1-3 hari kerja. Selain itu, konfigurasi Vertex AI jauh lebih rumit dibanding AI Studio (perlu membuat proyek GCP, mengatur akun layanan, mengonfigurasi izin IAM, dll.), sehingga banyak pengembang individu dan tim kecil langsung menyerah.
Perbandingan Pembatasan Gemini Image Generation di Platform Pihak Ketiga
| Platform | Batas Konkurensi | Batas RPD | Harga per Gambar (1K) | Catatan |
|---|---|---|---|---|
| AI Studio | RPM=10 | 1,500/hari | Gratis (terbatas) | Paling ketat |
| Vertex AI | RPM=60 | Tidak ada batas tetap | ~$0.067 | Perlu konfigurasi GCP |
| OpenRouter | Tergantung paket | Tergantung paket | ~$0.06-0.08 | Platform umum |
| Wentuo API | Tidak terbatas konkurensi | Tidak terbatas | $0.045 | Bayar per penggunaan, resolusi tidak terbatas |
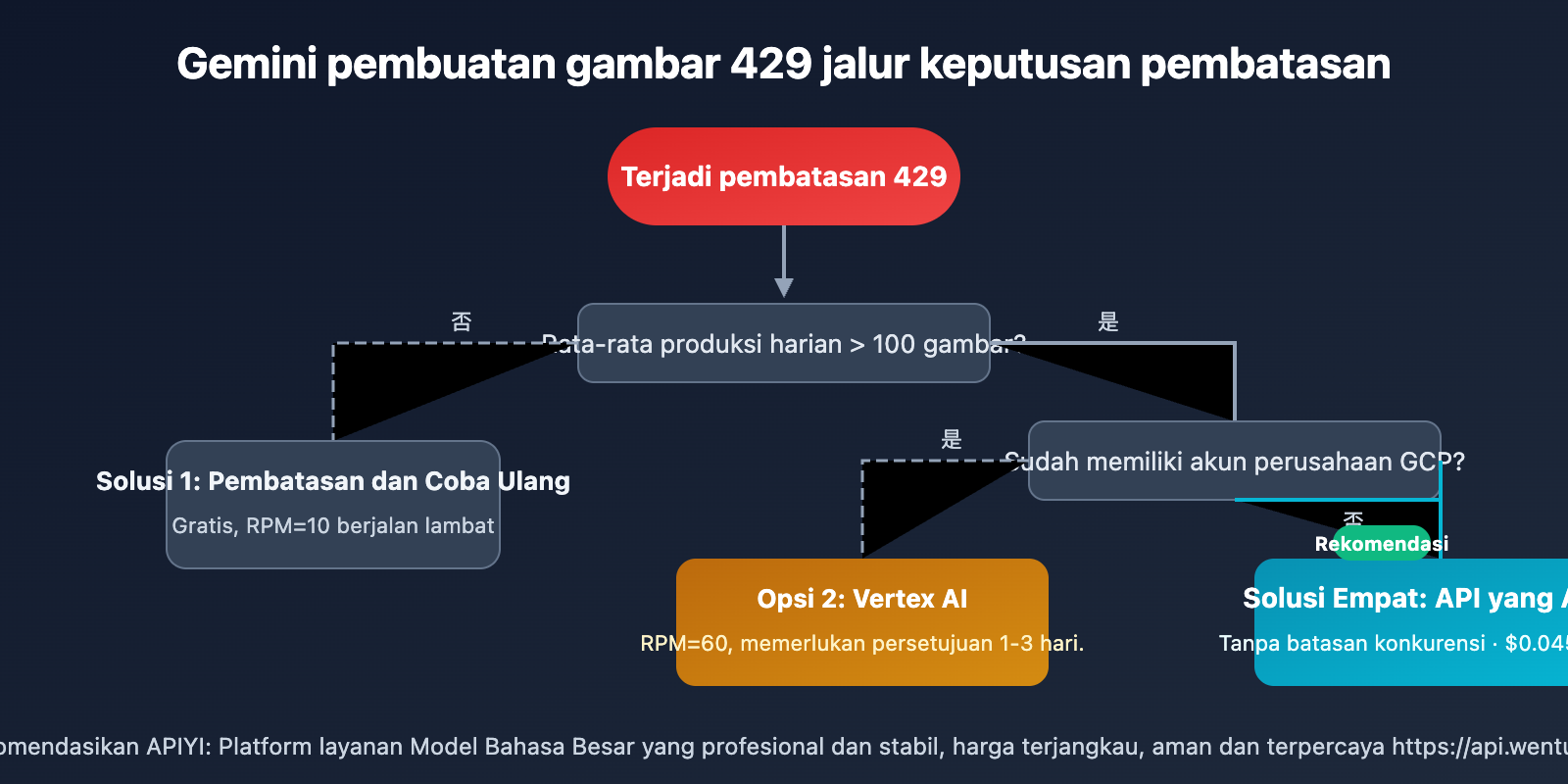
4 Solusi untuk Mengatasi Pembatasan 429 pada Gemini 3.1 Flash Image Preview
Solusi 1: Pembatasan Laju Permintaan + Percobaan Ulang Otomatis
Solusi paling dasar, tidak perlu ganti platform, tetapi efisiensinya rendah.
import time
import random
import requests
def generate_with_retry(prompt, max_retries=5):
"""Permintaan pembuatan gambar dengan percobaan ulang dan backoff"""
for attempt in range(max_retries):
try:
response = requests.post(endpoint, json=payload, headers=headers, timeout=120)
if response.status_code == 200:
return response.json()
elif response.status_code == 429:
# Exponential backoff + random jitter
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"Kode 429, menunggu {wait_time:.1f}s sebelum coba lagi ({attempt+1}/{max_retries})")
time.sleep(wait_time)
else:
response.raise_for_status()
except Exception as e:
print(f"Kesalahan permintaan: {e}")
time.sleep(2)
raise Exception("Melebihi jumlah percobaan maksimum")
Lihat skrip pembuatan batch lengkap (termasuk kontrol kecepatan)
import time
import random
import requests
import base64
from pathlib import Path
from concurrent.futures import ThreadPoolExecutor
class RateLimitedGenerator:
"""Generator batch yang mematuhi batas RPM=10 AI Studio"""
def __init__(self, api_key, rpm_limit=10):
self.api_key = api_key
self.interval = 60.0 / rpm_limit # Interval minimum antar permintaan
self.last_request_time = 0
self.endpoint = "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent"
def _wait_for_rate_limit(self):
elapsed = time.time() - self.last_request_time
if elapsed < self.interval:
time.sleep(self.interval - elapsed)
self.last_request_time = time.time()
def generate(self, prompt, output_path, retries=3):
for attempt in range(retries):
self._wait_for_rate_limit()
try:
response = requests.post(
f"{self.endpoint}?key={self.api_key}",
json={
"contents": [{"parts": [{"text": prompt}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"imageConfig": {"aspectRatio": "1:1", "imageSize": "1K"}
}
},
timeout=120
)
if response.status_code == 200:
data = response.json()
img = data["candidates"][0]["content"]["parts"][0]["inlineData"]["data"]
Path(output_path).write_bytes(base64.b64decode(img))
return True
elif response.status_code == 429:
wait = (2 ** attempt) + random.uniform(0, 2)
print(f"[429] Menunggu {wait:.1f}s ...")
time.sleep(wait)
except Exception as e:
print(f"Kesalahan: {e}")
time.sleep(2)
return False
# Contoh penggunaan
gen = RateLimitedGenerator("KUNCI_AISTUDIO_ANDA", rpm_limit=10)
prompts = ["matahari terbenam di atas gunung", "kucing di luar angkasa", "kota futuristik"]
for i, p in enumerate(prompts):
success = gen.generate(p, f"output_{i}.png")
print(f"{'✅' if success else '❌'} {p}")
Kelebihan: Tanpa biaya, cocok untuk permintaan dalam jumlah kecil
Kekurangan: Lambat, batas keras RPD=1,500 tidak bisa dilewati
Solusi 2: Migrasi ke Vertex AI untuk Meningkatkan Kuota
Cocok untuk pengguna perusahaan yang sudah memiliki akun Google Cloud.
Langkah-langkah:
- Buat proyek GCP dan aktifkan Vertex AI API
- Atur akun layanan dan izin IAM
- Ajukan peningkatan RPM di Google Cloud Console → IAM → Quotas
- Ganti endpoint di kode dari AI Studio ke Vertex AI
Kelebihan: RPM meningkat dari 10 menjadi 60+, dapat digunakan untuk skenario perusahaan
Kekurangan: Konfigurasi kompleks, siklus persetujuan 1-3 hari, biaya sesuai tarif standar Google Cloud
Solusi 3: Rotasi Multi-Proyek
Dengan membuat beberapa proyek GCP atau kunci API AI Studio, permintaan dilakukan secara bergiliran untuk menghindari batas RPD/RPM dari satu proyek.
import itertools
api_keys = ["KUNCI_1", "KUNCI_2", "KUNCI_3", "KUNCI_4", "KUNCI_5"]
key_pool = itertools.cycle(api_keys)
def generate_with_rotation(prompt):
"""Membuat gambar dengan rotasi kunci"""
key = next(key_pool)
# ... Kirim permintaan menggunakan kunci saat ini
return send_request(prompt, api_key=key)
Kelebihan: Secara teori, N kunci dapat menghasilkan throughput N kali lipat
Kekurangan: Melanggar Ketentuan Layanan (TOS) Google, berisiko akun diblokir; mengelola banyak kunci menambah kompleksitas
Solusi 4: Menggunakan Platform Pihak Ketiga Tanpa Batas Konkurensi
Ini adalah solusi yang akhirnya saya gunakan. Setelah membandingkan beberapa platform pihak ketiga, saya memilih Wentuo API wentuo.ai, alasannya sederhana:
| Dimensi Perbandingan | AI Studio | Vertex AI | Wentuo API |
|---|---|---|---|
| Batas Konkurensi | RPM=10 | RPM=60 | Tidak terbatas |
| Batas Harian | 1,500/hari | Dibatasi RPM | Tidak terbatas |
| Harga per Gambar (termasuk 4K) | Gratis tapi terbatas | $0.067-$0.151 | $0.045 |
| Bayar sesuai pemakaian (1K) | – | $0.067 | Sekitar $0.025 |
| Tingkat Kerumitan Konfigurasi | Sederhana | Kompleks | Sederhana |
| Perlu VPN? | Ya | Ya | Tidak |
Dalam penggunaan nyata, biaya $0.045 per gambar sudah termasuk resolusi 4K. Jika bayar per token, harganya sekitar $0.02-$0.05, tergantung resolusi. Yang paling penting adalah tidak ada batas konkurensi, tugas batch dapat berjalan dengan kecepatan penuh, tidak lagi terhambat oleh kode 429.
Cara pemanggilannya juga sederhana, cukup ganti endpoint:
import requests
import base64
API_KEY = "kunci-api-wentuo-anda"
ENDPOINT = "https://api.wentuo.ai/v1beta/models/gemini-3.1-flash-image-preview:generateContent"
headers = {
"Content-Type": "application/json",
"x-goog-api-key": API_KEY
}
payload = {
"contents": [{"parts": [{"text": "Kucing lucu memakai helm luar angkasa"}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"imageConfig": {"aspectRatio": "1:1", "imageSize": "2K"}
}
}
response = requests.post(ENDPOINT, headers=headers, json=payload, timeout=120)
result = response.json()
image_data = result["candidates"][0]["content"]["parts"][0]["inlineData"]["data"]
with open("output.png", "wb") as f:
f.write(base64.b64decode(image_data))
💡 Saran penggunaan: Jika volume pembuatan harian kamu melebihi 500 gambar, atau membutuhkan kecepatan konkurensi, disarankan langsung menggunakan solusi tanpa batas konkurensi dari Wentuo API wentuo.ai. Biaya per penggunaan $0.045/gambar (resolusi tidak terbatas), biaya per token serendah $0.018/gambar (512px), menghemat 33%-70% dibandingkan Google resmi.
Rekomendasi 4 Opsi untuk Mengatasi Limit 429 pada Gemini 3.1 Flash Image Preview
Setiap skenario cocok dengan solusi yang berbeda:
| Skenario Penggunaan | Solusi yang Direkomendasikan | Alasan |
|---|---|---|
| 🎨 Pembelajaran/Percobaan Pribadi | Opsi 1 (Throttle & Retry) | Gratis, volume kecil tidak berpengaruh |
| 🏢 Perusahaan yang Sudah Punya GCP | Opsi 2 (Vertex AI) | Sesuai aturan, bisa mengajukan kuota tinggi |
| 🔬 Pengujian Volume Besar Sementara | Opsi 3 (Multi Key) | Bisa dipakai jangka pendek, perhatikan risiko |
| 🚀 Lingkungan Produksi/Generasi Massal | Opsi 4 (API Stabil) | Tidak ada batas konkurensi, biaya paling rendah |
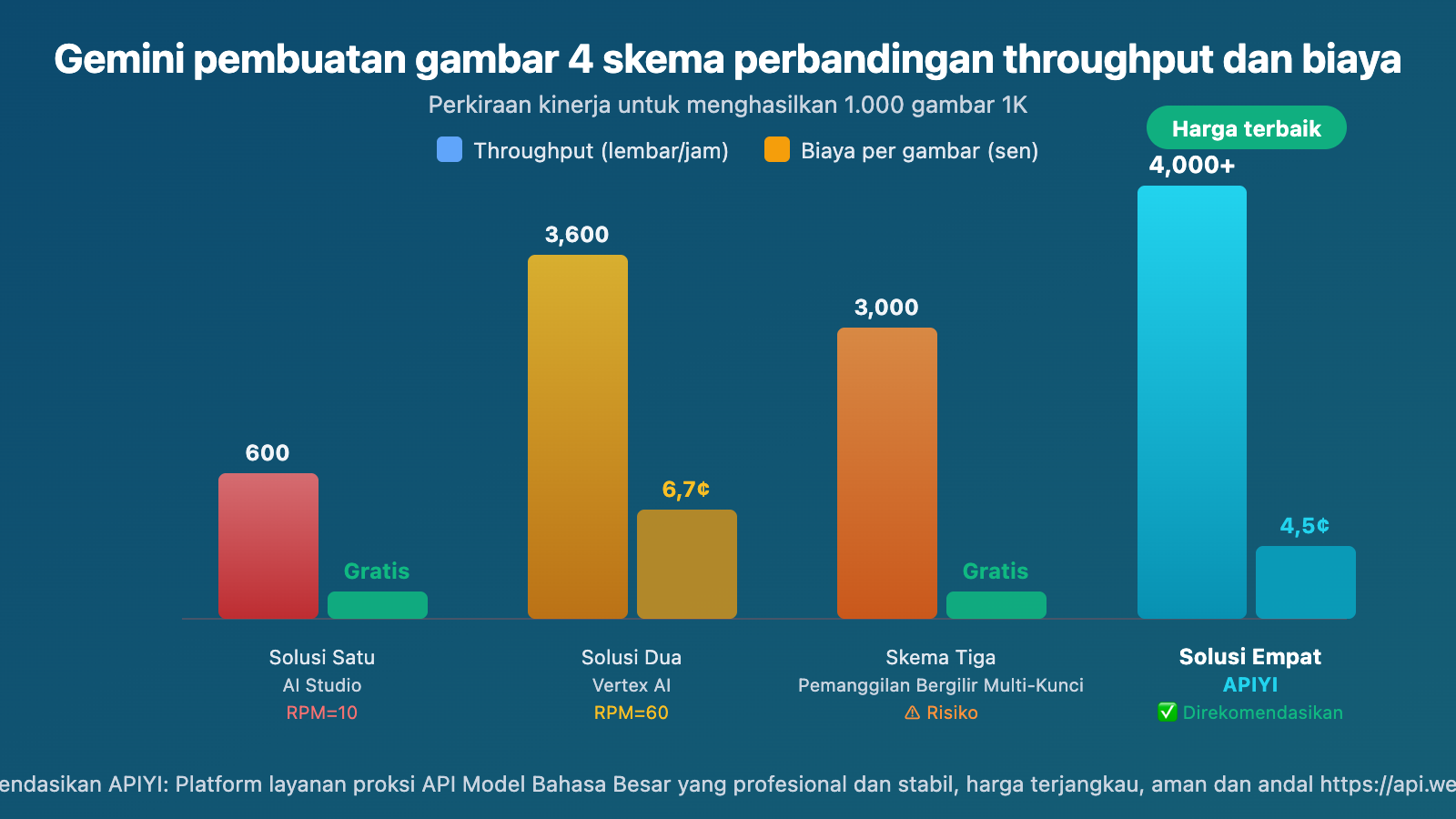
Perbandingan Throughput Berbagai Opsi Pembuatan Gambar Gemini
Asumsi: membuat 1.000 gambar resolusi 1K:
| Opsi | Perkiraan Waktu | Total Biaya | Kelayakan |
|---|---|---|---|
| AI Studio (RPM=10) | ~100 menit + Batas RPD mungkin perlu menunggu hari berikutnya | Gratis | ⚠️ Terkena batas RPD |
| Vertex AI (RPM=60) | ~17 menit | ~$67 | ✅ Perlu GCP |
| Polling Multi Key (5 Key) | ~20 menit | Gratis | ⚠️ Ada risiko akun diblokir |
| API Stabil (Tanpa batas konkurensi) | ~10-15 menit | $45 (per kali) / ~$25 (berdasarkan volume) | ✅ Direkomendasikan |
Tanya Jawab Umum
Q1: Setelah error 429, berapa lama Gemini 3.1 Flash Image Preview pulih?
Tergantung jenis limit yang terpicu:
- Limit RPM: Tunggu 1 menit, akan pulih otomatis.
- Limit RPD: Perlu menunggu hingga hari berikutnya (reset pada pukul 00:00 UTC).
- Limit TPM: Tunggu 1 menit, akan pulih.
Disarankan untuk memeriksa nilai quota_limit pada field details di kode untuk menentukan jenis limit spesifik dan mengambil strategi yang sesuai.
Q2: Apakah kualitas pembuatan gambar dari API Stabil sama dengan Google resmi?
Ya, API Stabil dari wentuo.ai langsung memanggil model Gemini 3.1 Flash Image Preview resmi dari Google, kualitas hasilnya sepenuhnya sama. Perbedaannya hanya pada:
- Menghilangkan batasan RPD/RPM
- Mendukung konkurensi tanpa batas
- Harga lebih murah ($0.045/gambar vs resmi $0.067/gambar@1K)
Q3: Bagaimana memilih antara pembayaran per kali dan berdasarkan volume?
Logika pemilihan sederhana:
- Selalu pakai resolusi 2K/4K → Pilih pembayaran per kali ($0.045/kali, paling hemat tanpa batas resolusi)
- Utamanya pakai 512px/1K → Pilih pembayaran berdasarkan volume (512px hanya $0.018/kali, hemat 60% dibanding per kali)
- Campuran resolusi → Hitung biaya rata-rata, biasanya pembayaran berdasarkan volume lebih hemat
API Stabil wentuo.ai mendukung kedua mode pembayaran dan bisa fleksibel berganti.
🎯 Ringkasan
Masalah pembatasan 429 pada Gemini 3.1 Flash Image Preview pada dasarnya adalah Google menetapkan batas kuota yang ketat (RPD/RPM) untuk AI Studio dan Vertex AI. Poin-poin utamanya:
- Pahami jenis pembatasan: 429 adalah batas kuota (masalah Anda), 503 adalah kelebihan beban server (masalah Google), solusinya sangat berbeda
- Evaluasi penggunaan Anda: Hingga 100 gambar per hari cukup dengan AI Studio, lebih dari 500 gambar disarankan untuk mempertimbangkan platform pihak ketiga
- Pilih solusi yang tepat: Untuk lingkungan produksi, disarankan menggunakan skema tanpa batas konkurensi untuk menghindari dampak pembatasan pada bisnis
- Perbandingan biaya sangat penting: Wentuo.ai API per panggilan $0.045/gambar (termasuk 4K), volume rendah hingga $0.018/gambar, menghemat 33%-70% dibandingkan resmi
Bagi pengembang yang perlu membuat gambar dalam jumlah besar, Wentuo.ai API (wentuo.ai) saat ini adalah pilihan terbaik untuk pengalaman menyeluruh—tanpa batas konkurensi, harga lebih rendah, tidak perlu VPN, antarmuka sepenuhnya kompatibel.
📚 Referensi
-
Dokumentasi resmi Google Gemini API: Penjelasan kuota dan pembatasan pembuatan gambar
- Tautan:
ai.google.dev/gemini-api/docs/image-generation - Penjelasan: Parameter kuota resmi dan praktik terbaik
- Tautan:
-
Manajemen kuota Google Cloud: Proses pengajuan kuota Vertex AI
- Tautan:
cloud.google.com/vertex-ai/docs/quotas - Penjelasan: Jalur resmi untuk pengguna perusahaan meningkatkan kuota
- Tautan:
-
Dokumentasi Wentuo.ai Nano Banana 2: Panduan integrasi pembuatan gambar tanpa batas konkurensi
- Tautan:
docs.wentuo.ai - Penjelasan: Penjelasan rinci dan contoh kode untuk dua skema penagihan (per panggilan/volume)
- Tautan:
📝 Tentang Penulis: Tim pembuat konten teknologi, fokus pada pembuatan gambar AI dan berbagi teknologi API. Untuk konten dan sumber daya teknologi lebih lanjut, kunjungi Wentuo.ai API (wentuo.ai) untuk informasi.
📋 Penjelasan Konten: Konten artikel ini disusun berdasarkan pengalaman penggunaan aktual, parameter pembatasan spesifik dapat berubah sesuai penyesuaian kebijakan Google. Jika memerlukan dukungan teknis, bantuan dapat diperoleh melalui Wentuo.ai API (wentuo.ai).