
著者注:Gemini 3.1 Flash Image Preview の画像生成における 429 レート制限問題の根本原因を詳細に分析し、AI Studio、Vertex AI、およびサードパーティプラットフォームの制限ポリシーを比較します。さらに、4つの実証済みの解決策を提供します。
Gemini 3.1 Flash Image Preview で画像を生成する際、最も厄介なのは生成品質ではなく、実行を開始した直後に 429 レート制限に阻まれることです。AI Studio でも Vertex AI でも、RPD(1日あたりのリクエスト数)と RPM(1分あたりのリクエスト数) の制限は非常に厳しく、バッチ生成はほぼ不可能です。
本記事では、実際の使用経験に基づき、429 レート制限の根本原因を詳細に分析し、異なるプラットフォーム間の制限ポリシーの違いを比較します。そして、4つの実証済みの解決策——並列処理無制限、1枚あたり $0.045 という低コストのプランを含む——を提供します。
核心的な価値:この記事を読み終えると、Gemini 画像生成の 429 エラーの根本的な仕組みを完全に理解し、あなたのシナリオに最適な解決策を見つけることができます。
Gemini 3.1 Flash Image Preview の 429 エラーとは
まず、このエラーがどのようなものか見てみましょう:
{
"error": {
"code": 429,
"message": "Resource has been exhausted (e.g. check quota).",
"status": "RESOURCE_EXHAUSTED",
"details": [
{
"reason": "RATE_LIMIT_EXCEEDED",
"metadata": {
"quota_limit": "GenerateContentRequestsPerDayPerProjectPerModel",
"quota_limit_value": "1500"
}
}
]
}
}
平易な言葉で説明すると:今日のリクエスト回数を使い切ったか、1分間のリクエストが頻繁すぎます。
503 エラーとは異なり、429 はサーバーが耐えられないわけではなく、Google があなたに設定したクォータ上限です。サーバーに空き計算能力があっても、制限に達すると直接拒否されます。
Gemini 画像生成における 429 エラーと 503 エラーの違い
| 比較項目 | 429 RESOURCE_EXHAUSTED | 503 UNAVAILABLE |
|---|---|---|
| 根本原因 | あなたのクォータが枯渇した | サーバーの計算能力不足 |
| トリガー条件 | RPD/RPM/TPM 制限を超えた | グローバルな高負荷 |
| 影響範囲 | あなたのプロジェクトのみ | すべてのユーザー |
| 待機で解決可能か | RPM は1分待機、RPD は翌日まで待機 | 通常数分から数時間 |
| 有料で解決可能か | Vertex AI でクォータを引き上げ可能 | 直接解決不可 |
| 根本的解決策 | プラットフォーム変更/クォータ引き上げ | 待機またはプラットフォーム変更 |
Gemini 3.1 Flash Image Preview 各プラットフォームのレート制限ポリシー比較
これが問題の核心です——異なるプラットフォーム間でレート制限の差は非常に大きいのです。
Gemini 画像生成 AI Studio のレート制限パラメータ
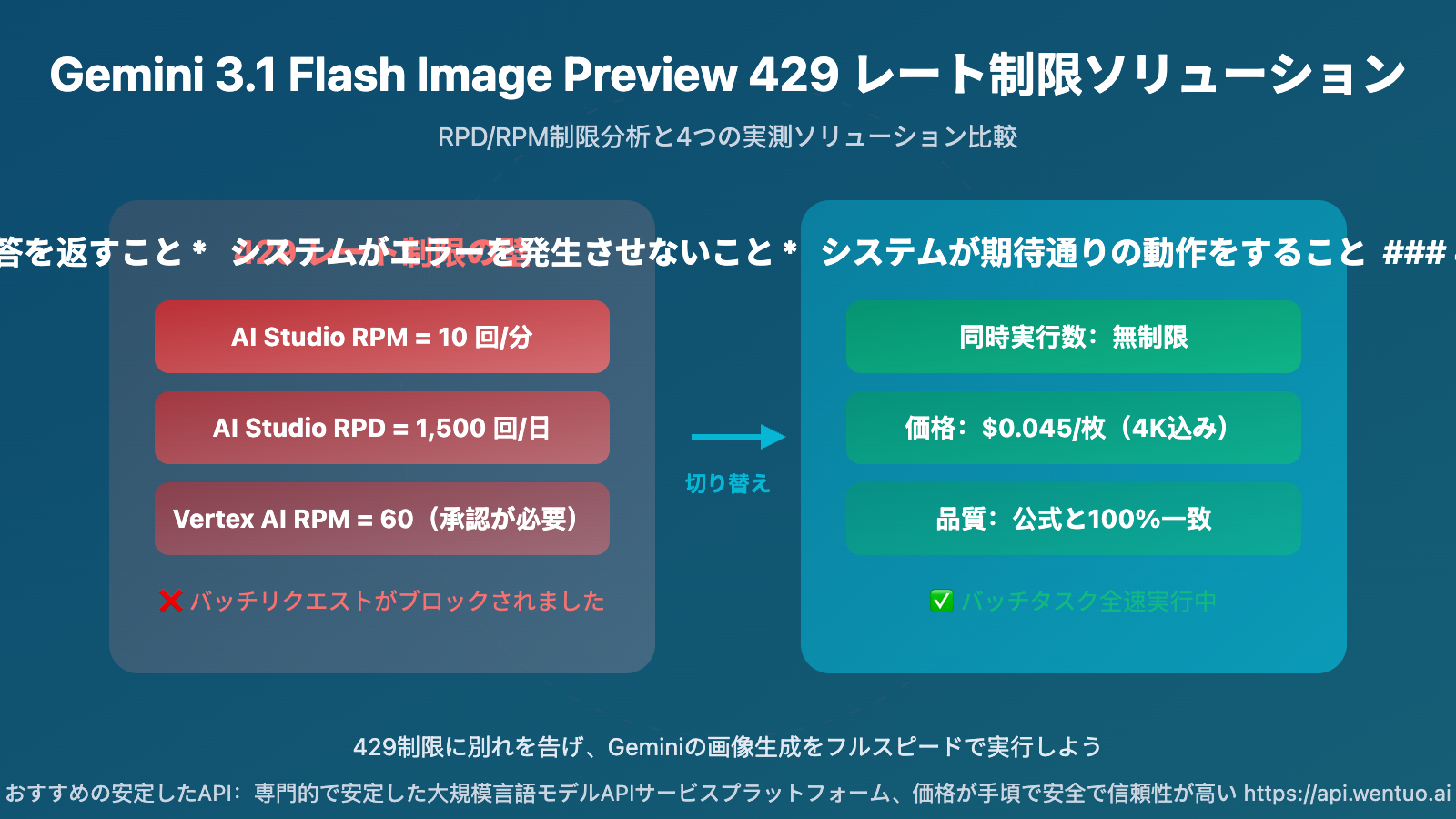
AI Studio は多くの開発者が最初に選ぶ、無料で使いやすい選択肢です。しかし、画像生成のレート制限は非常に厳格です:
| 制限の種類 | 制限値 | 換算 |
|---|---|---|
| RPM(1分あたりのリクエスト数) | 10 回 | 6秒に1回しかリクエストできません |
| RPD(1日あたりのリクエスト数) | 1,500 回 | 上限に達するまで約2.5時間 |
| TPM(1分あたりのトークン数) | 4,000,000 | 通常はボトルネックになりません |
| 画像出力 TPM | 12,000 トークン/分 | 約10枚/分 |
実際の体験:500枚の画像をバッチ生成する必要がある場合、RPM=10で計算すると、理論上の最短時間は50分です。しかし、ネットワーク遅延やリトライなどの要素を考慮すると、実際には1〜2時間かかります。1日に1,500枚を超える生成が必要な場合は、RPDの制限で完全に止まってしまいます。
Gemini 画像生成 Vertex AI のレート制限パラメータ
Vertex AI は Google Cloud のエンタープライズ向けソリューションで、割り当て量は多いですが、上限はあります:
| 制限の種類 | デフォルト値 | 申請による引き上げ |
|---|---|---|
| RPM | 60 回 | 可能(審査が必要) |
| RPD | 固定上限なし | ただしRPMとTPMに制約されます |
| TPM | 4,000,000 | 申請可能 |
| 画像出力 TPM | 24,000 トークン/分 | 申請可能 |
実際の体験:RPMが10から60に上がるので、かなり改善されたように見えますが、引き上げ申請にはGoogle Cloudのチケットプロセスが必要で、通常1〜3営業日かかります。また、Vertex AIの設定はAI Studioよりもはるかに複雑で(GCPプロジェクトの作成、サービスアカウントの設定、IAM権限の設定などが必要)、多くの個人開発者や小規模チームはあきらめてしまいます。
Gemini 画像生成 サードパーティプラットフォームのレート制限比較
| プラットフォーム | 同時実行制限 | RPD制限 | 単価(1K) | 備考 |
|---|---|---|---|---|
| AI Studio | RPM=10 | 1,500/日 | 無料(制限あり) | 最も厳しい |
| Vertex AI | RPM=60 | 固定上限なし | ~$0.067 | GCP設定が必要 |
| OpenRouter | プランによる | プランによる | ~$0.06-0.08 | 汎用プラットフォーム |
| APIYI | 同時実行制限なし | 制限なし | $0.045 | 従量課金、解像度制限なし |
Gemini 3.1 Flash Image Preview 429 レート制限を解決する4つの方法
方案一:Gemini 画像生成リクエストのスロットリング + 自動リトライ
最も基本的な方法で、プラットフォームを変更する必要はありませんが、効率は低いです。
import time
import random
import requests
def generate_with_retry(prompt, max_retries=5):
"""バックオフ付きリトライによる画像生成リクエスト"""
for attempt in range(max_retries):
try:
response = requests.post(endpoint, json=payload, headers=headers, timeout=120)
if response.status_code == 200:
return response.json()
elif response.status_code == 429:
# 指数バックオフ + ランダムジッター
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"429 レート制限、{wait_time:.1f}s 待機後リトライ ({attempt+1}/{max_retries})")
time.sleep(wait_time)
else:
response.raise_for_status()
except Exception as e:
print(f"リクエスト例外: {e}")
time.sleep(2)
raise Exception("最大リトライ回数を超えました")
完全なバッチ生成スクリプト(レート制御付き)を表示
import time
import random
import requests
import base64
from pathlib import Path
from concurrent.futures import ThreadPoolExecutor
class RateLimitedGenerator:
"""AI Studio RPM=10 制限を遵守するバッチジェネレーター"""
def __init__(self, api_key, rpm_limit=10):
self.api_key = api_key
self.interval = 60.0 / rpm_limit # リクエスト間の最小間隔
self.last_request_time = 0
self.endpoint = "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent"
def _wait_for_rate_limit(self):
elapsed = time.time() - self.last_request_time
if elapsed < self.interval:
time.sleep(self.interval - elapsed)
self.last_request_time = time.time()
def generate(self, prompt, output_path, retries=3):
for attempt in range(retries):
self._wait_for_rate_limit()
try:
response = requests.post(
f"{self.endpoint}?key={self.api_key}",
json={
"contents": [{"parts": [{"text": prompt}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"imageConfig": {"aspectRatio": "1:1", "imageSize": "1K"}
}
},
timeout=120
)
if response.status_code == 200:
data = response.json()
img = data["candidates"][0]["content"]["parts"][0]["inlineData"]["data"]
Path(output_path).write_bytes(base64.b64decode(img))
return True
elif response.status_code == 429:
wait = (2 ** attempt) + random.uniform(0, 2)
print(f"[429] {wait:.1f}s 待機中...")
time.sleep(wait)
except Exception as e:
print(f"例外: {e}")
time.sleep(2)
return False
# 使用例
gen = RateLimitedGenerator("YOUR_AISTUDIO_KEY", rpm_limit=10)
prompts = ["a sunset over mountains", "a cat in space", "futuristic city"]
for i, p in enumerate(prompts):
success = gen.generate(p, f"output_{i}.png")
print(f"{'✅' if success else '❌'} {p}")
メリット:コストゼロ、少量のリクエストに適しています
デメリット:速度が遅い、RPD=1,500の厳しい上限は突破できません
方案二:Gemini 画像生成を Vertex AI に移行して割り当て量を増やす
Google Cloud アカウントを持つ企業ユーザーに適しています。
操作手順:
- GCPプロジェクトを作成し、Vertex AI APIを有効化
- サービスアカウントとIAM権限を設定
- Google Cloud Console → IAM → Quotas でRPMの引き上げを申請
- コード内のエンドポイントをAI StudioからVertex AIに切り替え
メリット:RPMが10から60以上に向上、企業シナリオで使用可能
デメリット:設定が複雑、承認サイクルが1〜3日、Google Cloudの標準料金体系に従う
方案三:Gemini 画像生成のマルチプロジェクトローテーション
複数のGCPプロジェクトやAI Studio APIキーを作成し、リクエストを順番に送信することで、単一プロジェクトのRPD/RPM制限を回避します。
import itertools
api_keys = ["KEY_1", "KEY_2", "KEY_3", "KEY_4", "KEY_5"]
key_pool = itertools.cycle(api_keys)
def generate_with_rotation(prompt):
"""キーローテーションを使用して画像を生成"""
key = next(key_pool)
# ... 現在のキーを使用してリクエストを送信
return send_request(prompt, api_key=key)
メリット:理論上、N個のキーでN倍のスループットが得られます
デメリット:Googleのサービス利用規約(TOS)に違反し、アカウント停止のリスクがあります。複数のキー管理が複雑になります
方案四:Gemini 画像生成に同時実行制限なしのサードパーティプラットフォームを使用
これが私が最終的に採用した方法です。複数のサードパーティプラットフォームを比較した後、APIYI wentuo.aiを選択しました。理由は単純明快です:
| 比較項目 | AI Studio | Vertex AI | APIYI |
|---|---|---|---|
| 同時実行制限 | RPM=10 | RPM=60 | 制限なし |
| 日次制限 | 1,500回/日 | RPMに制約 | 制限なし |
| 単価(4K含む) | 無料(制限あり) | $0.067-$0.151 | $0.045 |
| 従量課金(1K) | – | $0.067 | 約$0.025 |
| 設定の複雑さ | 簡単 | 複雑 | 簡単 |
| VPNが必要か | はい | はい | いいえ |
実際に使用してみると、1回あたり$0.045(4K解像度を含む)の従量課金で、トークン単位の課金では解像度に応じて約$0.02〜$0.05です。最も重要なのは同時実行制限がないことで、バッチタスクを全速力で実行でき、429エラーで止まることはありません。
呼び出し方法も簡単で、エンドポイントを変更するだけです:
import requests
import base64
API_KEY = "your-wentuo-api-key"
ENDPOINT = "https://api.wentuo.ai/v1beta/models/gemini-3.1-flash-image-preview:generateContent"
headers = {
"Content-Type": "application/json",
"x-goog-api-key": API_KEY
}
payload = {
"contents": [{"parts": [{"text": "A cute cat wearing a space helmet"}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"imageConfig": {"aspectRatio": "1:1", "imageSize": "2K"}
}
}
response = requests.post(ENDPOINT, headers=headers, json=payload, timeout=120)
result = response.json()
image_data = result["candidates"][0]["content"]["parts"][0]["inlineData"]["data"]
with open("output.png", "wb") as f:
f.write(base64.b64decode(image_data))
💡 使用上のアドバイス:1日の生成量が500枚を超える場合、または同時実行速度に要件がある場合は、APIYI wentuo.aiの同時実行制限なしプランを直接使用することをお勧めします。従量課金は1枚あたり$0.045(解像度制限なし)、トークン単位の課金では$0.018/枚(512px)からで、Google公式よりも33%〜70%節約できます。
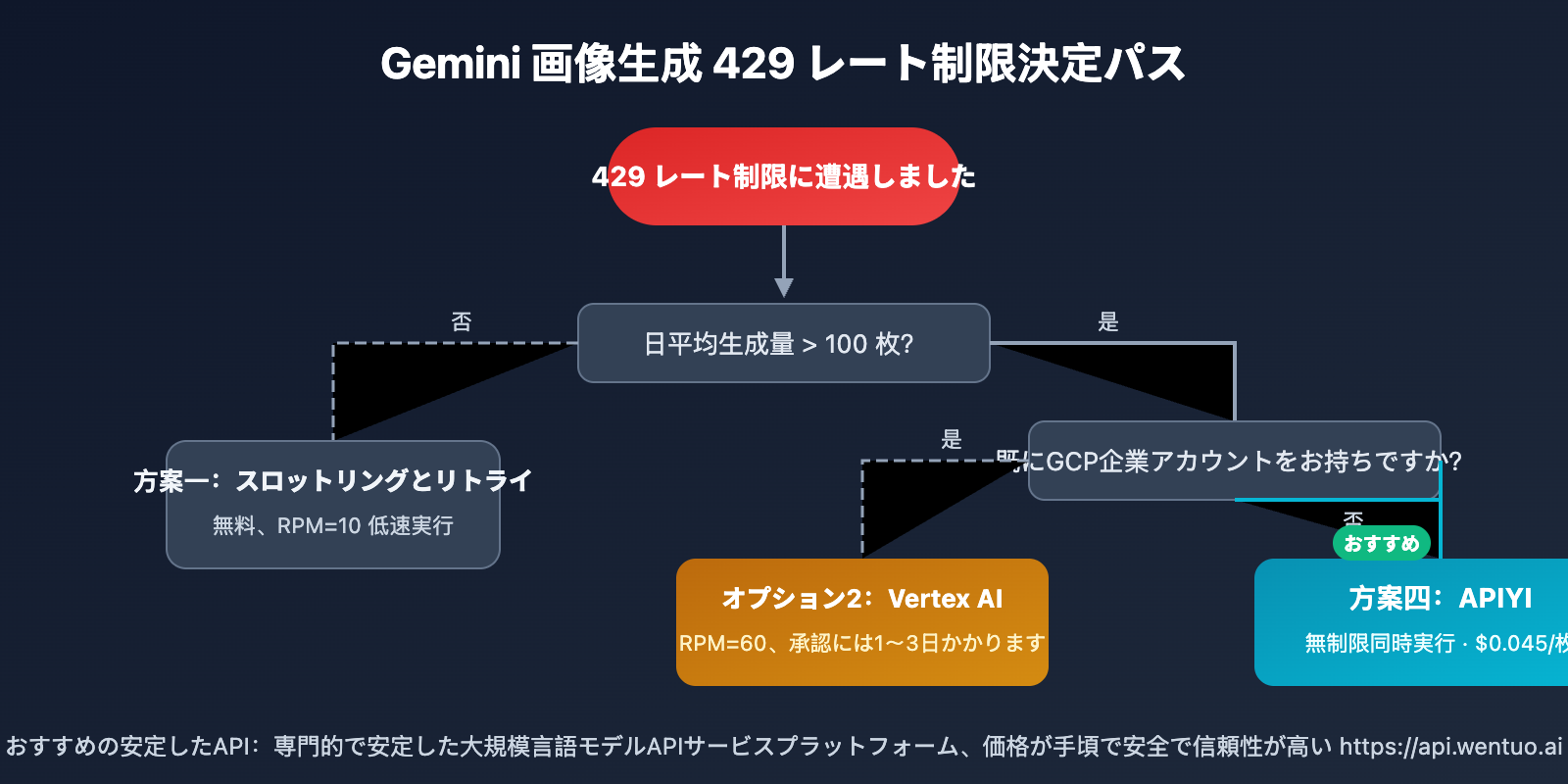
Gemini 3.1 Flash Image Preview 429 エラーの4つの解決策選択ガイド
異なるシナリオに適した異なる解決策:
| 使用シナリオ | 推奨解決策 | 理由 |
|---|---|---|
| 🎨 個人学習・体験 | 解決策1(スロットリング再試行) | 無料、少量なら影響なし |
| 🏢 企業が既にGCPを利用 | 解決策2(Vertex AI) | コンプライアンス対応、高クォータ申請可能 |
| 🔬 一時的な大量テスト | 解決策3(複数キー) | 短期利用可能、リスクに注意 |
| 🚀 本番環境/バッチ生成 | 解決策4(安定API) | 同時実行制限なし、コスト最安 |
Gemini 画像生成の異なる解決策のスループット比較
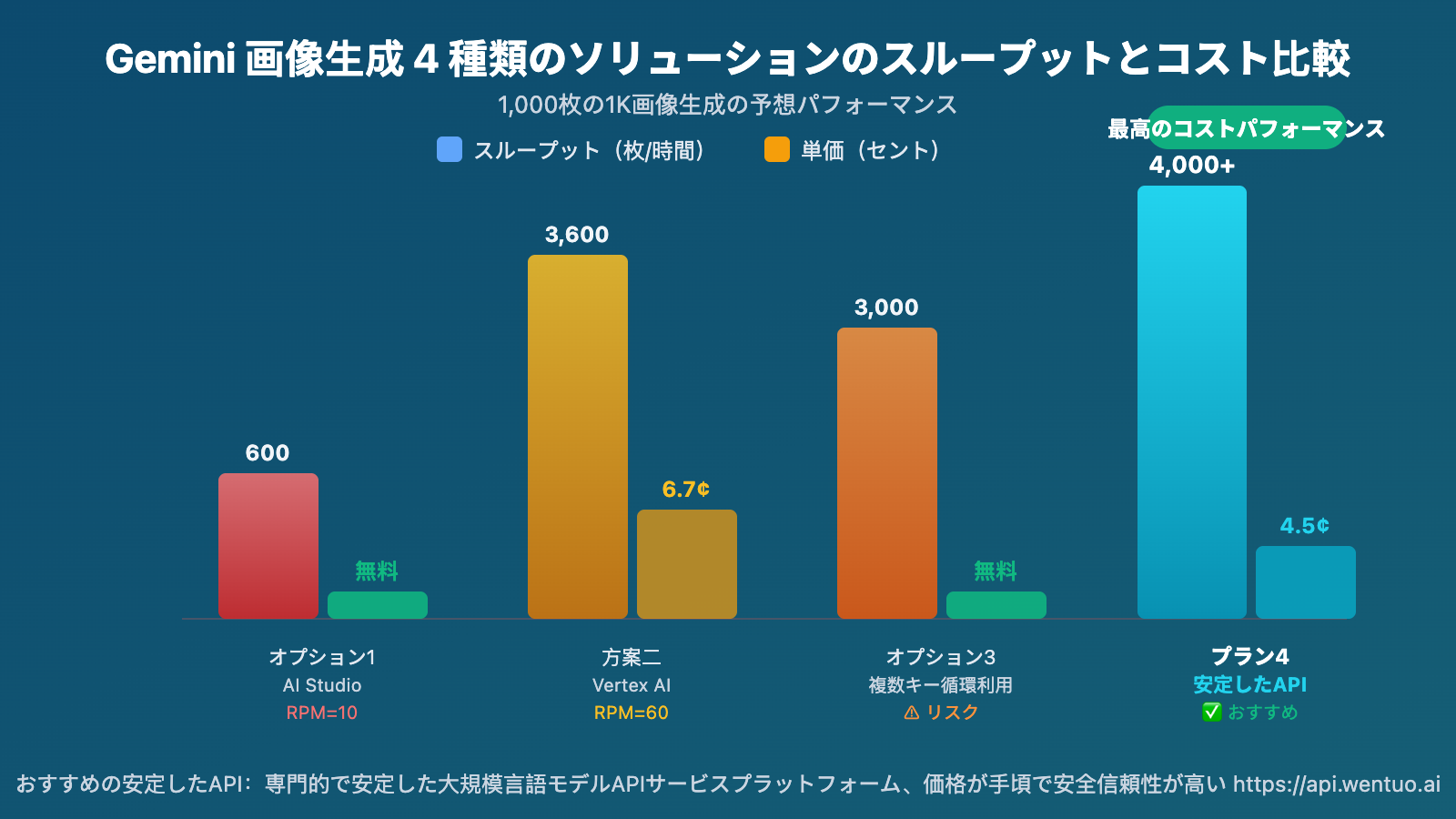
1,000枚の1K画像を生成すると仮定:
| 解決策 | 予想所要時間 | 総コスト | 実現可能性 |
|---|---|---|---|
| AI Studio(RPM=10) | ~100分 + RPD制限で翌日が必要な可能性あり | 無料 | ⚠️ RPD制限あり |
| Vertex AI(RPM=60) | ~17分 | ~$67 | ✅ GCPが必要 |
| 複数キーローテーション(5キー) | ~20分 | 無料 | ⚠️ アカウント停止リスクあり |
| 安定API(同時実行制限なし) | ~10-15分 | $45(従量制)/ ~$25(従量制) | ✅ 推奨 |
よくある質問
Q1: Gemini 3.1 Flash Image Preview 429 エラー発生後、どのくらいで回復しますか?
どのレート制限がトリガーされたかによります:
- RPM 制限:1分待機後に自動回復
- RPD 制限:翌日(UTC時間0時)のリセットを待つ必要あり
- TPM 制限:1分待機後に回復
コード内で details フィールドの quota_limit 値に基づいて具体的な制限タイプを判断し、対応する戦略を取ることをお勧めします。
Q2: 安定APIの画像生成品質はGoogle公式と同じですか?
はい、安定API(wentuo.ai)はGoogle公式のGemini 3.1 Flash Image Previewモデルを直接呼び出しており、生成品質は公式と完全に同一です。違いは以下のみです:
- RPD/RPM制限を撤廃
- 同時実行制限なしをサポート
- 価格がよりお得($0.045/枚 vs 公式 $0.067/枚@1K)
Q3: 従量制課金と従量制課金はどう選べばいいですか?
簡単な選択ロジック:
- 固定で2K/4K解像度を使用 → 従量制課金を選択($0.045/回、解像度無制限で最もお得)
- 主に512px/1Kを使用 → 従量制課金を選択(512pxはわずか$0.018/回、従量制より60%節約)
- 混合解像度 → 平均コストを計算、通常は従量制課金の方がお得
安定API(wentuo.ai)は2種類の課金方式の柔軟な切り替えをサポートしています。
🎯 まとめ
Gemini 3.1 Flash Image Preview の 429 レート制限問題は、本質的に Google が AI Studio と Vertex AI に設定した厳しいクォータ制限(RPD/RPM)に起因します。核心ポイントは以下の通りです:
- 制限タイプの理解:429 はクォータ制限(あなたの問題)、503 はサーバー過負荷(Google 側の問題)であり、解決策は全く異なります。
- 使用量の評価:1日あたり 100 枚以内なら AI Studio で十分、500 枚を超える場合はサードパーティプラットフォームの検討をお勧めします。
- 適切な解決策の選択:本番環境では、並列処理制限のないソリューションを使用し、レート制限によるビジネスへの影響を避けることをお勧めします。
- コスト比較が重要:Wentuo API は 1回あたり $0.045/枚(4K 画像を含む)、従量制では $0.018/枚まで低くなり、公式価格より 33%〜70% 節約できます。
バッチでの画像生成が必要な開発者にとって、Wentuo API (wentuo.ai) は現在、総合的な体験が最も優れた選択肢です——並列処理制限なし、低価格、VPN 不要、インターフェースは完全互換です。
📚 参考資料
-
Google Gemini API 公式ドキュメント: 画像生成のクォータとレート制限の説明
- リンク:
ai.google.dev/gemini-api/docs/image-generation - 説明: 公式のクォータパラメータとベストプラクティス
- リンク:
-
Google Cloud クォータ管理: Vertex AI のクォータ申請プロセス
- リンク:
cloud.google.com/vertex-ai/docs/quotas - 説明: 企業ユーザーがクォータを増やすための公式手順
- リンク:
-
Wentuo API Nano Banana 2 ドキュメント: 並列処理制限なしの画像生成接続ガイド
- リンク:
docs.wentuo.ai - 説明: 従量制/従量課金の 2 つの料金プランの詳細説明とコード例
- リンク:
📝 著者紹介:技術コンテンツ制作チーム。AI 画像生成と API 技術共有に特化。より多くの技術コンテンツとリソースは Wentuo API (wentuo.ai) でご覧いただけます。
📋 内容説明:本記事の内容は実際の使用経験に基づいてまとめられています。具体的なレート制限パラメータは Google のポリシー変更に伴い変動する可能性があります。技術サポートが必要な場合は、Wentuo API (wentuo.ai) を通じてサポートを入手できます。