
Note de l'auteur : Comparaison approfondie des capacités de programmation de GPT-5.4 et GPT-5.3 Codex, avec des données de 6 tests de référence comme SWE-Bench et Terminal-Bench, pour vous aider à choisir le modèle de programmation le plus adapté.
GPT-5.4 vient de sortir, et la première question de nombreux développeurs est : Ai-je encore besoin de GPT-5.3 Codex ? Après tout, GPT-5.4 se présente comme "le premier modèle unifié combinant programmation, raisonnement et contrôle informatique", tandis que GPT-5.3 Codex est le modèle phare d'OpenAI spécialement conçu pour la programmation.
Valeur essentielle : Cet article, à travers des données solides de 6 tests de référence, combinées à une comparaison complète des prix, du contexte et des scénarios d'utilisation, vous aide à faire le choix le plus clair.

Points clés des capacités de programmation : GPT-5.4 vs GPT-5.3 Codex
| Dimension de comparaison | GPT-5.4 | GPT-5.3 Codex | Gagnant |
|---|---|---|---|
| SWE-Bench Pro | 57.7% | 56.8% | GPT-5.4 |
| Terminal-Bench 2.0 | 75.1% | 77.3% | GPT-5.3 Codex |
| Toolathlon | 54.6% | 51.9% | GPT-5.4 |
| BrowseComp | 82.7% | 77.3% | GPT-5.4 |
| OSWorld | 75.0% | 74.0% | GPT-5.4 |
| Prix d'entrée | 2,50 $/M | 1,75 $/M | GPT-5.3 Codex |
Conclusion en une phrase de la comparaison de programmation GPT-5.4 vs GPT-5.3 Codex
GPT-5.4 est globalement en tête sur les tests de référence combinés, mais GPT-5.3 Codex reste plus performant et moins cher pour les tâches de programmation pure. Le choix dépend de votre scénario d'utilisation : uniquement écrire du code, ou un flux de travail mixte programmation + autres tâches.
La recommandation officielle d'OpenAI est également claire : pour la plupart des tâches, commencez par GPT-5.4 ; pour les tâches intensives de programmation pure, utilisez GPT-5.3 Codex.
SWE-Bench Pro : GPT-5.4 légèrement en tête
SWE-Bench Pro est une variante plus difficile et privée de référentiel de code, conçue spécifiquement pour résister à la contamination des données de benchmark. GPT-5.4 devance légèrement GPT-5.3 Codex avec 57,7 % contre 56,8 %, soit une avance d'environ 1 point de pourcentage.
Cet écart n'est pas énorme, mais si l'on considère que GPT-5.4 est un modèle généraliste et non spécialisé dans la programmation, le fait qu'il dépasse un modèle expert en programmation sur SWE-Bench Pro témoigne en soi de la profondeur d'intégration de ses capacités de codage.
Terminal-Bench 2.0 : GPT-5.3 Codex nettement en avance
Terminal-Bench 2.0 est un test exigeant qui évalue les capacités de programmation pure en terminal. GPT-5.3 Codex mène avec 77,3 % contre 75,1 %, soit une avance de 2,2 points de pourcentage – c'est le benchmark où GPT-5.3 Codex remporte sa victoire la plus nette.
Ce résultat est logique : GPT-5.3 Codex est optimisé spécifiquement pour la "programmation agentique" (Agentic Coding), ce qui lui confère un avantage naturel dans les scénarios verticaux comme la génération de code pur, l'auto-complétion de code et les opérations en terminal.
Toolathlon et BrowseComp : GPT-5.4 mène largement
Dans les tests impliquant l'appel d'outils (Toolathlon 54,6 % contre 51,9 %) et l'interaction avec le navigateur (BrowseComp 82,7 % contre 77,3 %), GPT-5.4 l'emporte largement. Cela reflète l'avantage de GPT-5.4 en termes de capacités d'agent globales "au-delà de la programmation" – appeler des outils, manipuler un navigateur, collaborer entre applications.

GPT-5.4 vs GPT-5.3 Codex : Comparaison des tarifs et spécifications pour la programmation
La différence de prix est un facteur central pour de nombreux développeurs. Voici une comparaison complète des spécifications des deux modèles :
| Dimension des spécifications | GPT-5.4 | GPT-5.3 Codex | Différence |
|---|---|---|---|
| Prix d'entrée | 2,50 $/M tokens | 1,75 $/M tokens | Codex 30 % moins cher |
| Prix de sortie | 15,00 $/M tokens | 14,00 $/M tokens | Codex 7 % moins cher |
| Cache d'entrée | 0,25 $/M tokens | Non communiqué | GPT-5.4 le supporte |
| Fenêtre de contexte | 1 050K tokens | 400K-1M tokens | GPT-5.4 plus grande |
| Sortie maximale | 128K tokens | Non explicitement communiqué | — |
| Computer Use | ✅ Support natif | ❌ Non supporté | Exclusif à GPT-5.4 |
| Tool Search | ✅ Économise 47 % de tokens | ❌ Non supporté | Exclusif à GPT-5.4 |
| Positionnement | Modèle phare généraliste | Spécialisé en programmation | Orientations différentes |
Calcul pratique du coût : GPT-5.4 vs GPT-5.3 Codex pour la programmation
Bien que GPT-5.3 Codex ait un prix unitaire inférieur, GPT-5.4 compense par deux facteurs :
- Moins de tokens de raisonnement : OpenAI indique officiellement que GPT-5.4 "résout les mêmes problèmes avec significativement moins de tokens de raisonnement", ce qui peut entraîner des coûts réels similaires, voire inférieurs.
- Tool Search économise 47 % : Pour les flux de travail d'agent qui appellent fréquemment des outils, la consommation de tokens de GPT-5.4 est considérablement réduite.
Conclusion : Si votre tâche est principalement de la génération de code pur ou de l'auto-complétion, GPT-5.3 Codex est moins cher. Si elle implique un flux de travail mixte programmation + appel d'outils + opérations navigateur, le coût réel de GPT-5.4 pourrait être plus avantageux.
Référence tarifaire : Les deux modèles peuvent être appelés via APIYI apiyi.com, avec des prix alignés sur les tarifs officiels. Inscription immédiate, recharge de 100 $ minimum avec un bonus de 10 %+ offert.
Différences de philosophie de conception entre GPT-5.4 et GPT-5.3 Codex
Comprendre l'intention de conception derrière chaque modèle est essentiel pour faire le bon choix.
GPT-5.3 Codex : Conçu pour la "programmation agentique"
Lors de sa sortie en février 2026, le positionnement d'OpenAI pour GPT-5.3 Codex était très clair : c'est un partenaire de programmation de niveau "stagiaire hautement productif". Ses caractéristiques principales :
- Exécution autonome de tâches d'ingénierie : Pas besoin de guidance pas à pas. Donnez-lui une tâche et il la mènera à bien de bout en bout.
- Boucle d'auto-correction : Écriture du code → exécution des tests → détection des erreurs → correction → re-test. L'ensemble de la boucle s'exécute automatiquement.
- Interruptible et réorientable : Vous pouvez l'interrompre à tout moment et ajuster la direction, sans perdre le contexte.
- 25% plus rapide que GPT-5.2 Codex : L'optimisation de la vitesse était l'un des arguments de vente principaux.
GPT-5.4 : L'unificateur programmation + raisonnement + contrôle
GPT-5.4 n'est pas une simple mise à niveau du modèle de programmation. C'est la tentative d'"unification" d'OpenAI – intégrer les capacités de programmation, le raisonnement profond, le contrôle informatique et l'expertise métier dans un seul modèle. Ses caractéristiques principales :
- Intègre les capacités de programmation de Codex : OpenAI a explicitement déclaré que GPT-5.4 "intègre les capacités de codage de pointe de GPT-5.3 Codex".
- Computer Use natif : Capable de contrôler directement l'interface d'un ordinateur, au-delà de la simple génération de code.
- Travaux d'expertise métier : GDPval 83.0%, taux de réussite de 87.3% sur les tâches de banque d'investissement.
- Simplification du choix de modèle : OpenAI souhaite que GPT-5.4 remplace plusieurs modèles spécialisés, réduisant ainsi la difficulté de choix.
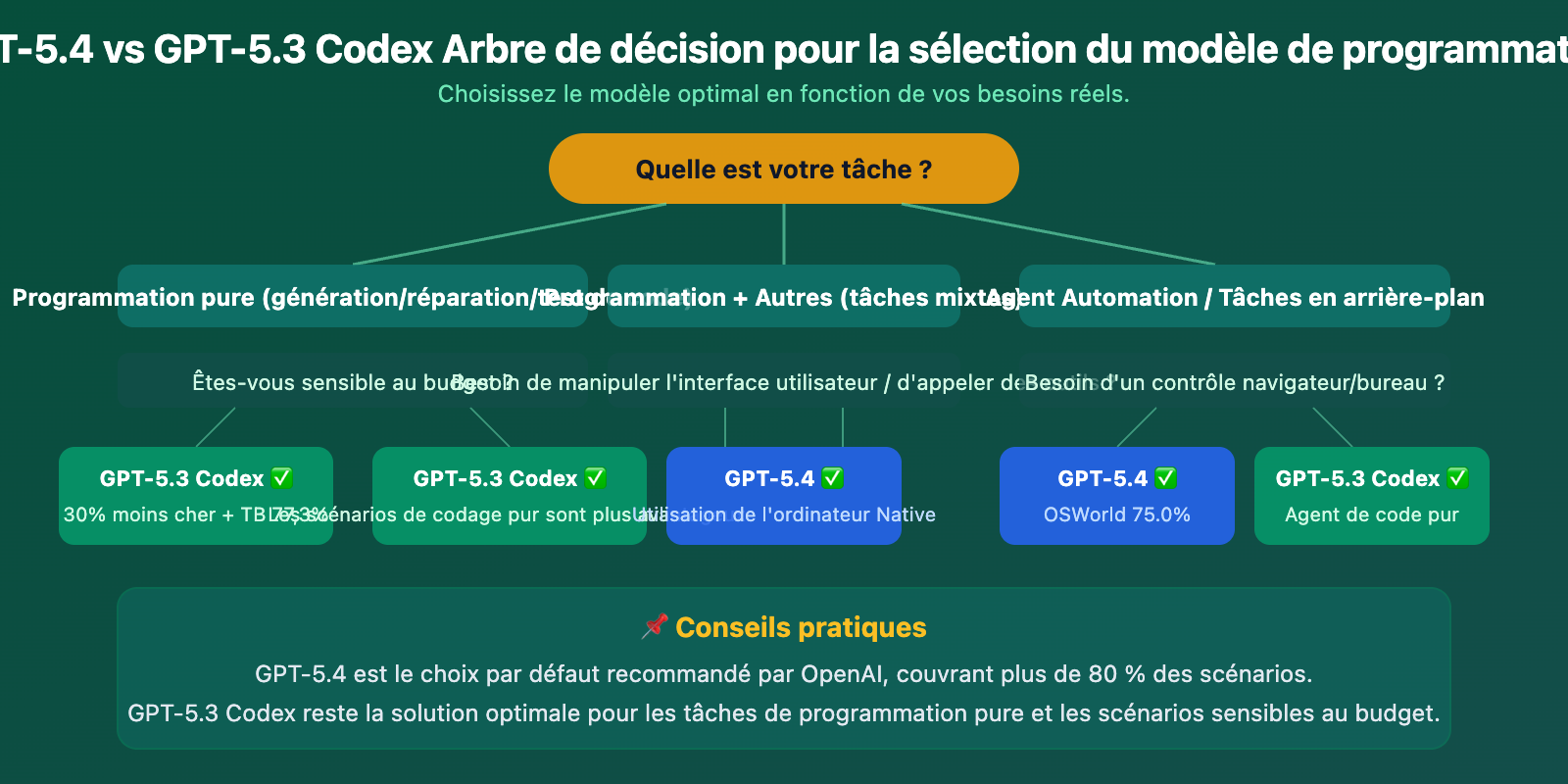
Guide de choix par scénario de programmation : GPT-5.4 vs GPT-5.3 Codex
La documentation officielle d'OpenAI fournit des recommandations claires pour le choix du modèle :
| Scénario d'utilisation | Modèle recommandé | Raison |
|---|---|---|
| La plupart des tâches Codex (par défaut) | GPT-5.4 | Capacités les plus complètes. Recommandation par défaut d'OpenAI. |
| Workflow mixte programmation + planification + rédaction | GPT-5.4 | Ses capacités interdisciplinaires dépassent largement celles de Codex. |
| Tâches purement intensives en programmation | GPT-5.3 Codex | Score Terminal-Bench de 77.3% plus élevé, optimisé spécifiquement pour le codage. |
| Programmation en binôme en temps réel | GPT-5.3 Codex Spark | Réponse ultra-rapide à 1000+ tokens/s (exclusif Pro). |
| Tâches de programmation sensibles au budget | GPT-5.3 Codex | Prix d'entrée 30% moins cher. |
| Analyse de grands dépôts de code | GPT-5.4 | Fenêtre de contexte maximale de 1.05M tokens. |
| Développement d'interface utilisateur front-end | GPT-5.4 | Retour de la communauté : code UI plus élégant et fonctionnellement plus complet. |
| Agent d'automatisation back-end | GPT-5.4 | Computer Use natif + Tool Search. |
Retours de la communauté des développeurs : GPT-5.4 vs GPT-5.3 Codex
Retours d'expérience concrets de la communauté des développeurs :
- Équipe Cursor (Lee Robinson) : "GPT-5.4 mène actuellement dans nos benchmarks internes. Les ingénieurs le trouvent plus naturel, plus décidé, il n'hésite pas face à des problèmes ambigus."
- Consensus des développeurs sur Reddit : GPT-5.3 Codex est plus fort pour les itérations rapides et les boucles d'implémentation ; pour la conception de systèmes complexes et la planification d'architecture, la tendance est de choisir d'autres modèles.
- Scénario de développement front-end : GPT-5.4 est considéré comme "clairement meilleur sur les tâches de codage front-end complexes, générant des résultats plus esthétiques et plus complets fonctionnellement".
GPT-5.4 vs GPT-5.3 Codex : Guide de démarrage rapide en programmation
Exemple minimaliste : Changer de modèle dans le Codex CLI
# Méthode 1 : Changement via la ligne de commande Codex CLI
# Utiliser GPT-5.4 (recommandé par défaut)
codex --model gpt-5.4 "Refactorise cette fonction en version asynchrone"
# Utiliser GPT-5.3 Codex (tâches de programmation pure)
codex --model gpt-5.3-codex "Corrige tous les échecs de tests unitaires"
# Méthode 2 : Comparaison des appels API
from openai import OpenAI
client = OpenAI(
api_key="VOTRE_CLÉ_API",
base_url="https://vip.apiyi.com/v1"
)
# GPT-5.4 : Adapté aux workflows mixtes
response = client.chat.completions.create(
model="gpt-5.4",
messages=[{"role": "user", "content": "Analyse ce code et génère des tests unitaires"}]
)
# GPT-5.3 Codex : Adapté aux tâches de programmation pure
response = client.chat.completions.create(
model="gpt-5.3-codex",
messages=[{"role": "user", "content": "Implémente un LRU Cache haute performance"}]
)
Conseil : Utilisez l'interface unifiée d'APIYI sur apiyi.com pour invoquer les deux modèles. Pas besoin de changer de clé API ou d'URL de base, ce qui facilite la comparaison des résultats dans des projets réels et le choix en fonction des besoins.
Questions fréquentes
Q1 : GPT-5.4 va-t-il complètement remplacer GPT-5.3 Codex ?
Non, il ne le remplacera pas complètement. La documentation officielle d'OpenAI liste toujours les deux comme modèles Codex disponibles. GPT-5.4 remplace GPT-5.3 Codex Spark en tant que "modèle par défaut recommandé", mais GPT-5.3 Codex conserve son avantage en termes de rapport qualité-prix pour les scénarios de programmation pure. Pour les tâches de codage pur sensibles au budget, GPT-5.3 Codex reste le meilleur choix.
Q2 : Comment changer entre ces deux modèles dans le Codex CLI ?
C'est très simple. Dans le Codex CLI, utilisez la commande /model pour basculer à chaud : tapez /model gpt-5.4 ou /model gpt-5.3-codex. Vous pouvez également définir le modèle par défaut dans ~/.codex/config.toml, ou le spécifier au démarrage avec le paramètre --model. La clé API d'APIYI sur apiyi.com fonctionne de la même manière.
Q3 : Comment tester rapidement la comparaison des performances de programmation des deux modèles ?
Étapes recommandées :
- Visitez APIYI sur apiyi.com pour créer un compte et obtenir une clé API unifiée.
- Préparez une tâche de programmation typique (par exemple, "implémenter un LRU Cache" ou "refactoriser une fonction asynchrone").
- Effectuez des appels avec
model="gpt-5.4"etmodel="gpt-5.3-codex"séparément. - Comparez la qualité du code généré, la vitesse et la consommation de tokens.
Résumé
Principales conclusions sur les capacités de programmation de GPT-5.4 vs GPT-5.3 Codex :
- GPT-5.4 est globalement plus performant : Il remporte 4 des 6 benchmarks (SWE-Bench Pro, Toolathlon, BrowseComp, OSWorld) et est le choix par défaut recommandé par OpenAI.
- GPT-5.3 Codex est plus spécialisé en programmation pure : Il mène de 2,2 points de pourcentage dans Terminal-Bench (77,3%) et reste optimal pour la génération de code pur et la programmation terminal.
- Écart de prix significatif : GPT-5.3 Codex est 30% moins cher en entrée (1,75 $ vs 2,50 $), ce qui représente un avantage majeur pour les scénarios sensibles au budget.
- Capacités exclusives de GPT-5.4 : Il possède des capacités natives de Computer Use et Tool Search (réduction de 47% des tokens) que GPT-5.3 Codex n'a pas.
En bref : La plupart des développeurs devraient utiliser GPT-5.4, tandis que GPT-5.3 Codex est idéal pour écrire du code pur tout en maîtrisant les coûts. Les deux modèles sont déjà disponibles sur APIYI apiyi.com, avec une interface unifiée pour basculer selon les besoins, et sont utilisables dès l'inscription.
📚 Références
-
Annonce de sortie d'OpenAI GPT-5.4 : Capacités principales et données de benchmark de GPT-5.4
- Lien :
openai.com/index/introducing-gpt-5-4/ - Description : Article de blog officiel, incluant les comparaisons de benchmarks comme SWE-Bench Pro et Terminal-Bench.
- Lien :
-
Annonce de sortie d'OpenAI GPT-5.3 Codex : Philosophie de conception du modèle de programmation par agent
- Lien :
openai.com/index/introducing-gpt-5-3-codex/ - Description : Explication du positionnement, des capacités et des cas d'utilisation de GPT-5.3 Codex.
- Lien :
-
Documentation des modèles OpenAI Codex : Guide officiel de sélection de modèle
- Lien :
developers.openai.com/codex/models/ - Description : Contient les recommandations officielles d'utilisation pour GPT-5.4 et GPT-5.3 Codex.
- Lien :
-
Page de tarification de l'API OpenAI : Informations de tarification actualisées des modèles
- Lien :
openai.com/api/pricing/ - Description : Comparaison des prix officiels entre GPT-5.4 et GPT-5.3 Codex.
- Lien :
Auteur : Équipe technique APIYI
Échanges techniques : N'hésitez pas à discuter de votre expérience avec GPT-5.4 et GPT-5.3 Codex dans les commentaires. Pour plus de ressources, visitez le centre de documentation APIYI à docs.apiyi.com.