
Note de l'auteur : Comparaison approfondie entre Gemini 3.1 Pro et Claude Opus 4.6 sur 13 dimensions (raisonnement, codage, multimodalité, prix, etc.), avec conseils de sélection par scénario et guide d'accès API.
En février 2026, le paysage concurrentiel des grands modèles de langage a connu une véritable « fracture » : plus aucun modèle ne domine outrageusement les autres. Le Gemini 3.1 Pro de Google, lancé le 19 février, a établi des records en matière de raisonnement et de multimodalité, tandis que le Claude Opus 4.6 d'Anthropic, sorti le 5 février, conserve son avance sur les tâches de niveau expert et l'appel d'outils (tool calling).
Valeur ajoutée : À la fin de cet article, vous saurez précisément dans quels scénarios chacun de ces modèles d'élite excelle et lequel choisir selon vos besoins spécifiques.

Comparaison des paramètres clés : Gemini 3.1 Pro vs Claude Opus 4.6
Commençons par les spécifications matérielles. Ces deux modèles représentent le summum actuel de l'IA, mais leurs philosophies de conception divergent nettement.
| Paramètre | Gemini 3.1 Pro | Claude Opus 4.6 | Remarques |
|---|---|---|---|
| Date de sortie | 19 février 2026 | 5 février 2026 | Opus est sorti deux semaines plus tôt |
| Fenêtre de contexte | 1 million de tokens (standard) | 1 million de tokens (Bêta) | Support natif pour Gemini, Bêta pour Opus |
| Sortie maximale | 64K tokens | 128K tokens | ✅ Opus double la mise |
| Modalités d'entrée | Texte, image, audio, vidéo, PDF | Texte, image, PDF | ✅ Gemini est plus complet |
| Traitement vidéo | Jusqu'à 1h de vidéo | ❌ Non supporté | Exclusivité Gemini |
| Traitement audio | Jusqu'à 8,4h d'audio | ❌ Non supporté | Exclusivité Gemini |
| Mode de raisonnement | 3 niveaux (Bas/Moyen/Haut) | Raisonnement adaptatif (dynamique) | Approches différentes |
| Prix (Entrée) | 2 $ / M tokens | 5 $ / M tokens | ✅ Gemini est 2,5x moins cher |
| Prix (Sortie) | 12 $ / M tokens | 25 $ / M tokens | ✅ Gemini est environ 2x moins cher |
🎯 Côté spécifications : Gemini 3.1 Pro prend une avance nette sur le multimodal et le prix, tandis que Claude Opus 4.6 domine sur la longueur de sortie (128K vs 64K). Cependant, les chiffres ne disent pas tout ; la vraie différence se cache dans les benchmarks.
Comparaison approfondie des benchmarks : Gemini 3.1 Pro vs Opus 4.6
C'est le cœur de cet article. Nous comparons point par point les performances selon quatre dimensions : le raisonnement, le codage, les capacités d'Agent et le travail intellectuel.
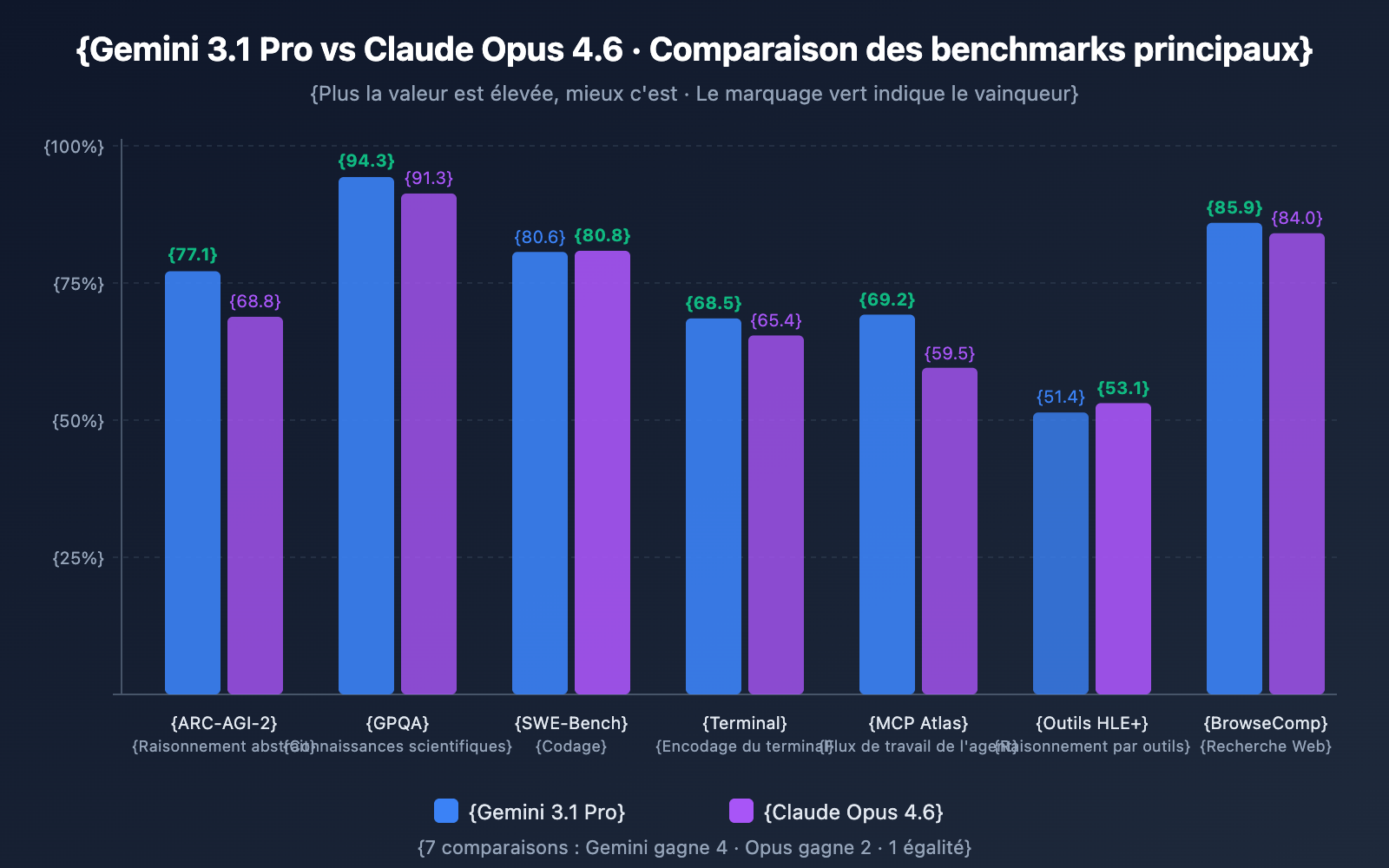
Comparaison des capacités de raisonnement
| Test de raisonnement | Gemini 3.1 Pro | Claude Opus 4.6 | Vainqueur |
|---|---|---|---|
| ARC-AGI-2 (Raisonnement abstrait) | 77,1 % | 68,8 % | ✅ Gemini (+8,3 pts) |
| GPQA Diamond (Expertise scientifique) | 94,3 % | 91,3 % | ✅ Gemini (+3,0 pts) |
| HLE sans outils (Raisonnement ultime) | 44,4 % | 40,0 % | ✅ Gemini (+4,4 pts) |
| HLE avec outils (Raisonnement assisté) | 51,4 % | 53,1 % | ✅ Opus (+1,7 pt) |
Analyse : Gemini 3.1 Pro domine largement sur les tâches de raisonnement pur. Son score de 77,1 % sur ARC-AGI-2 est presque 2,5 fois supérieur à celui de la génération précédente, Gemini 3.0 Pro (31,1 %). Cependant, dès que l'utilisation d'outils est autorisée, Opus 4.6 reprend l'avantage, ce qui montre qu'Opus excelle à utiliser les outils comme une extension de sa propre réflexion.
Comparaison des capacités de codage
| Test de codage | Gemini 3.1 Pro | Claude Opus 4.6 | Vainqueur |
|---|---|---|---|
| SWE-Bench Verified | 80,6 % | 80,8 % | ✅ Opus (légère avance) |
| Terminal-Bench 2.0 | 68,5 % | 65,4 % | ✅ Gemini (+3,1 pts) |
Analyse : Dans le domaine du code, les deux modèles sont au coude à coude. Ils sont quasiment à égalité sur SWE-Bench Verified (seulement 0,2 % d'écart), mais Gemini 3.1 Pro prend l'avantage de 3,1 points sur Terminal-Bench 2.0 (codage en environnement terminal). À noter que le modèle GPT-5.3-Codex d'OpenAI les dépasse tous deux avec un score de 77,3 % sur Terminal-Bench.
Comparaison des capacités d'Agent et d'appel d'outils
| Test d'Agent | Gemini 3.1 Pro | Claude Opus 4.6 | Vainqueur |
|---|---|---|---|
| MCP Atlas (Flux multi-étapes) | 69,2 % | 59,5 % | ✅ Gemini (+9,7 pts) |
| BrowseComp (Navigation web) | 85,9 % | 84,0 % | ✅ Gemini (+1,9 pt) |
| tau2-bench Retail (Appel d'outils) | – | 91,9 % | Opus (données marquantes) |
| OSWorld (Contrôle d'OS) | – | 72,7 % | Opus (données marquantes) |
Analyse : Sur MCP Atlas (flux de travail d'Agent multi-étapes), Gemini 3.1 Pro mène de 9,7 points, un signal fort pour les développeurs utilisant le Model Context Protocol. De son côté, Opus 4.6 affiche des performances impressionnantes sur l'appel d'outils (tau2-bench) et le contrôle de système d'exploitation (OSWorld).
Comparaison des capacités de travail intellectuel
| Test de connaissances | Gemini 3.1 Pro | Claude Opus 4.6 | Vainqueur |
|---|---|---|---|
| GDPval-AA Elo | 1317 | 1606 | ✅ Opus (+289 pts) |
Analyse : Sur GDPval-AA (qui simule des tâches intellectuelles réelles de niveau expert), Opus 4.6 surclasse Gemini 3.1 Pro avec un score Elo de 1606 contre 1317. Cet écart de 289 points est comparable à la différence entre un joueur d'échecs professionnel et un amateur. Cela signifie que pour des scénarios à haute valeur ajoutée comme la recherche analytique, la rédaction de rapports ou l'analyse financière, Opus 4.6 possède un avantage qualitatif majeur.
D'après ces données, les scénarios d'utilisation de ces deux grands modèles de langage sont très clairs.

5 scénarios pour choisir Gemini 3.1 Pro
- Raisonnement complexe et mathématiques : Avec un score ARC-AGI-2 de 77,1 % (soit 8,3 points d'avance), son système de réflexion à trois niveaux vous permet d'ajuster la profondeur du raisonnement selon vos besoins.
- Traitement multimodal : Support natif de la vidéo (jusqu'à 1 heure) et de l'audio (8,4 heures). Si votre activité implique l'analyse vidéo ou la transcription vocale, Gemini est le seul choix viable.
- Workflows multi-étapes MCP : Avec 69,2 % sur MCP Atlas (9,7 points d'avance), Gemini est plus fiable si vous construisez des systèmes d'Agents basés sur le Model Context Protocol.
- Scénarios sensibles aux coûts : Avec un prix d'entrée de 2 $ contre 5 $ et de sortie de 12 $ contre 25 $, le coût de Gemini ne représente que 40 % à 48 % de celui d'Opus pour une qualité équivalente.
- Recherche scientifique et académique : Son score de 94,3 % sur GPQA Diamond en fait le plus performant pour répondre à des questions de connaissances scientifiques de niveau expert.
5 scénarios pour choisir Claude Opus 4.6
- Travail de connaissance de niveau expert : Son score GDPval-AA de 1606 Elo est largement en tête, ce qui le rend idéal pour les rapports de recherche, les analyses financières ou les documents juridiques de haute valeur.
- Génération de textes longs : Avec une capacité de sortie maximale de 128K tokens (contre 64K pour Gemini), Opus est plus approprié pour générer des documents complets ou de longs blocs de code.
- Raisonnement assisté par outils : Il affiche une excellente performance de 53,1 % sur le test HLE avec outils (1,7 point d'avance), excellant dans l'utilisation d'outils externes comme extension de sa chaîne de raisonnement.
- Appel d'outils précis : Avec 91,9 % sur tau2-bench Retail, il est plus stable dans les scénarios d'Agents nécessitant des appels de fonctions de haute précision (comme OpenClaw).
- Scénarios critiques pour la sécurité : La technologie d'alignement de sécurité d'Anthropic est la plus mature parmi les modèles de pointe, offrant un meilleur contrôle lors du traitement de contenus sensibles.
Intégration rapide des API Gemini 3.1 Pro et Opus 4.6
Exemple minimaliste
Via la plateforme APIYI, les deux modèles utilisent une interface unifiée, il suffit de changer le paramètre model :
import openai
client = openai.OpenAI(
api_key="VOTRE_CLÉ_API",
base_url="https://vip.apiyi.com/v1"
)
# Utilisation de Gemini 3.1 Pro (plus performant en raisonnement et multimodal)
response = client.chat.completions.create(
model="gemini-3.1-pro",
messages=[{"role": "user", "content": "Explique les principes physiques de l'intrication quantique"}]
)
print(response.choices[0].message.content)
Voir l’exemple d’appel pour Claude Opus 4.6 et le code de basculement multi-modèles
import openai
client = openai.OpenAI(
api_key="VOTRE_CLÉ_API",
base_url="https://vip.apiyi.com/v1"
)
# Utilisation de Claude Opus 4.6 (plus performant pour le travail de connaissance et l'appel d'outils)
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[{"role": "user", "content": "Rédige un rapport d'analyse sur le chiffre d'affaires du T1"}]
)
print(response.choices[0].message.content)
# Fonction d'encapsulation pour la sélection dynamique du modèle
def smart_call(prompt, task_type="general"):
model_map = {
"reasoning": "gemini-3.1-pro",
"multimodal": "gemini-3.1-pro",
"knowledge": "claude-opus-4-6",
"coding": "claude-opus-4-6",
"general": "gemini-3.1-pro", # Utilise le moins cher par défaut
}
return client.chat.completions.create(
model=model_map.get(task_type, "gemini-3.1-pro"),
messages=[{"role": "user", "content": prompt}]
)
Conseil : Via la plateforme APIYI (apiyi.com), vous pouvez accéder simultanément à Gemini 3.1 Pro et Claude Opus 4.6 en utilisant la même clé API selon vos besoins. La plateforme offre des crédits de test gratuits ; nous vous recommandons de comparer les résultats des deux modèles dans votre scénario réel avant de décider.
Analyse comparative des coûts : Gemini 3.1 Pro vs Opus 4.6
La différence de prix est un facteur déterminant pour de nombreux développeurs. Prenons l'exemple d'une consommation mensuelle moyenne de 10 millions de tokens en entrée + 2 millions de tokens en sortie :
| Poste de coût | Gemini 3.1 Pro | Claude Opus 4.6 | Différence |
|---|---|---|---|
| Coût d'entrée | 20 $ | 50 $ | Gemini économise 30 $ |
| Coût de sortie | 24 $ | 50 $ | Gemini économise 26 $ |
| Coût total mensuel | 44 $ | 100 $ | Gemini économise 56 % |
| Coût total annuel | 528 $ | 1 200 $ | Gemini économise 672 $ |
Si votre scénario repose principalement sur le raisonnement et le multimodal, Gemini 3.1 Pro peut vous faire économiser plus de la moitié des frais sans presque aucune perte de qualité. Cependant, si votre cœur de métier concerne le travail de connaissance de niveau expert (écart de 289 points sur GDPval-AA), l'amélioration de la qualité offerte par Opus 4.6 pour 56 $ de plus par mois en vaut la peine.
🎯 Conseil pour économiser : En passant par la plateforme APIYI (apiyi.com), vous bénéficiez de tarifs préférentiels. La stratégie recommandée est d'utiliser Gemini 3.1 Pro comme modèle par défaut pour les requêtes quotidiennes, et de basculer vers Opus 4.6 uniquement pour le travail de connaissance et les appels d'outils précis.
Questions fréquemment posées
Q1 : Quelle est la différence entre la « réflexion à trois niveaux » de Gemini 3.1 Pro et la « réflexion adaptative » d’Opus 4.6 ?
Gemini 3.1 Pro permet aux développeurs de régler manuellement trois niveaux d'inférence (Low/Medium/High), contrôlant ainsi la quantité de calcul allouée au raisonnement. Le niveau Medium est une nouveauté que Google appelle « réflexion profonde modérée ». La réflexion adaptative de Claude Opus 4.6, quant à elle, laisse le modèle juger automatiquement de la profondeur de raisonnement nécessaire, bien que les développeurs puissent intervenir manuellement via le paramètre effort. Les deux approches sont similaires dans l'esprit, mais diffèrent dans l'exécution : Gemini ressemble plus à une boîte manuelle, tandis qu'Opus s'apparente à une boîte automatique.
Q2 : Peut-on utiliser les deux modèles en même temps ?
Tout à fait. Il est recommandé de passer par la plateforme APIYI (apiyi.com) pour y accéder : une seule clé API suffit pour invoquer les deux modèles. Vous pouvez ensuite mettre en place un routage dynamique selon le type de tâche : envoyez le raisonnement pur et les tâches multimodales vers Gemini 3.1 Pro (moins cher), et confiez le travail de connaissance complexe ou les appels d'outils précis à Claude Opus 4.6 (plus performant). La fonction smart_call dans l'exemple de code de cet article illustre parfaitement ce mode de fonctionnement.
Q3 : Lequel choisir pour le codage ?
Les deux modèles sont presque à égalité sur le plan du code (l'écart sur SWE-Bench n'est que de 0,2 %). Si vous travaillez principalement dans un environnement terminal (scripts CI/CD, outils en ligne de commande), Gemini 3.1 Pro mène de 3,1 points sur Terminal-Bench. Si vous avez besoin de générer de longs fichiers de code (plus de 64K tokens), la capacité de sortie de 128K de Claude Opus 4.6 est plus adaptée. Pour les budgets limités, les capacités de codage de Gemini 3.1 Pro sont largement suffisantes et coûtent deux fois moins cher. Via APIYI (apiyi.com), vous pouvez tester et comparer les deux modèles à tout moment.
Conclusion
Voici les conclusions clés du comparatif entre Gemini 3.1 Pro et Claude Opus 4.6 :
- Choisissez Gemini 3.1 Pro pour le raisonnement et le multimodal : il mène de 8,3 points sur ARC-AGI-2, supporte nativement la vidéo et l'audio, et son prix ne représente que 40 % à 48 % de celui d'Opus.
- Choisissez Claude Opus 4.6 pour le travail de connaissance et l'appel d'outils : il devance son concurrent de 289 points sur GDPval-AA, atteint 91,9 % sur tau2-bench pour l'appel d'outils, et offre une sortie maximale de 128K.
- Égalité pour le codage : l'écart sur SWE-Bench est négligeable (0,2 %). Priorité à Gemini si le budget est un facteur déterminant.
En février 2026, le paysage des modèles d'IA est entré dans une ère où « chacun a ses points forts ». La meilleure stratégie n'est pas d'en choisir un seul, mais de les utiliser de manière hybride selon le contexte. Nous vous recommandons d'accéder aux deux modèles via APIYI (apiyi.com) pour basculer de l'un à l'autre selon vos besoins et obtenir le meilleur rapport qualité-prix.
📚 Ressources de référence
-
Blog officiel de Gemini 3.1 Pro : Annonce de lancement et détails techniques de Google
- Lien :
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - Description : Découvrez la présentation complète des fonctionnalités de Gemini 3.1 Pro et son système de réflexion à trois niveaux.
- Lien :
-
Annonce de lancement de Claude Opus 4.6 : Blog technique officiel d'Anthropic
- Lien :
anthropic.com/news/claude-opus-4-6 - Description : Consultez l'intégralité des données de benchmark d'Opus 4.6 et sa fonction de réflexion adaptative.
- Lien :
-
Comparaison de modèles par Artificial Analysis : Plateforme d'évaluation indépendante tierce
- Lien :
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-claude-opus-4-6-adaptive - Description : Données objectives de comparaison transversale sur les performances, la vitesse et le prix.
- Lien :
-
Documentation Google AI pour les développeurs : Tarification et guide d'intégration de l'API Gemini
- Lien :
ai.google.dev/gemini-api/docs/pricing - Description : Consultez les derniers tarifs de l'API Gemini 3.1 Pro et les quotas gratuits.
- Lien :
Auteur : Équipe technique
Échanges techniques : N'hésitez pas à partager votre expérience d'utilisation entre ces deux modèles dans l'espace commentaires. Pour plus d'actualités sur les grands modèles de langage, visitez APIYI sur apiyi.com