
Author's Note: An in-depth comparison of Gemini 3.1 Pro and Claude Opus 4.6 across 13 dimensions, including reasoning, coding, multimodality, and pricing. Includes scenario recommendations and an API access guide.
In February 2026, the AI model landscape hit a real "turning point"—no single model can completely crush the competition anymore. Google's Gemini 3.1 Pro, released on February 19, set new records in reasoning and multimodality, while Anthropic's Claude Opus 4.6, launched on February 5, continues to lead in expert-level tasks and tool use.
Core Value: By the end of this article, you'll have a clear understanding of what these two top-tier models are best at and which one fits your specific needs.
Core Parameter Comparison: Gemini 3.1 Pro vs. Claude Opus 4.6
Let's start with the hardware specs. Both models represent the current pinnacle of AI, but their design philosophies are worlds apart.
| Dimension | Gemini 3.1 Pro | Claude Opus 4.6 | Comparison Notes |
|---|---|---|---|
| Release Date | Feb 19, 2026 | Feb 5, 2026 | Opus released two weeks earlier |
| context window | 1M tokens (Standard) | 1M tokens (Beta) | Native support for Gemini; Opus requires Beta |
| Max Output | 64K tokens | 128K tokens | ✅ Opus is double |
| Input Modalities | Text, Image, Audio, Video, PDF | Text, Image, PDF | ✅ Gemini is more comprehensive |
| Video Processing | Up to 1 hour | ❌ Not supported | Gemini exclusive |
| Audio Processing | Up to 8.4 hours | ❌ Not supported | Gemini exclusive |
| Reasoning Mode | Three-level (Low/Medium/High) | Adaptive (Dynamic) | Different design philosophies |
| Input Price | $2/1M Tokens | $5/1M Tokens | ✅ Gemini is 2.5x cheaper |
| Output Price | $12/1M Tokens | $25/1M Tokens | ✅ Gemini is ~2x cheaper |
🎯 From a specs perspective: Gemini 3.1 Pro has a clear edge in multimodal capabilities and pricing, while Claude Opus 4.6 leads in output length (128K vs. 64K). But specs are just part of the story; the real gap shows up in the benchmarks.
Gemini 3.1 Pro vs. Opus 4.6: Deep Benchmark Comparison
This is the core of our analysis. We'll break down the performance of these two Large Language Models across four key dimensions: reasoning, coding, Agent capabilities, and knowledge work.
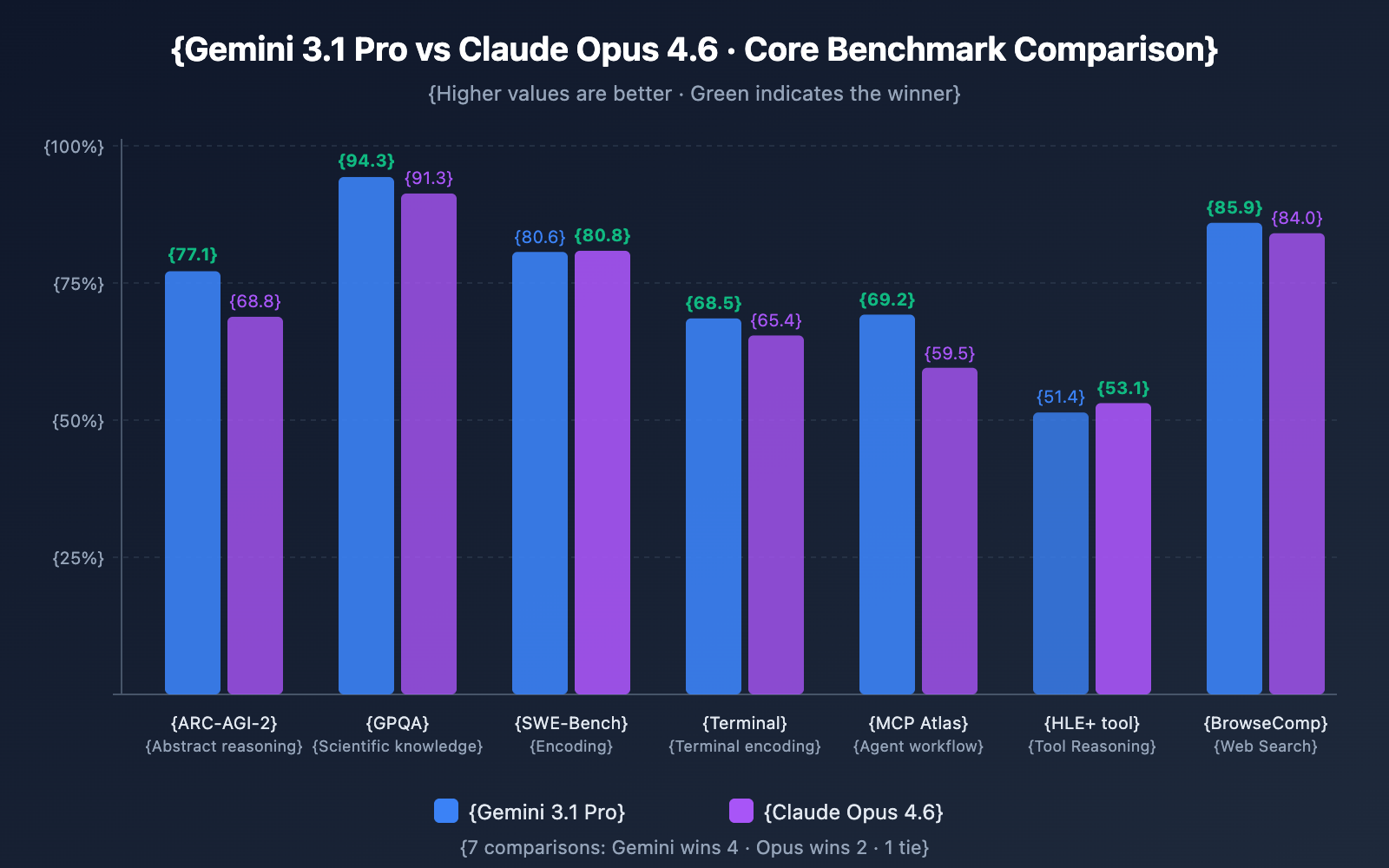
Reasoning Capabilities
| Reasoning Test | Gemini 3.1 Pro | Claude Opus 4.6 | Winner |
|---|---|---|---|
| ARC-AGI-2 (Abstract Reasoning) | 77.1% | 68.8% | ✅ Gemini (+8.3) |
| GPQA Diamond (Scientific Knowledge) | 94.3% | 91.3% | ✅ Gemini (+3.0) |
| HLE No Tools (Ultimate Reasoning) | 44.4% | 40.0% | ✅ Gemini (+4.4) |
| HLE With Tools (Tool-Assisted) | 51.4% | 53.1% | ✅ Opus (+1.7) |
Analysis: Gemini 3.1 Pro takes a clear lead in pure reasoning tasks. Its ARC-AGI-2 score of 77.1% is particularly impressive—nearly 2.5x higher than its predecessor, Gemini 3.0 Pro (31.1%). However, when tools are introduced, Opus 4.6 manages to pull ahead, suggesting it's slightly better at using external tools as an extension of its reasoning process.
Coding Capabilities
| Coding Test | Gemini 3.1 Pro | Claude Opus 4.6 | Winner |
|---|---|---|---|
| SWE-Bench Verified | 80.6% | 80.8% | ✅ Opus (Slight lead) |
| Terminal-Bench 2.0 | 68.5% | 65.4% | ✅ Gemini (+3.1) |
Analysis: It's a dead heat in the coding arena. They're virtually tied on SWE-Bench Verified (only a 0.2% difference), but Gemini 3.1 Pro shows a 3.1-point advantage in Terminal-Bench 2.0 (coding within a terminal environment). It's worth noting that OpenAI's GPT-5.3-Codex still leads both with a 77.3% score on Terminal-Bench.
Agent and Tool Invocation
| Agent Test | Gemini 3.1 Pro | Claude Opus 4.6 | Winner |
|---|---|---|---|
| MCP Atlas (Multi-step Workflows) | 69.2% | 59.5% | ✅ Gemini (+9.7) |
| BrowseComp (Web Search) | 85.9% | 84.0% | ✅ Gemini (+1.9) |
| tau2-bench Retail (Tool Calling) | – | 91.9% | Opus excels here |
| OSWorld (OS Control) | – | 72.7% | Opus excels here |
Analysis: Gemini 3.1 Pro dominates MCP Atlas (multi-step Agent workflows) by a significant 9.7 points—a major signal for developers using the Model Context Protocol. On the other hand, Opus 4.6 shows superior performance in specific tool-calling scenarios like tau2-bench and operating system control via OSWorld.
Knowledge Work Capabilities
| Knowledge Test | Gemini 3.1 Pro | Claude Opus 4.6 | Winner |
|---|---|---|---|
| GDPval-AA Elo | 1317 | 1606 | ✅ Opus (+289) |
Analysis: This is where Opus 4.6 really shines. In GDPval-AA (which simulates real-world, expert-level knowledge work), Opus 4.6 holds a massive lead with 1606 Elo compared to Gemini 3.1 Pro's 1317. A 289-point gap is the difference between a pro and an amateur. This suggests that for high-value knowledge work like research analysis, report writing, and financial modeling, Opus 4.6 has a qualitative edge.
Gemini 3.1 Pro vs. Opus 4.6: Which One Should You Choose?
Based on the data above, the ideal use cases for these two models are quite clear.

5 Scenarios to Choose Gemini 3.1 Pro
- Complex Reasoning and Math: With an ARC-AGI-2 score of 77.1% (an 8.3-point lead), its three-tier thinking system lets you adjust reasoning depth on demand.
- Multimodal Processing: Native support for video (up to 1 hour) and audio (up to 8.4 hours). If your workflow involves video analysis or speech transcription, Gemini is the only way to go.
- MCP Multi-step Workflows: Scoring 69.2% on MCP Atlas (a 9.7-point lead), Gemini is more reliable if you're building Agent systems based on the Model Context Protocol.
- Cost-Sensitive Projects: With input prices at $2 vs $5 and output at $12 vs $25, Gemini costs only 40%-48% of Opus for comparable quality.
- Scientific and Academic Research: GPQA Diamond score of 94.3% makes it the top performer for expert-level scientific Q&A.
5 Scenarios to Choose Claude Opus 4.6
- Expert-Level Knowledge Work: Its GDPval-AA 1606 Elo is miles ahead, making it perfect for high-value outputs like research reports, financial analysis, and legal documents.
- Long-Form Text Generation: With a maximum output of 128K tokens (compared to Gemini's 64K), Opus is better suited for generating entire documents or extensive codebases.
- Tool-Augmented Reasoning: Scoring 53.1% on HLE with tools (a 1.7-point lead), it excels at using external tools as an extension of its reasoning chain.
- Precise Tool Calling: A tau2-bench Retail score of 91.9% ensures more stability in Agent scenarios (like OpenClaw) that require high-precision function calling.
- Safety-Critical Scenarios: Anthropic's safety alignment technology is the most mature among frontier models, offering better control when handling sensitive content.
Quick API Integration for Gemini 3.1 Pro and Opus 4.6
Minimalist Example
Through the APIYI platform, both models use a unified interface—you just need to switch the model parameter:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Use Gemini 3.1 Pro (stronger reasoning and multimodal capabilities)
response = client.chat.completions.create(
model="gemini-3.1-pro",
messages=[{"role": "user", "content": "Explain the physical principles of quantum entanglement"}]
)
print(response.choices[0].message.content)
View Claude Opus 4.6 invocation example and multi-model switching code
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Use Claude Opus 4.6 (stronger knowledge work and tool calling)
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[{"role": "user", "content": "Write an analysis report on Q1 revenue"}]
)
print(response.choices[0].message.content)
# Wrapper function for dynamic model selection
def smart_call(prompt, task_type="general"):
model_map = {
"reasoning": "gemini-3.1-pro",
"multimodal": "gemini-3.1-pro",
"knowledge": "claude-opus-4-6",
"coding": "claude-opus-4-6",
"general": "gemini-3.1-pro", # Default to the more affordable option
}
return client.chat.completions.create(
model=model_map.get(task_type, "gemini-3.1-pro"),
messages=[{"role": "user", "content": prompt}]
)
Pro Tip: You can access both Gemini 3.1 Pro and Claude Opus 4.6 through the APIYI (apiyi.com) platform using a single API key. The platform offers free test credits, so we recommend comparing both models in your specific use case before making a final decision.
Gemini 3.1 Pro vs. Opus 4.6 Cost Comparison Analysis
Price difference is a deciding factor for many developers when choosing a model. Taking a monthly average of 10 million input tokens + 2 million output tokens as an example:
| Cost Item | Gemini 3.1 Pro | Claude Opus 4.6 | Difference |
|---|---|---|---|
| Input Cost | $20 | $50 | Gemini saves $30 |
| Output Cost | $24 | $50 | Gemini saves $26 |
| Total Monthly Cost | $44 | $100 | Gemini saves 56% |
| Total Yearly Cost | $528 | $1,200 | Gemini saves $672 |
If your use case is primarily reasoning and multimodal-focused, Gemini 3.1 Pro can save you more than half the cost with almost no loss in quality. However, if your core scenario involves expert-level knowledge work (where there's a 289-point gap in GDPval-AA), the quality boost you get for an extra $56 a month with Opus 4.6 is well worth it.
🎯 Money-saving Tip: Accessing through the APIYI apiyi.com platform offers discounted pricing. A recommended strategy is to use Gemini 3.1 Pro as your default model for handling daily requests, and only switch to Opus 4.6 for knowledge-intensive work and precise tool-calling scenarios.
FAQ
Q1: What’s the difference between Gemini 3.1 Pro’s “Three-level Thinking” and Opus 4.6’s “Adaptive Thinking”?
Gemini 3.1 Pro allows developers to manually set three reasoning levels—Low, Medium, and High—to control the amount of compute the model invests in reasoning. The Medium level is a new addition that Google calls "moderate deep thinking." Claude Opus 4.6's adaptive thinking, on the other hand, lets the model automatically determine the reasoning depth needed for a task, though developers can also manually intervene using the effort parameter. The concepts are similar, but the implementation differs—Gemini is more like a manual transmission, while Opus is more like an automatic.
Q2: Can I use both models at the same time?
Yes, you can. We recommend connecting through the APIYI apiyi.com platform, where a single API key lets you call both models. You can implement dynamic routing based on the task type: send reasoning and multimodal tasks to Gemini 3.1 Pro (cheaper) and route knowledge work or precise tool calls to Claude Opus 4.6 (more powerful). The smart_call function in the code examples earlier demonstrates this pattern.
Q3: Which one should I choose for coding scenarios?
Both models are nearly neck-and-neck in coding (with only a 0.2% difference on SWE-Bench). If you're mainly coding in a terminal environment (like CI/CD scripts or CLI tools), Gemini 3.1 Pro leads by 3.1 points on Terminal-Bench. If you need to generate long code files (over 64K tokens), Claude Opus 4.6's 128K output limit is a better fit. If you're on a tight budget, Gemini 3.1 Pro's coding capabilities are more than sufficient and cost half as much. You can test and compare both models anytime via APIYI apiyi.com.
Summary
Key takeaways from the Gemini 3.1 Pro vs. Claude Opus 4.6 comparison:
- Choose Gemini 3.1 Pro for reasoning and multimodal tasks: It leads by 8.3 points on ARC-AGI-2, offers native video and audio support, and costs only 40%-48% of what you'd pay for Opus.
- Choose Claude Opus 4.6 for knowledge work and tool use: It leads by 289 points on GDPval-AA, hits 91.9% in tau2-bench tool use, and supports a massive 128K maximum output.
- Coding capabilities are a tie: The SWE-Bench gap is a mere 0.2%. If you're on a tight budget, Gemini is the clear winner here.
By February 2026, the Large Language Model landscape has entered an era where "everyone has their own strengths." The best strategy isn't to pick one over the other, but to use a hybrid approach based on your specific needs. We recommend using APIYI (apiyi.com) to access both models simultaneously, allowing you to switch on the fly to get the best quality-to-cost ratio.
📚 References
-
Gemini 3.1 Pro Official Blog: Google's announcement and technical details.
- Link:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - Description: Explore the full feature set and the three-tier reasoning system of Gemini 3.1 Pro.
- Link:
-
Claude Opus 4.6 Announcement: Anthropic's official technical blog.
- Link:
anthropic.com/news/claude-opus-4-6 - Description: Check out the full benchmark data and adaptive reasoning features of Opus 4.6.
- Link:
-
Artificial Analysis Model Comparison: Independent third-party evaluation platform.
- Link:
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-claude-opus-4-6-adaptive - Description: Objective side-by-side data on performance, speed, and pricing.
- Link:
-
Google AI Developer Documentation: Gemini API pricing and integration guide.
- Link:
ai.google.dev/gemini-api/docs/pricing - Description: View the latest API pricing and free tiers for Gemini 3.1 Pro.
- Link:
Author: Technical Team
Technical Discussion: Feel free to share your experiences with these two models in the comments. For more AI model news, visit APIYI (apiyi.com).