
Anmerkung des Autors: Ein tiefgehender Vergleich von Gemini 3.1 Pro und Claude Opus 4.6 in 13 Dimensionen – von Reasoning und Coding bis hin zu Multimodalität und Preis. Inklusive Empfehlungen zur Szenarienauswahl und einem API-Integrationsleitfaden.
Im Februar 2026 erlebte die Wettbewerbslandschaft der KI-Modelle eine echte „Zäsur“ – es gibt kein einzelnes Modell mehr, das alle anderen in jeder Hinsicht dominiert. Das am 19. Februar von Google veröffentlichte Gemini 3.1 Pro stellte Rekorde im Bereich Reasoning und Multimodalität auf, während das am 5. Februar von Anthropic veröffentlichte Claude Opus 4.6 bei Expertenaufgaben und Tool-Aufrufen (Tool Calling) weiterhin die Nase vorn hat.
Kernwert: Nach der Lektüre dieses Artikels werden Sie genau wissen, in welchen Szenarien diese beiden Top-Modelle jeweils glänzen und welches Sie basierend auf Ihren spezifischen Anforderungen wählen sollten.

Inferenzleistung im Vergleich
| Inferenztest | Gemini 3.1 Pro | Claude Opus 4.6 | Gewinner |
|---|---|---|---|
| ARC-AGI-2 (Abstrakte Inferenz) | 77,1 % | 68,8 % | ✅ Gemini (+8,3 Punkte) |
| GPQA Diamond (Wissenschaft) | 94,3 % | 91,3 % | ✅ Gemini (+3,0 Punkte) |
| HLE ohne Tools (Ultimative Inferenz) | 44,4 % | 40,0 % | ✅ Gemini (+4,4 Punkte) |
| HLE mit Tools (Werkzeuggestützte Inferenz) | 51,4 % | 53,1 % | ✅ Opus (+1,7 Punkte) |
Analyse: Gemini 3.1 Pro führt bei reinen Inferenzaufgaben deutlich, insbesondere bei ARC-AGI-2. Die 77,1 % sind fast das 2,5-fache des Vorgängers Gemini 3.0 Pro (31,1 %). Sobald jedoch Werkzeuge erlaubt sind, überholt Opus 4.6 – das deutet darauf hin, dass Opus besser darin ist, Tools als Erweiterung seines Denkprozesses zu nutzen.
Codier-Fähigkeiten im Vergleich
| Codiertest | Gemini 3.1 Pro | Claude Opus 4.6 | Gewinner |
|---|---|---|---|
| SWE-Bench Verified | 80,6 % | 80,8 % | ✅ Opus (hauchdünn) |
| Terminal-Bench 2.0 | 68,5 % | 65,4 % | ✅ Gemini (+3,1 Punkte) |
Analyse: Im Bereich Coding liefern sich beide ein Kopf-an-Kopf-Rennen. Bei SWE-Bench Verified herrscht fast Gleichstand (Differenz nur 0,2 %), aber Gemini 3.1 Pro liegt bei Terminal-Bench 2.0 (Codierung in Terminal-Umgebungen) mit 3,1 Punkten vorn. Bemerkenswert ist, dass OpenAIs GPT-5.3-Codex mit 77,3 % bei Terminal-Bench beide übertrifft.
Agent- und Tool-Nutzung im Vergleich
| Agent-Test | Gemini 3.1 Pro | Claude Opus 4.6 | Gewinner |
|---|---|---|---|
| MCP Atlas (Mehrstufige Workflows) | 69,2 % | 59,5 % | ✅ Gemini (+9,7 Punkte) |
| BrowseComp (Web-Suche) | 85,9 % | 84,0 % | ✅ Gemini (+1,9 Punkte) |
| tau2-bench Retail (Tool-Aufrufe) | – | 91,9 % | Opus (herausragend) |
| OSWorld (Betriebssystem-Steuerung) | – | 72,7 % | Opus (herausragend) |
Analyse: Bei MCP Atlas (mehrstufige Agent-Workflows) führt Gemini 3.1 Pro mit beachtlichen 9,7 Punkten Vorsprung – ein wichtiges Signal für Entwickler, die das Model Context Protocol nutzen. Opus 4.6 hingegen glänzt mit beeindruckenden Werten bei tau2-bench (Tool-Aufrufe) und OSWorld (Betriebssystem-Steuerung).
Wissensarbeit im Vergleich
| Wissenstest | Gemini 3.1 Pro | Claude Opus 4.6 | Gewinner |
|---|---|---|---|
| GDPval-AA Elo | 1317 | 1606 | ✅ Opus (+289 Punkte) |
Analyse: Bei GDPval-AA (Simulation realer Expertenaufgaben in der Wissensarbeit) liegt Opus 4.6 mit 1606 Elo massiv vor Gemini 3.1 Pro (1317 Punkte). Ein Unterschied von 289 Punkten entspricht etwa dem Abstand zwischen einem Profi und einem Amateur. Das bedeutet: In Szenarien wie Forschungsanalysen, dem Verfassen von Berichten oder Finanzanalysen bietet Opus 4.6 einen qualitativen Vorteil.
Empfehlungen zur Szenariowahl: Gemini 3.1 Pro vs. Opus 4.6
Basierend auf den obigen Daten sind die Einsatzszenarien für beide Modelle sehr klar definiert.
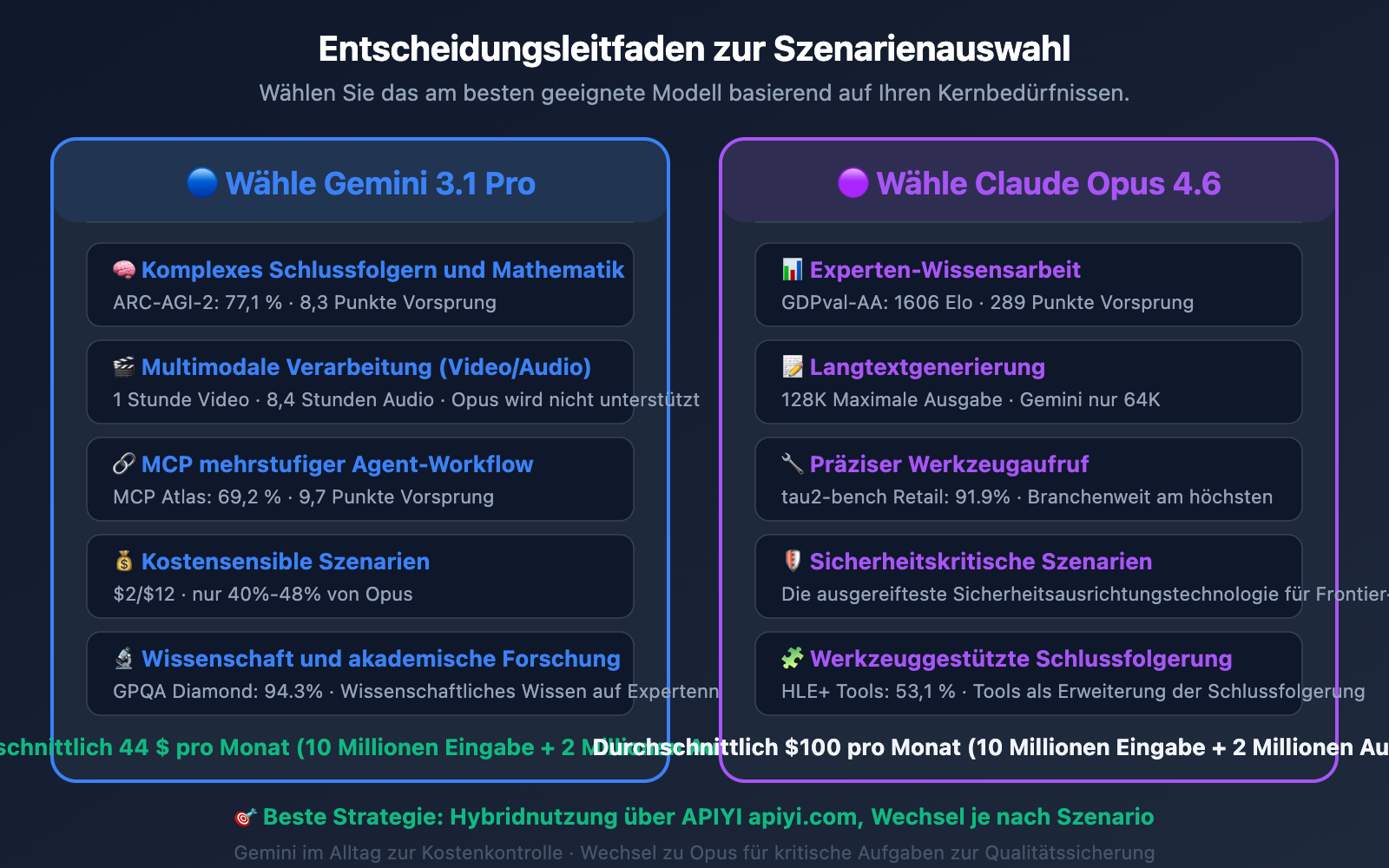
5 Szenarien für Gemini 3.1 Pro
- Komplexe Logik und Mathematik: Ein ARC-AGI-2 Score von 77,1 % (Vorsprung von 8,3 Punkten) und ein dreistufiges Denksystem ermöglichen es Ihnen, die Tiefe der Argumentation je nach Bedarf anzupassen.
- Multimodale Verarbeitung: Native Unterstützung für Video (1 Std.) und Audio (8,4 Std.). Wenn Ihr Geschäft Videoanalysen oder Transkriptionen umfasst, ist Gemini die einzige Wahl.
- MCP-Mehrschritt-Workflows: Mit einem MCP Atlas Score von 69,2 % (Vorsprung von 9,7 Punkten) ist Gemini zuverlässiger, wenn Sie Agent-Systeme auf Basis des Model Context Protocol entwickeln.
- Kostensensible Szenarien: Eingabepreis $2 vs. $5, Ausgabepreis $12 vs. $25. Bei vergleichbarer Qualität liegen die Kosten von Gemini bei nur 40-48 % von Opus.
- Wissenschaftliche und akademische Forschung: GPQA Diamond 94,3 % – die beste Leistung bei wissenschaftlichen Fachfragen auf Expertenniveau.
5 Szenarien für Claude Opus 4.6
- Wissensarbeit auf Expertenniveau: GDPval-AA 1606 Elo ist weit führend. Ideal für Forschungsberichte, Finanzanalysen, juristische Dokumente und andere hochwertige Ergebnisse.
- Generierung langer Texte: Maximaler Output von 128K Tokens (Gemini bietet 64K). Opus ist besser geeignet, wenn vollständige Dokumente oder umfangreicher Code generiert werden müssen.
- Tool-gestützte Logik (Reasoning): HLE mit Tool-Tests bei 53,1 % (Vorsprung von 1,7 Punkten). Exzellent darin, externe Tools als Erweiterung der Argumentationskette zu nutzen.
- Präzise Tool-Aufrufe: tau2-bench Retail 91,9 %. Stabiler in Agent-Szenarien (wie OpenClaw), die hochpräzise Funktionsaufrufe erfordern.
- Sicherheitskritische Szenarien: Die Safety-Alignment-Technologie von Anthropic gilt als die ausgereifteste unter den Spitzenmodellen, was eine bessere Kontrolle bei sensiblen Inhalten ermöglicht.
Gemini 3.1 Pro und Opus 4.6 API Schnellanbindung
Minimalbeispiel
Über die Plattform APIYI nutzen beide Modelle eine einheitliche Schnittstelle. Sie müssen lediglich den Parameter model anpassen:
import openai
client = openai.OpenAI(
api_key="IHR_API_SCHLÜSSEL",
base_url="https://vip.apiyi.com/v1"
)
# Nutzt Gemini 3.1 Pro (stärker in Reasoning und Multimodalität)
response = client.chat.completions.create(
model="gemini-3.1-pro",
messages=[{"role": "user", "content": "Erkläre die physikalischen Prinzipien der Quantenverschränkung"}]
)
print(response.choices[0].message.content)
Claude Opus 4.6 Aufrufbeispiel und Code für den Modellwechsel anzeigen
import openai
client = openai.OpenAI(
api_key="IHR_API_SCHLÜSSEL",
base_url="https://vip.apiyi.com/v1"
)
# Nutzt Claude Opus 4.6 (stärker bei Wissensarbeit und Tool-Aufrufen)
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[{"role": "user", "content": "Erstelle einen Analysebericht zum Umsatz im ersten Quartal (Q1)"}]
)
print(response.choices[0].message.content)
# Wrapper-Funktion zur dynamischen Modellauswahl
def smart_call(prompt, task_type="general"):
model_map = {
"reasoning": "gemini-3.1-pro",
"multimodal": "gemini-3.1-pro",
"knowledge": "claude-opus-4-6",
"coding": "claude-opus-4-6",
"general": "gemini-3.1-pro", # Standardmäßig das günstigere Modell verwenden
}
return client.chat.completions.create(
model=model_map.get(task_type, "gemini-3.1-pro"),
messages=[{"role": "user", "content": prompt}]
)
Empfehlung: Über die Plattform APIYI (apiyi.com) können Sie gleichzeitig auf Gemini 3.1 Pro und Claude Opus 4.6 zugreifen und mit demselben API-Schlüssel je nach Bedarf wechseln. Die Plattform bietet ein kostenloses Testguthaben an. Wir empfehlen, die Effektivität beider Modelle in Ihrem spezifischen Szenario zu vergleichen, bevor Sie eine endgültige Entscheidung treffen.
Kostenvergleichsanalyse: Gemini 3.1 Pro vs. Opus 4.6
Der Preisunterschied ist für viele Entwickler ein entscheidender Faktor bei der Modellauswahl. Nehmen wir als Beispiel ein monatliches Volumen von 10 Millionen Input-Token + 2 Millionen Output-Token:
| Kostenpunkt | Gemini 3.1 Pro | Claude Opus 4.6 | Differenz |
|---|---|---|---|
| Input-Kosten | $20 | $50 | Gemini spart $30 |
| Output-Kosten | $24 | $50 | Gemini spart $26 |
| Gesamtkosten/Monat | $44 | $100 | Gemini spart 56% |
| Gesamtkosten/Jahr | $528 | $1.200 | Gemini spart $672 |
Wenn Ihr Schwerpunkt auf Reasoning und Multimodalität liegt, kann Gemini 3.1 Pro mehr als die Hälfte der Kosten einsparen, ohne nennenswerte Qualitätseinbußen. Falls Ihr Kernszenario jedoch Experten-Wissensarbeit ist (GDPval-AA Differenz von 289 Punkten), rechtfertigt die Qualitätssteigerung von Opus 4.6 den Aufpreis von 56 $ pro Monat.
🎯 Spartipp: Über den API-Proxy-Dienst von APIYI (apiyi.com) erhalten Sie Zugang zu vergünstigten Preisen. Eine empfohlene Strategie ist es, Gemini 3.1 Pro als Standardmodell für tägliche Anfragen zu nutzen und nur bei komplexer Wissensarbeit oder präzisen Tool-Aufrufen auf Opus 4.6 umzusteigen.
Häufig gestellte Fragen
Q1: Was ist der Unterschied zwischen dem „Drei-Stufen-Denken“ von Gemini 3.1 Pro und dem „adaptiven Denken“ von Opus 4.6?
Gemini 3.1 Pro ermöglicht es Entwicklern, manuell zwischen drei Reasoning-Stufen (Low/Medium/High) zu wählen, um die Rechenleistung zu steuern, die das Modell in den Denkprozess investiert. Die Stufe „Medium“ ist neu und wird von Google als „moderate Denktiefe“ bezeichnet. Das adaptive Denken von Claude Opus 4.6 hingegen entscheidet automatisch, wie viel Reasoning für eine Aufgabe nötig ist, wobei Entwickler über den effort-Parameter manuell eingreifen können. Die Ansätze sind ähnlich, aber die Umsetzung unterscheidet sich – Gemini ist eher wie ein Schaltgetriebe, Opus wie ein Automatikgetriebe.
Q2: Können beide Modelle gleichzeitig genutzt werden?
Ja. Wir empfehlen den Zugriff über die Plattform APIYI (apiyi.com). Mit nur einem API-Schlüssel können Sie beide Modelle aufrufen. Nutzen Sie ein dynamisches Routing je nach Aufgabentyp: Reasoning- und multimodale Aufgaben laufen über Gemini 3.1 Pro (kostengünstiger), während komplexe Wissensarbeit und präzise Tool-Aufrufe über Claude Opus 4.6 (leistungsstärker) abgewickelt werden. Die Funktion smart_call im Code-Beispiel dieses Artikels zeigt genau diesen Modus.
Q3: Welches Modell sollte ich für Coding-Szenarien wählen?
Beide Modelle liegen beim Coding fast gleichauf (der Unterschied im SWE-Bench beträgt lediglich 0,2 %). Wenn Sie hauptsächlich in Terminal-Umgebungen programmieren (z. B. CI/CD-Skripte, Kommandozeilen-Tools), liegt Gemini 3.1 Pro im Terminal-Bench mit 3,1 Punkten vorne. Wenn Sie jedoch sehr lange Code-Dateien generieren müssen (über 64K Tokens), ist der 128K-Output von Claude Opus 4.6 besser geeignet. Bei begrenztem Budget ist die Coding-Leistung von Gemini 3.1 Pro absolut ausreichend und zudem nur halb so teuer. Über APIYI (apiyi.com) können Sie beide Modelle jederzeit testen und vergleichen.
Fazit
Hier sind die Kernpunkte des Vergleichs zwischen Gemini 3.1 Pro und Claude Opus 4.6:
- Reasoning und Multimodalität: Gemini 3.1 Pro wählen. Es führt im ARC-AGI-2 mit 8,3 Punkten Vorsprung, bietet native Unterstützung für Video und Audio und kostet nur etwa 40 % bis 48 % von Opus.
- Wissensarbeit und Tool-Aufrufe: Claude Opus 4.6 wählen. Es liegt im GDPval-AA mit 289 Punkten vorne, erreicht 91,9 % beim tau2-bench für Tool-Aufrufe und bietet einen maximalen Output von 128K.
- Coding-Fähigkeiten: Gleichauf. Der Unterschied im SWE-Bench beträgt nur 0,2 %. Bei knappem Budget ist Gemini die erste Wahl.
Im Februar 2026 hat die KI-Modelllandschaft eine Ära erreicht, in der jedes Modell seine spezifischen Stärken hat. Die beste Strategie ist kein Entweder-oder, sondern ein hybrider Einsatz je nach Szenario. Wir empfehlen, beide Modelle über APIYI (apiyi.com) anzubinden und je nach Bedarf zu wechseln, um das optimale Verhältnis zwischen Qualität und Kosten zu erzielen.
📚 Referenzen
-
Offizieller Gemini 3.1 Pro Blog: Google-Ankündigung und technische Details
- Link:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - Beschreibung: Vollständige Funktionsübersicht und das dreistufige Denksystem von Gemini 3.1 Pro ansehen.
- Link:
-
Claude Opus 4.6 Release-Ankündigung: Offizieller technischer Blog von Anthropic
- Link:
anthropic.com/news/claude-opus-4-6 - Beschreibung: Vollständige Benchmark-Daten und die adaptive Denkfunktion von Opus 4.6 ansehen.
- Link:
-
Artificial Analysis Modellvergleich: Unabhängige Bewertungsplattform von Drittanbietern
- Link:
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-claude-opus-4-6-adaptive - Beschreibung: Objektive Vergleichsdaten zu Leistung, Geschwindigkeit und Preis.
- Link:
-
Google AI Entwicklerdokumentation: Gemini API-Preise und Integrationsleitfaden
- Link:
ai.google.dev/gemini-api/docs/pricing - Beschreibung: Aktuelle API-Preise und kostenlose Kontingente für Gemini 3.1 Pro ansehen.
- Link:
Autor: Technik-Team
Technischer Austausch: Teilen Sie gerne Ihre Erfahrungen mit den beiden Modellen im Kommentarbereich. Weitere Informationen zu KI-Modellen finden Sie auf APIYI apiyi.com.