
ملاحظة المؤلف: مقارنة عميقة بين Gemini 3.1 Pro و Claude Opus 4.6 عبر 13 معياراً تشمل الاستدلال، البرمجة، تعدد الوسائط، والسعر، مع توصيات لاختيار السيناريو الأنسب ودليل للوصول عبر API.
في فبراير 2026، شهد مشهد المنافسة بين نماذج الذكاء الاصطناعي "انقساماً" حقيقياً؛ حيث لم يعد هناك نموذج واحد يهيمن بشكل مطلق على جميع المنافسين. سجل نموذج Gemini 3.1 Pro، الذي أطلقته جوجل في 19 فبراير، أرقاماً قياسية في الاستدلال وتعدد الوسائط، بينما حافظ نموذج Claude Opus 4.6، الذي أطلقته Anthropic في 5 فبراير، على صدارته في المهام ذات المستوى الخبير واستدعاء الأدوات.
القيمة الجوهرية: بعد قراءة هذا المقال، ستدرك بوضوح نقاط القوة لكل من هذين النموذجين الرائدين، وأيهما الأنسب لاحتياجاتك المحددة.

مقارنة المعلمات الأساسية بين Gemini 3.1 Pro و Claude Opus 4.6
لنلقِ نظرة أولاً على المواصفات العتادية. يمثل كلا النموذجين أعلى مستوى وصلت إليه تقنيات الذكاء الاصطناعي حالياً، لكن فلسفة التصميم تختلف بوضوح بينهما.
| بُعد المعلمة | Gemini 3.1 Pro | Claude Opus 4.6 | وصف المقارنة |
|---|---|---|---|
| تاريخ الإصدار | 19 فبراير 2026 | 5 فبراير 2026 | صدر Opus قبل أسبوعين |
| نافذة السياق | مليون توكن (قياسي) | مليون توكن (نسخة تجريبية) | دعم أصلي في Gemini، بينما يتطلب Opus تفعيل النسخة التجريبية |
| أقصى مخرجات | 64 ألف توكن | 128 ألف توكن | ✅ Opus يقدم الضعف |
| وسائط الإدخال | نص، صور، صوت، فيديو، PDF | نص، صور، PDF | ✅ Gemini أكثر شمولاً في تعدد الوسائط |
| معالجة الفيديو | فيديو يصل إلى ساعة | ❌ غير مدعوم | ميزة حصرية لـ Gemini |
| معالجة الصوت | صوت يصل إلى 8.4 ساعة | ❌ غير مدعوم | ميزة حصرية لـ Gemini |
| وضع الاستنتاج | تفكير ثلاثي المستويات (منخفض/متوسط/عالٍ) | تفكير تكيفي (تعديل ديناميكي) | اختلاف في فلسفة التصميم |
| سعر الإدخال | 2 دولار لكل مليون توكن | 5 دولار لكل مليون توكن | ✅ Gemini أرخص بـ 2.5 مرة |
| سعر المخرجات | 12 دولار لكل مليون توكن | 25 دولار لكل مليون توكن | ✅ Gemini أرخص بمرتين تقريباً |
🎯 على مستوى المواصفات: يتمتع Gemini 3.1 Pro بميزة واضحة في القدرات متعددة الوسائط والسعر، بينما يتفوق Claude Opus 4.6 في طول المخرجات (128 ألف مقابل 64 ألف). لكن المواصفات مجرد مرجع، الفجوة الحقيقية تظهر في بيانات المعايير المرجعية (Benchmarks).
مقارنة عميقة للمعايير المرجعية بين Gemini 3.1 Pro و Opus 4.6
هذا هو الجزء الأهم في المقال. سنقارن بينهما عبر أربعة أبعاد: الاستنتاج، البرمجة، قدرات الوكلاء (Agents)، والعمل المعرفي.
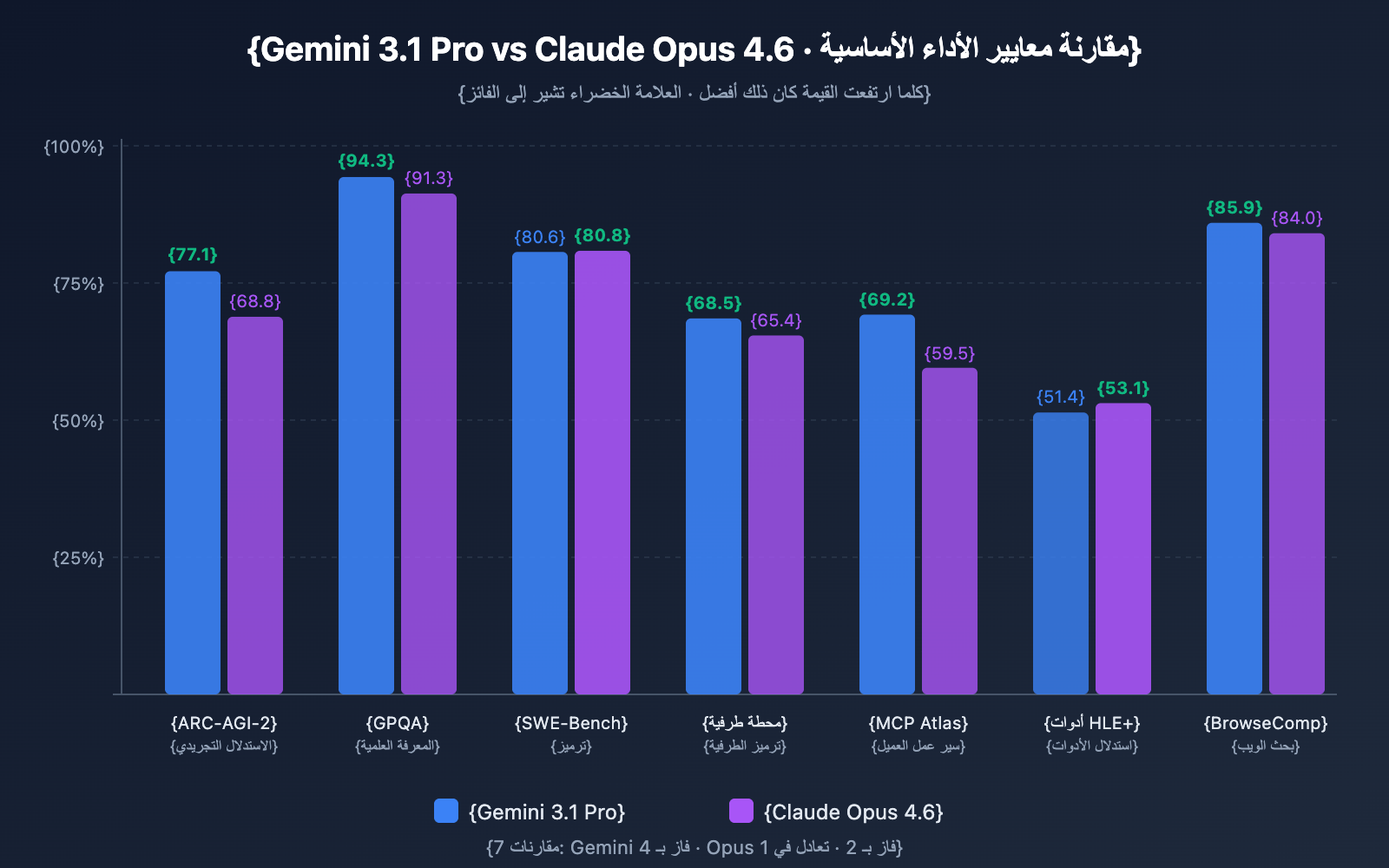
مقارنة قدرات الاستنتاج
| اختبار الاستنتاج | Gemini 3.1 Pro | Claude Opus 4.6 | الفائز |
|---|---|---|---|
| ARC-AGI-2 (الاستنتاج المجرد) | 77.1% | 68.8% | ✅ Gemini متفوق بـ 8.3 نقاط |
| GPQA Diamond (المعرفة العلمية) | 94.3% | 91.3% | ✅ Gemini متفوق بـ 3.0 نقاط |
| HLE بدون أدوات (الاستنتاج النهائي) | 44.4% | 40.0% | ✅ Gemini متفوق بـ 4.4 نقاط |
| HLE مع أدوات (الاستنتاج بمساعدة الأدوات) | 51.4% | 53.1% | ✅ Opus متفوق بـ 1.7 نقطة |
التحليل: يتصدر Gemini 3.1 Pro بشكل كامل في مهام الاستنتاج الصرف، خاصة في ARC-AGI-2 حيث حقق 77.1%، وهو ما يقرب من 2.5 ضعف ما حققه سلفه Gemini 3.0 Pro (31.1%). ولكن عند السماح باستخدام الأدوات، يتفوق Opus 4.6، مما يشير إلى أن Opus أكثر مهارة في استخدام الأدوات كإمتداد لعملية التفكير.
مقارنة قدرات البرمجة
| اختبار البرمجة | Gemini 3.1 Pro | Claude Opus 4.6 | الفائز |
|---|---|---|---|
| SWE-Bench Verified | 80.6% | 80.8% | ✅ Opus متفوق بفارق ضئيل |
| Terminal-Bench 2.0 | 68.5% | 65.4% | ✅ Gemini متفوق بـ 3.1 نقاط |
التحليل: في مجال البرمجة، يتساوى النموذجان تقريباً. في SWE-Bench Verified، الفارق يكاد لا يذكر (0.2% فقط)، لكن Gemini 3.1 Pro يتفوق في Terminal-Bench 2.0 (البرمجة في بيئة الطرفية) بـ 3.1 نقاط. ومن الجدير بالذكر أن نموذج GPT-5.3-Codex من OpenAI يتفوق عليهما في Terminal-Bench بنسبة 77.3%.
مقارنة قدرات الوكلاء واستدعاء الأدوات
| اختبار الوكلاء | Gemini 3.1 Pro | Claude Opus 4.6 | الفائز |
|---|---|---|---|
| MCP Atlas (سير عمل متعدد الخطوات) | 69.2% | 59.5% | ✅ Gemini متفوق بـ 9.7 نقاط |
| BrowseComp (البحث في الويب) | 85.9% | 84.0% | ✅ Gemini متفوق بـ 1.9 نقطة |
| tau2-bench Retail (استدعاء الأدوات) | – | 91.9% | بيانات Opus متميزة |
| OSWorld (التحكم في نظام التشغيل) | – | 72.7% | بيانات Opus متميزة |
التحليل: في MCP Atlas (سير عمل الوكلاء متعدد الخطوات)، يتفوق Gemini 3.1 Pro بفارق كبير يصل إلى 9.7 نقاط، وهو مؤشر مهم للمطورين الذين يستخدمون بروتوكول Model Context Protocol. بينما تبرز بيانات Opus 4.6 بشكل أكبر في استدعاء الأدوات عبر tau2-bench والتحكم في نظام التشغيل عبر OSWorld.
مقارنة قدرات العمل المعرفي
| اختبار المعرفة | Gemini 3.1 Pro | Claude Opus 4.6 | الفائز |
|---|---|---|---|
| GDPval-AA Elo | 1317 | 1606 | ✅ Opus متفوق بـ 289 نقطة |
التحليل: في GDPval-AA (الذي يحاكي مهام العمل المعرفي الحقيقية على مستوى الخبراء)، يتفوق Opus 4.6 بـ 1606 نقطة Elo، متجاوزاً Gemini 3.1 Pro الذي حقق 1317 نقطة بفارق كبير. هذا الفارق البالغ 289 نقطة يعادل الفجوة بين لاعب شطرنج محترف وهاوٍ. وهذا يعني أنه في سيناريوهات العمل المعرفي عالية القيمة مثل التحليل البحثي، كتابة التقارير، والتحليل المالي، يمتلك Opus 4.6 ميزة نوعية واضحة.
مقترحات اختيار السيناريو بين Gemini 3.1 Pro وOpus 4.6
بناءً على البيانات المذكورة أعلاه، تبدو سيناريوهات الاستخدام لكل من النموذجين واضحة تماماً.

5 سيناريوهات لاختيار Gemini 3.1 Pro
- الاستدلال المعقد والرياضيات: حقق 77.1% في ARC-AGI-2 (بفارق 8.3 نقطة)، ويتيح لك نظام التفكير ثلاثي المستويات ضبط عمق الاستدلال حسب الحاجة.
- المعالجة متعددة الوسائط: يدعم بشكل أصلي الفيديو (ساعة واحدة) والصوت (8.4 ساعة). إذا كان عملك يتضمن تحليل الفيديو أو تفريغ الصوت، فإن Gemini هو الخيار الوحيد.
- سير عمل MCP متعدد الخطوات: سجل 69.2% في MCP Atlas (بفارق 9.7 نقطة). إذا كنت تبني أنظمة وكلاء (Agents) تعتمد على بروتوكول سياق النموذج (Model Context Protocol)، فإن Gemini أكثر موثوقية.
- السيناريوهات الحساسة للتكلفة: سعر الإدخال 2 دولار مقابل 5 دولارات، وسعر الإخراج 12 دولاراً مقابل 25 دولاراً. بنفس الجودة، تبلغ تكلفة Gemini حوالي 40%-48% فقط من تكلفة Opus.
- البحث العلمي والأكاديمي: سجل 94.3% في GPQA Diamond، وهو الأفضل أداءً في الأسئلة والأجوبة العلمية بمستوى الخبراء.
5 سيناريوهات لاختيار Claude Opus 4.6
- العمل المعرفي بمستوى الخبراء: يتصدر بفارق كبير في GDPval-AA بـ 1606 Elo، مما يجعله مثالياً لتقارير الأبحاث، التحليل المالي، والوثائق القانونية وغيرها من المخرجات عالية القيمة.
- توليد النصوص الطويلة: أقصى مخرجات تصل إلى 128 ألف توكن (مقابل 64 ألف في Gemini)، مما يجعل Opus الأنسب عند الحاجة لتوليد وثائق كاملة أو أكواد برمجية طويلة.
- الاستدلال المعزز بالأدوات: سجل 53.1% في اختبار HLE مع الأدوات (بفارق 1.7 نقطة)، ويتفوق في استخدام الأدوات الخارجية كامتداد لسلسلة الاستدلال.
- استدعاء الأدوات بدقة: سجل 91.9% في tau2-bench Retail، وهو أكثر استقراراً في سيناريوهات الوكلاء (Agents) التي تتطلب استدعاء وظائف بدقة عالية (مثل OpenClaw).
- السيناريوهات الحساسة للأمان: تُعد تقنية المحاذاة الأمنية من Anthropic الأكثر نضجاً بين النماذج الرائدة، مما يجعله أكثر قابلية للتحكم عند التعامل مع المحتوى الحساس.
الوصول السريع إلى API لكل من Gemini 3.1 Pro و Opus 4.6
مثال مبسط للغاية
عبر منصة APIYI، يستخدم النموذجان واجهة موحدة، ما عليك سوى تغيير معلمة model:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# استخدام Gemini 3.1 Pro (أقوى في الاستدلال وتعدد الوسائط)
response = client.chat.completions.create(
model="gemini-3.1-pro",
messages=[{"role": "user", "content": "اشرح المبادئ الفيزيائية للتشابك الكمي"}]
)
print(response.choices[0].message.content)
عرض مثال استدعاء Claude Opus 4.6 وكود التبديل بين النماذج المتعددة
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# استخدام Claude Opus 4.6 (أقوى في العمل المعرفي واستدعاء الأدوات)
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[{"role": "user", "content": "اكتب تقريرًا تحليليًا حول إيرادات الربع الأول (Q1)"}]
)
print(response.choices[0].message.content)
# دالة مغلفة للاختيار الديناميكي للنموذج
def smart_call(prompt, task_type="general"):
model_map = {
"reasoning": "gemini-3.1-pro",
"multimodal": "gemini-3.1-pro",
"knowledge": "claude-opus-4-6",
"coding": "claude-opus-4-6",
"general": "gemini-3.1-pro", # استخدام الأرخص افتراضيًا
}
return client.chat.completions.create(
model=model_map.get(task_type, "gemini-3.1-pro"),
messages=[{"role": "user", "content": prompt}]
)
نصيحة: من خلال منصة APIYI (apiyi.com)، يمكنك الوصول إلى Gemini 3.1 Pro و Claude Opus 4.6 في وقت واحد، والتبديل بينهما حسب الحاجة باستخدام نفس مفتاح API. توفر المنصة رصيد اختبار مجاني، وننصح بمقارنة نتائج النموذجين في سيناريوهاتك الفعلية قبل اتخاذ القرار النهائي.
تحليل مقارنة التكلفة بين Gemini 3.1 Pro و Opus 4.6
تعد فجوة الأسعار عاملاً حاسمًا للعديد من المطورين عند الاختيار. بافتراض استهلاك شهري قدره 10 ملايين توكن إدخال + 2 مليون توكن إخراج:
| بند التكلفة | Gemini 3.1 Pro | Claude Opus 4.6 | الفارق |
|---|---|---|---|
| تكلفة الإدخال | $20 | $50 | توفير $30 مع Gemini |
| تكلفة الإخراج | $24 | $50 | توفير $26 مع Gemini |
| إجمالي التكلفة الشهرية | $44 | $100 | توفير 56% مع Gemini |
| إجمالي التكلفة السنوية | $528 | $1,200 | توفير $672 مع Gemini |
إذا كان السيناريو الخاص بك يعتمد بشكل أساسي على الاستدلال وتعدد الوسائط، فإن Gemini 3.1 Pro يمكنه توفير أكثر من نصف التكاليف دون فقدان الجودة تقريبًا. ولكن إذا كان السيناريو الأساسي هو العمل المعرفي على مستوى الخبراء (بفارق 289 نقطة في GDPval-AA)، فإن تحسين الجودة الذي ستحصل عليه مقابل إنفاق 56 دولارًا إضافيًا شهريًا على Opus 4.6 يستحق ذلك.
🎯 نصيحة لتوفير المال: يمكنك الاستمتاع بأسعار مخفضة عند الوصول عبر منصة APIYI (apiyi.com). الاستراتيجية الموصى بها هي جعل Gemini 3.1 Pro النموذج الافتراضي لمعالجة الطلبات اليومية، والتبديل إلى Opus 4.6 فقط في سيناريوهات العمل المعرفي واستدعاء الأدوات الدقيقة.
الأسئلة الشائعة
س1: ما الفرق بين “التفكير ثلاثي المستويات” في Gemini 3.1 Pro و”التفكير التكيفي” في Opus 4.6؟
يسمح Gemini 3.1 Pro للمطورين بضبط ثلاثة مستويات للاستدلال يدوياً (منخفض/متوسط/عالي)، للتحكم في كمية الحوسبة التي يستهلكها النموذج في التفكير. المستوى "المتوسط" هو إضافة جديدة تصفها جوجل بـ "التفكير العميق المعتدل". أما التفكير التكيفي في Claude Opus 4.6، فيقوم النموذج تلقائياً بتقدير عمق الاستدلال الذي تتطلبه المهمة، مع إمكانية تدخل المطور يدوياً عبر معامل effort. الفكرة في كليهما متشابهة لكن التنفيذ يختلف؛ Gemini يشبه "ناقل الحركة اليدوي"، بينما Opus يشبه "الأوتوماتيكي".
س2: هل يمكن استخدام النموذجين معاً؟
نعم، وبكل سهولة. يُنصح بالوصول إليهما عبر منصة APIYI (apiyi.com)، حيث يتيح لك مفتاح API واحد استدعاء النموذجين. يمكنك الاعتماد على التوجيه الديناميكي حسب نوع المهمة: مهام الاستدلال والمهام متعددة الوسائط تُوجه إلى Gemini 3.1 Pro (لأنه أوفر تكلفة)، بينما تُوجه الأعمال المعرفية واستدعاءات الأدوات الدقيقة إلى Claude Opus 4.6 (لأنه أكثر قوة). دالة smart_call المذكورة في أمثلة الكود توضح كيفية تطبيق هذا النمط.
س3: أيهما أختار لمهام البرمجة؟
النموذجان متساويان تقريباً في قدرات البرمجة (الفارق في اختبار SWE-Bench هو 0.2% فقط). إذا كان عملك يتركز بشكل أساسي في بيئة الطرفية (Terminal) مثل سكربتات CI/CD وأدوات سطر الأوامر، فإن Gemini 3.1 Pro يتفوق بـ 3.1 نقطة في Terminal-Bench. أما إذا كنت بحاجة لتوليد ملفات أكواد طويلة جداً (تتجاوز 64 ألف توكن)، فإن مخرجات Claude Opus 4.6 التي تصل إلى 128 ألف توكن هي الأنسب. وفي حال كانت الميزانية محدودة، فإن قدرات Gemini 3.1 Pro البرمجية كافية تماماً وبنصف السعر تقريباً. يمكنك دائماً تجربة ومقارنة النموذجين عبر APIYI (apiyi.com).
الخلاصة
الاستنتاجات الرئيسية للمقارنة بين Gemini 3.1 Pro و Claude Opus 4.6:
- للاستدلال والوسائط المتعددة، اختر Gemini 3.1 Pro: يتفوق بـ 8.3 نقطة في ARC-AGI-2، ويدعم الفيديو والصوت بشكل أصيل، وتكلفته تمثل فقط 40%-48% من تكلفة Opus.
- للأعمال المعرفية واستدعاء الأدوات، اختر Claude Opus 4.6: يتفوق بـ 289 نقطة في GDPval-AA، ويحقق 91.9% في استدعاء الأدوات (tau2-bench)، مع قدرة إنتاج مخرجات تصل لـ 128 ألف توكن.
- قدرات البرمجة متساوية بينهما: الفارق في SWE-Bench هو 0.2% فقط، لذا Gemini هو الخيار المفضل للميزانيات المحدودة.
في فبراير 2026، دخل مشهد نماذج الذكاء الاصطناعي عصر "التخصص"، حيث لكل نموذج نقاط قوة تميزه. الاستراتيجية الأمثل ليست اختيار أحدهما فقط، بل استخدامهما معاً بشكل هجين حسب السيناريو. نوصي بالوصول إلى النموذجين عبر APIYI (apiyi.com) للتبديل بينهما حسب الحاجة وتحقيق أفضل توازن بين الجودة والتكلفة.
📚 المصادر والمراجع
-
المدونة الرسمية لـ Gemini 3.1 Pro: إعلان جوجل والتفاصيل التقنية
- الرابط:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - الوصف: اطلع على التعريف الكامل بميزات Gemini 3.1 Pro ونظام التفكير ثلاثي المستويات.
- الرابط:
-
إعلان إطلاق Claude Opus 4.6: المدونة التقنية الرسمية لشركة Anthropic
- الرابط:
anthropic.com/news/claude-opus-4-6 - الوصف: اطلع على بيانات الاختبار المرجعي (Benchmark) الكاملة لـ Opus 4.6 وميزة التفكير التكيفي.
- الرابط:
-
مقارنة النماذج من Artificial Analysis: منصة تقييم مستقلة تابعة لجهة خارجية
- الرابط:
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-claude-opus-4-6-adaptive - الوصف: بيانات مقارنة أفقية موضوعية للأداء والسرعة والسعر.
- الرابط:
-
وثائق مطوري Google AI: دليل تسعير ووصول Gemini API
- الرابط:
ai.google.dev/gemini-api/docs/pricing - الوصف: اطلع على أحدث أسعار مفتاح API لـ Gemini 3.1 Pro والحصص المجانية.
- الرابط:
المؤلف: الفريق التقني
التبادل التقني: نرحب بمشاركة تجربة استخدامك لكلا النموذجين في قسم التعليقات، لمزيد من المعلومات حول نماذج الذكاء الاصطناعي، تفضل بزيارة APIYI apiyi.com