
作者注:从推理、编码、多模态、价格等 13 项维度深度对比 Gemini 3.1 Pro 和 Claude Opus 4.6,附场景选择建议和 API 接入指南
2026 年 2 月,AI 模型的竞争格局迎来了一次真正的「分裂」——不再有一个模型能全面碾压其他选手。Google 于 2 月 19 日发布的 Gemini 3.1 Pro 在推理和多模态上创下纪录,而 Anthropic 2 月 5 日发布的 Claude Opus 4.6 则在专家级任务和工具调用上保持领先。
核心价值: 看完本文,你将明确这两个顶级模型各自擅长什么场景,以及在你的具体需求下该选择哪一个。

Gemini 3.1 Pro 与 Claude Opus 4.6 核心参数对比
先看硬件规格。两个模型都代表了当前 AI 的最高水平,但设计哲学明显不同。
| 参数维度 | Gemini 3.1 Pro | Claude Opus 4.6 | 对比说明 |
|---|---|---|---|
| 发布日期 | 2026 年 2 月 19 日 | 2026 年 2 月 5 日 | Opus 早发布两周 |
| 上下文窗口 | 100 万 tokens(标准) | 100 万 tokens(Beta) | Gemini 原生支持,Opus 需 Beta 开启 |
| 最大输出 | 64K tokens | 128K tokens | ✅ Opus 翻倍 |
| 输入模态 | 文本、图片、音频、视频、PDF | 文本、图片、PDF | ✅ Gemini 多模态更全 |
| 视频处理 | 最长 1 小时视频 | ❌ 不支持 | Gemini 独有 |
| 音频处理 | 最长 8.4 小时音频 | ❌ 不支持 | Gemini 独有 |
| 推理模式 | 三级思考(Low/Medium/High) | 自适应思考(动态调节) | 设计理念不同 |
| 输入价格 | $2/百万 Token | $5/百万 Token | ✅ Gemini 便宜 2.5 倍 |
| 输出价格 | $12/百万 Token | $25/百万 Token | ✅ Gemini 便宜约 2 倍 |
🎯 规格层面: Gemini 3.1 Pro 在多模态能力和价格上有明显优势,Claude Opus 4.6 则在输出长度上领先(128K vs 64K)。但规格只是参考,真正的差距在 Benchmark 数据里。
Gemini 3.1 Pro 与 Opus 4.6 基准测试深度对比
这是本文最核心的部分。我们从推理、编码、Agent 能力、知识工作四个维度逐项对比。
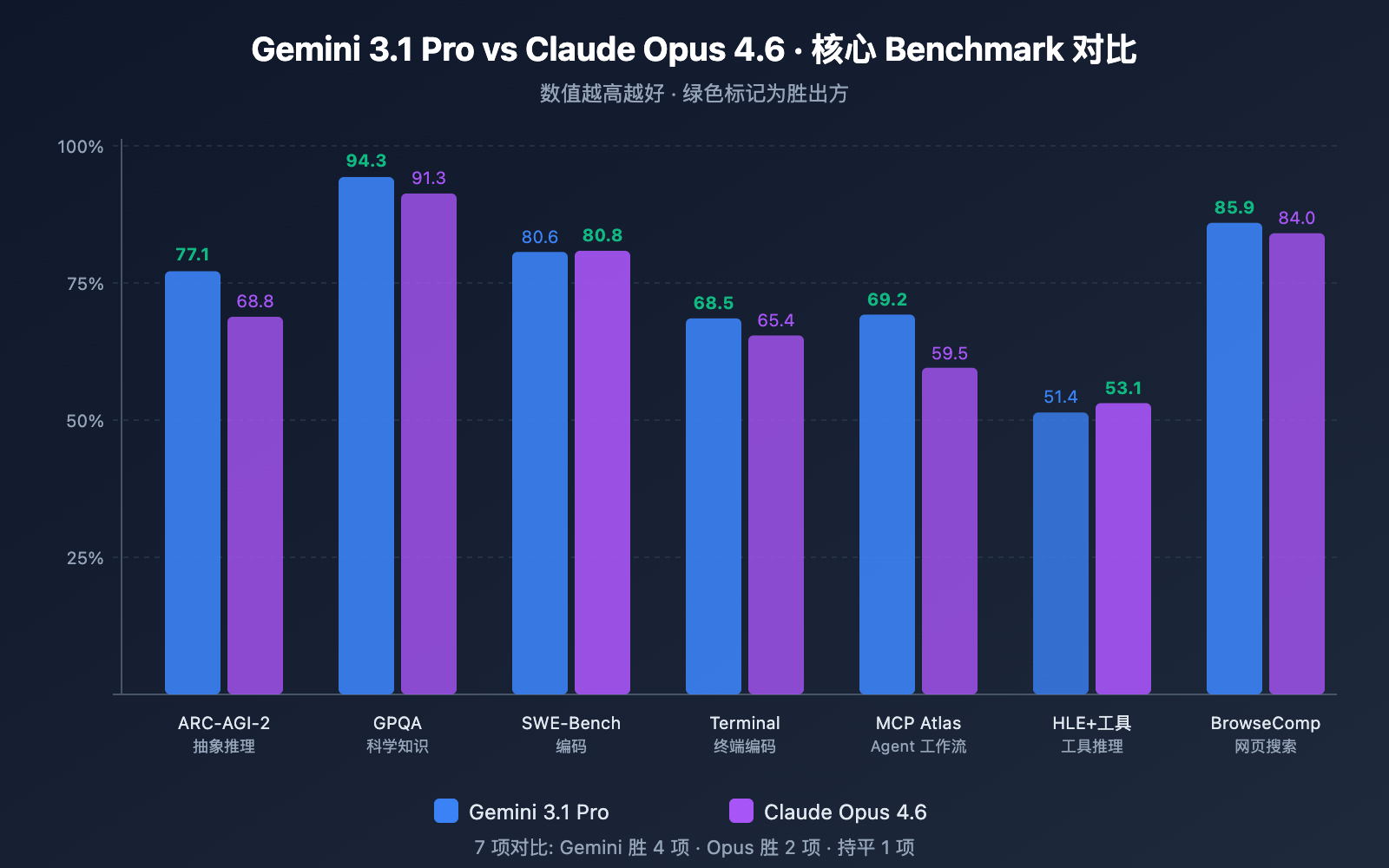
推理能力对比
| 推理测试 | Gemini 3.1 Pro | Claude Opus 4.6 | 胜出方 |
|---|---|---|---|
| ARC-AGI-2(抽象推理) | 77.1% | 68.8% | ✅ Gemini 高 8.3 分 |
| GPQA Diamond(科学知识) | 94.3% | 91.3% | ✅ Gemini 高 3.0 分 |
| HLE 无工具(终极推理) | 44.4% | 40.0% | ✅ Gemini 高 4.4 分 |
| HLE 有工具(工具辅助推理) | 51.4% | 53.1% | ✅ Opus 高 1.7 分 |
分析: Gemini 3.1 Pro 在纯推理任务上全面领先,特别是 ARC-AGI-2 的 77.1% 几乎是其前代 Gemini 3.0 Pro(31.1%)的 2.5 倍。但当允许使用工具时,Opus 4.6 反超——这说明 Opus 更擅长将工具作为推理的延伸。
编码能力对比
| 编码测试 | Gemini 3.1 Pro | Claude Opus 4.6 | 胜出方 |
|---|---|---|---|
| SWE-Bench Verified | 80.6% | 80.8% | ✅ Opus 微幅领先 |
| Terminal-Bench 2.0 | 68.5% | 65.4% | ✅ Gemini 高 3.1 分 |
分析: 编码领域两者势均力敌。SWE-Bench Verified 上几乎持平(差距仅 0.2%),但 Gemini 3.1 Pro 在 Terminal-Bench 2.0(终端环境编码)上领先 3.1 分。值得注意的是,OpenAI 的 GPT-5.3-Codex 在 Terminal-Bench 上以 77.3% 超过了两者。
Agent 与工具调用能力对比
| Agent 测试 | Gemini 3.1 Pro | Claude Opus 4.6 | 胜出方 |
|---|---|---|---|
| MCP Atlas(多步骤工作流) | 69.2% | 59.5% | ✅ Gemini 高 9.7 分 |
| BrowseComp(网页搜索) | 85.9% | 84.0% | ✅ Gemini 高 1.9 分 |
| tau2-bench Retail(工具调用) | – | 91.9% | Opus 数据突出 |
| OSWorld(操作系统控制) | – | 72.7% | Opus 数据突出 |
分析: 在 MCP Atlas(多步骤 Agent 工作流)上,Gemini 3.1 Pro 领先幅度达 9.7 分,这对使用 Model Context Protocol 的开发者来说是重要信号。而 Opus 4.6 在 tau2-bench 工具调用和 OSWorld 操作系统控制上的数据更加突出。
知识工作能力对比
| 知识测试 | Gemini 3.1 Pro | Claude Opus 4.6 | 胜出方 |
|---|---|---|---|
| GDPval-AA Elo | 1317 | 1606 | ✅ Opus 高 289 分 |
分析: 在 GDPval-AA(模拟真实专家级知识工作任务)上,Opus 4.6 以 1606 Elo 大幅领先 Gemini 3.1 Pro 的 1317 分。差距达 289 分,相当于专业棋手和业余选手的差距。这意味着在研究分析、报告撰写、金融分析等高价值知识工作场景中,Opus 4.6 有质的优势。
Gemini 3.1 Pro 与 Opus 4.6 场景选择建议
根据以上数据,两个模型的适用场景非常清晰。

选 Gemini 3.1 Pro 的 5 个场景
- 复杂推理和数学: ARC-AGI-2 得分 77.1%(领先 8.3 分),三级思考系统让你按需调节推理深度
- 多模态处理: 原生支持视频(1 小时)、音频(8.4 小时),如果你的业务涉及视频分析或语音转录,Gemini 是唯一选择
- MCP 多步骤工作流: MCP Atlas 69.2%(领先 9.7 分),如果你在构建基于 Model Context Protocol 的 Agent 系统,Gemini 更可靠
- 成本敏感场景: 输入价格 $2 vs $5,输出价格 $12 vs $25,同等质量下 Gemini 成本仅为 Opus 的 40%-48%
- 科学和学术研究: GPQA Diamond 94.3%,在专家级科学知识问答上表现最佳
选 Claude Opus 4.6 的 5 个场景
- 专家级知识工作: GDPval-AA 1606 Elo 遥遥领先,适合研究报告、金融分析、法律文档等高价值输出
- 长文本生成: 最大输出 128K tokens(Gemini 为 64K),需要生成完整文档、长篇代码时 Opus 更合适
- 工具增强推理: HLE 有工具测试 53.1%(领先 1.7 分),擅长将外部工具作为推理链的延伸
- 精确工具调用: tau2-bench Retail 91.9%,在需要高精度函数调用的 Agent 场景(如 OpenClaw)中更稳定
- 安全关键场景: Anthropic 的安全对齐技术在前沿模型中最为成熟,处理敏感内容时更可控
Gemini 3.1 Pro 和 Opus 4.6 API 快速接入
极简示例
通过 API易平台,两个模型使用统一接口,只需切换 model 参数:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# 使用 Gemini 3.1 Pro(推理和多模态更强)
response = client.chat.completions.create(
model="gemini-3.1-pro",
messages=[{"role": "user", "content": "解释量子纠缠的物理原理"}]
)
print(response.choices[0].message.content)
查看 Claude Opus 4.6 调用示例和多模型切换代码
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# 使用 Claude Opus 4.6(知识工作和工具调用更强)
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[{"role": "user", "content": "撰写一份关于 Q1 营收的分析报告"}]
)
print(response.choices[0].message.content)
# 动态选择模型的封装函数
def smart_call(prompt, task_type="general"):
model_map = {
"reasoning": "gemini-3.1-pro",
"multimodal": "gemini-3.1-pro",
"knowledge": "claude-opus-4-6",
"coding": "claude-opus-4-6",
"general": "gemini-3.1-pro", # 默认用更便宜的
}
return client.chat.completions.create(
model=model_map.get(task_type, "gemini-3.1-pro"),
messages=[{"role": "user", "content": prompt}]
)
建议: 通过 API易 apiyi.com 平台可以同时接入 Gemini 3.1 Pro 和 Claude Opus 4.6,使用同一个 API Key 按需切换。平台提供免费测试额度,建议在你的实际场景中对比两个模型的效果再做决定。
Gemini 3.1 Pro 与 Opus 4.6 成本对比分析
价格差距是很多开发者做选择时的决定性因素。以月均 1000 万输入 Token + 200 万输出 Token 为例:
| 成本项目 | Gemini 3.1 Pro | Claude Opus 4.6 | 差额 |
|---|---|---|---|
| 输入成本 | $20 | $50 | Gemini 省 $30 |
| 输出成本 | $24 | $50 | Gemini 省 $26 |
| 月总成本 | $44 | $100 | Gemini 省 56% |
| 年总成本 | $528 | $1,200 | Gemini 省 $672 |
如果你的场景是推理和多模态为主,Gemini 3.1 Pro 能在几乎不损失质量的前提下节省超过一半的费用。但如果你的核心场景是专家级知识工作(GDPval-AA 差距 289 分),Opus 4.6 每月多花 $56 换来的质量提升是值得的。
🎯 省钱建议: 在 API易 apiyi.com 平台接入可享受优惠价格。推荐策略是将 Gemini 3.1 Pro 作为默认模型处理日常请求,仅在知识工作和精确工具调用场景切换到 Opus 4.6。
常见问题
Q1: Gemini 3.1 Pro 的「三级思考」和 Opus 4.6 的「自适应思考」有什么区别?
Gemini 3.1 Pro 允许开发者手动设置 Low/Medium/High 三个推理级别,控制模型在推理上投入的计算量。Medium 级别是新增的,Google 称之为「适度深度思考」。Claude Opus 4.6 的自适应思考则由模型自动判断任务需要的推理深度,开发者也可以通过 effort 参数手动干预。两者思路类似但实现方式不同——Gemini 更像手动挡,Opus 更像自动挡。
Q2: 两个模型能同时使用吗?
可以。推荐通过 API易 apiyi.com 平台接入,一个 API Key 即可调用两个模型。根据任务类型动态路由:推理和多模态任务走 Gemini 3.1 Pro(更便宜),知识工作和精确工具调用走 Claude Opus 4.6(更强)。本文代码示例中的 smart_call 函数已展示了这种模式。
Q3: 编码场景该选哪个?
两个模型在编码上几乎持平(SWE-Bench 差距仅 0.2%)。如果主要是终端环境编码(如 CI/CD 脚本、命令行工具),Gemini 3.1 Pro 在 Terminal-Bench 上领先 3.1 分。如果需要生成长代码文件(超过 64K tokens),Claude Opus 4.6 的 128K 输出更合适。预算有限的话,Gemini 3.1 Pro 的编码能力完全够用且便宜一半。通过 API易 apiyi.com 两个模型都可以随时测试对比。
总结
Gemini 3.1 Pro 与 Claude Opus 4.6 的对比核心结论:
- 推理和多模态选 Gemini 3.1 Pro: ARC-AGI-2 领先 8.3 分,原生支持视频和音频,价格仅为 Opus 的 40%-48%
- 知识工作和工具调用选 Claude Opus 4.6: GDPval-AA 领先 289 分,tau2-bench 工具调用 91.9%,128K 最大输出
- 编码能力两者持平: SWE-Bench 差距仅 0.2%,预算有限优先选 Gemini
2026 年 2 月的 AI 模型格局已经进入「各有所长」的时代,最佳策略不是二选一,而是根据场景混合使用。推荐通过 API易 apiyi.com 同时接入两个模型,按需切换以获得最优的质量成本比。
📚 参考资料
-
Gemini 3.1 Pro 官方博客: Google 发布公告和技术细节
- 链接:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - 说明: 查看 Gemini 3.1 Pro 的完整功能介绍和三级思考系统
- 链接:
-
Claude Opus 4.6 发布公告: Anthropic 官方技术博客
- 链接:
anthropic.com/news/claude-opus-4-6 - 说明: 查看 Opus 4.6 的完整 Benchmark 数据和自适应思考功能
- 链接:
-
Artificial Analysis 模型对比: 第三方独立评测平台
- 链接:
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-claude-opus-4-6-adaptive - 说明: 客观的性能、速度、价格横向对比数据
- 链接:
-
Google AI 开发者文档: Gemini API 定价和接入指南
- 链接:
ai.google.dev/gemini-api/docs/pricing - 说明: 查看 Gemini 3.1 Pro 的最新 API 定价和免费额度
- 链接:
作者: 技术团队
技术交流: 欢迎在评论区分享你在两个模型间的使用体验,更多 AI 模型资讯可访问 API易 apiyi.com