
Примечание автора: глубокое сравнение Gemini 3.1 Pro и Claude Opus 4.6 по 13 параметрам, включая рассуждение, кодинг, мультимодальность и цену. Внутри — рекомендации по выбору сценариев и руководство по подключению к API.
В феврале 2026 года ландшафт конкуренции ИИ-моделей пережил настоящий «раскол» — больше нет одного лидера, который бы доминировал во всем. Вышедшая 19 февраля Gemini 3.1 Pro от Google установила рекорды в рассуждении и мультимодальности, а Claude Opus 4.6 от Anthropic, представленная 5 февраля, сохраняет первенство в экспертных задачах и вызовах инструментов (tool calling).
Ключевая ценность: после прочтения этой статьи вы будете четко понимать, в каких сценариях сильна каждая из этих топовых моделей, и какую из них выбрать под ваши конкретные задачи.

Сравнение ключевых характеристик Gemini 3.1 Pro и Claude Opus 4.6
Для начала взглянем на «железо». Оба облачных гиганта представляют собой вершину современного развития ИИ, но их философии проектирования заметно различаются.
| Параметр | Gemini 3.1 Pro | Claude Opus 4.6 | Комментарий |
|---|---|---|---|
| Дата релиза | 19 февраля 2026 г. | 5 февраля 2026 г. | Opus вышел на две недели раньше |
| Контекстное окно | 1 млн токенов (стандарт) | 1 млн токенов (Beta) | У Gemini нативная поддержка, у Opus нужно включать Beta |
| Максимальный вывод | 64K токенов | 128K токенов | ✅ У Opus в два раза больше |
| Модальности ввода | Текст, фото, аудио, видео, PDF | Текст, фото, PDF | ✅ Мультимодальность Gemini шире |
| Обработка видео | До 1 часа видео | ❌ Не поддерживается | Эксклюзив Gemini |
| Обработка аудио | До 8,4 часов аудио | ❌ Не поддерживается | Эксклюзив Gemini |
| Режим рассуждения | Три уровня (Low/Medium/High) | Адаптивный (динамический) | Разные подходы к архитектуре |
| Цена за вход (Input) | $2 / млн токенов | $5 / млн токенов | ✅ Gemini дешевле в 2,5 раза |
| Цена за выход (Output) | $12 / млн токенов | $25 / млн токенов | ✅ Gemini дешевле примерно в 2 раза |
🎯 На уровне характеристик: Gemini 3.1 Pro обладает явным преимуществом в мультимодальных возможностях и цене, в то время как Claude Opus 4.6 лидирует по длине генерируемого текста (128K против 64K). Однако сухие цифры — это лишь ориентир, настоящий разрыв виден в данных бенчмарков.
Глубокое сравнение бенчмарков Gemini 3.1 Pro и Opus 4.6
Это самая важная часть статьи. Мы сравним модели по четырем направлениям: рассуждение, кодинг, возможности агентов и интеллектуальная работа.
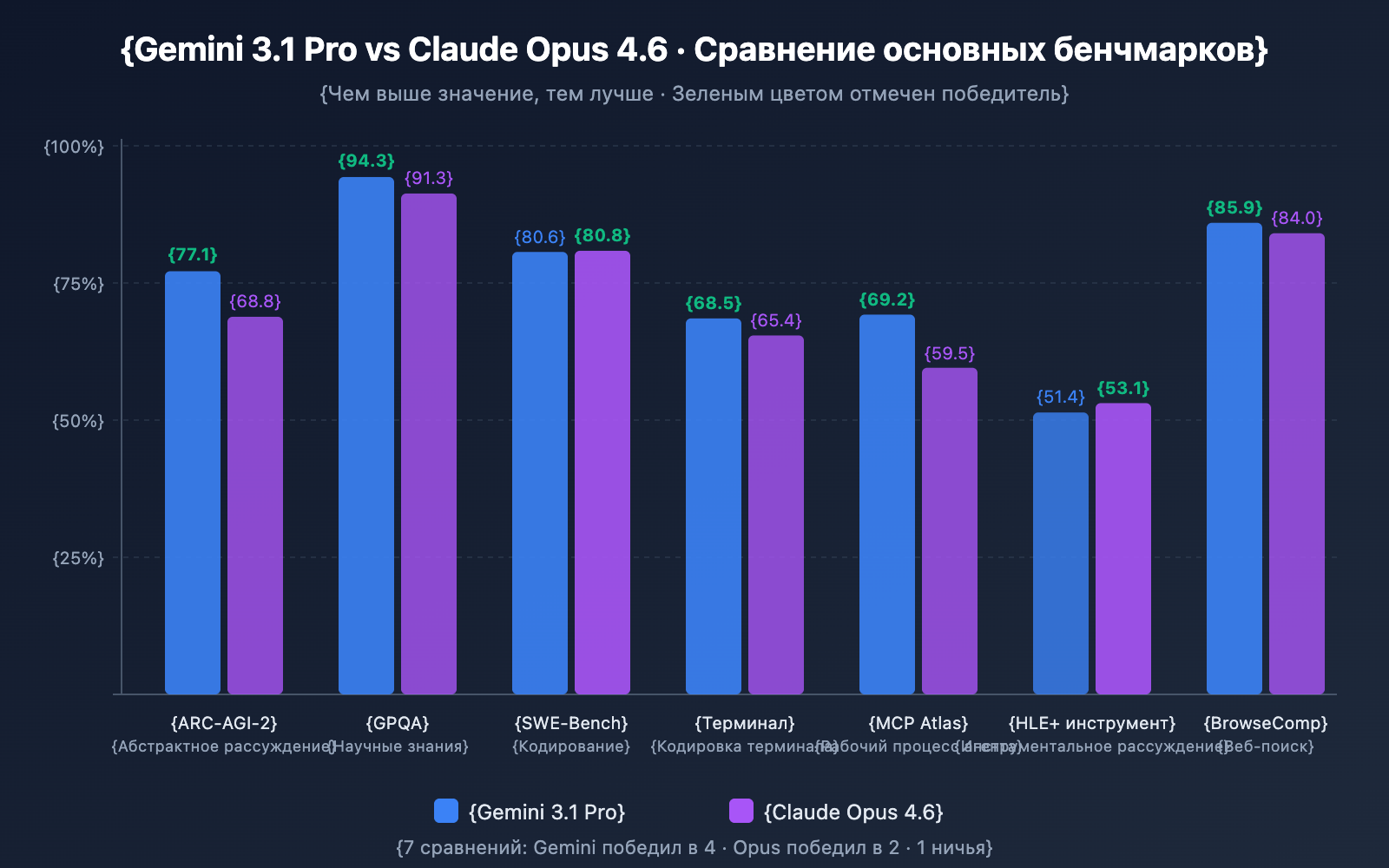
Сравнение способностей к рассуждению
| Тест на рассуждение | Gemini 3.1 Pro | Claude Opus 4.6 | Победитель |
|---|---|---|---|
| ARC-AGI-2 (Абстрактное рассуждение) | 77.1% | 68.8% | ✅ Gemini (+8.3%) |
| GPQA Diamond (Научные знания) | 94.3% | 91.3% | ✅ Gemini (+3.0%) |
| HLE без инструментов (Сложное рассуждение) | 44.4% | 40.0% | ✅ Gemini (+4.4%) |
| HLE с инструментами (С помощью инструментов) | 51.4% | 53.1% | ✅ Opus (+1.7%) |
Анализ: Gemini 3.1 Pro уверенно лидирует в задачах на «чистое» рассуждение. Особенно впечатляет результат в ARC-AGI-2 (77.1%), что почти в 2,5 раза выше, чем у предыдущего поколения Gemini 3.0 Pro (31.1%). Однако при использовании инструментов Opus 4.6 вырывается вперед — это говорит о том, что Opus лучше умеет использовать внешние средства как продолжение своего интеллекта.
Сравнение способностей к кодингу
| Тест на кодинг | Gemini 3.1 Pro | Claude Opus 4.6 | Победитель |
|---|---|---|---|
| SWE-Bench Verified | 80.6% | 80.8% | ✅ Opus (минимальный отрыв) |
| Terminal-Bench 2.0 | 68.5% | 65.4% | ✅ Gemini (+3.1%) |
Анализ: В области программирования модели идут ноздря в ноздрю. В SWE-Bench Verified результаты практически идентичны (разница всего 0.2%), но Gemini 3.1 Pro показала себя лучше в Terminal-Bench 2.0 (кодинг в терминальной среде). Стоит отметить, что GPT-5.3-Codex от OpenAI все еще обходит обе модели в Terminal-Bench с результатом 77.3%.
Сравнение способностей агентов и вызова инструментов
| Тест на агентов | Gemini 3.1 Pro | Claude Opus 4.6 | Победитель |
|---|---|---|---|
| MCP Atlas (Многошаговые процессы) | 69.2% | 59.5% | ✅ Gemini (+9.7%) |
| BrowseComp (Поиск в вебе) | 85.9% | 84.0% | ✅ Gemini (+1.9%) |
| tau2-bench Retail (Вызов инструментов) | — | 91.9% | Выдающиеся данные Opus |
| OSWorld (Управление ОС) | — | 72.7% | Выдающиеся данные Opus |
Анализ: В MCP Atlas (многошаговые агентские воркфлоу) Gemini 3.1 Pro лидирует с отрывом в 9.7 баллов, что является важным сигналом для разработчиков, использующих Model Context Protocol. В то же время Opus 4.6 демонстрирует впечатляющие результаты в вызове инструментов (tau2-bench) и управлении операционной системой (OSWorld).
Сравнение способностей к интеллектуальной работе
| Тест на знания | Gemini 3.1 Pro | Claude Opus 4.6 | Победитель |
|---|---|---|---|
| GDPval-AA Elo | 1317 | 1606 | ✅ Opus (+289 баллов) |
Анализ: В GDPval-AA (симуляция реальных экспертных задач) Opus 4.6 со своим рейтингом 1606 Elo значительно опережает Gemini 3.1 Pro (1317). Разница в 289 баллов сопоставима с разрывом между профессиональным шахматистом и любителем. Это означает, что в таких сценариях, как глубокая аналитика, написание отчетов и финансовый анализ, Opus 4.6 обладает качественным преимуществом.
Рекомендации по выбору между Gemini 3.1 Pro и Opus 4.6
Судя по приведенным данным, области применения обеих моделей предельно ясны.

5 сценариев для выбора Gemini 3.1 Pro
- Сложные рассуждения и математика: Результат ARC-AGI-2 составляет 77,1% (на 8,3 балла выше конкурента), а трехуровневая система мышления позволяет настраивать глубину рассуждений под ваши задачи.
- Мультимодальная обработка: Нативная поддержка видео (до 1 часа) и аудио (до 8,4 часов). Если ваша работа связана с анализом видео или транскрибацией речи, Gemini — ваш единственный вариант.
- Многошаговые рабочие процессы MCP: Результат MCP Atlas — 69,2% (опережение на 9,7 балла). Если вы строите агентские системы на базе Model Context Protocol, Gemini покажет себя надежнее.
- Сценарии, где важна стоимость: Цена за входные токены $2 против $5, за выходные — $12 против $25. При сопоставимом качестве затраты на Gemini составят всего 40–48% от стоимости Opus.
- Научные и академические исследования: Результат GPQA Diamond — 94,3%. Модель демонстрирует лучшие показатели в ответах на вопросы, требующие экспертных научных знаний.
5 сценариев для выбора Claude Opus 4.6
- Интеллектуальная работа экспертного уровня: Показатель GDPval-AA 1606 Elo говорит сам за себя. Модель идеально подходит для подготовки глубоких аналитических отчетов, финансового анализа и юридической документации.
- Генерация длинных текстов: Максимальный объем вывода — 128K токенов (против 64K у Gemini). Opus лучше справится, если нужно создать объемный документ или написать длинный программный код за один раз.
- Рассуждения с использованием инструментов: В тесте HLE с использованием инструментов модель набрала 53,1% (опережение на 1,7 балла). Она отлично умеет использовать внешние инструменты как логическое продолжение цепочки рассуждений.
- Точный вызов инструментов: В тесте tau2-bench Retail результат составил 91,9%. Модель стабильнее в сценариях с агентами (например, OpenClaw), где требуется ювелирная точность вызова функций.
- Сценарии, критичные к безопасности: Технологии этического выравнивания (safety alignment) от Anthropic считаются самыми зрелыми на рынке. Opus обеспечивает лучший контроль при работе с чувствительным или деликатным контентом.
Быстрое подключение к API Gemini 3.1 Pro и Opus 4.6
Минималистичный пример
Через платформу APIYI обе модели доступны через единый интерфейс — достаточно просто сменить параметр model:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Используем Gemini 3.1 Pro (сильнее в рассуждениях и мультимодальных задачах)
response = client.chat.completions.create(
model="gemini-3.1-pro",
messages=[{"role": "user", "content": "Объясни физический принцип квантовой запутанности"}]
)
print(response.choices[0].message.content)
Посмотреть пример вызова Claude Opus 4.6 и код для переключения между моделями
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Используем Claude Opus 4.6 (лучше справляется с интеллектуальными задачами и вызовом инструментов)
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[{"role": "user", "content": "Подготовь аналитический отчет по выручке за первый квартал (Q1)"}]
)
print(response.choices[0].message.content)
# Функция-обертка для динамического выбора модели
def smart_call(prompt, task_type="general"):
model_map = {
"reasoning": "gemini-3.1-pro",
"multimodal": "gemini-3.1-pro",
"knowledge": "claude-opus-4-6",
"coding": "claude-opus-4-6",
"general": "gemini-3.1-pro", # По умолчанию используем ту, что дешевле
}
return client.chat.completions.create(
model=model_map.get(task_type, "gemini-3.1-pro"),
messages=[{"role": "user", "content": prompt}]
)
Совет: Через платформу APIYI (apiyi.com) можно одновременно получить доступ к Gemini 3.1 Pro и Claude Opus 4.6, переключаясь между ними с помощью одного API-ключа по мере необходимости. Платформа предоставляет бесплатный тестовый баланс, так что рекомендуем сравнить результаты обеих моделей на ваших реальных задачах перед принятием решения.
Сравнительный анализ стоимости Gemini 3.1 Pro и Opus 4.6
Разница в цене часто становится решающим фактором для разработчиков. Возьмем для примера среднемесячный объем в 10 млн входных токенов + 2 млн выходных токенов:
| Статья расходов | Gemini 3.1 Pro | Claude Opus 4.6 | Разница |
|---|---|---|---|
| Входные токены | $20 | $50 | Gemini экономит $30 |
| Выходные токены | $24 | $50 | Gemini экономит $26 |
| Итого в месяц | $44 | $100 | Gemini дешевле на 56% |
| Итого в год | $528 | $1,200 | Gemini экономит $672 |
Если ваши задачи в основном связаны с рассуждениями и мультимодальностью, Gemini 3.1 Pro позволит сэкономить более половины бюджета практически без потери качества. Однако, если ваша основная сфера — экспертная работа со сложными знаниями (где разрыв в GDPval-AA составляет 289 баллов), то прирост качества от Opus 4.6 за дополнительные $56 в месяц вполне оправдан.
🎯 Как сэкономить: При подключении через платформу APIYI (apiyi.com) можно воспользоваться выгодными тарифами. Рекомендуемая стратегия: использовать Gemini 3.1 Pro как модель по умолчанию для повседневных запросов, и переключаться на Opus 4.6 только для глубокой аналитики или максимально точного вызова инструментов.
Часто задаваемые вопросы
Q1: В чем разница между «трехуровневым мышлением» Gemini 3.1 Pro и «адаптивным мышлением» Opus 4.6?
Gemini 3.1 Pro позволяет разработчикам вручную устанавливать один из трех уровней рассуждений (Low/Medium/High), контролируя объем вычислительных ресурсов, затрачиваемых моделью. Уровень Medium — это новинка, которую Google называет «умеренным глубоким мышлением». У Claude Opus 4.6 адаптивное мышление работает автоматически: модель сама определяет необходимую глубину рассуждений для задачи, хотя разработчик может вмешаться через параметр effort. Подходы схожи, но реализация разная: Gemini больше напоминает «ручную коробку передач», а Opus — «автомат».
Q2: Можно ли использовать обе модели одновременно?
Да. Мы рекомендуем подключаться через платформу APIYI (apiyi.com) — один API-ключ даст вам доступ к обеим моделям. Вы можете настроить динамическую маршрутизацию в зависимости от типа задачи: сложные рассуждения и мультимодальные запросы отправлять в Gemini 3.1 Pro (это дешевле), а интеллектуальную работу со знаниями и точные вызовы инструментов — в Claude Opus 4.6 (он здесь сильнее). Функция smart_call в примере кода выше как раз демонстрирует такой гибридный подход.
Q3: Какую модель выбрать для написания кода?
В плане кодинга модели идут практически наравне (разница в тесте SWE-Bench составляет всего 0.2%). Если ваша работа в основном сосредоточена в терминале (скрипты CI/CD, консольные утилиты), Gemini 3.1 Pro лидирует в Terminal-Bench на 3.1 балла. Если же вам нужно генерировать очень длинные файлы кода (более 64K токенов), Claude Opus 4.6 с его лимитом вывода в 128K будет предпочтительнее. При ограниченном бюджете возможностей Gemini 3.1 Pro более чем достаточно, при этом она стоит в два раза дешевле. На APIYI (apiyi.com) вы можете протестировать и сравнить обе модели в любое время.
Итоги
Основные выводы из сравнения Gemini 3.1 Pro и Claude Opus 4.6:
- Для рассуждений и мультимодальности выбирайте Gemini 3.1 Pro: преимущество в 8.3 балла на ARC-AGI-2, нативная поддержка видео и аудио, а цена составляет всего 40-48% от стоимости Opus.
- Для работы со знаниями и вызова инструментов выбирайте Claude Opus 4.6: отрыв в 289 баллов на GDPval-AA, точность вызова инструментов 91.9% на tau2-bench и огромный лимит вывода в 128K.
- В кодинге — паритет: разница на SWE-Bench ничтожна (0.2%), при экономии бюджета Gemini в приоритете.
В феврале 2026 года рынок ИИ-моделей окончательно перешел в эру специализации. Лучшая стратегия сегодня — не выбирать одну модель, а использовать их комбинацию в зависимости от сценария. Рекомендуем подключить обе модели через APIYI (apiyi.com) и переключаться между ними для достижения оптимального баланса качества и стоимости.
📚 Справочные материалы
-
Официальный блог Gemini 3.1 Pro: анонс и технические подробности от Google
- Ссылка:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - Описание: подробный обзор возможностей Gemini 3.1 Pro и трехуровневой системы мышления.
- Ссылка:
-
Анонс Claude Opus 4.6: официальный технический блог Anthropic
- Ссылка:
anthropic.com/news/claude-opus-4-6 - Описание: полные данные бенчмарков и описание функции адаптивного мышления Opus 4.6.
- Ссылка:
-
Сравнение моделей от Artificial Analysis: независимая платформа для оценки
- Ссылка:
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-claude-opus-4-6-adaptive - Описание: объективные данные для сравнительного анализа производительности, скорости и стоимости.
- Ссылка:
-
Документация Google AI для разработчиков: цены и руководство по подключению Gemini API
- Ссылка:
ai.google.dev/gemini-api/docs/pricing - Описание: актуальные тарифы на API Gemini 3.1 Pro и информация о бесплатных лимитах.
- Ссылка:
Автор: Техническая команда
Обсуждение: Делитесь своим опытом использования этих моделей в комментариях. Больше новостей из мира ИИ-моделей — на сайте APIYI apiyi.com