
Google lanzó oficialmente la familia de Modelos de Lenguaje Grande multimodales Gemini Omni el 19 de mayo de 2026 durante el evento Google I/O 2026, y el modelo inicial, Gemini Omni Flash, comenzó a desplegarse para los usuarios ese mismo día. Para quienes escuchan este nombre por primera vez, el término "Omni" es mucho más importante de lo que parece: representa la nueva dirección de Google para fusionar por completo las capacidades de razonamiento inteligente de Gemini con sus funciones de generación de medios. En este artículo, te explicaremos de la manera más sencilla qué es Google Omni, qué puede hacer, en qué se diferencia del anterior Veo y cómo puedes empezar a utilizarlo si eres desarrollador o creador.
Valor central: Al terminar de leer, entenderás el posicionamiento, los límites de capacidad, los canales de uso y el impacto en la industria de Google Omni (Gemini Omni), sin perderte en la terminología de los titulares.
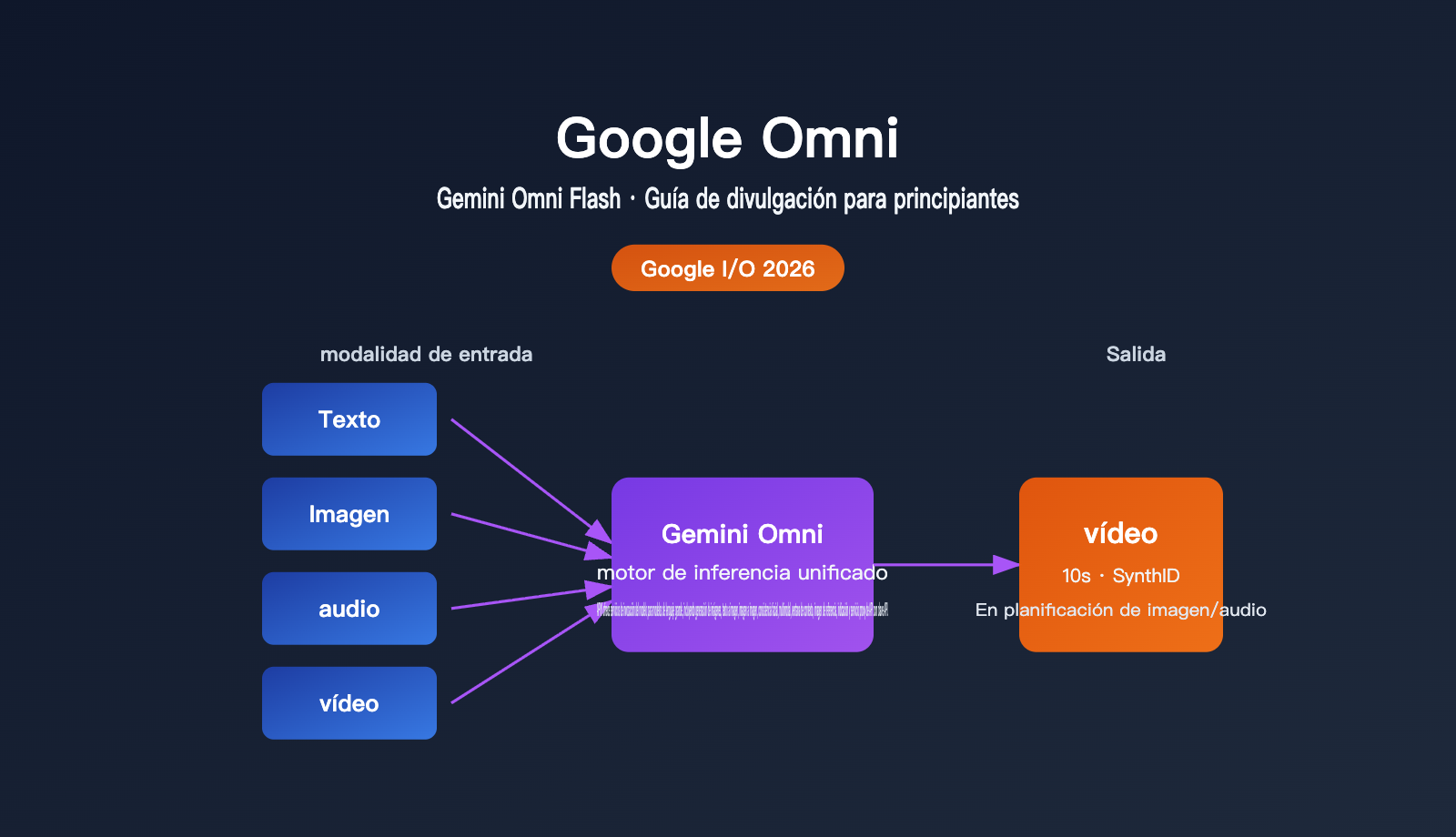
Qué es Google Omni: Un vistazo rápido a la información clave
En resumen: Google Omni es una "familia de modelos de generación multimodal" lanzada por Google, cuyo primer modelo es Gemini Omni Flash. Su mayor atractivo no es ser "otra IA que genera video", sino su capacidad para tomar texto, imágenes, audio y video en cualquier combinación como entrada, razonar sobre ellos de forma unificada y producir un video coherente.
El CEO de Google, Sundar Pichai, utilizó una frase muy directa en su discurso principal para describir su posicionamiento: "create anything from any input" (crear cualquier cosa a partir de cualquier entrada). En otras palabras, antes necesitabas usar un modelo para generar una imagen y luego otro para convertir esa imagen en video; Omni intenta realizar el razonamiento y la generación intermodal con un solo modelo.
| Elemento | Detalle |
|---|---|
| Fecha de lanzamiento | 19 de mayo de 2026 (Google I/O 2026) |
| Desarrollador | Google (Google DeepMind y Google Labs) |
| Modelo inicial | Gemini Omni Flash |
| Posicionamiento | Familia de modelos unificados de razonamiento multimodal + generación de medios |
| Modalidades de entrada | Texto, imagen, video, audio (cualquier combinación) |
| Modalidades de salida | Video (enfoque inicial), imagen y audio disponibles próximamente |
| Duración por segmento | Hasta 10 segundos (limitación de despliegue, no del modelo) |
| Identificación de contenido | Todos los videos incluyen marca de agua invisible SynthID |
| Planificación futura | Versión profesional Gemini Omni Pro, mayor duración, edición de audio |
💡 Consejo para principiantes: Si quieres probar los modelos más populares, incluida la serie Gemini, de inmediato, puedes usar el servicio proxy de API APIYI (apiyi.com) para realizar invocaciones del modelo mediante una interfaz unificada, evitando la molestia de registrarte en cada plataforma por separado.
Interpretación de las capacidades clave de Google Omni: ¿Por qué se considera de «nueva generación»?
Si solo nos fijamos en «qué entra y qué sale», es fácil confundir a Omni con otros modelos de video como Sora, Veo o Runway. Sin embargo, Nicole Brichtova, directora de producto de Google, ofreció una definición más precisa: «Es el siguiente paso que combina la inteligencia de Gemini con las capacidades de renderizado de los modelos multimedia». Las siguientes cuatro capacidades son clave para que los recién llegados entiendan la diferencia entre Omni y los modelos de video tradicionales.
1. Razonamiento multimodal, no una simple unión
La generación de video tradicional suele seguir un flujo de dos pasos: «texto → video» o «imagen + texto → video». El enfoque de Gemini Omni consiste en introducir todas las entradas en un mismo modelo, permitiéndole establecer una comprensión semántica unificada internamente y luego renderizar el video de una sola vez.
Por ejemplo, si proporcionas a Omni una foto de un producto, una pista de música de fondo y un guion publicitario, el modelo entenderá que «el producto debe aparecer cuando cambie el ritmo» y que «el guion debe corresponder con la acción en pantalla», en lugar de simplemente superponer la música sobre el video. Esta capacidad de «entender primero, generar después» proviene del ADN de razonamiento del propio modelo Gemini.
2. Comprensión física y conocimiento del mundo
En la demostración, Google destacó dos ejemplos: una toma de una bola de ágata rodando, donde el rebote, la detención y el sonido de colisión al caer cumplen con la física real; y una animación educativa estilo claymation (arcilla) sobre el plegamiento de proteínas, cuya estructura geométrica se ajusta a los conocimientos básicos de biología molecular. Aunque estos demos parecen simples, en realidad reflejan la comprensión del modelo sobre las «leyes del mundo real», y no solo un ajuste a nivel de píxeles.
Para los principiantes, esto significa que los videos generados por Omni tienen menos probabilidades de presentar defectos típicos de los videos de IA, como «objetos que se teletransportan», «iluminación errática» o «personajes con dedos de más».
3. Edición iterativa conversacional
Omni permite «generar primero y editar después mediante lenguaje natural». Después de que el modelo genere un video, puedes decirle: «cambia el fondo al atardecer» o «haz la toma más lenta», y el modelo realizará ajustes locales manteniendo la coherencia de los personajes, la escena y la acción.
Esta forma de interactuar se parece más a hablar con un editor de video que a escribir una indicación larga de una sola vez. Es especialmente amigable para quienes no tienen experiencia en ingeniería de indicaciones.
4. Avatar digital personalizado
Omni permite a los usuarios crear su propio avatar digital mediante autenticación biométrica y luego incrustarlo en los videos generados. Google enfatiza que este paso debe ser realizado por la propia persona para reducir el riesgo de abuso mediante el intercambio de rostros (deepfake).
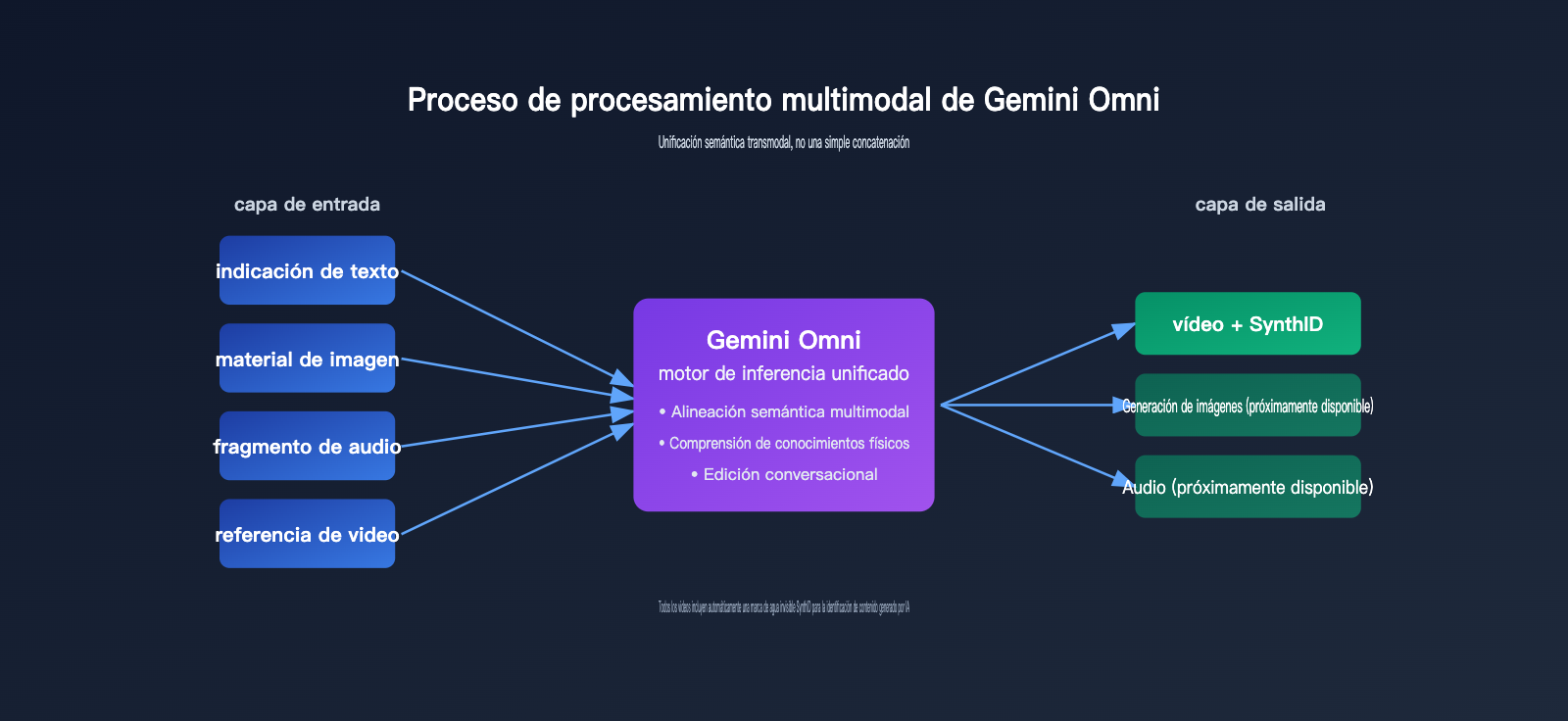
🎯 Resumen de capacidades: La clave de Omni no es una «mayor resolución» o «mayor duración», sino el trío de «razonamiento multimodal + sentido común físico + edición conversacional». Para integrar estas capacidades en tus productos, recomendamos probar los efectos de diferentes combinaciones de modelos a través de interfaces de agregación como APIYI (apiyi.com) antes de decidir la solución principal.
¿Cuál es la diferencia entre Gemini Omni y Veo?: Los dos nombres que más confunden a los principiantes
Muchos recién llegados preguntan: ¿Google no tiene ya a Veo? ¿Para qué sirve entonces Omni? Es una duda muy razonable, ya que ambos «pueden generar video», pero su posicionamiento es completamente distinto. La siguiente tabla es la forma más rápida para que un principiante entienda la relación entre ambos.
| Dimensión de comparación | Veo | Gemini Omni |
|---|---|---|
| Tipo de modelo | Modelo multimedia especializado | Modelo unificado de razonamiento multimodal + generación multimedia |
| Soporte de entrada | Texto, imagen | Texto + imagen + audio + video (cualquier combinación) |
| Profundidad de razonamiento | Principalmente a nivel de renderizado | Razonamiento mediante Gemini, unificación semántica multimodal |
| Método de edición | Principalmente regeneración | Soporta edición incremental conversacional |
| Comprensión física | General | Significativamente mejorada (destacado en el demo oficial) |
| Público objetivo | Creadores de video profesionales | Creadores + consumidores generales + desarrolladores |
| Posicionamiento actual | Herramienta de generación de video de alta calidad | Modelo base multimodal unificado para «crear cualquier cosa» |
Analogía simple: Veo es como una impresora de alta fidelidad; le das una imagen y puede imprimir un producto exquisito. Omni es más como un asistente todoterreno que puede entender tu intención; le das algunos materiales y una petición en una frase, y puede producir la pieza final. Es muy probable que ambos coexistan en el futuro, pero Omni representa la apuesta de Google por la ruta del «multimodal unificado».

🧭 Consejo de elección para principiantes: Si solo quieres generar clips cortos y hermosos, Veo sigue siendo suficiente; si vas a trabajar en escenarios de aplicación con «entrada mixta de texto, imagen, audio y video», Omni es la dirección más adecuada. Para comparar rápidamente el rendimiento real de estos dos tipos de modelos, recomendamos realizar pruebas A/B a través de una interfaz como APIYI (apiyi.com), que admite el cambio entre múltiples modelos, para que puedas cambiar de modelo sin cambiar el flujo de trabajo en tu código.
Cómo usar Gemini Omni Flash: Guía para principiantes
Desde su lanzamiento, Gemini Omni Flash ha estado disponible para diferentes grupos, aunque los canales no han sido uniformes. La siguiente tabla comparativa ayudará a los principiantes a determinar rápidamente "por dónde empezar".
| Tipo de usuario | Canal recomendado | ¿Es de pago? | Notas |
|---|---|---|---|
| Consumidor general | App de Gemini | Requiere suscripción a Google AI Plus/Pro/Ultra | Creatividad personal, creación de videos cortos |
| Creador de contenido | Google Flow | Requiere suscripción a Google AI | Orientado a flujos de trabajo creativos profesionales |
| Usuario de videos cortos | YouTube Shorts, YouTube Create App | Gratis | Experiencia gratuita por tiempo limitado, la mejor opción para empezar |
| Desarrollador / Empresa | Google API (próximamente) | Precio aún no anunciado | Disponible en unas semanas, atento a los anuncios |
| Evaluador de modelos | Plataformas de API agregadas de terceros | Según el precio de la plataforma | Ideal para equipos de desarrollo que comparan varios modelos |
La ruta más sencilla para empezar
- Si no tienes herramientas de IA de pago, te recomiendo empezar por YouTube Shorts o la aplicación YouTube Create para probar la generación de video gratuita de Omni; es la puerta de entrada con menor barrera.
- Si ya eres suscriptor de Google AI Plus o superior, abre la aplicación Gemini directamente; verás el acceso a la generación de video Omni en el panel de creación.
- Si eres desarrollador, lo más práctico actualmente es experimentar los resultados en el lado del consumidor mientras esperas a que se abra la API oficial; al mismo tiempo, puedes utilizar APIYI (apiyi.com) para invocar otros modelos de la serie Gemini ya disponibles y preparar tu cadena de invocación multimodal.
Una idea básica de invocación (tras el lanzamiento de la API oficial)
Aunque la API oficial para desarrolladores de Omni aún está en la fase de "lanzamiento en unas semanas", podemos diseñar la estructura de llamada con antelación para integrarla directamente cuando la interfaz esté disponible.
# Ejemplo de invocación agregada de modelos (estructura ilustrativa, sustituir el modelo cuando la API oficial de Omni esté abierta)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Acceso unificado a múltiples modelos a través de APIYI
)
# Invocación actual de modelos de la serie Gemini ya disponibles
response = client.chat.completions.create(
model="gemini-2.5-pro",
messages=[{"role": "user", "content": "Explica en una frase el valor central de los modelos multimodales"}]
)
print(response.choices[0].message.content)
💡 Consejo rápido: No es necesario esperar a que todas las API oficiales estén abiertas para empezar. Utiliza APIYI (apiyi.com) para configurar tu flujo con otros modelos de la serie Gemini; una vez que la API de Omni esté oficialmente en línea, solo tendrás que sustituir el nombre del modelo, con un coste de migración casi nulo.
Impacto de Google Omni en los desarrolladores y la industria
Muchos principiantes se preguntan: ¿qué significa este nuevo modelo para mí? La respuesta varía según si eres desarrollador, creador o empresa.
Impacto en los desarrolladores
| Dirección del impacto | Manifestación concreta |
|---|---|
| Modo de invocación | El diseño de la indicación multimodal reemplaza el flujo "primero texto a imagen, luego imagen a video" |
| Cadena de herramientas | El SDK debe adaptarse a "flujos de entrada de video/audio" en lugar de solo texto |
| Cumplimiento de contenido | La marca de agua SynthID se convierte en un requisito predeterminado; planificar su detección y visualización |
| Estructura de costes | El coste por generación puede ser mayor que la invocación de solo texto; requiere una gestión precisa del uso |
Para los ingenieros que están construyendo aplicaciones de IA, Omni envía una señal clara: las interfaces de IA del futuro ya no son "entrada de texto, salida de texto", sino "entrada multimodal, salida multimodal". Reestructurar los canales de datos y gestionar los recursos por modalidad con antelación te dará una ventaja competitiva cuando la API de Omni se abra oficialmente.
Impacto en la industria de contenidos
Las plataformas de videos cortos, las agencias de publicidad y los productores de contenido educativo serán los primeros en beneficiarse. Un video de alta calidad de 10 segundos que antes requería horas de edición puede producir un borrador utilizable en minutos con Omni Flash. Para los creadores de nicho, la barrera de "pasar de una imagen a una pieza terminada" se reduce significativamente.
Sin embargo, hay que tener en cuenta que la incrustación obligatoria de la marca de agua SynthID significa que el hecho de que algo sea "generado por IA" será cada vez más transparente. Las plataformas, las marcas y los reguladores podrían ajustar sus estrategias de etiquetado y auditoría de contenido basándose en esta marca de agua.
Impacto en los usuarios empresariales
A los usuarios empresariales les preocupan dos cosas: el cumplimiento y la seguridad de la marca, y los costes de escalabilidad. La marca de agua SynthID resuelve la mitad del primer problema, mientras que el segundo depende de los precios de la API que Google anuncie más adelante. Para los equipos sensibles al presupuesto, utilizar plataformas agregadas como APIYI (apiyi.com) para evaluar simultáneamente las capacidades de video o multimodales de varios proveedores (Gemini, GPT, Claude) y luego elegir según el coste y la calidad es la estrategia más prudente.
Preguntas frecuentes
Q1: ¿Google Omni y Gemini Omni son lo mismo?
Sí. Google Omni es una abreviatura no oficial; el nombre completo utilizado por Google es "Gemini Omni", que pertenece a la rama multimodal de la familia de modelos Gemini. Gemini Omni Flash fue el primer modelo lanzado de esta familia. Ambos nombres se refieren al mismo tipo de tecnología.
Q2: ¿Pueden los principiantes probar Gemini Omni gratis ahora mismo?
Sí. La forma más directa es utilizar la función de generación de video Omni en YouTube Shorts o en la aplicación YouTube Create, que actualmente está abierta de forma gratuita para los creadores. Si deseas usarlo en la aplicación Gemini, necesitarás una suscripción a Google AI Plus, Pro o Ultra.
Q3: ¿Por qué los clips de video de Gemini Omni solo duran 10 segundos?
Esta es una limitación de la fase de despliegue, no un límite de la capacidad del modelo en sí. La explicación oficial es que "durante la fase de alta demanda de cómputo, se prioriza el acceso a más usuarios". Modelos posteriores, como Omni Pro, irán aumentando gradualmente la duración del video.
Q4: ¿La marca de agua SynthID afecta la calidad del video o su uso comercial?
No. SynthID es una marca de agua invisible, imperceptible para el ojo humano y que no afecta la calidad de imagen. Su función es permitir que las plataformas y herramientas identifiquen que "este video fue generado por IA" durante la circulación del contenido. El uso comercial debe cumplir con los términos de servicio de Google.
Q5: ¿Qué deben preparar los desarrolladores ahora?
Primero, familiarizarse con la lógica de diseño de las indicaciones multimodales, en lugar de escribir solo indicaciones de texto. Segundo, organizar sus bibliotecas de recursos clasificándolas por modalidad. Tercero, probar con antelación el flujo de invocación del modelo; recomendamos utilizar la interfaz unificada de APIYI (apiyi.com) para llamar a los modelos actuales de la serie Gemini, de modo que puedas realizar una transición fluida cuando la API de Omni se lance oficialmente.
Q6: ¿Gemini Omni reemplazará a Veo?
A corto plazo, no. Veo sigue siendo el referente en generación de video de alta calidad, mientras que Omni representa la dirección unificada de "razonamiento multimodal + generación de medios". Es más probable que ambos coexistan en diferentes escenarios.
Resumen: Tres cosas que los principiantes deben recordar
Primero, la esencia de Gemini Omni es un modelo unificado de "razonamiento transmodal + generación de medios", no es simplemente "otra IA de video". Su capacidad diferenciadora se manifiesta en tres dimensiones: comprensión física, edición conversacional y razonamiento transmodal.
Segundo, la ruta de acceso más rápida para los principiantes es la entrada gratuita en YouTube Shorts o la aplicación YouTube Create, seguida por el canal de suscripción de la aplicación Gemini; la API para desarrolladores está en fase de "lanzamiento en las próximas semanas", por lo que puedes ir planificando tu arquitectura.
Tercero, Omni no reemplazará de inmediato las herramientas que ya conoces, pero representa la forma predominante de la IA multimodal en los próximos 1 o 2 años. Comprender de antemano sus métodos de entrada y salida, los requisitos de cumplimiento de SynthID y la diferencia de posicionamiento con respecto a Veo te ayudará a evitar rodeos en esta nueva ola de actualización de herramientas de IA. Si deseas invocar modelos principales como Gemini, GPT y Claude desde una sola interfaz, APIYI (apiyi.com) es actualmente la solución más sencilla, permitiéndote integrar la API de Gemini Omni en cuanto esté disponible.
Referencias
-
Blog oficial de Google – Anuncio de lanzamiento de Gemini Omni
- Enlace:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-omni - Descripción: Presentación oficial y autorizada sobre el posicionamiento y las capacidades de Gemini Omni por parte de Google.
- Enlace:
-
TechCrunch – Reportaje a fondo sobre Gemini Omni
- Enlace:
techcrunch.com/2026/05/19/googles-gemini-omni-turns-images-audio-and-text-into-video-and-thats-just-the-start - Descripción: Recopilación de las declaraciones clave de Sundar Pichai y Nicole Brichtova.
- Enlace:
-
9to5Google – Informe de experiencia con Gemini Omni Flash
- Enlace:
9to5google.com/2026/05/19/gemini-omni-create-anything-model-video - Descripción: Incluye descripciones de las demostraciones oficiales y el estado de disponibilidad del canal.
- Enlace:
Equipo de APIYI | Para seguir de cerca las novedades y guías prácticas sobre Modelos de Lenguaje Grande, visita APIYI en apiyi.com. Obtén créditos de prueba gratuitos y experimenta con una interfaz unificada para diversos modelos líderes, incluyendo la serie Gemini.