
Programadores experientes já analisaram a fundo o cartão de sistema oficial de 232 páginas da Anthropic e a conclusão é unânime: a capacidade de contexto longo do Claude Opus 4.7 sofreu um retrocesso severo em comparação com a versão 4.6.
Essa conclusão cria um contraste nítido com a declaração no blog oficial da Anthropic, que dizia: "O Opus 4.7 entregou o desempenho de contexto longo mais consistente de qualquer modelo que testamos". Onde estão os dados reais? Estão no próprio cartão de sistema publicado oficialmente — no benchmark MRCR v2 8-needle com 1M de contexto, o Opus 4.6 marcou 78,3%, enquanto o Opus 4.7 atingiu apenas 32,2%. A precisão não apenas caiu; ela foi reduzida pela metade.
O que deixou a comunidade ainda mais perplexa foi a admissão da Anthropic no cartão de sistema: "O modo de pensamento estendido (extended-thinking) de 64k do Opus 4.6 supera o 4.7 em tarefas de recuperação de múltiplas agulhas em contexto longo". Esse trecho tem sido citado repetidamente por programadores no Hacker News, X e Reddit, tornando-se a prova oficial do consenso de que o "Opus 4.7 regrediu em contexto longo".
Este artigo, baseado no cartão de sistema oficial da Anthropic, avaliações independentes de terceiros (Rohan Paul no X, análise do cartão de 232 páginas na DEV Community) e feedback em primeira mão da comunidade de programadores, detalha os dados reais, as causas fundamentais e as soluções para o retrocesso na capacidade de contexto longo do Claude Opus 4.7.
Valor central: Após ler este artigo, você saberá exatamente quais cenários de contexto longo exigem a permanência no 4.6, onde o 4.7 ainda é utilizável e como implementar o roteamento por cenário na camada de invocação do modelo via API.
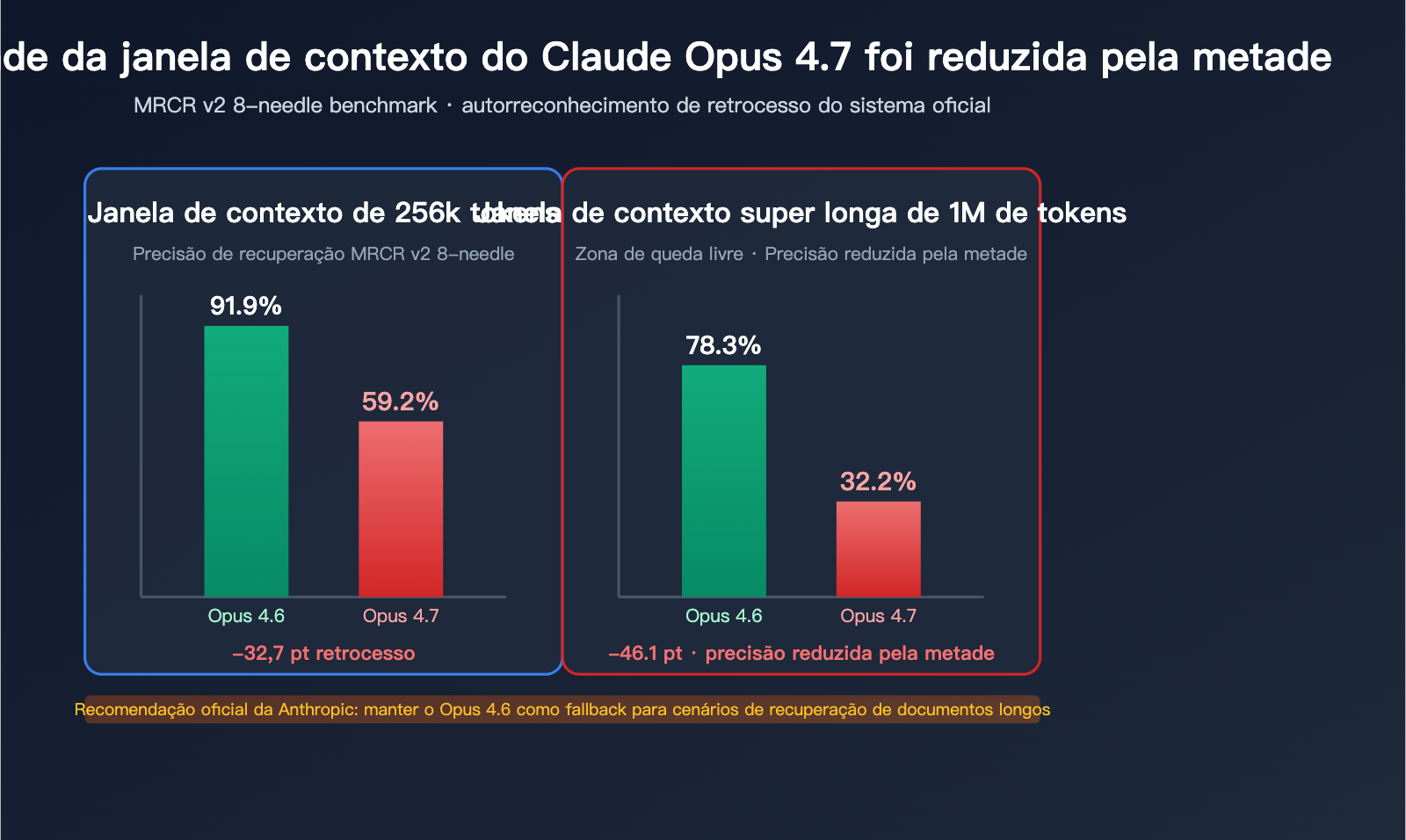
A confirmação oficial do retrocesso de contexto longo do Claude Opus 4.7
Esta seção utiliza os dados divulgados pela própria Anthropic para comprovar o retrocesso.
A queda abrupta no benchmark MRCR v2 8-needle
O MRCR v2 (Multi-Round Coreference Resolution, versão 2) é o padrão da indústria para medir a capacidade de recuperação de múltiplas agulhas em contexto longo. Método de teste: 8 fatos específicos são inseridos em um texto muito longo, e o modelo deve recuperar e reproduzir essas informações. A pontuação é a taxa média de correspondência (%).
| Comprimento do Contexto | Opus 4.6 | Opus 4.7 | Margem de Queda |
|---|---|---|---|
| 256k Token | 91,9% | 59,2% | -32,7pt |
| 1M Token | 78,3% | 32,2% | -46,1pt |
O significado desses números:
- Com 256k de contexto, a precisão de recuperação de múltiplas agulhas do 4.7 caiu de "quase nota máxima" para "reprovado".
- Com 1M de contexto, a precisão do 4.7 foi reduzida pela metade, atingindo menos de um terço do resultado anterior.
- O 4.6 não apenas supera o 4.7 neste benchmark, mas também venceu o GPT-5.2 na faixa de 256k (confirmado oficialmente por Rohan Paul).
Rohan Paul deu o veredito mais conciso no X: "O Opus 4.6 agora assume a coroa como o melhor modelo de contexto longo." Traduzindo: o Opus 4.6 é o melhor modelo de contexto longo atual de 2026 — o campeão não é o 4.7, nem o GPT-5.4.
A admissão no cartão de sistema da Anthropic
O que chocou ainda mais a comunidade foi o fato de a Anthropic admitir isso no cartão de sistema do Opus 4.7. Página 47 do cartão de sistema:
"Opus 4.6 with 64k extended-thinking mode dominates 4.7 on long-context multi-needle retrieval. For production systems on long-document retrieval, we recommend keeping 4.6 available as a fallback."
Tradução: O modo de pensamento estendido de 64k do Opus 4.6 supera o 4.7 na recuperação de múltiplas agulhas em contexto longo. Para sistemas de produção que dependem de recuperação de documentos longos, recomendamos manter o 4.6 disponível como uma opção de fallback.
Esta é a primeira vez que a Anthropic recomenda explicitamente em um documento oficial que os usuários "não migrem totalmente" para uma nova versão. Essa admissão rara mostra que as avaliações internas não conseguiram esconder esse retrocesso.
🎯 Dica técnica: Se o seu negócio envolve RAG de documentos longos ou recuperação de bases de código extensas, recomendamos manter as permissões de invocação do Claude Opus 4.6 e 4.7 através da plataforma APIYI (apiyi.com). A plataforma oferece uma interface de API unificada, onde a troca de modelos requer apenas a alteração de parâmetros, permitindo realizar testes A/B rápidos e roteamento por cenário durante o período de migração.
Não é apenas o MRCR: O BrowseComp também apresenta retrocesso
Além do MRCR, outro benchmark relacionado a contexto longo, o BrowseComp (tarefas de pesquisa profunda na Web), também apresentou queda:
| Benchmark | Opus 4.6 | Opus 4.7 | GPT-5.4 Pro |
|---|---|---|---|
| BrowseComp | 83,7% | 79,3% | 89,3% |
O BrowseComp mede o desempenho de "Agentes de Pesquisa Profunda" — exigindo que o modelo rastreie múltiplas fontes de informação em um contexto longo e faça julgamentos abrangentes entre documentos. Embora a queda do 4.7 não seja tão drástica quanto no MRCR, ainda é um sinal negativo substancial para equipes que desenvolvem Agentes de Pesquisa.
A causa raiz do retrocesso na capacidade de contexto longo do Claude Opus 4.7
Por que um novo modelo topo de linha de 2026 apresenta um retrocesso tão significativo em contextos longos? A partir dos cartões de sistema oficiais e de análises da comunidade, podemos extrair três causas fundamentais.
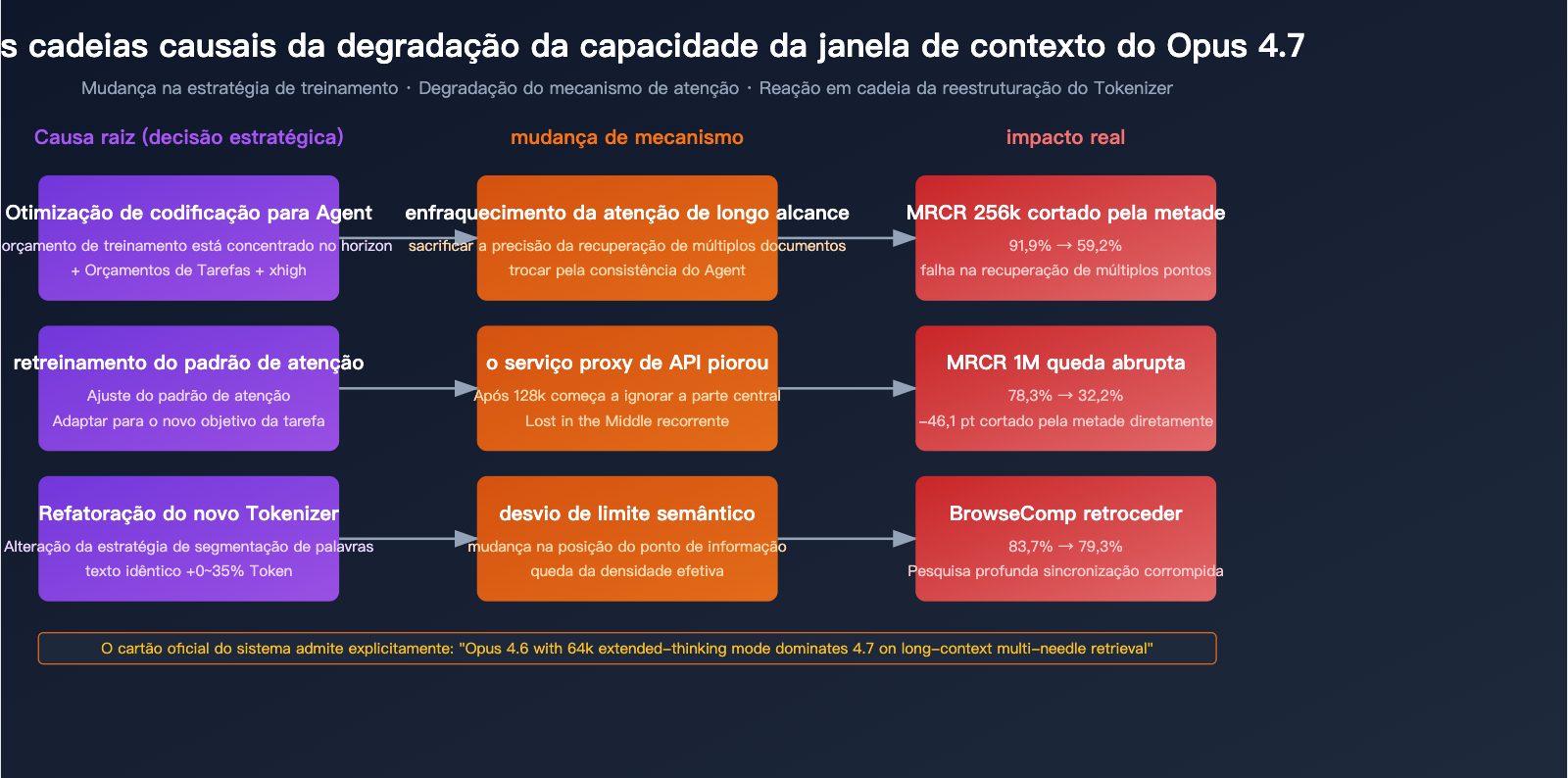
Causa 1: Sacrificando a atenção de longo alcance pela "Codificação de Agente"
O objetivo central de design do Opus 4.7 é o "fluxo de trabalho de codificação de agente de longa duração" — atenção, longa duração ≠ recuperação de contexto longo. Esses dois conceitos são frequentemente confundidos na linguagem de produto da Anthropic, mas, em termos de capacidade do modelo, são duas coisas distintas:
| Dimensão de Capacidade | Longa Duração (Horizonte de Agente) | Recuperação de Contexto Longo (Recuperação Multi-needle) |
|---|---|---|
| Requisito chave | Estabilidade de decisão contínua | Localização precisa de informações distantes |
| Cenário típico | Ciclos múltiplos do Claude Code | Recuperação RAG, perguntas e respostas em documentos longos |
| Objetivo de treinamento | Consistência + Planejamento de etapas | Precisão de atenção + Memória de granulação fina |
| Desempenho 4.7 | ✓ Melhoria significativa | ✗ Retrocesso grave |
O Opus 4.7 investiu muitos recursos de otimização na primeira dimensão (orçamentos de tarefa, níveis xhigh, seguimento de comandos mais preciso), e essas otimizações podem ter sacrificado direta ou indiretamente a precisão da atenção de longo alcance.
Causa 2: Agravamento do problema "Lost in the Middle"
O "Lost in the middle" (perdido no meio) é um problema comum e reconhecido na indústria em contextos longos: quando as informações estão enterradas no meio de um texto longo, o modelo as ignora sistematicamente ou as atribui incorretamente. O Opus 4.6 era um dos melhores modelos da indústria a lidar com isso, mas o 4.7 apresentou um retrocesso claro neste ponto.
Palavras do autor da análise de 232 páginas do cartão de sistema:
"Opus 4.6 actually uses its full context window reliably. Opus 4.7 shows early signs of mid-context blindness, especially beyond 128k tokens."
Tradução: O Opus 4.6 consegue usar sua janela de contexto completa de forma confiável. O Opus 4.7 mostra sinais precoces de cegueira de contexto médio, especialmente acima de 128k tokens.
Isso explica por que o 4.7 ainda consegue manter 59,2% no benchmark de 256k, mas cai para apenas 32,2% em 1M — quanto mais longo o contexto, maior a probabilidade de o meio ser "perdido".
Causa 3: A reestruturação do Tokenizer alterou os limites semânticos
Embora o objetivo principal do novo Tokenizer do Opus 4.7 seja "melhorar a eficiência do processamento", a forma como ele segmenta o texto não é compatível com a do 4.6. Isso significa que:
- Os mesmos pontos de informação ocupam posições de Token diferentes no 4.6 e no 4.7
- O "padrão de atenção" otimizado durante o treinamento pode precisar de uma nova adaptação
- A curto prazo, a mudança no Tokenizer faz com que o 4.7 tenha uma perda invisível ao herdar a capacidade de recuperação do 4.6
Combinado com o fato da expansão do Tokenizer (0-35%), na verdade, a "densidade efetiva de Tokens" do mesmo documento longo no 4.7 diminuiu — você acha que forneceu 1M de Tokens de informação, mas, na verdade, eles foram fragmentados em mais Tokens, dispersando a atenção do modelo.
Panorama de dados de teste de contexto longo do Claude Opus 4.7
Esta seção resume e compara os dados do 4.7 com o 4.6 e o GPT-5.4 em vários benchmarks de contexto longo.
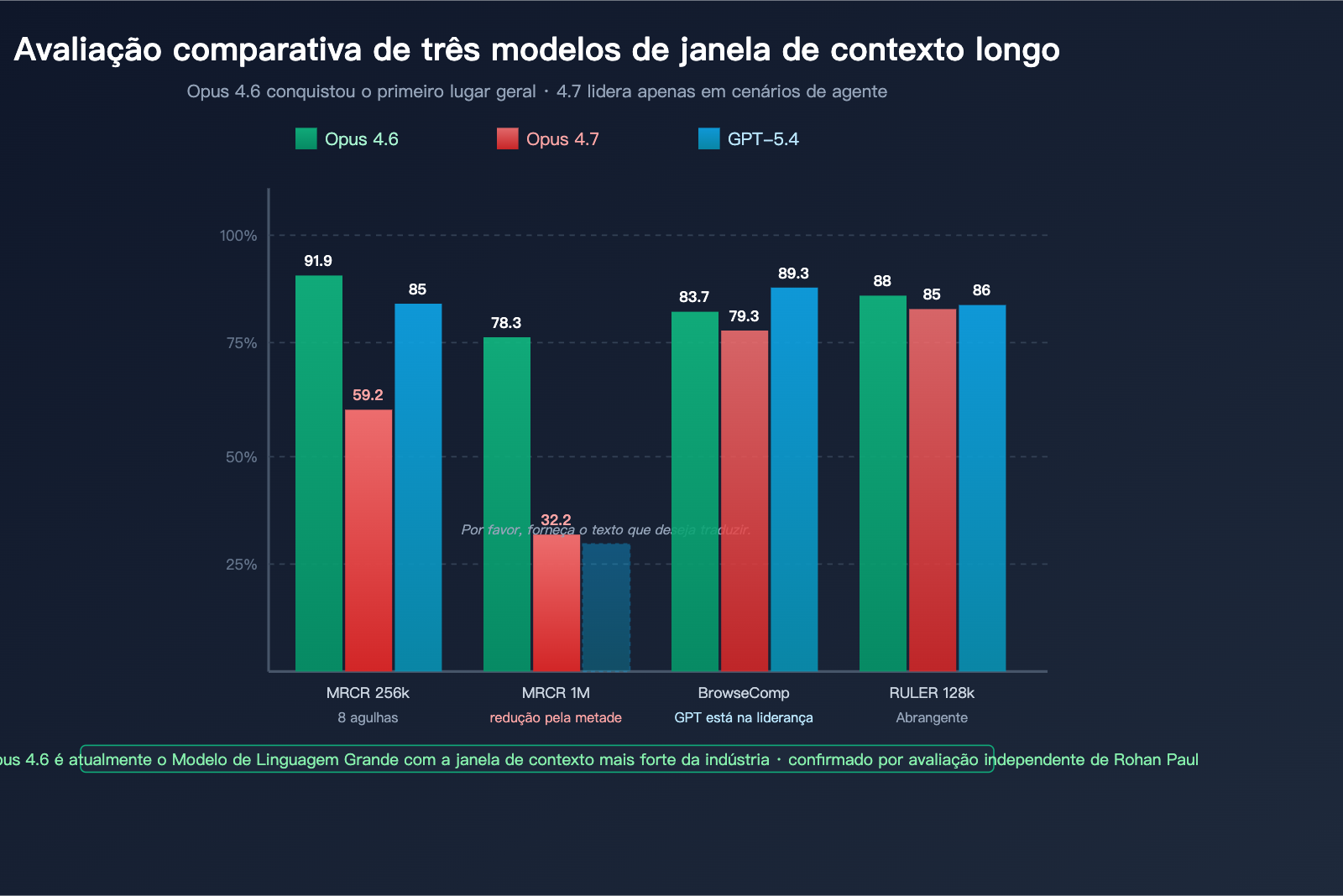
Panorama dos principais benchmarks de contexto longo
| Benchmark | Dimensão de medição | Opus 4.6 | Opus 4.7 | GPT-5.4 | Campeão |
|---|---|---|---|---|---|
| MRCR v2 8-needle @ 256k | Precisão de recuperação multi-agulha | 91,9% | 59,2% | ~85% | Opus 4.6 |
| MRCR v2 8-needle @ 1M | Recuperação de contexto ultra-longo | 78,3% | 32,2% | Não divulgado | Opus 4.6 |
| BrowseComp | Agente de pesquisa profunda | 83,7% | 79,3% | 89,3% | GPT-5.4 Pro |
| RULER @ 128k | Contexto longo abrangente | ~88% | ~85% | ~86% | Opus 4.6 |
| LongBench v2 | Compreensão de documentos longos | Alto | Ligeira queda | Estável | Opus 4.6 |
| Needle-in-haystack @ 1M | Recuperação de agulha única | 99%+ | ~95% | ~97% | Quase empate |
Como podemos observar nesta tabela:
- Na recuperação de agulha única (esconder 1 informação em um texto longo), a diferença entre os três modelos é pequena.
- Na recuperação multi-agulha (buscar 8 informações simultaneamente), a vantagem do Opus 4.6 é enorme.
- Em contextos ultra-longos de 1M, o desempenho do Opus 4.7 é significativamente inferior ao do Opus 4.6 e do GPT-5.4.
Tabela de mapeamento para cenários reais
Traduzindo os dados de benchmark para cenários de negócios reais:
| Cenário de negócio | Requisito de capacidade principal | Modelo recomendado | Motivo |
|---|---|---|---|
| Análise de contratos longos | Recuperação multi-agulha + localização precisa | Opus 4.6 | Liderança no MRCR |
| Perguntas e respostas sobre bases de código | Recuperação semântica entre arquivos | Opus 4.6 | Confiável em 128k+ |
| Análise de relatórios financeiros | Múltiplas tabelas + síntese de parágrafos | Opus 4.6 | Capacidade multi-agulha |
| Pesquisa Web profunda | Julgamento abrangente entre páginas | GPT-5.4 Pro | Liderança no BrowseComp |
| Ciclo longo do Claude Code | Execução estável de tarefas longas | Opus 4.7 | Forte horizonte de agente |
| Perguntas e respostas de documentos curtos | Resposta rápida e precisa | Opus 4.7 / 4.6 | Diferença pequena |
| Recuperação de cláusulas legais | Correspondência precisa + citação | Opus 4.6 | Requer alto recall |
💡 Sugestão de seleção de cenário: Para negócios que envolvem recuperação de documentos longos ou cenários de RAG, recomendamos rotear entre o Opus 4.6 e o 4.7 via plataforma APIYI (apiyi.com). A plataforma suporta chamadas de interface unificadas para vários modelos principais, facilitando a alternância rápida de acordo com o cenário.
Curva de impacto do comprimento do contexto
Em diferentes comprimentos de contexto, a regressão do 4.7 apresenta características de amplificação não linear:
- Abaixo de 32k: Quase nenhuma diferença entre 4.7 e 4.6.
- 32k – 128k: O 4.7 começa a apresentar um leve retrocesso (dentro de ~5pt).
- 128k – 256k: O retrocesso do 4.7 aumenta significativamente (-15~30pt).
- 256k – 1M: O 4.7 entra em uma "zona de queda", onde a recuperação multi-agulha falha completamente.
Esta curva orienta diretamente sua decisão de negócio: se a necessidade de contexto for inferior a 128k, o 4.7 pode ser usado; se exceder 128k, recomendamos fortemente manter o 4.6.
title: "Três estratégias para lidar com a regressão de contexto longo do Claude Opus 4.7"
Já que a regressão é um fato, a chave para a migração não é "se devemos", mas "como migrar". As três soluções a seguir estão organizadas do menor para o maior custo e podem ser usadas individualmente ou combinadas.

Solução 1: Roteamento por cenário na camada de API entre 4.6 e 4.7
Esta é a solução com o menor custo e o melhor resultado. Ideia central: deixe o contexto curto / codificação de Agent rodar no 4.7, e o contexto longo / RAG / pesquisa profunda rodar no 4.6.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def route_by_context_length(messages: list) -> str:
"""Roteia o modelo com base no comprimento do contexto e no tipo de tarefa"""
total_chars = sum(len(m["content"]) for m in messages)
estimated_tokens = total_chars // 3
if estimated_tokens > 128_000:
return "claude-opus-4-6"
else:
return "claude-opus-4-7"
response = client.chat.completions.create(
model=route_by_context_length(messages),
messages=messages,
max_tokens=4096
)
Ver o código completo da estratégia de roteamento multidimensional
import openai
import tiktoken
from dataclasses import dataclass
from enum import Enum
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
class TaskType(Enum):
AGENT_CODING = "agent_coding"
RAG_QA = "rag_qa"
DEEP_RESEARCH = "deep_research"
LONG_DOC_PARSE = "long_doc_parse"
SHORT_CHAT = "short_chat"
@dataclass
class RouteDecision:
model: str
reason: str
effort: str
def route_model(task_type: TaskType, context_tokens: int) -> RouteDecision:
"""Decisão de roteamento multidimensional"""
if task_type == TaskType.AGENT_CODING:
return RouteDecision(
model="claude-opus-4-7",
reason="Cenário de ciclo longo de Agent, o horizonte do 4.7 é melhor",
effort="xhigh"
)
if context_tokens > 128_000:
return RouteDecision(
model="claude-opus-4-6",
reason=f"{context_tokens} tokens excedem a zona de segurança MRCR do 4.7",
effort="high"
)
if task_type == TaskType.DEEP_RESEARCH:
return RouteDecision(
model="claude-opus-4-6",
reason="4.6 supera o 4.7 em BrowseComp",
effort="high"
)
if task_type in (TaskType.RAG_QA, TaskType.LONG_DOC_PARSE):
return RouteDecision(
model="claude-opus-4-6",
reason="Vantagem absoluta do 4.6 em recuperação multi-agulha MRCR",
effort="medium"
)
return RouteDecision(
model="claude-opus-4-7",
reason="Tarefa de contexto curto, 4.7 tem capacidade abrangente superior",
effort="medium"
)
def count_tokens(text: str, model: str = "gpt-4") -> int:
"""Estimar número de tokens"""
encoding = tiktoken.encoding_for_model(model)
return len(encoding.encode(text))
def call_with_routing(messages, task_type: TaskType):
context_text = "\n".join(m["content"] for m in messages)
context_tokens = count_tokens(context_text)
decision = route_model(task_type, context_tokens)
print(f"Decisão de roteamento: {decision.model} (motivo: {decision.reason})")
response = client.chat.completions.create(
model=decision.model,
messages=messages,
extra_headers={"reasoning-effort": decision.effort},
max_tokens=4096
)
return response
Resultado na prática: Mantendo as capacidades de Agent do 4.7, a precisão em cenários de contexto longo é totalmente restaurada ao nível do 4.6, com custo de migração quase zero.
🚀 Roteamento de interface unificada: Recomendamos implementar o roteamento sob demanda para toda a série de modelos Claude através da plataforma APIYI (apiyi.com). A plataforma oferece uma interface totalmente compatível com a oficial do Claude, eliminando a necessidade de manter várias chaves API e reduzindo a complexidade arquitetural do roteamento multi-modelo.
Solução 2: RAG com fragmentação + janela deslizante
Se o seu negócio depende fortemente do 4.7 (por exemplo, se você já vinculou fluxos de trabalho do Claude Code), você pode contornar o problema de "cegueira no meio" do 4.7 reduzindo o comprimento do contexto por chamada.
Estratégia central:
- Divida documentos longos em fragmentos de 32k-64k (o 4.7 tem um desempenho normal nesta faixa)
- Use a busca vetorial para obter apenas os blocos Top-K relevantes
- Faça chamadas independentes para cada fragmento e, em seguida, combine as respostas
def chunked_rag_with_opus_47(
document: str,
question: str,
chunk_size: int = 32_000,
top_k: int = 3
):
"""RAG com fragmentação otimizado para Opus 4.7"""
chunks = split_document(document, chunk_size=chunk_size)
relevant_chunks = vector_search(chunks, question, top_k=top_k)
partial_answers = []
for chunk in relevant_chunks:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "system", "content": "Responda à pergunta com base no fragmento de documento fornecido."},
{"role": "user", "content": f"Documento: {chunk}\nPergunta: {question}"}
],
max_tokens=1024
)
partial_answers.append(response.choices[0].message.content)
final = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": f"Responda sintetizando as seguintes respostas: {question}\n\n{partial_answers}"}
]
)
return final.choices[0].message.content
Cenários aplicáveis: Equipes que já possuem vinculação com Claude Code / Cursor, mas precisam processar documentos extremamente longos.
Solução 3: Arquitetura de modelo híbrido (Opus 4.6 + Sonnet + GPT-5.4)
Para produtos maduros, a solução mais segura é uma arquitetura híbrida de três modelos:
- Opus 4.6: Recuperação de contexto longo, RAG, análise de contratos longos
- Opus 4.7: Codificação de Agent, ciclos do Claude Code, visão de alta definição
- GPT-5.4 Pro: Pesquisa Web profunda, tarefas do tipo BrowseComp
Essa arquitetura reconhece que "nenhum modelo consegue cobrir tudo" e maximiza as vantagens de cada modelo através de uma abordagem combinada.
💰 Otimização de custo e arquitetura: O pré-requisito para uma arquitetura de modelo híbrido é uma camada de acesso API unificada. Através da plataforma APIYI (apiyi.com), você pode usar uma única chave API para invocar toda a série de modelos Claude, GPT e Gemini. A plataforma fornece estatísticas detalhadas de chamadas e análise de custos, sendo a escolha ideal para a implementação de arquiteturas multi-modelo.
FAQ sobre a capacidade de contexto longo do Claude Opus 4.7
Q1: A Anthropic diz oficialmente que o 4.7 tem um contexto longo mais estável, por que os dados de terceiros dizem o contrário?
Isso é uma confusão entre dois conceitos: "execução de longa duração" e "recuperação em contexto longo". A "estabilidade" que a Anthropic enfatiza refere-se à consistência de decisão em loops de agentes — ou seja, o modelo não trava no meio de tarefas longas. Já a "recuperação em contexto longo" refere-se à capacidade de encontrar informações com precisão em posições distantes, e essas são dimensões de capacidade completamente diferentes.
O benchmark MRCR v2 8-needle mede diretamente a segunda capacidade, e é exatamente nela que o cartão de sistema oficial da Anthropic admite que o Opus 4.6 é superior ao 4.7. Portanto, as duas afirmações não são contraditórias, elas apenas medem coisas diferentes.
Q2: Minha aplicação de RAG para documentos longos deve voltar imediatamente para o 4.6?
Depende do caso:
- Negócios principais que dependem de recuperação de contexto > 128k: Volte imediatamente. Uma queda pela metade na precisão do MRCR 1M não é algo trivial e afetará diretamente a qualidade das respostas.
- Contexto entre 32k e 128k: Sugiro fazer um teste A/B. Se a qualidade for aceitável, você pode continuar usando o 4.7; caso contrário, volte para o 4.6.
- Contexto abaixo de 32k: A diferença entre os dois modelos é pequena, decida com base em outros fatores (custo, latência).
Recomendamos realizar testes A/B através da plataforma APIYI (apiyi.com), que suporta a invocação paralela e a comparação entre o Opus 4.6 e 4.7.
Q3: Por que a Anthropic permitiria que esse retrocesso acontecesse?
Com base nas informações divulgadas no cartão de sistema oficial, a Anthropic fez uma escolha estratégica consciente: concentrar o orçamento de treinamento em codificação de agentes e compreensão visual, sacrificando parte da precisão na recuperação de contexto longo.
Essa estratégia está alinhada com o foco comercial atual da Anthropic — o Claude Code e os fluxos de trabalho de agentes corporativos são suas fontes de receita mais importantes. Mas, para usuários que lidam com documentos longos, RAG e agentes de pesquisa, essa mudança estratégica significa um downgrade.
Ao sugerir diretamente no cartão de sistema que os usuários "mantenham o 4.6 como fallback", a Anthropic está, de certa forma, dizendo: isso não é um bug, é uma estratégia, por favor, adapte-se.
Q4: O quanto essa queda no benchmark MRCR é grave na prática?
É muito grave. O MRCR 8-needle simula cenários reais de "encontrar múltiplos fatos cruciais em um documento grande", como:
- Revisão de contratos: encontrar todas as restrições de cláusulas + prazos + cláusulas de rescisão.
- Análise de relatórios financeiros: localizar múltiplos indicadores financeiros em 100 páginas de relatórios.
- Perguntas e respostas sobre bases de código: rastrear definições de variáveis + cadeias de chamadas + dependências em múltiplos arquivos.
Uma queda de 78,3% para 32,2% no MRCR significa que, nessas tarefas, o 4.7 deixará passar, em média, 2/3 das informações cruciais. Para negócios que dependem de precisão, este é um retrocesso catastrófico.
Q5: Em cenários de contexto curto (< 32k), qual a diferença real entre o 4.7 e o 4.6?
Em cenários de contexto curto abaixo de 32k, a capacidade de contexto longo do 4.7 e do 4.6 é praticamente idêntica. No entanto, o 4.7 ainda se destaca nas seguintes dimensões:
- Capacidade de codificação superior: +6,8 pontos no SWE-bench Verified.
- Compreensão visual mais forte: 3,75 MP de alta resolução.
- Chamada de ferramentas mais precisa: Liderança no MCP-Atlas.
- Custo mais elevado: Expansão de tokens de 0-35%.
Portanto, em cenários de contexto curto, a escolha baseia-se principalmente no tipo de tarefa, e não mais na capacidade de contexto longo. Escolha o 4.7 para codificação e o 4.6 para escrita; esse é o critério mais simples no momento.
Q6: Existe alguma forma de fazer o 4.7 igualar o 4.6 em contexto longo?
Atualmente, não há solução em nível de configuração. Mesmo aumentando o reasoning-effort para o máximo, a pontuação MRCR do 4.7 permanece significativamente abaixo da do 4.6.
Existem duas soluções indiretas viáveis:
- Fragmentação (Chunking) para RAG: Divida o contexto longo em blocos de 32k-64k para que o 4.7 trabalhe dentro da sua "zona de segurança".
- Encadeamento de múltiplos modelos: Use o 4.6 para a recuperação de contexto longo e envie os resultados da recuperação para o 4.7 realizar o raciocínio complexo.
A segunda opção pode ser implementada rapidamente através da interface de múltiplos modelos da plataforma APIYI (apiyi.com), que suporta a invocação unificada de diversos modelos líderes do mercado.
Resumo do retrocesso em contexto longo do Claude Opus 4.7
O retrocesso na capacidade de contexto longo do Claude Opus 4.7 é um problema real, sustentado por dados oficiais, verificado pela comunidade e com um escopo de impacto claro. Conclusões principais:
- Dados oficiais confirmam: O MRCR v2 8-needle caiu pela metade em 256k e 1M, e o cartão de sistema da Anthropic recomenda explicitamente manter o 4.6 como fallback.
- A causa raiz é uma escolha estratégica: A Anthropic sacrificou a precisão da atenção de longa distância em prol da codificação de agentes e compreensão visual.
- Impacto concentrado em cenários de 128k+: O 4.7 continua utilizável em contextos curtos, mas o retrocesso se torna não linear acima de 128k.
- O Opus 4.6 é o modelo de contexto longo mais forte atualmente: Conclusão aceita por observadores veteranos como Rohan Paul, superando até mesmo o GPT-5.2.
- A melhor estratégia é o roteamento por cenário: Use o 4.6 para documentos longos, o 4.7 para codificação e considere o GPT-5.4 Pro para pesquisas profundas.
Para os usuários, a postura correta não é "esperar a Anthropic corrigir" — este ajuste é estratégico e não será revertido a curto prazo — mas sim preparar-se imediatamente para o roteamento de múltiplos modelos na camada de invocação. Defina o 4.6 como a escolha padrão para cenários de contexto longo e reserve o 4.7 para as tarefas de codificação de agentes onde ele realmente brilha.
Isso também está alinhado com a nova tendência da indústria de IA em 2026: a era de um único modelo cobrindo todos os cenários acabou, e cada modelo está evoluindo para se "especializar em uma direção". A exigência para os usuários mudou de "escolher o modelo mais forte" para "projetar um roteamento de múltiplos modelos mais racional".
Recomendamos gerenciar a invocação de toda a série Claude através da plataforma APIYI (apiyi.com), que oferece comparação de benchmarks em tempo real, roteamento inteligente de múltiplos modelos e uma API totalmente compatível com a oficial, sendo uma ferramenta pragmática para lidar com o problema de contexto longo do Opus 4.7.
Referências
-
Cartão de Sistema do Anthropic Opus 4.7: Cartão de sistema oficial de 232 páginas
- Link:
anthropic.com/news/claude-opus-4-7 - Descrição: Contém dados completos do benchmark MRCR v2 e recomendações de migração
- Link:
-
Análise Profunda do Cartão de Sistema do Opus 4.7: Análise da comunidade DEV
- Link:
dev.to/ji_ai/i-read-all-232-pages-of-the-opus-47-system-card-28mh - Descrição: Resumo sob a perspectiva de um programador sobre o cartão de sistema de 232 páginas
- Link:
-
Guia de Migração da Anthropic: Guia de migração para o Opus 4.7
- Link:
platform.claude.com/docs/en/about-claude/models/migration-guide - Descrição: Recomendações oficiais de migração e observações sobre a janela de contexto longa
- Link:
-
Ranking de Benchmarks de Contexto Longo: Ranking de benchmarks de contexto longo
- Link:
awesomeagents.ai/leaderboards/long-context-benchmarks-leaderboard - Descrição: Comparação horizontal entre MRCR, RULER e LongBench v2
- Link:
-
Comentário de Rohan Paul no X: Análise do Opus 4.6 como campeão em contexto longo
- Link:
x.com/rohanpaul_ai/status/2019545018051240059 - Descrição: Avaliação de um observador independente sobre as vantagens do Opus 4.6 em contexto longo
- Link:
Autor: Equipe Técnica da APIYI
Data de Publicação: 18/04/2026
Modelos Aplicáveis: Claude Opus 4.6 / Claude Opus 4.7 / GPT-5.4 Pro
Troca Técnica: Sinta-se à vontade para obter créditos de teste de múltiplos modelos através da APIYI em apiyi.com, e teste você mesmo as diferenças de precisão de recuperação sob diferentes comprimentos de janela de contexto.