
O tempo de resposta excessivo ao chamar o modelo Gemini 3 Flash Preview é um desafio comum para desenvolvedores. Este artigo apresentará técnicas de configuração de parâmetros cruciais como timeout, max_tokens e thinking_level, ajudando você a dominar rapidamente métodos práticos para otimizar a velocidade de resposta do Gemini 3 Flash Preview.
Valor Principal: Ao ler este artigo, você aprenderá a controlar o tempo de resposta do Gemini 3 Flash Preview por meio da configuração adequada de parâmetros, alcançando uma melhoria significativa na velocidade e mantendo a qualidade da saída.

Análise das Causas do Longo Tempo de Resposta no Gemini 3 Flash Preview
Antes de mergulharmos nas técnicas de otimização, precisamos entender por que o Gemini 3 Flash Preview às vezes demora a responder.
Mecanismo de Tokens de Pensamento (Thinking Tokens)
O Gemini 3 Flash Preview utiliza um mecanismo de pensamento dinâmico, que é a causa central do aumento no tempo de resposta:
| Fator de Influência | Descrição | Impacto no Tempo de Resposta |
|---|---|---|
| Tarefas de raciocínio complexas | Problemas que envolvem raciocínio lógico exigem mais Tokens de pensamento | Aumenta significativamente o tempo de resposta |
| Profundidade de pensamento dinâmica | O modelo ajusta automaticamente a quantidade de pensamento baseada na complexidade | Questões simples são rápidas, complexas são lentas |
| Saída não-stream | No modo não-stream, é necessário esperar a conclusão de toda a geração | O tempo total de espera é maior |
| Quantidade de Tokens de saída | Quanto mais conteúdo para completar, maior o tempo de geração | Aumenta o tempo de resposta de forma linear |
De acordo com dados de testes da Artificial Analysis, a quantidade de Tokens que o Gemini 3 Flash Preview utiliza no nível máximo de pensamento pode chegar a cerca de 160 milhões, o que é mais que o dobro do Gemini 2.5 Flash. Isso significa que, em tarefas complexas, o modelo consome uma quantidade considerável de "tempo de pensamento".
Análise de Caso Real
A partir do feedback dos usuários, observa-se que, quando a tarefa exige velocidade no retorno mas não necessita de altíssima precisão, a configuração padrão do Gemini 3 Flash Preview pode não ser a ideal:
"Como a tarefa tem requisitos de velocidade para o tempo de retorno e não exige alta precisão, o raciocínio do gemini-3-flash-preview é muito longo."
A causa raiz dessa situação é:
- O modelo usa pensamento dinâmico por padrão, realizando raciocínio profundo automaticamente.
- A quantidade de Tokens de conclusão pode ultrapassar 7000+.
- É necessário considerar também os Tokens de pensamento consumidos durante o processo de raciocínio.
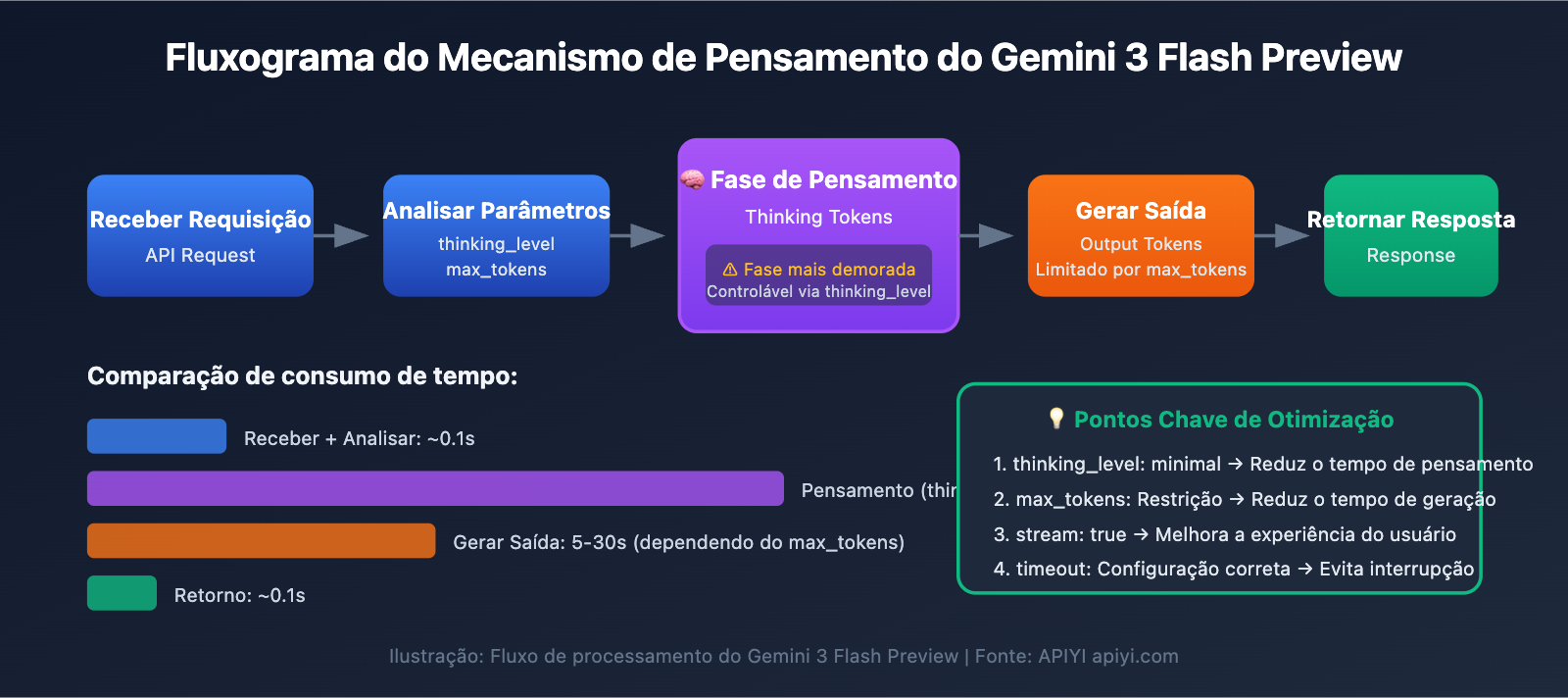
Principais pontos para otimizar a velocidade de resposta do Gemini 3 Flash Preview
| Ponto de otimização | Descrição | Efeito esperado |
|---|---|---|
| Configurar thinking_level | Controla a profundidade de raciocínio do modelo | Redução de 30-70% no tempo de resposta |
| Limitar max_tokens | Controla o tamanho da saída | Reduz o tempo de geração |
| Ajustar timeout | Define um tempo limite razoável | Evita que a requisição seja interrompida bruscamente |
| Usar saída em streaming | Retorna o conteúdo enquanto ele é gerado | Melhora a percepção de experiência do usuário |
| Escolher o cenário adequado | Usar níveis baixos de pensamento para tarefas simples | Aumento da eficiência geral |
Detalhamento do parâmetro thinking_level
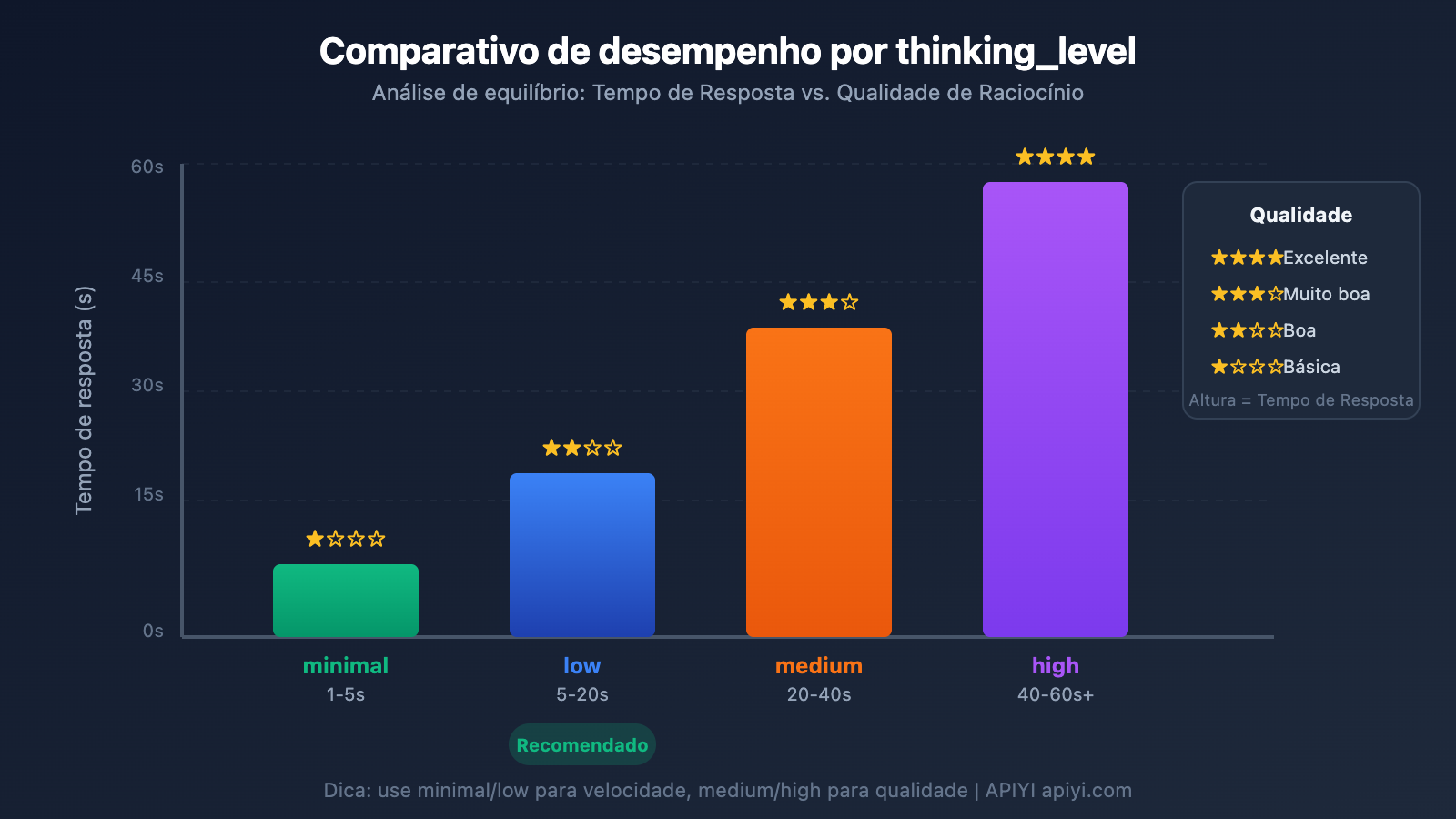
O Gemini 3 introduziu o parâmetro thinking_level, que é a configuração mais crítica para controlar a velocidade de resposta:
| thinking_level | Cenários aplicáveis | Velocidade de resposta | Qualidade do raciocínio |
|---|---|---|---|
| minimal | Diálogos simples, respostas rápidas | Mais rápida ⚡ | Básica |
| low | Tarefas diárias, raciocínio leve | Rápida | Boa |
| medium | Tarefas de complexidade média | Média | Muito boa |
| high | Raciocínio complexo, análise profunda | Lenta | Excelente |
🎯 Sugestão técnica: Se a sua tarefa não exige uma precisão extrema, mas precisa de uma resposta imediata, recomendamos configurar o
thinking_levelcomominimaloulow. Sugerimos realizar testes comparativos entre os diferentes níveis dethinking_levelatravés da plataforma APIYI (apiyi.com) para encontrar rapidamente a configuração ideal para o seu cenário de negócio.
Estratégia de configuração do parâmetro max_tokens
Limitar o max_tokens pode controlar efetivamente o comprimento da saída e, consequentemente, reduzir o tempo de resposta:
Quantidade de Tokens de saída → Afeta diretamente o tempo de geração
Quanto mais Tokens → Mais longo o tempo de resposta
Sugestões de configuração:
- Cenário de resposta simples: configure
max_tokensentre 500-1000 - Geração de conteúdo médio: configure
max_tokensentre 2000-4000 - Saída de conteúdo completo: configure conforme a necessidade real, mas fique atento ao risco de timeout
⚠️ Atenção: Configurar um max_tokens muito curto pode fazer com que a saída seja cortada, afetando a integridade da resposta. É necessário equilibrar velocidade e completude de acordo com a necessidade do negócio.
Guia rápido para otimizar a velocidade de resposta do Gemini 3 Flash Preview
Exemplo minimalista
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Usando a interface unificada da APIYI
)
# Configuração com prioridade em velocidade
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": "Explique brevemente o que é inteligência artificial"}],
max_tokens=1000, # Limitando o tamanho da saída
extra_body={
"thinking_level": "minimal" # Profundidade mínima de pensamento, resposta mais rápida
},
timeout=30 # Definindo um tempo limite de 30 segundos
)
print(response.choices[0].message.content)
Ver código completo – Inclui vários cenários de configuração
import openai
from typing import Literal
def create_gemini_client(api_key: str):
"""Cria o cliente Gemini 3 Flash"""
return openai.OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # Usando a interface unificada da APIYI
)
def call_gemini_optimized(
client: openai.OpenAI,
prompt: str,
thinking_level: Literal["minimal", "low", "medium", "high"] = "low",
max_tokens: int = 2000,
timeout: int = 60,
stream: bool = False
):
"""
Chamada otimizada do Gemini 3 Flash
Parâmetros:
client: Cliente OpenAI
prompt: Entrada do usuário
thinking_level: Profundidade de raciocínio (minimal/low/medium/high)
max_tokens: Número máximo de tokens de saída
timeout: Tempo limite (segundos)
stream: Se deve usar saída em streaming
"""
params = {
"model": "gemini-3-flash-preview",
"messages": [{"role": "user", "content": prompt}],
"max_tokens": max_tokens,
"stream": stream,
"extra_body": {
"thinking_level": thinking_level
},
"timeout": timeout
}
if stream:
# Saída em streaming - Melhora a experiência do usuário
response = client.chat.completions.create(**params)
full_content = ""
for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
print(content, end="", flush=True)
full_content += content
print() # Quebra de linha
return full_content
else:
# Saída sem streaming - Retorna tudo de uma vez
response = client.chat.completions.create(**params)
return response.choices[0].message.content
# Exemplo de uso
if __name__ == "__main__":
client = create_gemini_client("YOUR_API_KEY")
# Cenário 1: Prioridade de velocidade - Perguntas e respostas simples
print("=== Configuração de Prioridade de Velocidade ===")
result = call_gemini_optimized(
client,
prompt="Explique o que é machine learning em uma frase",
thinking_level="minimal",
max_tokens=500,
timeout=15
)
print(f"Resposta: {result}\n")
# Cenário 2: Configuração equilibrada - Tarefas diárias
print("=== Configuração Equilibrada ===")
result = call_gemini_optimized(
client,
prompt="Liste 5 melhores práticas de processamento de dados em Python",
thinking_level="low",
max_tokens=1500,
timeout=30
)
print(f"Resposta: {result}\n")
# Cenário 3: Prioridade de qualidade - Análise complexa
print("=== Configuração de Prioridade de Qualidade ===")
result = call_gemini_optimized(
client,
prompt="Analise as principais inovações da arquitetura Transformer e seu impacto no NLP",
thinking_level="high",
max_tokens=4000,
timeout=120
)
print(f"Resposta: {result}\n")
# Cenário 4: Saída em streaming - Melhorar a experiência
print("=== Saída em Streaming ===")
result = call_gemini_optimized(
client,
prompt="Apresente as principais características do Gemini 3 Flash",
thinking_level="low",
max_tokens=2000,
timeout=60,
stream=True
)
🚀 Começo rápido: Recomendamos usar a plataforma APIYI (apiyi.com) para testar rapidamente diferentes configurações de parâmetros. A plataforma oferece interfaces de API prontas para uso e suporta os principais modelos, como o Gemini 3 Flash Preview, facilitando a validação rápida dos efeitos de otimização.
Guia detalhado de configuração de parâmetros para otimizar a velocidade do Gemini 3 Flash Preview
Configuração de timeout (tempo limite)
Ao usar o Gemini 3 Flash Preview para raciocínio complexo, o tempo limite (timeout) padrão pode não ser suficiente. Aqui está a estratégia de configuração de timeout recomendada:
| Tipo de tarefa | Timeout recomendado | Descrição |
|---|---|---|
| Perguntas e respostas simples | 15-30 segundos | Combinado com thinking_level minimal |
| Tarefas cotidianas | 30-60 segundos | Combinado com thinking_level low/medium |
| Análises complexas | 60-120 segundos | Combinado com thinking_level high |
| Geração de textos longos | 120-180 segundos | Cenários com grande volume de tokens de saída |
Dicas fundamentais:
- No modo de saída não-streaming (non-streaming), é necessário esperar que todo o conteúdo seja gerado antes de receber o retorno.
- Se o timeout for configurado com um valor muito baixo, a requisição pode ser interrompida prematuramente.
- Recomendamos ajustar o tempo dinamicamente com base no volume real de tokens de saída e no
thinking_levelescolhido.
Migração do thinking_budget (antigo) para o thinking_level (novo)
O Google recomenda a migração do parâmetro antigo thinking_budget para o novo thinking_level:
| thinking_budget (antigo) | thinking_level (novo) | Instruções de migração |
|---|---|---|
| 0 | minimal | Raciocínio mínimo; note que ainda é necessário lidar com a assinatura de pensamento. |
| 1-1000 | low | Raciocínio leve |
| 1001-5000 | medium | Raciocínio moderado |
| 5001+ | high | Raciocínio profundo |
⚠️ Atenção: Não utilize thinking_budget e thinking_level na mesma requisição, pois isso pode causar comportamentos inesperados.
Plano de Configuração por Cenário para Otimização de Resposta do Gemini 3 Flash Preview
Cenário 1: Tarefas Simples de Alta Frequência (Prioridade: Velocidade)
Ideal para chatbots, perguntas e respostas rápidas, resumos de conteúdo e outros cenários sensíveis à latência:
# Configuração de prioridade de velocidade
config_speed_first = {
"thinking_level": "minimal",
"max_tokens": 500,
"timeout": 15,
"stream": True # Saída em streaming para melhorar a experiência
}
Efeito esperado:
- Tempo de resposta: 1-5 segundos
- Indicado para diálogos simples e respostas rápidas
Cenário 2: Tarefas de Rotina (Configuração Equilibrada)
Ideal para geração de conteúdo, auxílio com código, processamento de documentos e outras tarefas comuns:
# Configuração equilibrada
config_balanced = {
"thinking_level": "low",
"max_tokens": 2000,
"timeout": 45,
"stream": True
}
Efeito esperado:
- Tempo de resposta: 5-20 segundos
- Bom equilíbrio entre qualidade e velocidade
Cenário 3: Tarefas de Análise Complexas (Prioridade: Qualidade)
Ideal para análise de dados, design de soluções técnicas, pesquisa profunda e outros cenários que exigem raciocínio avançado:
# Configuração de prioridade de qualidade
config_quality_first = {
"thinking_level": "high",
"max_tokens": 8000,
"timeout": 180,
"stream": True # Recomendado usar streaming para tarefas longas
}
Efeito esperado:
- Tempo de resposta: 30-120 segundos
- Melhor qualidade de raciocínio
Tabela de Decisão para Escolha de Configuração
| Sua necessidade | thinking_level Recomendado | max_tokens Recomendado | timeout Recomendado |
|---|---|---|---|
| Resposta rápida, questão simples | minimal | 500-1000 | 15-30s |
| Tarefas diárias, qualidade média | low | 1500-2500 | 30-60s |
| Boa qualidade, tempo de espera aceitável | medium | 2500-4000 | 60-90s |
| Melhor qualidade, tarefas complexas | high | 4000-8000 | 120-180s |
💡 Sugestão de escolha: A configuração ideal depende do seu cenário específico e das exigências de qualidade. Sugerimos realizar testes práticos através da plataforma APIYI (apiyi.com) para encontrar a melhor opção para você. A plataforma suporta chamadas unificadas para o Gemini 3 Flash Preview, facilitando a comparação rápida entre diferentes configurações.
Dicas Avançadas de Otimização de Resposta para o Gemini 3 Flash Preview
Dica 1: Use saída em streaming para melhorar a experiência do usuário
Mesmo que o tempo total de resposta não mude, a saída em streaming melhora significativamente a percepção de velocidade pelo usuário:
# Exemplo de saída em streaming
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": prompt}],
stream=True,
extra_body={"thinking_level": "low"}
)
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
Vantagens:
- O usuário vê resultados parciais imediatamente
- Reduz a "ansiedade de espera"
- Permite decidir se deseja continuar durante o processo de geração
Dica 2: Ajuste os parâmetros dinamicamente com base na complexidade da entrada
def estimate_complexity(prompt: str) -> str:
"""Estima a complexidade da tarefa com base nas características do comando"""
indicators = {
"high": ["análise", "comparação", "por que", "princípio", "profundo", "explicação detalhada"],
"medium": ["como", "passos", "método", "introdução"],
"low": ["o que é", "simples", "rápido", "uma frase"]
}
prompt_lower = prompt.lower()
for level, keywords in indicators.items():
if any(kw in prompt_lower for kw in keywords):
return level
return "low" # Baixa complexidade por padrão
def get_optimized_config(prompt: str) -> dict:
"""Obtém configuração otimizada baseada no comando (prompt)"""
complexity = estimate_complexity(prompt)
configs = {
"low": {"thinking_level": "minimal", "max_tokens": 1000, "timeout": 20},
"medium": {"thinking_level": "low", "max_tokens": 2500, "timeout": 45},
"high": {"thinking_level": "medium", "max_tokens": 4000, "timeout": 90}
}
return configs.get(complexity, configs["low"])
Dica 3: Implemente um mecanismo de tentativa (retry)
Para problemas ocasionais de timeout, você pode implementar um sistema de retry inteligente:
import time
from typing import Optional
def call_with_retry(
client,
prompt: str,
max_retries: int = 3,
initial_timeout: int = 30
) -> Optional[str]:
"""Chamada com mecanismo de retry"""
for attempt in range(max_retries):
try:
timeout = initial_timeout * (attempt + 1) # Timeout incremental
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": prompt}],
max_tokens=2000,
timeout=timeout,
extra_body={"thinking_level": "low"}
)
return response.choices[0].message.content
except Exception as e:
print(f"Tentativa {attempt + 1} falhou: {e}")
if attempt < max_retries - 1:
time.sleep(2 ** attempt) # Exponential backoff
continue
return None

Referência de Dados de Desempenho do Gemini 3 Flash Preview
De acordo com os dados de teste da Artificial Analysis, o desempenho do Gemini 3 Flash Preview é o seguinte:
| Métrica de Desempenho | Valor | Descrição |
|---|---|---|
| Taxa de transferência bruta | 218 tokens/seg | Velocidade de saída |
| Comparado ao 2.5 Flash | 22% mais lento | Devido ao aumento da capacidade de raciocínio |
| Comparado ao GPT-5.1 high | 74% mais rápido | 125 tokens/seg |
| Comparado ao DeepSeek V3.2 | 627% mais rápido | 30 tokens/seg |
| Preço de entrada (Input) | $0.50/1M tokens | |
| Preço de saída (Output) | $3.00/1M tokens |
Equilíbrio entre Desempenho e Custo
| Configuração | Velocidade de Resposta | Consumo de Tokens | Custo-benefício |
|---|---|---|---|
| minimal thinking | Mais rápido | Mínimo | Máximo |
| low thinking | Rápido | Baixo | Alto |
| medium thinking | Médio | Médio | Médio |
| high thinking | Lento | Alto | Escolha para máxima qualidade |
💰 Otimização de Custos: Para projetos sensíveis ao orçamento, considere chamar a API do Gemini 3 Flash Preview através da plataforma APIYI (apiyi.com). Esta plataforma oferece métodos de cobrança flexíveis e, combinada com as técnicas de otimização de velocidade deste artigo, permite obter o melhor custo-benefício mantendo os custos sob controle.
Perguntas Frequentes (FAQ) sobre Otimização da Velocidade de Resposta do Gemini 3 Flash Preview
Q1: Por que a resposta continua lenta mesmo definindo um limite em max_tokens?
O max_tokens limita apenas o comprimento da saída e não afeta o processo de raciocínio do modelo. Se a resposta estiver lenta principalmente devido ao tempo de reflexão, você precisa configurar simultaneamente o parâmetro thinking_level como minimal ou low. Além disso, através da plataforma APIYI (apiyi.com), você pode obter serviços de API estáveis, o que, somado às técnicas de configuração de parâmetros deste artigo, melhora efetivamente a velocidade de resposta.
Q2: Configurar o thinking_level como minimal afeta a qualidade da resposta?
Haverá algum impacto, mas para tarefas simples a diferença não é grande. O nível minimal é ideal para perguntas e respostas rápidas, diálogos simples e cenários diretos. Se a tarefa envolver raciocínio lógico complexo, recomenda-se usar os níveis low ou medium. Sugerimos realizar testes A/B na plataforma APIYI (apiyi.com) para comparar a qualidade da saída em diferentes níveis de thinking_level e encontrar o ponto de equilíbrio ideal para o seu negócio.
Q3: O que é mais rápido: saída em fluxo (streaming) ou não-streaming?
O tempo total de geração é o mesmo, mas a experiência do usuário com a saída em fluxo (streaming) é muito superior. No modo streaming, o usuário pode ver partes do resultado imediatamente, enquanto o modo não-streaming exige esperar que toda a geração seja concluída. Para tarefas com tempo de geração mais longo, recomendamos fortemente o uso de streaming.
Q4: Como determinar qual deve ser o tempo de timeout?
O timeout deve ser configurado com base na extensão de saída esperada e no nível de thinking_level:
- minimal + 1000 tokens: 15-30 segundos
- low + 2000 tokens: 30-60 segundos
- medium + 4000 tokens: 60-90 segundos
- high + 8000 tokens: 120-180 segundos
A dica é testar primeiro com um timeout mais longo para observar o tempo de resposta real e depois ajustar conforme necessário.
Q5: O parâmetro antigo thinking_budget ainda funciona?
Sim, ele pode continuar sendo usado, mas o Google recomenda migrar para o parâmetro thinking_level para obter um desempenho mais previsível. Atenção: não use os dois parâmetros na mesma requisição. Se você usava anteriormente thinking_budget=0, deve configurar thinking_level="minimal" ao realizar a migração.
Resumo
O segredo para otimizar a velocidade de resposta do Gemini 3 Flash Preview está na configuração correta de três parâmetros fundamentais:
- thinking_level: escolha a profundidade de raciocínio adequada de acordo com a complexidade da tarefa.
- max_tokens: limite a quantidade de tokens com base no comprimento esperado da saída.
- timeout: defina um tempo limite razoável considerando o
thinking_levele o volume de saída.
Para cenários onde "a velocidade de resposta é prioritária e a precisão absoluta não é crítica", a configuração recomendada é:
- thinking_level:
minimaloulow - max_tokens: ajuste conforme a necessidade real para evitar saídas excessivamente longas.
- timeout: ajuste proporcionalmente para evitar que a resposta seja interrompida.
- stream:
True(para melhorar a experiência do usuário)
Recomendamos usar o APIYI (apiyi.com) para testar rapidamente diferentes combinações de parâmetros e encontrar a configuração ideal para o seu caso de uso.
Palavras-chave: Gemini 3 Flash Preview, otimização de velocidade de resposta, thinking_level, max_tokens, configuração de timeout, otimização de chamadas de API
Referências:
- Documentação oficial do Google AI: ai.google.dev/gemini-api/docs/gemini-3
- Google DeepMind: deepmind.google/models/gemini/flash/
- Testes de performance da Artificial Analysis: artificialanalysis.ai/articles/gemini-3-flash-everything-you-need-to-know
Este artigo foi escrito pela equipe técnica do APIYI Team. Para mais dicas sobre o uso de modelos de IA, visite help.apiyi.com