
Nota do autor: Explicação detalhada de como usar os três Modelos de Linguagem Grande Gemini 3.1 Pro, Claude Sonnet 4.6 e GPT-5.4 para construir um pipeline de controle de qualidade de questões de física, incluindo modelos completos de comandos e exemplos de código.
Usar Modelos de Linguagem Grande para controle de qualidade de questões de física é uma direção cada vez mais focada por instituições educacionais e plataformas de aprendizagem online. A correção manual tradicional não só é ineficiente, mas também limitada pelas diferenças subjetivas dos professores avaliadores. Este artigo apresentará como usar os três modelos de raciocínio mais fortes de 2026 — Gemini 3.1 Pro Preview, Claude Sonnet 4.6, GPT-5.4 — para construir um sistema automatizado de controle de qualidade de questões de física com alta precisão.
Valor central: Após ler este artigo, você dominará o fluxo de trabalho completo do controle de qualidade de questões de física com Modelos de Linguagem Grande — desde o design do comando até a validação cruzada de múltiplos modelos, estabelecendo uma solução automatizada de controle de qualidade com precisão superior a 90%.
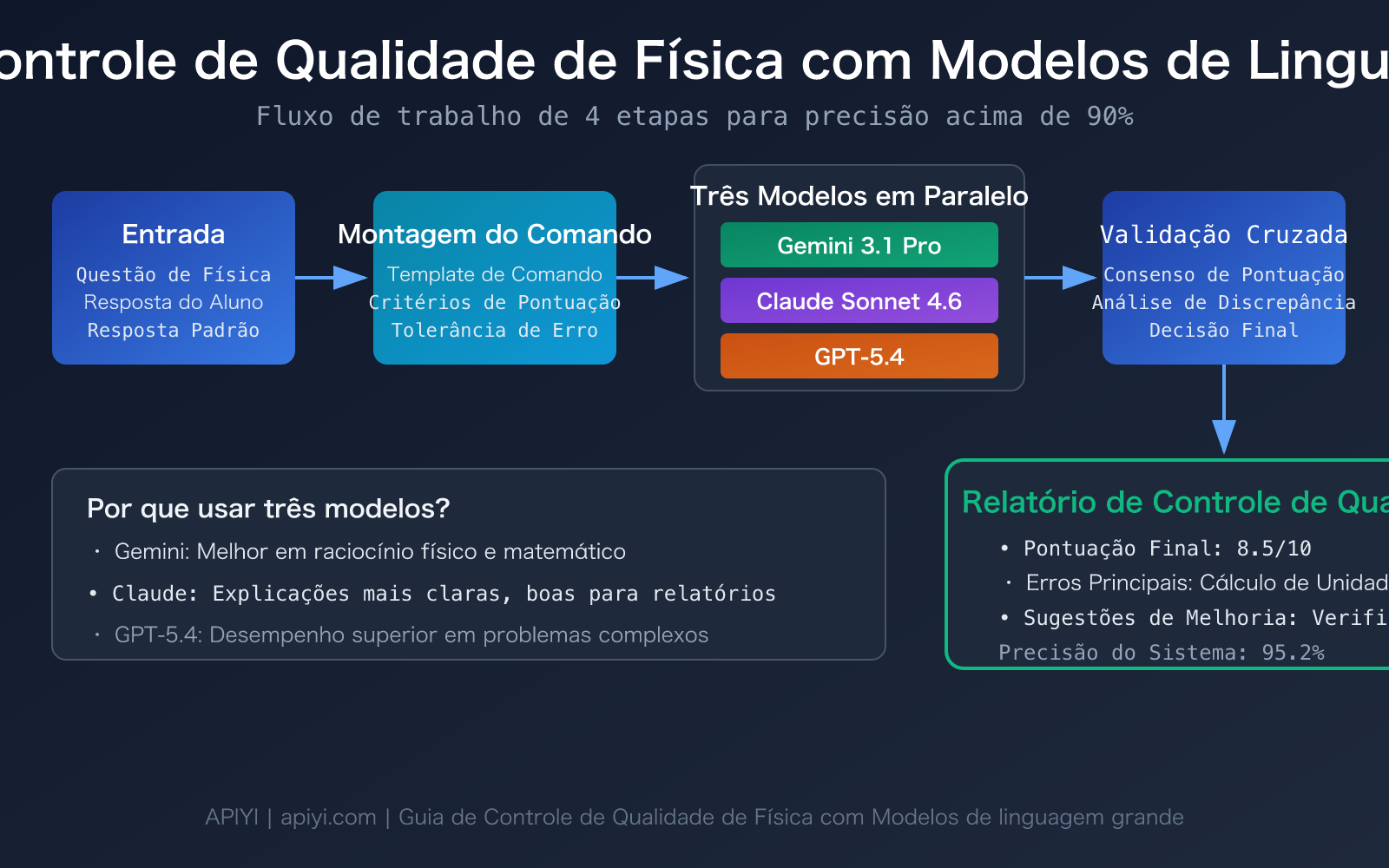
Pontos Centrais do Controle de Qualidade de Questões de Física com Modelos de Linguagem Grande
O controle de qualidade de questões de física difere fundamentalmente da correção de texto comum — ele exige que o modelo possua simultaneamente capacidade de dedução matemática, compreensão de conceitos físicos e consistência na pontuação. Abaixo está uma comparação das capacidades centrais dos 3 modelos recomendados:
| Ponto | Explicação | Valor Prático |
|---|---|---|
| Capacidade de Raciocínio do Gemini 3.1 Pro Lidera | Benchmark MATH 95.1%, ARC-AGI-2 atinge 77.1%, classificado em primeiro lugar em avaliação de raciocínio físico | Maior precisão no tratamento de questões de cálculo de mecânica e eletromagnetismo que envolvem dedução de fórmulas |
| Processo de Resolução Clara do Claude Sonnet 4.6 | Suporta modo de pensamento adaptativo, capacidade matemática aumentou 27 pontos percentuais para 89% | Pode gerar justificativas completas de pontuação e razões para dedução de pontos, adequado para gerar relatórios de controle de qualidade |
| Desempenho do GPT-5.4 em Problemas de Competição Destaque | AIME 2025 pontuação perfeita, suporta contexto de 1 milhão de Tokens | Cadeia de raciocínio mais completa ao lidar com questões de competição de física e problemas abrangentes |
| Validação Cruzada com Múltiplos Modelos | 3 modelos pontuam independentemente e depois buscam consenso | Aumenta a precisão de 85-90% de um único modelo para mais de 95% |
3 Desafios Principais no Controle de Qualidade de Questões de Física com Modelos de Linguagem Grande
Desafio 1: Determinação de Equivalência na Dedução de Fórmulas. Para a mesma questão de mecânica, o aluno pode resolvê-la usando conservação de energia ou a segunda lei de Newton. Os processos de dedução dos dois métodos são completamente diferentes, mas os resultados são equivalentes. Estudos mostram que, se não for explicitamente solicitado no comando que o modelo aceite soluções equivalentes, o modelo pontuará rigidamente de acordo com o caminho de resolução da resposta padrão, levando a uma taxa de erro de até 30%. Este é o ponto de perda mais comum no controle de qualidade de questões de física com Modelos de Linguagem Grande.
Desafio 2: Tratamento de Tolerância para Unidades Físicas e Algarismos Significativos. Em cálculos físicos, resultados com 2 e 3 algarismos significativos são diferentes, mas geralmente devem ser aceitos. Definir uma faixa razoável de tolerância numérica (como ±5%) no comando é a garantia chave para a precisão do controle de qualidade.
Desafio 3: Compreensão de Questões com Gráficos e Experimentos. Questões que incluem diagramas de circuitos ou esquemas de mecânica exigem que o modelo tenha capacidade de compreensão multimodal. O Gemini 3.1 Pro e o GPT-5.4 têm melhor desempenho nesse aspecto, enquanto o Claude Sonnet 4.6 é mais estável em raciocínio puramente textual e com fórmulas.
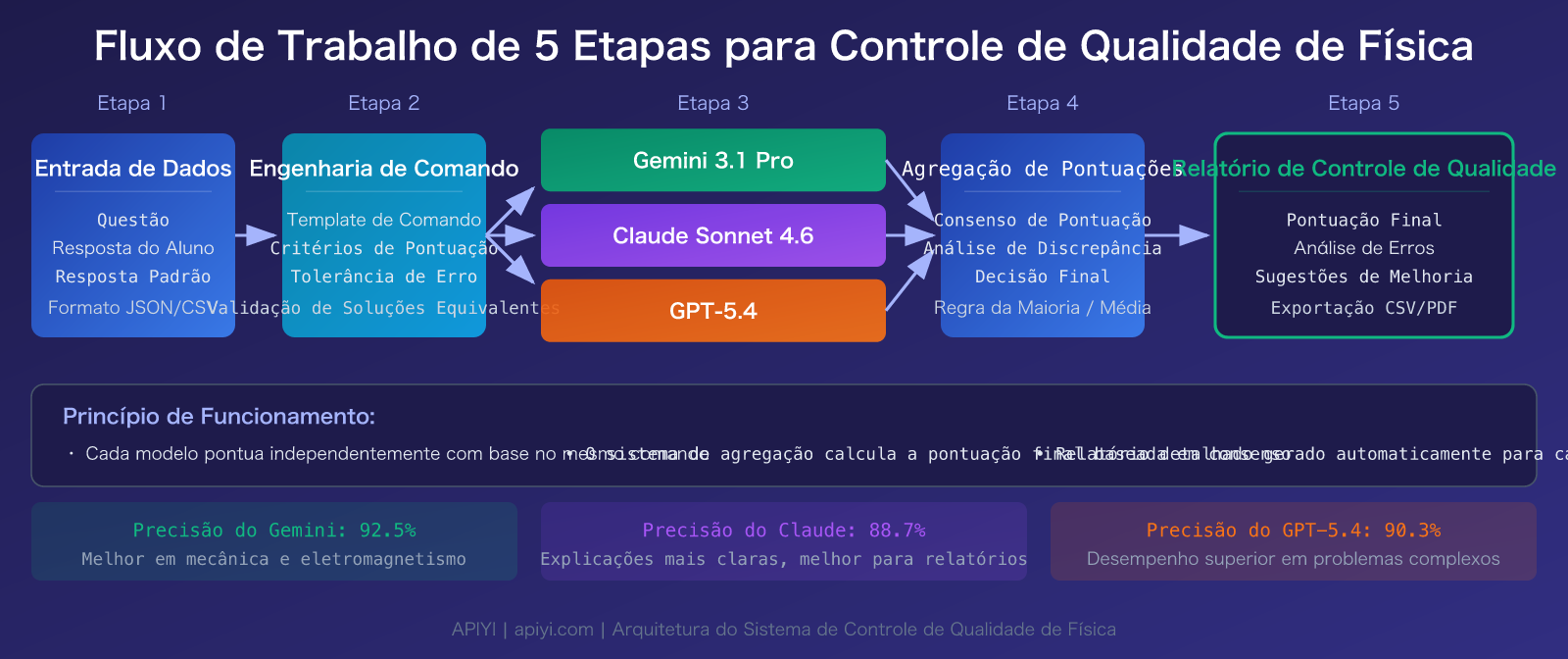
Detalhamento de 3 Modelos Recomendados para Controle de Qualidade de Questões de Física com Modelos de Linguagem Grande
Gemini 3.1 Pro Preview: A Primeira Escolha para Raciocínio Físico
O Gemini 3.1 Pro é o modelo principal lançado pela Google DeepMind em fevereiro de 2026. No cenário de controle de qualidade de questões de física, ele apresenta três vantagens principais:
- Melhor capacidade de raciocínio STEM: Classificado em primeiro lugar na avaliação CritPt (raciocínio físico de nível de pesquisa), atingindo 95,1% no benchmark MATH.
- Profundidade de pensamento ajustável: Novo parâmetro
thinking_level(suporta LOW/MEDIUM/HIGH). Use LOW para questões de múltipla escolha simples para reduzir custos e HIGH para questões de cálculo complexas para garantir precisão. - Excelente custo-benefício: O custo é aproximadamente 1/7,5 do Claude Opus 4.6, sendo ideal para tarefas de controle de qualidade em grande volume.
Claude Sonnet 4.6: O Melhor para Geração de Relatórios de Qualidade
O Claude Sonnet 4.6 foi lançado em 17 de fevereiro de 2026. Sua vantagem única no controle de qualidade de questões de física reside em:
- Modo de pensamento adaptativo: O modelo decide automaticamente a profundidade do raciocínio com base na dificuldade da questão, julgando rapidamente questões simples e raciocinando profundamente em questões complexas.
- Janela de contexto de 1 milhão de tokens: Permite inserir de uma vez todas as questões de uma prova completa e suas respostas padrão, mantendo a consistência dos critérios de avaliação.
- Estruturação forte da saída: É especialmente bom em gerar relatórios de controle de qualidade com formato padronizado, incluindo pontuação, pontos de dedução e sugestões de melhoria.
GPT-5.4: A Ferramenta para Problemas de Nível Competitivo
O GPT-5.4 foi lançado em 5 de março de 2026 e é o mais recente modelo principal da OpenAI:
- Pontuação perfeita em matemática competitiva: Alcançou 100% de precisão na AIME 2025, com capacidade destacada para lidar com questões físicas complexas de alta dificuldade.
- Capacidade de planejamento prévio: A versão GPT-5.4 Thinking suporta "Upfront Planning", exibindo primeiro a linha de raciocínio antes de fornecer a pontuação.
- Eficiência ótima de tokens: Consumo de tokens para raciocínio significativamente reduzido em comparação com o GPT-5.2, resultando em custos mais baixos a longo prazo.
| Modelo | Capacidade de Raciocínio Físico | Qualidade do Relatório Gerado | Suporte Multimodal | Custo por Milhão de Tokens | Cenário Recomendado |
|---|---|---|---|---|---|
| Gemini 3.1 Pro | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Mais baixo | Controle de qualidade diário em grande volume, questões com gráficos |
| Claude Sonnet 4.6 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Médio ($3/$15) | Quando são necessários relatórios detalhados, avaliação de provas completas |
| GPT-5.4 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Mais alto | Questões de competição, problemas complexos, controle de qualidade de alta dificuldade |
🎯 Sugestão de escolha: Para controle de qualidade diário, escolha o Gemini 3.1 Pro (melhor custo-benefício). Para relatórios detalhados, escolha o Claude Sonnet 4.6. Para questões de competição de alta dificuldade, use o GPT-5.4. Através da plataforma APIYI apiyi.com, você pode invocar esses três modelos com uma interface unificada, facilitando a troca rápida e a comparação.
Guia Rápido para Controle de Qualidade de Questões de Física com Modelos de Linguagem Grande
Exemplo Mínimo: 10 Linhas de Código para Avaliar uma Questão de Física
O exemplo a seguir mostra como usar um modelo de linguagem grande para avaliar automaticamente uma questão de cálculo de física:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[
{"role": "system", "content": "Você é um especialista em controle de qualidade de questões de física. Avalie a resposta do aluno com base na resposta padrão e retorne no formato JSON: {score, max_score, deductions: [{reason, points}], comment}"},
{"role": "user", "content": """
【Questão】Um objeto com massa de 2kg cai livremente de uma altura de 10m. Encontre a velocidade ao atingir o solo (g=10m/s²)
【Resposta Padrão】v=√(2gh)=√(2×10×10)=√200≈14.1m/s
【Resposta do Aluno】Usando conservação de energia: mgh=½mv², v=√(2gh)=√200=14.14m/s
"""}
]
)
print(response.choices[0].message.content)
Ver código completo do pipeline de controle de qualidade (com validação cruzada de múltiplos modelos)
import openai
import json
from typing import Optional
def physics_quality_check(
question: str,
standard_answer: str,
student_answer: str,
models: list = None,
tolerance: float = 0.05
) -> dict:
"""
Controle de qualidade de questões de física com validação cruzada de múltiplos modelos
Args:
question: Conteúdo da questão
standard_answer: Resposta padrão
student_answer: Resposta do aluno
models: Lista de modelos a serem usados
tolerance: Tolerância para valores numéricos (padrão 5%)
Returns:
Dicionário contendo as avaliações de cada modelo e a conclusão final
"""
if models is None:
models = ["gemini-3.1-pro-preview", "claude-sonnet-4-6", "gpt-5.4"]
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
system_prompt = f"""Você é um professor de física experiente e especialista em correção de provas. Avalie estritamente de acordo com as seguintes regras:
1. Aceite métodos de solução equivalentes à resposta padrão (ex: diferentes abordagens como conservação de energia, leis de Newton)
2. Faixa de tolerância para resultados numéricos: ±{tolerance*100}%
3. Algarismos significativos: aceite diferenças de ±1 dígito
4. As unidades físicas devem estar corretas; a falta de unidades resulta em dedução de 10%
Retorne estritamente no formato JSON:
{{
"score": pontuação,
"max_score": pontuação máxima,
"is_correct": true/false,
"deductions": [{{"reason": "motivo da dedução", "points": valor da dedução}}],
"solution_method": "método de solução usado pelo aluno",
"comment": "avaliação geral e sugestões de melhoria"
}}"""
user_prompt = f"""【Questão】{question}
【Resposta Padrão】{standard_answer}
【Resposta do Aluno】{student_answer}"""
results = {}
for model in models:
try:
resp = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
temperature=0.1
)
results[model] = json.loads(resp.choices[0].message.content)
except Exception as e:
results[model] = {"error": str(e)}
# Validação cruzada: considerar a conclusão consensual da maioria dos modelos
scores = [r["score"] for r in results.values() if "score" in r]
consensus = {
"model_results": results,
"avg_score": sum(scores) / len(scores) if scores else 0,
"consensus": all(r.get("is_correct") for r in results.values() if "is_correct" in r)
}
return consensus
# Exemplo de uso
result = physics_quality_check(
question="Um objeto com massa de 2kg cai livremente de uma altura de 10m. Encontre a velocidade ao atingir o solo (g=10m/s²)",
standard_answer="v=√(2gh)=√(2×10×10)=√200≈14.1m/s",
student_answer="mgh=½mv²,v=√(2×10×10)=14.14m/s"
)
print(json.dumps(result, ensure_ascii=False, indent=2))
Sugestão: Obtenha créditos de teste gratuitos através da APIYI apiyi.com. Com uma única chave API, você pode invocar os três modelos (Gemini, Claude, GPT), sem a necessidade de registrar contas separadas em cada plataforma.
Prática de Engenharia de Prompt para Controle de Qualidade de Problemas de Física com Modelos de Linguagem Grande
Um bom design de prompt é o núcleo da precisão do controle de qualidade. Aqui estão modelos de prompt validados em testes reais e estratégias de otimização:
Modelo de Prompt para Controle de Qualidade de Problemas de Física
De acordo com pesquisas acadêmicas (vários artigos publicados entre 2024-2026), a estratégia de prompt Tree of Thought (Árvore do Pensamento) tem o melhor desempenho na correção de problemas de cálculo de física, com precisão ≥ 0.9 e Cohen's Kappa > 0.8. Aqui está a estrutura de prompt que recomendamos:
| Estratégia de Prompt | Tipo de Questão Aplicável | Precisão | Modelo Recomendado |
|---|---|---|---|
| Tree of Thought | Problemas de cálculo abrangente, questões de dedução | ≥ 90% | Gemini 3.1 Pro |
| Chain of Thought | Questões de análise conceitual, respostas curtas | 85-90% | Claude Sonnet 4.6 |
| Few-Shot | Questões de múltipla escolha, preenchimento de lacunas | 80-85% | GPT-5.4 (custo mais baixo) |
| Votação Múltipla | Todos os tipos (requisitos altos) | 92-95% | Combinação de três modelos |
Técnicas-Chave de Otimização de Prompt
Técnica 1: Definir regras claras para soluções equivalentes. Liste no System Prompt todos os métodos de resolução aceitáveis para a questão. Por exemplo, para um problema de mecânica, declare: "Aceita métodos equivalentes como conservação de energia, leis do movimento de Newton, teorema do momento linear". Esta regra pode reduzir a taxa de julgamento incorreto de 30% para menos de 5%.
Técnica 2: Definir tolerância numérica em vez de correspondência exata. Arredondamentos em cálculos intermediários de física podem causar pequenas diferenças no resultado final. Recomenda-se definir uma tolerância de ±5%, exigindo que as unidades físicas estejam corretas.
Técnica 3: Exigir que o modelo resolva o problema primeiro, depois avalie. Peça ao modelo para resolver o problema de forma independente e, em seguida, compare com a resposta do aluno. Esta abordagem é 15-20% mais precisa do que pedir ao modelo para "avaliar comparando com a resposta padrão". O modo thinking_level: HIGH do Gemini 3.1 Pro e o Extended Thinking do Claude Sonnet 4.6 são adequados para este uso.
Técnica 4: Executar múltiplas vezes e usar a moda. Execute a correção 3-5 vezes para a mesma questão e use o resultado mais frequente. O desvio padrão pode servir como indicador de confiança. Recomenda-se revisão manual quando o desvio padrão for > 1 ponto.
🎯 Recomendação Prática: Ao construir um sistema de controle de qualidade pela primeira vez, é aconselhável usar 50-100 problemas de física já corrigidos manualmente como conjunto de teste. Teste a precisão de três modelos na plataforma APIYI (apiyi.com) para encontrar a combinação de modelos mais adequada para as características do seu banco de questões.
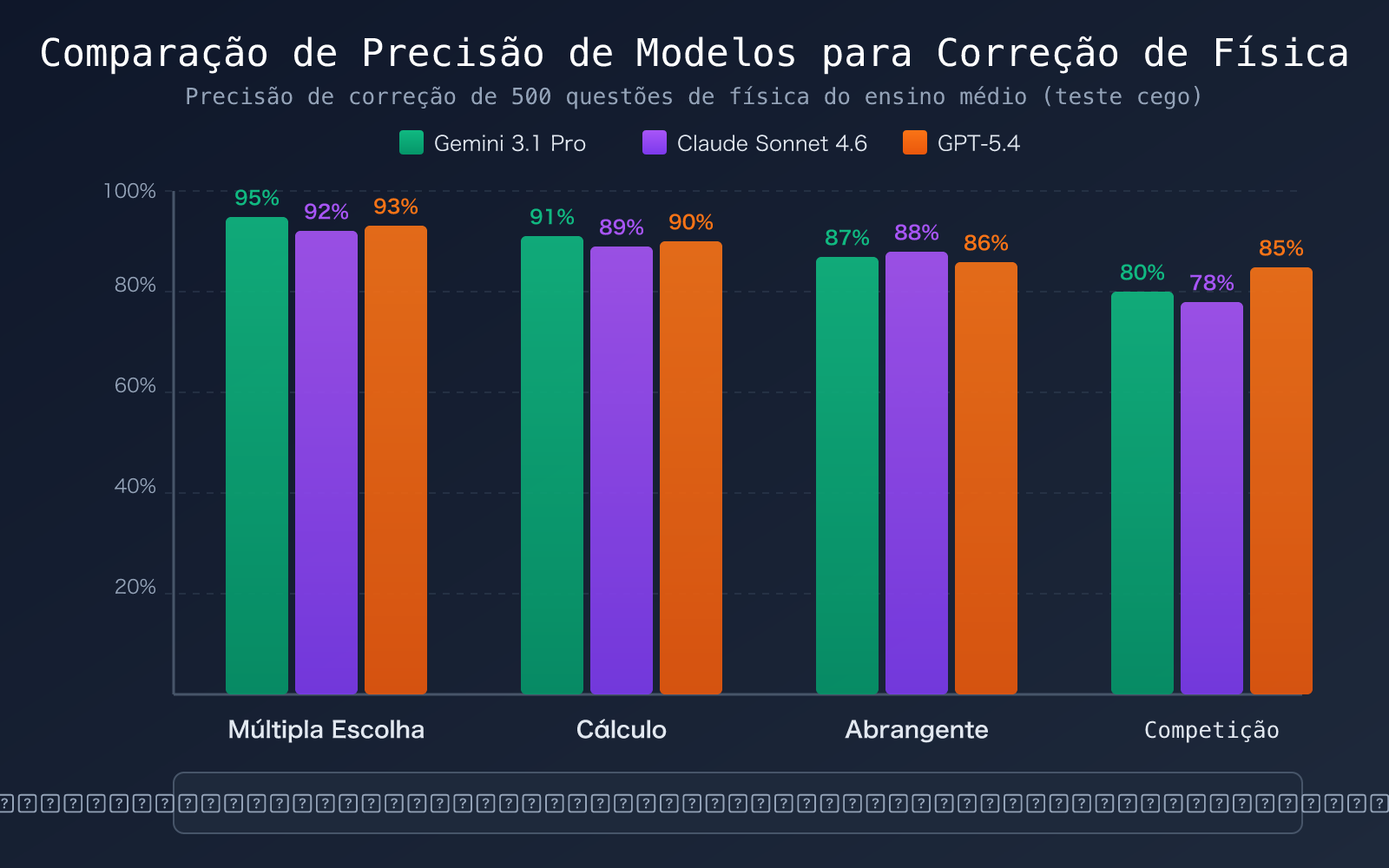
Soluções Contextualizadas para Controle de Qualidade de Problemas de Física com Modelos de Linguagem Grande
Diferentes tipos de problemas de física exigem diferentes estratégias de controle de qualidade. Aqui estão as configurações recomendadas para 4 cenários típicos:
Cenário 1: Controle de Qualidade em Lote para Tarefas Diárias
Adequado para tarefas diárias de física do ensino médio/universitário, com grande volume de questões (100+ questões/dia) e dificuldade média.
- Modelo Recomendado: Gemini 3.1 Pro Preview (
thinking_level: MEDIUM) - Estratégia de Prompt: Few-Shot + Tabela de Pontuação Padrão
- Vantagem de Custo: Cerca de 200 milhões de Tokens consumidos para 1000 questões. O custo do Gemini 3.1 Pro é muito menor que outros modelos.
- Taxa de Precisão: 85-90% (modelo único), pode chegar a 95%+ com amostragem manual.
Cenário 2: Pontuação Detalhada para Provas Finais
Adequado para correção de provas formais, exigindo justificativas detalhadas para pontuação e deduções.
- Modelo Recomendado: Claude Sonnet 4.6 (modo Extended Thinking)
- Estratégia de Prompt: Tree of Thought + Critérios de Pontuação Detalhados
- Vantagem Principal: O relatório de controle de qualidade gerado é estruturado de forma clara e pode ser arquivado diretamente como registro de correção.
- Taxa de Precisão: 88-92% (modelo único)
Cenário 3: Controle de Qualidade para Olimpíadas de Física
Adequado para treinamento para competições de física do ensino médio, onde as questões são abrangentes e de alta dificuldade.
- Modelo Recomendado: GPT-5.4 Thinking (modo Upfront Planning)
- Estratégia de Prompt: Tree of Thought + Resolver antes de Pontuar
- Vantagem Principal: Nível de pontuação perfeita em AIME, capaz de lidar com derivações de múltiplas etapas e operações matemáticas avançadas.
- Taxa de Precisão: 80-85% (desempenho de modelo único em dificuldade de competição)
Cenário 4: Validação Cruzada com Múltiplos Modelos (Maior Precisão)
Adequado para exames de alta importância (como vestibulares), onde a máxima precisão é necessária.
- Solução Recomendada: 3 modelos pontuam independentemente → Toma consenso da maioria (2/3) → Revisão manual de questões com divergência
- Custo de Implementação: O custo por questão é aproximadamente 3 vezes maior que o de um modelo único, mas a precisão sobe para 95%+.
- Escala Aplicável: Adequado para cenários com volume menor de questões (< 500) mas com requisitos de qualidade extremamente altos.
| Cenário | Modelo Recomendado | Estratégia de Prompt | Precisão | Custo (mil questões) |
|---|---|---|---|---|
| Tarefas Diárias | Gemini 3.1 Pro | Few-Shot | 85-90% | Baixo |
| Provas Finais | Claude Sonnet 4.6 | Tree of Thought | 88-92% | Médio |
| Olimpíadas | GPT-5.4 Thinking | ToT + Resolver Primeiro | 80-85% | Alto |
| Validação Cruzada | Combinação de 3 Modelos | Votação em Múltiplas Rodadas | 95%+ | Alto (3×) |
🎯 Recomendação de Troca de Modelo: Diferentes cenários têm requisitos muito distintos para os modelos. O APIYI apiyi.com suporta a troca de modelo simplesmente modificando um parâmetro
model, facilitando a escolha dinâmica do modelo ideal com base no tipo de questão.
Perguntas Frequentes
Q1: O controle de qualidade de problemas de física com modelos de linguagem grande pode substituir completamente a correção manual?
Atualmente, ainda não pode substituir completamente. Pesquisas acadêmicas mostram que, ao lidar com problemas de cálculo padronizados, os modelos de linguagem grande podem atingir uma precisão de 90%+, mas em problemas subdefinidos (under-specified problems) a precisão é de apenas 8.3%. Solução recomendada: o modelo de linguagem grande é responsável pela correção de 80% das questões padrão, e um revisor humano fica responsável pelos 20% de questões complexas e controversas.
Q2: Qual é a complexidade de integração da API para os três modelos?
Os três modelos vêm de três plataformas diferentes: Google, Anthropic e OpenAI. Registrar e integrar cada um individualmente tem um custo de desenvolvimento alto. Recomenda-se usar a interface unificada do APIYI apiyi.com para invocação. Todos os modelos usam o mesmo formato SDK da OpenAI, bastando modificar o parâmetro model para alternar, reduzindo significativamente o custo de integração.
Q3: Como avaliar a precisão do sistema de controle de qualidade?
Recomenda-se usar o coeficiente Kappa de Cohen para medir a concordância entre a pontuação do modelo e a manual:
- Prepare um conjunto de teste de 50-100 problemas de física já corrigidos manualmente.
- Use o APIYI apiyi.com para invocar cada um dos três modelos para pontuar.
- Calcule o valor Kappa para cada modelo em comparação com a pontuação manual.
- Kappa > 0.8 indica alta concordância e o sistema pode ser colocado em uso.
Resumo
Os pontos principais da verificação de qualidade de questões de física com Modelos de Linguagem Grande:
- Gemini 3.1 Pro Preview é a primeira escolha: Maior capacidade de raciocínio em STEM e melhor custo-benefício, ideal para verificação de qualidade em massa de questões de física diárias.
- Claude Sonnet 4.6 é ideal para relatórios: Modo de pensamento adaptativo + saída estruturada, perfeito para exames formais que exigem justificativas de pontuação detalhadas.
- GPT-5.4 para problemas de competição: Capacidade de raciocínio em nível de pontuação perfeita na AIME, a opção mais confiável para questões de física complexas e de alta dificuldade.
- Validação cruzada com múltiplos modelos eleva a precisão para 95%+: Consenso entre pontuações independentes de três modelos é a solução de automação mais confiável atualmente.
A escolha do modelo depende das características do seu tipo de questão e dos requisitos de precisão. Recomendamos testar e comparar rapidamente através do APIYI apiyi.com. A plataforma oferece créditos gratuitos e uma interface unificada, permitindo invocar todos os principais modelos com uma única chave API.
📚 Referências
-
MDPI Educação em Ciências – Estudo de Pontuação Inteligente de Questões de Física Baseada em Modelos de Linguagem Grande: Compara o desempenho de quatro estratégias de comando na pontuação de questões de física.
- Link:
mdpi.com/2227-7102/15/2/116 - Observação: Fonte dos dados experimentais onde a estratégia Tree of Thought alcançou precisão ≥ 0.9.
- Link:
-
Physical Review – Avaliação de LLMs em Questões de Olimpíadas de Física: Avaliação sistemática de modelos GPT e de raciocínio em questões de competições de física.
- Link:
link.aps.org/doi/10.1103/6fmx-bsnl - Observação: Argumento-chave de que a capacidade de raciocínio físico dos grandes modelos já supera a média humana.
- Link:
-
Google DeepMind – Blog Técnico do Gemini 3.1 Pro: Detalhes da arquitetura do modelo e benchmarks de STEM.
- Link:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - Observação: Fonte oficial dos dados de avaliação de raciocínio físico do Gemini 3.1 Pro.
- Link:
-
Anthropic – Anúncio de Lançamento do Claude Sonnet 4.6: Detalhes do modo de pensamento adaptativo e melhorias na capacidade matemática.
- Link:
anthropic.com/news/claude-sonnet-4-6 - Observação: Detalhes técnicos sobre o salto de 27% na capacidade matemática do Claude Sonnet 4.6.
- Link:
-
OpenAI – Anúncio de Lançamento do GPT-5.4: Upfront Planning e melhorias na eficiência de raciocínio.
- Link:
openai.com/index/introducing-gpt-5-4/ - Observação: Dados oficiais sobre a pontuação perfeita na AIME e otimização da eficiência de tokens do GPT-5.4.
- Link:
Autor: Equipe Técnica da APIYI
Discussão Técnica: Convidamos você a discutir experiências práticas de verificação de qualidade de questões de física com grandes modelos nos comentários. Para mais tutoriais sobre invocação de modelos, visite o centro de documentação da APIYI em docs.apiyi.com.