
作者注:深度分析 Claude Opus 4.6 Thinking 模型通過 API 中轉調用時 content should be a valid list 報錯的根本原因,解析 /v1/messages 與 /v1/chat/completions 兩種端點的格式差異和兼容方案
你有沒有遇到過這個場景:用 claude-opus-4-6-thinking 模型,通過 /v1/chat/completions(OpenAI 格式)調用一切正常,但切到 /v1/messages(Anthropic 原生格式)反而報錯 content: Input should be a valid list?這個看起來違反直覺的現象,其實揭示了 Thinking 模型在兩種 API 格式之間的深層兼容性問題。本文將從 API 底層格式出發,徹底講清楚報錯原因和正確的調用方式。
核心價值: 讀完本文,你將理解 Thinking 模型在兩種 API 格式中的行爲差異,解決 content should be a valid list 報錯,並掌握多輪對話中 thinking blocks 的正確處理方式。

Claude Thinking 模型 API 兼容性核心要點
先直接回答這個"反直覺"現象的本質。
| 要點 | 說明 | 影響 |
|---|---|---|
| 報錯根因 | 中轉將 content: "string" 傳給了期望 content: [list] 的 /v1/messages |
格式不匹配導致 400 錯誤 |
| OpenAI 格式能跑通 | /v1/chat/completions 允許 content 爲字符串,自動剝離 thinking blocks |
格式簡單,兼容性好 |
| Anthropic 格式報錯 | /v1/messages 嚴格要求 content 爲內容塊列表,且 thinking 必須排首位 |
中轉格式轉換不完整 |
| 模型名差異 | claude-opus-4-6-thinking 是中轉平臺別名,官方模型名是 claude-opus-4-6 |
thinking 通過參數而非模型名啓用 |
| 正確做法 | 使用 OpenAI 格式調用,或確保中轉正確處理 content 格式轉換 | 選對端點 + 正確傳參 |
Claude Thinking 模型 API 報錯的技術本質
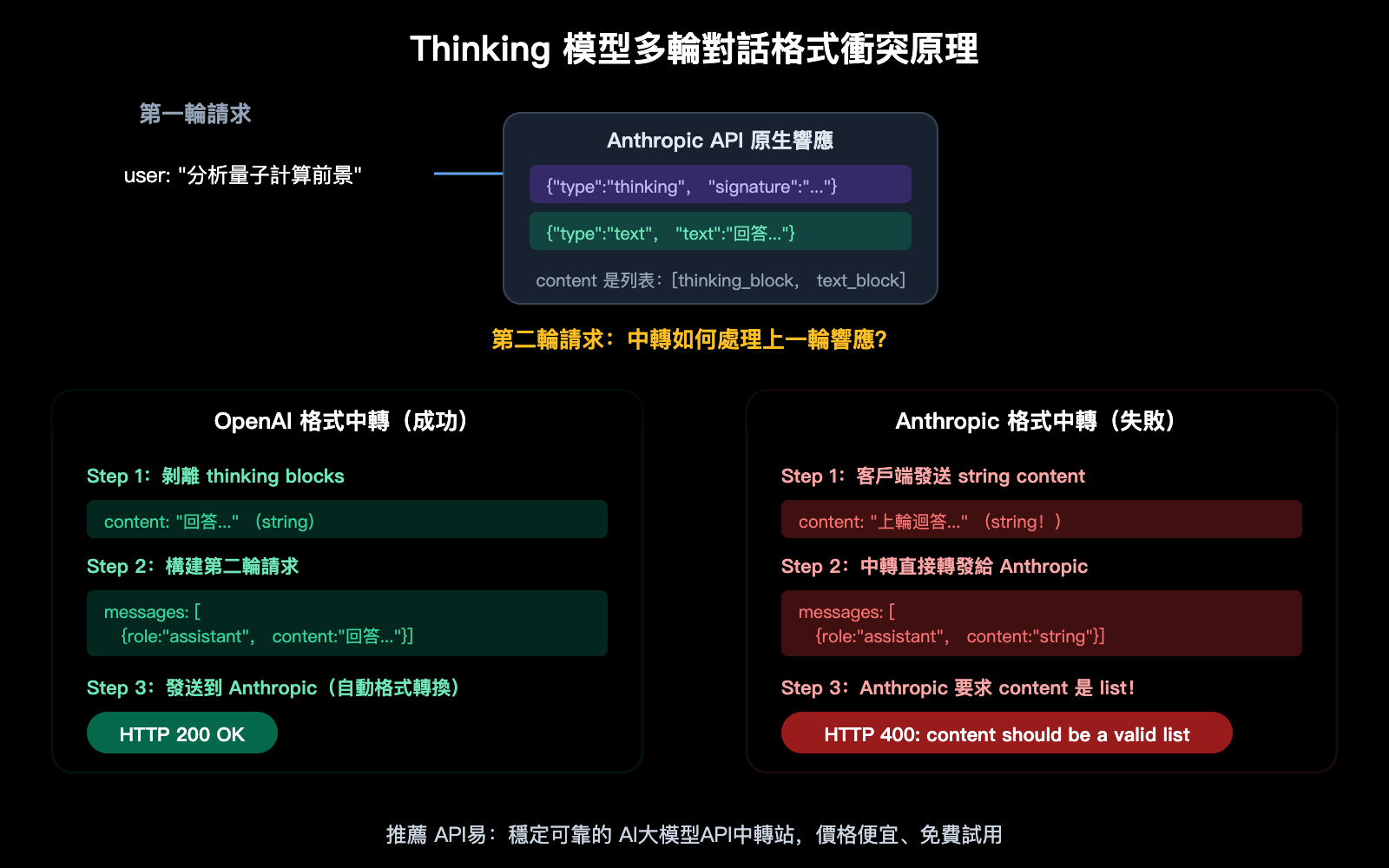
這個錯誤信息 content: Input should be a valid list 揭示了一個關鍵的格式差異:
Anthropic 原生 API(/v1/messages) 的 content 字段必須是一個 內容塊數組(list):
{
"role": "assistant",
"content": [
{"type": "thinking", "thinking": "讓我分析這個問題...", "signature": "CpcH..."},
{"type": "text", "text": "這是我的回答..."}
]
}
OpenAI 兼容格式(/v1/chat/completions) 的 content 可以是 純字符串:
{
"role": "assistant",
"content": "這是我的回答..."
}
當 API 中轉平臺(如 APIYI 後臺)的渠道配置爲 /v1/messages 格式時,如果上游客戶端發送的是 OpenAI 格式的字符串 content,中轉需要把 "string" 轉換爲 [{"type": "text", "text": "string"}]。如果這個轉換不完整——特別是對 Thinking 模型的響應回傳到下一輪對話時——就會觸發 Input should be a valid list 錯誤。
Claude Thinking 模型 API 兩種端點格式詳細對比
這是理解這個問題的關鍵:兩種端點對 content 字段的要求根本不同。
Claude Thinking 模型 API 格式差異
| 對比維度 | /v1/chat/completions(OpenAI) |
/v1/messages(Anthropic) |
|---|---|---|
| content 類型 | string 或 array |
必須是 array(內容塊列表) |
| thinking 返回 | 不返回詳細思考過程 | 返回 thinking 類型內容塊 |
| signature 傳遞 | 放在 provider_specific_fields |
直接在 thinking 塊的 signature 字段 |
| 多輪對話 | 純文本傳遞,無需關心 thinking 排序 | assistant 消息必須以 thinking 塊開頭 |
| thinking 啓用方式 | 模型名後綴或參數 | thinking: {"type": "adaptive"} 參數 |
| prompt caching | 不支持 | 支持 |
| 思考過程可見 | 不可見 | 可見(summarized thinking) |
Claude Thinking 模型 API 請求格式對比
OpenAI 格式調用(推薦用於中轉場景):
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-6-thinking", # 中轉平臺別名
messages=[
{"role": "user", "content": "分析量子計算的商業前景"}
],
max_tokens=16000
)
print(response.choices[0].message.content)
查看 Anthropic 原生格式調用代碼
import anthropic
client = anthropic.Anthropic(api_key="YOUR_API_KEY")
response = client.messages.create(
model="claude-opus-4-6", # 官方模型名,不帶 -thinking
max_tokens=16000,
thinking={
"type": "adaptive" # 通過參數啓用 thinking
},
messages=[
{"role": "user", "content": "分析量子計算的商業前景"}
]
)
# 響應中 content 是列表,包含 thinking 塊和 text 塊
for block in response.content:
if block.type == "thinking":
print(f"[思考過程] {block.thinking[:100]}...")
elif block.type == "text":
print(f"[回答] {block.text}")
關鍵區別:
- 模型名是
claude-opus-4-6(不帶-thinking後綴) - thinking 通過
thinking={"type": "adaptive"}參數啓用 - 響應 content 是內容塊列表,不是字符串
- 多輪對話時必須把完整的 content 列表(含 thinking 塊)傳回
🎯 調用建議: 如果你通過中轉平臺調用 Claude Thinking 模型,優先使用
/v1/chat/completions(OpenAI 格式),兼容性最好。
API易 apiyi.com 平臺的 OpenAI 兼容端點已針對 Thinking 模型做了格式適配,自動處理 thinking blocks 的轉換。
Claude Thinking 模型 API 爲什麼 OpenAI 格式反而能跑通
這是最違反直覺的部分:用"非原生"的 OpenAI 格式調用 Claude Thinking 模型,兼容性反而更好。原因有三:
原因一:content 格式寬容度不同
OpenAI 格式允許 content 是純字符串 "hello",也允許是內容塊數組 [{"type":"text","text":"hello"}]。Anthropic 原生格式只接受內容塊數組,字符串格式直接報錯。
當客戶端代碼用字符串方式傳遞 content(這是 OpenAI SDK 的默認行爲),中轉如果走 OpenAI 格式通道,客戶端和上游端點格式一致,沒有轉換問題。但如果走 Anthropic 格式通道,字符串就不被接受了。
原因二:thinking blocks 的自動剝離
OpenAI 兼容模式會自動把 Claude 響應中的 thinking blocks 剝離掉,只返回最終文本。這意味着:
- 客戶端不會收到 thinking blocks
- 下一輪對話時不需要傳回 thinking blocks
- 不存在 thinking 塊排序問題
Anthropic 原生格式則要求在多輪對話中完整保留 thinking blocks,並且 assistant 消息必須以 thinking 塊開頭。如果中轉沒有正確處理這個排序要求,就會報錯。
原因三:thoughtSignature 的傳遞問題
如前文所述,Anthropic 格式的 thinking blocks 包含加密簽名(signature),必須原樣回傳。OpenAI 格式直接跳過了這個環節——不返回簽名,也不需要傳回簽名。
🎯 選型建議: 通過 API 中轉調用 Claude Thinking 模型,優先用
/v1/chat/completions格式,避免 thinking blocks 格式兼容問題。
API易 apiyi.com 的 OpenAI 兼容端點已經對 Thinking 模型做了完整適配。
Claude Thinking 模型 API 調用方案對比
Claude Thinking 模型 API 三種調用方案
| 方案 | 端點 | 格式兼容性 | thinking 可見 | prompt caching |
|---|---|---|---|---|
| OpenAI 格式中轉 | /v1/chat/completions |
最好(string content) | 不可見 | 不支持 |
| Anthropic 原生直連 | /v1/messages |
需嚴格遵循格式 | 可見 | 支持 |
| Anthropic 格式中轉 | /v1/messages(中轉) |
取決於中轉實現 | 取決於中轉 | 部分支持 |
Claude Thinking 模型 API 模型名稱差異
不同平臺對 Thinking 模型的命名方式不同,這也是常見混淆點:
| 平臺 | 模型名 | thinking 啓用方式 |
|---|---|---|
| Anthropic 官方 | claude-opus-4-6 |
thinking: {"type": "adaptive"} 參數 |
| API 中轉(如 API易) | claude-opus-4-6-thinking |
模型名後綴隱式啓用 |
| OpenRouter | anthropic/claude-opus-4.6 |
參數啓用 |
| AWS Bedrock | anthropic.claude-opus-4-6-v1 |
參數啓用 |
在 Anthropic 官方 API 中,沒有 claude-opus-4-6-thinking 這個模型名。-thinking 後綴是中轉平臺的命名約定,讓用戶通過模型名直接啓用 thinking 功能,無需手動設置參數。
提示: 如果你在 API易 apiyi.com 使用
claude-opus-4-6-thinking模型名,平臺會自動在請求中添加thinking: {"type": "adaptive"}參數。這樣你用 OpenAI SDK 就能直接獲得 thinking 能力,無需修改代碼。
Claude Thinking 模型 API 常見踩坑和解決方案

常見問題
Q1: 用 OpenAI 格式調 Thinking 模型,會不會失去思考能力?
不會。模型的思考(thinking)過程發生在 Anthropic 服務端,與調用端點格式無關。用 OpenAI 格式調用時,模型仍然會進行完整的思考推理,只是思考過程的文字摘要不會返回給客戶端。最終回答的質量和深度是一樣的——你得到的是"經過深思熟慮的答案",只是看不到"思考過程的文字記錄"。
Q2: 什麼場景必須用 /v1/messages 原生格式?
兩種場景需要原生格式:1)你需要看到模型的思考過程(summarized thinking),用於調試、教育或展示推理鏈;2)你需要使用 prompt caching 降低成本——緩存功能只在 /v1/messages 端點可用。如果這兩個需求都沒有,用 OpenAI 格式更省心。通過 API易 apiyi.com 的 OpenAI 兼容端點調用最簡單。
Q3: APIYI 後臺渠道配置爲 /v1/messages 時,怎麼解決兼容問題?
兩個方案:1)將渠道切換爲 OpenAI 類型(/v1/chat/completions),從根本上避免格式轉換問題;2)如果必須用 /v1/messages 渠道,需要確保中轉層正確地將客戶端的 string content 轉換爲 list 格式,並在多輪對話中正確處理 thinking blocks 的排序和 signature 傳遞。方案 1 更簡單可靠。
Q4: adaptive thinking 和舊版 extended thinking 有什麼區別?
Opus 4.6 推薦使用 thinking: {"type": "adaptive"}(自適應思考),模型根據問題複雜度自動決定是否思考以及思考多深。舊版 thinking: {"type": "enabled", "budget_tokens": N} 在 Opus 4.6 和 Sonnet 4.6 上已棄用。新版還增加了 effort 參數(low/medium/high/max)來控制思考深度,默認 high。
總結
Claude Thinking 模型 API 兼容性問題的核心要點:
- 報錯根因是 content 格式不匹配: Anthropic 原生 API 嚴格要求 content 爲列表(list),而 OpenAI 格式允許字符串——中轉渠道如果走
/v1/messages但客戶端發的是字符串,就會報Input should be a valid list - OpenAI 格式兼容性更好: 自動剝離 thinking blocks、不需要傳回 signature、content 可以是字符串——中轉場景首選
- -thinking 後綴是中轉約定,不是官方模型名: 官方模型名是
claude-opus-4-6,thinking 通過參數啓用
通過 API 中轉調用 Claude Thinking 模型,最簡單的方案就是統一使用 OpenAI 兼容格式。
推薦通過 API易 apiyi.com 調用,平臺已針對 Thinking 模型做了格式兼容優化,提供免費額度和多模型統一接口。
📚 參考資料
-
Claude API Extended Thinking 文檔: 思考模式的完整 API 參考
- 鏈接:
platform.claude.com/docs/en/build-with-claude/extended-thinking - 說明: 包含 adaptive thinking、effort 參數、內容塊格式的詳細說明
- 鏈接:
-
Claude API OpenAI SDK 兼容性文檔: OpenAI 格式調用 Claude 的官方指南
- 鏈接:
platform.claude.com/docs/en/api/openai-sdk - 說明: 包含兼容性限制和不支持的功能列表
- 鏈接:
-
Claude API 錯誤碼參考: 所有 API 錯誤類型的說明
- 鏈接:
platform.claude.com/docs/en/api/errors - 說明: 包含 invalid_request_error 的具體排查方法
- 鏈接:
-
API易文檔中心: 通過 OpenAI 兼容接口調用 Claude Thinking 模型
- 鏈接:
docs.apiyi.com - 說明: 已針對 Thinking 模型做格式適配,自動處理 thinking blocks 轉換
- 鏈接:
作者: APIYI 技術團隊
技術交流: 歡迎在評論區討論,更多資料可訪問 API易 docs.apiyi.com 文檔中心