
Para programmer ahli di luar sana telah membedah 232 halaman sistem kartu resmi dari Anthropic, dan kesimpulannya bulat: Kemampuan konteks panjang Claude Opus 4.7 mengalami kemunduran serius dibandingkan versi 4.6.
Kesimpulan ini sangat kontras dengan pernyataan dalam blog resmi Anthropic yang menyebutkan, "Opus 4.7 memberikan performa konteks panjang yang paling konsisten dari semua model yang kami uji." Di mana data aslinya? Data tersebut ada di dalam sistem kartu yang mereka publikasikan sendiri—pada tolok ukur MRCR v2 8-needle dengan konteks 1 juta token, Opus 4.6 mencetak skor 78,3%, sementara Opus 4.7 hanya 32,2%. Akurasi ini bukan sekadar turun, tapi anjlok drastis.
Yang lebih menggemparkan komunitas adalah pengakuan Anthropic di sistem kartu tersebut: "Mode extended-thinking 64k pada Opus 4.6 jauh mengungguli 4.7 dalam tugas pengambilan multi-needle konteks panjang." Kutipan ini terus-menerus dikutip oleh programmer senior di Hacker News, X, dan Reddit sebagai bukti resmi bahwa "kemampuan konteks panjang Opus 4.7 mengalami kemunduran."
Artikel ini membedah data nyata, penyebab mendasar, dan solusi untuk kemunduran kemampuan Claude Opus 4.7 pada konteks panjang, berdasarkan sistem kartu resmi Anthropic, ulasan pihak ketiga (Rohan Paul di X, analisis sistem kartu 232 halaman di DEV Community), serta umpan balik langsung dari komunitas programmer.
Nilai Inti: Setelah membaca artikel ini, Anda akan tahu persis—skenario konteks panjang mana yang harus tetap menggunakan 4.6, skenario mana yang masih bisa menggunakan 4.7, dan cara melakukan routing berbasis skenario di lapisan pemanggilan API.
Bukti Resmi Kemunduran Konteks Panjang Claude Opus 4.7
Bagian ini menggunakan data yang dipublikasikan sendiri oleh Anthropic untuk membuktikan fakta kemunduran tersebut.
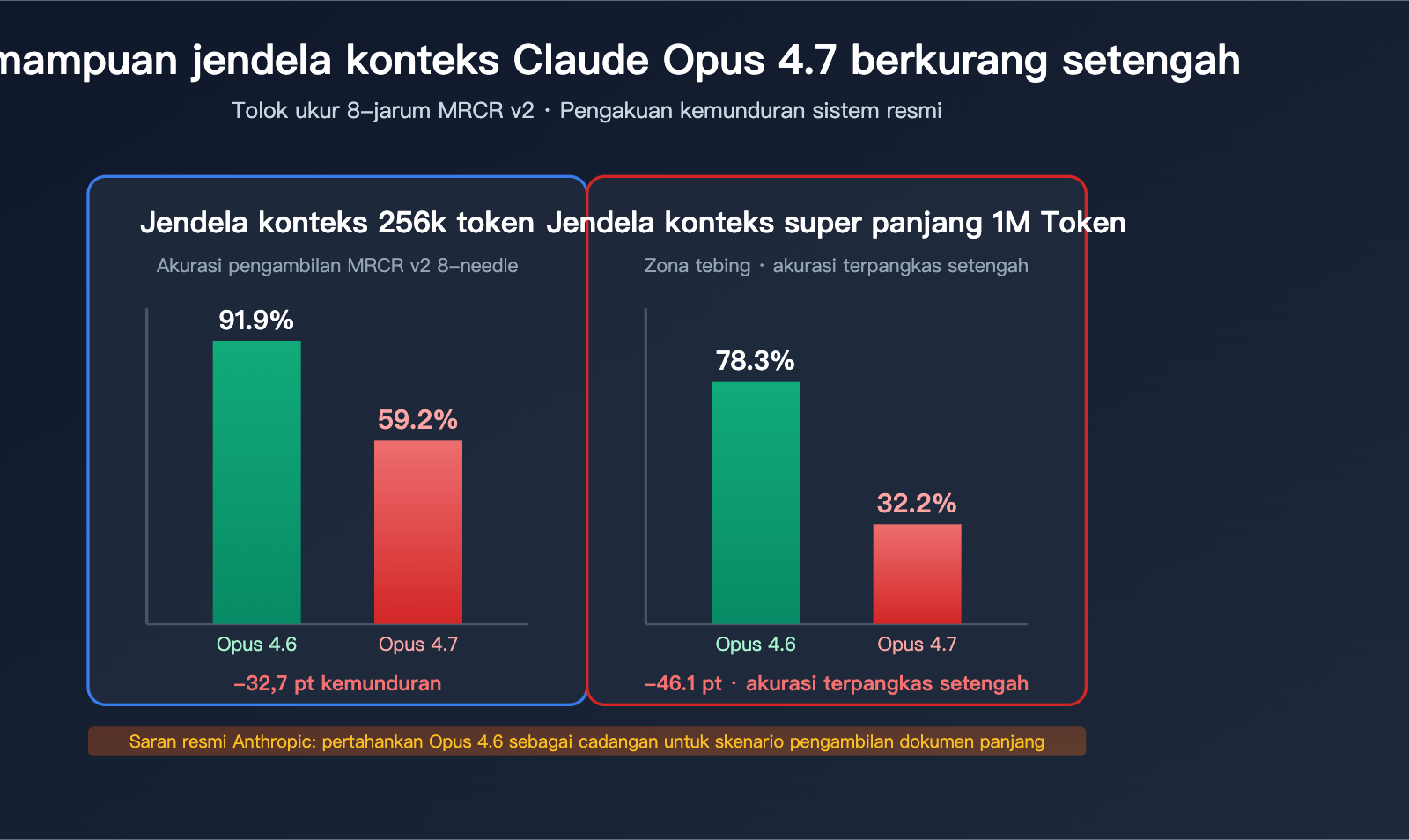
Penurunan Drastis pada Tolok Ukur MRCR v2 8-needle
MRCR v2 (Multi-Round Coreference Resolution, versi 2) adalah tolok ukur standar industri untuk mengukur kemampuan pengambilan multi-needle pada konteks panjang. Cara pengujiannya: menyisipkan 8 fakta spesifik ke dalam teks yang sangat panjang, dan meminta model untuk mengambil serta mereproduksi fakta tersebut. Skornya adalah tingkat kecocokan rata-rata (%).
| Panjang Konteks | Opus 4.6 | Opus 4.7 | Tingkat Penurunan |
|---|---|---|---|
| 256k Token | 91,9% | 59,2% | -32,7pt |
| 1M Token | 78,3% | 32,2% | -46,1pt |
Arti dari angka-angka ini:
- Pada konteks 256k, akurasi pengambilan multi-needle 4.7 jatuh dari "hampir sempurna" menjadi "tidak lulus".
- Pada konteks 1M, akurasi 4.7 anjlok drastis, bahkan kurang dari sepertiganya.
- Pada tolok ukur ini, 4.6 tidak hanya mengungguli 4.7, tetapi juga mengalahkan GPT-5.2 pada jangkauan 256k (dikonfirmasi resmi oleh Rohan Paul).
Rohan Paul memberikan penilaian paling ringkas di platform X: "Opus 4.6 sekarang merebut mahkota sebagai model konteks panjang terbaik." Artinya: Opus 4.6 adalah model konteks panjang terbaik saat ini di tahun 2026—juaranya bukanlah 4.7, bukan juga GPT-5.4.
Pengakuan Anthropic di Sistem Kartu
Yang lebih mengguncang komunitas adalah Anthropic mengakui hal ini sendiri di sistem kartu Opus 4.7. Berikut kutipan halaman 47:
"Opus 4.6 dengan mode extended-thinking 64k mendominasi 4.7 pada pengambilan multi-needle konteks panjang. Untuk sistem produksi yang mengandalkan pengambilan dokumen panjang, kami menyarankan untuk tetap menyediakan 4.6 sebagai opsi fallback."
Artinya: Mode extended-thinking 64k pada Opus 4.6 jauh mengungguli 4.7 dalam pengambilan multi-needle konteks panjang. Untuk sistem produksi yang bergantung pada pengambilan dokumen panjang, disarankan untuk tetap menggunakan 4.6 sebagai opsi cadangan.
Ini adalah pertama kalinya Anthropic secara eksplisit menyarankan pengguna dalam dokumentasi resmi untuk "tidak sepenuhnya bermigrasi" ke versi baru. Pengakuan langka ini menunjukkan bahwa evaluasi internal pun tidak dapat menutupi kemunduran ini.
🎯 Saran Teknis: Jika bisnis Anda melibatkan RAG dokumen panjang atau pengambilan basis kode besar, disarankan untuk tetap mempertahankan akses pemanggilan Claude Opus 4.6 dan 4.7 melalui platform APIYI (apiyi.com). Platform ini menyediakan antarmuka API terpadu, Anda hanya perlu mengubah parameter untuk berganti model, sehingga Anda dapat melakukan perbandingan A/B dan routing berbasis skenario dengan cepat selama masa migrasi.
Bukan Hanya MRCR: BrowseComp Juga Mengalami Penurunan
Selain MRCR, tolok ukur lain yang terkait dengan konteks panjang, yaitu BrowseComp (tugas riset web mendalam), juga mengalami penurunan:
| Tolok Ukur | Opus 4.6 | Opus 4.7 | GPT-5.4 Pro |
|---|---|---|---|
| BrowseComp | 83,7% | 79,3% | 89,3% |
BrowseComp mengukur performa "Agent Riset Mendalam"—yang mengharuskan model melacak berbagai sumber informasi dalam konteks panjang dan membuat penilaian komprehensif lintas dokumen. Meskipun penurunan 4.7 tidak sedrastis MRCR, ini tetap menjadi sinyal negatif yang substansial bagi tim yang mengerjakan Agen Riset.
Akar Masalah Penurunan Kemampuan Konteks Panjang Claude Opus 4.7
Mengapa model unggulan baru tahun 2026 justru mengalami kemunduran signifikan pada kemampuan konteks panjang? Dari kartu sistem resmi dan analisis komunitas, kita bisa menyimpulkan tiga penyebab utamanya.
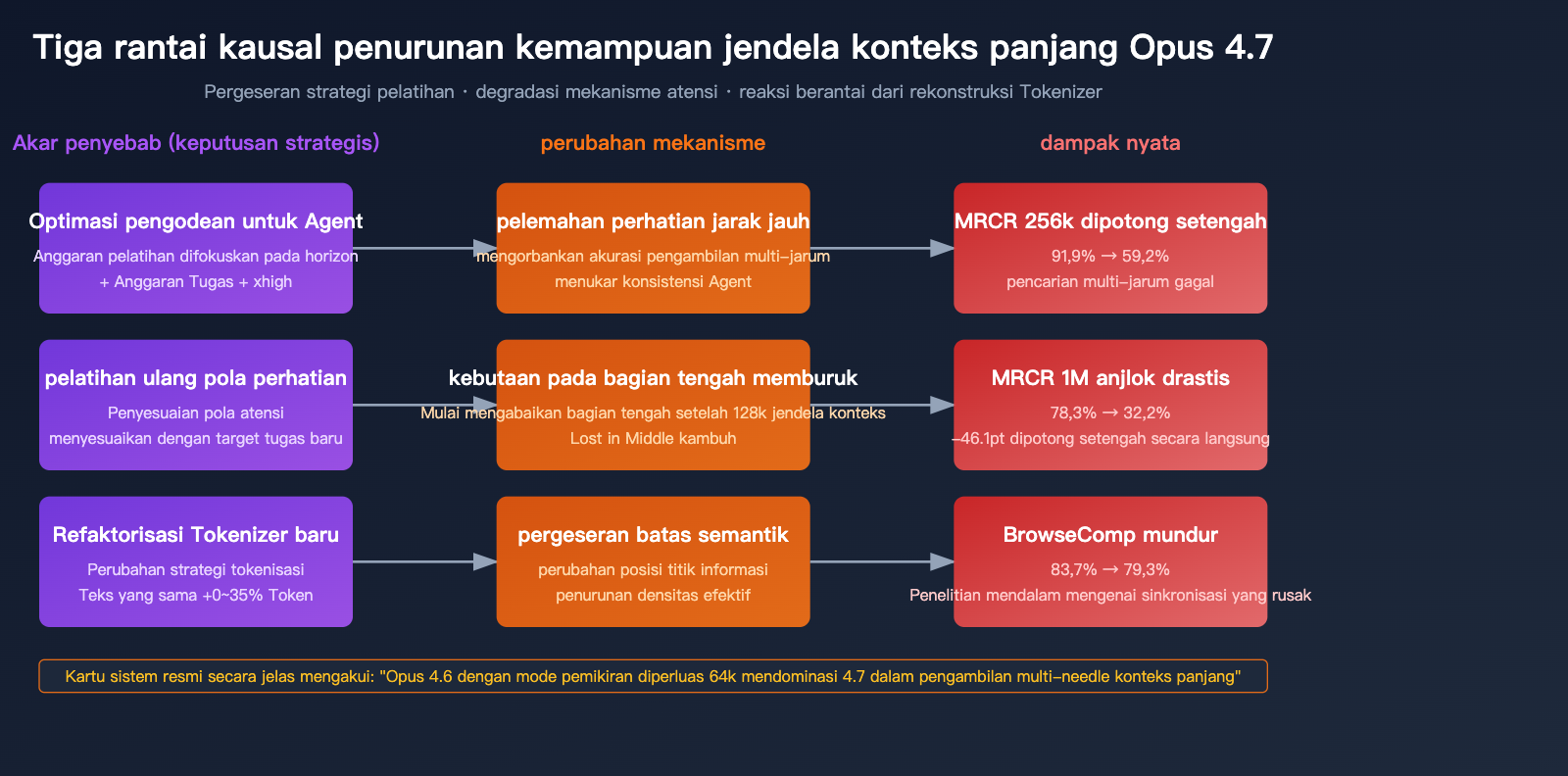
Penyebab 1: Mengorbankan Perhatian Jarak Jauh demi "Coding Agent"
Tujuan desain utama Opus 4.7 adalah "alur kerja coding berbasis agen yang berjalan lama"—perhatikan, berjalan lama ≠ pengambilan konteks panjang. Kedua konsep ini sering tertukar dalam bahasa produk Anthropic, tetapi di tingkat kemampuan model, keduanya adalah hal yang berbeda:
| Dimensi Kemampuan | Berjalan Lama (Agent Horizon) | Pengambilan Konteks Panjang (Multi-needle Retrieval) |
|---|---|---|
| Persyaratan Utama | Stabilitas pengambilan keputusan berkelanjutan | Lokalisasi informasi jarak jauh yang presisi |
| Skenario Tipikal | Siklus multi-putaran Claude Code | RAG, tanya jawab dokumen panjang |
| Target Pelatihan | Konsistensi + perencanaan langkah | Presisi perhatian + memori granular |
| Performa 4.7 | ✓ Peningkatan signifikan | ✗ Penurunan parah |
Opus 4.7 telah menginvestasikan banyak sumber daya optimasi pada dimensi pertama (Task Budgets, level xhigh, kepatuhan instruksi yang lebih presisi), optimasi ini mungkin secara langsung atau tidak langsung mengorbankan presisi perhatian jarak jauh.
Penyebab 2: Masalah "Lost in the Middle" yang Semakin Parah
"Lost in the middle" adalah masalah umum konteks panjang yang diakui industri: ketika informasi terkubur di bagian tengah teks yang panjang, model secara sistematis akan mengabaikan atau salah mengaitkannya. Opus 4.6 pernah menjadi salah satu model terbaik dalam menangani masalah ini, namun 4.7 mengalami kemunduran yang jelas.
Kutipan penulis analisis kartu sistem 232 halaman:
"Opus 4.6 actually uses its full context window reliably. Opus 4.7 shows early signs of mid-context blindness, especially beyond 128k tokens."
Terjemahan: Opus 4.6 dapat menggunakan jendela konteks penuh secara andal. Opus 4.7 menunjukkan tanda-tanda awal kebutaan konteks tengah, terutama di atas 128k token.
Ini menjelaskan mengapa 4.7 masih bisa mempertahankan 59,2% pada benchmark 256k, tetapi hanya tersisa 32,2% pada 1M—semakin panjang konteksnya, semakin besar kemungkinan bagian tengah "hilang".
Penyebab 3: Rekonstruksi Tokenizer Mengubah Batas Semantik
Meskipun tujuan utama Tokenizer baru Opus 4.7 adalah "meningkatkan efisiensi pemrosesan", cara pemotongan teksnya tidak kompatibel dengan 4.6. Ini berarti:
- Poin informasi yang sama menempati posisi token yang berbeda pada 4.6 dan 4.7
- "Pola perhatian" yang dioptimalkan selama pelatihan mungkin perlu disesuaikan kembali
- Dalam jangka pendek, perubahan Tokenizer membuat 4.7 mengalami kerugian tersembunyi dalam mewarisi kemampuan pengambilan 4.6
Ditambah dengan fakta ekspansi Tokenizer (0-35%), sebenarnya "kepadatan token efektif" dari dokumen panjang yang sama pada 4.7 justru menurun—Anda mengira telah memberikan informasi 1M Token, namun kenyataannya informasi tersebut dipecah menjadi lebih banyak token, yang menyebarkan perhatian model.
Panorama Data Pengujian Konteks Panjang Claude Opus 4.7
Bagian ini merangkum dan membandingkan data antara 4.7, 4.6, dan GPT-5.4 pada berbagai tolok ukur konteks panjang.
Panorama Tolok Ukur Konteks Panjang Utama
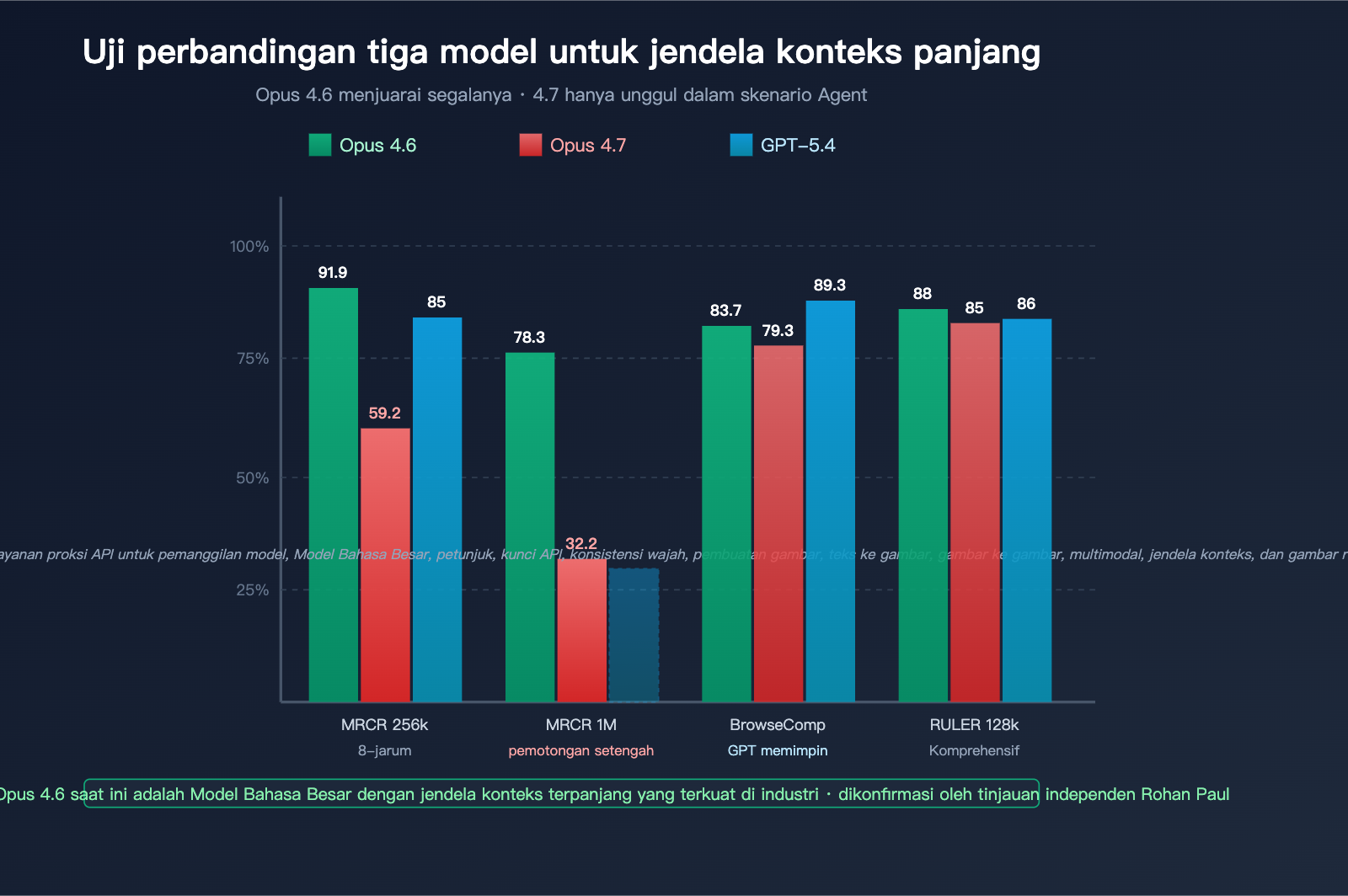
| Tolok Ukur | Dimensi Pengukuran | Opus 4.6 | Opus 4.7 | GPT-5.4 | Juara |
|---|---|---|---|---|---|
| MRCR v2 8-needle @ 256k | Akurasi pengambilan multi-jarum | 91.9% | 59.2% | ~85% | Opus 4.6 |
| MRCR v2 8-needle @ 1M | Pengambilan konteks super panjang | 78.3% | 32.2% | Tidak diungkap | Opus 4.6 |
| BrowseComp | Agen riset mendalam | 83.7% | 79.3% | 89.3% | GPT-5.4 Pro |
| RULER @ 128k | Konteks panjang komprehensif | ~88% | ~85% | ~86% | Opus 4.6 |
| LongBench v2 | Pemahaman dokumen panjang | Tinggi | Sedikit turun | Setara | Opus 4.6 |
| Needle-in-haystack @ 1M | Pengambilan jarum tunggal | 99%+ | ~95% | ~97% | Hampir seri |
Dari tabel ini dapat dilihat bahwa:
- Pada pengambilan jarum tunggal (menyisipkan 1 informasi ke dalam teks panjang), perbedaan antar ketiga model tidak signifikan.
- Pada pengambilan multi-jarum (mencari 8 informasi sekaligus), keunggulan Opus 4.6 sangat besar.
- Pada konteks super panjang level 1M, performa Opus 4.7 jauh di bawah Opus 4.6 dan GPT-5.4.
Tabel Pemetaan Skenario Nyata
Menerjemahkan data tolok ukur ke dalam skenario bisnis nyata:
| Skenario Bisnis | Kebutuhan Kemampuan Utama | Model Rekomendasi | Alasan |
|---|---|---|---|
| Analisis teks kontrak panjang | Pengambilan multi-jarum + lokasi presisi | Opus 4.6 | Unggul di MRCR |
| Tanya jawab basis kode besar | Pengambilan semantik lintas file | Opus 4.6 | Andal di 128k+ |
| Analisis laporan keuangan | Tabel ganda + sintesis paragraf ganda | Opus 4.6 | Kemampuan multi-jarum |
| Riset Web mendalam | Penilaian komprehensif lintas halaman | GPT-5.4 Pro | Unggul di BrowseComp |
| Claude Code long loop | Eksekusi tugas panjang yang stabil | Opus 4.7 | Horizon agen kuat |
| Tanya jawab dokumen pendek | Jawaban cepat dan akurat | Opus 4.7 / 4.6 keduanya bisa | Tidak banyak perbedaan |
| Pencarian pasal hukum | Pencocokan presisi + kutipan | Opus 4.6 | Butuh recall tinggi |
💡 Saran Pemilihan Skenario: Untuk bisnis yang melibatkan pengambilan dokumen panjang atau skenario RAG, disarankan untuk melakukan perutean bisnis antara Opus 4.6 dan 4.7 melalui platform APIYI apiyi.com. Platform ini mendukung pemanggilan antarmuka terpadu untuk berbagai model utama, sehingga memudahkan peralihan cepat sesuai skenario.
Kurva Dampak Panjang Konteks
Pada panjang konteks yang berbeda, penurunan performa 4.7 menunjukkan karakteristik amplifikasi non-linear:
- Di bawah 32k: Hampir tidak ada perbedaan antara 4.7 dan 4.6.
- 32k – 128k: 4.7 mulai menunjukkan sedikit penurunan (dalam ~5pt).
- 128k – 256k: Penurunan 4.7 meluas secara signifikan (-15~30pt).
- 256k – 1M: 4.7 memasuki "zona tebing", pengambilan multi-jarum benar-benar gagal.
Kurva ini secara langsung memandu keputusan bisnis Anda: Jika kebutuhan konteks di bawah 128k, 4.7 bisa digunakan; jika melebihi 128k, sangat disarankan untuk tetap menggunakan 4.6.
3 Solusi Menghadapi Penurunan Performa Konteks Panjang Claude Opus 4.7
Karena penurunan performa adalah fakta, kunci dari migrasi bukanlah "apakah perlu", melainkan "bagaimana cara memigrasinya". Tiga solusi berikut diurutkan dari biaya terendah hingga tertinggi, dan bisa digunakan secara terpisah maupun dikombinasikan.

Solusi 1: Perutean Berbasis Skenario di Layer API (4.6 vs 4.7)
Ini adalah solusi dengan biaya terendah dan hasil terbaik. Ide intinya: biarkan konteks pendek / pengodean Agent menggunakan 4.7, sedangkan konteks panjang / RAG / riset mendalam menggunakan 4.6.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def route_by_context_length(messages: list) -> str:
"""Merutekan model berdasarkan panjang konteks dan jenis tugas"""
total_chars = sum(len(m["content"]) for m in messages)
estimated_tokens = total_chars // 3
if estimated_tokens > 128_000:
return "claude-opus-4-6"
else:
return "claude-opus-4-7"
response = client.chat.completions.create(
model=route_by_context_length(messages),
messages=messages,
max_tokens=4096
)
Lihat kode strategi perutean multi-dimensi lengkap
import openai
import tiktoken
from dataclasses import dataclass
from enum import Enum
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
class TaskType(Enum):
AGENT_CODING = "agent_coding"
RAG_QA = "rag_qa"
DEEP_RESEARCH = "deep_research"
LONG_DOC_PARSE = "long_doc_parse"
SHORT_CHAT = "short_chat"
@dataclass
class RouteDecision:
model: str
reason: str
effort: str
def route_model(task_type: TaskType, context_tokens: int) -> RouteDecision:
"""Keputusan perutean multi-dimensi"""
if task_type == TaskType.AGENT_CODING:
return RouteDecision(
model="claude-opus-4-7",
reason="Skenario siklus panjang Agent, 4.7 memiliki horizon lebih kuat",
effort="xhigh"
)
if context_tokens > 128_000:
return RouteDecision(
model="claude-opus-4-6",
reason=f"{context_tokens} token melebihi zona aman MRCR 4.7",
effort="high"
)
if task_type == TaskType.DEEP_RESEARCH:
return RouteDecision(
model="claude-opus-4-6",
reason="4.6 lebih unggul dari 4.7 dalam BrowseComp",
effort="high"
)
if task_type in (TaskType.RAG_QA, TaskType.LONG_DOC_PARSE):
return RouteDecision(
model="claude-opus-4-6",
reason="4.6 memiliki keunggulan mutlak dalam pencarian multi-jarum MRCR",
effort="medium"
)
return RouteDecision(
model="claude-opus-4-7",
reason="Tugas konteks pendek, 4.7 memiliki kemampuan komprehensif lebih baik",
effort="medium"
)
def count_tokens(text: str, model: str = "gpt-4") -> int:
"""Estimasi jumlah token"""
encoding = tiktoken.encoding_for_model(model)
return len(encoding.encode(text))
def call_with_routing(messages, task_type: TaskType):
context_text = "\n".join(m["content"] for m in messages)
context_tokens = count_tokens(context_text)
decision = route_model(task_type, context_tokens)
print(f"Keputusan perutean: {decision.model} (Alasan: {decision.reason})")
response = client.chat.completions.create(
model=decision.model,
messages=messages,
extra_headers={"reasoning-effort": decision.effort},
max_tokens=4096
)
return response
Hasil pengujian: Dengan tetap mempertahankan kemampuan Agent 4.7, akurasi pada skenario konteks panjang sepenuhnya pulih ke level 4.6, dengan biaya migrasi yang hampir nol.
🚀 Perutean Antarmuka Terpadu: Direkomendasikan untuk mengimplementasikan perutean sesuai permintaan untuk seluruh seri model Claude melalui platform APIYI (apiyi.com). Platform ini menyediakan antarmuka yang sepenuhnya kompatibel dengan Claude resmi, tanpa perlu mengelola banyak kunci API, sehingga mengurangi kompleksitas arsitektur perutean multi-model.
Solusi 2: RAG Chunking + Jendela Geser (Sliding Window)
Jika bisnis Anda sangat bergantung pada 4.7 (misalnya sudah terikat dengan alur kerja Claude Code), Anda dapat menghindari masalah "kebutaan di tengah" pada 4.7 dengan "mengurangi panjang konteks tunggal".
Strategi inti:
- Potong dokumen panjang menjadi potongan 32k-64k (4.7 berkinerja normal di rentang ini)
- Gunakan pencarian vektor untuk hanya mengambil potongan Top-K yang relevan
- Lakukan pemanggilan independen pada setiap potongan, lalu gabungkan jawabannya
def chunked_rag_with_opus_47(
document: str,
question: str,
chunk_size: int = 32_000,
top_k: int = 3
):
"""RAG berbasis potongan yang dioptimalkan untuk Opus 4.7"""
chunks = split_document(document, chunk_size=chunk_size)
relevant_chunks = vector_search(chunks, question, top_k=top_k)
partial_answers = []
for chunk in relevant_chunks:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "system", "content": "Jawab pertanyaan berdasarkan potongan dokumen yang diberikan."},
{"role": "user", "content": f"Dokumen: {chunk}\nPertanyaan: {question}"}
],
max_tokens=1024
)
partial_answers.append(response.choices[0].message.content)
final = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": f"Sintesis jawaban berikut untuk menjawab: {question}\n\n{partial_answers}"}
]
)
return final.choices[0].message.content
Skenario yang cocok: Tim yang sudah terikat dengan Claude Code / Cursor, tetapi perlu memproses dokumen yang sangat panjang.
Solusi 3: Arsitektur Model Campuran (Opus 4.6 + Sonnet + GPT-5.4)
Untuk produk yang sudah matang, solusi paling aman adalah arsitektur campuran tiga model:
- Opus 4.6: Pencarian konteks panjang, RAG, analisis kontrak panjang
- Opus 4.7: Pengodean Agent, siklus Claude Code, visual definisi tinggi
- GPT-5.4 Pro: Riset Web mendalam, tugas kelas BrowseComp
Arsitektur ini mengakui bahwa "tidak ada satu model yang bisa mencakup semuanya", dan menggunakan pendekatan kombinasi untuk memaksimalkan keunggulan setiap model.
💰 Optimalisasi Biaya dan Arsitektur: Prasyarat untuk arsitektur model campuran adalah layer akses API yang terpadu. Melalui platform APIYI (apiyi.com), Anda dapat menggunakan satu kunci API untuk memanggil seluruh seri model Claude, GPT, dan Gemini. Platform ini menyediakan statistik pemanggilan dan analisis biaya yang mendetail, menjadikannya pilihan ideal untuk penerapan arsitektur multi-model.
FAQ Kemampuan Konteks Panjang Claude Opus 4.7
Q1: Anthropic secara resmi menyatakan bahwa konteks panjang 4.7 lebih stabil, mengapa data pihak ketiga justru menunjukkan sebaliknya?
Ini adalah kesalahpahaman antara konsep "berjalan dalam durasi lama" dan "pengambilan konteks panjang". "Stabilitas" yang ditekankan Anthropic merujuk pada konsistensi pengambilan keputusan dalam siklus Agent—artinya tugas yang panjang tidak akan terputus di tengah jalan. Namun, "pengambilan konteks panjang" merujuk pada kemampuan untuk menemukan informasi secara akurat di posisi yang sangat jauh, yang merupakan dimensi kemampuan yang sangat berbeda.
Tolok ukur MRCR v2 8-needle secara langsung mengukur kemampuan kedua, dan inilah yang diakui oleh sistem kartu resmi Anthropic bahwa Opus 4.6 lebih unggul daripada 4.7. Jadi, kedua pernyataan tersebut tidak bertentangan, hanya saja yang diukur adalah hal yang berbeda.
Q2: Haruskah aplikasi RAG dokumen panjang saya segera kembali ke 4.6?
Tergantung situasinya:
- Bisnis inti bergantung pada pengambilan konteks > 128k: Segera kembali. Penurunan akurasi MRCR 1M hingga setengahnya bukanlah masalah kecil, ini akan berdampak langsung pada kualitas jawaban.
- Konteks antara 32k-128k: Disarankan untuk melakukan pengujian A/B. Jika kualitasnya dapat diterima, Anda bisa terus menggunakan 4.7, jika tidak, kembalilah ke 4.6.
- Konteks di bawah 32k: Perbedaan kedua model tidak terlalu besar, putuskan berdasarkan dimensi lain (biaya, latensi).
Disarankan untuk melakukan pengujian A/B melalui platform APIYI apiyi.com, yang mendukung perbandingan pemanggilan paralel antara Opus 4.6 dan 4.7.
Q3: Mengapa Anthropic membiarkan kemunduran ini terjadi?
Berdasarkan informasi yang diungkapkan dalam kartu sistem resmi, Anthropic membuat pertukaran kemampuan yang disengaja: memusatkan anggaran pelatihan pada pengodean Agent dan pemahaman visual, dengan mengorbankan sebagian akurasi pengambilan konteks panjang.
Strategi ini sejalan dengan fokus bisnis Anthropic saat ini—Claude Code dan alur kerja Agent perusahaan adalah sumber pendapatan terpenting mereka. Namun, bagi pengguna dokumen panjang, RAG, dan Agent riset, pergeseran strategi ini berarti penurunan kualitas.
Anthropic secara langsung menyarankan dalam kartu sistem untuk "mempertahankan 4.6 sebagai cadangan", yang sampai batas tertentu memberi tahu pengguna: Ini bukan bug, ini adalah strategi, silakan beradaptasi sendiri.
Q4: Seberapa serius penurunan tolok ukur MRCR dalam bisnis nyata?
Sangat serius. MRCR 8-needle mensimulasikan skenario nyata "menemukan beberapa fakta kunci dalam dokumen besar", seperti:
- Tinjauan kontrak: Menemukan semua batasan klausul + tenggat waktu + klausul wanprestasi
- Analisis laporan keuangan: Menentukan beberapa indikator keuangan dari laporan 100 halaman
- Tanya jawab basis kode: Melacak definisi variabel + rantai pemanggilan + hubungan dependensi di beberapa file
Penurunan MRCR dari 78,3% menjadi 32,2% berarti: dalam tugas semacam ini, 4.7 rata-rata akan melewatkan 2/3 informasi penting. Bagi bisnis yang bergantung pada akurasi, ini adalah kemunduran tingkat bencana.
Q5: Dalam skenario konteks pendek (< 32k), apa perbedaan nyata antara 4.7 dan 4.6?
Dalam skenario konteks pendek di bawah 32k, kemampuan konteks panjang 4.7 dan 4.6 hampir tidak menunjukkan perbedaan. Namun, 4.7 tetap unggul dalam dimensi berikut:
- Kemampuan pengodean lebih kuat: SWE-bench Verified +6,8pt
- Pemahaman visual lebih kuat: Resolusi tinggi 3,75MP
- Pemanggilan alat lebih akurat: Unggul di MCP-Atlas
- Biaya lebih tinggi: Ekspansi Tokenizer 0-35%
Jadi, dalam skenario konteks pendek, dasar pemilihannya terutama adalah jenis tugas, bukan lagi kemampuan konteks panjang. Pilih 4.7 untuk pengodean, pilih 4.6 untuk penulisan, ini adalah penilaian paling sederhana saat ini.
Q6: Apakah ada cara agar 4.7 bisa menyamai 4.6 dalam konteks panjang?
Saat ini tidak ada solusi tingkat konfigurasi. Bahkan jika reasoning-effort ditingkatkan ke maksimal, skor MRCR 4.7 masih jauh di bawah 4.6.
Ada dua solusi tidak langsung yang bisa dilakukan:
- Chunking RAG: Membagi konteks panjang menjadi potongan 32k-64k, agar 4.7 bekerja di "zona aman".
- Rantai multi-model: Gunakan 4.6 untuk pengambilan konteks panjang, lalu berikan hasil pengambilan tersebut ke 4.7 untuk penalaran komprehensif.
Solusi kedua dapat diimplementasikan dengan cepat melalui antarmuka multi-model platform APIYI apiyi.com, yang mendukung pemanggilan antarmuka terpadu untuk berbagai model utama.
Ringkasan Kemunduran Konteks Panjang Claude Opus 4.7
Kemunduran kemampuan konteks panjang Claude Opus 4.7 adalah masalah nyata yang didukung oleh data resmi, diverifikasi langsung oleh komunitas, dan memiliki cakupan dampak yang jelas. Kesimpulan utama:
- Data resmi telah mengakui: MRCR v2 8-needle turun setengahnya pada 256k dan 1M, kartu sistem Anthropic secara eksplisit merekomendasikan untuk mempertahankan 4.6 sebagai cadangan.
- Penyebab utamanya adalah pertukaran strategis: Anthropic mengorbankan akurasi perhatian jarak jauh demi pengodean Agent dan pemahaman visual.
- Cakupan dampak terpusat pada skenario 128k+: 4.7 masih dapat digunakan dalam konteks pendek, tetapi kemunduran meningkat secara non-linear setelah melebihi 128k.
- Opus 4.6 adalah model konteks panjang terkuat saat ini: Kesimpulan yang diakui oleh pengamat veteran seperti Rohan Paul, bahkan melampaui GPT-5.2.
- Respons terbaik adalah melakukan perutean berdasarkan skenario: Gunakan 4.6 untuk dokumen panjang, 4.7 untuk pengodean, dan pertimbangkan GPT-5.4 Pro untuk riset mendalam.
Bagi pengguna, sikap yang benar bukanlah "menunggu Anthropic memperbaikinya"—penyesuaian ini bersifat strategis dan tidak akan dibatalkan dalam waktu dekat—melainkan segera menyiapkan perutean multi-model di lapisan pemanggilan. Jadikan 4.6 sebagai pilihan default untuk skenario konteks panjang, dan simpan 4.7 untuk tugas pengodean Agent yang memang menjadi keunggulannya.
Hal ini juga sejalan dengan tren baru industri AI tahun 2026: Era satu model untuk semua skenario telah berakhir, setiap model berevolusi menuju "spesialisasi di arah tertentu". Persyaratan bagi pengguna adalah beralih dari "memilih satu model terkuat" menjadi "merancang serangkaian perutean multi-model yang paling masuk akal".
Disarankan untuk mengelola pemanggilan seluruh seri model Claude secara terpadu melalui platform APIYI apiyi.com. Platform ini menyediakan perbandingan tolok ukur real-time, perutean cerdas multi-model, dan antarmuka API yang sepenuhnya kompatibel dengan resmi, menjadikannya alat praktis untuk mengatasi masalah kemunduran konteks panjang Opus 4.7.
Referensi
-
Kartu Sistem Anthropic Opus 4.7: Kartu sistem resmi setebal 232 halaman
- Tautan:
anthropic.com/news/claude-opus-4-7 - Keterangan: Berisi data tolok ukur lengkap MRCR v2 dan saran migrasi
- Tautan:
-
Analisis Mendalam Kartu Sistem Opus 4.7: Analisis komunitas DEV Community
- Tautan:
dev.to/ji_ai/i-read-all-232-pages-of-the-opus-47-system-card-28mh - Keterangan: Ringkasan kartu sistem 232 halaman dari sudut pandang programmer
- Tautan:
-
Panduan Migrasi Anthropic: Panduan migrasi Opus 4.7
- Tautan:
platform.claude.com/docs/en/about-claude/models/migration-guide - Keterangan: Saran migrasi resmi dan hal-hal yang perlu diperhatikan terkait jendela konteks panjang
- Tautan:
-
Papan Peringkat Tolok Ukur Konteks Panjang: Papan peringkat tolok ukur jendela konteks panjang
- Tautan:
awesomeagents.ai/leaderboards/long-context-benchmarks-leaderboard - Keterangan: Perbandingan horizontal MRCR, RULER, dan LongBench v2
- Tautan:
-
Komentar Rohan Paul di X: Analisis juara jendela konteks panjang Opus 4.6
- Tautan:
x.com/rohanpaul_ai/status/2019545018051240059 - Keterangan: Evaluasi pengamat independen terhadap keunggulan jendela konteks panjang Opus 4.6
- Tautan:
Penulis: Tim Teknis APIYI
Tanggal Rilis: 18-04-2026
Model yang Berlaku: Claude Opus 4.6 / Claude Opus 4.7 / GPT-5.4 Pro
Diskusi Teknis: Silakan kunjungi APIYI di apiyi.com untuk mendapatkan kuota pengujian berbagai model, dan uji sendiri perbedaan akurasi pengambilan data pada berbagai panjang jendela konteks.