
Catatan Penulis: Panduan detail tentang cara membangun jalur pemeriksaan kualitas soal fisika menggunakan tiga Model Bahasa Besar: Gemini 3.1 Pro, Claude Sonnet 4.6, dan GPT-5.4, dilengkapi dengan template petunjuk dan contoh kode lengkap.
Penggunaan Model Bahasa Besar untuk pemeriksaan kualitas soal fisika semakin menjadi perhatian lembaga pendidikan dan platform pembelajaran online. Pemeriksaan manual tradisional tidak hanya tidak efisien, tetapi juga terbatas pada perbedaan penilaian subjektif dari pengajar. Artikel ini akan memperkenalkan cara memanfaatkan Gemini 3.1 Pro Preview, Claude Sonnet 4.6, dan GPT-5.4—tiga model penalaran terkuat tahun 2026—untuk membangun sistem pemeriksaan kualitas otomatis soal fisika dengan akurasi tinggi.
Nilai Inti: Setelah membaca artikel ini, Anda akan menguasai alur kerja lengkap pemeriksaan kualitas soal fisika dengan Model Bahasa Besar—dari desain petunjuk hingga validasi silang multi-model, membangun solusi otomatisasi pemeriksaan kualitas dengan akurasi melebihi 90%.
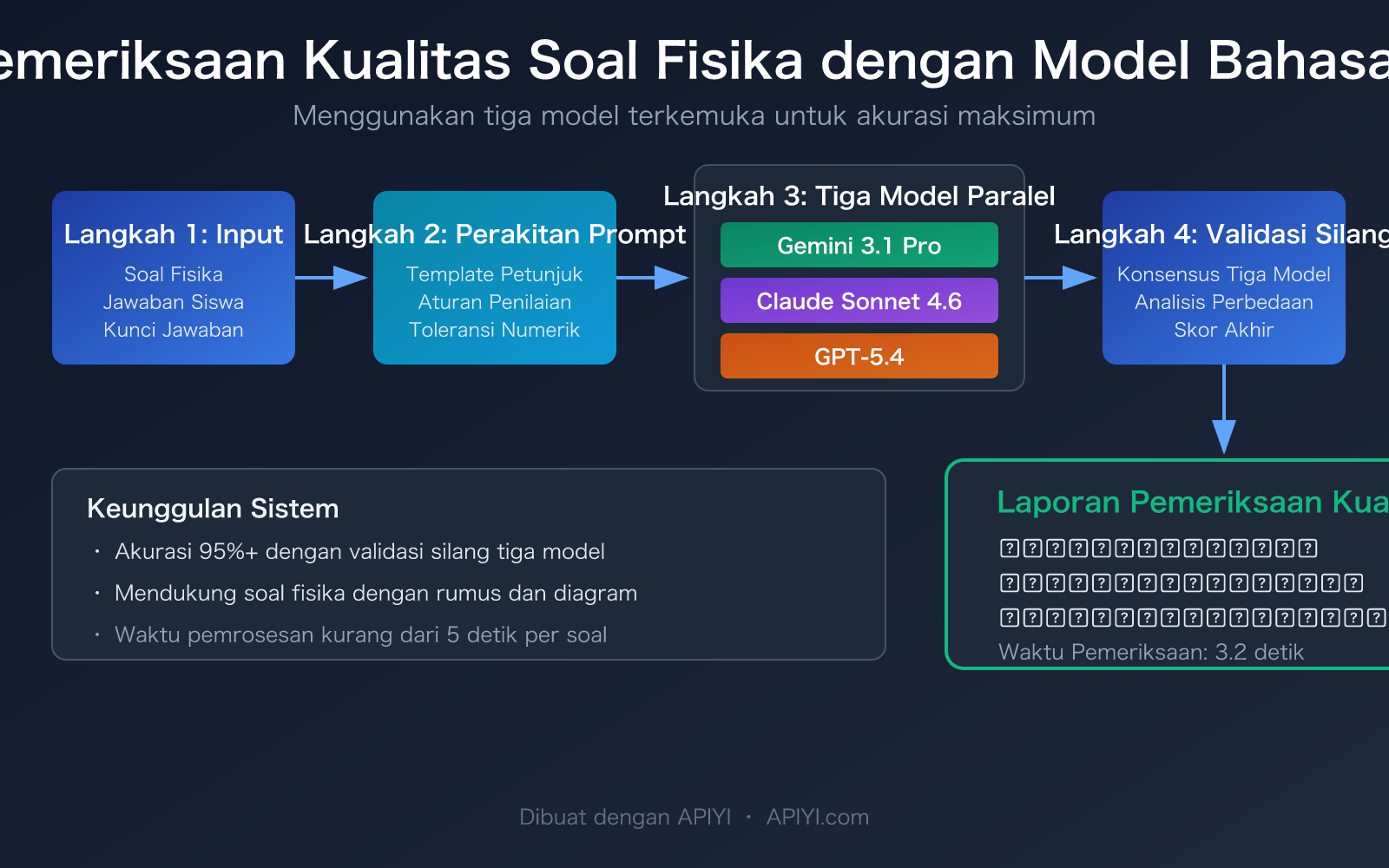
Poin Inti Pemeriksaan Kualitas Soal Fisika dengan Model Bahasa Besar
Pemeriksaan kualitas soal fisika berbeda secara mendasar dari koreksi teks biasa—model harus memiliki kemampuan deduksi matematika, pemahaman konsep fisika, dan konsistensi penilaian secara bersamaan. Berikut adalah perbandingan kemampuan inti dari 3 model yang direkomendasikan:
| Poin | Penjelasan | Nilai Praktis |
|---|---|---|
| Kemampuan Penalaran Gemini 3.1 Pro Unggul | Skor MATH 95.1%, ARC-AGI-2 mencapai 77.1%, peringkat pertama dalam evaluasi penalaran fisika | Akurasi tertinggi dalam menangani soal hitungan mekanika dan elektromagnetika dengan deduksi rumus |
| Proses Penyelesaian Claude Sonnet 4.6 Jelas | Mendukung mode berpikir adaptif, kemampuan matematika melonjak 27 poin persentase menjadi 89% | Dapat menghasilkan dasar penilaian lengkap dan alasan pengurangan poin, cocok untuk membuat laporan pemeriksaan kualitas |
| Kinerja GPT-5.4 Unggul pada Soal Kompetisi Sulit | Nilai sempurna AIME 2025, mendukung konteks 1 juta Token | Rantai penalaran paling lengkap saat menangani soal kompetisi fisika dan soal komprehensif |
| Validasi Silang Multi-Model | Tiga model menilai secara independen lalu mengambil konsensus | Meningkatkan akurasi model tunggal 85-90% menjadi 95%+ |
3 Tantangan Utama Pemeriksaan Kualitas Soal Fisika dengan Model Bahasa Besar
Tantangan pertama: Penentuan kesetaraan deduksi rumus. Untuk soal mekanika yang sama, siswa mungkin menyelesaikannya dengan hukum kekekalan energi, atau dengan hukum kedua Newton. Proses deduksi kedua metode ini sepenuhnya berbeda, tetapi hasilnya setara. Penelitian menunjukkan bahwa jika tidak secara eksplisit meminta model untuk menerima solusi setara dalam petunjuk, model akan menilai secara kaku sesuai jalur penyelesaian jawaban standar, menyebabkan tingkat kesalahan penilaian mencapai 30%. Ini adalah titik kehilangan poin paling umum dalam pemeriksaan kualitas soal fisika dengan Model Bahasa Besar.
Tantangan kedua: Penanganan toleransi satuan fisika dan angka penting. Dalam perhitungan fisika, hasil yang mempertahankan 2 angka penting dan 3 angka penting berbeda, tetapi biasanya harus diterima. Menetapkan rentang toleransi numerik yang wajar (seperti ±5%) dalam petunjuk adalah jaminan kunci untuk akurasi pemeriksaan kualitas.
Tantangan ketiga: Pemahaman soal dengan diagram dan eksperimen. Soal yang mengandung diagram rangkaian listrik atau ilustrasi mekanika memerlukan model memiliki kemampuan pemahaman multimodal. Gemini 3.1 Pro dan GPT-5.4 memiliki kinerja yang lebih baik dalam hal ini, sedangkan Claude Sonnet 4.6 lebih stabil dalam penalaran teks murni dan rumus.
Gemini 3.1 Pro Preview: Pilihan Utama untuk Penalaran Fisika
Gemini 3.1 Pro adalah model andalan yang dirilis oleh Google DeepMind pada Februari 2026. Dalam skenario pemeriksaan kualitas soal fisika, model ini memiliki tiga keunggulan inti:
- Kemampuan Penalaran STEM Terkuat: Menduduki peringkat pertama dalam evaluasi CritPt (penalaran fisika tingkat penelitian), mencapai 95.1% pada tolok ukur MATH.
- Kedalaman Pemikiran Dapat Disesuaikan: Menambahkan parameter
thinking_level(mendukung LOW/MEDIUM/HIGH). Gunakan LOW untuk pilihan ganda sederhana untuk menekan biaya, dan HIGH untuk soal hitung komprehensif untuk memastikan akurasi. - Rasio Biaya-Manfaat Sangat Tinggi: Biayanya hanya sekitar 1/7.5 dari Claude Opus 4.6, cocok untuk tugas pemeriksaan kualitas dalam jumlah besar.
Claude Sonnet 4.6: Terbaik untuk Pembuatan Laporan Pemeriksaan
Claude Sonnet 4.6 dirilis pada 17 Februari 2026. Keunggulan uniknya dalam pemeriksaan kualitas soal fisika terletak pada:
- Mode Pemikiran Adaptif: Model akan secara otomatis menentukan kedalaman penalaran berdasarkan tingkat kesulitan soal, memberikan penilaian cepat untuk soal mudah dan penalaran mendalam untuk soal kompleks.
- Jendela Konteks 1 Juta Token: Memungkinkan untuk mengirimkan semua soal dan kunci jawaban dari satu set ujian sekaligus, menjaga konsistensi standar penilaian.
- Struktur Output yang Kuat: Sangat ahli dalam menghasilkan laporan pemeriksaan kualitas dengan format yang rapi, mencakup skor, poin pengurangan, dan saran perbaikan.
GPT-5.4: Senjata Ampuh untuk Soal Kompetisi yang Sulit
GPT-5.4 dirilis pada 5 Maret 2026, merupakan model andalan terbaru dari OpenAI:
- Skor Sempurna untuk Matematika Kompetisi: Mencapai akurasi 100% dalam AIME 2025, kemampuan menangani soal fisika komprehensif dengan tingkat kesulitan tinggi sangat menonjol.
- Kemampuan Perencanaan Awal: Versi GPT-5.4 Thinking mendukung "Upfront Planning", menampilkan alur penalaran terlebih dahulu sebelum memberikan skor.
- Efisiensi Token Optimal: Dibandingkan dengan GPT-5.2, konsumsi token untuk penalaran berkurang drastis, sehingga biaya penggunaan jangka panjang lebih rendah.
| Model | Kemampuan Penalaran Fisika | Kualitas Pembuatan Laporan | Dukungan Multimodal | Biaya per Juta Token | Skenario Rekomendasi |
|---|---|---|---|---|---|
| Gemini 3.1 Pro | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Terendah | Pemeriksaan kualitas harian dalam jumlah besar, soal yang mengandung grafik/diagram |
| Claude Sonnet 4.6 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Sedang ($3/$15) | Membutuhkan laporan pemeriksaan detail, penilaian untuk set ujian lengkap |
| GPT-5.4 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Lebih Tinggi | Soal kompetisi, soal komprehensif besar, pemeriksaan kualitas dengan tingkat kesulitan tinggi |
🎯 Saran Pemilihan: Untuk pemeriksaan kualitas harian, pilih Gemini 3.1 Pro (rasio biaya-manfaat tertinggi). Jika membutuhkan laporan detail, pilih Claude Sonnet 4.6. Untuk soal kompetisi tingkat tinggi, gunakan GPT-5.4. Melalui platform APIYI apiyi.com, Anda dapat memanggil ketiga model ini dengan satu antarmuka terpadu, memudahkan pergantian dan perbandingan yang cepat.
Mulai Cepat Pemeriksaan Kualitas Soal Fisika dengan Model Bahasa Besar
Contoh Minimalis: 10 Baris Kode untuk Penilaian Otomatis Soal Fisika
Contoh berikut menunjukkan cara menggunakan Model Bahasa Besar untuk melakukan penilaian otomatis pada sebuah soal hitung fisika:
import openai
client = openai.OpenAI(
api_key="KUNCI_API_ANDA",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[
{"role": "system", "content": "Anda adalah ahli pemeriksaan kualitas soal fisika. Nilailah jawaban siswa berdasarkan kunci jawaban, dan keluarkan dalam format JSON: {score, max_score, deductions: [{reason, points}], comment}"},
{"role": "user", "content": """
【Soal】Sebuah benda bermassa 2kg jatuh bebas dari ketinggian 10m, tentukan kecepatan saat menyentuh tanah (g=10m/s²)
【Kunci Jawaban】v=√(2gh)=√(2×10×10)=√200≈14.1m/s
【Jawaban Siswa】Menggunakan hukum kekekalan energi: mgh=½mv², v=√(2gh)=√200=14.14m/s
"""}
]
)
print(response.choices[0].message.content)
Lihat kode pipeline pemeriksaan kualitas lengkap (termasuk validasi silang multi-model)
import openai
import json
from typing import Optional
def physics_quality_check(
question: str,
standard_answer: str,
student_answer: str,
models: list = None,
tolerance: float = 0.05
) -> dict:
"""
Pemeriksaan kualitas silang multi-model untuk soal fisika
Args:
question: Konten soal
standard_answer: Kunci jawaban
student_answer: Jawaban siswa
models: Daftar model yang digunakan
tolerance: Toleransi nilai numerik (default 5%)
Returns:
Kamus yang berisi skor dari setiap model dan kesimpulan akhir
"""
if models is None:
models = ["gemini-3.1-pro-preview", "claude-sonnet-4-6", "gpt-5.4"]
client = openai.OpenAI(
api_key="KUNCI_API_ANDA",
base_url="https://vip.apiyi.com/v1"
)
system_prompt = f"""Anda adalah guru fisika senior dan ahli pemeriksaan ujian. Harap berikan penilaian dengan ketat sesuai aturan berikut:
1. Terima metode penyelesaian yang setara dengan kunci jawaban (misalnya, jalur berbeda seperti hukum kekekalan energi, hukum Newton, dll.)
2. Rentang toleransi hasil numerik: ±{tolerance*100}%
3. Angka penting: Terima perbedaan ±1 digit
4. Satuan fisika harus benar, kekurangan satuan dikurangi 10%
Keluarkan dengan format JSON yang ketat:
{{
"score": skor,
"max_score": skor maksimal,
"is_correct": true/false,
"deductions": [{{"reason": "alasan pengurangan", "points": nilai pengurangan}}],
"solution_method": "metode penyelesaian yang digunakan siswa",
"comment": "evaluasi komprehensif dan saran perbaikan"
}}"""
user_prompt = f"""【Soal】{question}
【Kunci Jawaban】{standard_answer}
【Jawaban Siswa】{student_answer}"""
results = {}
for model in models:
try:
resp = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
temperature=0.1
)
results[model] = json.loads(resp.choices[0].message.content)
except Exception as e:
results[model] = {"error": str(e)}
# Validasi silang: Ambil kesimpulan konsensus dari mayoritas model
scores = [r["score"] for r in results.values() if "score" in r]
consensus = {
"model_results": results,
"avg_score": sum(scores) / len(scores) if scores else 0,
"consensus": all(r.get("is_correct") for r in results.values() if "is_correct" in r)
}
return consensus
# Contoh penggunaan
result = physics_quality_check(
question="Sebuah benda bermassa 2kg jatuh bebas dari ketinggian 10m, tentukan kecepatan saat menyentuh tanah (g=10m/s²)",
standard_answer="v=√(2gh)=√(2×10×10)=√200≈14.1m/s",
student_answer="mgh=½mv²,v=√(2×10×10)=14.14m/s"
)
print(json.dumps(result, ensure_ascii=False, indent=2))
Saran: Dapatkan kuota uji coba gratis melalui APIYI apiyi.com. Dengan satu Kunci API, Anda dapat memanggil ketiga model Gemini, Claude, dan GPT, tanpa perlu mendaftar akun terpisah di ketiga platform.
Praktik Rekayasa Prompt untuk Pemeriksaan Kualitas Soal Fisika Model Bahasa Besar
Desain Prompt yang baik adalah inti dari akurasi pemeriksaan kualitas. Berikut adalah templat Prompt dan strategi optimasi yang telah teruji dalam praktik:
Templat Prompt Pemeriksaan Kualitas Soal Fisika
Berdasarkan penelitian akademis (beberapa makalah yang diterbitkan tahun 2024-2026), strategi prompt Tree of Thought (Pohon Pemikiran) menunjukkan performa terbaik dalam penilaian soal hitungan fisika, dengan akurasi ≥ 0.9 dan Cohen's Kappa > 0.8. Berikut adalah struktur Prompt yang kami rekomendasikan:
| Strategi Prompt | Jenis Soal yang Cocok | Akurasi | Model yang Direkomendasikan |
|---|---|---|---|
| Tree of Thought | Soal hitungan komprehensif, soal derivasi | ≥ 90% | Gemini 3.1 Pro |
| Chain of Thought | Soal analisis konsep, soal jawaban singkat | 85-90% | Claude Sonnet 4.6 |
| Few-Shot | Soal pilihan ganda, soal isian | 80-85% | GPT-5.4 (biaya lebih rendah) |
| Pemungutan Suara Berganda | Semua jenis soal (persyaratan tinggi) | 92-95% | Kombinasi tiga model |
Teknik Kunci Optimasi Prompt
Teknik 1: Tentukan aturan penerimaan metode penyelesaian yang setara. Cantumkan semua metode penyelesaian yang dapat diterima untuk soal tersebut dalam System Prompt. Misalnya, untuk soal mekanika, nyatakan: "Menerima metode kekekalan energi, hukum gerak Newton, teorema momentum, dan metode setara lainnya". Aturan ini dapat menurunkan tingkat kesalahan penilaian dari 30% menjadi di bawah 5%.
Teknik 2: Tetapkan toleransi numerik, bukan pencocokan eksak. Pembulatan dalam proses perhitungan fisika dapat menyebabkan perbedaan kecil pada hasil akhir. Disarankan untuk menetapkan toleransi ±5%, sekaligus mensyaratkan satuan fisika harus benar.
Teknik 3: Minta model untuk menyelesaikan soal terlebih dahulu baru kemudian memberi nilai. Minta model untuk menyelesaikan soal secara independen terlebih dahulu, kemudian membandingkannya dengan jawaban siswa. Cara ini 15-20% lebih akurat daripada langsung meminta model "memberi nilai dengan mencocokkan jawaban standar". Mode thinking_level: HIGH pada Gemini 3.1 Pro dan Extended Thinking pada Claude Sonnet 4.6 cocok untuk penggunaan ini.
Teknik 4: Jalankan beberapa kali dan ambil modus. Jalankan penilaian untuk soal yang sama sebanyak 3-5 kali dan ambil hasil yang paling sering muncul. Standar deviasi dapat digunakan sebagai indikator kepercayaan. Disarankan untuk ditinjau ulang secara manual jika standar deviasi > 1 poin.
🎯 Saran Praktis: Saat pertama kali membangun sistem pemeriksaan kualitas, disarankan untuk menggunakan 50-100 soal fisika yang telah dikoreksi secara manual sebagai set pengujian. Uji akurasi ketiga model di APIYI apiyi.com, dan temukan kombinasi model yang paling cocok dengan karakteristik bank soal Anda.

Solusi Terkustomisasi untuk Pemeriksaan Kualitas Soal Fisika dengan Model Bahasa Besar
Jenis soal fisika yang berbeda memerlukan strategi pemeriksaan kualitas yang berbeda. Berikut adalah konfigurasi yang direkomendasikan untuk 4 skenario khas:
Skenario 1: Pemeriksaan Kualitas Rutin untuk Tugas Harian
Cocok untuk tugas harian fisika SMA/kuliah, dengan volume soal besar (100+ soal/hari) dan tingkat kesulitan menengah.
- Model yang Direkomendasikan: Gemini 3.1 Pro Preview (
thinking_level: MEDIUM) - Strategi Petunjuk: Few-Shot + tabel penilaian standar
- Keunggulan Biaya: Sekitar 200 ribu Token untuk 1000 soal, biaya Gemini 3.1 Pro jauh lebih rendah dibanding model lain
- Akurasi: 85-90% (model tunggal), bisa mencapai 95%+ jika dikombinasikan dengan pemeriksaan manual acak
Skenario 2: Penilaian Rinci untuk Ujian Akhir Semester
Cocok untuk koreksi ujian formal, memerlukan dasar penilaian yang detail dan alasan pengurangan nilai.
- Model yang Direkomendasikan: Claude Sonnet 4.6 (mode Extended Thinking)
- Strategi Petunjuk: Tree of Thought + aturan penilaian terperinci
- Keunggulan Inti: Laporan pemeriksaan kualitas yang dihasilkan memiliki struktur jelas, bisa langsung diarsipkan sebagai catatan koreksi
- Akurasi: 88-92% (model tunggal)
Skenario 3: Pemeriksaan Kualitas Soal Kompetisi Fisika
Cocok untuk pelatihan kompetisi fisika SMA, soal bersifat komprehensif dan tingkat kesulitan tinggi.
- Model yang Direkomendasikan: GPT-5.4 Thinking (mode Upfront Planning)
- Strategi Petunjuk: Tree of Thought + selesaikan soal dulu baru beri nilai
- Keunggulan Inti: Level nilai sempurna AIME, mampu menangani derivasi multi-langkah dan operasi matematika tingkat tinggi
- Akurasi: 80-85% (kinerja model tunggal pada tingkat kesulitan kompetisi)
Skenario 4: Validasi Silang Multi-Model (Akurasi Tertinggi)
Cocok untuk ujian dengan konsekuensi tinggi (seperti ujian masuk), memerlukan akurasi tertinggi.
- Solusi yang Direkomendasikan: 3 model menilai secara independen → ambil konsensus mayoritas 2/3 → soal yang masih ada perbedaan diperiksa ulang secara manual
- Biaya Implementasi: Biaya per soal sekitar 3 kali lipat dari model tunggal, tetapi akurasi meningkat menjadi 95%+
- Skala Penerapan: Cocok untuk volume soal kecil (< 500 soal) tetapi dengan persyaratan kualitas yang sangat tinggi
| Skenario | Model yang Direkomendasikan | Strategi Petunjuk | Akurasi | Biaya (per 1000 soal) |
|---|---|---|---|---|
| Tugas Harian | Gemini 3.1 Pro | Few-Shot | 85-90% | Rendah |
| Ujian Akhir Semester | Claude Sonnet 4.6 | Tree of Thought | 88-92% | Menengah |
| Soal Kompetisi | GPT-5.4 Thinking | ToT + Selesaikan Soal Dulu | 80-85% | Cukup Tinggi |
| Validasi Silang | Kombinasi Tiga Model | Pemungutan Suara Multi-Ronde | 95%+ | Tinggi (3×) |
🎯 Saran Pergantian Model: Persyaratan model untuk skenario yang berbeda sangat bervariasi. APIYI apiyi.com mendukung pergantian model hanya dengan mengubah satu parameter
model, memudahkan pemilihan model optimal secara dinamis berdasarkan jenis soal.
Pertanyaan Umum
Q1: Apakah pemeriksaan kualitas soal fisika dengan Model Bahasa Besar bisa sepenuhnya menggantikan koreksi manual?
Saat ini belum bisa sepenuhnya menggantikan. Penelitian akademis menunjukkan bahwa akurasi Model Bahasa Besar dalam menangani soal perhitungan terstandarisasi bisa mencapai 90%+, tetapi pada masalah yang kurang terdefinisi (under-specified problems) akurasinya hanya 8.3%. Solusi yang direkomendasikan: Model Bahasa Besar bertanggung jawab untuk koreksi 80% soal standar, sementara manusia bertanggung jawab untuk pemeriksaan ulang 20% soal kompleks dan soal yang kontroversial.
Q2: Bagaimana kompleksitas integrasi API untuk ketiga model ini?
Ketiga model ini berasal dari tiga platform berbeda: Google, Anthropic, dan OpenAI. Jika mendaftar dan mengintegrasikannya satu per satu, biaya pengembangannya akan cukup tinggi. Direkomendasikan untuk melakukan pemanggilan melalui antarmuka terpadu APIYI apiyi.com. Semua model menggunakan format SDK OpenAI yang sama, hanya perlu mengubah parameter model untuk beralih, sehingga secara signifikan mengurangi biaya integrasi.
Q3: Bagaimana cara mengevaluasi akurasi sistem pemeriksaan kualitas?
Direkomendasikan menggunakan koefisien Cohen's Kappa untuk mengukur konsistensi antara penilaian model dan penilaian manual:
- Siapkan 50-100 soal fisika yang sudah dikoreksi manual sebagai set pengujian
- Panggil ketiga model untuk memberi nilai melalui APIYI apiyi.com
- Hitung nilai Kappa untuk setiap model dibandingkan dengan penilaian manual
- Jika Kappa > 0.8, berarti konsistensi tinggi dan sistem siap digunakan
Ringkasan
Inti dari pemeriksaan kualitas soal fisika dengan Model Bahasa Besar:
- Pilihan utama Gemini 3.1 Pro Preview: Kemampuan penalaran STEM terkuat, rasio harga-kinerja tertinggi, cocok untuk pemeriksaan kualitas soal fisika sehari-hari dalam jumlah besar.
- Claude Sonnet 4.6 cocok untuk pembuatan laporan: Mode berpikir adaptif + output terstruktur, cocok untuk ujian formal yang memerlukan dasar penilaian yang rinci.
- GPT-5.4 untuk soal kompetisi yang sulit: Kemampuan penalaran setara nilai sempurna AIME, paling andal untuk menangani soal fisika tingkat tinggi yang kompleks.
- Validasi silang multi-model meningkatkan akurasi hingga 95%+: Tiga model memberikan penilaian independen dan diambil konsensusnya, merupakan solusi otomatisasi pemeriksaan kualitas yang paling andal saat ini.
Pemilihan model bergantung pada karakteristik jenis soal dan tingkat akurasi yang dibutuhkan. Disarankan untuk menguji dan membandingkan dengan cepat melalui APIYI apiyi.com. Platform ini menyediakan kuota gratis dan antarmuka terpadu, satu Kunci API saja sudah cukup untuk memanggil semua model utama.
📚 Referensi
-
MDPI Education Sciences – Penelitian Penilaian Cerdas Soal Fisika Berbasis Model Bahasa Besar: Membandingkan kinerja empat strategi Prompt dalam penilaian soal fisika.
- Tautan:
mdpi.com/2227-7102/15/2/116 - Penjelasan: Sumber data eksperimen akurasi ≥ 0.9 untuk strategi Tree of Thought.
- Tautan:
-
Physical Review – Evaluasi LLM pada Soal Olimpiade Fisika: Evaluasi sistematis GPT dan model penalaran pada soal kompetisi fisika.
- Tautan:
link.aps.org/doi/10.1103/6fmx-bsnl - Penjelasan: Argumen kunci bahwa kemampuan penalaran fisika Model Bahasa Besar telah melampaui rata-rata manusia.
- Tautan:
-
Google DeepMind – Blog Teknis Gemini 3.1 Pro: Detail arsitektur model dan pengujian patokan STEM.
- Tautan:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - Penjelasan: Sumber resmi data evaluasi penalaran fisika Gemini 3.1 Pro.
- Tautan:
-
Anthropic – Pengumuman Peluncuran Claude Sonnet 4.6: Detail peningkatan mode berpikir adaptif dan kemampuan matematika.
- Tautan:
anthropic.com/news/claude-sonnet-4-6 - Penjelasan: Detail teknis peningkatan 27% kemampuan matematika Claude Sonnet 4.6.
- Tautan:
-
OpenAI – Pengumuman Peluncuran GPT-5.4: Upfront Planning dan peningkatan efisiensi penalaran.
- Tautan:
openai.com/index/introducing-gpt-5-4/ - Penjelasan: Data resmi nilai sempurna AIME dan optimasi efisiensi Token GPT-5.4.
- Tautan:
Penulis: Tim Teknis APIYI
Diskusi Teknis: Selamat berdiskusi di kolom komentar mengenai pengalaman praktis pemeriksaan kualitas soal fisika dengan Model Bahasa Besar. Untuk lebih banyak tutorial pemanggilan model, kunjungi pusat dokumentasi APIYI di docs.apiyi.com.