
Note de l'auteur : Le Qwen3.5-35B-A3B atteint un score de 69,2 sur SWE-bench Verified avec seulement 3B de paramètres actifs, surpassant la génération précédente Qwen3-235B. Considéré par la communauté r/LocalLLaMA comme une étape majeure pour les modèles open source face aux modèles fermés, cet article analyse en profondeur son architecture technique et sa valeur réelle.
La communauté r/LocalLLaMA est en ébullition : le Qwen3.5-35B-A3B a obtenu un score de 69,2 sur SWE-bench Verified avec seulement 3B de paramètres actifs. Il ne se contente pas de surpasser le Qwen3 de 235B de la génération précédente, il établit également un nouveau record de capacités de programmation pour les modèles exécutables localement. La communauté y voit un signe fort : un modèle de 35B capable de tourner sur du matériel grand public et dont les compétences en codage approchent le niveau de GPT-4o mini.
Valeur ajoutée : En lisant cet article, vous comprendrez pourquoi le Qwen3.5-35B fait sensation dans la communauté open source, comment son architecture MoE parvient à offrir une "grande puissance dans un petit format", et comment l'utiliser en local ou dans le cloud.

Points clés du Qwen3.5-35B
| Point clé | Description | Signification |
|---|---|---|
| Paramètres totaux | 35 milliards (35B) | Architecture MoE |
| Paramètres actifs | Seulement 3 milliards (3B) | Efficacité extrême |
| SWE-bench Verified | 69,2 points | Dépasse le Qwen3-235B |
| GPQA Diamond | 84,2 points | Raisonnement niveau master |
| Fenêtre de contexte | 256K natif / 1M+ étendu | Extension YaRN |
| Configuration requise | 22 Go de RAM/VRAM | Accessible au grand public |
| Licence open source | Apache 2.0 | Entièrement ouvert |
Pourquoi la communauté r/LocalLLaMA discute-t-elle du Qwen3.5-35B ?
r/LocalLLaMA est la communauté de grands modèles de langage locaux la plus active sur Reddit. Les membres se concentrent sur une question centrale : quel modèle peut tourner sur mon matériel tout en étant suffisamment puissant ?
Le Qwen3.5-35B-A3B répond parfaitement à ce besoin :
- 35B de paramètres totaux, mais seulement 3B activés par inférence — ce qui signifie qu'il peut fonctionner de manière fluide sur un Mac ou un GPU avec 22 Go de mémoire.
- Ses capacités de programmation (69,2 sur SWE-bench) surpassent le Qwen3-235B, qui possède pourtant 7 fois plus de paramètres.
- Licence Apache 2.0, entièrement open source, sans aucune restriction commerciale.
L'avis de la communauté : "Run Qwen 35B. It's a great chatbot, good enough for task automation." Cela résume les attentes principales des utilisateurs locaux : efficace, rapide et abordable.
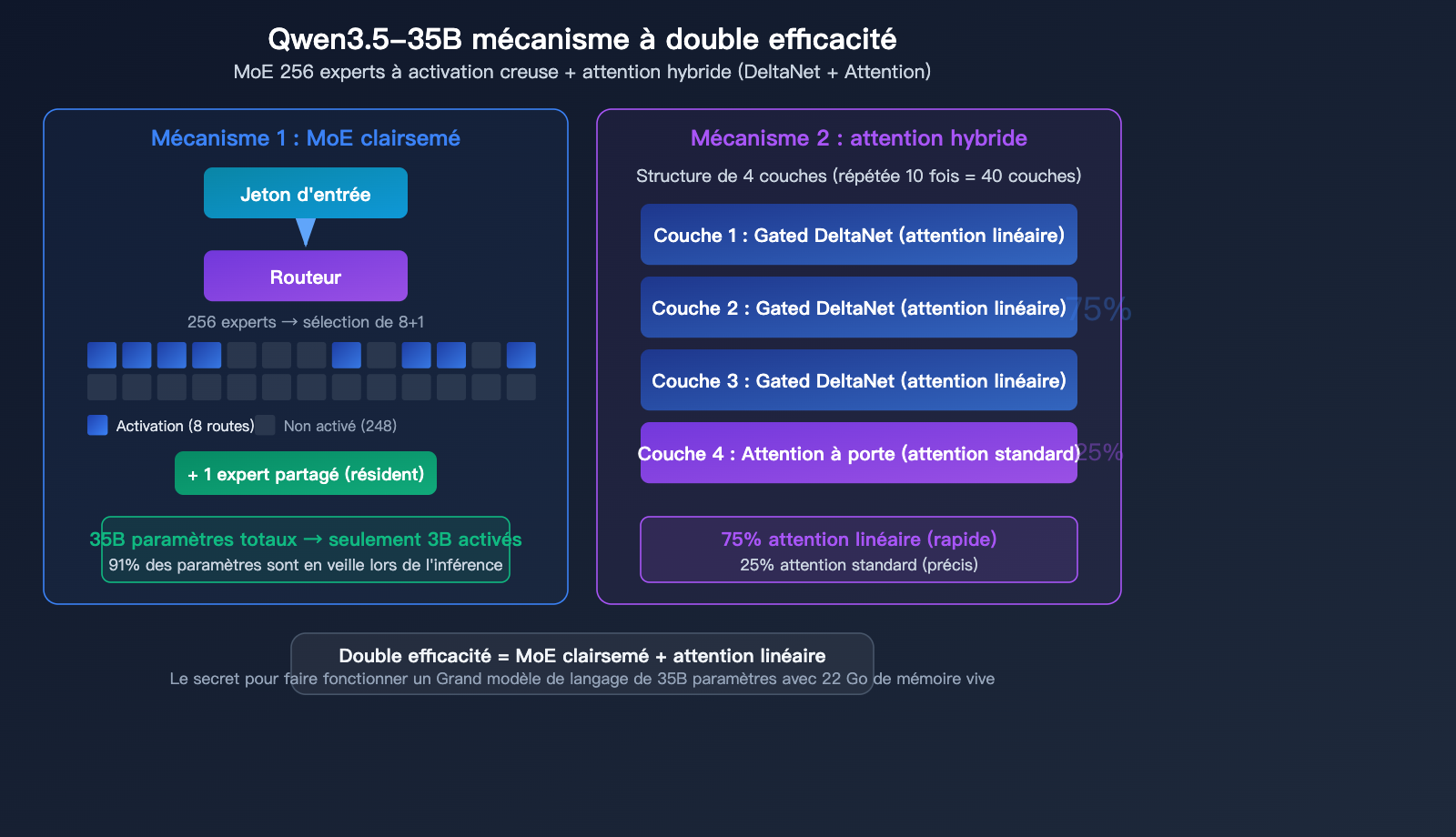
Analyse approfondie de l'architecture Qwen3.5-35B
Architecture MoE à 256 experts
Le modèle Qwen3.5-35B-A3B adopte une architecture de mélange d'experts (MoE) extrêmement fine :
| Paramètres d'architecture | Valeur | Description |
|---|---|---|
| Paramètres totaux | 35B | Somme de tous les paramètres des experts |
| Paramètres actifs | 3B | Activés à chaque inférence |
| Nombre total d'experts | 256 | Répartition à granularité très fine |
| Experts activés | 8 routés + 1 partagé | 9 experts sélectionnés par étape |
| Nombre de couches | 40 | Réseau profond |
| Dimension cachée | 2048 | Conception compacte |
Mécanisme d'attention hybride
Qwen3.5-35B n'est pas un Transformer pur, il utilise une conception à attention hybride :
La structure est répétée tous les 4 niveaux : 3 couches de Gated DeltaNet (attention linéaire) + 1 couche de Gated Attention (attention standard)
| Type d'attention | Part des couches | Caractéristiques |
|---|---|---|
| Gated DeltaNet | 75% | Attention linéaire, inférence rapide |
| Gated Attention | 25% | Attention standard, haute précision |
La subtilité de cette conception hybride réside dans le fait que la majeure partie du calcul est effectuée via une attention linéaire efficace, n'utilisant l'attention standard (plus gourmande en calcul) que sur les couches critiques. C'est le secret derrière ses 35B de paramètres pour seulement 22 Go de mémoire — non seulement l'activation des experts est parcimonieuse, mais le mécanisme d'attention lui-même est optimisé.
🎯 Aperçu technique : L'architecture du Qwen3.5-35B représente la tendance la plus récente des modèles MoE pour 2026 : une granularité ultra-fine de 256 experts combinée à une attention hybride. Si vous souhaitez profiter des gains d'efficacité offerts par cette architecture, vous pouvez invoquer les API de la série Qwen3.5 directement via le service proxy API APIYI (apiyi.com), sans déploiement local nécessaire.
Analyse complète des données d'évaluation de Qwen3.5-35B
Évaluation en programmation de Qwen3.5-35B
| Benchmark | Qwen3.5 35B-A3B | Référence | Note |
|---|---|---|---|
| SWE-bench Verified | 69.2 | Qwen3-235B: <69 | Dépasse la génération précédente 7x plus grande |
| LiveCodeBench v6 | 74.6 | – | Excellentes capacités en programmation réelle |
| CodeForces | 2 028 | – | Niveau compétition |
Évaluation du raisonnement et des connaissances de Qwen3.5-35B
| Benchmark | Qwen3.5 35B-A3B | Note |
|---|---|---|
| GPQA Diamond | 84.2 | Raisonnement scientifique niveau master |
| MMLU-Pro | 85.3 | Connaissances multidisciplinaires |
| MMLU-Redux | 93.3 | Compréhension des connaissances |
| HMMT Feb 2025 | 89.0 | Compétition de mathématiques |
| IFEval | 91.9 | Respect des instructions |
Évaluation multimodale de Qwen3.5-35B
| Benchmark | Qwen3.5 35B-A3B | Note |
|---|---|---|
| MMMU | 81.4 | Compréhension multimodale (proche des 79.6 de Claude Sonnet 4.5) |
| MMMU-Pro | 75.1 | Multimodal complexe |
| MathVision | 83.9 | Raisonnement mathématique visuel |
| VideoMME | 86.6 | Compréhension vidéo |
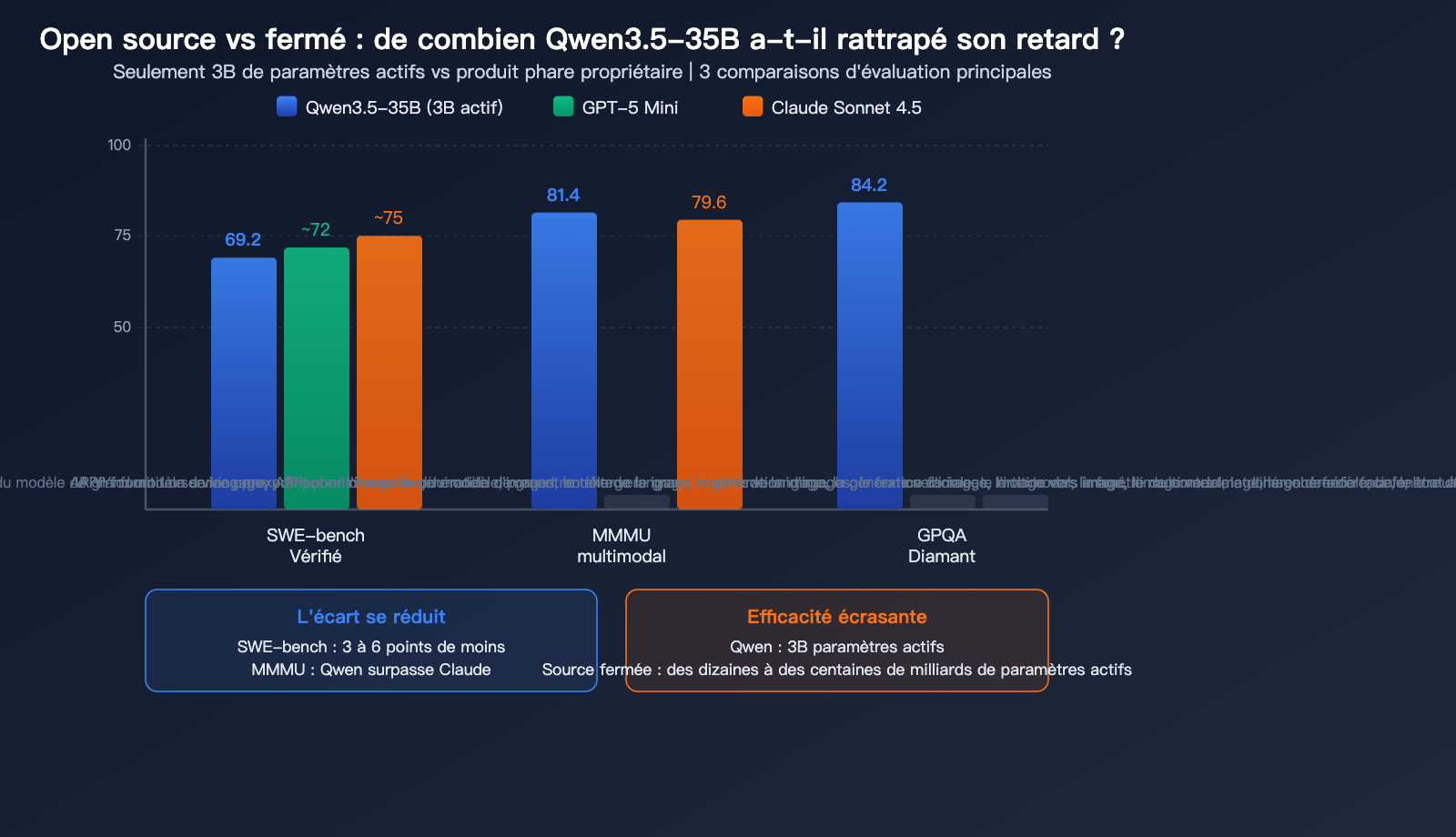
Comparaison entre Qwen3.5-35B et les modèles fermés
C'est la question qui préoccupe le plus la communauté : à quel point un modèle open source de 35B peut-il rattraper les modèles fermés ?
| Dimension | Qwen3.5 35B | GPT-5 Mini | Claude Sonnet 4.5 | Écart |
|---|---|---|---|---|
| SWE-bench | 69.2 | ~72 | ~75 | 3-6 points |
| MMMU | 81.4 | – | 79.6 | Dépassement |
| GPQA Diamond | 84.2 | – | – | Haut niveau |
| Paramètres actifs | 3B | ~dizaines de B | Inconnu | Efficacité supérieure |
| Exécutable en local | Oui (22GB) | Non | Non | Avantage unique |
L'avis de la communauté : En programmation, l'écart entre Qwen3.5-35B et les modèles de type GPT-5 Mini s'est réduit à seulement 3-6 points, et il surpasse même Claude Sonnet 4.5 en multimodal. Compte tenu de ses 3B de paramètres actifs et de sa capacité à tourner en local, son ratio efficacité/performance est probablement le meilleur parmi tous les modèles publics.
💡 Conseil pratique : Si vous souhaitez comparer les performances réelles de Qwen3.5-35B avec des modèles fermés, vous pouvez utiliser APIYI (apiyi.com) pour invoquer simultanément Qwen3.5, Claude et GPT, et effectuer un test A/B sur vos propres tâches.
Guide de déploiement local de Qwen3.5-35B
Configuration matérielle et méthodes de déploiement
| Méthode de déploiement | Configuration matérielle | Scénarios recommandés |
|---|---|---|
| Ollama | 22 Go+ RAM/VRAM | Le plus simple, exécution en un clic |
| vLLM | GPU + 24 Go+ VRAM | Débit de niveau production |
| SGLang | GPU + 24 Go+ VRAM | Recommandé pour un débit élevé |
| KTransformers | Hybride CPU + GPU | Matériel modeste |
| LM Studio | 22 Go+ RAM | Interface graphique conviviale |
Déploiement en un clic avec Ollama
# Une seule commande suffit après l'installation
ollama run qwen3.5:35b
Invocation via API (sans déploiement local)
Si vous ne souhaitez pas gérer les contraintes du déploiement local, l'invocation via API est la solution la plus simple :
import openai
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{
"role": "user",
"content": "Aide-moi à relire ce code Python pour identifier les goulots d'étranglement de performance"
}],
temperature=0.6, # 0.6 recommandé pour les tâches de programmation
max_tokens=32768
)
print(response.choices[0].message.content)
Voir le basculement entre le mode Thinking et le mode standard
import openai
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://vip.apiyi.com/v1"
)
# Mode Thinking (raisonnement approfondi, idéal pour les tâches complexes)
response_thinking = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{"role": "user", "content": "Analyse la complexité temporelle de cet algorithme"}],
temperature=1.0,
top_p=0.95,
max_tokens=32768
)
# Mode sans Thinking (réponse rapide)
response_fast = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{"role": "user", "content": "Écris une fonction de tri rapide"}],
temperature=0.7,
top_p=0.8,
max_tokens=32768,
extra_body={"chat_template_kwargs": {"enable_thinking": False}}
)
🚀 Conseil de déploiement : Le déploiement local est idéal pour les scénarios hors ligne ou nécessitant une confidentialité stricte. Pour le développement quotidien, nous recommandons d'utiliser APIYI (apiyi.com) : c'est plus rapide, sans maintenance matérielle, et vous permet de basculer librement entre Qwen3.5, Claude et GPT.
Vue d'ensemble de la famille Qwen3.5
Comparaison des spécifications de la série Qwen3.5
| Modèle | Paramètres totaux | Paramètres actifs | SWE-bench | Mémoire min. | Positionnement |
|---|---|---|---|---|---|
| Qwen3.5-4B | 4B | 4B (Dense) | – | 8 Go | Léger et accessible |
| Qwen3.5-9B | 9B | 9B (Dense) | – | 12 Go | Efficace au quotidien |
| Qwen3.5-27B | 27B | 27B (Dense) | 72.4 | 22 Go | Haute précision |
| Qwen3.5-35B-A3B | 35B | 3B (MoE) | 69.2 | 22 Go | Le roi de l'efficacité |
| Qwen3.5-122B-A10B | 122B | 10B (MoE) | – | – | Haut de gamme |
| Qwen3.5-397B-A17B | 397B | 17B (MoE) | 76.4 | – | Modèle phare |
Conseils de sélection :
- Équipement 22 Go : 35B-A3B (MoE, rapide mais précision légèrement inférieure) ou 27B (Dense, un peu plus lent mais plus précis).
- Recherche du meilleur rapport performance/coût : 35B-A3B, seulement 3B de paramètres utilisés par invocation.
- Recherche de la précision maximale : 27B Dense, sans passer par l'architecture MoE.
🎯 Choix de l'API : Via APIYI (apiyi.com), vous pouvez invoquer toute la gamme Qwen3.5, du 4B au 397B, selon vos besoins. Une seule clé API suffit pour basculer de manière flexible entre les différentes tailles de modèles Qwen et les modèles propriétaires comme Claude ou GPT.
FAQ
Q1 : Qwen3.5-35B ou 27B, lequel choisir ?
Les deux nécessitent environ 22 Go de mémoire. Le 35B-A3B utilise une architecture MoE (3 à 5 fois plus rapide, mais avec une précision légèrement inférieure), tandis que le 27B est une architecture Dense (plus précis, mais plus lent). Pour les tâches de programmation, la différence est minime (69,2 vs 72,4 sur SWE-bench). Pour les conversations quotidiennes, nous recommandons le 35B (plus rapide), et pour les tâches complexes, le 27B (plus précis). Vous pouvez invoquer les deux via APIYI apiyi.com pour les comparer.
Q2 : Les modèles open source rattrapent-ils vraiment les modèles propriétaires ?
Oui, mais avec quelques nuances. Le Qwen3.5-35B dépasse Claude Sonnet 4.5 sur MMMU (81,4 vs 79,6) et l'écart avec GPT-5 Mini sur SWE-bench n'est que de 3 points. Cependant, sur les tâches de programmation les plus ardues et le raisonnement complexe, les fleurons propriétaires (Claude Opus 4.5, GPT-5.4) conservent un avantage notable. L'open source réduit l'écart, mais n'a pas encore totalement égalé les meilleurs modèles propriétaires.
Q3 : Un Mac avec 22 Go peut-il faire tourner Qwen3.5-35B ?
Oui. Le Qwen3.5-35B-A3B n'active que 3 milliards de paramètres par inférence ; un Mac doté de 22 Go de mémoire unifiée (comme les configurations de base M2/M3/M4) peut l'exécuter de manière fluide. Nous recommandons d'utiliser Ollama (ollama run qwen3.5:35b) pour un démarrage en un clic. Si vous ne souhaitez pas effectuer de déploiement local, l'invocation via le cloud sur APIYI apiyi.com est encore plus simple.
Conclusion
Voici les 5 points clés à retenir sur le record établi par Qwen3.5-35B en programmation open source :
- Révolution de l'efficacité : 35B de paramètres totaux pour seulement 3B actifs. Il fonctionne avec 22 Go et surpasse en programmation les modèles de 235B de la génération précédente.
- Puissance en programmation : 69,2 sur SWE-bench, 2028 sur CodeForces et 74,6 sur LiveCodeBench ; une nouvelle référence pour les modèles locaux.
- Innovation architecturale : MoE à 256 experts + attention hybride (DeltaNet + attention standard), offrant le meilleur ratio efficacité/capacité.
- L'open source rattrape le propriétaire : dépasse Claude Sonnet 4.5 sur MMMU et se rapproche de GPT-5 Mini sur SWE-bench ; l'écart se resserre.
- Ouverture totale : licence Apache 2.0, aucune restriction commerciale, coût de déploiement local nul.
Qwen3.5-35B prouve une chose : les modèles open source ne sont plus de simples versions au rabais des modèles propriétaires, ils les rattrapent, voire les dépassent, avec une efficacité supérieure. Nous vous recommandons d'accéder à toute la gamme Qwen3.5 ainsi qu'aux modèles propriétaires via APIYI apiyi.com, afin de comparer les performances des deux mondes sur vos tâches réelles avec une seule clé API.
📚 Références
-
Fiche technique du modèle Qwen3.5-35B-A3B – Hugging Face : Paramètres techniques complets et données d'évaluation
- Lien :
huggingface.co/Qwen/Qwen3.5-35B-A3B - Description : Inclut les détails de l'architecture, les scores d'évaluation et les recommandations de paramètres d'inférence.
- Lien :
-
Dépôt GitHub de Qwen3.5 : Code source et guide de déploiement
- Lien :
github.com/QwenLM/Qwen3.5 - Description : Contient le téléchargement complet des poids du modèle et la documentation de déploiement.
- Lien :
-
Guide complet de Qwen3.5 : Évaluation de la série complète et analyse de l'architecture
- Lien :
techie007.substack.com/p/qwen-35-the-complete-guide-benchmarks - Description : Comparaison détaillée de toute la famille de modèles et analyse comparative avec les modèles propriétaires.
- Lien :
-
Ollama – Qwen3.5:35B : Déploiement local en un clic
- Lien :
ollama.com/library/qwen3.5:35b - Description : La méthode la plus simple pour une exécution en local.
- Lien :
Auteur : Équipe technique APIYI
Échanges techniques : N'hésitez pas à partager votre expérience de déploiement local de Qwen3.5 dans les commentaires. Pour plus d'informations sur l'intégration des modèles d'IA, consultez le centre de documentation APIYI sur docs.apiyi.com.