
作者注:深度对比 Claude Opus 4.7 与 GLM-5.1 在编程领域的能力差异,涵盖 SWE-Bench、CursorBench 等基准测试、长周期自主编码、API 定价,帮助开发者选择最适合的编码模型。

2026 年 4 月,AI 编码领域迎来了两个重磅选手的正面交锋。4 月 7 日,智谱 AI(Z.ai)发布开源模型 GLM-5.1,以 SWE-Bench Pro 58.4 分登顶全球榜首;仅 9 天后的 4 月 16 日,Anthropic 发布 Claude Opus 4.7,CursorBench 从 58% 跃升至 70%,Rakuten-SWE-Bench 解决任务量达到 4.6 的 3 倍。
两个模型定位不同、架构不同、价格差距巨大——但在编码这个核心战场上正面竞争。API易 apiyi.com 已同时上线这两个模型,开发者可以通过统一接口快速对比。
核心价值:看完本文,你将清楚两个模型各自的编码优势,以及在不同场景下应该选谁。
Claude Opus 4.7 vs GLM-5.1 核心参数对比
| 对比维度 | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| 发布日期 | 2026.04.16 | 2026.04.07 |
| 开发商 | Anthropic | 智谱 AI(Z.ai) |
| 模型架构 | 闭源 | 744B MoE(40B 活跃参数) |
| 开源许可 | ❌ 闭源 | ✅ MIT 许可证(完全开放) |
| 上下文窗口 | 1M tokens | 200K tokens |
| 最大输出 | 128K tokens | 131K tokens |
| API 输入价格 | $5 / MTok | $1 / MTok |
| API 输出价格 | $25 / MTok | $3.2 / MTok |
| 视觉能力 | ✅ 2576px / 3.75MP | ✅ 支持 |
| 思考模式 | Adaptive Thinking | 多模式 Thinking |
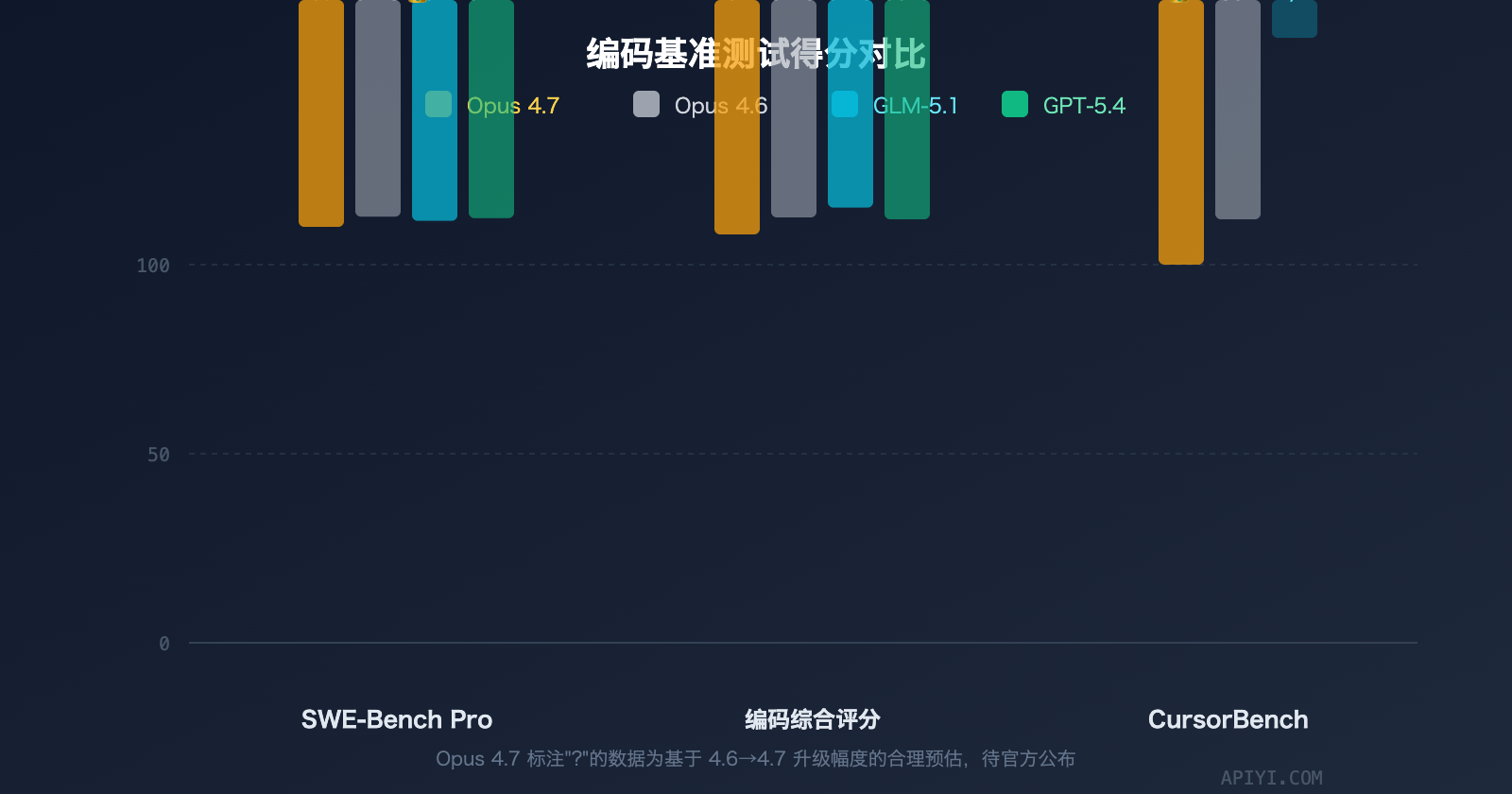
| SWE-Bench Pro | 预计 > 57.3(4.6 的分数) | 58.4(当前榜首) |
| CursorBench | 70% | — |
| 训练硬件 | 美国 GPU 集群 | 华为昇腾 910B |
🎯 快速结论:如果你追求极致编码能力 + 超长上下文 + 视觉理解,选 Opus 4.7;如果你追求极致性价比 + 开源可控 + 足够强的编码能力,选 GLM-5.1。两个模型在 API易 apiyi.com 上均已上线。
编程基准测试深度对比
SWE-Bench Pro:GLM-5.1 当前领先
SWE-Bench Pro 是目前最权威的真实世界编码基准测试之一,测试模型解决 GitHub 上真实 Issue 的能力。
| 模型 | SWE-Bench Pro | 排名 |
|---|---|---|
| GLM-5.1 | 58.4 | #1 |
| GPT-5.4 | 57.7 | #2 |
| Claude Opus 4.6 | 57.3 | #3 |
| Claude Opus 4.7 | 预计 > 57.3 | 待更新 |
GLM-5.1 以 58.4 分登顶 SWE-Bench Pro,超越 GPT-5.4(57.7)和 Claude Opus 4.6(57.3)。值得注意的是,Opus 4.7 相比 4.6 在编码领域有显著提升(CursorBench +12pp,Rakuten-SWE-Bench 3 倍),其 SWE-Bench Pro 分数预计会有实质性提高,但截至发稿时尚未公布。
CursorBench:Opus 4.7 大幅领先
CursorBench 测试模型在真实 IDE 环境(Cursor 编辑器)中的代码编写能力,更贴近日常开发场景。
| 模型 | CursorBench |
|---|---|
| Claude Opus 4.7 | 70% |
| Claude Opus 4.6 | 58% |
| GLM-5.1 | 暂无数据 |
编码综合评分(Coding Composite)
编码综合评分聚合了 SWE-Bench Pro、Terminal-Bench 2.0 和 NL2Repo 等多个维度:
| 模型 | 编码综合评分 |
|---|---|
| GPT-5.4 | 58.0 |
| Claude Opus 4.6 | 57.5 |
| GLM-5.1 | 54.9 |
| Claude Opus 4.7 | 预计显著高于 4.6 |
在综合编码评分上,Claude Opus 4.6 以 57.5 领先 GLM-5.1 的 54.9。Opus 4.7 的综合编码能力预计将进一步拉开差距。
🎯 解读:GLM-5.1 在 SWE-Bench Pro 单项上做到了最强,但在编码综合能力上,Claude 系列仍然保持领先。开发者可以通过 API易 apiyi.com 同时接入两个模型,在自己的实际项目中进行 A/B 测试。
编程场景能力深度对比
基准测试只是一个维度。在实际编程场景中,两个模型展现出截然不同的优势。
长周期自主编码
这是 GLM-5.1 的杀手级特性。
| 长周期能力 | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| 最大自主执行时间 | 取决于 Task Budget | 8 小时不间断 |
| 自主循环 | 支持多步骤智能体 | 完整「计划→执行→测试→修复→优化」闭环 |
| Token 预算管理 | Task Budgets(新功能) | 内置长任务管理 |
| 自我修复 | 编码时自动修复 | 实验→分析→优化自主循环 |
GLM-5.1 能够在长达 8 小时的时间内持续自主执行编码任务,形成「实验→分析→优化」的闭环,这在处理大型重构、跨模块迁移等场景中极具优势。
Opus 4.7 虽然通过 Task Budgets 和 xhigh 推理等级增强了长任务能力,但更侧重于「在预算内高效完成」而非「长时间无限执行」。
智能体任务(Agentic Tasks)
| 智能体能力 | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| MCP 原生支持 | ✅ 深度优化 | ✅ 支持 |
| 工具调用效率 | 更少调用,更多推理 | 积极使用工具 |
| 多步骤可靠性 | 非常高 | 高 |
| 上下文管理 | 1M tokens 超长上下文 | 200K tokens |
| 子智能体管理 | 精细控制(可调节) | 支持 |
在智能体任务方面,Opus 4.7 的1M token 上下文窗口是压倒性优势。处理大型代码库时,Opus 4.7 可以一次性加载更多文件上下文,减少信息丢失。
代码审查与重构
| 代码审查能力 | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| 指令精确度 | 更字面化执行,精准不遗漏 | 灵活解读 |
| 自验证能力 | 先验证再输出(新增) | 支持 |
| 大文件处理 | 1M 上下文加载完整代码库 | 200K 限制可能需要分段 |
| 视觉审查 | 高分辨率截图理解 | 基础视觉 |
快速编码与日常开发
| 日常编码 | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| 响应速度 | 中等 | 较快 |
| API 成本 | $5/$25 per MTok | $1/$3.2 per MTok |
| 代码风格 | 更精炼,倾向推理 | 详细注释,倾向工具调用 |
| 多语言支持 | 优秀 | 优秀(中文代码注释更自然) |
价格对比:5 倍的成本差距
价格是选择模型时不可忽视的因素。两者的定价差距非常大:
| 计费项 | Claude Opus 4.7 | GLM-5.1 | 差距 |
|---|---|---|---|
| 输入价格 | $5 / MTok | $1 / MTok | Opus 贵 5 倍 |
| 输出价格 | $25 / MTok | $3.2 / MTok | Opus 贵 7.8 倍 |
| 缓存价格 | 标准 Cache 折扣 | $0.26 / MTok | GLM 缓存极便宜 |
| 长上下文溢价 | 无 | 无 | — |
实际场景成本估算
假设一个中型开发团队每月消耗 500M tokens(输入+输出各半):
| 使用模型 | 月均输入成本 | 月均输出成本 | 月度总计 |
|---|---|---|---|
| Opus 4.7 | $1,250 | $6,250 | $7,500 |
| GLM-5.1 | $250 | $800 | $1,050 |
| 差价 | — | — | $6,450/月 |
GLM-5.1 的成本仅为 Opus 4.7 的约 14%。对于预算敏感的团队,这是决定性的差异。
🎯 成本优化策略:通过 API易 apiyi.com 平台,你可以灵活调配两个模型——将复杂的架构设计和代码审查交给 Opus 4.7,将大量的日常代码生成和批处理任务交给 GLM-5.1。平台的统一接口使得多模型策略的实施成本极低。

不同场景的选择建议
选 Claude Opus 4.7 的场景
- 超大代码库处理:需要一次性加载数十个文件的上下文(1M vs 200K)
- 代码审查与安全审计:需要极高精确度和自验证能力
- 多模态开发:需要理解 UI 截图、设计稿、文档图片(3.75MP 高分辨率视觉)
- 企业级可靠性要求:需要稳定的闭源商业支持
- 复杂推理密集型编码:数学计算、算法设计等需要深度推理的场景
选 GLM-5.1 的场景
- 长周期自主开发:需要模型持续工作数小时完成大型重构
- 成本敏感的批量任务:CI/CD 集成、批量代码生成、自动化测试
- 私有化部署:需要在自己的服务器上运行模型(MIT 许可证,完全开放)
- 中文开发环境:中文代码注释和文档生成更自然流畅
- SWE-Bench 类任务:解决 GitHub Issue、修复 Bug 等真实世界编码任务
最佳实践:双模型策略
| 任务类型 | 推荐模型 | 理由 |
|---|---|---|
| 架构设计与技术方案 | Opus 4.7 | 深度推理 + 超长上下文 |
| 日常代码编写 | GLM-5.1 | 成本低,质量够用 |
| 代码审查 | Opus 4.7 | 精确度 + 自验证 |
| 大批量代码生成 | GLM-5.1 | 成本仅 14% |
| Bug 修复(GitHub Issue) | GLM-5.1 | SWE-Bench Pro 榜首 |
| 多文件重构 | Opus 4.7 | 1M 上下文优势 |
| 长时间自主任务 | GLM-5.1 | 8 小时自主执行 |
| UI/截图相关开发 | Opus 4.7 | 3.75MP 高分辨率视觉 |
🎯 统一管理建议:API易 apiyi.com 已同时上线 Claude Opus 4.7 和 GLM-5.1,开发者可以通过同一个 API Key 和统一的 OpenAI 兼容接口调用两个模型,根据任务类型灵活切换,实现最优的编码效率和成本平衡。
常见问题
Q1:GLM-5.1 真的比 Claude Opus 强吗?
看具体维度。在 SWE-Bench Pro 单项上,GLM-5.1(58.4)确实超过了 Opus 4.6(57.3),但在编码综合评分上 Opus 4.6(57.5)领先 GLM-5.1(54.9)。Opus 4.7 作为 4.6 的重大升级,综合编码能力预计进一步拉开差距。总体而言,Opus 4.7 综合更强,但 GLM-5.1 在特定场景(长周期任务、SWE-Bench 类任务)有独特优势。
Q2:GLM-5.1 便宜这么多,质量够用吗?
对于大多数编码任务,够用。GLM-5.1 在 SWE-Bench Pro 上的表现证明它具备顶级编码能力。有评测数据显示它达到了 Claude Opus 4.6 编码能力的 94.6%,但价格仅为 1/5 到 1/8。通过 API易 apiyi.com 实际对比后再做决策是最稳妥的方式。
Q3:两个模型可以通过同一个接口调用吗?
可以。API易 apiyi.com 提供统一的 OpenAI 兼容接口,只需更换模型 ID 即可在 Claude Opus 4.7 和 GLM-5.1 之间切换,无需修改代码框架或管理多个 API Key。
总结
Claude Opus 4.7 vs GLM-5.1 编程对比的核心结论:
- SWE-Bench Pro 单项:GLM-5.1(58.4)当前领先,但 Opus 4.7 的分数尚未公布
- 综合编码能力:Opus 系列整体领先,4.7 的 CursorBench 70% 和 3 倍 Rakuten-SWE-Bench 提升令人印象深刻
- 长周期自主编码:GLM-5.1 的 8 小时自主执行是独特卖点
- 上下文窗口:Opus 4.7 的 1M 是 GLM-5.1 的 5 倍,处理大型代码库的优势明显
- 价格差距:GLM-5.1 的成本仅为 Opus 4.7 的约 14%
- 开源优势:GLM-5.1 采用 MIT 许可证,支持私有化部署和自由定制
最优策略不是二选一,而是双模型配合——高价值任务用 Opus 4.7,高频批量任务用 GLM-5.1。API易 apiyi.com 已同时上线两个模型,开发者可通过统一接口灵活调用,实现编码效率和成本的最佳平衡。
📚 参考资料
-
VentureBeat – GLM-5.1 开源发布报道: GLM-5.1 登顶 SWE-Bench Pro 的详细报道
- 链接:
venturebeat.com/technology/ai-joins-the-8-hour-work-day-as-glm-ships-5-1-open-source-llm-beating-opus-4 - 说明: 权威科技媒体的发布报道,包含基准测试数据
- 链接:
-
MarkTechPost – GLM-5.1 技术分析: 754B 智能体模型的技术解析
- 链接:
marktechpost.com/2026/04/08/z-ai-introduces-glm-5-1 - 说明: 包含架构详情和 8 小时自主执行能力分析
- 链接:
-
Anthropic 官方 – Claude Opus 4.7 发布: 完整的升级说明
- 链接:
anthropic.com/news/claude-opus-4-7 - 说明: Opus 4.7 的官方公告和基准测试数据
- 链接:
-
GLM-5.1 HuggingFace 模型页: 开源模型下载和文档
- 链接:
huggingface.co/zai-org/GLM-5.1 - 说明: MIT 许可证下的模型权重和部署指南
- 链接:
-
Claude API 文档 – 模型概览: 所有 Claude 模型的技术规格
- 链接:
platform.claude.com/docs/en/about-claude/models/overview - 说明: 官方模型参数、定价和功能对比
- 链接:
作者: APIYI 技术团队
技术交流: 欢迎在评论区讨论,更多资料可访问 API易 docs.apiyi.com 文档中心