
谷歌在 2026 年 5 月 19 日的 Google I/O 2026 大会上正式发布了 Gemini Omni 多模态模型家族,首发型号 Gemini Omni Flash 当天就开始向用户推送。对于第一次听到这个名字的新人来说,「Omni」这个词远比想象中重要——它代表了谷歌把 Gemini 的智能推理能力和媒体生成能力彻底融合的全新方向。本文将用最通俗的方式,带你 5 分钟看懂 Google Omni 到底是什么、能做什么、和过去的 Veo 有何不同,以及作为开发者或创作者该如何上手。
核心价值: 读完本文,你将清楚 Google Omni (Gemini Omni) 的定位、能力边界、使用渠道与行业意义,不再被各种新闻标题里的术语绕晕。
Google Omni 是什么:核心信息速览
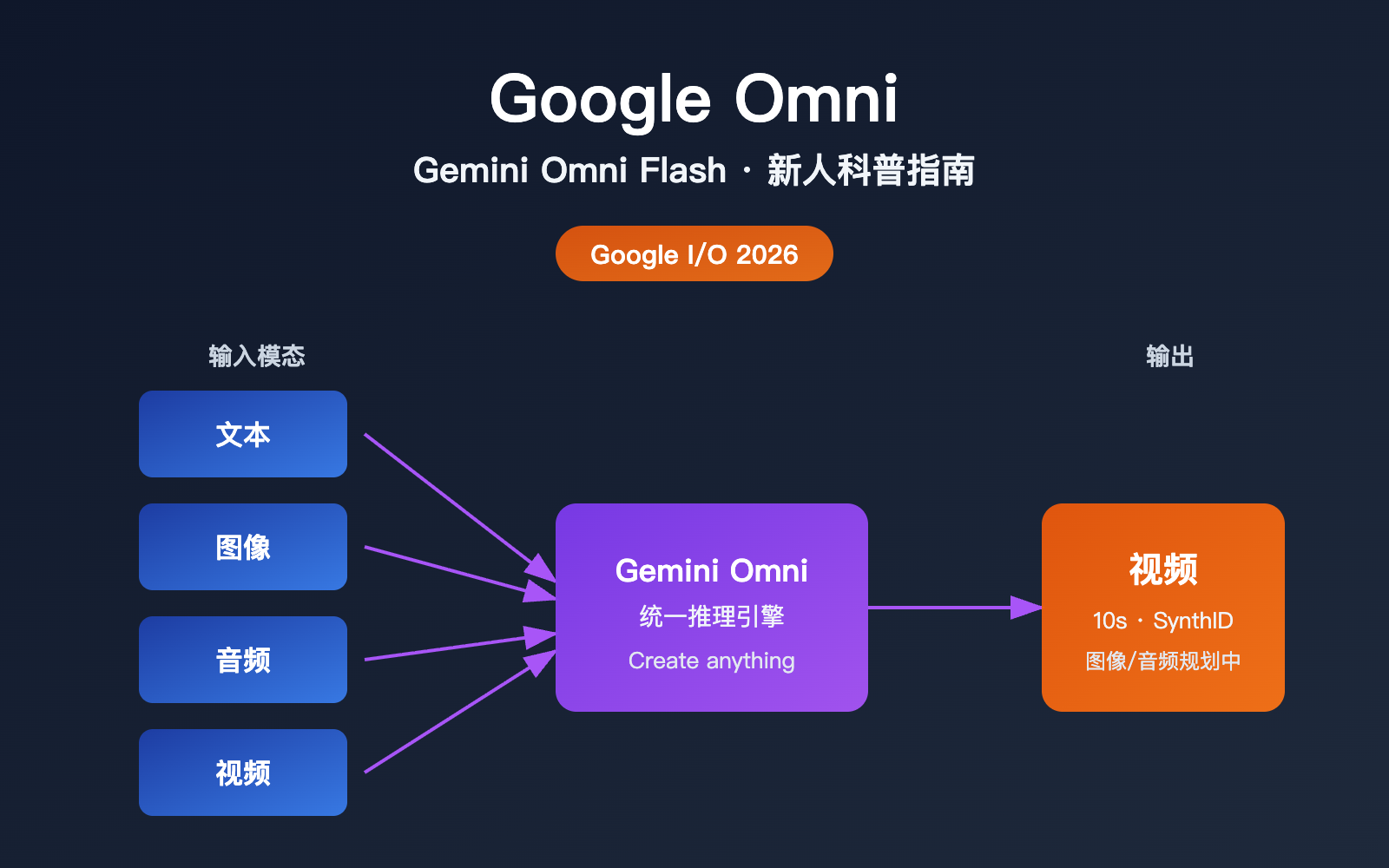
简单一句话总结:Google Omni 是谷歌推出的「多模态生成模型家族」,首款型号是 Gemini Omni Flash。它的最大卖点不是「又一个会生成视频的 AI」,而是「能把文字、图像、音频、视频任意组合作为输入,统一推理后产出一段连贯视频」。
谷歌 CEO Sundar Pichai 在主旨演讲里用了一句很直白的话来形容它的定位:「create anything from any input」。换句话说,过去你需要先用一个模型生成图,再用另一个模型把图变成视频;而 Omni 试图用一个模型完成跨模态的推理与生成。
| 信息项 | 详情 |
|---|---|
| 发布时间 | 2026 年 5 月 19 日 (Google I/O 2026) |
| 发布方 | Google (Google DeepMind & Google Labs) |
| 首发型号 | Gemini Omni Flash |
| 模型定位 | 多模态推理 + 媒体生成统一模型家族 |
| 输入模态 | 文本、图像、视频、音频 (任意组合) |
| 输出模态 | 视频 (首发主推),图像与音频后续开放 |
| 单段时长 | 最长 10 秒 (部署阶段限制,非模型上限) |
| 内容标识 | 全部视频自动嵌入 SynthID 隐形水印 |
| 后续规划 | Gemini Omni Pro 专业版、更长时长、音频编辑能力 |
💡 新人提示: 想第一时间体验包含 Gemini 系列在内的多种主流模型,可以通过 API易 apiyi.com 用统一接口快速调用,免去逐个平台注册的麻烦。
Google Omni 关键能力解读:为什么说它是「新一代」
如果只看「输入是什么、输出是什么」,容易把 Omni 当成 Sora、Veo、Runway 这些视频模型的同类。但谷歌产品总监 Nicole Brichtova 给了一个更精准的说法:「这是结合 Gemini 智能与媒体模型渲染能力的下一步。」下面四个能力,是新人理解 Omni 与传统视频模型差异的关键。
1. 跨模态推理,而非简单拼接
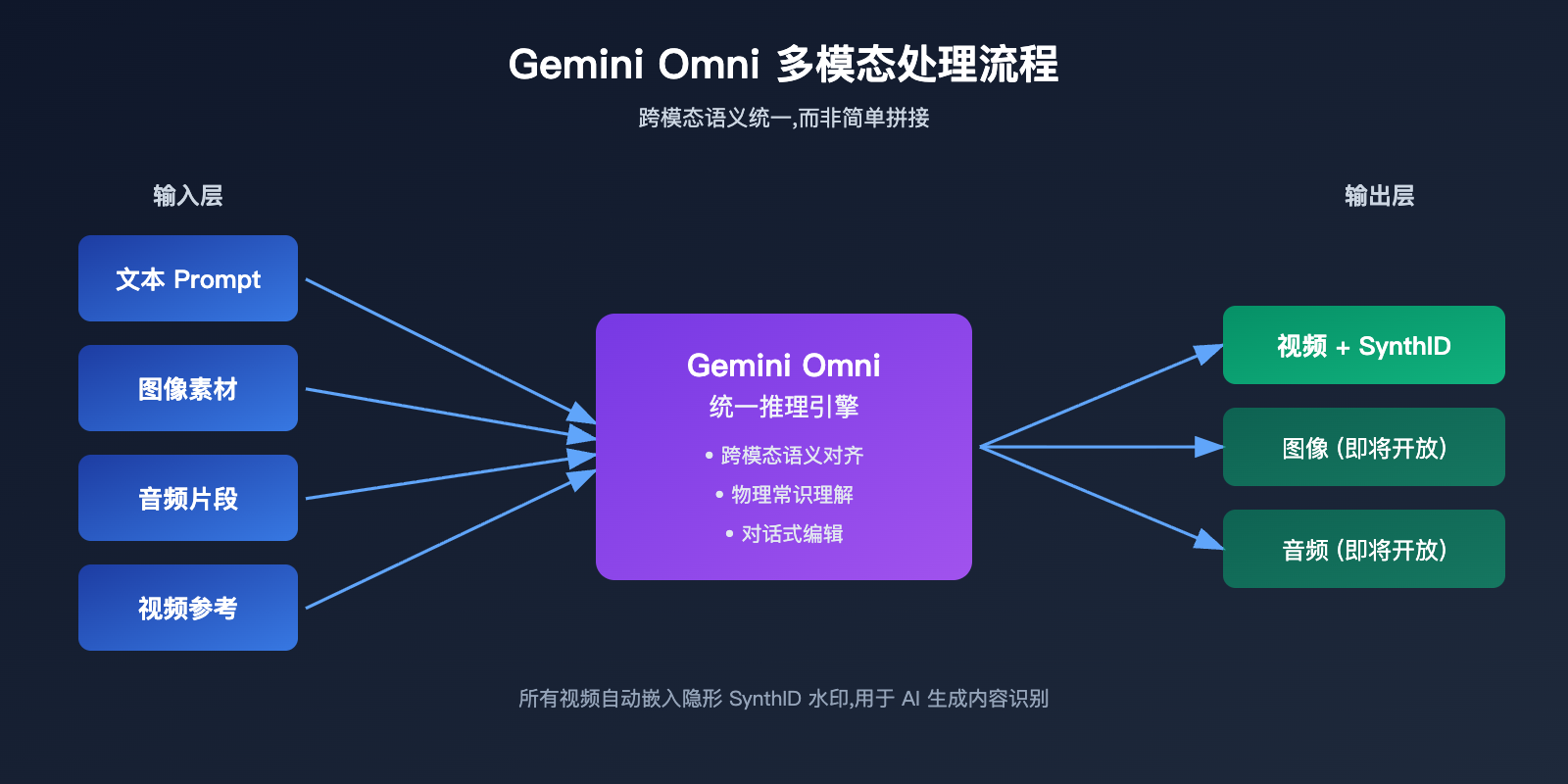
传统视频生成往往是「文字 → 视频」或「图 + 文字 → 视频」的两步式流程。Gemini Omni 的做法是把所有输入扔进同一个模型,让它在内部建立一个统一的语义理解,然后一次性渲染出视频。
举个例子,如果你把一张产品照片、一段背景音乐和一段广告台词同时丢给 Omni,它会理解「产品要在节奏切换时出现」「台词要和画面动作呼应」,而不是简单地把音乐叠在视频上。这种「先理解、再生成」的能力,是 Gemini 模型本身的推理基因带来的。
2. 物理理解与世界知识
谷歌在演示中重点展示了两个例子:一个滚动玛瑙球的镜头,小球落地时的反弹、停留、碰撞声音都符合真实物理;另一个是蛋白质折叠的 claymation 黏土风格科普动画,几何结构基本符合分子生物学常识。这两个 demo 看似简单,实际背后是模型对「真实世界规律」的理解,而不仅仅是像素层面的拟合。
对新人来说,这意味着 Omni 生成的视频更不容易出现「物体瞬移」「光影错乱」「人物多手指」等典型 AI 视频瑕疵。
3. 对话式迭代编辑
Omni 支持「先生成、再用自然语言修改」。你可以让模型生成一段视频后,再说「把背景换成黄昏」「把镜头慢一点」,模型会在保持人物、场景、动作连贯的前提下做局部调整。
这种交互方式更像和一个剪辑师对话,而不是一次性写好长 prompt。对没有提示词工程经验的新人尤其友好。
4. 自定义数字分身 Avatar
Omni 允许用户通过生物特征认证创建自己的数字分身,然后把这个 Avatar 嵌入到生成的视频中。谷歌强调这一步必须本人完成生物认证,目的是降低换脸滥用风险。
🎯 能力总结: Omni 的关键不是「更高分辨率」或「更长时长」,而是「跨模态推理 + 物理常识 + 对话编辑」三件套。要把这些能力放进自己的产品,我们建议通过 API易 apiyi.com 这类聚合接口测试不同模型组合的效果,再决定主力方案。
Gemini Omni 和 Veo 有什么区别:新人最容易混淆的两个名字
很多新人会问:谷歌不是已经有 Veo 了吗,Omni 又是干什么的?这是非常合理的疑问,因为它们都「能生成视频」,但定位完全不同。下面这张表是新人理解两者关系的最快方式。
| 对比维度 | Veo | Gemini Omni |
|---|---|---|
| 模型类型 | 专用媒体模型 | 多模态推理 + 媒体生成统一模型 |
| 输入支持 | 文本、图像 | 文本 + 图像 + 音频 + 视频 (任意组合) |
| 推理深度 | 渲染层面为主 | 调用 Gemini 推理,跨模态语义统一 |
| 编辑方式 | 重新生成为主 | 支持对话式增量编辑 |
| 物理理解 | 一般 | 显著增强 (官方 demo 重点强调) |
| 适用人群 | 专业视频创作者 | 创作者 + 普通消费者 + 开发者 |
| 当前定位 | 高质量视频生成工具 | 跨模态「create anything」基础模型 |
简单类比:Veo 像是一台高保真打印机,你给它一张图,它能打出精美的成品;而 Omni 更像一个能理解你意图的全能助理,你随手丢一些素材和一句话需求,它就能产出成片。两者未来很可能并存,但 Omni 代表了谷歌押注的「统一多模态」路线。

🧭 新人选择建议: 如果你只是想生成精美短片,Veo 依然够用;如果你要做「图文音视频混合输入」的应用场景,Omni 是更合适的方向。要快速对比这两类模型的实际表现,推荐通过 API易 apiyi.com 这种支持多模型切换的接口做 A/B 测试,以便在同一套代码里换模型不换流程。
Gemini Omni Flash 怎么用:新人上手指南
发布之初,Gemini Omni Flash 已经向不同人群开放,但渠道并不统一。下面这张渠道对照表可以帮新人快速判断「我应该从哪里开始用」。
| 用户类型 | 推荐入口 | 是否收费 | 备注 |
|---|---|---|---|
| 普通消费者 | Gemini app | 需订阅 Google AI Plus/Pro/Ultra | 个人创意、短视频制作 |
| 内容创作者 | Google Flow | 需订阅 Google AI 套餐 | 面向专业创意工作流 |
| 短视频用户 | YouTube Shorts、YouTube Create App | 免费 | 限时免费体验,首选入门通道 |
| 开发者 / 企业 | Google API (即将上线) | 暂未公布定价 | 数周内开放,可关注后续公告 |
| 多模型评估者 | 第三方聚合 API 平台 | 看平台定价 | 适合同时对比多家模型的研发团队 |
新人最简单的上手路径
- 如果你完全没有付费 AI 工具,推荐先去 YouTube Shorts 或 YouTube Create App 体验免费的 Omni 视频生成,这是门槛最低的入口。
- 如果你已经是 Google AI Plus 及以上订阅用户,直接打开 Gemini app,在创作面板里就能看到 Omni 视频生成入口。
- 如果你是开发者,目前最务实的做法是先在消费者端体验效果,等待官方 API 开放;同时通过 API易 apiyi.com 调用 Gemini 系列其它已开放型号,提前打通自己的多模态调用链路。
一段最简调用思路 (待官方 API 开放后)
虽然 Omni 的官方开发者 API 还在「数周内推出」阶段,但我们可以预先设计调用结构,等接口开放即可直接接入。
# 多模型聚合调用示例 (示意结构,Omni 官方 API 开放后替换 model 即可)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # 通过 API易 统一接入多模型
)
# 当前可立即调用 Gemini 系列已开放型号
response = client.chat.completions.create(
model="gemini-2.5-pro",
messages=[{"role": "user", "content": "用一句话解释多模态模型的核心价值"}]
)
print(response.choices[0].message.content)
💡 快速上手建议: 新人不必等到所有官方 API 全部开放再动手,通过 API易 apiyi.com 提前用 Gemini 系列其它型号搭好流程,等 Omni API 正式上线后只需替换模型名称,几乎零迁移成本。
Google Omni 对开发者和行业的影响
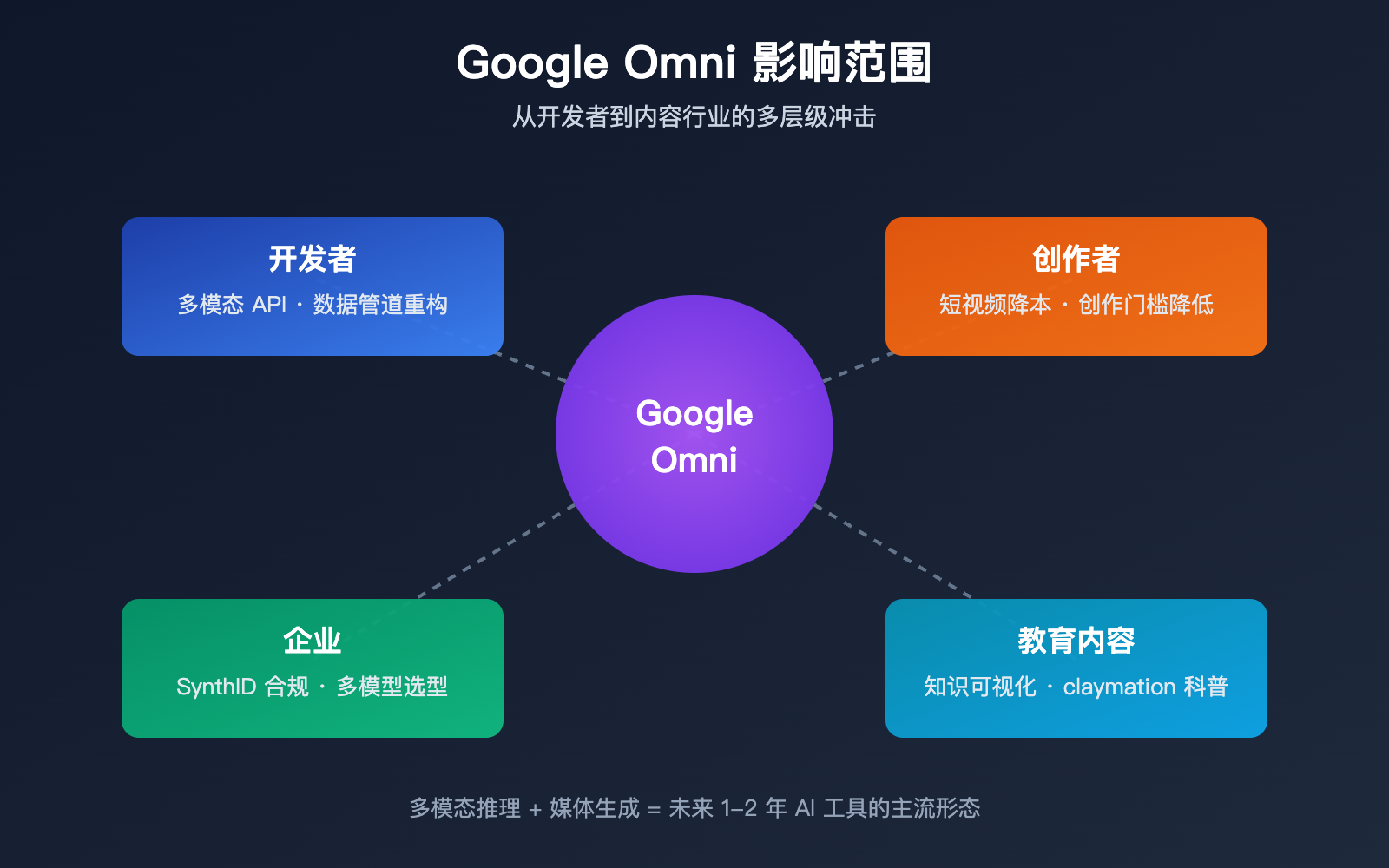
很多新人会关心:这个新模型对我意味着什么?这个问题对开发者、创作者、企业三类人群答案不同。
对开发者的影响
| 影响方向 | 具体表现 |
|---|---|
| 调用方式 | 多模态 prompt 设计取代「先 t2i 再 i2v」流水线 |
| 工具链 | SDK 需要适配「视频/音频输入流」而非纯文本 |
| 内容合规 | SynthID 水印成为默认要求,需提前规划检测与展示 |
| 成本结构 | 单次生成成本可能高于纯文本调用,需精细管理用量 |
对正在搭建 AI 应用的工程师来说,Omni 释放了一个明确信号:未来的 AI 接口不再是「文本进文本出」,而是「多模态进多模态出」。提前重构数据管道、把素材以模态分类管理,会让你在 Omni API 正式开放时占据先发优势。
对内容行业的影响
短视频平台、广告公司、教育内容生产者会最先受益。一段 10 秒的高质量视频原本需要几个小时的剪辑,Omni Flash 可以在几分钟内产出可用的初稿。对长尾创作者来说,「从一张图到一段成片」的门槛被显著拉低。
但需要注意,SynthID 水印的强制嵌入,也意味着「AI 生成」这件事会越来越透明。平台、品牌方、监管机构都可能基于这个水印做内容标注与审核策略调整。
对企业用户的影响
企业用户最关心两件事:一是合规与品牌安全,二是规模化成本。SynthID 水印解决了第一类问题的一半;而第二类问题取决于谷歌后续公布的 API 定价。对预算敏感的团队来说,提前通过 API易 apiyi.com 这类聚合平台同时评估 Gemini、GPT、Claude 等多家厂商的视频或多模态能力,再根据成本与质量做选型,是更稳妥的策略。
常见问题
Q1: Google Omni 和 Gemini Omni 是同一个东西吗?
是的。Google Omni 是非官方的简称,谷歌官方使用的全称是「Gemini Omni」,属于 Gemini 模型家族下的多模态分支。Gemini Omni Flash 则是这个家族的首发型号。两个名字指的是同一类技术。
Q2: 新人现在能免费体验 Gemini Omni 吗?
可以。最直接的方式是在 YouTube Shorts 或 YouTube Create App 中使用 Omni 视频生成功能,目前对创作者免费开放。如果你想在 Gemini app 里使用,则需要 Google AI Plus、Pro 或 Ultra 订阅。
Q3: Gemini Omni 单段视频为什么只有 10 秒?
这是部署阶段的限制,而非模型本身的能力上限。官方解释是「在算力紧张阶段,先把能力开放给更多用户」。后续 Omni Pro 等型号会逐步延长视频时长。
Q4: SynthID 水印会影响视频画质或商用吗?
不会。SynthID 是隐形水印,人眼无法察觉,也不会影响画质。它的作用是让平台和工具能在内容流转过程中识别「这段视频由 AI 生成」。商业使用需要遵循谷歌服务条款。
Q5: 开发者现在该做什么准备?
第一,熟悉多模态 prompt 的设计逻辑,而不是只写文本提示词。第二,梳理自己的素材库,按模态分类。第三,提前把多模型调用流程跑通,推荐通过 API易 apiyi.com 用统一接口调用现有 Gemini 系列型号,等 Omni API 正式上线后无缝切换。
Q6: Gemini Omni 会取代 Veo 吗?
短期内不会。Veo 仍然是高质量专用视频生成的代表,Omni 则代表「多模态推理 + 媒体生成」的统一方向。两者更可能在不同场景下并存。
总结:新人应该记住的三件事
第一,Gemini Omni 的本质是「跨模态推理 + 媒体生成」的统一模型,不是简单的「又一个视频 AI」。它的差异化能力体现在物理理解、对话式编辑与跨模态推理三个维度。
第二,新人最快的体验路径是 YouTube Shorts 或 YouTube Create App 的免费入口,其次才是 Gemini app 的订阅渠道;开发者 API 正在「数周内推出」阶段,可以先规划架构。
第三,Omni 不会立刻取代你熟悉的工具,但它代表了未来 1-2 年内多模态 AI 的主流形态。提前理解它的输入输出方式、SynthID 合规要求,以及与 Veo 的定位差异,会让你在新一轮 AI 工具升级中少走弯路。如果你想在一套接口里同时调用 Gemini、GPT、Claude 等主流模型,通过 API易 apiyi.com 是当前最省心的方案,等 Gemini Omni API 正式开放后也能第一时间接入。
参考资料
-
Google 官方博客 – Gemini Omni 发布公告
- 链接:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-omni - 说明: 谷歌官方对 Gemini Omni 定位与能力的权威介绍
- 链接:
-
TechCrunch – Gemini Omni 深度报道
- 链接:
techcrunch.com/2026/05/19/googles-gemini-omni-turns-images-audio-and-text-into-video-and-thats-just-the-start - 说明: 引述 Sundar Pichai 与 Nicole Brichtova 的关键表态
- 链接:
-
9to5Google – Gemini Omni Flash 体验报道
- 链接:
9to5google.com/2026/05/19/gemini-omni-create-anything-model-video - 说明: 包含官方 demo 描述与渠道开放情况
- 链接:
APIYI Team | 关注更多 AI 大模型动态与实战指南,可访问 API易 apiyi.com 获取免费测试额度,体验包括 Gemini 系列在内的多种主流模型统一接口。