
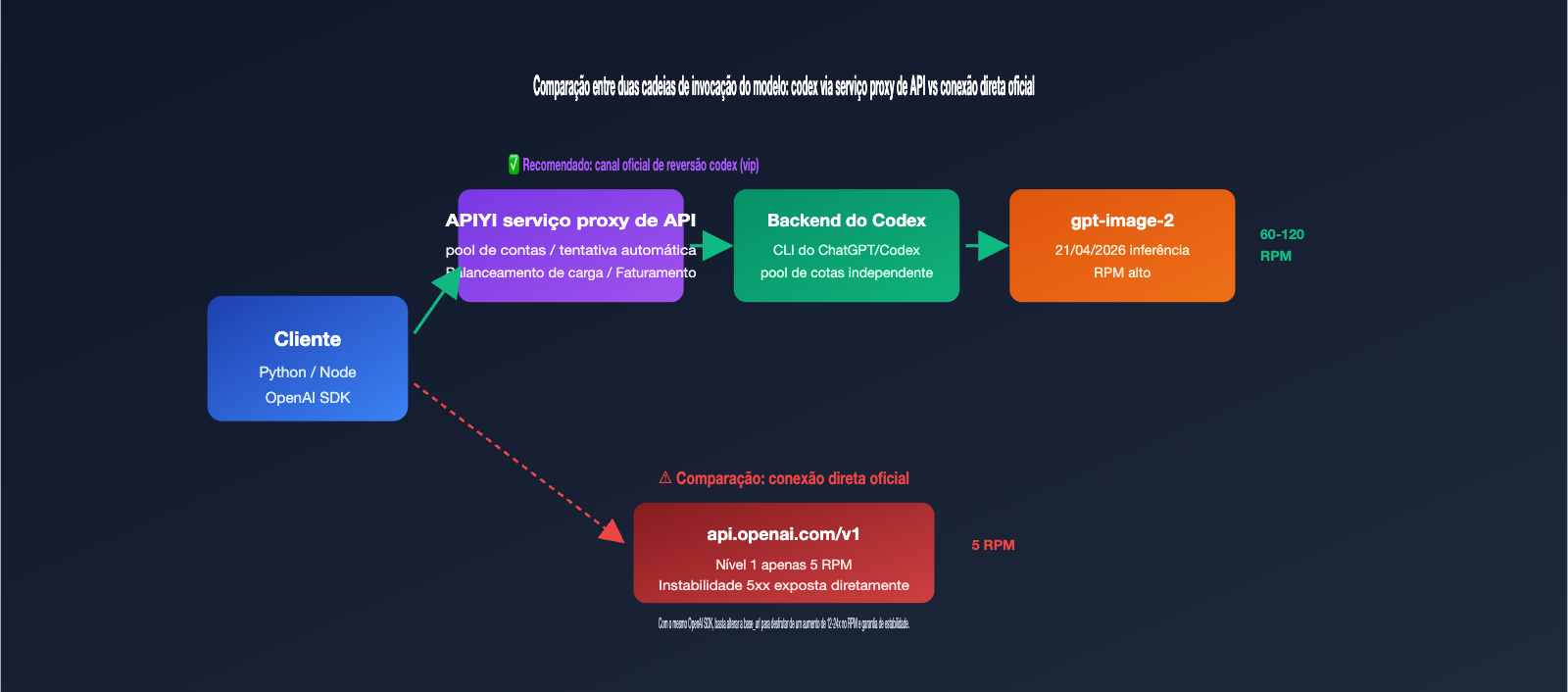
Se você acabou de integrar o gpt-image-2 em um ambiente de produção, provavelmente já esbarrou em dois problemas críticos: limites de taxa (rate limits) e estabilidade. Os limites oficiais da OpenAI para o gpt-image-2 são extremamente rigorosos; contas Tier 1 permitem apenas 5 requisições por minuto, o que causa erros 429 assim que você tenta processar algo em lote. Além disso, oscilações 5xx podem derrubar várias chamadas seguidas. Por isso, muitas equipes recorrem a "canais reversos oficiais" — fazendo engenharia reversa no backend do gpt-image-2 integrado ao ChatGPT Pro/Codex CLI para aproveitar cotas de RPM mais altas e conexões mais estáveis.
O modelo gpt-image-2-vip, disponível na APIYI (apiyi.com), utiliza exatamente essa rota reversa do Codex. Este artigo detalha 5 recursos principais, 30 opções de dimensões, 3 endpoints compatíveis e o código prático para você integrar essa solução diretamente em produção.

O que é a "Codex Reverse API": 3 diferenças essenciais em relação à conexão oficial
Muitos desenvolvedores, ao ouvirem falar pela primeira vez sobre a "Codex Reverse API", podem pensar que se trata de uma interface ilegal. Na verdade, ela se refere à engenharia reversa da cadeia de invocação do gpt-image-2, embutida no Codex CLI da OpenAI e no ChatGPT Pro. Quando a OpenAI lançou o gpt-image-2 em abril de 2026, ela o integrou simultaneamente ao Codex CLI (habilidade $imagegen) e ao cliente ChatGPT. Esses dois pontos de entrada compartilham um conjunto independente de cotas de taxa, com estratégias de limitação diferentes da API pública.
O que o canal da Codex Reverse API faz é: expor esse fluxo de dados interno do Codex como uma interface REST, permitindo que você use o gpt-image-2 como se estivesse chamando uma API comum da OpenAI, mas processando tudo pelo backend do ChatGPT. O modelo gpt-image-2-vip é uma implementação desse tipo, e ele possui 3 diferenças essenciais em comparação com a conexão oficial.
| Dimensão | Conexão Oficial OpenAI | Canal Codex Reverse (gpt-image-2-vip) |
|---|---|---|
| Limite de Taxa | Nível 1: 5 RPM, requer recarga para desbloquear | Usa o pool compartilhado do Codex, muito superior ao Nível 1 |
| Modelo de Cobrança | Cobrança por níveis de tamanho/qualidade | Preço único de $0,03/imagem, 30 tamanhos pelo mesmo valor |
| Estabilidade | Afetado diretamente por flutuações 5xx oficiais | Pool de múltiplas contas + retentativa automática, isola instabilidades |
Parâmetro quality |
Suporta low/medium/high/auto | Não suportado (segue a estratégia interna do Codex) |
Lote n |
Suporta 1-4 imagens | Não suportado, retorna 1 imagem por vez |
| Validade da URL | 60 minutos | ~24 horas |
🎯 Conceito principal: A "Reverse API" não é uma "violação". Ela expõe a cadeia de invocação interna de um produto da própria OpenAI (Codex CLI) como uma interface REST. A APIYI (apiyi.com) transformou esse canal em um produto comercial, cujo valor central não é contornar a OpenAI, mas disponibilizar as cotas de taxa mais estáveis do lado do Codex para os usuários da API.
5 características principais do gpt-image-2-vip
Após entender as diferenças do canal, as características específicas ficam mais claras. Os 5 pontos abaixo são as diferenças mais cruciais entre o gpt-image-2-vip e os modelos da mesma série gpt-image-2-all ou o oficial gpt-image-2, sendo detalhes que muitas vezes passam despercebidos na documentação.
Característica 1: 30 tamanhos fixos, cobrança única de $0,03
O maior valor de engenharia do gpt-image-2-vip é transformar o "tamanho" em um parâmetro de primeira classe. O modelo suporta 10 proporções de aspecto × 3 níveis de resolução = 30 tamanhos definidos. Basta especificar no parâmetro size, sem precisar contornar com ajustes no comando. No nível de cobrança, é ainda mais direto: todos os 30 tamanhos custam uniformemente $0,03/imagem, eliminando custos ocultos de "tamanhos maiores serem mais caros". Para equipes que trabalham com geração baseada em modelos ou miniaturas em lote, isso representa um aumento enorme na previsibilidade de custos.
| Nível de Resolução | Pixels do lado menor | Pixels do lado maior (limite) | Cenários de uso |
|---|---|---|---|
| 1K | ~1024 | ~1820 | Miniaturas, capas de feed, redes sociais |
| 2K | ~2048 | ~3640 | Pôsteres, imagens principais de e-commerce, cartões de conteúdo |
| 4K | ~2880 | ~3840 | Impressão de alta definição, materiais de vídeo, materiais impressos |
As 10 proporções cobrem necessidades comuns como 1:1 (quadrado), 16:9 (paisagem), 9:16 (retrato), 4:3, 3:2, 21:9, eliminando a necessidade de cortes posteriores. Outro valor oculto da precificação única é que você pode alternar resoluções no seu pipeline de produção conforme a necessidade do negócio sem afetar o modelo financeiro — por exemplo, ao realizar testes A/B rodando o mesmo comando em 1K e 4K para comparação, o custo é totalmente previsível, sem surpresas na fatura do fim do mês.
Característica 2: Compatibilidade total com três endpoints
O gpt-image-2-vip suporta simultaneamente os três endpoints de imagem padrão da OpenAI: /v1/images/generations (texto para imagem puro), /v1/images/edits (imagem para imagem e edição) e /v1/chat/completions (geração de imagem via chat). Isso é fundamental, pois significa que você não precisa reescrever o código do SDK existente; basta alterar o model de gpt-image-2 para gpt-image-2-vip e apontar a base_url para o serviço proxy de API.
Característica 3: Fusão de múltiplas imagens e imagem para imagem
Através do endpoint /v1/images/edits, você pode enviar de 1 a N imagens e, combinado com uma descrição de comando, o modelo realizará transferência de estilo, fusão de conteúdo e rearranjo de layout. Por exemplo, combinar "imagem do produto + imagem do modelo + imagem de fundo" em uma única imagem principal de e-commerce. Recomenda-se comprimir cada imagem para menos de 1,5 MB para evitar um aumento significativo no consumo de tokens de entrada.
Característica 4: Compreensão nativa de chinês
O gpt-image-2-vip compartilha o mesmo backend de inferência do gpt-image-2 oficial, herdando a capacidade de renderização de texto em vários idiomas, incluindo chinês, japonês, coreano, hindi e bengali. Comandos em chinês não precisam ser traduzidos para o inglês; títulos em pôsteres e textos em botões podem ser reproduzidos com precisão, algo que o Midjourney e o Stable Diffusion não conseguem fazer.
Característica 5: Requisições com falha não são cobradas
Este é um detalhe de cobrança, mas de grande importância para a produção em larga escala. Qualquer requisição que retorne 5xx, timeout ou que seja bloqueada por políticas de segurança não será cobrada; apenas invocações que retornam imagens com sucesso são contabilizadas. Isso permite que você implemente retentativas com espera exponencial sem medo de que o processo de retentativa infle sua fatura. Combinado com o preço de "$0,03/imagem", a estimativa de custos torna-se extremamente simples: planejar a geração de 10.000 imagens custa cerca de $300, sem necessidade de modelar por tamanho ou qualidade, facilitando a aprovação financeira e de produto.
Fluxo de invocação e exemplos de código: comece com 5 linhas em Python
A lógica de integração é bem direta e idêntica ao SDK oficial da OpenAI; basta alternar a base_url e o model. Abaixo, apresento um exemplo mínimo funcional para geração de imagens, onde a base_url aponta para o serviço proxy de API da APIYI (apiyi.com).
from openai import OpenAI
import base64
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
resp = client.images.generate(
model="gpt-image-2-vip",
prompt="Visual principal de evento de lançamento tecnológico com tons escuros, título em neon centralizado 『APIYI · gpt-image-2 disponível』, texto pequeno no canto inferior esquerdo 2026",
size="2048x1152"
)
img_b64 = resp.data[0].b64_json
with open("poster_2k.png", "wb") as f:
f.write(base64.b64decode(img_b64))
Se você precisar realizar uma tarefa de imagem para imagem ou fusão de múltiplas imagens, basta substituir client.images.generate por client.images.edit e adicionar image=[open("a.png","rb"), open("b.png","rb")]. O formato do corpo da requisição para todos os três endpoints segue as especificações oficiais da OpenAI.
🎯 Dica para começar rápido: Para testar esse fluxo em 30 segundos, recomendamos criar uma chave API na APIYI (apiyi.com) e usar o modelo
gpt-image-2-vipcom qualquer tamanho para gerar uma imagem de teste. Requisições que falham não são cobradas, então você pode ajustar os parâmetros com tranquilidade.
Como escolher entre 30 tamanhos: guia rápido por cenário
Muitas pessoas, ao se depararem com 30 opções de size, perguntam-se "qual escolher". Classificamos as opções de acordo com os cenários de negócio. Um ponto importante: todos os tamanhos possuem o mesmo preço, portanto, escolha o tamanho estritamente de acordo com a sua necessidade, sem precisar sacrificar a resolução para economizar.
| Cenário de negócio | Proporção recomendada | Resolução recomendada | Tamanho típico |
|---|---|---|---|
| Capa de artigo / Thumbnail | 16:9 / 3:2 | 2K | 2048×1152 |
| Vertical (Redes Sociais) | 9:16 / 4:5 | 2K | 1152×2048 |
| Imagem de produto / Detalhes | 1:1 | 2K ou 4K | 2048×2048 ou 2880×2880 |
| Hero image de site | 21:9 / 16:9 | 4K | 3840×1640 ou 3840×2160 |
| Ilustração para PPT | 16:9 | 1K ou 2K | 1820×1024 |
| Impressos / Pôsteres | 3:4 / 2:3 | 4K | 2880×3840 |
| Miniaturas de feed | 1:1 | 1K | 1024×1024 |
| Banner horizontal | 21:9 | 1K | 1820×780 |
🎯 Sugestão de escolha de tamanho: Recomendamos priorizar o padrão 2K para ambientes de produção; o tamanho do arquivo fica entre 1-3 MB, oferecendo o melhor equilíbrio entre velocidade de carregamento e qualidade visual. Utilize 4K apenas quando precisar de impressão ou exibição em telas grandes, e reserve o 1K para cenários de imagens menores, como miniaturas de feed.
Comparativo dos três canais da série gpt-image-2: vip / all / oficial
No APIYI (apiyi.com), existem três modelos relacionados ao gpt-image-2. É muito fácil escolher o errado e ter problemas, então vou explicar as diferenças abaixo para evitar retrabalho após a integração.
O gpt-image-2 (conexão direta oficial) utiliza a API pública da OpenAI, suporta os parâmetros quality e n, mas você precisa lidar com o limite de taxa baixo de 5 RPM. O gpt-image-2-all é um canal agregado que suporta todos os parâmetros, mas o tamanho é controlado pelo comando e não é tão preciso. O gpt-image-2-vip é o protagonista deste artigo; ele utiliza a engenharia reversa oficial do codex, tendo como pontos fortes o bloqueio preciso de size + precificação unificada + alto RPM.
| ID do Modelo | Tipo de Canal | Taxa (RPM) | Controle de Tamanho | Parâmetro quality | Imagens por vez | Cenário Recomendado |
|---|---|---|---|---|---|---|
gpt-image-2 |
Conexão direta oficial | Limite Tier | size preciso |
✅ | 1-4 | Sensível a níveis de qualidade, chamadas de baixa frequência |
gpt-image-2-all |
Canal agregado | Médio | Via descrição do comando | ✅ | 1-4 | Migração de código antigo, necessidade do parâmetro quality |
gpt-image-2-vip |
Codex (rev. oficial) | Alto RPM | size preciso |
❌ | 1 | Produção em lote, tamanho fixo, prioridade em estabilidade |
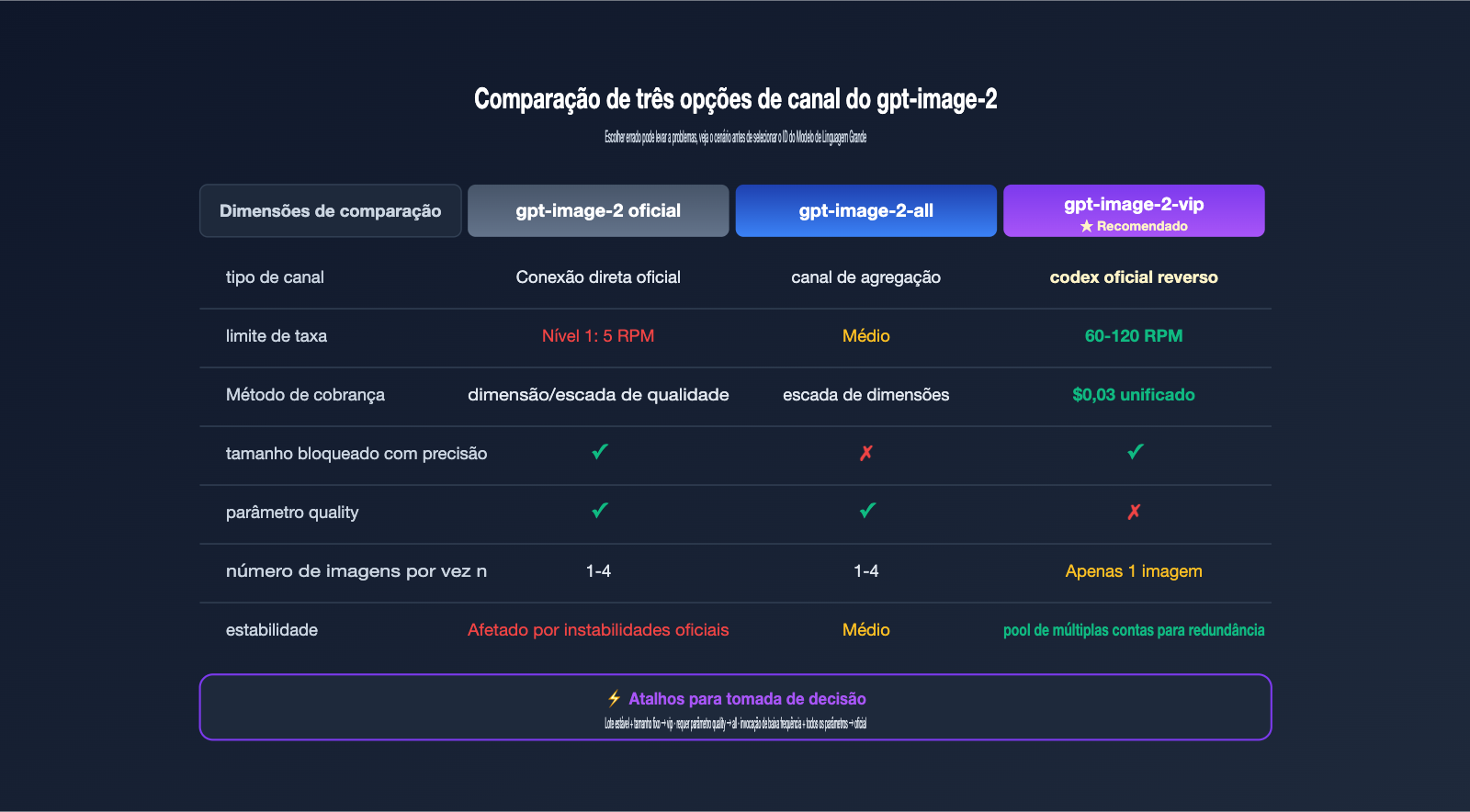
Decisão simples: Se você precisa de alta estabilidade, produção em lote, tamanho fixo e faturamento previsível, escolha o gpt-image-2-vip. Se você precisa obrigatoriamente do quality=high para alta fidelidade, escolha o gpt-image-2-all. Apenas considere o gpt-image-2 se tiver chamadas de baixa frequência e precisar de todo o conjunto de parâmetros.
Melhores práticas de estabilidade: timeout, novas tentativas e validade da URL
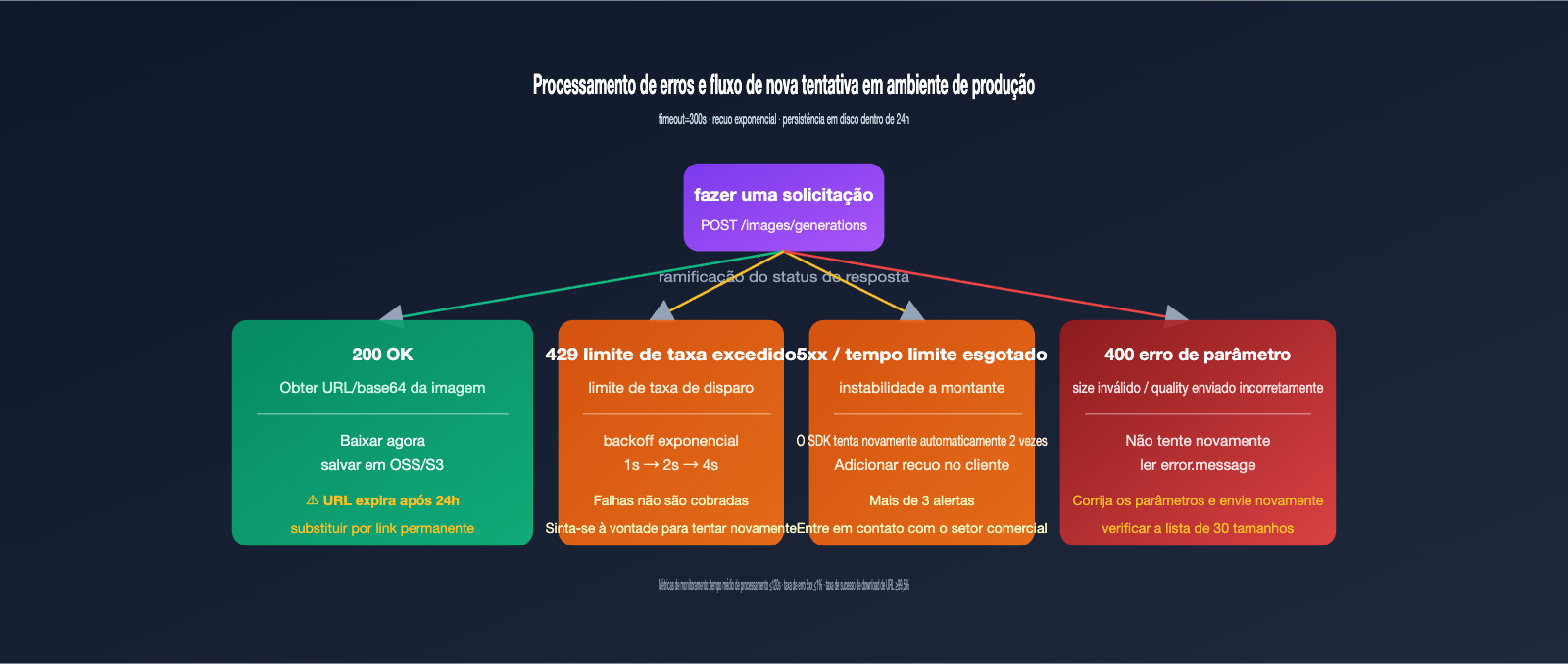
A taxa do gpt-image-2-vip é maior que a oficial, mas o tempo de geração é mais longo: a inferência oficial leva cerca de 30-60 segundos, enquanto o canal VIP, por ter uma camada extra de proxy e novas tentativas, geralmente leva de 90-150 segundos. O código de produção deve ser configurado de acordo com esse tempo, caso contrário, ocorrerão falhas por timeout.
Prática 1: Definir o tempo limite (timeout) para 300 segundos
O timeout padrão do SDK da OpenAI é de 60 segundos, o que é insuficiente para o gpt-image-2-vip. Recomenda-se passar explicitamente timeout=300 para o cliente. Em casos raros de comandos complexos, o tempo pode chegar a 200 segundos, então 300 segundos é uma margem mais segura.
client = OpenAI(
api_key="sua-chave-apiyi",
base_url="https://api.apiyi.com/v1",
timeout=300,
max_retries=2
)
Prática 2: Implementar recuo exponencial para erros 5xx
Embora a camada de proxy já realize uma tentativa, adicionar uma camada de recuo exponencial (1s → 2s → 4s) no cliente pode aumentar ainda mais a taxa de sucesso. Requisições com falha não são cobradas, o que torna as novas tentativas gratuitas.
Prática 3: Baixar e salvar a URL retornada em até 24 horas
A URL da imagem retornada pelo gpt-image-2-vip tem validade de cerca de 24 horas; após isso, retornará 404. Portanto, assim que obtiver a URL, baixe-a imediatamente para o seu OSS/S3, não insira a URL diretamente no banco de dados para referência de longo prazo. Para tarefas em lote, recomenda-se concluir o download em até 5 minutos após a geração.
Prática 4: Comprimir a imagem de entrada para menos de 1,5 MB
A imagem de entrada da interface /v1/images/edits é processada com alta fidelidade, e os tokens de entrada estão diretamente ligados ao número de pixels da imagem. O consumo de tokens entre uma imagem de referência 4K e uma de 1024px pode variar em até 4 vezes. Redimensione a imagem no cliente para 1024-2048 pixels no lado maior antes de fazer o upload; isso economiza dinheiro e acelera a inferência.
Prática 5: Não bloqueie chamadas individuais, use filas assíncronas
Como cada geração leva de 90-150 segundos, você não deve usar loops síncronos em série, caso contrário, 100 imagens levariam de duas a três horas. A prática recomendada é enviar as solicitações de geração para uma fila de tarefas assíncronas (Celery/asyncio), onde a thread de negócio retorna imediatamente o ID da tarefa, e o front-end obtém o resultado final via polling ou WebSocket. Isso permite aproveitar ao máximo a taxa de 60 RPM e utilizar todo o potencial de alta concorrência do canal VIP.
Três cenários práticos de integração
Depois de toda a teoria, vamos ver como colocar o gpt-image-2-vip para rodar em um cenário de negócio real. Os três casos abaixo são os que mais aparecem nas nossas dúvidas de suporte, e a estrutura de código é bem enxuta.
Cenário 1: Geração em lote de imagens principais para e-commerce
Entrada: Uma imagem de produto com fundo branco + um texto em chinês. Saída: 30 imagens principais com estilos diferentes. O fluxo utiliza um template de comando fixo, substituindo apenas o marcador de "estilo", e executa 30 chamadas em lote para /v1/images/edits, com o tamanho da imagem fixado em 2048x2048 (tamanho padrão para e-commerce). O custo para 30 imagens é de $0,90, com um tempo total de execução de cerca de 2 minutos (concorrência de 60 RPM).
Cenário 2: Localização de pôsteres em múltiplos idiomas
Entrada: Uma imagem base de um pôster em inglês + texto no idioma de destino. Saída: Versões do pôster em chinês, japonês e coreano. Aproveitando a capacidade de renderização de texto multilíngue do gpt-image-2-vip, o comando é direto: "mude o título para 'Novo Lançamento', use a fonte Source Han Sans e mantenha o layout original". Com uma única chamada, você obtém a versão localizada sem precisar editar no PSD.
Cenário 3: Pipeline de ilustrações para slides de PPT
Entrada: Descrições de capítulos geradas por um Modelo de Linguagem Grande. Saída: Uma ilustração por página. Este é o núcleo das ferramentas de "PPT com um clique" que vemos no TikTok; todas as ilustrações são padronizadas para 1820x1024 (proporção 16:9 padrão de PPT), a qualidade é travada no nível alto pelo canal VIP, o custo por página é de $0,03, e o custo total de ilustrações para um PPT de 20 páginas é de apenas $0,60. Somando com o texto do Modelo de Linguagem Grande, é possível produzir um PPT completo por menos de $1.
A estrutura de engenharia comum a esses três cenários é: o nível externo usa uma fila de tarefas para agendamento, o nível interno chama o gpt-image-2-vip e, após a geração, a imagem é imediatamente salva no OSS. O front-end exibe os links permanentes do OSS, em vez de usar diretamente a URL temporária de 24 horas retornada pelo modelo.
Erros Comuns e Solução de Problemas
A tabela abaixo cobre os tipos de erro mais frequentes relatados em nosso grupo de suporte. Consultá-la diretamente resolve 90% dos problemas de integração.
| Fenômeno de Erro | Causa Raiz | Solução |
|---|---|---|
| 408 / 504 Timeout | Timeout configurado muito curto | Ajuste o timeout para 300 segundos |
| 400 invalid size | Tamanho não está entre os 30 permitidos | Use os tamanhos padrão listados na documentação |
| 400 unsupported_parameter | Parâmetros quality ou n>1 enviados |
O canal VIP não suporta, remova esses campos |
| URL da imagem 404 | URL expirou após 24 horas | Faça o download para seu próprio armazenamento logo após a geração |
| Chinês renderizado como caracteres estranhos ou quadrados | O comando usou caracteres muito raros | Use caracteres comuns ou descreva no comando "usar fonte Source Han Sans" |
| input_tokens acima do esperado | Imagem de referência muito grande | Comprima no cliente para menos de 1.5MB |
Perguntas Frequentes (FAQ)
Q1: A qualidade da imagem do gpt-image-2-vip é diferente da oficial?
O modelo base é exatamente o mesmo, ambos utilizam o snapshot gpt-image-2-2026-04-21. A diferença reside apenas na rota de agendamento: a oficial utiliza o pool de cotas da API, enquanto o VIP utiliza o pool de cotas Codex. Não há diferença na qualidade visual da imagem; testes cegos em larga escala não conseguem distinguir.
Q2: Por que o parâmetro quality não é suportado?
A chamada interna do Codex CLI utiliza uma estratégia fixa de quality=high. O canal VIP reutiliza essa rota, por isso não é possível expor a opção de qualidade para a camada superior. Se o seu negócio realmente precisa de níveis low/medium para redução de custos, utilize o gpt-image-2-all.
Q3: Requisições com falha realmente não são cobradas?
Sim. A política de cobrança da APIYI (apiyi.com) é "cobrança por resposta bem-sucedida". Erros de parâmetro 4xx, erros de serviço 5xx e timeouts não são contabilizados no consumo. Você pode verificar isso item por item na sua fatura.
Q4: É possível chamar a API diretamente de servidores na China?
Sim. O domínio api.apiyi.com utiliza uma rota compatível com as normas locais, sem necessidade de VPN. Este é um dos principais motivos pelos quais muitas equipes escolhem nosso serviço proxy de API.
Q5: Qual é o limite de RPM do canal VIP?
Não existe um limite rígido público; ele depende do nível de ocupação do pool de contas. Geralmente, o uso comercial pode atingir estavelmente de 60 a 120 RPM, muito acima dos 5 RPM do Tier 1 oficial. Se precisar de uma concorrência maior, entre em contato com o setor comercial para liberação.
Q6: A API retorna apenas uma imagem por vez, como fazer em lote?
Basta realizar chamadas concorrentes em um loop externo. O asyncio.gather ou concurrent.futures.ThreadPoolExecutor do Python conseguem atingir facilmente 60 RPM. Como o canal VIP realiza inferência assíncrona, a submissão concorrente não é limitada pela CPU, o gargalo está apenas no RPM da camada de proxy.
Q7: Múltiplas chamadas com o mesmo comando produzirão o mesmo resultado?
Não serão exatamente iguais. O gpt-image-2-vip segue a estratégia interna do Codex e não expõe o parâmetro seed, portanto, há aleatoriedade em cada geração. Se o seu negócio exige resultados reproduzíveis, torne o comando muito específico (por exemplo, códigos de cor fixos, descrição de composição fixa) ou use a primeira imagem satisfatória como imagem de referência no endpoint /v1/images/edits para ajustes finos.
Q8: Como monitorar a estabilidade do ambiente de produção?
Recomendamos coletar estatísticas de três indicadores no cliente: tempo médio de geração, taxa de erro 5xx e taxa de sucesso no download da URL. Em condições normais, o tempo médio deve ser inferior a 120 segundos, a taxa de erro 5xx <1% e a taxa de sucesso de download >99.5%. Qualquer anomalia em um desses itens indica que o nível do pool de contas está baixo, sendo necessário entrar em contato com o setor comercial para ajustar os recursos.
Resumo
O gpt-image-2-vip é um produto comercial de geração de imagens baseado no canal reverso oficial do Codex. Seus 5 recursos principais resolvem, um a um, os problemas da conexão direta oficial: 30 tamanhos disponíveis + cobrança unificada de $0,03 + compatibilidade com três endpoints + suporte nativo ao chinês + sem cobrança em caso de falha. Para equipes que trabalham com produção de conteúdo, materiais de e-commerce, automação de PPT e geração em lote de cartazes, esta é atualmente uma das soluções de acesso ao gpt-image-2 com o melhor custo-benefício.
A integração exige apenas a alteração da base_url e do model; o código do SDK é totalmente reutilizável seguindo a sintaxe oficial da OpenAI. Para o ambiente de produção, recomendamos definir o timeout para 300 segundos, implementar backoff exponencial para erros 5xx e salvar as URLs das imagens localmente dentro de 24 horas. Ao evitar esses três problemas comuns, você conseguirá rodar volumes de produção com estabilidade. Se você está avaliando soluções de acesso ao gpt-image-2 para produção, pode criar uma conta diretamente na APIYI (apiyi.com) e testar o canal VIP com dados reais do seu negócio antes de tomar uma decisão.
Sobre o autor: A equipe da APIYI é especializada em acesso agregado a modelos e infraestrutura de inferência de alta concorrência, lidando diariamente com diversas consultas sobre integração de API de geração de imagens. Este artigo foi organizado com base em dados reais de produção. Para detalhes sobre os parâmetros do gpt-image-2-vip, acesse docs.apiyi.com.