
Gemini 3 Flash Preview 모델을 호출할 때 응답 시간이 너무 길어지는 문제는 개발자들이 자주 겪는 과제입니다. 이 글에서는 timeout, max_tokens, thinking_level 등 주요 파라미터 설정 팁을 소개하여, Gemini 3 Flash Preview의 응답 속도를 빠르게 최적화하는 실무적인 방법을 알려드릴게요.
핵심 가치: 이 글을 읽고 나면, 파라미터를 합리적으로 설정하여 Gemini 3 Flash Preview의 응답 시간을 제어하는 방법을 배우게 됩니다. 이를 통해 출력 품질을 유지하면서도 응답 속도를 획기적으로 향상시킬 수 있습니다.

Gemini 3 Flash Preview 응답 시간이 긴 원인 분석
최적화 팁을 깊이 알아보기 전에, 왜 Gemini 3 Flash Preview의 응답 시간이 때때로 길어지는지 이해할 필요가 있습니다.
사고 토큰 (Thinking Tokens) 메커니즘
Gemini 3 Flash Preview는 동적 사고 메커니즘을 채택하고 있는데, 이것이 응답 시간을 길게 만드는 핵심 원인입니다.
| 영향 요인 | 설명 | 응답 시간에 미치는 영향 |
|---|---|---|
| 복잡한 추론 작업 | 논리적 추론이 필요한 문제는 더 많은 사고 토큰을 필요로 함 | 응답 시간 현저히 증가 |
| 동적 사고 깊이 | 모델이 문제의 복잡도에 따라 사고량을 자동으로 조절함 | 쉬운 문제는 빠르고, 복잡한 문제는 느림 |
| 비스트리밍 출력 | 비스트리밍 모드에서는 전체 생성이 완료될 때까지 기다려야 함 | 전체 대기 시간 증가 |
| 출력 토큰 수 | 완성되는 내용이 많을수록 생성 시간이 길어짐 | 응답 시간 선형적으로 증가 |
Artificial Analysis의 테스트 데이터에 따르면, Gemini 3 Flash Preview는 최고 사고 레벨일 때 약 1.6억 개의 토큰을 사용할 수 있으며, 이는 Gemini 2.5 Flash의 두 배 이상입니다. 즉, 복잡한 작업에서 모델이 방대한 "사고 시간"을 소모한다는 뜻이죠.
실제 사례 분석
사용자 피드백을 보면, 작업 결과의 반환 속도는 중요하지만 정확도 요구사항은 높지 않을 때 Gemini 3 Flash Preview의 기본 설정이 이상적이지 않을 수 있습니다.
"작업 속도는 중요하지만 정확도는 크게 상관없는데, gemini-3-flash-preview의 추론 시간이 너무 길어요."
이런 상황의 근본적인 원인은 다음과 같습니다.
- 모델이 기본적으로 동적 사고를 사용하여 자동으로 깊은 추론을 수행함
- 완성된 출력 토큰 수가 7,000개를 넘을 수 있음
- 추론 과정에서 소모되는 사고 토큰을 추가로 고려해야 함
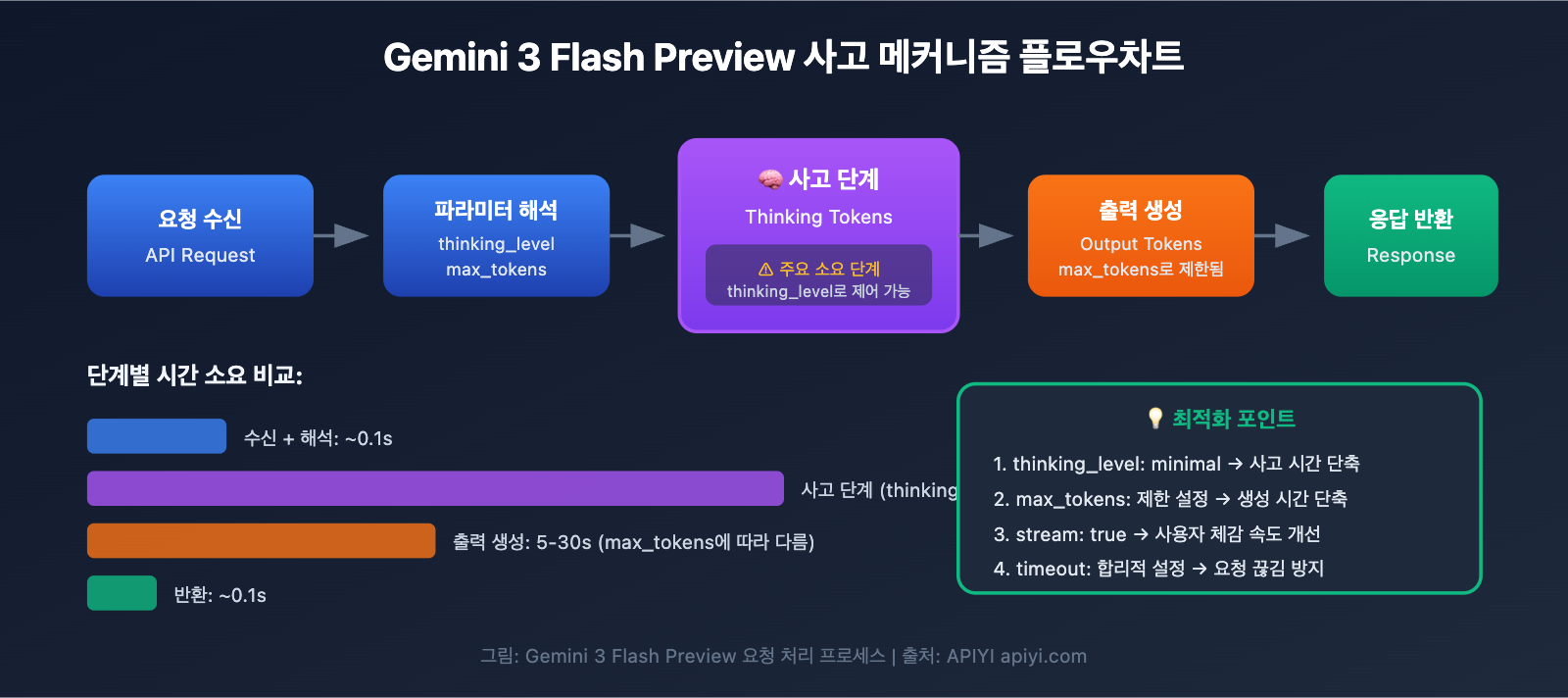
Gemini 3 Flash Preview 응답 속도 최적화 핵심 포인트
| 최적화 포인트 | 설명 | 예상 효과 |
|---|---|---|
| thinking_level 설정 | 모델의 사고 깊이를 제어해요 | 응답 시간 30~70% 단축 |
| max_tokens 제한 | 출력 길이를 제어해요 | 생성 시간 감소 |
| timeout 조정 | 합리적인 타임아웃 시간을 설정해요 | 요청이 중간에 끊기는 현상 방지 |
| 스트리밍 출력 사용 | 생성과 동시에 결과를 반환해요 | 사용자 경험 개선 |
| 적합한 시나리오 선택 | 단순한 작업에는 낮은 사고 레벨을 적용해요 | 전반적인 효율성 향상 |
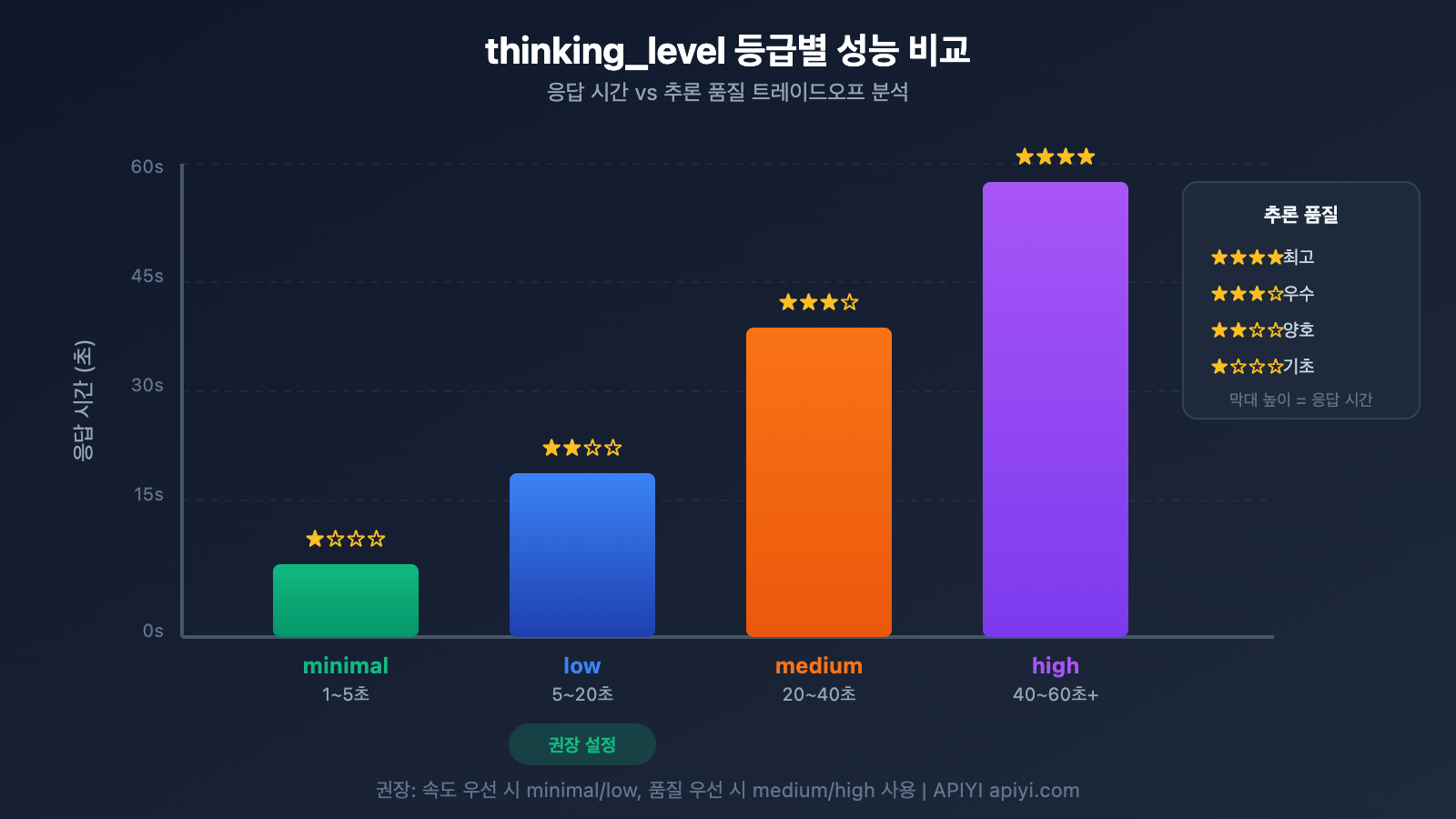
thinking_level 파라미터 상세 설명
Gemini 3에서는 thinking_level 파라미터가 도입되었는데요. 이는 응답 속도를 조절하는 가장 핵심적인 설정이에요.
| thinking_level | 적용 시나리오 | 응답 속도 | 추론 품질 |
|---|---|---|---|
| minimal | 단순 대화, 빠른 응답 필요 시 | 가장 빠름 ⚡ | 기초 수준 |
| low | 일상적인 작업, 가벼운 추론 | 빠름 | 양호 |
| medium | 중간 난이도의 작업 | 보통 | 우수 |
| high | 복잡한 추론, 심층 분석 | 느림 | 최상 |
🎯 기술 팁: 작업의 정확도보다 빠른 응답이 더 중요하다면
thinking_level을minimal이나low로 설정하는 것을 추천드려요. APIYI(apiyi.com) 플랫폼에서 다양한thinking_level을 직접 테스트해 보며 서비스 시나리오에 딱 맞는 설정을 빠르게 찾아보세요.
max_tokens 파라미터 설정 전략
max_tokens를 제한하면 출력 길이를 효과적으로 제어할 수 있어 응답 시간을 줄이는 데 큰 도움이 돼요.
출력 토큰 수 → 생성 시간에 직접적인 영향
토큰 수가 많을수록 → 응답 시간 길어짐
설정 권장안:
- 간단한 답변 시나리오:
max_tokens를 500~1000으로 설정 - 중간 길이 콘텐츠 생성:
max_tokens를 2000~4000으로 설정 - 전체 콘텐츠 출력: 실제 필요에 따라 설정하되, 타임아웃 위험에 주의
⚠️ 주의: max_tokens를 너무 짧게 설정하면 답변이 도중에 끊겨 완성도가 떨어질 수 있어요. 업무 요구사항에 맞춰 속도와 완성도 사이의 균형을 맞추는 것이 중요합니다.
Gemini 3 Flash Preview 응답 속도 최적화 퀵 스타트
최소한의 예제
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # 使用 APIYI 统一接口
)
# 速度优先配置
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": "简单介绍一下人工智能"}],
max_tokens=1000, # 限制输出长度
extra_body={
"thinking_level": "minimal" # 最小思考深度,最快响应
},
timeout=30 # 设置 30 秒超时
)
print(response.choices[0].message.content)
전체 코드 보기 – 다양한 설정 시나리오 포함
import openai
from typing import Literal
def create_gemini_client(api_key: str):
"""创建 Gemini 3 Flash 客户端"""
return openai.OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # 使用 APIYI 统一接口
)
def call_gemini_optimized(
client: openai.OpenAI,
prompt: str,
thinking_level: Literal["minimal", "low", "medium", "high"] = "low",
max_tokens: int = 2000,
timeout: int = 60,
stream: bool = False
):
"""
优化配置的 Gemini 3 Flash 调用
参数:
client: OpenAI 客户端
prompt: 用户输入
thinking_level: 思考深度 (minimal/low/medium/high)
max_tokens: 最大输出 Token 数
timeout: 超时时间(秒)
stream: 是否使用流式输出
"""
params = {
"model": "gemini-3-flash-preview",
"messages": [{"role": "user", "content": prompt}],
"max_tokens": max_tokens,
"stream": stream,
"extra_body": {
"thinking_level": thinking_level
},
"timeout": timeout
}
if stream:
# 流式输出 - 改善用户体验
response = client.chat.completions.create(**params)
full_content = ""
for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
print(content, end="", flush=True)
full_content += content
print() # 换行
return full_content
else:
# 非流式输出 - 一次性返回
response = client.chat.completions.create(**params)
return response.choices[0].message.content
# 使用示例
if __name__ == "__main__":
client = create_gemini_client("YOUR_API_KEY")
# 场景 1: 速度优先 - 简单问答
print("=== 速度优先配置 ===")
result = call_gemini_optimized(
client,
prompt="用一句话解释什么是机器学习",
thinking_level="minimal",
max_tokens=500,
timeout=15
)
print(f"回答: {result}\n")
# 场景 2: 平衡配置 - 日常任务
print("=== 平衡配置 ===")
result = call_gemini_optimized(
client,
prompt="列出 5 个 Python 数据处理的最佳实践",
thinking_level="low",
max_tokens=1500,
timeout=30
)
print(f"回答: {result}\n")
# 场景 3: 质量优先 - 复杂分析
print("=== 质量优先配置 ===")
result = call_gemini_optimized(
client,
prompt="分析 Transformer 架构的核心创新点及其对 NLP 的影响",
thinking_level="high",
max_tokens=4000,
timeout=120
)
print(f"回答: {result}\n")
# 场景 4: 流式输出 - 改善体验
print("=== 流式输出 ===")
result = call_gemini_optimized(
client,
prompt="介绍 Gemini 3 Flash 的主要特点",
thinking_level="low",
max_tokens=2000,
timeout=60,
stream=True
)
🚀 빠른 시작: APIYI(apiyi.com) 플랫폼을 사용하면 다양한 파라미터 설정을 즉시 테스트해 볼 수 있어요. Gemini 3 Flash Preview를 포함한 주요 모델들을 바로 사용할 수 있는 API 인터페이스를 제공하므로, 최적화 효과를 아주 간편하게 검증할 수 있습니다.
Gemini 3 Flash Preview 응답 속도 최적화 파라미터 설정 가이드
timeout 초과 시간 설정
Gemini 3 Flash Preview를 사용하여 복잡한 추론을 수행할 때, 기본 timeout 설정으로는 시간이 부족할 수 있어요. 다음은 권장되는 timeout 설정 전략이에요:
| 작업 유형 | 권장 timeout | 설명 |
|---|---|---|
| 간단한 문답 | 15~30초 | minimal thinking_level과 함께 사용 |
| 일상적인 작업 | 30~60초 | low/medium thinking_level과 함께 사용 |
| 복잡한 분석 | 60~120초 | high thinking_level과 함께 사용 |
| 긴 텍스트 생성 | 120~180초 | 대량의 출력 토큰이 발생하는 시나리오 |
핵심 팁:
- 비스트리밍(Non-streaming) 출력 모드에서는 모든 내용이 생성될 때까지 기다려야 응답이 반환돼요.
- 만약 timeout을 너무 짧게 설정하면 요청이 중간에 끊길 수 있어요.
- 실제 출력되는 토큰 양과 thinking_level에 따라 유동적으로 조절하는 것을 추천해요.
thinking_level과 이전 버전 thinking_budget 마이그레이션
Google은 이전 버전의 thinking_budget 파라미터에서 신규 버전인 thinking_level로 마이그레이션하는 것을 권장하고 있어요:
| 이전 버전 thinking_budget | 신규 버전 thinking_level | 마이그레이션 안내 |
|---|---|---|
| 0 | minimal | 최소한의 사고, 사고 시그니처 처리가 여전히 필요함에 유의 |
| 1-1000 | low | 가벼운 사고 |
| 1001-5000 | medium | 중간 정도의 사고 |
| 5001+ | high | 심층적인 사고 |
⚠️ 주의: 하나의 요청에 thinking_budget과 thinking_level을 동시에 사용하지 마세요. 예상치 못한 동작이 발생할 수 있습니다.
Gemini 3 Flash Preview 응답 속도 최적화 시나리오별 설정 방안
시나리오 1: 고빈도 단순 작업 (속도 우선)
챗봇, 빠른 문답, 요약 등 지연 시간에 민감한 서비스에 적합한 설정이에요:
# 속도 우선 설정
config_speed_first = {
"thinking_level": "minimal",
"max_tokens": 500,
"timeout": 15,
"stream": True # 스트리밍 출력으로 사용자 경험 개선
}
예상 효과:
- 응답 시간: 1~5초
- 간단한 대화 및 빠른 답변에 최적화
시나리오 2: 일상적인 업무 (균형 잡힌 설정)
콘텐츠 생성, 코드 보조, 문서 처리 등 일반적인 작업에 적합한 설정이에요:
# 균형 잡힌 설정
config_balanced = {
"thinking_level": "low",
"max_tokens": 2000,
"timeout": 45,
"stream": True
}
예상 효과:
- 응답 시간: 5~20초
- 품질과 속도의 적절한 균형 유지
시나리오 3: 복잡한 분석 작업 (품질 우선)
데이터 분석, 기술 설계, 심층 연구 등 깊은 추론이 필요한 상황에 적합한 설정이에요:
# 품질 우선 설정
config_quality_first = {
"thinking_level": "high",
"max_tokens": 8000,
"timeout": 180,
"stream": True # 긴 작업에는 스트리밍 권장
}
예상 효과:
- 응답 시간: 30~120초
- 최상의 추론 품질 제공
설정 선택 가이드
| 필요 사항 | 권장 thinking_level | 권장 max_tokens | 권장 timeout |
|---|---|---|---|
| 빠른 답변, 간단한 질문 | minimal | 500-1000 | 15-30s |
| 일상 작업, 일반 품질 | low | 1500-2500 | 30-60s |
| 우수한 품질, 대기 가능 | medium | 2500-4000 | 60-90s |
| 최고 품질, 복잡한 작업 | high | 4000-8000 | 120-180s |
💡 선택 제안: 어떤 설정을 사용할지는 구체적인 애플리케이션 시나리오와 요구되는 품질 수준에 따라 달라져요. APIYI (apiyi.com) 플랫폼에서 실제 테스트를 진행하며 본인의 니즈에 가장 잘 맞는 설정을 찾아보시는 것을 추천합니다. 이 플랫폼은 Gemini 3 Flash Preview를 위한 통합 인터페이스를 제공하여 다양한 설정 효과를 빠르게 비교해 볼 수 있습니다.
Gemini 3 Flash Preview 응답 속도 최적화 심화 팁
팁 1: 스트리밍 출력을 사용한 사용자 경험 개선
전체 응답 시간은 동일하더라도, 스트리밍 출력을 사용하면 사용자가 느끼는 체감 대기 시간을 획기적으로 줄일 수 있어요.
# 스트리밍 출력 예시
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": prompt}],
stream=True,
extra_body={"thinking_level": "low"}
)
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
장점:
- 사용자가 결과의 일부를 즉시 확인할 수 있습니다.
- '대기 불안감'을 줄여줍니다.
- 생성 과정 중에 계속 진행할지 여부를 판단할 수 있습니다.
팁 2: 입력 복잡도에 따른 동적 파라미터 조정
def estimate_complexity(prompt: str) -> str:
"""프롬프트 특징에 따른 작업 복잡도 추정"""
indicators = {
"high": ["분석", "대조", "왜", "원리", "심층", "상세 설명"],
"medium": ["방법", "단계", "방식", "소개"],
"low": ["무엇인지", "간단히", "빠르게", "한 문장"]
}
prompt_lower = prompt.lower()
for level, keywords in indicators.items():
if any(kw in prompt_lower for kw in keywords):
return level
return "low" # 기본값: 낮은 복잡도
def get_optimized_config(prompt: str) -> dict:
"""프롬프트에 따른 최적화 설정 가져오기"""
complexity = estimate_complexity(prompt)
configs = {
"low": {"thinking_level": "minimal", "max_tokens": 1000, "timeout": 20},
"medium": {"thinking_level": "low", "max_tokens": 2500, "timeout": 45},
"high": {"thinking_level": "medium", "max_tokens": 4000, "timeout": 90}
}
return configs.get(complexity, configs["low"])
팁 3: 요청 재시도 메커니즘 구현
간혹 발생하는 타임아웃 문제에 대비하여 스마트한 재시도 로직을 구현할 수 있습니다.
import time
from typing import Optional
def call_with_retry(
client,
prompt: str,
max_retries: int = 3,
initial_timeout: int = 30
) -> Optional[str]:
"""재시도 메커니즘이 포함된 호출"""
for attempt in range(max_retries):
try:
timeout = initial_timeout * (attempt + 1) # 타임아웃 점진적 증가
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": prompt}],
max_tokens=2000,
timeout=timeout,
extra_body={"thinking_level": "low"}
)
return response.choices[0].message.content
except Exception as e:
print(f"시도 {attempt + 1} 실패: {e}")
if attempt < max_retries - 1:
time.sleep(2 ** attempt) # 지수 백오프
continue
return None

Gemini 3 Flash Preview 성능 데이터 참고
Artificial Analysis의 테스트 데이터에 따르면, Gemini 3 Flash Preview의 성능 수치는 다음과 같습니다.
| 성능 지표 | 수치 | 설명 |
|---|---|---|
| 원시 처리량(Throughput) | 218 tokens/초 | 출력 속도 |
| 2.5 Flash 대비 | 22% 느림 | 추론 능력이 추가되었기 때문 |
| GPT-5.1 high 대비 | 74% 빠름 | 125 tokens/초 |
| DeepSeek V3.2 대비 | 627% 빠름 | 30 tokens/초 |
| 입력 비용 | $0.50/1M tokens | |
| 출력 비용 | $3.00/1M tokens |
성능과 비용의 균형
| 설정 구성 | 응답 속도 | 토큰 소모 | 비용 효율성 |
|---|---|---|---|
| minimal thinking | 가장 빠름 | 가장 낮음 | 가장 높음 |
| low thinking | 빠름 | 낮은 편 | 높음 |
| medium thinking | 중간 | 중간 | 중간 |
| high thinking | 느림 | 높은 편 | 품질을 중시할 때 선택 |
💰 비용 최적화: 예산에 민감한 프로젝트라면 APIYI(apiyi.com) 플랫폼을 통해 Gemini 3 Flash Preview API를 호출하는 것을 고려해 보세요. 이 플랫폼은 유연한 과금 방식을 제공하며, 본문의 속도 최적화 팁과 결합하면 비용을 제어하면서도 최고의 가성비를 얻을 수 있습니다.
Gemini 3 Flash Preview 응답 속도 최적화 자주 묻는 질문(FAQ)
Q1: max_tokens를 제한했는데도 왜 응답이 여전히 느린가요?
max_tokens는 출력 길이만 제한할 뿐, 대규모 언어 모델의 사고 과정에는 영향을 주지 않아요. 응답이 느린 주요 원인이 긴 생각 시간 때문이라면, thinking_level 매개변수를 minimal이나 low로 함께 설정해야 합니다. 또한, APIYI(apiyi.com) 플랫폼을 이용하면 안정적인 API 서비스를 받을 수 있으며, 본문에서 소개한 파라미터 설정 팁을 활용해 응답 속도를 효과적으로 개선할 수 있습니다.
Q2: thinking_level을 minimal로 설정하면 답변 품질이 떨어질까요?
어느 정도 영향이 있을 수 있지만, 단순한 작업에서는 큰 차이가 없어요. minimal 단계는 빠른 질의응답이나 간단한 대화 시나리오에 적합합니다. 만약 작업에 복잡한 논리적 추론이 필요하다면 low나 medium 단계를 권장해요. APIYI(apiyi.com) 플랫폼에서 A/B 테스트를 진행하며 다양한 thinking_level에 따른 출력 품질을 비교해 보고, 여러분의 비즈니스에 가장 적합한 균형점을 찾아보세요.
Q3: 스트리밍 출력과 비스트리밍 출력 중 어느 것이 더 빠른가요?
전체 생성 시간은 동일하지만, 사용자가 체감하는 경험은 스트리밍 출력이 훨씬 더 좋습니다. 스트리밍 모드에서는 사용자가 결과의 일부를 즉시 볼 수 있는 반면, 비스트리밍 모드는 전체 생성이 완료될 때까지 기다려야 하거든요. 생성 시간이 긴 작업이라면 스트리밍 출력을 강력히 추천합니다.
Q4: 타임아웃(timeout)은 어느 정도로 설정하는 게 좋을까요?
타임아웃은 예상되는 출력 길이와 thinking_level에 맞춰 설정해야 합니다.
- minimal + 1000 tokens: 15~30초
- low + 2000 tokens: 30~60초
- medium + 4000 tokens: 60~90초
- high + 8000 tokens: 120~180초
먼저 넉넉한 타임아웃으로 실제 응답 시간을 테스트해 본 뒤, 그 결과에 따라 조정하는 것이 좋습니다.
Q5: 기존의 thinking_budget 파라미터는 계속 사용할 수 있나요?
계속 사용할 수는 있지만, Google은 더 예측 가능한 성능을 위해 thinking_level 파라미터로 전환할 것을 권장하고 있어요. 주의할 점은 동일한 요청에서 두 파라미터를 동시에 사용하면 안 된다는 것입니다. 이전에 thinking_budget=0을 사용했다면, 전환 시 thinking_level="minimal"로 설정하시면 됩니다.
요약
Gemini 3 Flash Preview의 응답 속도 최적화의 핵심은 다음 세 가지 주요 매개변수를 적절하게 설정하는 데 있습니다.
- thinking_level: 작업 복잡도에 따라 적절한 사고 깊이를 선택하세요.
- max_tokens: 예상되는 출력 길이에 맞춰 토큰(Token) 수를 제한하세요.
- timeout: thinking_level과 출력량에 맞춰 합리적인 타임아웃을 설정하세요.
"응답 속도가 중요하고 정확도에 대한 요구사항이 상대적으로 높지 않은" 시나리오에서는 다음과 같은 설정을 추천드려요.
- thinking_level:
minimal또는low - max_tokens: 실제 필요에 따라 설정하여 출력이 지나치게 길어지는 것을 방지
- timeout: 설정값에 맞춰 적절히 조정하여 응답이 중간에 끊기지 않도록 관리
- stream:
True(사용자 경험 개선)
APIYI(apiyi.com)를 통해 다양한 매개변수 조합을 빠르게 테스트해 보고, 여러분의 비즈니스 시나리오에 가장 적합한 최적의 설정을 찾아보세요.
키워드: Gemini 3 Flash Preview, 응답 속도 최적화, thinking_level, max_tokens, timeout 설정, API 호출 최적화
참고 자료:
- Google AI 공식 문서: ai.google.dev/gemini-api/docs/gemini-3
- Google DeepMind: deepmind.google/models/gemini/flash/
- Artificial Analysis 성능 테스트: artificialanalysis.ai/articles/gemini-3-flash-everything-you-need-to-know
본 게시글은 APIYI Team 기술팀에서 작성하였습니다. 더 많은 AI 모델 활용 팁은 help.apiyi.com을 방문해 주세요.