
Catatan Penulis: Qwen3.5-35B-A3B mencapai skor 69,2 pada SWE-bench Verified dengan hanya 3B parameter aktif, melampaui generasi sebelumnya Qwen3-235B. Komunitas r/LocalLLaMA menganggapnya sebagai tonggak sejarah bagi model sumber terbuka (open-source) dalam mengejar model tertutup. Artikel ini menganalisis secara mendalam arsitektur teknis dan nilai praktisnya.
Komunitas r/LocalLLaMA baru-baru ini ramai membahas satu hal: Qwen3.5-35B-A3B mencapai skor 69,2 pada SWE-bench Verified dengan hanya 3B parameter aktif. Ini tidak hanya melampaui Qwen3-235B generasi sebelumnya, tetapi juga memecahkan rekor kemampuan pemrograman di antara model yang dapat dijalankan secara lokal. Komunitas melihat ini sebagai tanda penting bahwa model sumber terbuka mulai mengejar model tertutup—sebuah model 35B yang dapat berjalan di perangkat keras konsumen, dengan kemampuan pemrograman yang mendekati level GPT-5 mini.
Nilai Inti: Setelah membaca artikel ini, Anda akan memahami mengapa Qwen3.5-35B memicu kehebohan di komunitas sumber terbuka, bagaimana arsitektur MoE-nya mencapai "bodi kecil dengan kemampuan besar", serta cara menggunakannya di lokal maupun cloud.

Poin Utama Qwen3.5-35B
| Poin | Penjelasan | Signifikansi |
|---|---|---|
| Total Parameter | 35 Miliar (35B) | Arsitektur MoE |
| Parameter Aktif | Hanya 3 Miliar (3B) | Efisiensi Maksimal |
| SWE-bench Verified | 69,2 poin | Melampaui Qwen3-235B |
| GPQA Diamond | 84,2 poin | Penalaran tingkat pascasarjana |
| Jendela Konteks | Native 256K / Ekspansi 1M+ | Ekspansi YaRN |
| Kebutuhan Operasi | 22GB RAM/VRAM | Tersedia untuk konsumen |
| Lisensi Sumber Terbuka | Apache 2.0 | Terbuka sepenuhnya |
Mengapa komunitas r/LocalLLaMA membahas Qwen3.5-35B
r/LocalLLaMA adalah komunitas Model Bahasa Besar lokal paling aktif di Reddit, di mana anggota berfokus pada pertanyaan inti: Model apa yang bisa berjalan di perangkat keras saya, namun memiliki kemampuan yang cukup kuat?
Qwen3.5-35B-A3B menjawab kebutuhan tersebut dengan tepat:
- Total 35B parameter, tetapi hanya mengaktifkan 3B setiap inferensi—artinya model ini dapat berjalan lancar di Mac atau GPU dengan RAM 22GB.
- Kemampuan pemrograman (SWE-bench 69,2) melampaui Qwen3-235B generasi sebelumnya yang memiliki jumlah parameter 7 kali lipat lebih besar.
- Sumber terbuka sepenuhnya di bawah lisensi Apache 2.0, tanpa batasan komersial apa pun.
Komentar komunitas: "Run Qwen 35B. It's a great chatbot, good enough for task automation." Ini mewakili tuntutan inti dari para pemain deployment lokal—cukup, cepat, dan murah.
Analisis Mendalam Arsitektur Qwen3.5-35B
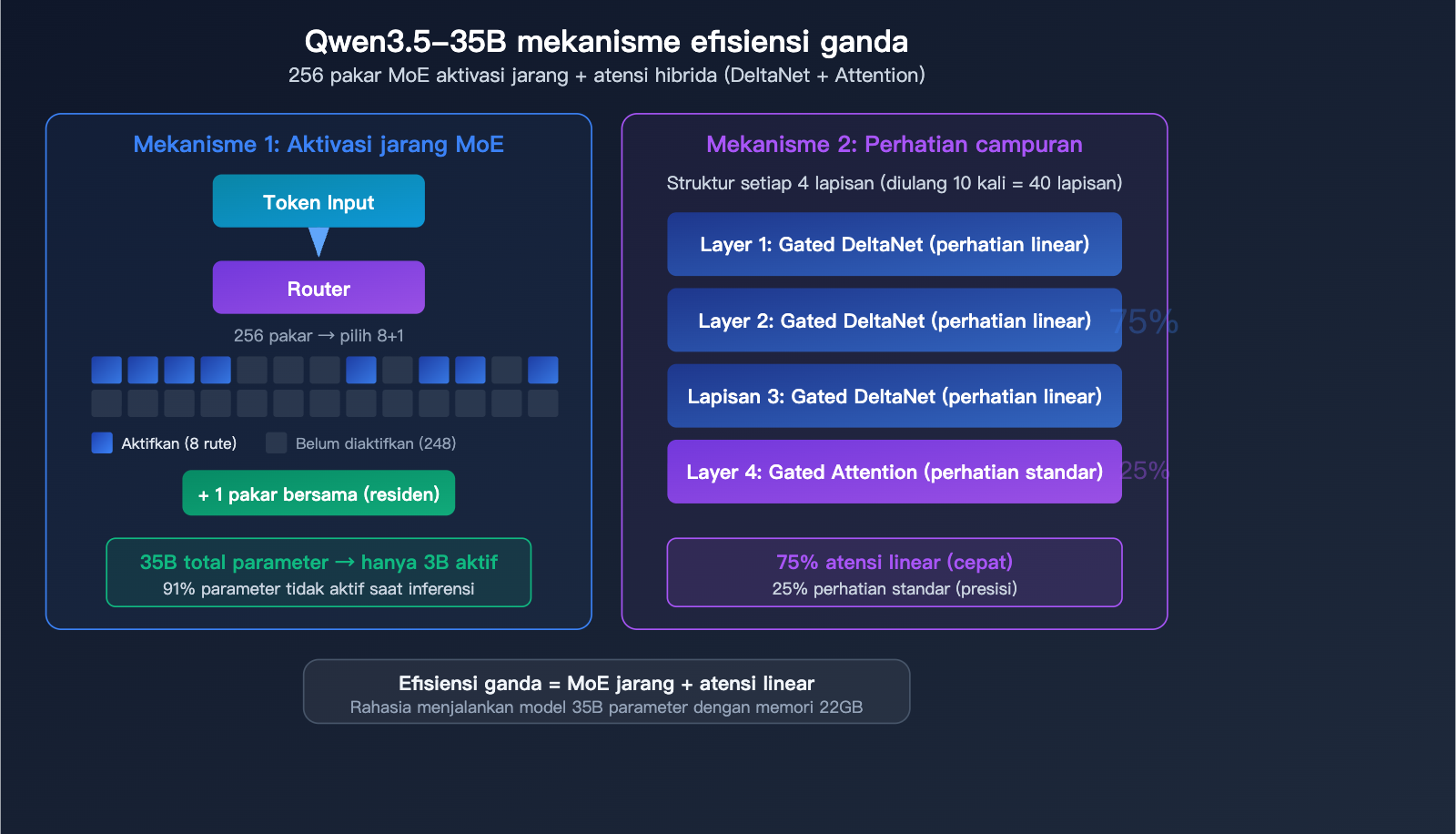
Arsitektur MoE dengan 256 Pakar
Qwen3.5-35B-A3B menggunakan arsitektur Mixture of Experts (MoE) yang sangat presisi:
| Parameter Arsitektur | Nilai | Penjelasan |
|---|---|---|
| Total Parameter | 35B | Jumlah seluruh parameter pakar |
| Parameter Aktif | 3B | Diaktifkan setiap inferensi |
| Total Pakar | 256 | Pembagian tugas yang sangat detail |
| Pakar Aktif | 8 Rute + 1 Bersama | Memilih 9 pakar per langkah |
| Jumlah Layer | 40 Layer | Jaringan mendalam |
| Dimensi Tersembunyi | 2048 | Desain ringkas |
Mekanisme Atensi Hibrida
Qwen3.5-35B bukanlah Transformer murni, melainkan menggunakan desain atensi hibrida:
Struktur setiap 4 layer terdiri dari: 3 layer Gated DeltaNet (atensi linear) + 1 layer Gated Attention (atensi standar)
| Tipe Atensi | Proporsi Layer | Karakteristik |
|---|---|---|
| Gated DeltaNet | 75% | Atensi linear, inferensi cepat |
| Gated Attention | 25% | Atensi standar, akurasi tinggi |
Keunggulan desain hibrida ini terletak pada efisiensinya: sebagian besar komputasi dilakukan menggunakan atensi linear yang cepat, sementara atensi standar yang lebih berat hanya digunakan pada layer-layer krusial. Inilah rahasia di balik performa 35B parameter namun hanya membutuhkan memori 22GB—bukan hanya aktivasi pakar yang jarang, mekanisme atensinya pun telah dioptimalkan.
🎯 Wawasan Teknis: Desain arsitektur Qwen3.5-35B mewakili tren terbaru model MoE tahun 2026—256 pakar dengan granularitas tinggi + atensi hibrida. Jika Anda ingin merasakan peningkatan efisiensi dari arsitektur ini, Anda dapat langsung memanggil API seri Qwen3.5 melalui APIYI di apiyi.com tanpa perlu melakukan deployment lokal.
Interpretasi Menyeluruh Data Evaluasi Qwen3.5-35B
Evaluasi Pemrograman Qwen3.5-35B
| Tolok Ukur Evaluasi | Qwen3.5 35B-A3B | Referensi Perbandingan | Penjelasan |
|---|---|---|---|
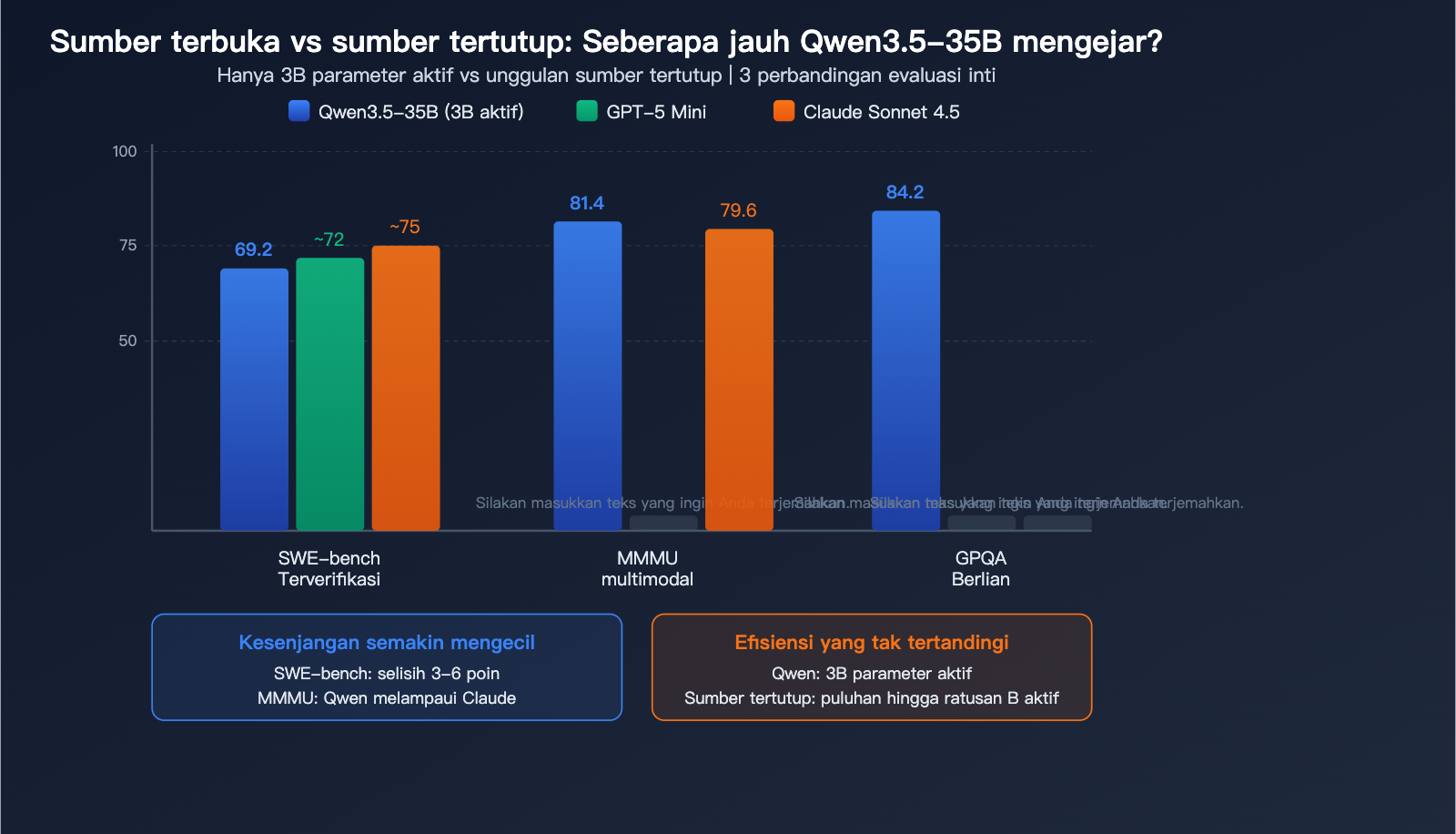
| SWE-bench Verified | 69.2 | Qwen3-235B: <69 | Melampaui pendahulu 7x lebih besar |
| LiveCodeBench v6 | 74.6 | – | Kuat dalam pemrograman real-time |
| CodeForces | 2,028 | – | Level kompetisi |
Evaluasi Penalaran dan Pengetahuan Qwen3.5-35B
| Tolok Ukur Evaluasi | Qwen3.5 35B-A3B | Penjelasan |
|---|---|---|
| GPQA Diamond | 84.2 | Penalaran ilmiah tingkat pascasarjana |
| MMLU-Pro | 85.3 | Pengetahuan multidisiplin |
| MMLU-Redux | 93.3 | Pemahaman pengetahuan |
| HMMT Feb 2025 | 89.0 | Kompetisi matematika |
| IFEval | 91.9 | Kepatuhan instruksi |
Evaluasi Multimodal Qwen3.5-35B
| Tolok Ukur Evaluasi | Qwen3.5 35B-A3B | Penjelasan |
|---|---|---|
| MMMU | 81.4 | Pemahaman multimodal (mendekati 79.6 milik Claude Sonnet 4.5) |
| MMMU-Pro | 75.1 | Multimodal tingkat kesulitan tinggi |
| MathVision | 83.9 | Penalaran matematika visual |
| VideoMME | 86.6 | Pemahaman video |
Perbandingan Qwen3.5-35B dengan Model Closed-Source
Ini adalah pertanyaan yang paling banyak ditanyakan komunitas—seberapa jauh model open-source 35B dapat mengejar model closed-source?
| Dimensi | Qwen3.5 35B | GPT-5 Mini | Claude Sonnet 4.5 | Selisih |
|---|---|---|---|---|
| SWE-bench | 69.2 | ~72 | ~75 | Beda 3-6 poin |
| MMMU | 81.4 | – | 79.6 | Melampaui |
| GPQA Diamond | 84.2 | – | – | Unggul |
| Parameter Aktif | 3B | ~Puluhan B | Tidak diketahui | Efisiensi tinggi |
| Bisa dijalankan lokal | Ya (22GB) | Tidak | Tidak | Keunggulan unik |
Pandangan inti komunitas: Dalam pemrograman, selisih Qwen3.5-35B dengan model sekelas GPT-5 Mini telah menyempit hingga 3-6 poin, bahkan melampaui Claude Sonnet 4.5 dalam aspek multimodal. Mengingat model ini hanya membutuhkan 3B parameter aktif dan dapat dijalankan secara lokal, rasio efisiensi/kemampuannya mungkin yang tertinggi di antara semua model publik.
💡 Saran praktis: Jika Anda ingin membandingkan performa aktual antara Qwen3.5-35B dan model closed-source, Anda dapat menggunakan layanan proksi API APIYI di apiyi.com untuk memanggil Qwen3.5, Claude, dan GPT secara bersamaan guna melakukan perbandingan A/B pada tugas Anda sendiri.
Panduan Deployment Lokal Qwen3.5-35B
Persyaratan Perangkat Keras dan Metode Deployment
| Metode Deployment | Persyaratan Perangkat Keras | Skenario yang Disarankan |
|---|---|---|
| Ollama | RAM/VRAM 22GB+ | Paling mudah, sekali klik jalan |
| vLLM | GPU + VRAM 24GB+ | Throughput tingkat produksi |
| SGLang | GPU + VRAM 24GB+ | Direkomendasikan untuk throughput tinggi |
| KTransformers | Hybrid CPU + GPU | Perangkat keras spesifikasi rendah |
| LM Studio | RAM 22GB+ | Ramah dengan antarmuka grafis |
Deployment Sekali Klik dengan Ollama
# Jalankan perintah ini setelah instalasi
ollama run qwen3.5:35b
Melalui Pemanggilan API (Tanpa Deployment Lokal)
Jika Anda tidak ingin repot dengan deployment lokal, menggunakan API adalah cara termudah:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{
"role": "user",
"content": "Bantu saya meninjau kode Python ini, temukan bottleneck kinerjanya"
}],
temperature=0.6, # 0.6 disarankan untuk tugas pemrograman
max_tokens=32768
)
print(response.choices[0].message.content)
Lihat cara beralih antara mode Thinking dan non-Thinking
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Mode Thinking (penalaran mendalam, cocok untuk tugas kompleks)
response_thinking = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{"role": "user", "content": "Analisis kompleksitas waktu algoritma ini"}],
temperature=1.0,
top_p=0.95,
max_tokens=32768
)
# Mode non-Thinking (jawaban cepat)
response_fast = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{"role": "user", "content": "Tulis fungsi quicksort"}],
temperature=0.7,
top_p=0.8,
max_tokens=32768,
extra_body={"chat_template_kwargs": {"enable_thinking": False}}
)
🚀 Saran Deployment: Deployment lokal cocok untuk skenario yang sensitif terhadap privasi dan offline. Untuk pengembangan sehari-hari, disarankan menggunakan APIYI (apiyi.com)—lebih cepat, tidak perlu memelihara perangkat keras, dan Anda bisa bebas beralih antara Qwen3.5, Claude, dan GPT.
Sekilas Keluarga Model Qwen3.5
Perbandingan Spesifikasi Seri Qwen3.5
| Model | Total Parameter | Parameter Aktif | SWE-bench | Memori Minimum | Posisi |
|---|---|---|---|---|---|
| Qwen3.5-4B | 4B | 4B (Dense) | – | 8GB | Ringan untuk pemula |
| Qwen3.5-9B | 9B | 9B (Dense) | – | 12GB | Efisien untuk harian |
| Qwen3.5-27B | 27B | 27B (Dense) | 72.4 | 22GB | Presisi tinggi |
| Qwen3.5-35B-A3B | 35B | 3B (MoE) | 69.2 | 22GB | Raja efisiensi |
| Qwen3.5-122B-A10B | 122B | 10B (MoE) | – | – | Menengah ke atas |
| Qwen3.5-397B-A17B | 397B | 17B (MoE) | 76.4 | – | Flagship |
Saran Pemilihan:
- Perangkat 22GB: 35B-A3B (MoE, cepat tapi presisi sedikit lebih rendah) atau 27B (Dense, sedikit lebih lambat tapi lebih akurat)
- Mengejar efisiensi biaya terbaik: 35B-A3B, hanya menggunakan 3B parameter per inferensi
- Mengejar presisi tertinggi: 27B Dense, tidak menggunakan jalur MoE
🎯 Pemilihan API: Melalui APIYI (apiyi.com), Anda dapat memanggil seluruh seri model Qwen3.5, mulai dari 4B hingga 397B sesuai kebutuhan. Satu kunci API sudah cukup untuk beralih secara fleksibel antara berbagai skala model Qwen serta model closed-source seperti Claude dan GPT.
Pertanyaan Umum
Q1: Antara Qwen3.5-35B dan 27B, mana yang harus dipilih?
Keduanya membutuhkan memori sekitar 22GB. 35B-A3B menggunakan arsitektur MoE (3-5 kali lebih cepat namun akurasi sedikit lebih rendah), sedangkan 27B menggunakan arsitektur Dense (lebih akurat namun lebih lambat). Untuk tugas pemrograman, perbedaannya tidak terlalu signifikan (SWE-bench 69.2 vs 72.4). Untuk percakapan sehari-hari, disarankan memilih 35B (lebih cepat), dan untuk tugas yang membutuhkan ketelitian, pilih 27B (lebih akurat). Anda bisa membandingkan keduanya secara langsung melalui APIYI di apiyi.com.
Q2: Apakah model sumber terbuka benar-benar mengejar model tertutup?
Ya, tetapi dengan catatan. Qwen3.5-35B melampaui Claude Sonnet 4.5 di MMMU (81.4 vs 79.6), dan selisihnya dengan GPT-5 Mini di SWE-bench hanya 3 poin. Namun, untuk tugas pemrograman tersulit dan penalaran kompleks, model unggulan tertutup (Claude Opus 4.5, GPT-5.4) masih memiliki keunggulan yang jelas. Model sumber terbuka sedang memperkecil jarak, tetapi belum sepenuhnya menyamai model tertutup papan atas.
Q3: Bisakah Mac dengan 22GB menjalankan Qwen3.5-35B?
Bisa. Qwen3.5-35B-A3B hanya mengaktifkan 3B parameter setiap kali inferensi, sehingga Mac dengan memori terpadu 22GB (seperti konfigurasi dasar M2/M3/M4) dapat menjalankannya dengan lancar. Disarankan menggunakan Ollama (ollama run qwen3.5:35b) untuk menjalankan dengan satu klik. Jika tidak ingin melakukan deployment lokal, pemanggilan via cloud melalui APIYI di apiyi.com jauh lebih praktis.
Kesimpulan
5 poin penting mengenai rekor baru pemrograman sumber terbuka oleh Qwen3.5-35B:
- Revolusi Efisiensi: Total parameter 35B dengan hanya 3B yang aktif, dapat berjalan di 22GB, dan kemampuan pemrograman melampaui model 235B generasi sebelumnya.
- Kekuatan Pemrograman: SWE-bench 69.2, CodeForces 2028, LiveCodeBench 74.6, menjadi standar baru untuk model lokal.
- Inovasi Arsitektur: 256 pakar MoE + atensi campuran (DeltaNet + Attention standar), memberikan rasio efisiensi/kemampuan yang optimal.
- Sumber Terbuka Mengejar Model Tertutup: MMMU melampaui Claude Sonnet 4.5, SWE-bench mendekati GPT-5 Mini, jarak semakin tipis.
- Terbuka Sepenuhnya: Lisensi Apache 2.0, tanpa batasan komersial, biaya deployment lokal nol.
Qwen3.5-35B membuktikan satu hal: Model sumber terbuka bukan lagi sekadar versi hemat dari model tertutup, melainkan sedang mengejar bahkan melampaui dengan efisiensi yang lebih tinggi. Disarankan untuk mengakses seluruh seri Qwen3.5 dan model tertutup melalui APIYI di apiyi.com, gunakan satu kunci API untuk membandingkan perbedaan performa antara model sumber terbuka dan tertutup pada tugas nyata Anda.
📚 Referensi
-
Kartu Model Qwen3.5-35B-A3B – Hugging Face: Parameter teknis lengkap dan data evaluasi
- Tautan:
huggingface.co/Qwen/Qwen3.5-35B-A3B - Penjelasan: Berisi detail arsitektur, skor evaluasi, dan rekomendasi parameter inferensi
- Tautan:
-
Repositori GitHub Qwen3.5: Kode sumber terbuka dan panduan penerapan
- Tautan:
github.com/QwenLM/Qwen3.5 - Penjelasan: Berisi unduhan bobot model lengkap dan dokumentasi penerapan
- Tautan:
-
Panduan Lengkap Qwen3.5: Evaluasi seluruh seri dan analisis arsitektur
- Tautan:
techie007.substack.com/p/qwen-35-the-complete-guide-benchmarks - Penjelasan: Perbandingan mendetail seluruh keluarga model dan tinjauan silang dengan model sumber tertutup
- Tautan:
-
Ollama – Qwen3.5:35B: Penerapan lokal sekali klik
- Tautan:
ollama.com/library/qwen3.5:35b - Penjelasan: Cara termudah untuk menjalankan model secara lokal
- Tautan:
Penulis: Tim Teknis APIYI
Diskusi Teknis: Jangan ragu untuk berbagi pengalaman penerapan lokal Qwen3.5 Anda di kolom komentar. Untuk materi akses model AI lainnya, silakan kunjungi pusat dokumentasi APIYI di docs.apiyi.com