
Nota do autor: O Qwen3.5-35B-A3B atingiu 69,2 pontos no SWE-bench Verified com apenas 3B de parâmetros ativos, superando o Qwen3-235B da geração anterior. A comunidade r/LocalLLaMA o considera um marco na corrida dos modelos open-source contra os proprietários. Este artigo analisa profundamente sua arquitetura técnica e valor prático.
A comunidade r/LocalLLaMA tem sido palco de um debate intenso recentemente: O Qwen3.5-35B-A3B atingiu 69,2 pontos no SWE-bench Verified com apenas 3B de parâmetros ativos, superando não apenas o Qwen3 de 235B da geração anterior, mas também estabelecendo um novo recorde de capacidade de programação entre modelos executáveis localmente. A comunidade vê isso como um sinal claro de que os modelos open-source estão alcançando os proprietários — um modelo de 35B que roda em hardware de consumo e possui capacidades de programação próximas ao nível do GPT-5 mini.
Valor central: Ao ler este artigo, você entenderá por que o Qwen3.5-35B causou tanto impacto na comunidade open-source, como sua arquitetura MoE consegue "grande capacidade em um corpo pequeno" e como utilizá-lo localmente ou na nuvem.

Principais pontos do Qwen3.5-35B
| Ponto | Descrição | Significado |
|---|---|---|
| Total de parâmetros | 35 bilhões (35B) | Arquitetura MoE |
| Parâmetros ativos | Apenas 3 bilhões (3B) | Eficiência extrema |
| SWE-bench Verified | 69,2 pontos | Supera o Qwen3-235B |
| GPQA Diamond | 84,2 pontos | Raciocínio de nível pós-graduação |
| Janela de contexto | Nativa 256K / Expansível 1M+ | Expansão via YaRN |
| Requisitos de execução | 22GB de RAM/VRAM | Disponível para hardware de consumo |
| Licença open-source | Apache 2.0 | Totalmente aberto |
Por que a comunidade r/LocalLLaMA está discutindo o Qwen3.5-35B
O r/LocalLLaMA é a comunidade de modelos de linguagem grande locais mais ativa no Reddit, onde os membros focam na questão central: que modelo pode rodar no meu hardware e ser poderoso o suficiente?
O Qwen3.5-35B-A3B atende perfeitamente a essa demanda:
- 35B de parâmetros totais, mas ativa apenas 3B por inferência — o que significa que ele pode rodar fluentemente em um Mac ou GPU com 22GB de memória.
- Capacidade de programação (SWE-bench 69,2) superior ao Qwen3-235B da geração anterior, que possui 7 vezes mais parâmetros.
- Totalmente open-source sob licença Apache 2.0, sem restrições comerciais.
A avaliação da comunidade: "Execute o Qwen 35B. É um ótimo chatbot, bom o suficiente para automação de tarefas." Isso representa a demanda central dos entusiastas de implantação local: eficiente, rápido e acessível.
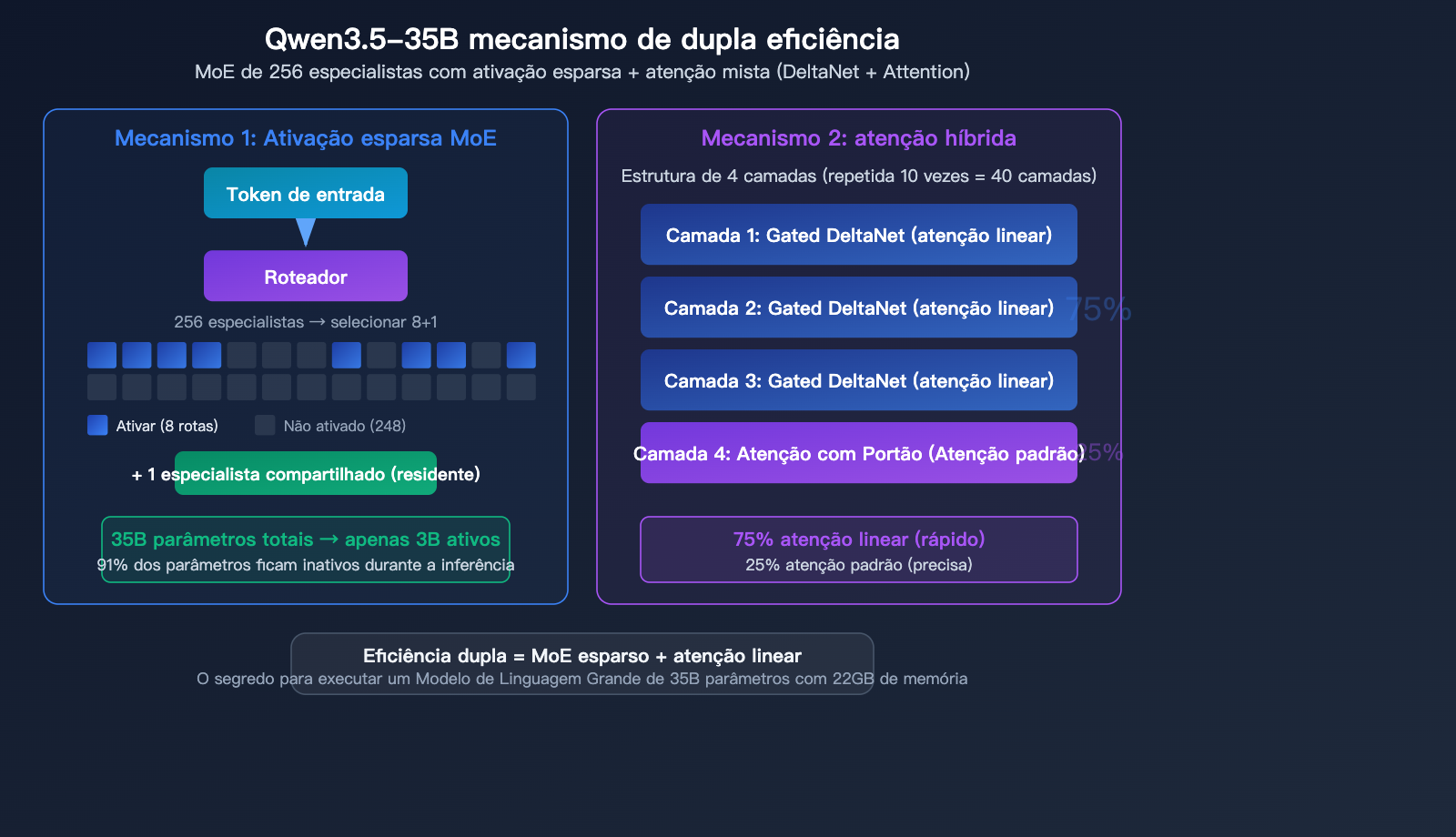
Análise profunda da arquitetura do Qwen3.5-35B
Arquitetura MoE com 256 especialistas
O Qwen3.5-35B-A3B utiliza uma arquitetura de Mistura de Especialistas (MoE) extremamente refinada:
| Parâmetro de Arquitetura | Valor | Descrição |
|---|---|---|
| Parâmetros totais | 35B | Soma de todos os parâmetros dos especialistas |
| Parâmetros ativos | 3B | Ativados a cada inferência |
| Total de especialistas | 256 | Divisão de trabalho de granulação fina |
| Especialistas ativos | 8 roteados + 1 compartilhado | 9 especialistas selecionados por vez |
| Camadas | 40 camadas | Rede profunda |
| Dimensão oculta | 2048 | Design compacto |
Mecanismo de atenção híbrida
O Qwen3.5-35B não é um Transformer puro, mas adota um design de atenção híbrida:
A estrutura a cada 4 camadas é composta por: 3 camadas de Gated DeltaNet (atenção linear) + 1 camada de Gated Attention (atenção padrão)
| Tipo de atenção | Proporção de camadas | Características |
|---|---|---|
| Gated DeltaNet | 75% | Atenção linear, inferência rápida |
| Gated Attention | 25% | Atenção padrão, alta precisão |
A genialidade deste design híbrido reside no fato de que a maior parte do cálculo é realizada usando atenção linear eficiente, reservando a atenção padrão, que é computacionalmente mais pesada, apenas para as camadas críticas. Este é o segredo por trás de um modelo de 35B que requer apenas 22GB de memória — não apenas a ativação dos especialistas é esparsa, mas o próprio mecanismo de atenção foi otimizado.
🎯 Insight técnico: O design arquitetônico do Qwen3.5-35B representa a tendência mais recente dos modelos MoE em 2026 — 256 especialistas de granulação fina + atenção híbrida. Se você deseja experimentar o ganho de eficiência que essa arquitetura proporciona, pode invocar a API da série Qwen3.5 diretamente através do serviço proxy de API da APIYI (apiyi.com), sem a necessidade de implantação local.
Interpretação completa dos dados de avaliação do Qwen3.5-35B
Avaliação de programação do Qwen3.5-35B
| Benchmark | Qwen3.5 35B-A3B | Referência | Observação |
|---|---|---|---|
| SWE-bench Verified | 69.2 | Qwen3-235B: <69 | Supera a geração anterior 7x maior |
| LiveCodeBench v6 | 74.6 | – | Forte em programação em tempo real |
| CodeForces | 2.028 | – | Nível de competição |
Avaliação de raciocínio e conhecimento do Qwen3.5-35B
| Benchmark | Qwen3.5 35B-A3B | Observação |
|---|---|---|
| GPQA Diamond | 84.2 | Raciocínio científico nível pós-graduação |
| MMLU-Pro | 85.3 | Conhecimento multidisciplinar |
| MMLU-Redux | 93.3 | Compreensão de conhecimento |
| HMMT Feb 2025 | 89.0 | Competição de matemática |
| IFEval | 91.9 | Seguimento de instruções |
Avaliação multimodal do Qwen3.5-35B
| Benchmark | Qwen3.5 35B-A3B | Observação |
|---|---|---|
| MMMU | 81.4 | Compreensão multimodal (próximo aos 79.6 do Claude Sonnet 4.5) |
| MMMU-Pro | 75.1 | Multimodal de alta dificuldade |
| MathVision | 83.9 | Raciocínio matemático visual |
| VideoMME | 86.6 | Compreensão de vídeo |
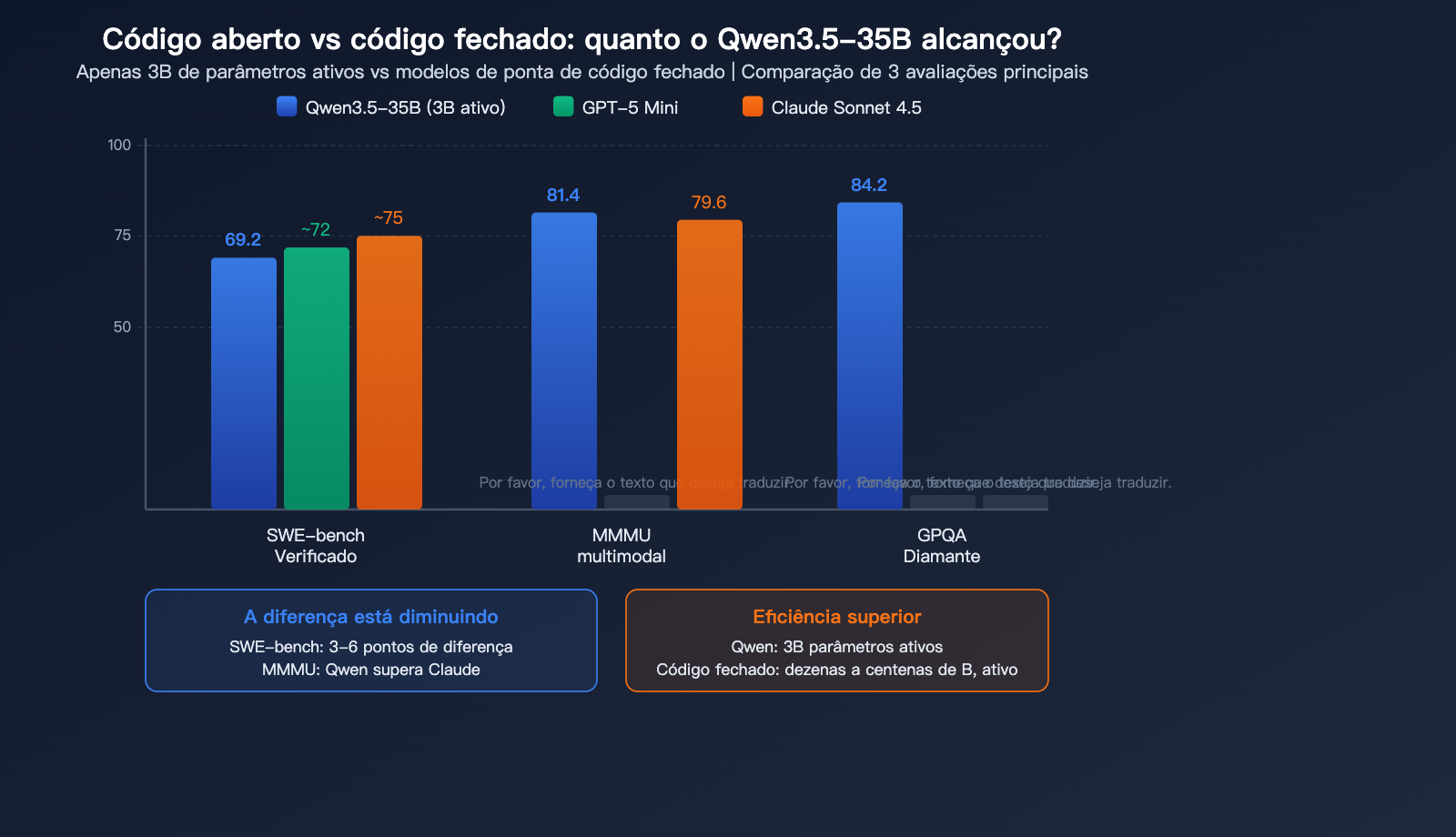
Comparação do Qwen3.5-35B com modelos de código fechado
Esta é a questão que mais interessa à comunidade: até onde um modelo open source de 35B consegue chegar em relação aos modelos fechados?
| Dimensão | Qwen3.5 35B | GPT-5 Mini | Claude Sonnet 4.5 | Diferença |
|---|---|---|---|---|
| SWE-bench | 69.2 | ~72 | ~75 | 3-6 pontos |
| MMMU | 81.4 | – | 79.6 | Superou |
| GPQA Diamond | 84.2 | – | – | Topo de linha |
| Parâmetros ativos | 3B | ~dezenas de B | Desconhecido | Eficiência superior |
| Execução local | Sim (22GB) | Não | Não | Vantagem exclusiva |
A visão central da comunidade: A diferença do Qwen3.5-35B para modelos de nível GPT-5 Mini em programação caiu para apenas 3-6 pontos, e ele chega a superar o Claude Sonnet 4.5 em tarefas multimodais. Considerando que ele requer apenas 3B de parâmetros ativos e pode ser executado localmente, a relação eficiência/capacidade é provavelmente a mais alta entre todos os modelos públicos.
💡 Dica prática: Se você quiser comparar o desempenho real do Qwen3.5-35B com modelos de código fechado, você pode usar o serviço proxy de API da APIYI (apiyi.com) para invocar o Qwen3.5, Claude e GPT simultaneamente e realizar um teste A/B em suas próprias tarefas.
Guia de implantação local do Qwen3.5-35B
Requisitos de hardware e métodos de implantação
| Método de implantação | Requisitos de hardware | Cenário recomendado |
|---|---|---|
| Ollama | 22GB+ RAM/VRAM | O mais simples, execução com um clique |
| vLLM | GPU + 24GB+ VRAM | Vazão de nível de produção |
| SGLang | GPU + 24GB+ VRAM | Recomendado para alta vazão |
| KTransformers | Híbrido CPU + GPU | Hardware de baixo desempenho |
| LM Studio | 22GB+ RAM | Interface gráfica amigável |
Implantação com um clique via Ollama
# Após a instalação, basta um comando para executar
ollama run qwen3.5:35b
Invocação do modelo via API (sem necessidade de implantação local)
Se você não quer ter o trabalho de configurar localmente, a forma mais simples é realizar a invocação do modelo diretamente via API:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{
"role": "user",
"content": "Ajude-me a revisar este código Python e encontrar gargalos de desempenho"
}],
temperature=0.6, # 0.6 é recomendado para tarefas de programação
max_tokens=32768
)
print(response.choices[0].message.content)
Ver alternância entre modo Thinking e modo sem Thinking
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Modo Thinking (raciocínio profundo, ideal para tarefas complexas)
response_thinking = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{"role": "user", "content": "Analise a complexidade de tempo deste algoritmo"}],
temperature=1.0,
top_p=0.95,
max_tokens=32768
)
# Modo sem Thinking (resposta rápida)
response_fast = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{"role": "user", "content": "Escreva uma função de quicksort"}],
temperature=0.7,
top_p=0.8,
max_tokens=32768,
extra_body={"chat_template_kwargs": {"enable_thinking": False}}
)
🚀 Dica de implantação: A implantação local é ideal para cenários offline ou que exigem privacidade. Para o desenvolvimento diário, recomendamos a APIYI (apiyi.com) — é mais rápido, dispensa a manutenção de hardware e permite alternar livremente entre o Qwen3.5, Claude e GPT.
Visão geral da família de modelos Qwen3.5
Comparação de especificações da série Qwen3.5
| Modelo | Parâmetros totais | Parâmetros ativos | SWE-bench | Memória mínima | Posicionamento |
|---|---|---|---|---|---|
| Qwen3.5-4B | 4B | 4B (Denso) | – | 8GB | Entrada leve |
| Qwen3.5-9B | 9B | 9B (Denso) | – | 12GB | Eficiência diária |
| Qwen3.5-27B | 27B | 27B (Denso) | 72.4 | 22GB | Alta precisão densa |
| Qwen3.5-35B-A3B | 35B | 3B (MoE) | 69.2 | 22GB | Rei da eficiência |
| Qwen3.5-122B-A10B | 122B | 10B (MoE) | – | – | Médio-alto desempenho |
| Qwen3.5-397B-A17B | 397B | 17B (MoE) | 76.4 | – | Flagship |
Sugestão de escolha:
- Equipamentos com 22GB: 35B-A3B (MoE, rápido, mas com precisão ligeiramente menor) ou 27B (Denso, um pouco mais lento, mas mais preciso).
- Busca pelo melhor custo-benefício: 35B-A3B, utiliza apenas 3B de parâmetros por inferência.
- Busca pela máxima precisão: 27B Denso, sem utilizar a arquitetura MoE.
🎯 Seleção de API: Através da APIYI (apiyi.com), você pode realizar a invocação do modelo de toda a série Qwen3.5, escolhendo conforme a necessidade, de 4B a 397B. Com uma única chave API, você alterna de forma flexível entre diferentes escalas do Qwen e modelos de código fechado como Claude e GPT.
Perguntas Frequentes
Q1: Qual escolher entre o Qwen3.5-35B e o 27B?
Ambos exigem cerca de 22 GB de memória. O 35B-A3B utiliza a arquitetura MoE (3 a 5 vezes mais rápido, porém com precisão ligeiramente menor), enquanto o 27B utiliza a arquitetura Dense (mais preciso, porém mais lento). Em tarefas de programação, a diferença entre eles não é grande (SWE-bench 69,2 vs 72,4). Para conversas do dia a dia, recomendo o 35B (mais rápido); para tarefas minuciosas, escolha o 27B (mais preciso). Você pode invocar ambos simultaneamente para comparação através do APIYI apiyi.com.
Q2: Os modelos de código aberto estão realmente alcançando os de código fechado?
Sim, mas com ressalvas. O Qwen3.5-35B superou o Claude Sonnet 4.5 no MMMU (81,4 vs 79,6) e a diferença no SWE-bench para o GPT-5 Mini é de apenas 3 pontos. No entanto, nas tarefas de programação mais difíceis e no raciocínio complexo, os modelos de código fechado de elite (Claude Opus 4.5, GPT-5.4) ainda mantêm uma vantagem clara. O código aberto está diminuindo a distância, mas ainda não empatou totalmente com o topo dos modelos fechados.
Q3: Um Mac com 22 GB consegue rodar o Qwen3.5-35B?
Sim. O Qwen3.5-35B-A3B ativa apenas 3B de parâmetros por inferência, então Macs com 22 GB de memória unificada (como as configurações de entrada dos chips M2/M3/M4) podem executá-lo fluentemente. Recomendo usar o Ollama (ollama run qwen3.5:35b) para iniciar com um clique. Se não quiser fazer a implantação local, a invocação na nuvem via APIYI apiyi.com é mais conveniente.
Resumo
5 pontos-chave sobre como o Qwen3.5-35B estabeleceu um novo recorde em programação de código aberto:
- Revolução na eficiência: 35B de parâmetros totais com apenas 3B ativos, roda com 22 GB, superando a capacidade de programação de modelos anteriores de 235B.
- Poder de programação: SWE-bench 69,2, CodeForces 2028, LiveCodeBench 74,6; o novo padrão para modelos locais.
- Inovação arquitetural: MoE com 256 especialistas + atenção híbrida (DeltaNet + Attention padrão), a melhor relação eficiência/capacidade.
- Código aberto alcançando o fechado: Superou o Claude Sonnet 4.5 no MMMU e se aproximou do GPT-5 Mini no SWE-bench; a lacuna está diminuindo.
- Totalmente aberto: Licença Apache 2.0, sem restrições comerciais, custo zero para implantação local.
O Qwen3.5-35B prova uma coisa: os modelos de código aberto não são mais apenas versões "lite" dos fechados, mas estão alcançando e até superando-os com maior eficiência. Recomendo acessar toda a série Qwen3.5 e modelos de código fechado via APIYI apiyi.com; use uma única chave API para comparar o desempenho de ambos em suas tarefas reais.
📚 Referências
-
Cartão do modelo Qwen3.5-35B-A3B – Hugging Face: Parâmetros técnicos completos e dados de avaliação
- Link:
huggingface.co/Qwen/Qwen3.5-35B-A3B - Descrição: Contém detalhes da arquitetura, pontuações de avaliação e recomendações de parâmetros de inferência
- Link:
-
Repositório GitHub do Qwen3.5: Código-fonte aberto e guias de implantação
- Link:
github.com/QwenLM/Qwen3.5 - Descrição: Inclui o download dos pesos completos do modelo e a documentação de implantação
- Link:
-
Guia Completo do Qwen3.5: Avaliação de toda a série e análise de arquitetura
- Link:
techie007.substack.com/p/qwen-35-the-complete-guide-benchmarks - Descrição: Comparação detalhada de toda a família de modelos e análise comparativa com modelos de código fechado
- Link:
-
Ollama – Qwen3.5:35B: Implantação local com um clique
- Link:
ollama.com/library/qwen3.5:35b - Descrição: A maneira mais simples de executar localmente
- Link:
Autor: Equipe técnica da APIYI
Troca técnica: Sinta-se à vontade para compartilhar sua experiência de implantação local do Qwen3.5 na seção de comentários. Para mais materiais sobre integração de modelos de IA, acesse a central de documentação da APIYI em docs.apiyi.com