
Авторское примечание: Qwen3.5-35B-A3B с активными параметрами всего в 3B набрала 69.2 балла в SWE-bench Verified, обойдя предыдущее поколение Qwen3-235B. Сообщество r/LocalLLaMA считает это вехой в гонке открытых моделей за закрытыми. В статье — глубокий анализ архитектуры и практической ценности.
Сообщество r/LocalLLaMA сейчас активно обсуждает одну новость: Qwen3.5-35B-A3B с активными параметрами всего в 3B набрала 69.2 балла в SWE-bench Verified. Она не только превзошла Qwen3 с 235 млрд параметров, но и установила новый рекорд программирования среди моделей, запускаемых локально. Сообщество считает это важным сигналом: открытые модели догоняют закрытые. Теперь 35B-модель, способная работать на потребительском железе, по уровню программирования приближается к GPT-5 mini.
Основная ценность: Прочитав эту статью, вы узнаете, почему Qwen3.5-35B произвела фурор в open-source сообществе, как её архитектура MoE позволяет достичь «большой силы при малых габаритах» и как использовать её локально или в облаке.

Основные характеристики Qwen3.5-35B
| Параметр | Описание | Значимость |
|---|---|---|
| Общие параметры | 35 млрд (35B) | Архитектура MoE |
| Активные параметры | Всего 3 млрд (3B) | Высокая эффективность |
| SWE-bench Verified | 69.2 балла | Превосходит Qwen3-235B |
| GPQA Diamond | 84.2 балла | Рассуждения уровня магистратуры |
| Контекстное окно | Нативное 256K / расширение 1M+ | Расширение YaRN |
| Требования | 22 ГБ RAM/VRAM | Доступно для потребительского железа |
| Лицензия | Apache 2.0 | Полностью открыта |
Почему r/LocalLLaMA обсуждает Qwen3.5-35B
r/LocalLLaMA — самое активное сообщество по локальным большим языковым моделям на Reddit. Участников волнует главный вопрос: какая модель пойдет на моем железе и будет при этом достаточно мощной?
Qwen3.5-35B-A3B идеально отвечает этому запросу:
- 35B общих параметров, но при каждом вызове модели активируется только 3B — это значит, что она плавно работает на Mac или GPU с 22 ГБ памяти.
- Способности к программированию (69.2 балла в SWE-bench) превосходят Qwen3-235B, у которой параметров в 7 раз больше.
- Полностью открыта по лицензии Apache 2.0, без каких-либо коммерческих ограничений.
Отзыв сообщества: «Запускайте Qwen 35B. Это отличный чат-бот, вполне подходящий для автоматизации задач». Это отражает главные требования локальных пользователей: эффективность, скорость и доступность.
Глубокий разбор архитектуры Qwen3.5-35B
MoE-архитектура с 256 экспертами
Модель Qwen3.5-35B-A3B использует архитектуру «смесь экспертов» (MoE) с очень высокой степенью детализации:
| Параметр архитектуры | Значение | Описание |
|---|---|---|
| Общее число параметров | 35B | Сумма параметров всех экспертов |
| Активные параметры | 3B | Задействуются при каждом выводе |
| Всего экспертов | 256 | Ультратонкое разделение задач |
| Активные эксперты | 8 маршрутизируемых + 1 общий | 9 экспертов на каждый шаг |
| Количество слоев | 40 | Глубокая нейронная сеть |
| Размерность скрытого слоя | 2048 | Компактный дизайн |
Механизм смешанного внимания
Qwen3.5-35B — это не классический Transformer, а модель с дизайном смешанного внимания:
Структура каждых 4 слоев выглядит так: 3 слоя Gated DeltaNet (линейное внимание) + 1 слой Gated Attention (стандартное внимание).
| Тип внимания | Доля слоев | Особенности |
|---|---|---|
| Gated DeltaNet | 75% | Линейное внимание, высокая скорость вывода |
| Gated Attention | 25% | Стандартное внимание, высокая точность |
Главная фишка такого дизайна в том, что большая часть вычислений выполняется с помощью эффективного линейного внимания, а стандартное внимание задействуется только на ключевых слоях. В этом и кроется секрет того, как модель с 35 млрд параметров потребляет всего 22 ГБ видеопамяти — оптимизирована не только разреженная активация экспертов, но и сам механизм внимания.
🎯 Технический инсайт: Архитектура Qwen3.5-35B задает тренд для MoE-моделей 2026 года: 256 экспертов с ультратонкой детализацией + смешанное внимание. Если хотите оценить эффективность этой архитектуры на практике, вы можете использовать API Qwen3.5 через сервис-прокси APIYI (apiyi.com) без необходимости локального развертывания.

Полный разбор данных тестирования Qwen3.5-35B
Тестирование программирования Qwen3.5-35B
| Бенчмарк | Qwen3.5 35B-A3B | Сравнение | Примечание |
|---|---|---|---|
| SWE-bench Verified | 69.2 | Qwen3-235B: <69 | Превосходит модель предыдущего поколения в 7 раз большего размера |
| LiveCodeBench v6 | 74.6 | — | Отличные навыки программирования в реальном времени |
| CodeForces | 2,028 | — | Уровень соревновательного программирования |
Тестирование логических рассуждений и знаний Qwen3.5-35B
| Бенчмарк | Qwen3.5 35B-A3B | Примечание |
|---|---|---|
| GPQA Diamond | 84.2 | Научные рассуждения уровня аспирантуры |
| MMLU-Pro | 85.3 | Междисциплинарные знания |
| MMLU-Redux | 93.3 | Понимание знаний |
| HMMT Feb 2025 | 89.0 | Математические олимпиады |
| IFEval | 91.9 | Следование инструкциям |
Мультимодальное тестирование Qwen3.5-35B
| Бенчмарк | Qwen3.5 35B-A3B | Примечание |
|---|---|---|
| MMMU | 81.4 | Мультимодальное понимание (близко к 79.6 у Claude Sonnet 4.5) |
| MMMU-Pro | 75.1 | Сложные мультимодальные задачи |
| MathVision | 83.9 | Визуальные математические рассуждения |
| VideoMME | 86.6 | Понимание видео |
Сравнение Qwen3.5-35B с закрытыми моделями
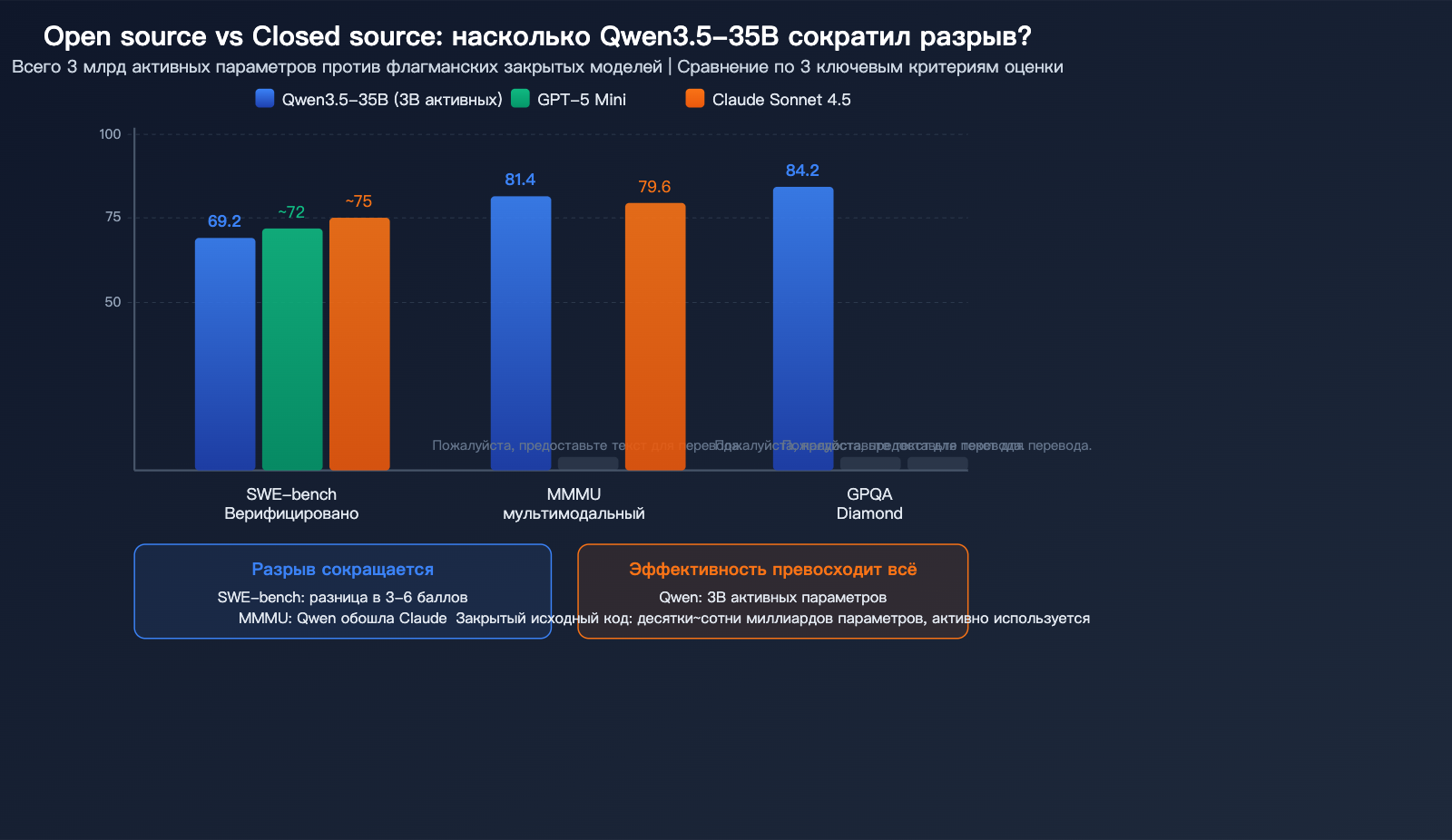
Это самый волнующий вопрос сообщества: насколько открытая модель на 35B параметров может приблизиться к закрытым аналогам?
| Параметр | Qwen3.5 35B | GPT-5 Mini | Claude Sonnet 4.5 | Разрыв |
|---|---|---|---|---|
| SWE-bench | 69.2 | ~72 | ~75 | 3-6 баллов |
| MMMU | 81.4 | — | 79.6 | Превосходство |
| GPQA Diamond | 84.2 | — | — | Топ-уровень |
| Активные параметры | 3B | ~десятки B | Неизвестно | Эффективность |
| Локальный запуск | Да (22GB) | Нет | Нет | Уникальное преимущество |
Основной вывод сообщества: В задачах программирования разрыв между Qwen3.5-35B и моделями уровня GPT-5 Mini сократился до 3-6 баллов, а в мультимодальных задачах модель даже обходит Claude Sonnet 4.5. Учитывая, что для работы требуется всего 3B активных параметров и возможен локальный запуск, соотношение эффективности и возможностей у этой модели, пожалуй, лучшее среди всех публичных решений.
💡 Практический совет: Если вы хотите сравнить реальную производительность Qwen3.5-35B с закрытыми моделями, вы можете использовать сервис-прокси API APIYI (apiyi.com) для одновременного вызова Qwen3.5, Claude и GPT, чтобы провести A/B тестирование на ваших собственных задачах.
Руководство по локальному развертыванию Qwen3.5-35B
Аппаратные требования и способы развертывания
| Способ развертывания | Аппаратные требования | Рекомендуемые сценарии |
|---|---|---|
| Ollama | 22 ГБ+ RAM/VRAM | Самый простой, запуск в один клик |
| vLLM | GPU + 24 ГБ+ VRAM | Промышленная производительность |
| SGLang | GPU + 24 ГБ+ VRAM | Рекомендуется для высокой пропускной способности |
| KTransformers | Гибрид CPU + GPU | Для слабого оборудования |
| LM Studio | 22 ГБ+ RAM | Удобный графический интерфейс |
Развертывание через Ollama в один клик
# После установки достаточно одной команды
ollama run qwen3.5:35b
Вызов через API (без локального развертывания)
Если вы не хотите возиться с локальной установкой, самый простой способ — использовать API:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{
"role": "user",
"content": "Помоги мне провести ревью этого кода на Python и найти узкие места в производительности"
}],
temperature=0.6, # Для задач программирования рекомендуется 0.6
max_tokens=32768
)
print(response.choices[0].message.content)
Переключение между режимом Thinking и обычным режимом
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Режим Thinking (глубокое рассуждение, подходит для сложных задач)
response_thinking = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{"role": "user", "content": "Проанализируй временную сложность этого алгоритма"}],
temperature=1.0,
top_p=0.95,
max_tokens=32768
)
# Обычный режим (быстрый ответ)
response_fast = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{"role": "user", "content": "Напиши функцию быстрой сортировки"}],
temperature=0.7,
top_p=0.8,
max_tokens=32768,
extra_body={"chat_template_kwargs": {"enable_thinking": False}}
)
🚀 Совет по развертыванию: Локальный запуск подходит для сценариев, чувствительных к конфиденциальности, или при работе офлайн. Для повседневной разработки рекомендуем использовать сервис-прокси API APIYI (apiyi.com) — это быстрее, не требует обслуживания оборудования, а также позволяет легко переключаться между Qwen3.5, Claude и GPT.
Обзор всего семейства моделей Qwen3.5
Сравнение характеристик серии Qwen3.5
| Модель | Всего параметров | Активных параметров | SWE-bench | Мин. память | Позиционирование |
|---|---|---|---|---|---|
| Qwen3.5-4B | 4B | 4B (Dense) | — | 8 ГБ | Легкая, для старта |
| Qwen3.5-9B | 9B | 9B (Dense) | — | 12 ГБ | Эффективная, для задач |
| Qwen3.5-27B | 27B | 27B (Dense) | 72.4 | 22 ГБ | Высокая точность |
| Qwen3.5-35B-A3B | 35B | 3B (MoE) | 69.2 | 22 ГБ | Король эффективности |
| Qwen3.5-122B-A10B | 122B | 10B (MoE) | — | — | Средне-высокий сегмент |
| Qwen3.5-397B-A17B | 397B | 17B (MoE) | 76.4 | — | Флагман |
Советы по выбору:
- Устройство с 22 ГБ: 35B-A3B (MoE, быстро, но точность чуть ниже) или 27B (Dense, чуть медленнее, но точнее).
- Максимальная эффективность: 35B-A3B, при каждом вызове модели задействуется всего 3B параметров.
- Максимальная точность: 27B Dense, без использования архитектуры MoE.
🎯 Выбор API: Через сервис APIYI (apiyi.com) можно вызывать всю линейку моделей Qwen3.5, от 4B до 397B. Один API-ключ позволяет гибко переключаться между моделями Qwen разного масштаба, а также закрытыми моделями вроде Claude и GPT.
Часто задаваемые вопросы
Q1: Что выбрать: Qwen3.5-35B или 27B?
Обе модели требуют около 22 ГБ оперативной памяти. 35B-A3B использует архитектуру MoE (работает в 3–5 раз быстрее, но точность чуть ниже), а 27B — архитектуру Dense (более точная, но медленная). В задачах программирования разница между ними невелика (SWE-bench 69.2 против 72.4). Для повседневного общения лучше выбрать 35B (из-за скорости), а для сложных задач — 27B (из-за точности). Через APIYI apiyi.com можно вызывать обе модели одновременно для сравнения.
Q2: Действительно ли open-source модели догоняют закрытые?
Да, но с оговорками. Qwen3.5-35B превзошла Claude Sonnet 4.5 в тесте MMMU (81.4 против 79.6), а в SWE-bench отставание от GPT-5 Mini составляет всего 3 балла. Однако в самых сложных задачах по программированию и комплексным рассуждениям флагманские закрытые модели (Claude Opus 4.5, GPT-5.4) по-прежнему имеют заметное преимущество. Open-source сокращает разрыв, но еще не полностью сравнялся с топовыми закрытыми решениями.
Q3: Можно ли запустить Qwen3.5-35B на Mac с 22 ГБ памяти?
Да. Qwen3.5-35B-A3B активирует только 3 млрд параметров при каждом выводе, поэтому Mac с 22 ГБ объединенной памяти (например, базовые конфигурации M2/M3/M4) справятся с этим без проблем. Рекомендуем использовать Ollama (ollama run qwen3.5:35b) для запуска в один клик. Если не хотите возиться с локальным развертыванием, облачный вызов через APIYI apiyi.com будет удобнее.
Итоги
5 ключевых выводов о том, почему Qwen3.5-35B установила новый рекорд в open-source программировании:
- Революция эффективности: 35 млрд параметров при 3 млрд активных, достаточно 22 ГБ памяти для запуска, а навыки программирования превосходят модели предыдущего поколения на 235 млрд параметров.
- Сила в коде: SWE-bench 69.2, CodeForces 2028, LiveCodeBench 74.6 — новый эталон для локальных моделей.
- Инновации в архитектуре: 256 экспертов MoE + гибридное внимание (DeltaNet + стандартное Attention) обеспечивают оптимальное соотношение эффективности и возможностей.
- Open-source догоняет закрытые модели: превосходство над Claude Sonnet 4.5 в MMMU и близость к GPT-5 Mini в SWE-bench доказывают, что разрыв сокращается.
- Полная открытость: лицензия Apache 2.0, никаких коммерческих ограничений, нулевые затраты на локальное развертывание.
Qwen3.5-35B доказывает одно: open-source модели больше не являются «урезанными» версиями закрытых, они догоняют и даже обходят их за счет более высокой эффективности. Рекомендуем подключаться к APIYI apiyi.com, чтобы получить доступ ко всей линейке Qwen3.5 и закрытым моделям одновременно — используйте один ключ, чтобы сравнить, как они справляются с вашими реальными задачами.
📚 Справочные материалы
-
Карточка модели Qwen3.5-35B-A3B — Hugging Face: полные технические характеристики и данные тестирования.
- Ссылка:
huggingface.co/Qwen/Qwen3.5-35B-A3B - Описание: содержит детали архитектуры, результаты бенчмарков и рекомендации по параметрам вывода.
- Ссылка:
-
Репозиторий Qwen3.5 на GitHub: исходный код и руководство по развертыванию.
- Ссылка:
github.com/QwenLM/Qwen3.5 - Описание: включает ссылки на скачивание весов модели и документацию по развертыванию.
- Ссылка:
-
Полное руководство по Qwen3.5: анализ архитектуры и результаты тестирования всей серии.
- Ссылка:
techie007.substack.com/p/qwen-35-the-complete-guide-benchmarks - Описание: подробное сравнение всей линейки моделей и сопоставление с закрытыми аналогами.
- Ссылка:
-
Ollama — Qwen3.5:35B: локальный запуск в один клик.
- Ссылка:
ollama.com/library/qwen3.5:35b - Описание: самый простой способ запустить модель локально.
- Ссылка:
Автор: Техническая команда APIYI
Техническое сообщество: Делитесь своим опытом локального развертывания Qwen3.5 в комментариях. Больше материалов по интеграции AI-моделей можно найти в центре документации APIYI по адресу docs.apiyi.com.