
Nota del autor: El modelo Qwen3.5-35B-A3B ha alcanzado una puntuación de 69.2 en SWE-bench Verified con solo 3B de parámetros activos, superando al Qwen3-235B de la generación anterior. La comunidad r/LocalLLaMA lo considera un hito en la carrera de los modelos de código abierto frente a los cerrados. Este artículo analiza en profundidad su arquitectura técnica y su valor real.
La comunidad r/LocalLLaMA ha estado debatiendo intensamente un tema reciente: el Qwen3.5-35B-A3B ha logrado 69.2 puntos en SWE-bench Verified con solo 3B de parámetros activos, superando no solo al Qwen3 de 235B de la generación anterior, sino también estableciendo un nuevo récord de capacidad de programación entre los modelos ejecutables localmente. La comunidad considera esto un hito importante para que los modelos de código abierto alcancen a los cerrados: un modelo de 35B que puede ejecutarse en hardware de consumo y cuyas capacidades de programación se acercan al nivel de GPT-5 mini.
Valor central: Al terminar de leer este artículo, entenderás por qué el Qwen3.5-35B ha causado tanto revuelo en la comunidad de código abierto, cómo su arquitectura MoE logra "gran capacidad en un cuerpo pequeño" y cómo utilizarlo tanto localmente como en la nube.

Puntos clave del Qwen3.5-35B
| Punto clave | Descripción | Significado |
|---|---|---|
| Parámetros totales | 35 mil millones (35B) | Arquitectura MoE |
| Parámetros activos | Solo 3 mil millones (3B) | Eficiencia extrema |
| SWE-bench Verified | 69.2 puntos | Supera al Qwen3-235B |
| GPQA Diamond | 84.2 puntos | Razonamiento a nivel de posgrado |
| Ventana de contexto | 256K nativos / 1M+ extendidos | Extensión YaRN |
| Requisitos de ejecución | 22GB de RAM/VRAM | Disponible para hardware de consumo |
| Licencia de código abierto | Apache 2.0 | Completamente abierto |
Por qué la comunidad r/LocalLLaMA está hablando del Qwen3.5-35B
r/LocalLLaMA es la comunidad de modelos de lenguaje grandes locales más activa en Reddit, y sus miembros se centran en una pregunta fundamental: ¿Qué modelo puedo ejecutar en mi hardware que sea lo suficientemente potente?
El Qwen3.5-35B-A3B cumple exactamente con esta necesidad:
- 35B de parámetros totales, pero solo activa 3B por cada inferencia, lo que significa que puede ejecutarse sin problemas en un Mac o GPU con 22GB de memoria.
- Su capacidad de programación (69.2 en SWE-bench) supera al Qwen3-235B de la generación anterior, que tiene 7 veces más parámetros.
- Es de código abierto bajo licencia Apache 2.0, sin restricciones comerciales.
La comunidad comenta: "Ejecuta Qwen 35B. Es un gran chatbot, lo suficientemente bueno para la automatización de tareas". Esto representa la demanda central de los usuarios de despliegue local: que sea útil, rápido y económico.
Análisis profundo de la arquitectura Qwen3.5-35B
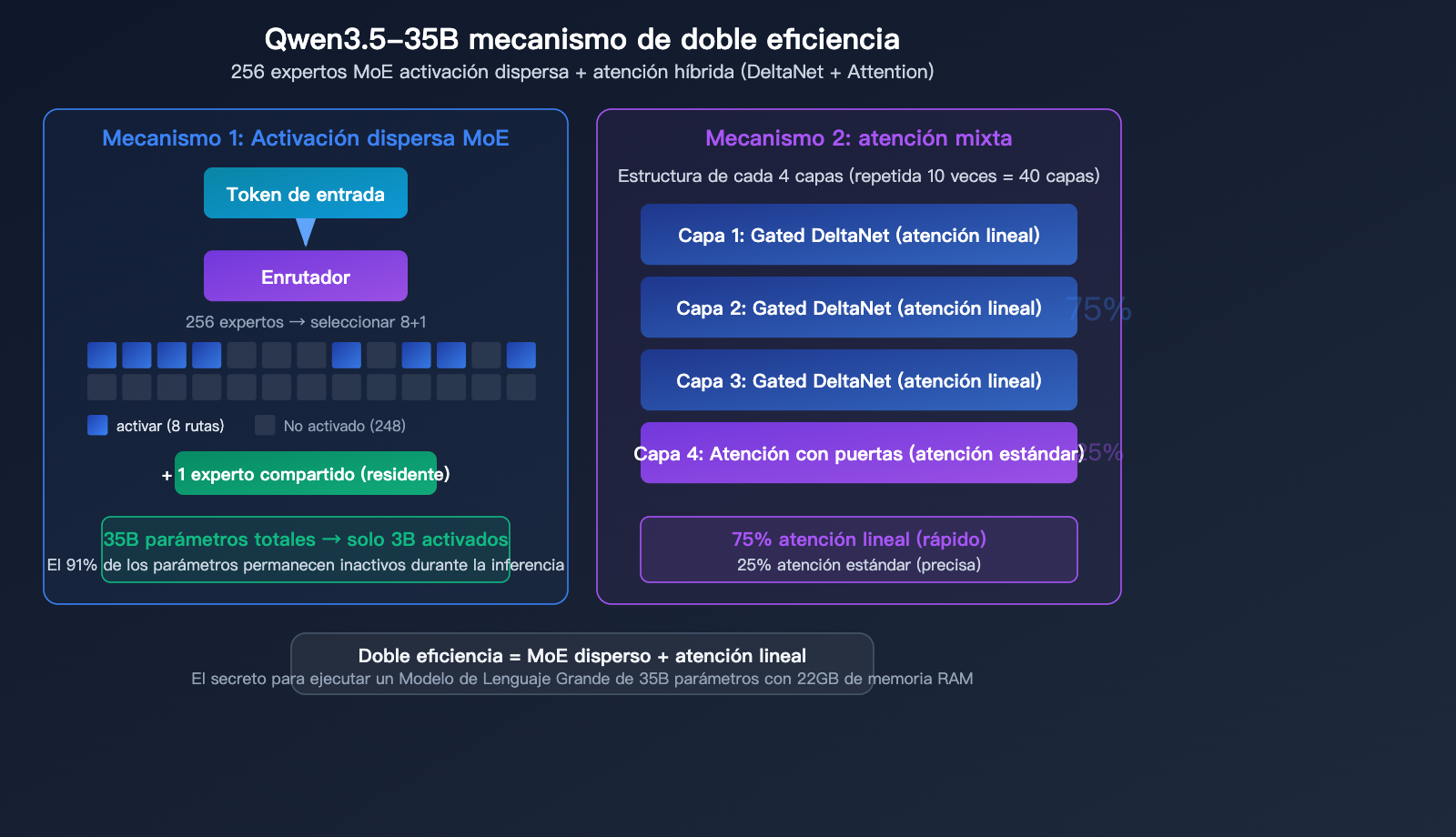
Arquitectura MoE de 256 expertos
El modelo Qwen3.5-35B-A3B utiliza una arquitectura de Mezcla de Expertos (MoE) extremadamente refinada:
| Parámetros de arquitectura | Valor | Descripción |
|---|---|---|
| Parámetros totales | 35B | Suma de todos los parámetros de expertos |
| Parámetros activos | 3B | Activados en cada inferencia |
| Total de expertos | 256 | División de trabajo de grano fino |
| Expertos activados | 8 enrutados + 1 compartido | 9 expertos seleccionados por paso |
| Capas | 40 capas | Red profunda |
| Dimensión oculta | 2048 | Diseño compacto |
Mecanismo de atención híbrida
Qwen3.5-35B no es un Transformer puro, sino que emplea un diseño de atención híbrida:
La estructura por cada 4 capas es: 3 capas de Gated DeltaNet (atención lineal) + 1 capa de Gated Attention (atención estándar).
| Tipo de atención | Proporción de capas | Características |
|---|---|---|
| Gated DeltaNet | 75% | Atención lineal, inferencia rápida |
| Gated Attention | 25% | Atención estándar, alta precisión |
La genialidad de este diseño híbrido radica en que la mayor parte del cálculo se realiza mediante una atención lineal eficiente, reservando la atención estándar, que consume más recursos, solo para las capas críticas. Este es el secreto de cómo logra 35B de parámetros ocupando solo 22GB de memoria: no solo se optimiza la activación dispersa de expertos, sino también el propio mecanismo de atención.
🎯 Perspectiva técnica: El diseño arquitectónico de Qwen3.5-35B representa la última tendencia en modelos MoE para 2026: 256 expertos de grano fino + atención híbrida. Si deseas experimentar la eficiencia que aporta esta arquitectura, puedes invocar directamente las API de la serie Qwen3.5 a través de APIYI (apiyi.com), sin necesidad de despliegue local.
Análisis detallado de los datos de evaluación de Qwen3.5-35B
Evaluación de programación de Qwen3.5-35B
| Benchmark | Qwen3.5 35B-A3B | Referencia comparativa | Nota |
|---|---|---|---|
| SWE-bench Verified | 69.2 | Qwen3-235B: <69 | Supera a la generación anterior 7 veces mayor |
| LiveCodeBench v6 | 74.6 | – | Alta capacidad de programación en tiempo real |
| CodeForces | 2,028 | – | Nivel de competencia |
Evaluación de razonamiento y conocimiento de Qwen3.5-35B
| Benchmark | Qwen3.5 35B-A3B | Nota |
|---|---|---|
| GPQA Diamond | 84.2 | Razonamiento científico a nivel de posgrado |
| MMLU-Pro | 85.3 | Conocimiento multidisciplinario |
| MMLU-Redux | 93.3 | Comprensión del conocimiento |
| HMMT Feb 2025 | 89.0 | Competencia matemática |
| IFEval | 91.9 | Seguimiento de instrucciones |
Evaluación multimodal de Qwen3.5-35B
| Benchmark | Qwen3.5 35B-A3B | Nota |
|---|---|---|
| MMMU | 81.4 | Comprensión multimodal (cerca del 79.6 de Claude Sonnet 4.5) |
| MMMU-Pro | 75.1 | Multimodal de alta dificultad |
| MathVision | 83.9 | Razonamiento matemático visual |
| VideoMME | 86.6 | Comprensión de video |
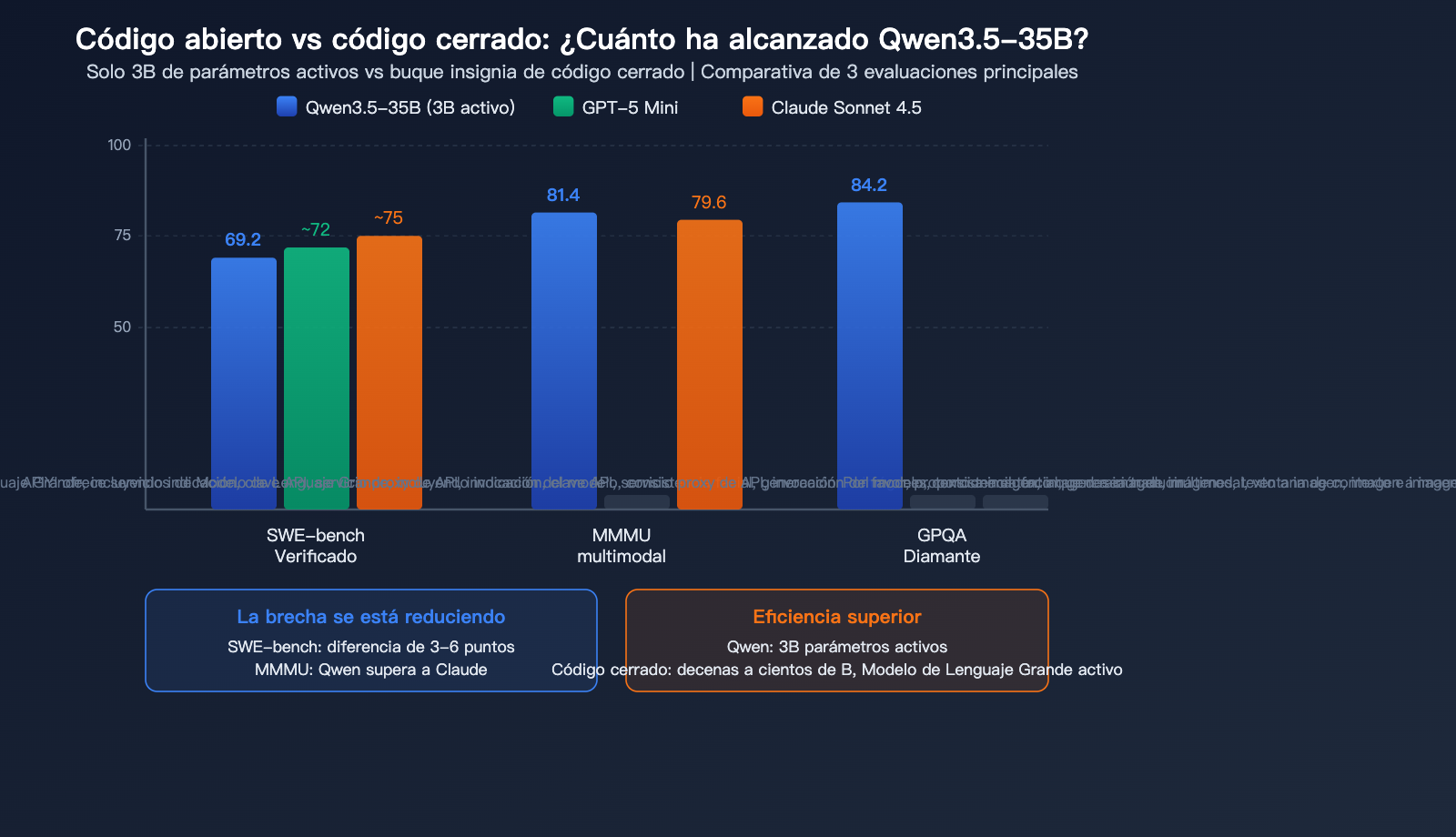
Comparativa de Qwen3.5-35B con modelos de código cerrado
Esta es la pregunta que más preocupa a la comunidad: ¿qué tan cerca está un modelo de código abierto de 35B de los modelos cerrados?
| Dimensión | Qwen3.5 35B | GPT-5 Mini | Claude Sonnet 4.5 | Diferencia |
|---|---|---|---|---|
| SWE-bench | 69.2 | ~72 | ~75 | 3-6 puntos |
| MMMU | 81.4 | – | 79.6 | Superado |
| GPQA Diamond | 84.2 | – | – | Nivel superior |
| Parámetros activos | 3B | ~decenas de B | Desconocido | Eficiencia superior |
| Ejecución local | Sí (22GB) | No | No | Ventaja única |
Opinión central de la comunidad: La brecha de programación entre Qwen3.5-35B y los modelos de nivel GPT-5 Mini se ha reducido a solo 3-6 puntos, e incluso supera a Claude Sonnet 4.5 en capacidades multimodales. Considerando que solo requiere 3B de parámetros activos y puede ejecutarse localmente, la relación eficiencia/capacidad es posiblemente la más alta entre todos los modelos públicos.
💡 Consejo práctico: Si deseas comparar el rendimiento real entre Qwen3.5-35B y los modelos de código cerrado, puedes usar el servicio proxy de API APIYI (apiyi.com) para invocar Qwen3.5, Claude y GPT simultáneamente y realizar una comparativa A/B en tus propias tareas.
Guía de despliegue local de Qwen3.5-35B
Requisitos de hardware y métodos de despliegue
| Método de despliegue | Requisitos de hardware | Escenario recomendado |
|---|---|---|
| Ollama | 22GB+ RAM/VRAM | El más sencillo, ejecución en un clic |
| vLLM | GPU + 24GB+ VRAM | Rendimiento de nivel producción |
| SGLang | GPU + 24GB+ VRAM | Recomendado para alto rendimiento |
| KTransformers | CPU + GPU híbrido | Hardware de gama baja |
| LM Studio | 22GB+ RAM | Interfaz gráfica amigable |
Despliegue en un clic con Ollama
# Tras la instalación, ejecútalo con un solo comando
ollama run qwen3.5:35b
Invocación del modelo mediante API (sin despliegue local)
Si no quieres complicarte con el despliegue local, la forma más sencilla es realizar la invocación del modelo directamente a través de nuestra API:
import openai
client = openai.OpenAI(
api_key="TU_CLAVE_API",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{
"role": "user",
"content": "Ayúdame a revisar este código Python y encuentra los cuellos de botella de rendimiento"
}],
temperature=0.6, # 0.6 recomendado para tareas de programación
max_tokens=32768
)
print(response.choices[0].message.content)
Ver cómo alternar entre el modo Thinking y el modo normal
import openai
client = openai.OpenAI(
api_key="TU_CLAVE_API",
base_url="https://vip.apiyi.com/v1"
)
# Modo Thinking (razonamiento profundo, ideal para tareas complejas)
response_thinking = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{"role": "user", "content": "Analiza la complejidad temporal de este algoritmo"}],
temperature=1.0,
top_p=0.95,
max_tokens=32768
)
# Modo sin Thinking (respuesta rápida)
response_fast = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{"role": "user", "content": "Escribe una función de ordenamiento rápido (quicksort)"}],
temperature=0.7,
top_p=0.8,
max_tokens=32768,
extra_body={"chat_template_kwargs": {"enable_thinking": False}}
)
🚀 Consejo de despliegue: El despliegue local es ideal para escenarios offline o que requieren privacidad. Para el desarrollo diario, recomendamos usar APIYI (apiyi.com); es más rápido, no requiere mantenimiento de hardware y te permite cambiar libremente entre Qwen3.5, Claude y GPT.
Resumen de la familia de modelos Qwen3.5
Comparativa de especificaciones de la serie Qwen3.5
| Modelo | Parámetros totales | Parámetros activos | SWE-bench | Memoria mínima | Posicionamiento |
|---|---|---|---|---|---|
| Qwen3.5-4B | 4B | 4B (Denso) | – | 8GB | Ligero/Entrada |
| Qwen3.5-9B | 9B | 9B (Denso) | – | 12GB | Eficiente/Diario |
| Qwen3.5-27B | 27B | 27B (Denso) | 72.4 | 22GB | Alta precisión |
| Qwen3.5-35B-A3B | 35B | 3B (MoE) | 69.2 | 22GB | Rey de la eficiencia |
| Qwen3.5-122B-A10B | 122B | 10B (MoE) | – | – | Gama media-alta |
| Qwen3.5-397B-A17B | 397B | 17B (MoE) | 76.4 | – | Insignia |
Recomendaciones de selección:
- Equipos de 22GB: 35B-A3B (MoE, rápido pero con precisión ligeramente menor) o 27B (Denso, un poco más lento pero más preciso).
- Búsqueda de máxima relación calidad-precio: 35B-A3B, solo 3B de parámetros por inferencia.
- Búsqueda de máxima precisión: 27B Denso, sin utilizar la arquitectura MoE.
🎯 Selección de API: A través de APIYI (apiyi.com) puedes invocar toda la serie de modelos Qwen3.5, eligiendo desde 4B hasta 397B según tus necesidades. Con una sola clave API, puedes alternar de forma flexible entre diferentes escalas de modelos Qwen y modelos de código cerrado como Claude o GPT.
Preguntas frecuentes
Q1: ¿Cuál debería elegir, Qwen3.5-35B o 27B?
Ambos requieren aproximadamente 22 GB de memoria. El 35B-A3B utiliza una arquitectura MoE (de 3 a 5 veces más rápido, pero con una precisión ligeramente menor), mientras que el 27B utiliza una arquitectura densa (más preciso, pero más lento). En tareas de programación, la diferencia entre ambos no es significativa (SWE-bench 69.2 frente a 72.4). Para conversaciones cotidianas, recomiendo el 35B (por su velocidad), y para tareas de precisión, el 27B (por su exactitud). A través de APIYI (apiyi.com), puedes invocar ambos modelos simultáneamente para compararlos.
Q2: ¿Están realmente los modelos de código abierto alcanzando a los de código cerrado?
Sí, pero con condiciones. El Qwen3.5-35B supera al Claude Sonnet 4.5 en MMMU (81.4 frente a 79.6) y la diferencia en SWE-bench con el GPT-5 Mini es de solo 3 puntos. Sin embargo, en las tareas de programación más difíciles y en razonamientos complejos, los modelos insignia de código cerrado (Claude Opus 4.5, GPT-5.4) siguen teniendo una ventaja clara. El código abierto está reduciendo la brecha, pero aún no ha igualado por completo a los mejores modelos cerrados.
Q3: ¿Puede un Mac de 22 GB ejecutar Qwen3.5-35B?
Sí. El Qwen3.5-35B-A3B solo activa 3B de parámetros por cada inferencia, por lo que un Mac con 22 GB de memoria unificada (como los modelos base M2/M3/M4) puede ejecutarlo con fluidez. Recomiendo usar Ollama (ollama run qwen3.5:35b) para iniciarlo con un solo comando. Si no deseas realizar una implementación local, la invocación en la nube a través de APIYI (apiyi.com) resulta mucho más cómoda.
Resumen
5 claves para entender por qué el Qwen3.5-35B ha marcado un nuevo récord en programación de código abierto:
- Revolución en eficiencia: Con 35B de parámetros totales y solo 3B activos, puede ejecutarse con 22 GB, superando en capacidad de programación a modelos de 235B de la generación anterior.
- Potencia en programación: Con 69.2 en SWE-bench, 2028 en CodeForces y 74.6 en LiveCodeBench, se convierte en el nuevo estándar para modelos locales.
- Innovación arquitectónica: MoE de 256 expertos + atención híbrida (DeltaNet + atención estándar), logrando la mejor relación eficiencia/capacidad.
- El código abierto alcanza al cerrado: Supera al Claude Sonnet 4.5 en MMMU y se acerca al GPT-5 Mini en SWE-bench; la brecha se sigue cerrando.
- Totalmente abierto: Bajo licencia Apache 2.0, sin restricciones comerciales y con coste cero para despliegues locales.
El Qwen3.5-35B demuestra una cosa: los modelos de código abierto ya no son solo versiones de bajo rendimiento de los cerrados, sino que están alcanzando e incluso superando a estos con una mayor eficiencia. Te recomiendo acceder a toda la serie Qwen3.5 y a los modelos de código cerrado a través de APIYI (apiyi.com); con una sola clave API podrás comparar el rendimiento de ambos en tus tareas reales.
📚 Referencias
-
Tarjeta del modelo Qwen3.5-35B-A3B – Hugging Face: Parámetros técnicos completos y datos de evaluación
- Enlace:
huggingface.co/Qwen/Qwen3.5-35B-A3B - Descripción: Incluye detalles de la arquitectura, puntuaciones de evaluación y recomendaciones de parámetros de inferencia
- Enlace:
-
Repositorio de GitHub de Qwen3.5: Código abierto y guía de despliegue
- Enlace:
github.com/QwenLM/Qwen3.5 - Descripción: Contiene la descarga de los pesos completos del modelo y la documentación de despliegue
- Enlace:
-
Guía completa de Qwen3.5: Evaluación de toda la serie y análisis de arquitectura
- Enlace:
techie007.substack.com/p/qwen-35-the-complete-guide-benchmarks - Descripción: Comparativa detallada de toda la familia de modelos y análisis frente a modelos de código cerrado
- Enlace:
-
Ollama – Qwen3.5:35B: Despliegue local en un solo clic
- Enlace:
ollama.com/library/qwen3.5:35b - Descripción: La forma más sencilla de ejecutarlo localmente
- Enlace:
Autor: Equipo técnico de APIYI
Intercambio técnico: Te invitamos a compartir tu experiencia con el despliegue local de Qwen3.5 en la sección de comentarios. Para más información sobre la integración de modelos de IA, visita el centro de documentación de APIYI en docs.apiyi.com