
"Mengapa setiap permintaan Claude Code saya memakan 400 ribu input token? Mengapa tagihannya begitu mahal?" — Ini adalah reaksi pertama banyak pengguna Claude Code saat melihat statistik penggunaan mereka. Faktanya, sebagian besar dari 400 ribu token tersebut kemungkinan besar sudah terkena cache hit, sehingga biaya sebenarnya mungkin hanya 1/10 dari angka yang terlihat. Namun, jika cache tidak kena (miss), tagihannya memang bisa membuat dompet menangis.
Nilai Utama: Setelah membaca artikel ini, Anda akan memahami mekanisme caching otomatis Claude Code, 8 penyebab umum kegagalan cache, serta 6 tips praktis untuk memangkas input token dari 400 ribu menjadi 50 ribu.

Penjelasan Mendalam tentang Mekanisme Prompt Caching Otomatis di Claude Code
Apakah Claude Code secara otomatis menggunakan cache?
Ya, benar. Claude Code secara otomatis mengaktifkan Prompt Caching dari Anthropic di setiap permintaan API tanpa perlu konfigurasi tambahan. Ini adalah perilaku bawaan, bukan fitur opsional.
Setiap kali Anda mengirim pesan di Claude Code, konten yang dikirim ke API disusun dengan urutan sebagai berikut:
| Urutan Penyusunan | Konten | Estimasi Ukuran | Perilaku Cache |
|---|---|---|---|
| Lapisan 1 | Definisi Tool (Read/Edit/Bash, dll.) | ~5.000 Token | Hampir statis, tingkat hit tinggi |
| Lapisan 2 | Petunjuk sistem + CLAUDE.md | ~3.000-10.000 Token | Tetap dalam sesi, tingkat hit tinggi |
| Lapisan 3 | Riwayat percakapan (semua pesan sebelumnya) | Terus bertambah | Pencocokan awalan, akumulasi cache bertahap |
| Lapisan 4 | Pesan baru saat ini | Variabel | Tidak akan pernah masuk cache |
Mekanisme Kunci: Cache didasarkan pada pencocokan awalan (prefix matching)—selama N token pertama dari permintaan sama persis dengan konten yang di-cache sebelumnya, N token tersebut akan mendapatkan hit cache. Dalam percakapan berkelanjutan, pada putaran ke-20, 95%+ token input biasanya berasal dari hit cache.
Harga Cache: Mengapa Hit Cache Sangat Penting
| Jenis Operasi | Harga Input Dasar Relatif | Harga Aktual Sonnet 4/MTok | Harga Aktual Opus 4/MTok |
|---|---|---|---|
| Input Biasa (Tanpa Cache) | 1x | $3,00 | $15,00 |
| Penulisan Cache 5 menit | 1,25x | $3,75 | $18,75 |
| Penulisan Cache 1 jam | 2x | $6,00 | $30,00 |
| Hit/Pembacaan Cache | 0,1x | $0,30 | $1,50 |
| Output | — | $15,00 | $75,00 |
Contoh konkret: Jika permintaan Anda memiliki 400.000 token input:
Skenario A: Tanpa cache sama sekali
├── 400rb Token × $3/MTok (Sonnet) = $1,20 per permintaan
Skenario B: 95% hit cache (sesi Claude Code tipikal)
├── Hit cache 380rb Token × $0,30/MTok = $0,114
├── Penulisan cache 10rb Token × $3,75/MTok = $0,0375
├── Input baru 10rb Token × $3/MTok = $0,03
├── Total = $0,18 per permintaan
└── Biaya aktual hanya 15% dari tanpa cache
🎯 Tips Teknis: Pemanggilan API Claude melalui APIYI (apiyi.com) juga mendukung mekanisme Prompt Caching, di mana biaya input berkurang 90% saat terjadi hit cache. Jika proyek Anda mengintegrasikan Claude melalui API, disarankan untuk merancang struktur petunjuk agar memaksimalkan rasio hit cache.
TTL Cache: Keuntungan Tersembunyi bagi Pengguna Max
| Paket Langganan | TTL Cache | Biaya Penulisan | Penjelasan |
|---|---|---|---|
| API Pay-as-you-go | 5 menit | 1,25x | Cache kedaluwarsa jika tidak ada aktivitas >5 menit |
| Pro / Team | 5 menit | 1,25x | Sama seperti di atas |
| Max 5x / 20x | 1 jam | 2x | Penulisan lebih mahal tapi jendela hit 12x lebih besar |
Meskipun harga penulisan cache pengguna Max adalah 2x (lebih tinggi dari standar 1,25x), TTL 1 jam berarti cache tetap ada saat Anda kembali setelah minum kopi. Bagi pengembang yang menggunakan alat secara berkala, perbedaan ini sangat signifikan.
Setiap hit cache akan mengatur ulang pengatur waktu TTL, jadi selama Anda tetap aktif, cache pada dasarnya tidak akan kedaluwarsa.
Cache Tidak Hit? 8 Penyebab Umum dan Solusinya
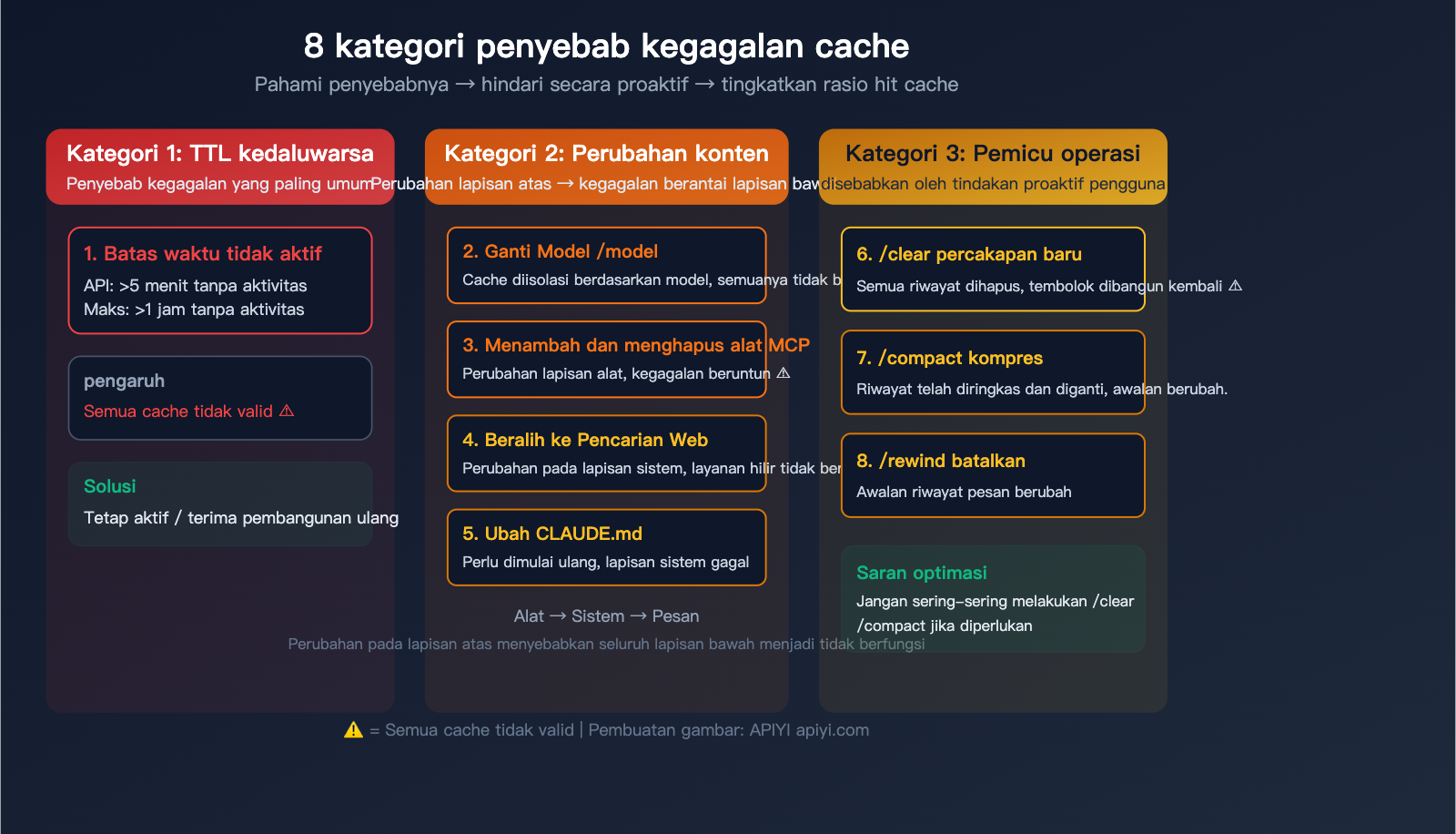
Penyebab utama kegagalan cache hanya satu: Awalan permintaan tidak cocok dengan konten cache. Secara spesifik di Claude Code, 8 situasi berikut akan menyebabkan cache gagal:
Kategori Pertama: TTL Kedaluwarsa
| Penyebab | Kondisi Pemicu | Cakupan Dampak | Solusi |
|---|---|---|---|
| 1. Timeout idle | Pengguna API >5 menit tanpa aksi, Pengguna Max >1 jam | Semua cache gagal | Tetap aktif atau terima biaya pembangunan ulang |
Ini adalah penyebab kegagalan cache yang paling umum. Jika Anda meninggalkan sesi selama lebih dari 5 menit (pengguna API) atau 1 jam (pengguna Max), permintaan berikutnya akan memicu pembangunan ulang cache secara penuh.
Kategori Kedua: Kegagalan Berantai Akibat Perubahan Konten
Cache mengikuti struktur hierarki yang ketat: Definisi Tool → Petunjuk sistem → Riwayat percakapan. Perubahan pada lapisan atas akan menyebabkan semua lapisan di bawahnya gagal.
| Penyebab | Kondisi Pemicu | Cakupan Dampak | Tingkat Keparahan |
|---|---|---|---|
| 2. Ganti model | Menggunakan perintah /model |
Semua cache (cache diisolasi per model) | ⚠️ Tinggi |
| 3. Tambah/Hapus MCP Tool | Instal atau uninstall MCP Server | Lapisan Tool + semua di bawahnya | ⚠️ Tinggi |
| 4. Ganti Web Search | Mengaktifkan atau menonaktifkan pencarian web | Lapisan sistem + semua di bawahnya | ⚠️ Sedang |
| 5. Ubah CLAUDE.md | Restart setelah mengedit file konfigurasi proyek | Lapisan sistem + semua di bawahnya | ⚠️ Sedang |
Kategori Ketiga: Kegagalan Akibat Pemicu Operasi
| Penyebab | Kondisi Pemicu | Cakupan Dampak | Tingkat Keparahan |
|---|---|---|---|
| 6. Buka percakapan baru | /clear atau buat sesi baru |
Semua cache (riwayat percakapan dihapus) | ⚠️ Tinggi |
| 7. Gunakan /compact | Kompresi riwayat percakapan secara aktif | Cache lapisan riwayat percakapan gagal | ⚠️ Sedang |
| 8. Gunakan /rewind | Membatalkan pesan sebelumnya | Awalan riwayat percakapan berubah | ⚠️ Sedang |
Batasan Teknis yang Sering Terlupakan: Panjang Cache Minimum
Jika petunjuk Anda di bawah jumlah token berikut, cache akan dilewati secara diam-diam tanpa pesan kesalahan:
| Model | Panjang Minimum yang Dapat Di-cache |
|---|---|
| Claude Opus 4.6 / Haiku 4.5 | 4.096 Token |
| Claude Sonnet 4.6 | 2.048 Token |
| Claude Sonnet 4.5 / 4 | 1.024 Token |
Untuk Claude Code, karena definisi Tool + petunjuk sistem sudah melebihi 5.000 token, batasan ini hampir tidak pernah terpicu. Namun, jika Anda membangun aplikasi melalui API sendiri, perhatikan batas bawah ini.
💡 Saran: Jika Anda membangun aplikasi sendiri melalui APIYI (apiyi.com) untuk memanggil API Claude, pastikan panjang petunjuk sistem melebihi ambang batas cache minimum yang sesuai untuk model tersebut, jika tidak, cache tidak akan berfungsi.
Mengapa Anda melihat 400 ribu Token input: Komposisi konteks Claude Code
Setelah memahami mekanisme caching, mari kita bedah apa saja yang membentuk "400 ribu Token input" yang mengejutkan itu.
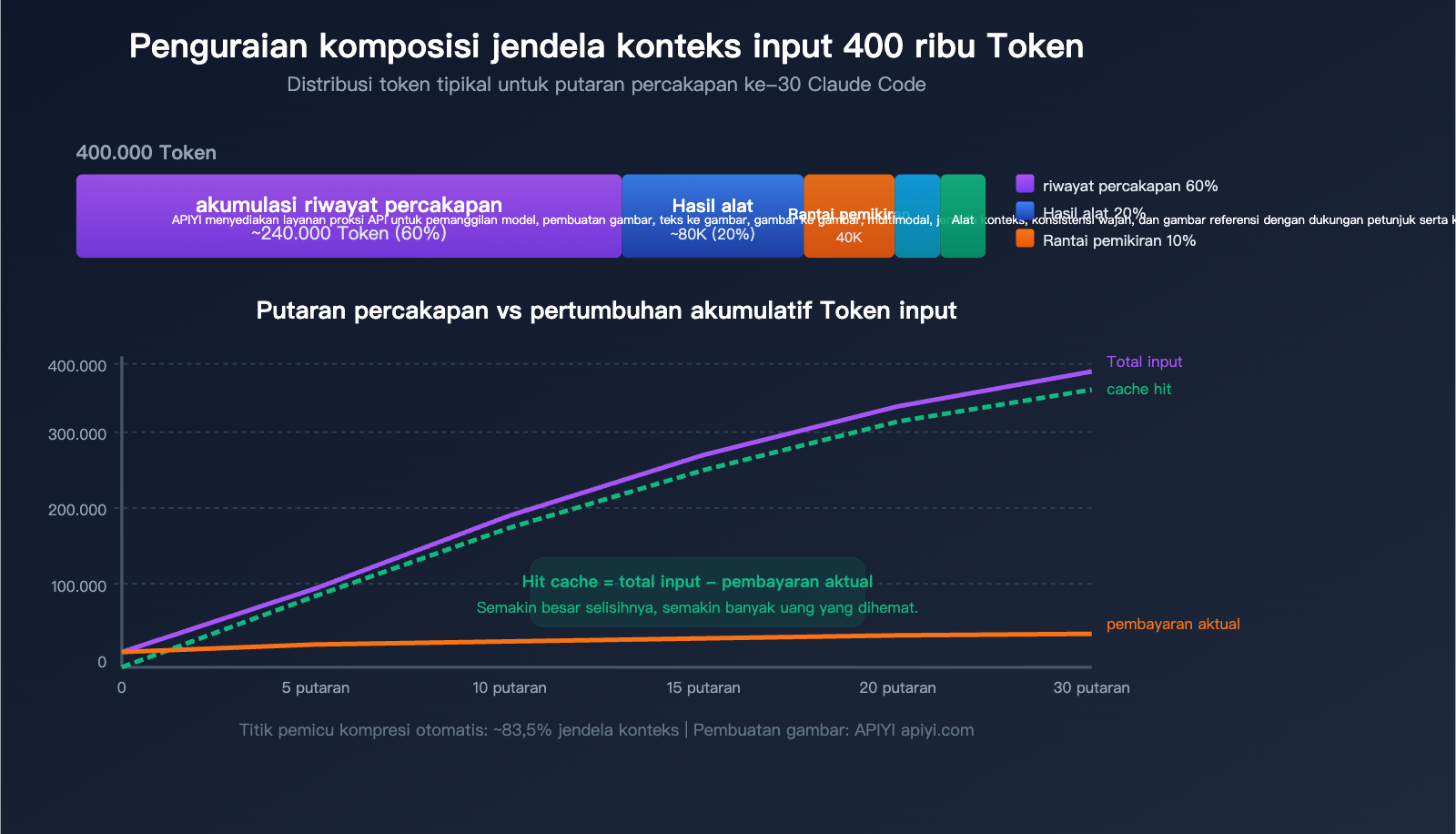
5 Sumber Utama Konsumsi Token
| Sumber | Proporsi | Estimasi dalam 400k | Karakteristik |
|---|---|---|---|
| Akumulasi Riwayat Percakapan | ~60% | ~240k | Seluruh riwayat dikirim ulang setiap putaran |
| Hasil Pemanggilan Alat | ~20% | ~80k | Hasil baca file, pencarian grep menetap di konteks |
| Rantai Pemikiran (CoT) | ~10% | ~40k | Thinking block dari beberapa putaran awal menjadi input |
| Petunjuk Sistem + CLAUDE.md | ~5% | ~20k | Disertakan dalam setiap pesan |
| Definisi Alat | ~5% | ~20k | Skema dari semua alat yang tersedia |
Fakta Inti: Semakin Panjang Percakapan, Semakin Besar Input
Cara kerja Claude Code adalah mengirim ulang seluruh riwayat percakapan pada setiap permintaan. Artinya:
- Putaran ke-1: Input ~20k Token (Petunjuk sistem + Definisi alat + Pertanyaan Anda)
- Putaran ke-5: Input ~100k Token (Akumulasi riwayat percakapan 4 putaran)
- Putaran ke-15: Input ~250k Token (Termasuk banyak hasil baca file)
- Putaran ke-30: Input ~400k+ Token (Mendekati ambang batas kompresi otomatis)
Namun perlu diingat: Sebagian besar dari input ini adalah cache hit. Dalam 400 ribu Token pada putaran ke-30, mungkin hanya 10-20 ribu yang merupakan konten baru yang tidak di-cache.
Masalah Khusus pada Basis Kode Besar
Claude Code tidak memuat seluruh basis kode ke dalam konteks secara otomatis. Ia membaca file sesuai kebutuhan. Namun, pada basis kode yang besar:
- Satu pencarian
grepmungkin mengembalikan hasil dalam jumlah besar, yang semuanya masuk ke konteks - Pembacaan file secara eksploratif, di mana konten setiap file menetap di riwayat percakapan
- Mode agen yang menjalankan operasi multi-langkah secara mandiri, di mana hasil pemanggilan alat di setiap langkah terakumulasi
Situasi di mana Anda melihat 400 ribu Token kemungkinan besar disebabkan oleh kombinasi berikut:
- Basis kode berukuran besar, Claude Code membaca banyak file untuk dianalisis
- Jumlah putaran percakapan yang banyak, menyebabkan akumulasi riwayat
- Mungkin belum menggunakan
/compactatau/clearsecara berkala - File CLAUDE.md yang mungkin terlalu panjang
6 Tips Praktis: Memangkas Input Token dari 400 Ribu menjadi 50 Ribu
Tips 1: Instruksi Presisi, Hindari Pemindaian Global
Ini adalah optimasi paling penting dan paling mudah dilakukan.
❌ Instruksi samar (memicu pemindaian file skala besar):
"Bantu saya optimalkan performa proyek ini"
"Periksa bug di dalam kode"
"Refaktor modul ini"
✅ Instruksi presisi (hanya membaca file yang diperlukan):
"Optimalkan waktu respons fungsi processRequest di src/api/handler.ts"
"Perbaiki pengecualian null pointer di baris 45 file src/auth/login.ts"
"Migrasikan fungsi formatDate di src/utils/format.ts dari moment ke dayjs"
Instruksi yang samar akan menyebabkan Claude Code menggunakan Glob + Grep + Read untuk memindai banyak file guna "memahami" kebutuhan Anda, dan konten setiap file akan menetap selamanya dalam riwayat percakapan. Instruksi yang presisi memungkinkannya hanya membaca 1-2 file yang relevan.
Efek penghematan Token: Mengurangi 60-80% Token hasil pemanggilan alat.
Tips 2: Gunakan /clear dan /compact Tepat Waktu
# Bersihkan percakapan saat beralih ke tugas yang tidak relevan
/clear
# Kompres riwayat saat percakapan panjang namun tugas belum selesai
/compact
# Kompres dengan instruksi, untuk menyimpan informasi tertentu
/compact simpan contoh kode dan definisi antarmuka API, sisanya bisa diringkas
| Perintah | Efek | Skenario Penggunaan | Catatan |
|---|---|---|---|
/clear |
Menghapus seluruh riwayat percakapan | Beralih ke tugas yang benar-benar berbeda | Seluruh cache tidak berlaku |
/compact |
AI meringkas riwayat, menggantikan teks asli | Tahap tengah percakapan panjang | Cache sebagian tidak berlaku, namun konteks menyusut drastis |
Efek nyata: Percakapan dengan 400 ribu Token biasanya dapat dikompres menjadi 50-80 ribu Token setelah menggunakan /compact.
Tips 3: Optimalkan File CLAUDE.md
CLAUDE.md akan dimuat di setiap pesan. CLAUDE.md sebesar 10.000 Token akan dikirim 30 kali dalam 30 putaran percakapan (meskipun setelah cache hit hanya dikenakan biaya 0,1x, ia tetap memakan ruang konteks yang berharga).
Saran optimasi:
├── Batasi CLAUDE.md dalam 500 baris (aturan inti)
├── Pindahkan penjelasan alur kerja mendetail ke Skills (muat sesuai kebutuhan)
├── Letakkan dokumen referensi di knowledge-base/ (Read saat diperlukan)
└── Hindari menaruh contoh kode panjang di CLAUDE.md
🚀 Saran Praktis: Meringkas CLAUDE.md tidak hanya mengurangi konsumsi Token,
tetapi juga membuat Claude Code lebih fokus pada aturan inti.
Jika Anda menggunakan APIYI (apiyi.com) untuk membangun asisten pengkodean AI serupa,
kami juga menyarankan untuk membatasi panjang petunjuk sistem.
Tips 4: Manfaatkan Subagent untuk Mengisolasi Output Panjang
Saat perlu menjalankan operasi yang menghasilkan output besar, gunakan Subagent sebagai pengganti eksekusi langsung:
❌ Eksekusi langsung di percakapan utama (output masuk ke konteks utama):
"Jalankan test suite dan analisis penyebab kegagalan"
→ Output tes bisa mencapai 50.000+ Token, menetap selamanya di riwayat percakapan
✅ Biarkan Claude Code menggunakan Subagent (output diisolasi di sub-proses):
"Gunakan sub-tugas untuk menjalankan test suite, hanya ringkas nama tes yang gagal dan penyebabnya untuk saya"
→ Konteks utama hanya bertambah ~500 Token ringkasan
Efek penghematan Token: Satu operasi dapat mengurangi 10.000-50.000 Token yang masuk ke konteks utama.
Tips 5: Pilih Model dan Tingkat Effort yang Sesuai
| Jenis Tugas | Model Rekomendasi | Tingkat Effort | Penjelasan |
|---|---|---|---|
| Modifikasi/Format sederhana | Sonnet | low | Tidak butuh pemikiran mendalam |
| Pengembangan rutin | Sonnet | medium | Rasio harga-performa terbaik |
| Desain arsitektur kompleks | Opus | high | Membutuhkan penalaran mendalam |
| Tinjauan kode | Sonnet | medium | Rasio harga-performa lebih baik dari Opus |
# Kurangi kedalaman berpikir, kurangi Token thinking (nantinya menjadi input)
# Atur effort lebih rendah untuk tugas sederhana
/effort low
# Atau kontrol batas Token berpikir melalui variabel lingkungan
MAX_THINKING_TOKENS=8000
Rantai pemikiran (thinking) yang diperluas akan menjadi bagian dari Token input pada putaran berikutnya. Menurunkan tingkat effort dapat secara signifikan mengurangi akumulasi Token di putaran selanjutnya.
Tips 6: Gunakan Perintah /context untuk Memantau Distribusi Token
# Melihat distribusi penggunaan Token saat ini
/context
Perintah /context akan menampilkan persentase Token dari setiap bagian dalam konteks saat ini, membantu Anda menemukan apa yang sebenarnya menghabiskan ruang. Temuan umum:
- Hasil pencarian grep tertentu mengembalikan 20.000 Token, padahal hanya 5% yang berguna.
- File besar yang dibaca sebelumnya tidak lagi diperlukan tetapi masih ada di dalam konteks.
- CLAUDE.md memakan ruang yang lebih besar dari yang diperkirakan.
Setelah menemukan masalahnya, gunakan /compact atau /clear secara tepat sasaran.
💰 Saran Biaya: Bagi pengguna API dengan sistem bayar per penggunaan, tips optimasi ini dapat langsung menurunkan tagihan Anda.
Melalui fitur statistik penggunaan di platform APIYI (apiyi.com), Anda dapat melihat distribusi Token setiap permintaan dengan jelas,
membantu Anda mengidentifikasi titik panas biaya.
Studi Kasus Praktis: Menekan Biaya dari $60 menjadi $8 per Hari
Berikut adalah proses optimasi nyata yang dilakukan:
Sebelum Optimasi (Proyek Python skala besar, pengguna berat Claude Code)
Penggunaan harian:
├── Putaran percakapan: ~50 putaran/hari
├── Rata-rata Token input: 350-450 ribu/putaran
├── Tingkat hit cache: ~70% (karena sering /clear dan gonta-ganti model)
├── Biaya API harian (Opus 4): ~$60
└── Rata-rata bulanan: ~$1.320
Setelah Optimasi (Menerapkan 6 Trik)
Penggunaan harian:
├── Putaran percakapan: ~40 putaran/hari (lebih presisi, tidak butuh banyak putaran)
├── Rata-rata Token input: 80-120 ribu/putaran (petunjuk presisi + compact berkala)
├── Tingkat hit cache: ~92% (mengurangi gangguan cache yang tidak perlu)
├── Biaya API harian (Utama Sonnet 4, Opus hanya untuk tugas kompleks): ~$8
└── Rata-rata bulanan: ~$176
| Item Optimasi | Persentase Penghematan | Penjelasan |
|---|---|---|
| Petunjuk presisi vs pemindaian samar | ~35% | Poin keuntungan terbesar |
| /compact dan /clear tepat waktu | ~25% | Mengontrol pembengkakan akumulatif |
| Sonnet menggantikan Opus (80% tugas) | ~20% | Penurunan model tanpa terasa |
| Menyederhanakan CLAUDE.md | ~8% | Mengurangi beban tetap per putaran |
| Isolasi output panjang dengan Subagent | ~7% | Menghindari polusi konteks oleh hasil besar |
| Menurunkan level effort | ~5% | Mengurangi akumulasi Token pemikiran |
Pertanyaan Umum (FAQ)
Q1: Apakah 400 ribu Token yang ditampilkan Claude Code adalah jumlah yang benar-benar ditagihkan?
Tidak. Claude Code secara otomatis mengaktifkan Prompt Caching. Dalam sesi aktif, 95%+ Token input biasanya merupakan hit cache, dengan biaya hanya 0,1x dari harga dasar. Dari 400 ribu Token, mungkin hanya 20-40 ribu Token yang dihitung dengan harga penuh. Kamu bisa menggunakan /context untuk melihat tingkat hit cache yang sebenarnya. Pemanggilan model melalui APIYI apiyi.com juga mendukung mekanisme caching ini.
Q2: Apakah saya masih perlu memikirkan konsumsi Token jika menggunakan paket langganan Max?
Perlu, namun alasannya berbeda. Paket langganan Max tidak menagih berdasarkan Token, tetapi memiliki batas penggunaan mingguan. Konsumsi Token yang terlalu tinggi akan membuatmu lebih cepat mencapai batas penggunaan tersebut. Menyederhanakan konteks tidak hanya memperpanjang waktu penggunaan, tetapi juga membuat Claude Code lebih akurat dalam memahami kebutuhanmu (semakin presisi konteksnya, semakin baik jawabannya).
Q3: Mana yang lebih baik, /compact atau /clear?
Tergantung situasinya. Jika kamu akan memulai tugas yang benar-benar berbeda, gunakan /clear untuk mengosongkan semuanya. Jika kamu masih dalam tugas yang sama namun percakapan menjadi sangat panjang, gunakan /compact untuk mempertahankan konteks penting sekaligus mengompres ukurannya. /compact mendukung petunjuk kustom, misalnya /compact simpan semua catatan perubahan kode dan definisi antarmuka API.
Q4: Apakah memperbarui ke versi terbaru Claude Code akan otomatis mengoptimalkan penggunaan Token?
Ya, disarankan untuk selalu menggunakan versi terbaru. Anthropic terus mengoptimalkan strategi manajemen konteks Claude Code, termasuk waktu pemicu kompresi otomatis (saat ini terpicu pada penggunaan konteks ~83,5%), pemuatan tertunda definisi alat MCP (hanya memuat nama alat, memuat skema lengkap saat digunakan), dan sebagainya. Versi baru biasanya memberikan tingkat hit cache yang lebih baik dan manajemen konteks yang lebih cerdas.

Ringkasan: Memahami Cache + Penggunaan Presisi = Biaya Terkendali
Prompt Caching pada Claude Code adalah mekanisme optimasi otomatis yang sangat hebat—Anda tidak perlu melakukan konfigurasi apa pun, sistem ini sudah membantu Anda menghemat uang. Namun, dengan memahami cara kerja dan kondisi yang menyebabkan cache tidak valid, Anda bisa meningkatkan efisiensi penghematan dari "otomatis 70%" menjadi "aktif 95%".
Ingat 3 prinsip utama ini:
- Jaga cache tetap aktif: Hindari tindakan yang tidak perlu yang dapat memutus cache (sering berganti model, sembarangan menggunakan /clear)
- Kendalikan pembengkakan konteks: Gunakan petunjuk yang presisi + /compact secara berkala agar riwayat percakapan tidak tumbuh tanpa batas
- Pilih alat dan model yang tepat: Untuk 80% tugas, Sonnet sudah cukup; simpan Opus untuk skenario yang benar-benar membutuhkannya
Bagi pengguna API dengan sistem bayar per penggunaan, kami menyarankan untuk mengelola pemanggilan model Claude secara terpusat melalui APIYI (apiyi.com) dan memanfaatkan fitur pemantauan penggunaan platform untuk terus mengoptimalkan konsumsi token. Bagi pengguna interaktif yang intens, disarankan untuk langsung menggunakan paket langganan Claude Max, dikombinasikan dengan teknik optimasi dalam artikel ini untuk mendapatkan nilai terbaik.
📝 Penulis Artikel: Tim Teknis APIYI | APIYI apiyi.com – Platform akses terpadu untuk 300+ API Model Bahasa Besar
Referensi
-
Dokumentasi Prompt Caching Anthropic: Penjelasan mendalam tentang mekanisme cache resmi
- Tautan:
docs.anthropic.com/en/docs/build-with-claude/prompt-caching - Keterangan: TTL cache, rasio harga, dan persyaratan panjang minimum
- Tautan:
-
Panduan Manajemen Biaya Claude Code: Saran optimasi token resmi
- Tautan:
code.claude.com/docs/en/costs - Keterangan: Strategi pengendalian biaya yang direkomendasikan secara resmi oleh Anthropic
- Tautan:
-
Praktik Terbaik Claude Code: Manajemen konteks dan optimasi efisiensi
- Tautan:
anthropic.com/engineering/claude-code-best-practices - Keterangan: Berisi saran praktis seperti penggunaan petunjuk presisi, penggunaan compact, dll.
- Tautan: