
作者注:Qwen3.5-35B-A3B 以仅 3B 活跃参数在 SWE-bench Verified 达到 69.2 分,超越上一代 Qwen3-235B,被 r/LocalLLaMA 社区视为开源追赶闭源的里程碑,本文深度分析技术架构和实际价值
r/LocalLLaMA 社区最近在热议一件事:Qwen3.5-35B-A3B 以仅 3B 活跃参数在 SWE-bench Verified 上取得 69.2 分,不仅超越了上一代 235B 参数的 Qwen3,更在本地可运行的模型中刷新了编程能力记录。社区将此视为开源模型赶超闭源的重要标志——一个可以在消费级硬件上运行的 35B 模型,编程能力已经接近 GPT-5 mini 级别。
核心价值: 读完本文,你将了解 Qwen3.5-35B 为什么在开源社区引发轰动,它的 MoE 架构如何实现"小身材大能力",以及如何在本地和云端使用它。

Qwen3.5-35B 核心要点
| 要点 | 说明 | 意义 |
|---|---|---|
| 总参数 | 350 亿 (35B) | MoE 架构 |
| 活跃参数 | 仅 30 亿 (3B) | 极致效率 |
| SWE-bench Verified | 69.2 分 | 超越 Qwen3-235B |
| GPQA Diamond | 84.2 分 | 研究生级推理 |
| 上下文窗口 | 原生 256K / 扩展 1M+ | YaRN 扩展 |
| 运行需求 | 22GB 内存/显存 | 消费级可用 |
| 开源协议 | Apache 2.0 | 完全开放 |
为什么 r/LocalLLaMA 社区在讨论 Qwen3.5-35B
r/LocalLLaMA 是 Reddit 上最活跃的本地大模型社区,成员关注的核心问题是:什么模型能在我的硬件上跑,同时能力足够强?
Qwen3.5-35B-A3B 恰好命中了这个需求:
- 35B 总参数,但每次推理只激活 3B——这意味着它可以在 22GB 内存的 Mac 或 GPU 上流畅运行
- 编程能力(SWE-bench 69.2)超越了上一代参数量 7 倍的 Qwen3-235B
- Apache 2.0 完全开源,无任何商业限制
社区评价:"Run Qwen 35B. It's a great chatbot, good enough for task automation." 这代表了本地部署玩家的核心诉求——够用、够快、够便宜。
Qwen3.5-35B 架构深度解析
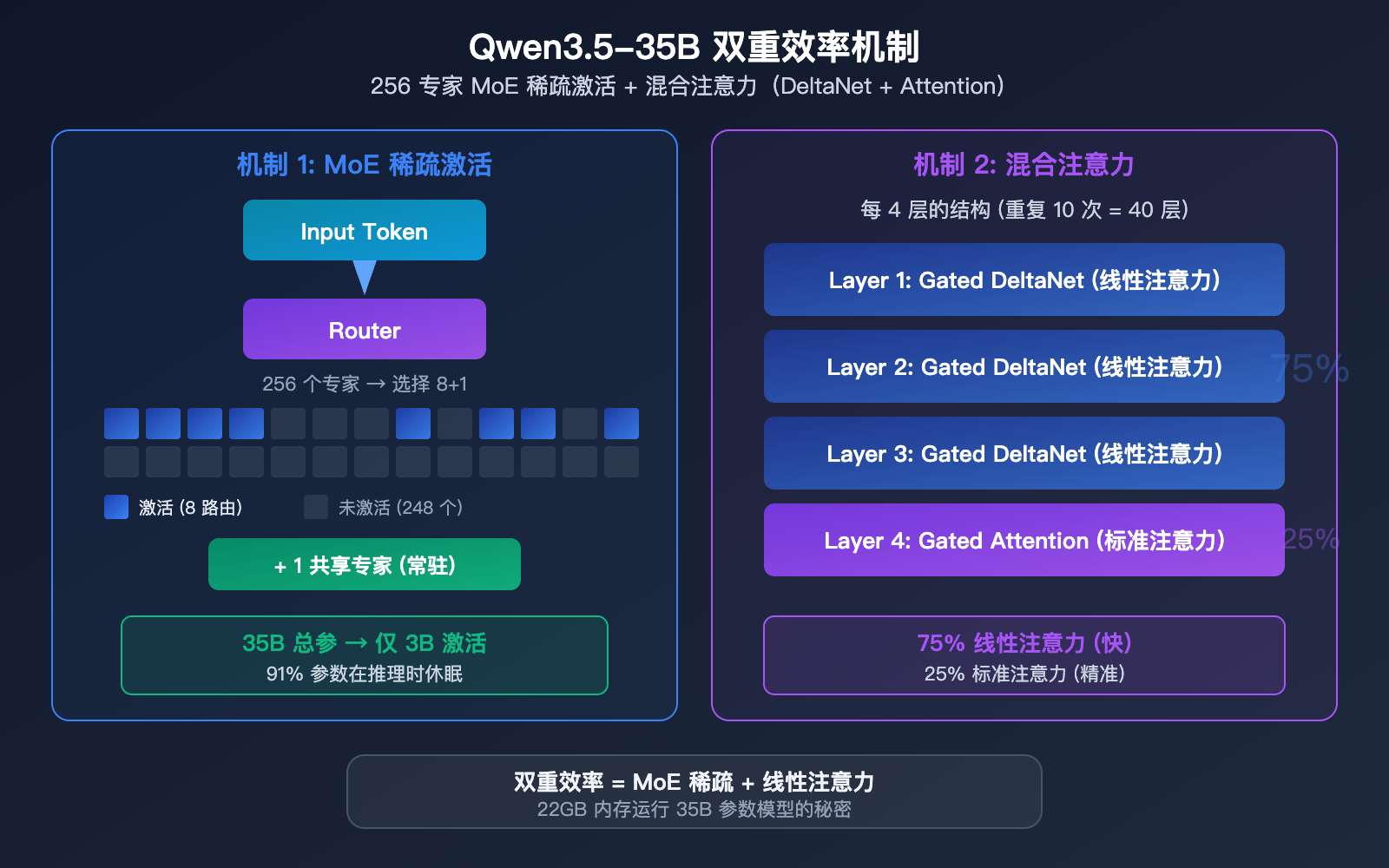
256 个专家的 MoE 架构
Qwen3.5-35B-A3B 采用了极为精细的混合专家(MoE)架构:
| 架构参数 | 数值 | 说明 |
|---|---|---|
| 总参数 | 35B | 全部专家参数之和 |
| 活跃参数 | 3B | 每次推理激活 |
| 专家总数 | 256 个 | 极细粒度分工 |
| 激活专家 | 8 路由 + 1 共享 | 每次选 9 个专家 |
| 层数 | 40 层 | 深度网络 |
| 隐藏维度 | 2048 | 紧凑设计 |
混合注意力机制
Qwen3.5-35B 不是纯 Transformer,而是采用了混合注意力设计:
每 4 层中的结构为:3 层 Gated DeltaNet(线性注意力) + 1 层 Gated Attention(标准注意力)
| 注意力类型 | 层占比 | 特点 |
|---|---|---|
| Gated DeltaNet | 75% | 线性注意力,推理快 |
| Gated Attention | 25% | 标准注意力,精度高 |
这种混合设计的精妙之处在于:大部分计算使用高效的线性注意力完成,只在关键层使用计算量更大的标准注意力。这就是 35B 参数但仅需 22GB 内存的秘密——不只是专家稀疏激活,连注意力机制本身也被优化了。
🎯 技术洞察: Qwen3.5-35B 的架构设计代表了 2026 年 MoE 模型的最新趋势——256 专家极细粒度 + 混合注意力。如果你想体验这种架构带来的效率提升,可以通过 API易 apiyi.com 直接调用 Qwen3.5 系列 API,无需本地部署。
Qwen3.5-35B 评测数据全面解读
Qwen3.5-35B 编程评测
| 评测基准 | Qwen3.5 35B-A3B | 对比参考 | 说明 |
|---|---|---|---|
| SWE-bench Verified | 69.2 | Qwen3-235B: <69 | 超越 7 倍体量前代 |
| LiveCodeBench v6 | 74.6 | – | 实时编程强 |
| CodeForces | 2,028 | – | 竞赛级水平 |
Qwen3.5-35B 推理与知识评测
| 评测基准 | Qwen3.5 35B-A3B | 说明 |
|---|---|---|
| GPQA Diamond | 84.2 | 研究生级科学推理 |
| MMLU-Pro | 85.3 | 多学科知识 |
| MMLU-Redux | 93.3 | 知识理解 |
| HMMT Feb 2025 | 89.0 | 数学竞赛 |
| IFEval | 91.9 | 指令遵循 |
Qwen3.5-35B 多模态评测
| 评测基准 | Qwen3.5 35B-A3B | 说明 |
|---|---|---|
| MMMU | 81.4 | 多模态理解(接近 Claude Sonnet 4.5 的 79.6) |
| MMMU-Pro | 75.1 | 高难度多模态 |
| MathVision | 83.9 | 视觉数学推理 |
| VideoMME | 86.6 | 视频理解 |
Qwen3.5-35B 与闭源模型对比
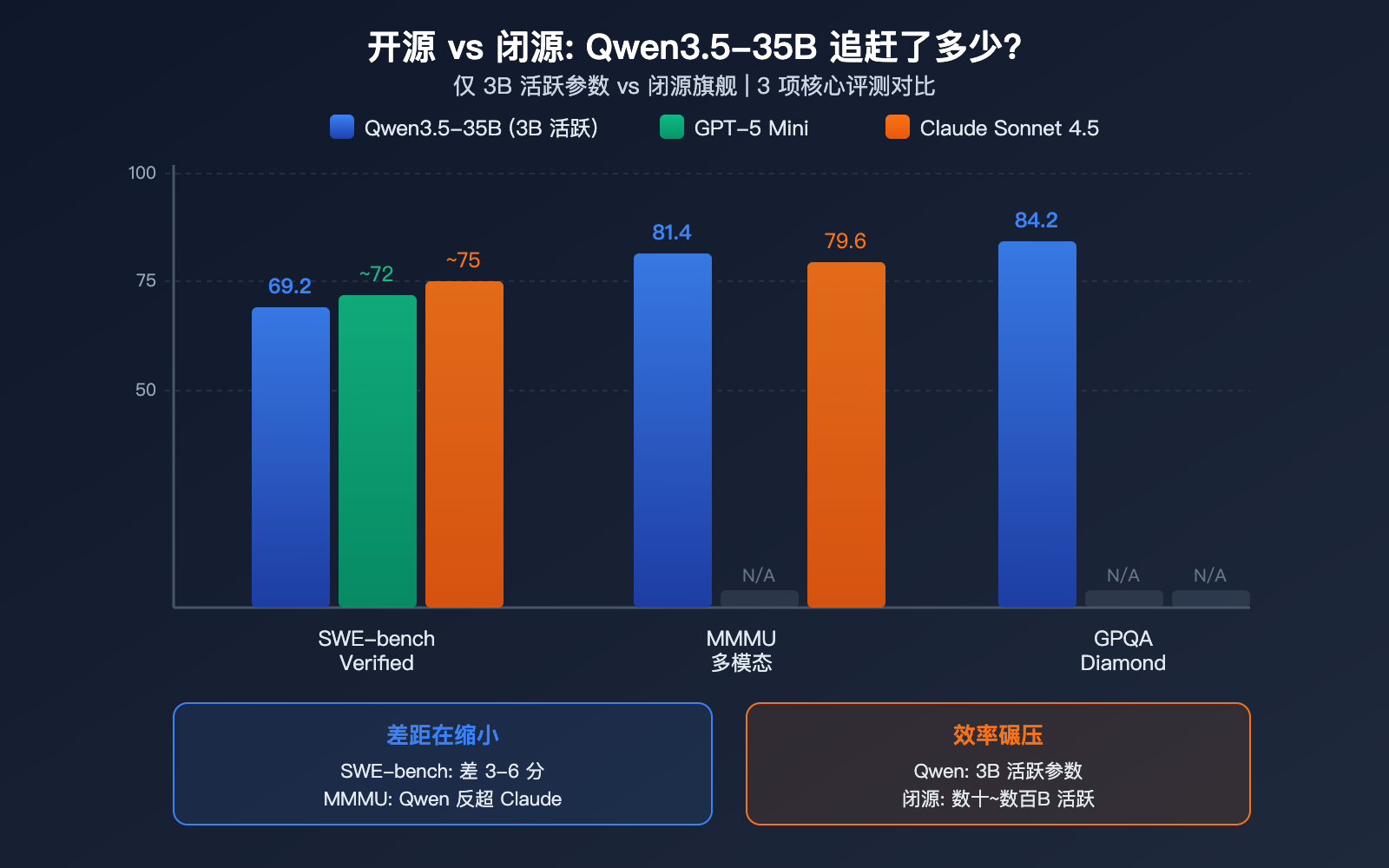
这是社区最关心的问题——35B 开源模型到底能追上闭源多少?
| 维度 | Qwen3.5 35B | GPT-5 Mini | Claude Sonnet 4.5 | 差距 |
|---|---|---|---|---|
| SWE-bench | 69.2 | ~72 | ~75 | 差 3-6 分 |
| MMMU | 81.4 | – | 79.6 | 反超 |
| GPQA Diamond | 84.2 | – | – | 顶级 |
| 活跃参数 | 3B | ~数十B | 未知 | 效率碾压 |
| 本地可运行 | 是 (22GB) | 否 | 否 | 独有优势 |
社区的核心观点: Qwen3.5-35B 在编程上与 GPT-5 Mini 级别模型差距已缩小到 3-6 分,在多模态上甚至反超 Claude Sonnet 4.5。考虑到它仅需 3B 活跃参数且可以本地运行,效率/能力比在所有公开模型中可能是最高的。
💡 实用建议: 如果你想对比 Qwen3.5-35B 和闭源模型的实际表现差异,可以通过 API易 apiyi.com 同时调用 Qwen3.5、Claude、GPT,在你自己的任务上做 A/B 对比。
Qwen3.5-35B 本地部署指南
硬件要求与部署方式
| 部署方式 | 硬件要求 | 推荐场景 |
|---|---|---|
| Ollama | 22GB+ RAM/VRAM | 最简单,一键运行 |
| vLLM | GPU + 24GB+ VRAM | 生产级吞吐 |
| SGLang | GPU + 24GB+ VRAM | 高吞吐推荐 |
| KTransformers | CPU + GPU 混合 | 低配硬件 |
| LM Studio | 22GB+ RAM | 图形界面友好 |
Ollama 一键部署
# 安装后一行命令即可运行
ollama run qwen3.5:35b
通过 API 调用(无需本地部署)
如果你不想折腾本地部署,直接通过 API 调用是最简单的方式:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{
"role": "user",
"content": "帮我review这段Python代码,找出性能瓶颈"
}],
temperature=0.6, # 编程任务推荐 0.6
max_tokens=32768
)
print(response.choices[0].message.content)
查看 Thinking 模式与非 Thinking 模式切换
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Thinking 模式 (深度推理,适合复杂任务)
response_thinking = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{"role": "user", "content": "分析这个算法的时间复杂度"}],
temperature=1.0,
top_p=0.95,
max_tokens=32768
)
# 非 Thinking 模式 (快速回答)
response_fast = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{"role": "user", "content": "写一个快排函数"}],
temperature=0.7,
top_p=0.8,
max_tokens=32768,
extra_body={"chat_template_kwargs": {"enable_thinking": False}}
)
🚀 部署建议: 本地部署适合隐私敏感和离线场景。日常开发推荐通过 API易 apiyi.com 调用——速度更快、无需维护硬件,同时可以在 Qwen3.5 和 Claude、GPT 之间自由切换。
Qwen3.5 全家族模型一览
Qwen3.5 系列规格对比
| 模型 | 总参数 | 活跃参数 | SWE-bench | 最低内存 | 定位 |
|---|---|---|---|---|---|
| Qwen3.5-4B | 4B | 4B (Dense) | – | 8GB | 轻量入门 |
| Qwen3.5-9B | 9B | 9B (Dense) | – | 12GB | 高效日常 |
| Qwen3.5-27B | 27B | 27B (Dense) | 72.4 | 22GB | 密集高精度 |
| Qwen3.5-35B-A3B | 35B | 3B (MoE) | 69.2 | 22GB | 效率之王 |
| Qwen3.5-122B-A10B | 122B | 10B (MoE) | – | – | 中高端 |
| Qwen3.5-397B-A17B | 397B | 17B (MoE) | 76.4 | – | 旗舰 |
选型建议:
- 22GB 设备: 35B-A3B(MoE,快但精度稍低)或 27B(Dense,稍慢但更精准)
- 追求极致性价比: 35B-A3B,每次推理仅 3B 参数
- 追求最高精度: 27B Dense,不走 MoE 路线
🎯 API 选型: 通过 API易 apiyi.com 可以调用 Qwen3.5 全系列模型,从 4B 到 397B 按需选择。一个 Key 即可在不同规模的 Qwen 模型和 Claude、GPT 等闭源模型之间灵活切换。
常见问题
Q1: Qwen3.5-35B 和 27B 该选哪个?
两者都需要约 22GB 内存。35B-A3B 是 MoE 架构(快 3-5 倍但精度略低),27B 是 Dense 架构(更精准但更慢)。编程任务两者差距不大(SWE-bench 69.2 vs 72.4),日常对话建议选 35B(更快),精细任务选 27B(更准)。通过 API易 apiyi.com 可以同时调用两者对比。
Q2: 开源模型真的在追赶闭源了吗?
是的,但有前提。Qwen3.5-35B 在 MMMU 上超越 Claude Sonnet 4.5(81.4 vs 79.6),SWE-bench 与 GPT-5 Mini 差距仅 3 分。但在最难的编程任务和复杂推理上,闭源旗舰(Claude Opus 4.5、GPT-5.4)仍有明显优势。开源正在缩小差距,但尚未完全追平顶尖闭源。
Q3: 22GB Mac 能跑 Qwen3.5-35B 吗?
可以。Qwen3.5-35B-A3B 每次推理仅激活 3B 参数,22GB 统一内存的 Mac(如 M2/M3/M4 起步配置)可以流畅运行。推荐使用 Ollama(ollama run qwen3.5:35b)一键启动。如不想本地部署,通过 API易 apiyi.com 云端调用更方便。
总结
Qwen3.5-35B 创下开源编程新纪录的 5 个关键解读:
- 效率革命: 35B 总参数仅 3B 活跃,22GB 即可运行,编程能力超越上一代 235B 模型
- 编程实力: SWE-bench 69.2、CodeForces 2028、LiveCodeBench 74.6,本地模型新标杆
- 架构创新: 256 专家 MoE + 混合注意力(DeltaNet + 标准 Attention),效率/能力比最优
- 开源追赶闭源: MMMU 超越 Claude Sonnet 4.5,SWE-bench 接近 GPT-5 Mini,差距在缩小
- 完全开放: Apache 2.0 协议,无商业限制,本地部署零成本
Qwen3.5-35B 证明了一件事:开源模型不再只是闭源的低配版,而是正在以更高的效率追赶甚至反超。推荐通过 API易 apiyi.com 同时接入 Qwen3.5 全系列和闭源模型,一个 Key 对比开源与闭源在你实际任务上的表现差异。
📚 参考资料
-
Qwen3.5-35B-A3B 模型卡 – Hugging Face: 完整的技术参数和评测数据
- 链接:
huggingface.co/Qwen/Qwen3.5-35B-A3B - 说明: 包含架构细节、评测分数和推理参数推荐
- 链接:
-
Qwen3.5 GitHub 仓库: 开源代码和部署指南
- 链接:
github.com/QwenLM/Qwen3.5 - 说明: 包含完整模型权重下载和部署文档
- 链接:
-
Qwen3.5 完整指南: 全系列评测和架构分析
- 链接:
techie007.substack.com/p/qwen-35-the-complete-guide-benchmarks - 说明: 详细的全家族模型对比和闭源模型横评
- 链接:
-
Ollama – Qwen3.5:35B: 本地一键部署
- 链接:
ollama.com/library/qwen3.5:35b - 说明: 最简单的本地运行方式
- 链接:
作者: APIYI 技术团队
技术交流: 欢迎在评论区分享你的 Qwen3.5 本地部署体验,更多 AI 模型接入资料可访问 API易 docs.apiyi.com 文档中心