
谷歌在 2026 年 5 月 19 日的 Google I/O 2026 大會上正式發佈了 Gemini Omni 多模態模型家族,首發型號 Gemini Omni Flash 當天就開始向用戶推送。對於第一次聽到這個名字的新人來說,「Omni」這個詞遠比想象中重要——它代表了谷歌把 Gemini 的智能推理能力和媒體生成能力徹底融合的全新方向。本文將用最通俗的方式,帶你 5 分鐘看懂 Google Omni 到底是什麼、能做什麼、和過去的 Veo 有何不同,以及作爲開發者或創作者該如何上手。
核心價值: 讀完本文,你將清楚 Google Omni (Gemini Omni) 的定位、能力邊界、使用渠道與行業意義,不再被各種新聞標題裏的術語繞暈。
Google Omni 是什麼:核心信息速覽
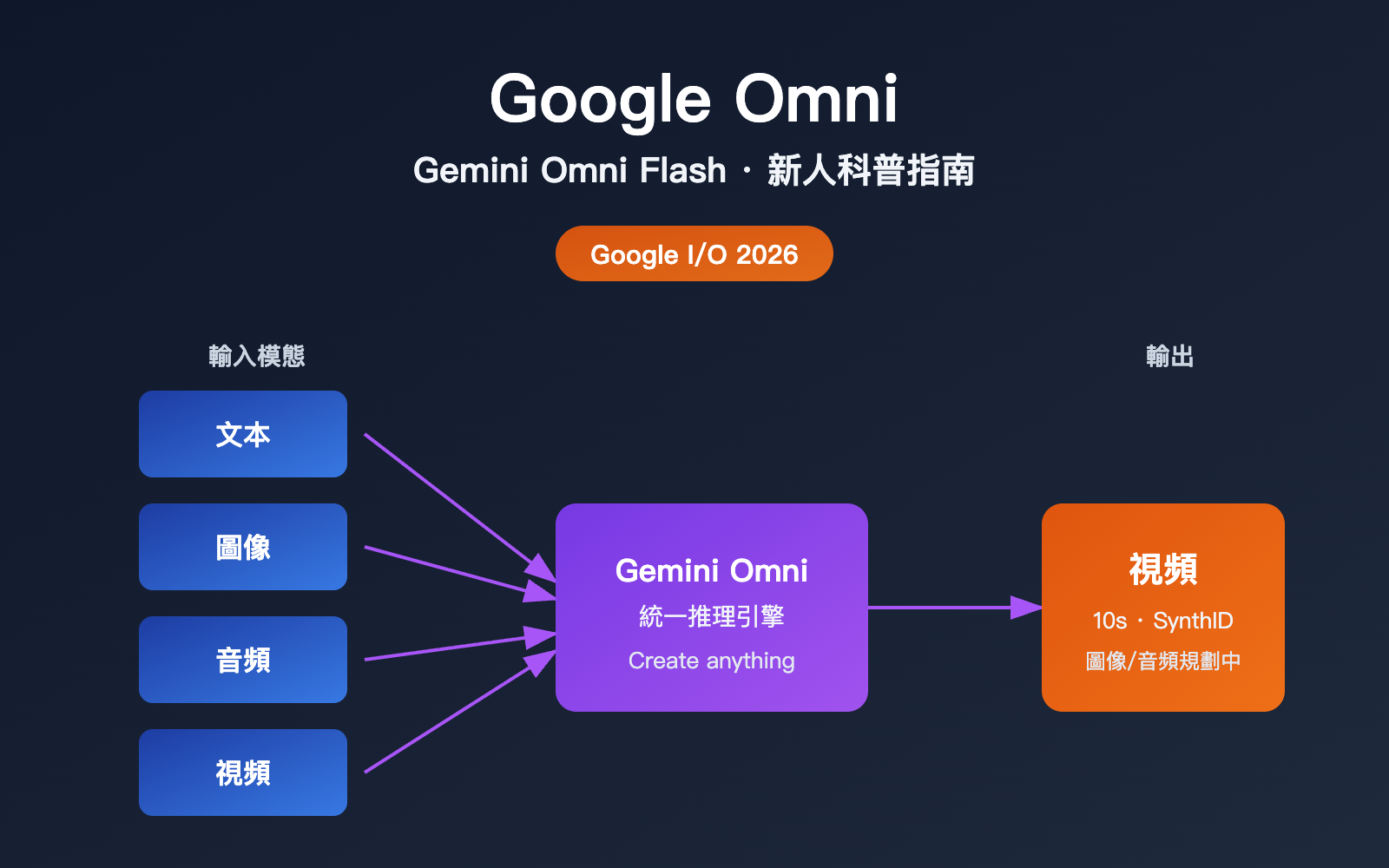
簡單一句話總結:Google Omni 是谷歌推出的「多模態生成模型家族」,首款型號是 Gemini Omni Flash。它的最大賣點不是「又一個會生成視頻的 AI」,而是「能把文字、圖像、音頻、視頻任意組合作爲輸入,統一推理後產出一段連貫視頻」。
谷歌 CEO Sundar Pichai 在主旨演講裏用了一句很直白的話來形容它的定位:「create anything from any input」。換句話說,過去你需要先用一個模型生成圖,再用另一個模型把圖變成視頻;而 Omni 試圖用一個模型完成跨模態的推理與生成。
| 信息項 | 詳情 |
|---|---|
| 發佈時間 | 2026 年 5 月 19 日 (Google I/O 2026) |
| 發佈方 | Google (Google DeepMind & Google Labs) |
| 首發型號 | Gemini Omni Flash |
| 模型定位 | 多模態推理 + 媒體生成統一模型家族 |
| 輸入模態 | 文本、圖像、視頻、音頻 (任意組合) |
| 輸出模態 | 視頻 (首發主推),圖像與音頻後續開放 |
| 單段時長 | 最長 10 秒 (部署階段限制,非模型上限) |
| 內容標識 | 全部視頻自動嵌入 SynthID 隱形水印 |
| 後續規劃 | Gemini Omni Pro 專業版、更長時長、音頻編輯能力 |
💡 新人提示: 想第一時間體驗包含 Gemini 系列在內的多種主流模型,可以通過 API易 apiyi.com 用統一接口快速調用,免去逐個平臺註冊的麻煩。
Google Omni 關鍵能力解讀:爲什麼說它是「新一代」
如果只看「輸入是什麼、輸出是什麼」,容易把 Omni 當成 Sora、Veo、Runway 這些視頻模型的同類。但谷歌產品總監 Nicole Brichtova 給了一個更精準的說法:「這是結合 Gemini 智能與媒體模型渲染能力的下一步。」下面四個能力,是新人理解 Omni 與傳統視頻模型差異的關鍵。
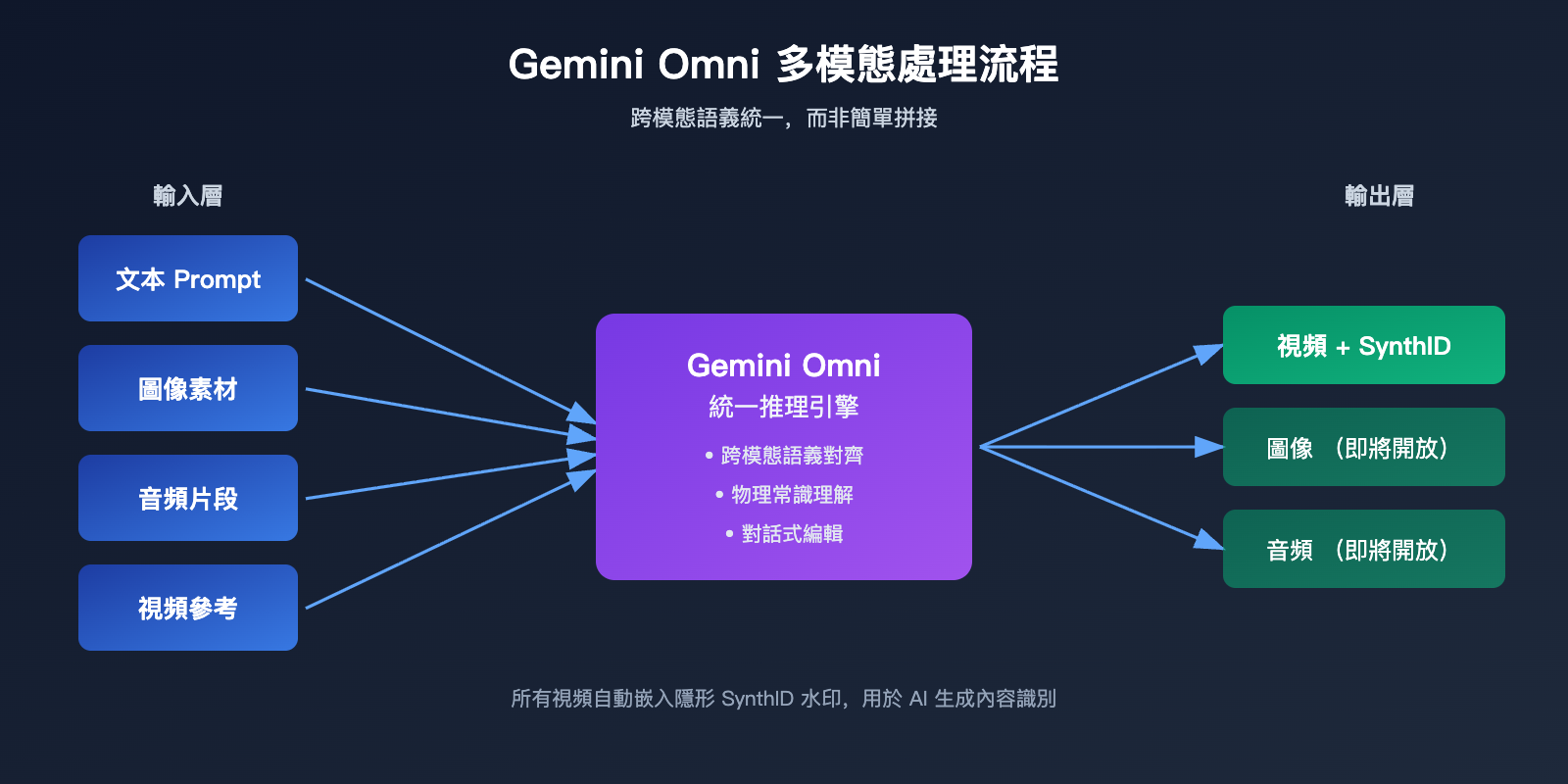
1. 跨模態推理,而非簡單拼接
傳統視頻生成往往是「文字 → 視頻」或「圖 + 文字 → 視頻」的兩步式流程。Gemini Omni 的做法是把所有輸入扔進同一個模型,讓它在內部建立一個統一的語義理解,然後一次性渲染出視頻。
舉個例子,如果你把一張產品照片、一段背景音樂和一段廣告臺詞同時丟給 Omni,它會理解「產品要在節奏切換時出現」「臺詞要和畫面動作呼應」,而不是簡單地把音樂疊在視頻上。這種「先理解、再生成」的能力,是 Gemini 模型本身的推理基因帶來的。
2. 物理理解與世界知識
谷歌在演示中重點展示了兩個例子:一個滾動瑪瑙球的鏡頭,小球落地時的反彈、停留、碰撞聲音都符合真實物理;另一個是蛋白質摺疊的 claymation 黏土風格科普動畫,幾何結構基本符合分子生物學常識。這兩個 demo 看似簡單,實際背後是模型對「真實世界規律」的理解,而不僅僅是像素層面的擬合。
對新人來說,這意味着 Omni 生成的視頻更不容易出現「物體瞬移」「光影錯亂」「人物多手指」等典型 AI 視頻瑕疵。
3. 對話式迭代編輯
Omni 支持「先生成、再用自然語言修改」。你可以讓模型生成一段視頻後,再說「把背景換成黃昏」「把鏡頭慢一點」,模型會在保持人物、場景、動作連貫的前提下做局部調整。
這種交互方式更像和一個剪輯師對話,而不是一次性寫好長 prompt。對沒有提示詞工程經驗的新人尤其友好。
4. 自定義數字分身 Avatar
Omni 允許用戶通過生物特徵認證創建自己的數字分身,然後把這個 Avatar 嵌入到生成的視頻中。谷歌強調這一步必須本人完成生物認證,目的是降低換臉濫用風險。
🎯 能力總結: Omni 的關鍵不是「更高分辨率」或「更長時長」,而是「跨模態推理 + 物理常識 + 對話編輯」三件套。要把這些能力放進自己的產品,我們建議通過 API易 apiyi.com 這類聚合接口測試不同模型組合的效果,再決定主力方案。
Gemini Omni 和 Veo 有什麼區別:新人最容易混淆的兩個名字
很多新人會問:谷歌不是已經有 Veo 了嗎,Omni 又是幹什麼的?這是非常合理的疑問,因爲它們都「能生成視頻」,但定位完全不同。下面這張表是新人理解兩者關係的最快方式。
| 對比維度 | Veo | Gemini Omni |
|---|---|---|
| 模型類型 | 專用媒體模型 | 多模態推理 + 媒體生成統一模型 |
| 輸入支持 | 文本、圖像 | 文本 + 圖像 + 音頻 + 視頻 (任意組合) |
| 推理深度 | 渲染層面爲主 | 調用 Gemini 推理,跨模態語義統一 |
| 編輯方式 | 重新生成爲主 | 支持對話式增量編輯 |
| 物理理解 | 一般 | 顯著增強 (官方 demo 重點強調) |
| 適用人羣 | 專業視頻創作者 | 創作者 + 普通消費者 + 開發者 |
| 當前定位 | 高質量視頻生成工具 | 跨模態「create anything」基礎模型 |
簡單類比:Veo 像是一臺高保真打印機,你給它一張圖,它能打出精美的成品;而 Omni 更像一個能理解你意圖的全能助理,你隨手丟一些素材和一句話需求,它就能產出成片。兩者未來很可能並存,但 Omni 代表了谷歌押注的「統一多模態」路線。

🧭 新人選擇建議: 如果你只是想生成精美短片,Veo 依然夠用;如果你要做「圖文音視頻混合輸入」的應用場景,Omni 是更合適的方向。要快速對比這兩類模型的實際表現,推薦通過 API易 apiyi.com 這種支持多模型切換的接口做 A/B 測試,以便在同一套代碼裏換模型不換流程。
Gemini Omni Flash 怎麼用:新人上手指南
發佈之初,Gemini Omni Flash 已經向不同人羣開放,但渠道並不統一。下面這張渠道對照表可以幫新人快速判斷「我應該從哪裏開始用」。
| 用戶類型 | 推薦入口 | 是否收費 | 備註 |
|---|---|---|---|
| 普通消費者 | Gemini app | 需訂閱 Google AI Plus/Pro/Ultra | 個人創意、短視頻製作 |
| 內容創作者 | Google Flow | 需訂閱 Google AI 套餐 | 面向專業創意工作流 |
| 短視頻用戶 | YouTube Shorts、YouTube Create App | 免費 | 限時免費體驗,首選入門通道 |
| 開發者 / 企業 | Google API (即將上線) | 暫未公佈定價 | 數週內開放,可關注後續公告 |
| 多模型評估者 | 第三方聚合 API 平臺 | 看平臺定價 | 適合同時對比多家模型的研發團隊 |
新人最簡單的上手路徑
- 如果你完全沒有付費 AI 工具,推薦先去 YouTube Shorts 或 YouTube Create App 體驗免費的 Omni 視頻生成,這是門檻最低的入口。
- 如果你已經是 Google AI Plus 及以上訂閱用戶,直接打開 Gemini app,在創作面板裏就能看到 Omni 視頻生成入口。
- 如果你是開發者,目前最務實的做法是先在消費者端體驗效果,等待官方 API 開放;同時通過 API易 apiyi.com 調用 Gemini 系列其它已開放型號,提前打通自己的多模態調用鏈路。
一段最簡調用思路 (待官方 API 開放後)
雖然 Omni 的官方開發者 API 還在「數週內推出」階段,但我們可以預先設計調用結構,等接口開放即可直接接入。
# 多模型聚合調用示例 (示意結構,Omni 官方 API 開放後替換 model 即可)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # 通過 API易 統一接入多模型
)
# 當前可立即調用 Gemini 系列已開放型號
response = client.chat.completions.create(
model="gemini-2.5-pro",
messages=[{"role": "user", "content": "用一句話解釋多模態模型的核心價值"}]
)
print(response.choices[0].message.content)
💡 快速上手建議: 新人不必等到所有官方 API 全部開放再動手,通過 API易 apiyi.com 提前用 Gemini 系列其它型號搭好流程,等 Omni API 正式上線後只需替換模型名稱,幾乎零遷移成本。
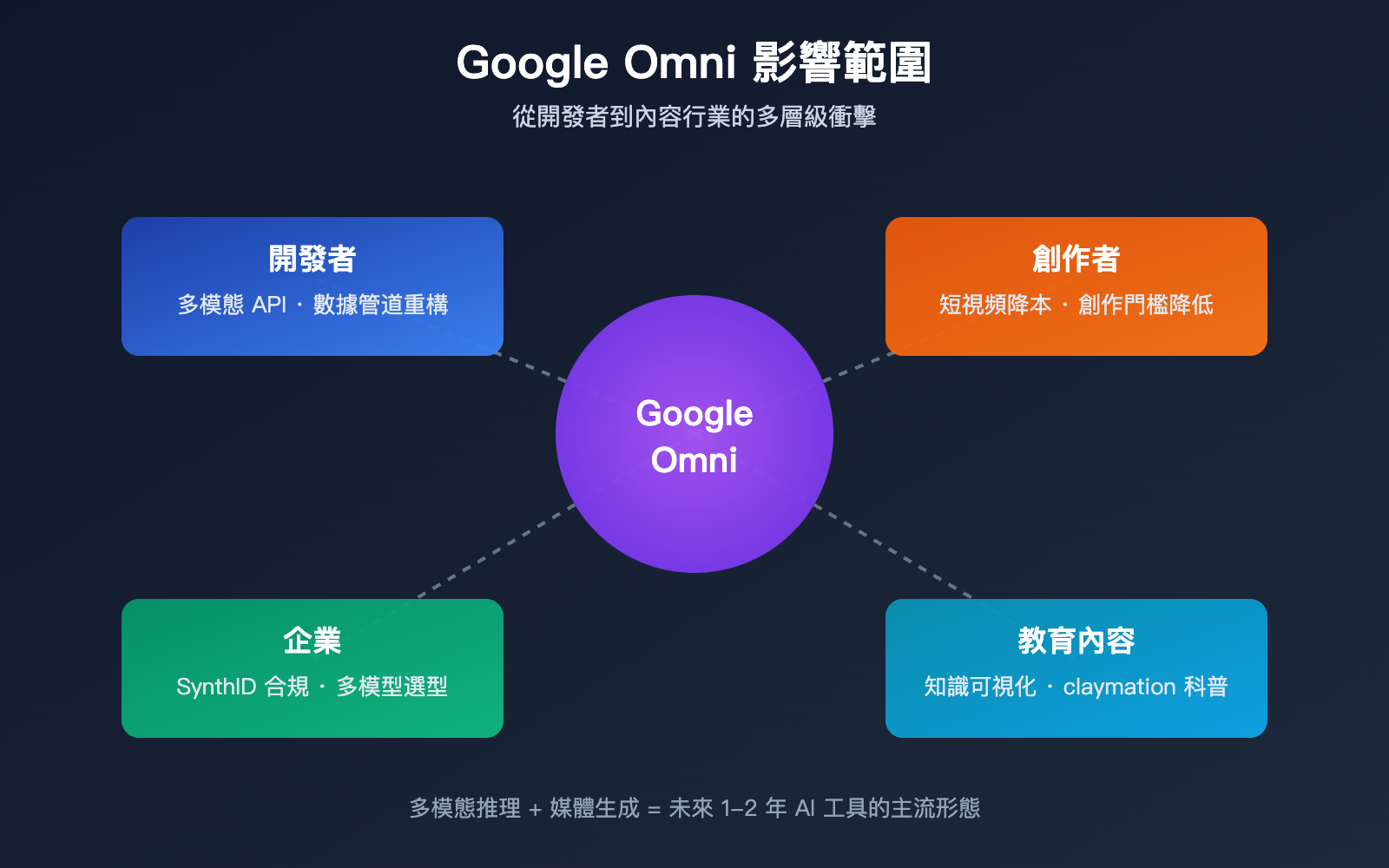
Google Omni 對開發者和行業的影響
很多新人會關心:這個新模型對我意味着什麼?這個問題對開發者、創作者、企業三類人羣答案不同。
對開發者的影響
| 影響方向 | 具體表現 |
|---|---|
| 調用方式 | 多模態 prompt 設計取代「先 t2i 再 i2v」流水線 |
| 工具鏈 | SDK 需要適配「視頻/音頻輸入流」而非純文本 |
| 內容合規 | SynthID 水印成爲默認要求,需提前規劃檢測與展示 |
| 成本結構 | 單次生成成本可能高於純文本調用,需精細管理用量 |
對正在搭建 AI 應用的工程師來說,Omni 釋放了一個明確信號:未來的 AI 接口不再是「文本進文本出」,而是「多模態進多模態出」。提前重構數據管道、把素材以模態分類管理,會讓你在 Omni API 正式開放時佔據先發優勢。
對內容行業的影響
短視頻平臺、廣告公司、教育內容生產者會最先受益。一段 10 秒的高質量視頻原本需要幾個小時的剪輯,Omni Flash 可以在幾分鐘內產出可用的初稿。對長尾創作者來說,「從一張圖到一段成片」的門檻被顯著拉低。
但需要注意,SynthID 水印的強制嵌入,也意味着「AI 生成」這件事會越來越透明。平臺、品牌方、監管機構都可能基於這個水印做內容標註與審覈策略調整。
對企業用戶的影響
企業用戶最關心兩件事:一是合規與品牌安全,二是規模化成本。SynthID 水印解決了第一類問題的一半;而第二類問題取決於谷歌後續公佈的 API 定價。對預算敏感的團隊來說,提前通過 API易 apiyi.com 這類聚合平臺同時評估 Gemini、GPT、Claude 等多家廠商的視頻或多模態能力,再根據成本與質量做選型,是更穩妥的策略。
常見問題
Q1: Google Omni 和 Gemini Omni 是同一個東西嗎?
是的。Google Omni 是非官方的簡稱,谷歌官方使用的全稱是「Gemini Omni」,屬於 Gemini 模型家族下的多模態分支。Gemini Omni Flash 則是這個家族的首發型號。兩個名字指的是同一類技術。
Q2: 新人現在能免費體驗 Gemini Omni 嗎?
可以。最直接的方式是在 YouTube Shorts 或 YouTube Create App 中使用 Omni 視頻生成功能,目前對創作者免費開放。如果你想在 Gemini app 裏使用,則需要 Google AI Plus、Pro 或 Ultra 訂閱。
Q3: Gemini Omni 單段視頻爲什麼只有 10 秒?
這是部署階段的限制,而非模型本身的能力上限。官方解釋是「在算力緊張階段,先把能力開放給更多用戶」。後續 Omni Pro 等型號會逐步延長視頻時長。
Q4: SynthID 水印會影響視頻畫質或商用嗎?
不會。SynthID 是隱形水印,人眼無法察覺,也不會影響畫質。它的作用是讓平臺和工具能在內容流轉過程中識別「這段視頻由 AI 生成」。商業使用需要遵循谷歌服務條款。
Q5: 開發者現在該做什麼準備?
第一,熟悉多模態 prompt 的設計邏輯,而不是隻寫文本提示詞。第二,梳理自己的素材庫,按模態分類。第三,提前把多模型調用流程跑通,推薦通過 API易 apiyi.com 用統一接口調用現有 Gemini 系列型號,等 Omni API 正式上線後無縫切換。
Q6: Gemini Omni 會取代 Veo 嗎?
短期內不會。Veo 仍然是高質量專用視頻生成的代表,Omni 則代表「多模態推理 + 媒體生成」的統一方向。兩者更可能在不同場景下並存。
總結:新人應該記住的三件事
第一,Gemini Omni 的本質是「跨模態推理 + 媒體生成」的統一模型,不是簡單的「又一個視頻 AI」。它的差異化能力體現在物理理解、對話式編輯與跨模態推理三個維度。
第二,新人最快的體驗路徑是 YouTube Shorts 或 YouTube Create App 的免費入口,其次纔是 Gemini app 的訂閱渠道;開發者 API 正在「數週內推出」階段,可以先規劃架構。
第三,Omni 不會立刻取代你熟悉的工具,但它代表了未來 1-2 年內多模態 AI 的主流形態。提前理解它的輸入輸出方式、SynthID 合規要求,以及與 Veo 的定位差異,會讓你在新一輪 AI 工具升級中少走彎路。如果你想在一套接口裏同時調用 Gemini、GPT、Claude 等主流模型,通過 API易 apiyi.com 是當前最省心的方案,等 Gemini Omni API 正式開放後也能第一時間接入。
參考資料
-
Google 官方博客 – Gemini Omni 發佈公告
- 鏈接:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-omni - 說明: 谷歌官方對 Gemini Omni 定位與能力的權威介紹
- 鏈接:
-
TechCrunch – Gemini Omni 深度報道
- 鏈接:
techcrunch.com/2026/05/19/googles-gemini-omni-turns-images-audio-and-text-into-video-and-thats-just-the-start - 說明: 引述 Sundar Pichai 與 Nicole Brichtova 的關鍵表態
- 鏈接:
-
9to5Google – Gemini Omni Flash 體驗報道
- 鏈接:
9to5google.com/2026/05/19/gemini-omni-create-anything-model-video - 說明: 包含官方 demo 描述與渠道開放情況
- 鏈接:
APIYI Team | 關注更多 AI 大模型動態與實戰指南,可訪問 API易 apiyi.com 獲取免費測試額度,體驗包括 Gemini 系列在內的多種主流模型統一接口。