
Nota del autor: Comparativa profunda entre Gemini 3.1 Pro y Claude Opus 4.6 a través de 13 dimensiones (razonamiento, programación, multimodalidad, precio, etc.), con sugerencias de selección de escenarios y guía de acceso a la API.
En febrero de 2026, el panorama competitivo de los modelos de IA experimentó una verdadera "fragmentación": ya no existe un único modelo que supere por completo a todos los demás. Gemini 3.1 Pro, lanzado por Google el 19 de febrero, batió récords en razonamiento y multimodalidad, mientras que Claude Opus 4.6, presentado por Anthropic el 5 de febrero, mantuvo el liderazgo en tareas de nivel experto y llamada a herramientas.
Valor principal: Al terminar de leer este artículo, tendrás claro en qué escenarios destaca cada uno de estos modelos de primer nivel y cuál elegir según tus necesidades específicas.
Comparativa de capacidad de razonamiento
| Prueba de razonamiento | Gemini 3.1 Pro | Claude Opus 4.6 | Ganador |
|---|---|---|---|
| ARC-AGI-2 (Razonamiento abstracto) | 77.1% | 68.8% | ✅ Gemini (+8.3 pts) |
| GPQA Diamond (Conocimiento científico) | 94.3% | 91.3% | ✅ Gemini (+3.0 pts) |
| HLE sin herramientas (Razonamiento definitivo) | 44.4% | 40.0% | ✅ Gemini (+4.4 pts) |
| HLE con herramientas (Razonamiento asistido) | 51.4% | 53.1% | ✅ Opus (+1.7 pts) |
Análisis: Gemini 3.1 Pro lidera de forma clara en tareas de razonamiento puro, especialmente en ARC-AGI-2, donde su 77.1% es casi 2.5 veces superior al de su predecesor Gemini 3.0 Pro (31.1%). Sin embargo, cuando se permite el uso de herramientas, Opus 4.6 toma la delantera, lo que sugiere que Opus es más hábil integrando herramientas como una extensión de su propio razonamiento.
Comparativa de capacidad de programación
| Prueba de programación | Gemini 3.1 Pro | Claude Opus 4.6 | Ganador |
|---|---|---|---|
| SWE-Bench Verified | 80.6% | 80.8% | ✅ Opus (Liderazgo mínimo) |
| Terminal-Bench 2.0 | 68.5% | 65.4% | ✅ Gemini (+3.1 pts) |
Análisis: En el ámbito de la programación, ambos modelos están muy parejos. En SWE-Bench Verified el resultado es prácticamente un empate (solo 0.2% de diferencia), aunque Gemini 3.1 Pro destaca en Terminal-Bench 2.0 (programación en entornos de terminal) con una ventaja de 3.1 puntos. Cabe mencionar que el GPT-5.3-Codex de OpenAI supera a ambos en Terminal-Bench con un 77.3%.
Comparativa de Agentes e invocación de herramientas
| Prueba de Agente | Gemini 3.1 Pro | Claude Opus 4.6 | Ganador |
|---|---|---|---|
| MCP Atlas (Flujos de varios pasos) | 69.2% | 59.5% | ✅ Gemini (+9.7 pts) |
| BrowseComp (Búsqueda web) | 85.9% | 84.0% | ✅ Gemini (+1.9 pts) |
| tau2-bench Retail (Invocación de herramientas) | – | 91.9% | Opus destaca |
| OSWorld (Control del SO) | – | 72.7% | Opus destaca |
Análisis: En MCP Atlas (flujos de trabajo de agentes de varios pasos), Gemini 3.1 Pro aventaja por 9.7 puntos, una señal importante para los desarrolladores que utilizan el Model Context Protocol. Por su parte, Opus 4.6 muestra datos sobresalientes en la invocación de herramientas de tau2-bench y en el control de sistemas operativos con OSWorld.
Comparativa de capacidad de trabajo intelectual
| Prueba de conocimiento | Gemini 3.1 Pro | Claude Opus 4.6 | Ganador |
|---|---|---|---|
| GDPval-AA Elo | 1317 | 1606 | ✅ Opus (+289 pts) |
Análisis: En GDPval-AA (que simula tareas reales de trabajo intelectual de nivel experto), Opus 4.6 supera ampliamente a Gemini 3.1 Pro con 1606 puntos Elo frente a 1317. Una diferencia de 289 puntos es comparable a la que existe entre un jugador profesional y un aficionado. Esto implica que en escenarios de alto valor como investigación, redacción de informes técnicos o análisis financiero, Opus 4.6 ofrece una ventaja cualitativa superior.
Gemini 3.1 Pro vs. Opus 4.6: Sugerencias de selección de escenarios
Según los datos anteriores, los escenarios de aplicación para ambos modelos son muy claros.
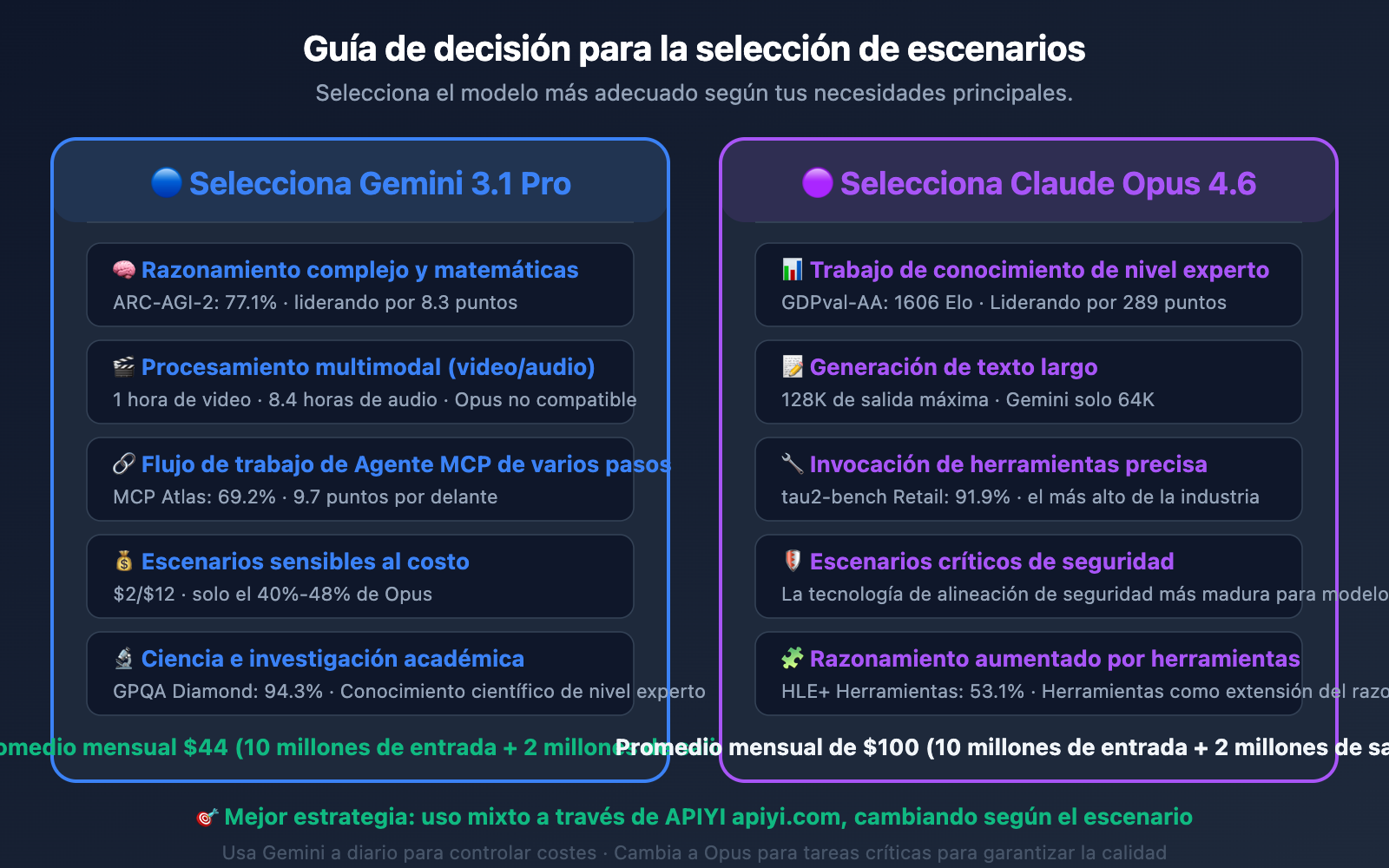
5 escenarios para elegir Gemini 3.1 Pro
- Razonamiento complejo y matemáticas: Puntuación ARC-AGI-2 del 77.1% (8.3 puntos por delante); su sistema de pensamiento de tres niveles permite ajustar la profundidad del razonamiento según la necesidad.
- Procesamiento multimodal: Soporte nativo para video (1 hora) y audio (8.4 horas). Si tu negocio implica análisis de video o transcripción de voz, Gemini es la única opción.
- Flujos de trabajo multi-paso MCP: MCP Atlas 69.2% (9.7 puntos por delante). Si estás construyendo sistemas de Agentes basados en el Model Context Protocol, Gemini resulta más confiable.
- Escenarios sensibles al costo: Precio de entrada $2 vs $5, precio de salida $12 vs $25. Con una calidad equivalente, el costo de Gemini es solo el 40%-48% del de Opus.
- Investigación científica y académica: GPQA Diamond 94.3%; ofrece el mejor rendimiento en preguntas y respuestas de conocimiento científico de nivel experto.
5 escenarios para elegir Claude Opus 4.6
- Trabajo de conocimiento de nivel experto: GDPval-AA 1606 Elo, situándose muy por delante; es ideal para informes de investigación, análisis financieros, documentos legales y otros resultados de alto valor.
- Generación de texto largo: Salida máxima de 128K tokens (frente a los 64K de Gemini). Opus es más adecuado cuando se requiere generar documentos completos o código extenso.
- Razonamiento aumentado por herramientas: HLE con pruebas de herramientas al 53.1% (1.7 puntos por delante); destaca al utilizar herramientas externas como una extensión de la cadena de razonamiento.
- Llamada a herramientas precisa: tau2-bench Retail 91.9%; es más estable en escenarios de Agentes que requieren llamadas a funciones de alta precisión (como OpenClaw).
- Escenarios críticos de seguridad: La tecnología de alineación de seguridad de Anthropic es la más madura entre los modelos de vanguardia, lo que permite un mayor control al manejar contenido sensible.
Acceso rápido a la API de Gemini 3.1 Pro y Opus 4.6
Ejemplo minimalista
A través de la plataforma APIYI, ambos modelos utilizan una interfaz unificada; solo necesitas cambiar el parámetro model:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Usando Gemini 3.1 Pro (mejor en razonamiento y multimodalidad)
response = client.chat.completions.create(
model="gemini-3.1-pro",
messages=[{"role": "user", "content": "Explica los principios físicos del entrelazamiento cuántico"}]
)
print(response.choices[0].message.content)
Ver ejemplo de llamada a Claude Opus 4.6 y código de cambio entre modelos
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Usando Claude Opus 4.6 (mejor en tareas de conocimiento y llamadas a herramientas)
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[{"role": "user", "content": "Redacta un informe de análisis sobre los ingresos del primer trimestre (Q1)"}]
)
print(response.choices[0].message.content)
# Función encapsulada para selección dinámica de modelo
def smart_call(prompt, task_type="general"):
model_map = {
"reasoning": "gemini-3.1-pro",
"multimodal": "gemini-3.1-pro",
"knowledge": "claude-opus-4-6",
"coding": "claude-opus-4-6",
"general": "gemini-3.1-pro", # Por defecto usa el más económico
}
return client.chat.completions.create(
model=model_map.get(task_type, "gemini-3.1-pro"),
messages=[{"role": "user", "content": prompt}]
)
Sugerencia: A través de la plataforma APIYI (apiyi.com), puedes acceder simultáneamente a Gemini 3.1 Pro y Claude Opus 4.6, cambiando entre ellos según sea necesario con la misma clave API. La plataforma ofrece una cuota de prueba gratuita; te recomendamos comparar el rendimiento de ambos modelos en tu escenario real antes de decidirte.
Análisis comparativo de costes entre Gemini 3.1 Pro y Opus 4.6
La diferencia de precio es un factor decisivo para muchos desarrolladores. Tomando como ejemplo un promedio mensual de 10 millones de tokens de entrada + 2 millones de tokens de salida:
| Concepto de coste | Gemini 3.1 Pro | Claude Opus 4.6 | Diferencia |
|---|---|---|---|
| Coste de entrada | $20 | $50 | Gemini ahorra $30 |
| Coste de salida | $24 | $50 | Gemini ahorra $26 |
| Coste total mensual | $44 | $100 | Gemini ahorra un 56% |
| Coste total anual | $528 | $1,200 | Gemini ahorra $672 |
Si tu escenario se centra principalmente en el razonamiento y la multimodalidad, Gemini 3.1 Pro puede ahorrarte más de la mitad de los costes sin apenas perder calidad. Sin embargo, si tu caso de uso principal es el trabajo de conocimiento de nivel experto (con una diferencia de 289 puntos en GDPval-AA), la mejora de calidad que ofrece Opus 4.6 justifica los $56 adicionales al mes.
🎯 Consejo para ahorrar: Accede a través de la plataforma APIYI (apiyi.com) para disfrutar de precios preferenciales. Una estrategia recomendada es usar Gemini 3.1 Pro como modelo predeterminado para las solicitudes diarias y cambiar a Opus 4.6 solo para tareas de conocimiento complejo y llamadas a herramientas de alta precisión.
Preguntas frecuentes
Q1: ¿Cuál es la diferencia entre el «razonamiento de tres niveles» de Gemini 3.1 Pro y el «razonamiento adaptativo» de Opus 4.6?
Gemini 3.1 Pro permite a los desarrolladores configurar manualmente tres niveles de razonamiento (Bajo/Medio/Alto), controlando la cantidad de cómputo que el modelo invierte en la tarea. El nivel Medio es una novedad que Google denomina «pensamiento profundo moderado». Por otro lado, el razonamiento adaptativo de Claude Opus 4.6 permite que el modelo determine automáticamente la profundidad de razonamiento necesaria, aunque los desarrolladores también pueden intervenir manualmente mediante el parámetro effort. Ambos conceptos son similares pero su implementación difiere: Gemini funciona más como una transmisión manual, mientras que Opus es como una automática.
Q2: ¿Se pueden utilizar ambos modelos al mismo tiempo?
Sí, es posible. Lo más recomendable es integrarlos a través de la plataforma APIYI (apiyi.com), donde con una sola clave API puedes realizar la invocación del modelo de ambos sistemas. Puedes implementar un enrutamiento dinámico según el tipo de tarea: dirige las tareas de razonamiento y multimodales a Gemini 3.1 Pro (que es más económico), y deja el trabajo de conocimiento y las llamadas a herramientas precisas para Claude Opus 4.6 (que es más potente). La función smart_call en los ejemplos de código de este artículo ya ilustra este modelo de uso.
Q3: ¿Cuál elegir para escenarios de programación (coding)?
Ambos modelos están prácticamente a la par en cuanto a programación (la diferencia en SWE-Bench es de apenas un 0.2%). Si tu trabajo se centra principalmente en entornos de terminal (como scripts de CI/CD o herramientas de línea de comandos), Gemini 3.1 Pro lidera en Terminal-Bench por 3.1 puntos. Si necesitas generar archivos de código muy extensos (que superen los 64K tokens), la capacidad de salida de 128K de Claude Opus 4.6 es más adecuada. Si el presupuesto es un factor limitante, la capacidad de programación de Gemini 3.1 Pro es totalmente suficiente y cuesta la mitad. A través de APIYI (apiyi.com), puedes probar y comparar ambos modelos en cualquier momento.
Resumen
Conclusiones clave de la comparativa entre Gemini 3.1 Pro y Claude Opus 4.6:
- Para razonamiento y tareas multimodales, elige Gemini 3.1 Pro: Lidera en ARC-AGI-2 por 8.3 puntos, ofrece soporte nativo para video y audio, y su precio es solo entre el 40% y 48% del costo de Opus.
- Para trabajo de conocimiento y uso de herramientas, elige Claude Opus 4.6: Supera en GDPval-AA por 289 puntos, alcanza un 91.9% en llamadas a herramientas (tau2-bench) y ofrece una salida máxima de 128K.
- En capacidad de programación, hay un empate técnico: La diferencia en SWE-Bench es de solo 0.2%; si el presupuesto es prioridad, Gemini es la opción preferida.
En febrero de 2026, el panorama de los Modelos de Lenguaje Grande ha entrado en una era donde cada uno destaca en áreas específicas. La mejor estrategia no es elegir uno sobre otro, sino utilizarlos de forma híbrida según el escenario. Te recomendamos acceder a ambos modelos simultáneamente a través de APIYI (apiyi.com) para alternar según tus necesidades y obtener la mejor relación entre calidad y costo.
📚 Referencias
-
Blog oficial de Gemini 3.1 Pro: Anuncios y detalles técnicos de Google
- Enlace:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - Descripción: Consulta la presentación completa de las funciones de Gemini 3.1 Pro y su sistema de pensamiento de tres niveles.
- Enlace:
-
Anuncio de lanzamiento de Claude Opus 4.6: Blog técnico oficial de Anthropic
- Enlace:
anthropic.com/news/claude-opus-4-6 - Descripción: Consulta los datos completos de Benchmark y la función de pensamiento adaptativo de Opus 4.6.
- Enlace:
-
Comparativa de modelos en Artificial Analysis: Plataforma de evaluación independiente de terceros
- Enlace:
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-claude-opus-4-6-adaptive - Descripción: Datos objetivos de comparativa horizontal de rendimiento, velocidad y precio.
- Enlace:
-
Documentación para desarrolladores de Google AI: Guía de precios y acceso a la API de Gemini
- Enlace:
ai.google.dev/gemini-api/docs/pricing - Descripción: Consulta los precios más recientes de la API de Gemini 3.1 Pro y las cuotas gratuitas.
- Enlace:
Autor: Equipo técnico
Intercambio técnico: Te invitamos a compartir tu experiencia de uso entre ambos modelos en la sección de comentarios. Para más información sobre modelos de IA, visita APIYI apiyi.com