
Lange Antwortzeiten beim Aufruf des Modells Gemini 3 Flash Preview sind eine häufige Herausforderung für Entwickler. In diesem Artikel stellen wir Ihnen Techniken zur Konfiguration von Schlüsselparametern wie timeout, max_tokens und thinking_level vor, mit denen Sie praktische Methoden zur Optimierung der Antwortgeschwindigkeit von Gemini 3 Flash Preview schnell meistern können.
Kernvorteil: Nach der Lektüre dieses Artikels werden Sie gelernt haben, wie Sie die Antwortzeit von Gemini 3 Flash Preview durch eine sinnvolle Parameterkonfiguration steuern können, um bei gleichbleibender Ausgabequalität eine signifikante Steigerung der Antwortgeschwindigkeit zu erzielen.

Ursachenanalyse für lange Antwortzeiten bei Gemini 3 Flash Preview
Bevor wir uns mit den Optimierungstechniken befassen, müssen wir verstehen, warum die Antwortzeiten von Gemini 3 Flash Preview manchmal recht lang ausfallen.
Der Mechanismus der Denk-Token (Thinking Tokens)
Gemini 3 Flash Preview nutzt einen dynamischen Denkmechanismus, der die Hauptursache für längere Antwortzeiten ist:
| Einflussfaktor | Erläuterung | Auswirkung auf die Antwortzeit |
|---|---|---|
| Komplexe logische Aufgaben | Fragen, die logisches Schlussfolgern erfordern, benötigen mehr Thinking Tokens | Signifikante Erhöhung der Antwortzeit |
| Dynamische Denktiefe | Das Modell passt den Denkaufwand automatisch an die Komplexität der Frage an | Einfache Fragen schnell, komplexe Fragen langsam |
| Nicht-Streaming-Ausgabe | Im Nicht-Streaming-Modus muss gewartet werden, bis die gesamte Generierung abgeschlossen ist | Längere Gesamtwartezeit |
| Anzahl der Ausgabe-Token | Je umfangreicher die Antwort, desto länger dauert die Generierung | Lineare Erhöhung der Antwortzeit |
Laut Testdaten von Artificial Analysis kann die Menge der verwendeten Token bei Gemini 3 Flash Preview auf der höchsten Denkstufe etwa 160 Millionen erreichen – mehr als doppelt so viel wie bei Gemini 2.5 Flash. Das bedeutet, dass das Modell bei komplexen Aufgaben eine erhebliche Menge an „Denkzeit“ verbraucht.
Tatsächliche Fallanalyse
Aus Nutzerfeedback geht hervor, dass die Standardkonfiguration von Gemini 3 Flash Preview oft nicht ideal ist, wenn eine schnelle Antwort erforderlich ist, die Genauigkeit jedoch eine untergeordnete Rolle spielt:
„Da die Aufgabe eine zeitkritische Rückmeldung erfordert und die Genauigkeit nicht so wichtig ist, dauert das Reasoning bei gemini-3-flash-preview zu lange.“
Die Hauptursachen für dieses Szenario sind:
- Das Modell verwendet standardmäßig dynamisches Denken und führt automatisch tiefgehende logische Schlüsse (Reasoning) durch.
- Die Anzahl der generierten Token kann über 7000 liegen.
- Zusätzlich müssen die Thinking Tokens berücksichtigt werden, die während des Reasoning-Prozesses verbraucht werden.
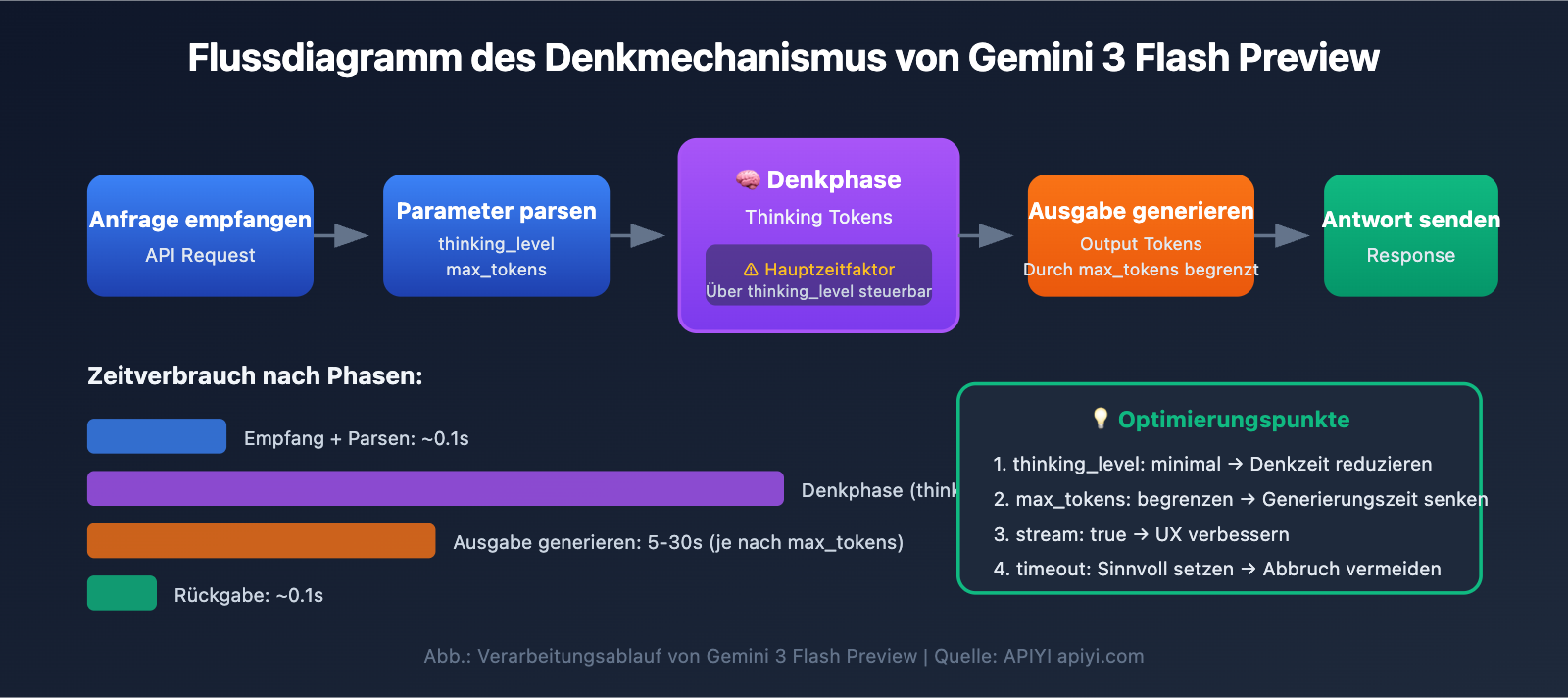
Kernpunkte zur Optimierung der Antwortgeschwindigkeit von Gemini 3 Flash Preview
| Optimierungspunkt | Erläuterung | Erwarteter Effekt |
|---|---|---|
| thinking_level einstellen | Kontrolliert die Denktiefe des Modells | Reduziert die Antwortzeit um 30–70 % |
| max_tokens begrenzen | Kontrolliert die Ausgabelänge | Verkürzt die Generierungszeit |
| Timeout anpassen | Setzt eine angemessene Zeitüberschreitung | Vermeidet das Abschneiden von Anfragen |
| Streaming-Ausgabe verwenden | Rückgabe während der Generierung | Verbessert die Benutzererfahrung |
| Passendes Szenario wählen | Niedrige Denktiefe für einfache Aufgaben | Steigerung der Gesamteffizienz |
Parameter thinking_level im Detail
Gemini 3 führt den Parameter thinking_level ein. Dies ist die entscheidende Konfiguration zur Steuerung der Antwortgeschwindigkeit:
| thinking_level | Anwendungsfall | Antwortgeschwindigkeit | Inferenzqualität |
|---|---|---|---|
| minimal | Einfache Dialoge, schnelle Antworten | Am schnellsten ⚡ | Basis |
| low | Alltägliche Aufgaben, leichte Inferenz | Schnell | Gut |
| medium | Aufgaben mittlerer Komplexität | Mittel | Besser |
| high | Komplexe Inferenz, Tiefenanalyse | Langsam | Bestmöglich |
🎯 Technischer Hinweis: Wenn Ihre Aufgabe keine extrem hohe Genauigkeit erfordert, aber eine schnelle Antwort benötigt, wird empfohlen,
thinking_levelaufminimaloderlowzu setzen. Wir empfehlen, verschiedenethinking_levelüber die APIYI (apiyi.com) Plattform einem Vergleichstest zu unterziehen, um schnell die für Ihr Geschäftsszenario am besten geeignete Konfiguration zu finden.
Konfigurationsstrategie für den Parameter max_tokens
Die Begrenzung von max_tokens kann die Ausgabelänge effektiv kontrollieren und dadurch die Antwortzeit verkürzen:
Anzahl der Output-Token → Direkter Einfluss auf die Generierungszeit
Höhere Token-Anzahl → Längere Antwortzeit
Empfehlungen zur Konfiguration:
- Szenarien mit kurzen Antworten:
max_tokensauf 500–1000 setzen. - Generierung mittlerer Inhalte:
max_tokensauf 2000–4000 setzen. - Vollständige Inhaltsausgabe: Je nach tatsächlichem Bedarf festlegen, dabei jedoch das Timeout-Risiko beachten.
⚠️ Hinweis: Ein zu niedrig angesetzter Wert für max_tokens führt dazu, dass die Ausgabe abgeschnitten wird, was die Vollständigkeit der Antwort beeinträchtigt. Es gilt, die Balance zwischen Geschwindigkeit und Vollständigkeit basierend auf den geschäftlichen Anforderungen zu finden.
Schnelleinstieg in die Geschwindigkeitsoptimierung von Gemini 3 Flash Preview
Minimalistisches Beispiel
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # 使用 APIYI 统一接口
)
# 速度优先配置
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": "简单介绍一下人工智能"}],
max_tokens=1000, # 限制输出长度
extra_body={
"thinking_level": "minimal" # 最小思考深度,最快响应
},
timeout=30 # 设置 30 秒超时
)
print(response.choices[0].message.content)
Vollständigen Code anzeigen – enthält verschiedene Konfigurationsszenarien
import openai
from typing import Literal
def create_gemini_client(api_key: str):
"""创建 Gemini 3 Flash 客户端"""
return openai.OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # 使用 APIYI 统一接口
)
def call_gemini_optimized(
client: openai.OpenAI,
prompt: str,
thinking_level: Literal["minimal", "low", "medium", "high"] = "low",
max_tokens: int = 2000,
timeout: int = 60,
stream: bool = False
):
"""
优化配置的 Gemini 3 Flash 调用
参数:
client: OpenAI 客户端
prompt: 用户输入
thinking_level: 思考深度 (minimal/low/medium/high)
max_tokens: 最大输出 Token 数
timeout: 超时时间(秒)
stream: 是否使用流式输出
"""
params = {
"model": "gemini-3-flash-preview",
"messages": [{"role": "user", "content": prompt}],
"max_tokens": max_tokens,
"stream": stream,
"extra_body": {
"thinking_level": thinking_level
},
"timeout": timeout
}
if stream:
# 流式输出 - 改善用户体验
response = client.chat.completions.create(**params)
full_content = ""
for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
print(content, end="", flush=True)
full_content += content
print() # 换行
return full_content
else:
# 非流式输出 - 一次性返回
response = client.chat.completions.create(**params)
return response.choices[0].message.content
# 使用示例
if __name__ == "__main__":
client = create_gemini_client("YOUR_API_KEY")
# 场景 1: 速度优先 - 简单问答
print("=== 速度优先配置 ===")
result = call_gemini_optimized(
client,
prompt="用一句话解释什么是机器学习",
thinking_level="minimal",
max_tokens=500,
timeout=15
)
print(f"回答: {result}\n")
# 场景 2: 平衡配置 - 日常任务
print("=== 平衡配置 ===")
result = call_gemini_optimized(
client,
prompt="列出 5 个 Python 数据处理的最佳实践",
thinking_level="low",
max_tokens=1500,
timeout=30
)
print(f"回答: {result}\n")
# 场景 3: 质量优先 - 复杂分析
print("=== 质量优先配置 ===")
result = call_gemini_optimized(
client,
prompt="分析 Transformer 架构的核心创新点及其对 NLP 的影响",
thinking_level="high",
max_tokens=4000,
timeout=120
)
print(f"回答: {result}\n")
# 场景 4: 流式输出 - 改善体验
print("=== 流式输出 ===")
result = call_gemini_optimized(
client,
prompt="介绍 Gemini 3 Flash 的主要特点",
thinking_level="low",
max_tokens=2000,
timeout=60,
stream=True
)
🚀 Schnellstart: Es wird empfohlen, die APIYI (apiyi.com) Plattform zu nutzen, um verschiedene Parameterkonfigurationen schnell zu testen. Die Plattform bietet sofort einsatzbereite API-Schnittstellen und unterstützt führende Modelle wie Gemini 3 Flash Preview, was die schnelle Validierung von Optimierungseffekten erleichtert.
Gemini 3 Flash Preview: Konfiguration der Parameter zur Optimierung der Reaktionszeit
timeout – Konfiguration der Zeitüberschreitung
Bei komplexen Schlussfolgerungen (Reasoning) mit Gemini 3 Flash Preview reicht der Standard-Timeout oft nicht aus. Hier ist eine empfohlene Strategie für die timeout-Konfiguration:
| Task-Typ | Empfohlener Timeout | Erläuterung |
|---|---|---|
| Einfache Fragen & Antworten | 15–30 Sek. | In Kombination mit minimal thinking_level |
| Alltagsaufgaben | 30–60 Sek. | In Kombination mit low/medium thinking_level |
| Komplexe Analysen | 60–120 Sek. | In Kombination mit high thinking_level |
| Lange Textgenerierung | 120–180 Sek. | Szenarien mit hoher Token-Ausgabemenge |
Wichtige Tipps:
- Im Nicht-Streaming-Modus (Non-Streaming) wird die Antwort erst zurückgegeben, wenn der gesamte Inhalt generiert wurde.
- Wenn der Timeout zu kurz gewählt ist, kann die Anfrage vorzeitig abgebrochen werden.
- Es wird empfohlen, den Wert dynamisch an die erwartete Token-Menge und das gewählte
thinking_levelanzupassen.
Migration von thinking_budget zum neuen thinking_level
Google empfiehlt den Umstieg vom alten Parameter thinking_budget auf das neue thinking_level:
| Altes thinking_budget | Neues thinking_level | Migrationshinweise |
|---|---|---|
| 0 | minimal | Minimales Denken; beachten Sie, dass Denksignaturen weiterhin verarbeitet werden müssen. |
| 1-1000 | low | Leichtes Denken |
| 1001-5000 | medium | Moderates Denken |
| 5001+ | high | Tiefgehendes Denken |
⚠️ Hinweis: Verwenden Sie thinking_budget und thinking_level niemals gleichzeitig in derselben Anfrage. Dies kann zu unvorhersehbarem Verhalten des Modells führen.
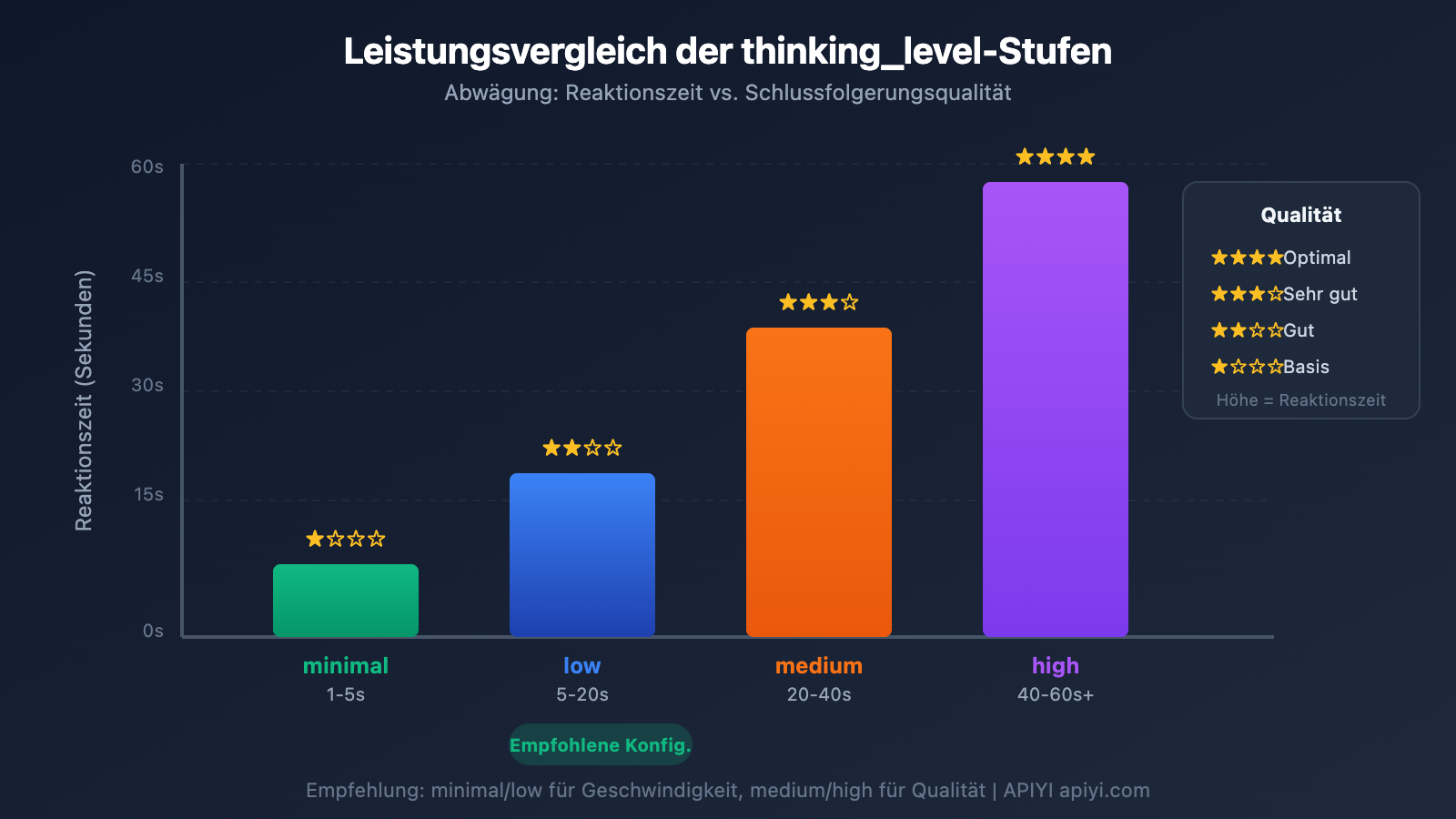
Gemini 3 Flash Preview Szenariobasierte Konfigurationslösungen zur Optimierung der Antwortgeschwindigkeit
Szenario 1: Hochfrequente einfache Aufgaben (Geschwindigkeit priorisiert)
Geeignet für Chatbots, schnelle Fragen und Antworten, Zusammenfassungen und andere latenzkritische Szenarien:
# Konfiguration: Geschwindigkeit zuerst
config_speed_first = {
"thinking_level": "minimal",
"max_tokens": 500,
"timeout": 15,
"stream": True # Streaming-Ausgabe verbessert die Nutzererfahrung
}
Erwartete Ergebnisse:
- Antwortzeit: 1–5 Sekunden
- Ideal für einfache Dialoge und schnelle Rückmeldungen
Szenario 2: Tägliche geschäftliche Aufgaben (Ausgewogene Konfiguration)
Geeignet für die Erstellung von Inhalten, Code-Unterstützung, Dokumentenverarbeitung und andere Standardaufgaben:
# Ausgewogene Konfiguration
config_balanced = {
"thinking_level": "low",
"max_tokens": 2000,
"timeout": 45,
"stream": True
}
Erwartete Ergebnisse:
- Antwortzeit: 5–20 Sekunden
- Gute Balance zwischen Qualität und Geschwindigkeit
Szenario 3: Komplexe Analyseaufgaben (Qualität priorisiert)
Geeignet für Datenanalysen, technisches Design, Tiefenforschung und andere Szenarien, die intensives logisches Denken erfordern:
# Konfiguration: Qualität zuerst
config_quality_first = {
"thinking_level": "high",
"max_tokens": 8000,
"timeout": 180,
"stream": True # Streaming wird für lange Aufgaben empfohlen
}
Erwartete Ergebnisse:
- Antwortzeit: 30–120 Sekunden
- Beste Reasoning-Qualität
Konfigurations-Entscheidungstabelle
| Ihre Anforderungen | Empfohlenes thinking_level | Empfohlenes max_tokens | Empfohlener timeout |
|---|---|---|---|
| Schnelle Antwort, einfache Frage | minimal | 500-1000 | 15-30s |
| Tägliche Aufgaben, normale Qualität | low | 1500-2500 | 30-60s |
| Gute Qualität, Wartezeit akzeptabel | medium | 2500-4000 | 60-90s |
| Beste Qualität, komplexe Aufgabe | high | 4000-8000 | 120-180s |
💡 Empfehlung zur Auswahl: Welche Konfiguration Sie wählen, hängt primär von Ihrem spezifischen Anwendungsfall und Ihren Qualitätsanforderungen ab. Wir empfehlen, praktische Tests über die Plattform APIYI (apiyi.com) durchzuführen, um die für Sie am besten geeignete Option zu finden. Die Plattform unterstützt den Zugriff auf Gemini 3 Flash Preview über eine einheitliche Schnittstelle, was den schnellen Vergleich verschiedener Konfigurationen erleichtert.
Gemini 3 Flash Preview: Fortgeschrittene Techniken zur Optimierung der Antwortgeschwindigkeit
Technik 1: Streaming-Ausgabe zur Verbesserung der Benutzererfahrung
Auch wenn sich die Gesamtantwortzeit nicht ändert, kann die Streaming-Ausgabe die wahrgenommene Wartezeit für den Benutzer erheblich verkürzen:
# Beispiel für Streaming-Ausgabe
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": prompt}],
stream=True,
extra_body={"thinking_level": "low"}
)
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
Vorteile:
- Benutzer sehen sofort erste Ergebnisse
- Reduziert den "Wartezeiten-Frust"
- Entscheidung über Fortsetzung bereits während der Generierung möglich
Technik 2: Dynamische Parameteranpassung basierend auf der Eingabekomplexität
def estimate_complexity(prompt: str) -> str:
"""Schätzt die Aufgabenkomplexität basierend auf Prompt-Merkmalen"""
indicators = {
"high": ["analysieren", "vergleichen", "warum", "prinzip", "vertiefend", "detailliert erklären"],
"medium": ["wie", "schritte", "methode", "vorstellen"],
"low": ["was ist", "einfach", "schnell", "ein satz"]
}
prompt_lower = prompt.lower()
for level, keywords in indicators.items():
if any(kw in prompt_lower for kw in keywords):
return level
return "low" # Standardmäßig niedrige Komplexität
def get_optimized_config(prompt: str) -> dict:
"""Ruft die optimierte Konfiguration basierend auf dem Prompt ab"""
complexity = estimate_complexity(prompt)
configs = {
"low": {"thinking_level": "minimal", "max_tokens": 1000, "timeout": 20},
"medium": {"thinking_level": "low", "max_tokens": 2500, "timeout": 45},
"high": {"thinking_level": "medium", "max_tokens": 4000, "timeout": 90}
}
return configs.get(complexity, configs["low"])
Technik 3: Implementierung eines Retry-Mechanismus
Bei gelegentlichen Timeout-Problemen kann ein intelligenter Retry-Mechanismus helfen:
import time
from typing import Optional
def call_with_retry(
client,
prompt: str,
max_retries: int = 3,
initial_timeout: int = 30
) -> Optional[str]:
"""Aufruf mit Retry-Mechanismus"""
for attempt in range(max_retries):
try:
timeout = initial_timeout * (attempt + 1) # Inkrementeller Timeout
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": prompt}],
max_tokens=2000,
timeout=timeout,
extra_body={"thinking_level": "low"}
)
return response.choices[0].message.content
except Exception as e:
print(f"Versuch {attempt + 1} fehlgeschlagen: {e}")
if attempt < max_retries - 1:
time.sleep(2 ** attempt) # Exponentielles Backoff
continue
return None
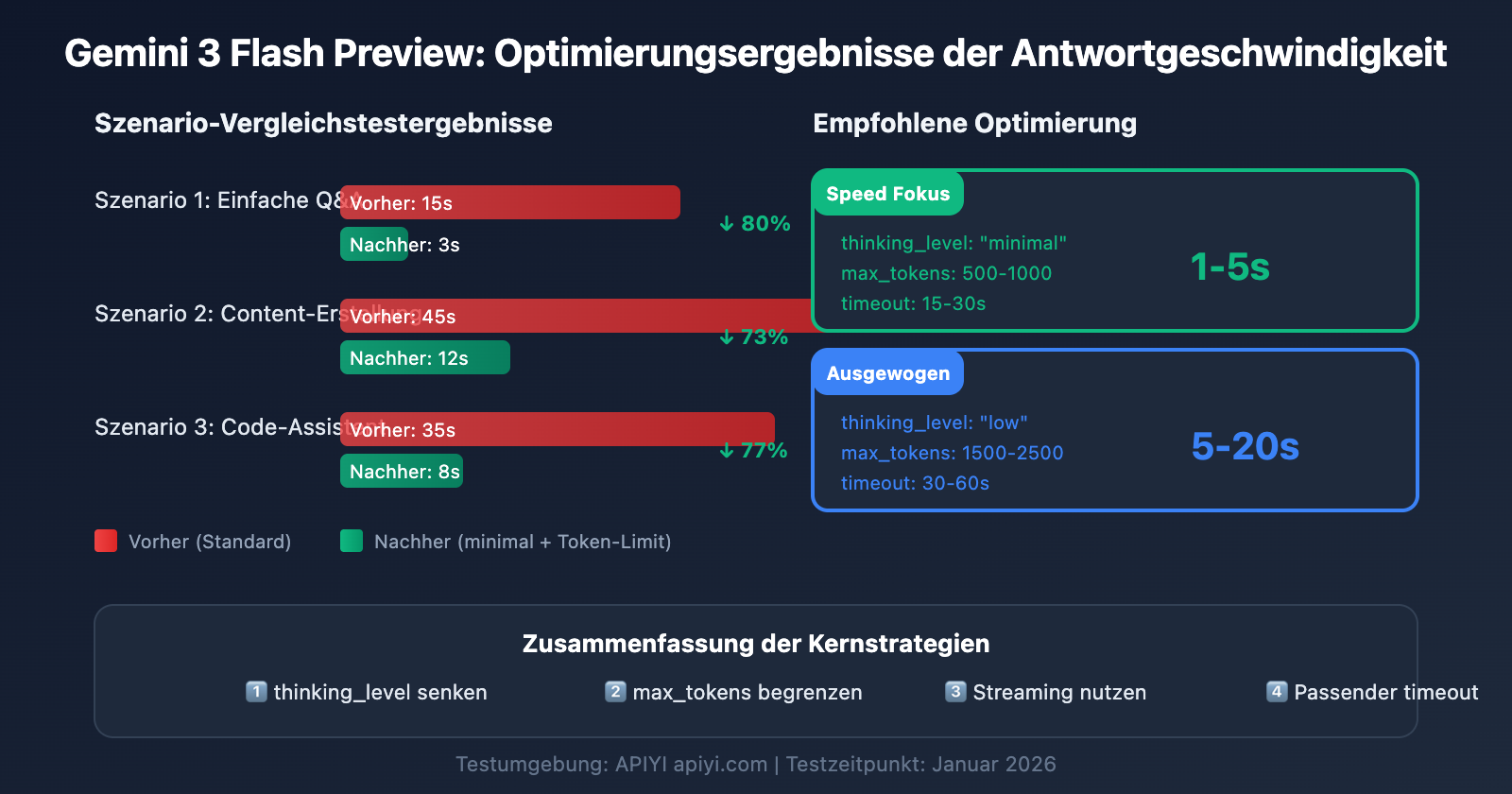
Referenzdaten zur Performance von Gemini 3 Flash Preview
Basierend auf den Testdaten von Artificial Analysis stellt sich die Performance von Gemini 3 Flash Preview wie folgt dar:
| Performance-Metrik | Wert | Beschreibung |
|---|---|---|
| Rohdurchsatz | 218 Tokens/Sek. | Ausgabegeschwindigkeit |
| Vergleich zu 2.5 Flash | 22 % langsamer | Aufgrund der erweiterten Reasoning-Fähigkeiten |
| Vergleich zu GPT-5.1 high | 74 % schneller | 125 Tokens/Sek. |
| Vergleich zu DeepSeek V3.2 | 627 % schneller | 30 Tokens/Sek. |
| Eingabepreis | 0,50 $/1 Mio. Tokens | |
| Ausgabepreis | 3,00 $/1 Mio. Tokens |
Balance zwischen Performance und Kosten
| Konfiguration | Antwortgeschwindigkeit | Token-Verbrauch | Kosteneffizienz |
|---|---|---|---|
| minimal thinking | Am schnellsten | Am niedrigsten | Am höchsten |
| low thinking | Schnell | Niedriger | Hoch |
| medium thinking | Mittel | Mittel | Mittel |
| high thinking | Langsam | Höher | Wahl für maximale Qualität |
💰 Kostenoptimierung: Für budgetsensitive Projekte empfiehlt es sich, die Gemini 3 Flash Preview API über die Plattform APIYI (apiyi.com) aufzurufen. Diese Plattform bietet flexible Abrechnungsmodelle. In Kombination mit den in diesem Artikel beschriebenen Techniken zur Geschwindigkeitsoptimierung lässt sich so das beste Preis-Leistungs-Verhältnis bei voller Kostenkontrolle erzielen.
Häufig gestellte Fragen (FAQ) zur Optimierung der Antwortgeschwindigkeit von Gemini 3 Flash Preview
Q1: Warum ist die Antwort trotz max_tokens-Limit immer noch langsam?
max_tokens begrenzt lediglich die Länge der Ausgabe, beeinflusst jedoch nicht den Denkprozess des Modells. Wenn die langsame Reaktion primär auf eine lange Bedenkzeit zurückzuführen ist, müssen Sie zusätzlich den Parameter thinking_level auf minimal oder low setzen. Zudem können Sie über die Plattform APIYI (apiyi.com) einen stabilen API-Service beziehen, der in Verbindung mit den hier vorgestellten Konfigurationstipps die Antwortgeschwindigkeit effektiv verbessert.
Q2: Beeinträchtigt ein minimales thinking_level die Antwortqualität?
Es gibt gewisse Auswirkungen, die jedoch bei einfachen Aufgaben kaum ins Gewicht fallen. Die Stufe minimal eignet sich hervorragend für schnelle Q&A-Runden oder einfache Dialoge. Wenn die Aufgabe komplexe logische Schlussfolgerungen erfordert, empfehlen wir die Stufen low oder medium. Wir raten dazu, A/B-Tests über die Plattform APIYI (apiyi.com) durchzuführen, um die Ausgabequalität bei verschiedenen thinking_level-Einstellungen zu vergleichen und den optimalen Balancepunkt für Ihren spezifischen Anwendungsfall zu finden.
Q3: Was ist schneller: Streaming-Ausgabe oder Nicht-Streaming?
Die gesamte Generierungszeit ist identisch, aber die Benutzererfahrung bei der Streaming-Ausgabe ist deutlich besser. Im Streaming-Modus sieht der Nutzer sofort Teilergebnisse, während er im Nicht-Streaming-Modus warten muss, bis die gesamte Antwort generiert wurde. Für Aufgaben mit längeren Generierungszeiten wird die Streaming-Ausgabe dringend empfohlen.
Q4: Wie bestimme ich die richtige Länge für das Timeout?
Das Timeout sollte basierend auf der erwarteten Ausgabelänge und dem gewählten thinking_level festgelegt werden:
- minimal + 1000 Tokens: 15–30 Sekunden
- low + 2000 Tokens: 30–60 Sekunden
- medium + 4000 Tokens: 60–90 Sekunden
- high + 8000 Tokens: 120–180 Sekunden
Wir empfehlen, zunächst mit einem großzügigen Timeout zu testen, die tatsächlichen Antwortzeiten zu messen und den Wert dann entsprechend anzupassen.
Q5: Kann der alte Parameter thinking_budget weiterhin verwendet werden?
Ja, er kann weiterhin genutzt werden. Google empfiehlt jedoch die Migration auf den Parameter thinking_level, um eine besser vorhersehbare Performance zu erzielen. Achten Sie darauf, nicht beide Parameter im selben Request zu verwenden. Falls Sie bisher thinking_budget=0 genutzt haben, sollten Sie bei der Migration thinking_level="minimal" wählen.
Fazit
Der Schlüssel zur Optimierung der Reaktionsgeschwindigkeit von Gemini 3 Flash Preview liegt in der korrekten Konfiguration von drei entscheidenden Parametern:
- thinking_level: Wählen Sie die passende Denktiefe basierend auf der Komplexität der Aufgabe.
- max_tokens: Begrenzen Sie die Anzahl der Tokens entsprechend der erwarteten Ausgabelänge.
- timeout: Setzen Sie ein angemessenes Zeitlimit basierend auf dem
thinking_levelund der Ausgabemenge.
Für Szenarien, in denen "die Antwortgeschwindigkeit Priorität hat und die Präzision weniger kritisch ist", wird folgende Konfiguration empfohlen:
- thinking_level:
minimaloderlow - max_tokens: Basierend auf dem tatsächlichen Bedarf einstellen, um unnötig lange Antworten zu vermeiden.
- timeout: Entsprechend anpassen, um vorzeitige Abbrüche zu verhindern.
- stream:
True(zur Verbesserung der Benutzererfahrung)
Wir empfehlen, verschiedene Parameterkombinationen schnell über APIYI (apiyi.com) zu testen, um die Konfiguration zu finden, die am besten zu Ihrem Business-Szenario passt.
Schlüsselwörter: Gemini 3 Flash Preview, Optimierung der Reaktionsgeschwindigkeit, thinking_level, max_tokens, timeout-Konfiguration, API-Aufruf-Optimierung
Referenzen:
- Offizielle Google AI Dokumentation: ai.google.dev/gemini-api/docs/gemini-3
- Google DeepMind: deepmind.google/models/gemini/flash/
- Artificial Analysis Performance-Tests: artificialanalysis.ai/articles/gemini-3-flash-everything-you-need-to-know
Dieser Artikel wurde vom technischen Team von APIYI erstellt. Weitere Tipps zur Nutzung von KI-Modellen finden Sie unter help.apiyi.com