
Als Google DeepMind am 20. November 2025 Nano Banana Pro veröffentlichte, betonten sie immer wieder: „untouched areas remain pixel-perfect — no generation drift, no quality loss across iterative edits“. Wenn man das wörtlich nimmt, bedeutet es, dass die KI eine „Photoshop-artige echte lokale Bearbeitung“ erreicht hat. Wer jedoch die Architektur von Gemini 3 Pro Image kennt, stellt fest, dass es sich im Kern um ein autoregressives Transformer-Modell handelt, das das gesamte Bild neu zeichnet – derselbe Mechanismus, mit dem Textmodelle das nächste Token vorhersagen.
Wie können diese beiden Aussagen gleichzeitig wahr sein? Zeichnet das Nano Banana Pro Bilderzeugungsprinzip das gesamte Bild neu oder führt es eine echte lokale Bearbeitung durch? Dieser Artikel analysiert das Prinzip tiefgreifend anhand der vier Ebenen: Gemini 3 Inferenz-Backbone, visuelle Token-Autoregressivität, Masken-Hard-Constraints und Bounding-Box-Semantik-Lokalisierung, um Ingenieuren ein echtes Verständnis der Funktionsweise zu vermitteln.
| Kernfrage | Intuitive Antwort | Wahrheit |
|---|---|---|
| Ist es eine lokale PS-Bearbeitung? | Ja | Nein, im Kern erfolgt weiterhin ein vollständiges Token-Neuzeichnen |
| Warum dann pixel-perfect? | Das Modell ist schlau | Drei harte Constraints: Maske + semantische Lokalisierung + BBox |
| Gleicher Ursprung wie GPT-Image-2? | Ähnlich | Beides autoregressiv, aber Gemini 3 hat explizite Inferenz |
| Driftet es bei mehrfacher Bearbeitung? | Ja | Fast gar nicht, das ist das Hauptverkaufsargument von Pro |
Wenn Sie diese zugrunde liegende Logik verstehen, können Sie Eingabeaufforderungen schreiben, die die Gemini 3-Inferenz wirklich aktivieren, Maskenmodi sinnvoll wählen und die Falle „sieht lokal aus, ist aber ein Neuzeichnen“ vermeiden. Wir empfehlen den Lesern, Nano Banana Pro über die APIYI-Plattform (apiyi.com) zu testen und jede Theorie mit der tatsächlichen Wirkung abzugleichen.
Nano Banana Pro Bilderzeugungsprinzip: Vollständiges Neuzeichnen oder echte lokale Bearbeitung?
Bevor wir diese Frage beantworten, müssen wir zwei leicht zu verwechselnde Dinge unterscheiden: den Generierungsmechanismus und die Nutzungserfahrung.
Vom Generierungsmechanismus her folgen Nano Banana Pro, sein Vorgänger Nano Banana und OpenAI GPT-Image-2 demselben Pfad: autoregressive Transformer-Bild-Token-Neugenerierung. Mit anderen Worten: Selbst wenn Sie die KI nur bitten, die Farbe einer Krawatte zu ändern, muss das Modell intern das gesamte Bild in visuelle Token komprimieren, dann die gesamte Token-Sequenz von Anfang bis Ende neu vorhersagen und schließlich wieder in Pixel dekodieren. Es gibt keinen physikalischen Pfad, bei dem „nur ein kleiner Teil der Pixel bewegt wird, während der Rest unverändert bleibt“.
Aus Sicht der Nutzungserfahrung bietet Nano Banana Pro dem Benutzer jedoch das Gefühl einer „nahezu echten lokalen Bearbeitung“. Google gibt offiziell an: Im Maskenmodus oder bei semantischer Lokalisierung bleiben nicht bearbeitete Bereiche fast auf Pixelebene erhalten, ohne Generierungsdrift und ohne Qualitätsverlust bei mehrfacher Bearbeitung. Wie wird diese Erfahrung aus der zugrunde liegenden Architektur des „vollständigen Neuzeichnens“ herausgepresst?
Die Antwort lautet: Constraint Engineering. Google hat den autoregressiven Generierungsprozess mit drei Ebenen harter Constraints überlagert: Masken-Token-Sperrung, Bounding-Box-Bereichsdefinition und eine semantische „Beibehalten-Liste“ von Gemini 3. Diese drei Constraints veranlassen das Modell dazu, beim Neuzeichnen „aktiv zu wählen“, die Token der nicht bearbeiteten Bereiche des Originalbildes zu reproduzieren. Das ist die wahre Ingenieursleistung des Nano Banana Pro-Teams.
Zusammenhang zwischen Neuzeichnungslogik und lokaler Bearbeitungserfahrung
| Perspektive | Tatsächliche Situation | Nutzererfahrung |
|---|---|---|
| Architektur | Vollständiges Token-Neuzeichnen | Sieht aus wie lokale Bearbeitung |
| Nicht bearbeitete Bereiche | Neu generierte Token | Fast identisch mit Originalpixeln |
| Bearbeitungsgrenzen | Autoregressive, kontinuierliche Generierung | Natürlicher Übergang ohne Artefakte |
| Bearbeitungsbefehle | Übermittlung durch Constraints | Automatische Anpassung von Licht/Perspektive |
Wenn Sie diese Trennung von „Mechanismus und Erfahrung“ verstehen, können Sie erklären, warum sich bei Nano Banana Pro nach der Bearbeitung die nicht bearbeiteten Bereiche manchmal minimal verändern – das ist der notwendige Preis für das Token-Neuzeichnen. Google hat diese Veränderung durch Constraints jedoch so weit unterdrückt, dass sie für das menschliche Auge fast unmerklich ist. Wir empfehlen, Nano Banana Pro auf APIYI (apiyi.com) zu nutzen, um dasselbe Bild wiederholt zu bearbeiten und die Drift-Amplitude zu beobachten; dieser Vergleich macht das theoretische Verständnis greifbar.
Das Funktionsprinzip von Nano Banana Pro: Das autoregressive Rückgrat von Gemini 3 Pro Image
Um das Funktionsprinzip von Nano Banana Pro zu verstehen, kommt man an seinem offiziellen Namen nicht vorbei: Gemini 3 Pro Image. Dieser Name offenbart seine zwei zentralen Abstammungslinien: das Gemini 3-Inferenz-Rückgrat und den Bilderzeugungs-Decoder.
Gemini 3 ist das multimodale Flaggschiff-Sprachmodell, das Google nur zwei Tage vor der Veröffentlichung von Nano Banana Pro vorgestellt hat und das für seine „Schlussfolgerungsfähigkeit“ bekannt ist. Nano Banana Pro verwendet direkt das Transformer-Rückgrat von Gemini 3 Pro, hat lediglich visuelle Token in das Vokabular aufgenommen und am Ausgang einen Bild-Decoder angeschlossen. Mit anderen Worten: Es ist kein eigenständiges Bildmodell, sondern eine spezielle Ausprägung der multimodalen Gemini 3-Familie, die auf die Bilderzeugung spezialisiert ist.
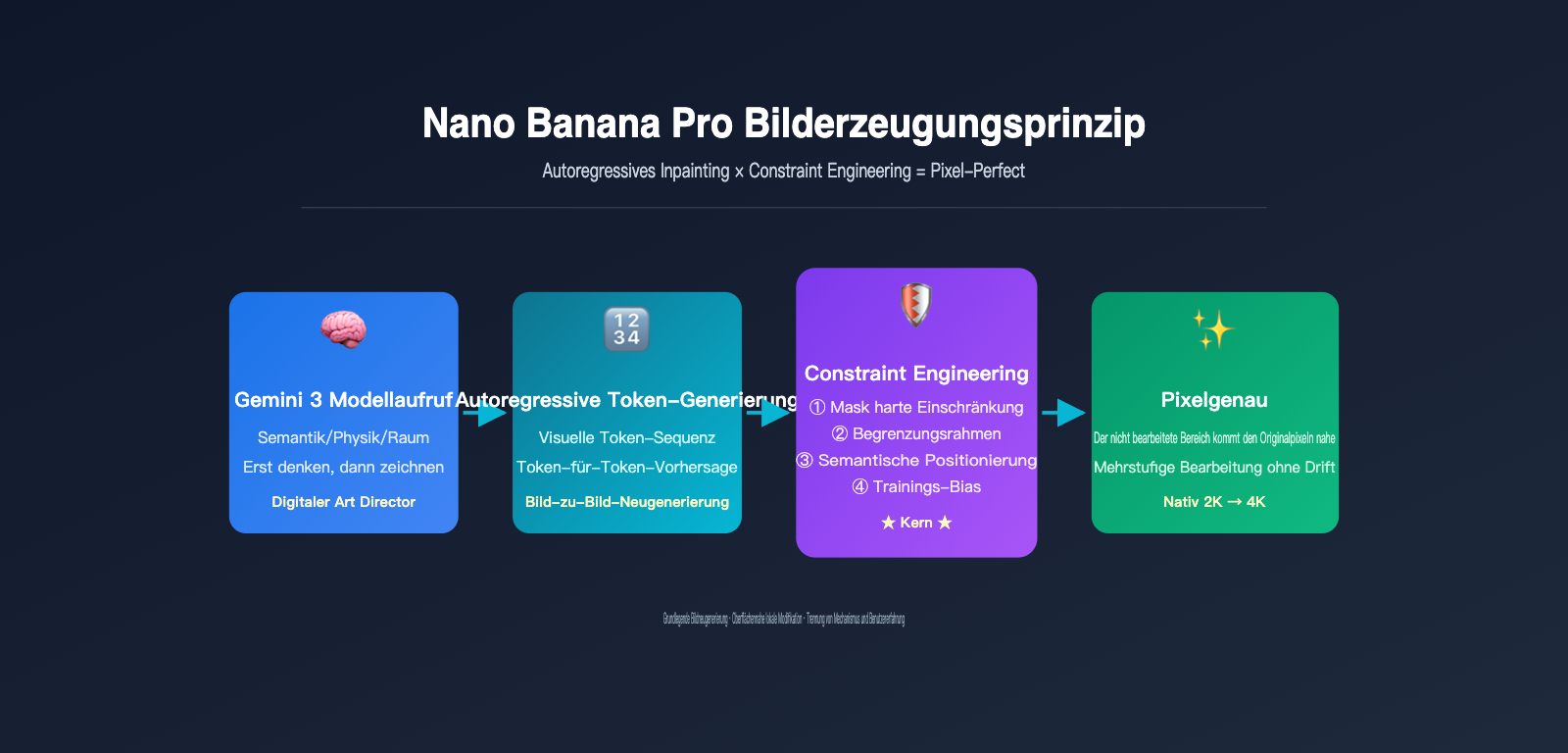
Dies führt zu einer grundlegenden Veränderung: Bevor Nano Banana Pro den ersten Pixel zeichnet, nutzt es Gemini 3, um zu schlussfolgern, „was gezeichnet werden soll“. Google beschreibt es offiziell so: „Es fungiert weniger wie ein traditionelles Diffusionsmodell und mehr wie ein digitaler Art Director“ – es analysiert zuerst die semantische Logik, die physikalischen Kausalitäten und die räumlichen Beziehungen der Eingabeaufforderung, bevor es in die Phase der visuellen Token-Generierung übergeht.
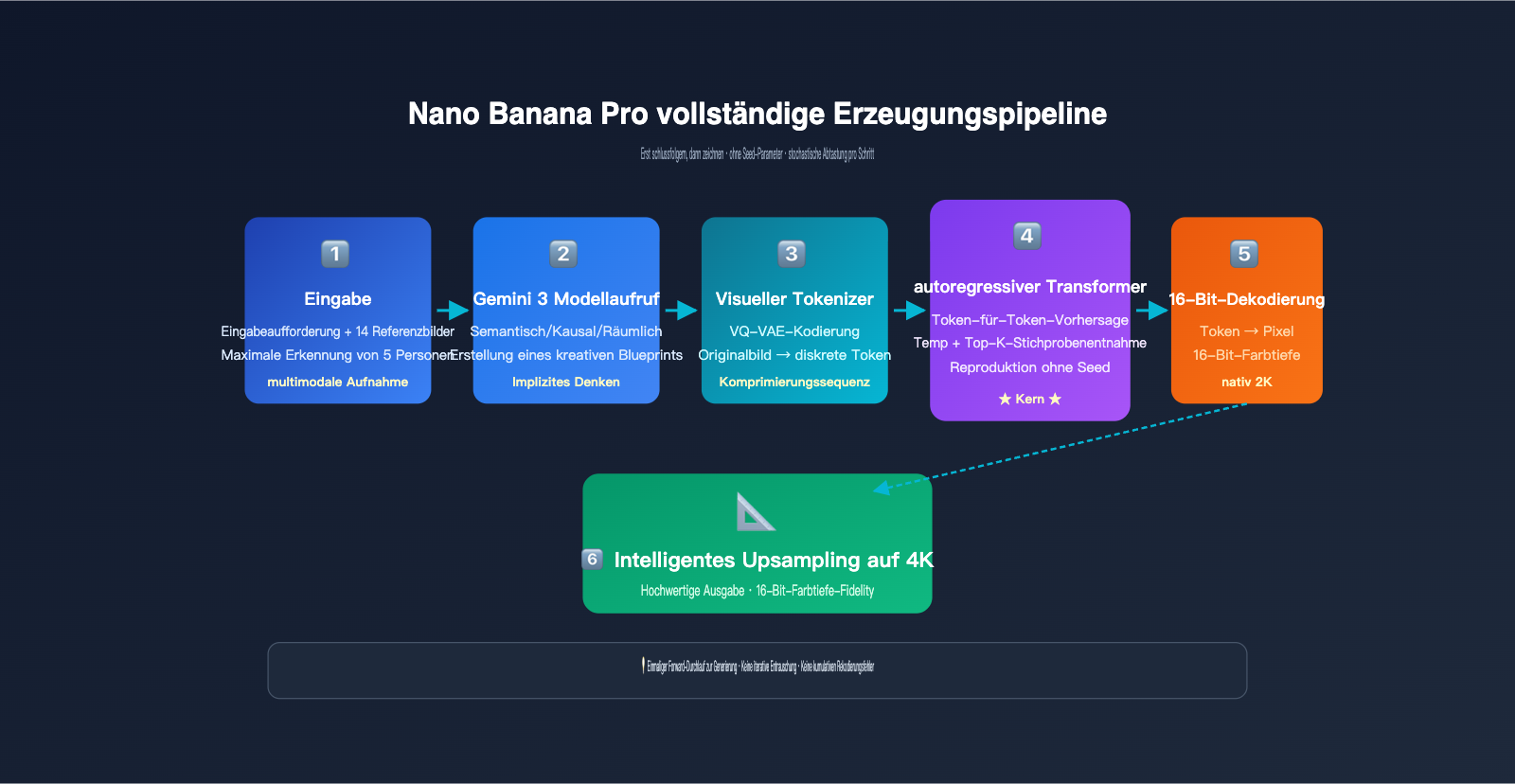
Der konkrete Arbeitsablauf lässt sich in fünf Phasen unterteilen:
- Multimodale Eingabeanalyse: Das Gemini 3-Inferenz-Rückgrat nimmt gleichzeitig die Texteingabeaufforderung des Benutzers und bis zu 14 Referenzbilder auf, um den gesamten Aufgabenkontext zu verstehen.
- Strukturierte Inferenz (interner Entwurf): Das Modell „überlegt“ sich intern zuerst die räumliche Anordnung des Bildes, die Identität der Personen, die Beleuchtungseinstellungen sowie die Teile, die beibehalten oder geändert werden sollen, und erstellt einen unsichtbaren „Gestaltungsentwurf“.
- Kodierung der visuellen Token des Originalbildes: Referenzbilder werden durch einen Diskretisierungsmechanismus, ähnlich wie bei VQ-VAE, in eine Sequenz visueller Token komprimiert.
- Autoregressive Token-Vorhersage: Unter dem Aufmerksamkeitsmechanismus des Gemini 3-Rückgrats sagt das Modell von links nach rechts nacheinander jedes visuelle Token des Ausgabebildes voraus, wobei es bei jedem Schritt sowohl die vollständigen Prompt-Token als auch die Originalbild-Token „sehen“ kann.
- Dekodierung und Upsampling: Die Ausgabe-Token werden durch einen 16-Bit-Farbtiefen-Decoder in ein natives 2K-Bild zurückverwandelt und anschließend intelligent auf 4K hochskaliert.
Die zwei einzigartigen Fähigkeiten des Gemini 3-Inferenz-Rückgrats
Die erste ist „Erst denken, dann zeichnen“. Das ist kein bloßer Werbeslogan – die Inferenzfähigkeit von Gemini 3 bei Textaufgaben überträgt sich direkt auf die Bilderzeugung. Gibt man ihm eine komplexe Anweisung wie „Ändere die Kleidung dieser Person so, dass sie ihrem beruflichen Status entspricht“, wären herkömmliche Bildmodelle überfordert. Nano Banana Pro schlussfolgert jedoch zuerst: „Diese Person sieht aus wie ein Arzt → es sollte ein weißer Kittel sein“, und beginnt erst dann mit dem Zeichnen.
Die zweite ist Grounding mit Google Search. Nano Banana Pro kann während des Generierungsprozesses Google-Suchwerkzeuge aufrufen, um Fakten zu überprüfen – etwa wenn man es auffordert, ein „Produkt, das kürzlich von einer bestimmten Marke veröffentlicht wurde“ zu zeichnen; es kann online nach echten Referenzen für das Aussehen suchen. Dies ist das derzeit einzige Bilderzeugungsmodell, das natives Such-Grounding unterstützt, und eine der größten Differenzierungsmerkmale zwischen Nano Banana Pro und GPT-Image-2. Wenn Sie die Grounding-Fähigkeiten in einer Produktionsumgebung testen möchten, können Sie Nano Banana Pro über APIYI (apiyi.com) einbinden; die Plattform bietet eine Schnittstellenspezifikation, die mit der offiziellen von Google identisch ist.
Erwähnenswert ist, dass Nano Banana Pro keine Seed-Parameter unterstützt. Da es sich um eine autoregressive Generierung handelt, wird bei jedem Abtastschritt aus der Wahrscheinlichkeitsverteilung gewählt (gesteuert durch Temperatur und Top-K), anders als bei Diffusionsmodellen, bei denen das Ergebnis durch ein festes Anfangsrauschen exakt reproduziert werden kann. Diese Eigenschaft ist sowohl eine Einschränkung als auch eine bewusste Designentscheidung, um die Kreativität des Modells zu bewahren.
Die 4 Kontrollmechanismen für KI-Bildbearbeitung: Wie Pixel-Perfect erreicht wird
Da das zugrunde liegende Verfahren eine vollständige Bildneugenerierung ist, stellt sich die Frage: Wie garantiert Nano Banana Pro, dass nicht bearbeitete Bereiche nahezu pixelgenau erhalten bleiben? Die Antwort liegt in vier Kontrollmechanismen, die Google für die KI-Bildbearbeitung implementiert hat. Dies ist die entscheidende technische Innovation der Pro-Version gegenüber dem Basismodell Nano Banana.
Erste Ebene: Masken-Hard-Constraint. Dies ist der direkteste Weg: Der Benutzer stellt eine Schwarz-Weiß-Maske in der gleichen Größe bereit. Weiße Bereiche erlauben der KI die Generierung neuer Token, während schwarze Bereiche das Modell zwingen, die Token des Originalbildes exakt zu kopieren. Dies entspricht einer "Hard-Copy-Regel" während der autoregressiven Generierung. Dies ist die technologische Basis für das, was Google als "pixel-perfect untouched areas" bezeichnet.
Zweite Ebene: Bounding-Box-Lokalisierung. Nano Banana Pro unterstützt Bounding-Box-Parameter mit Koordinaten, die auf einen Bereich von 0–1000 normalisiert sind. Sie können dem Modell mitteilen: "Ändere nur den Bereich innerhalb des Rechtecks von (200, 300) bis (600, 500)". Das System wandelt die Bounding Box automatisch in eine interne Maskenbeschränkung um, was komfortabler ist als das manuelle Zeichnen einer Maske.
Dritte Ebene: Semantische Lokalisierung durch Gemini 3. Dies ist die "magischste" Ebene. Sie müssen lediglich in natürlicher Sprache sagen: "Ändere den Hintergrund in einen Strand". Das Gemini 3-Modell erkennt automatisch, welche Token im Bild den "Hintergrund" repräsentieren, und generiert eine implizite Maske. Dieser maskenfreie Bearbeitungsmodus deckt laut Google "die meisten Bearbeitungsszenarien" ab.
Vierte Ebene: Trainings-Bias "Nicht erwähnt bedeutet beibehalten". Google hat riesige Mengen an "Originalbild-zu-bearbeitetem-Bild"-Paaren verwendet, um dem Modell eine implizite Regel beizubringen: Sofern der Prompt nicht explizit eine Änderung fordert, sollen andere Bereiche Token für Token aus dem Originalbild kopiert werden. Dieser Bias ist fest in den Gewichten verankert und wird bei der Inferenz automatisch angewendet.
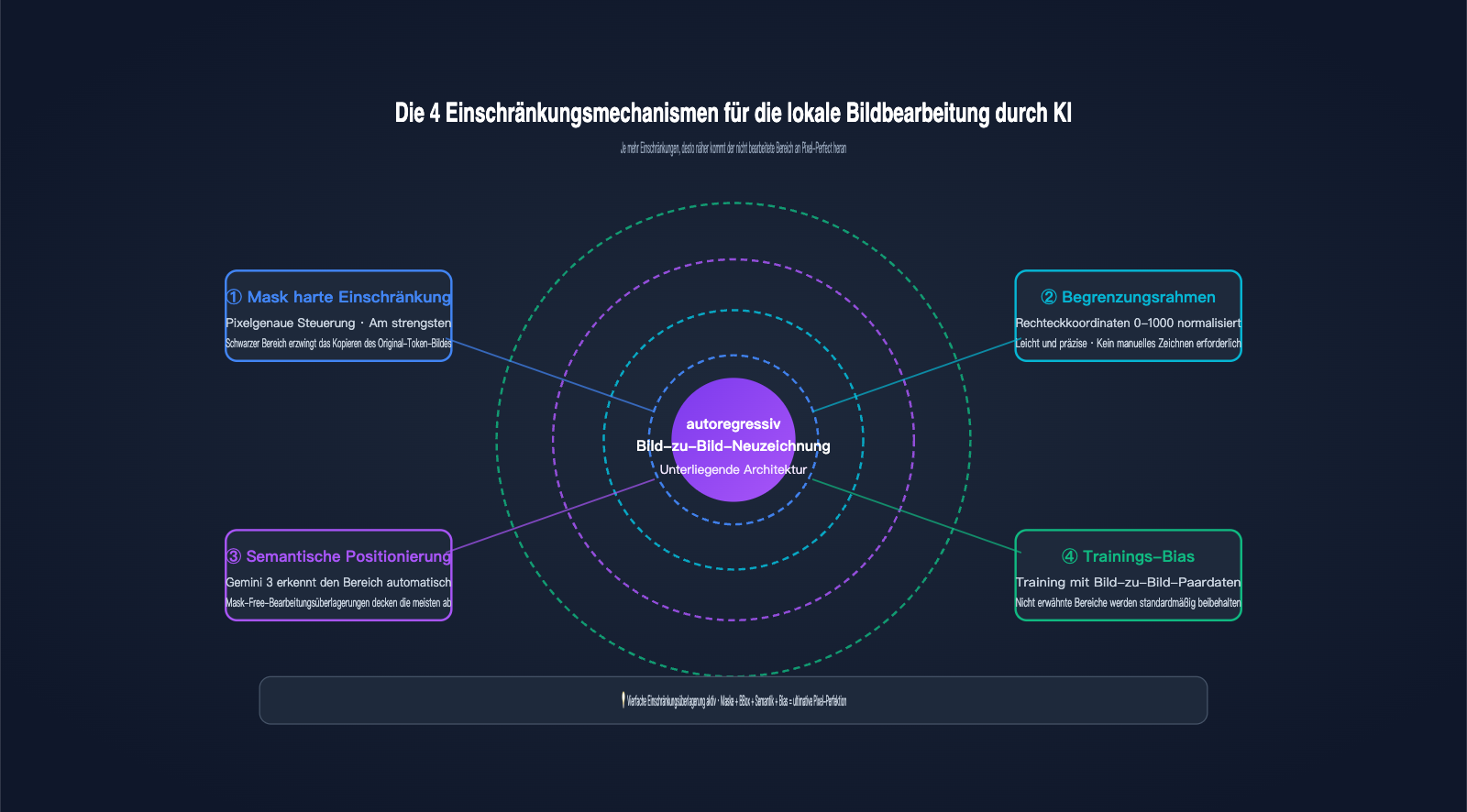
Vergleich der 4 Kontrollmechanismen
| Kontrollmechanismus | Kontrollgranularität | Benutzeraufwand | Anwendungsfall |
|---|---|---|---|
| Masken-Hard-Constraint | Pixelebene | Maske erforderlich | Präzise Reparatur/Objektaustausch |
| Bounding Box | Rechteckbereich | Nur Koordinaten | Bearbeitung bekannter rechteckiger Bereiche |
| Semantische Lokalisierung | Semantisches Objekt | Nur Texteingabe | Die meisten alltäglichen Bearbeitungen |
| Trainings-Bias | Global | Keine Konfiguration | Standardmäßig in allen Szenarien aktiv |
Die vier Ebenen schließen sich nicht gegenseitig aus, sondern wirken kumulativ. Die strengste Kombination ist "Maske + Bounding Box + semantische Anweisung", was die Pixel-Perfect-Erfahrung von Nano Banana Pro auf die Spitze treibt. Unsere Tests bei APIYI (apiyi.com) haben gezeigt, dass selbst bei der alleinigen Nutzung von semantischer Lokalisierung und Trainings-Bias die meisten alltäglichen Bearbeitungen eine Konsistenz erreichen, die für das menschliche Auge kaum von der Vorlage zu unterscheiden ist.
Technische Gründe für die Stabilität bei mehrfacher Bearbeitung
Einer der Marketing-Schwerpunkte von Nano Banana Pro ist die "kumulationsfreie Qualität bei mehrfacher Bearbeitung". Dies hat zwei Gründe: Erstens benötigt die autoregressive Architektur im Gegensatz zu Diffusionsmodellen keine wiederholte VAE-Kodierung/Dekodierung. Es findet nur eine Token-zu-Pixel-Konvertierung statt, wodurch keine Rekodierungsfehler akkumuliert werden. Zweitens sorgt die Masken-Hard-Constraint dafür, dass nicht bearbeitete Bereiche Token für Token aus dem Original kopiert werden, was selbst bei mehreren Iterationen kaum neue Zufälligkeit einführt.
Dies steht in krassem Gegensatz zu herkömmlichem Stable Diffusion, bei dem wiederholtes Inpainting oft zu Qualitätsverlusten führt. Wenn Ihr Workflow 5–10 Iterationen auf demselben Basisbild erfordert, ist Nano Banana Pro derzeit nahezu das einzige Modell, das diese Anforderung stabil bewältigen kann.
Gemini 3 Pro Image vs. GPT-Image-2: Differenzierung der beiden Ansätze
Viele Teams beobachten derzeit sowohl Gemini 3 Pro Image (Nano Banana Pro) als auch GPT-Image-2 von OpenAI. Obwohl beide auf autoregressiven Modellen basieren, setzen sie unterschiedliche Schwerpunkte in Bezug auf Positionierung und Fähigkeiten.
GPT-Image-2 legt den Fokus auf den „Thinking-Modus“ und eine hohe Genauigkeit bei der Textwiedergabe (offiziell ca. 99 %) und eignet sich hervorragend für Layouts mit mehreren Objekten und Szenarien mit viel Text. Nano Banana Pro hingegen setzt auf das Gemini 3-Inferenz-Backbone, 4K-Ausgabe, die Fusion von bis zu 14 Bildern, die Gesichtskonsistenz für 5 Personen sowie die exklusive „Grounding with Google Search“-Funktion.

Die wesentlichen Unterschiede zwischen dem Nano Banana Pro Bilderzeugungsprinzip und dem Implementierungspfad von GPT-Image-2 lassen sich in dieser Tabelle zusammenfassen:
| Dimension | Nano Banana Pro | GPT-Image-2 |
|---|---|---|
| Basismodell | Gemini 3 Pro | GPT-4o multimodal |
| Inferenz-Erweiterung | Implizite Gemini 3-Inferenz | Expliziter Thinking-Modus |
| Max. Auflösung | 4K (Upsampling von 2K) | 4K nativ |
| Limit für Bild-Eingabe | 14 Bilder | Mehrere (Limit nicht öffentlich) |
| Gesichtskonsistenz | Bis zu 5 Personen gleichzeitig | Stark, Limit nicht öffentlich |
| Textwiedergabe | Branchenführend, mehrsprachig | 99 % Genauigkeit |
| Echtzeit-Informationen | ✅ Google Search Grounding | ❌ |
| Seed-Parameter | ❌ Nicht unterstützt | Teilweise steuerbar |
| Stärke bei lokaler Bearbeitung | Pixelgenau in nicht bearbeiteten Bereichen | Mehrstufig ohne Drift |
| Preis pro Bild | 2K $0,139 / 4K $0,24 | Hochwertig 1024 $0,211 |
Empfehlung zur Modellauswahl: Achten Sie vor allem auf zwei Punkte: Wenn Sie Markenmaterial, Produktbilder oder Szenarien mit mehreren Charakteren erstellen müssen, sind die Bildfusion und die Gesichtskonsistenz von Nano Banana Pro besser geeignet. Wenn Ihr Kernszenario hingegen lange Textplakate, komplexe Layouts oder die Anordnung von über 100 Objekten umfasst, ist der Thinking-Modus von GPT-Image-2 möglicherweise stabiler. Wir empfehlen, beide Modelle über die APIYI-Plattform (apiyi.com) anzubinden und auf Basis Ihrer tatsächlichen Szenarien kleine A/B-Tests durchzuführen, bevor Sie sich für ein Hauptmodell entscheiden.
Nano Banana Pro API in der Praxis: Vom Mask- bis zum Bounding-Box-Szenario
Nachdem wir die Prinzipien verstanden haben, schauen wir uns an, wie man die KI-Bildbearbeitungsfunktionen von Nano Banana Pro in der Praxis einsetzt. Hier ist ein minimal ausführbares Python-Beispiel, das Gemini 3 Pro Image über den APIYI-kompatiblen Endpunkt aufruft:
from google import genai
from PIL import Image
client = genai.Client(
api_key="your-apiyi-key",
http_options={"base_url": "https://vip.apiyi.com/v1"}
)
original = Image.open("portrait.png")
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=[
"Behalte die Identität der Person und den Hintergrund bei, tausche lediglich das weiße T-Shirt gegen ein dunkelblaues Sakko aus und behalte die ursprüngliche Licht- und Schattenrichtung bei.",
original
]
)
for part in response.candidates[0].content.parts:
if part.inline_data:
with open("edited.png", "wb") as f:
f.write(part.inline_data.data)
Beachten Sie die Formulierung der Eingabeaufforderung: Geben Sie explizit an, „was beibehalten werden soll“, „was geändert werden soll“ und „dass die ursprüngliche Beleuchtung beibehalten werden soll“. Dies aktiviert direkt die semantische Lokalisierungsfähigkeit des Gemini 3-Inferenz-Backbones. Wenn eine präzisere Bereichssteuerung erforderlich ist, können Sie eine Bounding-Box-Eingabeaufforderung hinzufügen:
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=[
"Ersetze im Bereich der Bounding Box [200, 150, 600, 700] die Kleidung durch ein dunkelblaues Sakko. Alle anderen Bereiche sollen pixelgenau beibehalten werden.",
original
]
)
Die Koordinaten verwenden einen normalisierten Bereich von 0–1000, der bei der tatsächlichen Verarbeitung auf die Bildgröße abgebildet wird. Für eine noch strengere Kontrolle kann ein Maskenbild als zusätzliche Eingabe hinzugefügt werden.
5 Tipps für die praktische Optimierung
Basierend auf dem Nano Banana Pro-Implementierungsprinzip haben wir 5 Empfehlungen für die technische Umsetzung zusammengefasst:
- Geben Sie in der Eingabeaufforderung immer eine Beibehaltungsliste an: „Identität der Person, Hintergrund und Beleuchtung beibehalten“ ist der Schlüssel zur Aktivierung der vierstufigen Einschränkungen.
- Bevorzugen Sie semantische Lokalisierung: Sofern die Bearbeitungsgrenzen keine pixelgenaue Präzision erfordern, ist der maskenfreie Modus effizienter.
- Bildfusion auf maximal 14 Bilder begrenzen: Ein Überschreiten des offiziellen Limits führt zum Abschneiden und beeinträchtigt die Konsistenz.
- Wahl zwischen 2K und 4K je nach Verwendungszweck: Für Web- oder Mobilanzeigen reicht 2K ($0,139) aus; für Druck oder Großbildschirme sollten Sie 4K ($0,24) verwenden.
- Versuchen Sie nicht, Ergebnisse mit Seeds zu reproduzieren: Nano Banana Pro unterstützt keine Seeds. Für eine stabile Reproduktion sollten Sie stattdessen mit Gewichtungen in der Eingabeaufforderung und Referenzbildern arbeiten.
Preisgestaltung und Szenario-Abgleich
| Konfiguration | Kosten pro Bild | Empfohlenes Szenario |
|---|---|---|
| 2K Einzelbild | $0,139 | Social Media / Web-Bilder |
| 4K Einzelbild | $0,24 | Druck / Großbildschirme / Marketing-Visuals |
| 4K + 14-Bild-Fusion | $0,24 + Eingabe-Token | Marken-Szenarien mit mehreren Charakteren |
| 4K + Grounding | $0,24 + Such-Token | Echte Produkt- / Ereignisbilder |
Wir empfehlen, für Batch-Aufgaben in der Produktionsumgebung die Batch-API von APIYI (apiyi.com) zu verwenden. Dies senkt die Kosten bei gleichbleibender Qualität erheblich und eignet sich ideal für die massenhafte Erstellung von Materialbibliotheken.
Nano Banana Pro FAQ zur Bilderzeugung und Entscheidungshilfen
F1: Ist Nano Banana Pro eher ein Zeichenwerkzeug oder ein Tool für lokale Bearbeitungen?
A: Die zugrunde liegende Technologie ist das „autoregressive Token-Neuzeichnen des gesamten Bildes“, also „Zeichnen“. Durch vier Ebenen von Einschränkungen – Masken-Hard-Constraints, Bounding Boxes, semantische Lokalisierung durch Gemini 3 und Trainings-Bias – wird jedoch ein Nutzungserlebnis erreicht, das einer „echten lokalen Bearbeitung“ sehr nahekommt. Beides widerspricht sich nicht: Die Architektur basiert auf dem Neuzeichnen, das Engineering sorgt für die Fixierung.
F2: Warum behauptet der Hersteller, dass nicht bearbeitete Bereiche „pixel-perfect“ sind?
A: Im Masken-Modus werden die Ausgabetoken für die schwarzen Bereiche gezwungen, den Token an den entsprechenden Positionen des Originalbildes zu entsprechen, wodurch die Pixel nach der Dekodierung nahezu identisch sind. Streng genommen gibt es durch die VQ-VAE-Kodierung/Dekodierung minimale Verluste, daher ist es „nahezu“ pixelgenau und nicht mathematisch exakt identisch. Im täglichen Gebrauch ist dies für das menschliche Auge jedoch nicht wahrnehmbar.
F3: Warum unterstützt Nano Banana Pro keinen Seed?
A: Die autoregressive Generierung tastet bei jedem Schritt aus einer Wahrscheinlichkeitsverteilung ab, was sich grundlegend vom Mechanismus der Diffusionsmodelle unterscheidet, bei denen das anfängliche Rauschen fixiert wird. Google hat sich entschieden, den Seed-Parameter nicht offenzulegen, um die kreative Vielfalt des Modells zu erhalten. Wenn Sie Ergebnisse stabil reproduzieren müssen, verwenden Sie bitte eine Kombination aus detaillierter Eingabeaufforderung und Referenzbild. Wir empfehlen, auf APIYI (apiyi.com) die Stabilität der Ausgaben mit verschiedenen Vorlagen für Eingabeaufforderungen zu testen, um eine „nahezu deterministische“ Kombination für Ihren Workflow zu finden.
F4: Wie entscheide ich mich zwischen Nano Banana Pro und GPT-Image-2?
A: Szenarien mit mehreren Charakteren, Markenmaterialien oder Bedarf an Echtzeitinformationen (Grounding) → wählen Sie Nano Banana Pro. Komplexe Layouts, Poster mit viel Text oder Layouts mit über 100 Objekten → wählen Sie GPT-Image-2. Beide basieren auf autoregressiven Modellen; die Unterschiede in der Erfahrung ergeben sich hauptsächlich aus den verschiedenen Ansätzen von Google und OpenAI beim Constraint-Engineering.
F5: Kann ich den Bearbeitungsbereich ohne Maske präzise lokalisieren?
A: Ja, das ist auf zwei Arten möglich. Erstens über den Bounding-Box-Parameter (normalisierte Koordinaten von 0-1000); zweitens durch die semantische Lokalisierung des Gemini 3-Inferenz-Backbones. Sie müssen in der Eingabeaufforderung lediglich sagen: „Ändere das rote Objekt unten rechts im Bild.“ Letzteres deckt die meisten Szenarien ab, während Ersteres für klar definierte rechteckige Bereiche verwendet wird.
F6: Wie nutzt man „Grounding with Google Search“ in der Praxis?
A: Geben Sie in der Eingabeaufforderung explizit Elemente an, die faktisch überprüft werden müssen, wie z. B. „Erstelle ein Bild des neuesten Tesla Cybertruck von 2025 auf der Mondoberfläche“. Das Modell ruft automatisch die Google-Suche auf, um Referenzen für das reale Aussehen zu erhalten, bevor es mit der Generierung beginnt. Dies ist eine exklusive Funktion von Nano Banana Pro; GPT-Image-2 bietet derzeit keine vergleichbare Funktion.
Fazit: Das Verständnis von Constraint-Engineering ist der Schlüssel zu Nano Banana Pro
Nano Banana Pro ist ein technisch äußerst ausgeklügeltes Produkt. Es erfindet das Paradigma der Bilderzeugung nicht neu, sondern nutzt das autoregressive Gemini 3-Backbone und verpackt die Architektur des „Neuzeichnens des gesamten Bildes“ durch vier Ebenen von Constraint-Engineering (Masken-Hard-Constraints, Bounding Boxes, semantische Lokalisierung und Trainings-Bias) in ein Nutzererlebnis, das einer „echten lokalen Bearbeitung“ nahekommt.
Nur wenn man diese Trennung zwischen „Mechanismus und Erlebnis“ versteht, kann man präzise Eingabeaufforderungen schreiben, die diese vier Ebenen aktivieren, die Bearbeitungsmodi sinnvoll wählen und Workflows mit mehreren Iterationen planen. Der Kern der Bilderzeugungsprinzipien von Nano Banana Pro ist keine „Black Magic“, sondern das vollständige Zusammenspiel von Constraint-Engineering.
Wir empfehlen, praktische Tests und Vergleiche über die Plattform APIYI (apiyi.com) durchzuführen. Diese Plattform unterstützt einheitliche Schnittstellenaufrufe für verschiedene gängige Modelle wie Nano Banana Pro, GPT-Image-2 und Stable Diffusion. Dies erleichtert die schnelle Validierung der in diesem Artikel genannten Prinzipien und Optimierungstechniken, um die optimale Wahl für Ihre Produktionsszenarien zu treffen.
Dieser Artikel wurde vom APIYI-Team verfasst und basiert auf offiziellen Informationen von Google DeepMind, Vertex AI sowie eigenen Praxistests. Wenn Sie Gemini 3 Pro Image (Nano Banana Pro) in einer Produktionsumgebung nutzen möchten, besuchen Sie die offizielle Website von APIYI unter apiyi.com, um die Dokumentation zur Anbindung zu erhalten.