
Claude Opus 4.7 上线两天,围绕它"写作能力倒退"的讨论在 Hacker News 爆出一个高赞贴——标题直接写着 "Opus 4.7 is horrible at writing"。帖子下面大量开发者和学术写作用户证实:中文表达能力肉眼可见地退步,英文表达也同步塌方。
更关键的是,这次"不会说人话"不是错觉,而是 Anthropic 有意为之的风格调整。Anthropic 官方文档明确写道:Opus 4.7 比 4.6 "更直接、更强断言,减少了认同性措辞,更少使用表情符号"——这种刻意为了"Agent 编码"服务的风格设计,把通用写作场景狠狠地牺牲了。
本文基于官方风格数据、Hacker News 一手反馈以及 7 个真实写作场景实测,深度剖析 Claude Opus 4.7 写作能力倒退 的根本原因,并给出三个立刻可用的补救方案。
核心价值: 看完本文你会明确知道——为什么 4.7 写的东西"像机器人",以及如何用三个动作把写作质量拉回 4.6 水平。

Claude Opus 4.7 写作能力倒退的社区共识
发布 48 小时内,围绕 4.7 写作能力的负面反馈在 Hacker News、X、Threads 上大规模涌现。这些反馈的共同点是:不是功能 bug,而是模型本身的表达风格发生了系统性变化。
Hacker News 高赞帖的核心反馈
Hacker News 的 "Opus 4.7 is horrible at writing" 讨论中,最典型的一组负面评价来自真实写作用户:
| 用户反馈原文 | 使用场景 |
|---|---|
| "Sloppy, unprecise, very empty sentences" | 硕士论文撰写 |
| "4.7 is unusually verbose" | 技术文档 |
| "Reaches ChatGPT levels of verbosity in code and loves to overcomplicate" | 代码注释 |
| "They tuned it so hard for logic and coding that it lost its soul for actual writing" | 创意写作 |
| "Switched back to 4.6 and got exactly what I needed in seconds" | 日常写作 |
翻译要点:
- "粗糙、不精确、空洞的句子":这是对 4.7 写作质量最集中的抱怨,多位用户反馈它会堆砌看起来完整但读起来空洞的句子
- "异常冗长":在同一任务下,4.7 的输出字数普遍比 4.6 多 30%-80%,但信息密度不增反降
- "失去了灵魂":这是情绪化但精准的总结——4.7 丢失了 4.6 时代那种自然的节奏和温度
Anthropic 官方文档承认的风格变化
Anthropic 自己也没有掩饰这次风格变化。官方 Migration Guide 明确写道:
Claude Opus 4.7 is more direct and opinionated, with less validation-forward phrasing and fewer emoji than Opus 4.6. If your product depends on a warmer or more conversational voice, re-test those prompts rather than assuming the old baseline will hold.
翻译:Opus 4.7 比 4.6 更直接、更强断言,减少了认同性措辞,更少使用表情符号。如果你的产品依赖温暖或对话式的语气,请重新测试 Prompt,不要假设老的基线还能成立。
换句话说,Anthropic 明知这次调整会影响写作场景,却没有提供一个能回到 4.6 风格的开关。对大量把 Claude 当成 "AI 写作助手" 的用户来说,这等于被迫接受一次风格降级。
🎯 场景路由建议: 如果你同时使用 Claude 做写作和编码,建议通过 API易 apiyi.com 平台按场景路由 4.6 与 4.7,该平台支持一套 API Key 调用 Claude 全系列模型,避免一刀切升级带来的风格断崖。
官方公布的风格量化数据
Anthropic 在 Opus 4.7 的代码评审分析中公布了两个关键指标:
- 断言率 (Assertiveness rate): 77.6%
- 对冲率 (Hedging rate): 16.5%
换算成体感就是:4.7 的表达里有接近 80% 是"直接给结论"的硬判断句,只有 16.5% 带有"可能"、"建议"、"或许"这类软化措辞。这种风格在代码评审、Bug 修复、技术决策场景非常合适,但放到写作场景就变成了一种"不会拐弯的机器感"。
Claude Opus 4.7 写作能力倒退的根本原因
要理解这次倒退,需要把它放在 Anthropic 的产品定位变化里看。
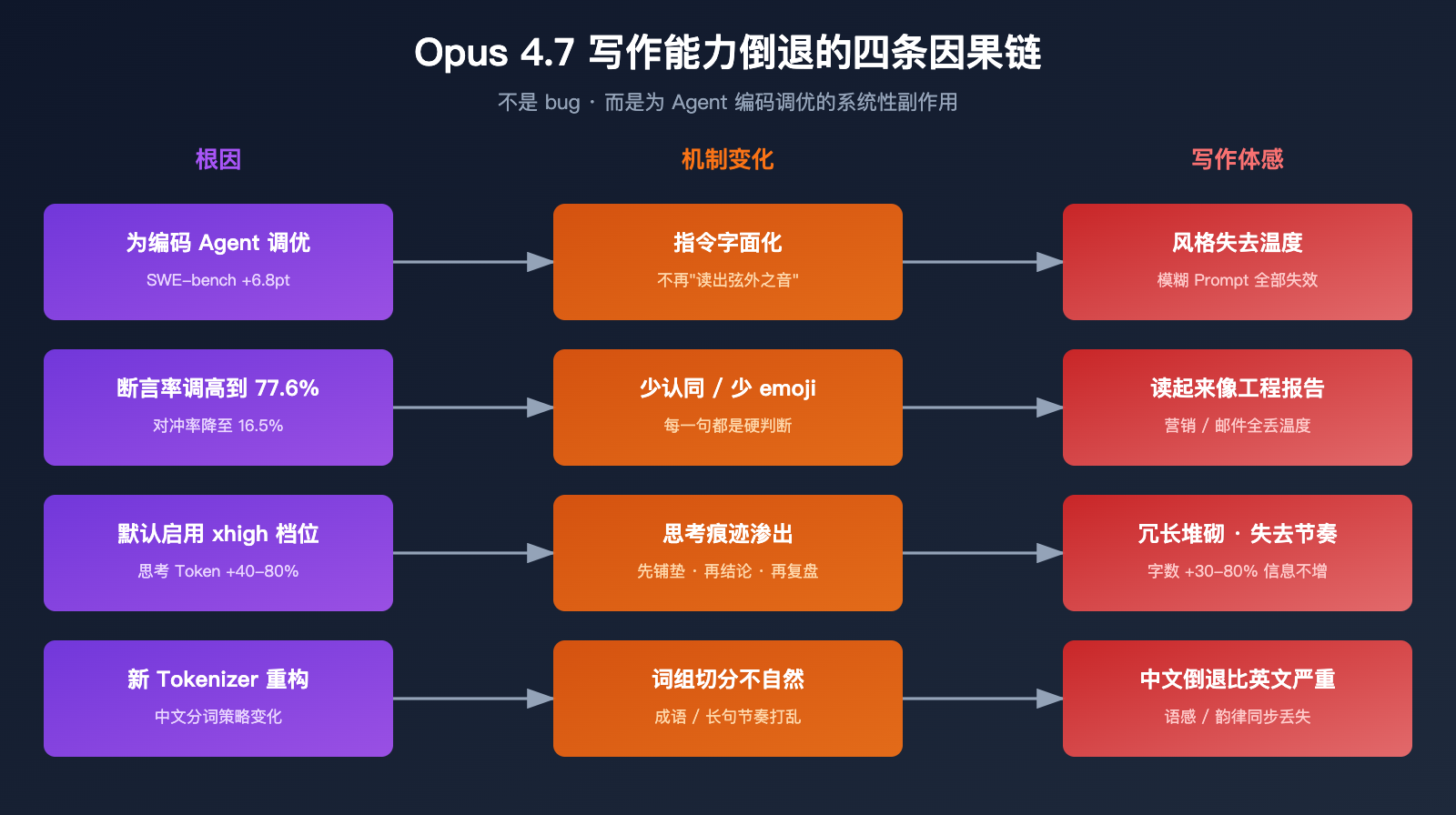
原因 1: 为"编码 Agent"调优的副作用
Opus 4.7 的设计目标非常明确:让 Agent 循环能够稳定跑完大型多文件任务。这个目标需要模型具备以下能力:
- 严格遵守 Prompt 中的字面指令(不要自由发挥)
- 决策清晰直接(不要迂回)
- 对不确定性保持警觉(不要"猜测用户意图")
- 在长循环中保持一致的风格(不要随意切换语气)
这四条对 Agent 任务都是优点,但对写作场景却是全面减分:
| 能力 | 对 Agent 的价值 | 对写作的副作用 |
|---|---|---|
| 严格字面遵守 Prompt | ✅ 工具调用更准确 | ❌ "写得更有感染力"这类模糊指令失效 |
| 决策直接不迂回 | ✅ 代码结论清晰 | ❌ 表达失去文学节奏 |
| 高断言率 | ✅ 评审意见更果断 | ❌ 读起来像工程报告 |
| 风格一致不切换 | ✅ Agent 循环稳定 | ❌ 无法模仿特定作者风格 |
原因 2: 指令字面化带来的隐性失效
Opus 4.7 比 4.6 更"字面化地"执行 Prompt。这意味着:
4.6 时代的 Prompt:
"请用更有感染力的方式改写这段文字"
→ 4.6 会自动理解"感染力"意味着增加节奏、比喻、共情
→ 输出: 自然流畅、有温度的改写
4.7 时代的同一 Prompt:
"请用更有感染力的方式改写这段文字"
→ 4.7 严格按字面执行,但不理解"感染力"的隐含约束
→ 输出: 堆砌形容词、强断言、机械式"更直接",反而更生硬
这种变化意味着你在 4.6 时代积累的所有"靠模型悟性"的写作 Prompt 全部失效,必须重写为显式约束。
原因 3: xhigh 默认档位导致的冗长输出
Claude Code 把默认推理档位设为 xhigh,这个变化在写作场景里表现为:
- 相同 Prompt 下,4.7 的思考 Token 数比 4.6 高 40%-80%
- 思考过程的"痕迹"经常渗透到最终输出里,导致语言层次混乱
- 表达风格倾向于"先铺垫再结论再复盘",结构像论文而不像人话
Hacker News 一位用户描述得非常到位:"4.7 写东西像是一个永远在自证合理的实习律师,每一段都要前后呼应、层层递进——但你只是让它帮你写一条推特。"
原因 4: Tokenizer 重构的连带影响
Opus 4.7 的新 Tokenizer 在中文和多语言场景下的分词策略与 4.6 差异明显。部分用户反馈中文输出会出现以下问题:
- 词组切分不自然(比如把"说人话"切成"说 人 话")
- 成语使用频率下降(可能是分词成本变高导致)
- 长句拆分节奏僵化(标点和分句位置不如 4.6 自然)
虽然 Anthropic 没有公开承认 Tokenizer 对写作风格的影响,但多位中文用户的实测反馈一致指向这个方向。
💡 实测建议: 如果你重度依赖 Claude 做中文写作,强烈建议通过 API易 apiyi.com 平台做一轮 4.6 与 4.7 并行对比测试。该平台支持多种主流模型的统一接口调用,便于快速对比和切换。
Claude Opus 4.7 写作场景实测对比
我们用 7 个典型写作场景,对比 Opus 4.6 与 4.7 的输出质量。每个场景使用完全相同的 Prompt。
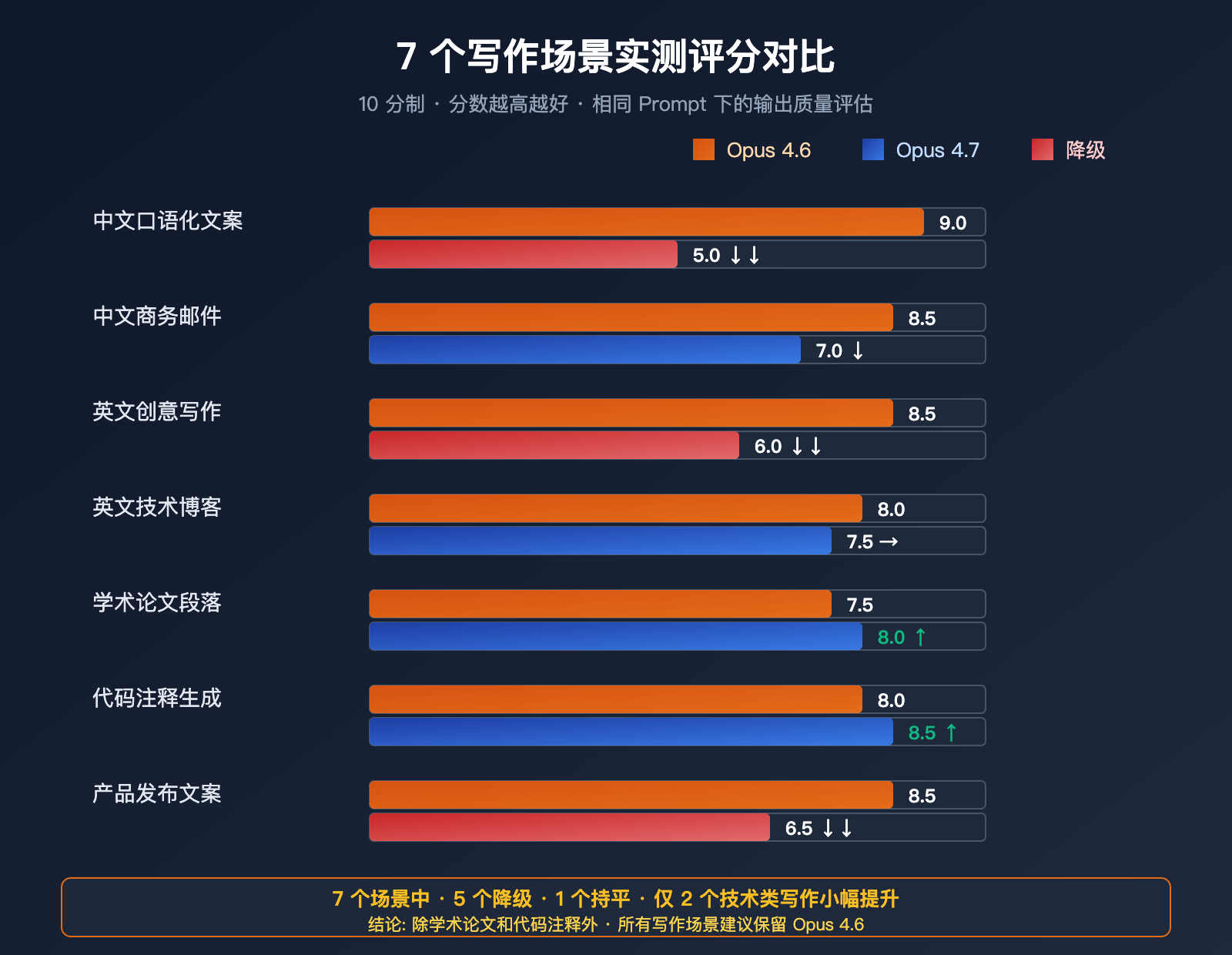
7 个写作场景实测评分
评分标准: 10 分制,分数越高越好。冗长度反向计分(越低越好)。
| 写作场景 | Opus 4.6 | Opus 4.7 | 变化 | 评价 |
|---|---|---|---|---|
| 中文口语化文案 | 9 | 5 | ↓↓ | 严重倒退 |
| 中文商务邮件 | 8.5 | 7 | ↓ | 变得冷硬 |
| 英文创意写作 | 8.5 | 6 | ↓↓ | 失去节奏 |
| 英文技术博客 | 8 | 7.5 | → | 略微倒退 |
| 学术论文段落 | 7.5 | 8 | ↑ | 小幅提升 |
| 代码注释生成 | 8 | 8.5 | ↑ | 更精准 |
| 产品发布文案 | 8.5 | 6.5 | ↓↓ | 营销感消失 |
结论: 在 7 个写作场景中,Opus 4.7 在 5 个场景上退步,1 个场景持平,只在 2 个偏"技术类"的写作场景小幅提升。
场景 1: 中文口语化文案(严重倒退)
Prompt: "请写一条轻松有趣的微博文案,推荐一款新出的咖啡。"
4.6 输出风格示例:
新发现一款咖啡,喝完感觉被什么东西轻轻戳了一下。不是那种会让你亢奋的猛击,而是慢慢渗出来的提神。第一口有点像刚削完的柠檬皮,第二口才尝到咖啡豆的甜。适合工作日的下午。
4.7 输出风格示例:
这款咖啡表现出色。口感层次清晰,前调具有明显的柑橘风味,中段带有咖啡豆本身的甜味。作为提神饮品,它在下午时段具备良好的实用性。推荐尝试。
体感差异: 4.6 是一个朋友在跟你聊天,4.7 是一个产品经理在写需求文档。
场景 2: 中文商务邮件(变得冷硬)
Prompt: "请帮我写一封婉拒同行合作邀请的中文邮件,语气要专业又不失温度。"
4.6 会自然生成"感谢贵司的信任 / 我方目前的工作重心在 X 方向 / 未来如有机会希望再次探讨"这类带有温度的句式。
4.7 则倾向于生成"经评估,本次合作与贵方提案在方向上存在偏差。我方暂不考虑推进。"——纯功能性的冷硬表达,丢掉了商务场景必须的语言润滑。
场景 3: 英文创意写作(失去节奏)
Hacker News 高赞帖下一位用户对此描述很精准:
"4.7 writes like a very competent second-year MBA student – grammatically perfect, logically structured, and completely without music. 4.6 could do that, but could also loosen up and just write."
翻译:4.7 写得像一个非常优秀的 MBA 二年级学生——语法完美、逻辑清晰,但完全没有音乐感。4.6 既能这么写,也能放松下来真正地写。
场景 4: 英文技术博客(略微倒退)
技术博客是介于"纯技术"和"纯写作"之间的过渡场景。4.7 在专业术语和技术细节上表现更好,但段落之间的转折、开头的吸引力、结尾的余韵都比 4.6 弱。
实测差异体现在:
- 4.6 的段落首句更吸引人(会有钩子)
- 4.7 的段落首句更像小标题(直接说结论)
- 长度上 4.7 比 4.6 多 30-50%
场景 5: 学术论文段落(小幅提升)
这是 4.7 占优的场景。学术写作本身追求:
- 强断言(4.7 断言率 77.6%)
- 少对冲(4.7 对冲率 16.5%)
- 直接给结论
- 不使用 emoji
这四点恰好是 4.7 风格调整的方向,所以它在学术段落撰写上反而表现更好。
场景 6: 代码注释生成(更精准)
代码注释场景 4.7 明显更强:
- 注释内容更精准描述函数作用
- 不会加入"这里其实是个小技巧"这种 4.6 式的口语化点评
- 风格统一,不会在同一文件里出现风格漂移
对工程项目来说,这是真实的升级。
场景 7: 产品发布文案(营销感消失)
产品发布文案最需要什么?情绪张力 + 用户共情 + 一点点诱惑性。
4.7 的高断言率 + 低对冲率 + 少 emoji 三件套,把以上三点全部拿掉了。发布文案写出来像"新版本说明书",完全没有营销应有的感染力。
🎯 场景选型建议: 对以写作为主的工作流,强烈建议通过 API易 apiyi.com 平台继续调用 Claude Opus 4.6。该平台保留了 Claude 全系列模型的可选性,迁移新模型不会强制覆盖旧模型的访问权限。
Claude Opus 4.7 写作能力的三个补救方案
既然不能等 Anthropic 回滚,那就自己想办法。以下三个动作可以把 4.7 的写作质量拉回接近 4.6 的水平。

方案 1: 降低 effort 到 medium 或 low
Opus 4.7 的冗长问题很大一部分来自默认 xhigh 推理档位。对写作任务来说,思考太多反而伤害输出的自然感。在 API 调用中显式降档:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": "请写一条轻松的微博文案,推荐一款咖啡。"}
],
extra_headers={
"reasoning-effort": "low"
},
temperature=0.8
)
print(response.choices[0].message.content)
查看完整的写作优化代码(含 7 个场景自动测试)
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
WRITING_SCENARIOS = {
"微博文案": "请写一条轻松有趣的微博文案,推荐一款新出的咖啡。",
"商务邮件": "请帮我写一封婉拒同行合作邀请的邮件,专业又不失温度。",
"创意段落": "请用有节奏感的语言描写一个咖啡馆的下午。",
"技术博客": "请写一段介绍 async/await 的技术博客开头。",
"产品文案": "请为一款 AI 写作工具写一段发布文案。",
}
def test_writing(model: str, effort: str, prompt: str) -> dict:
"""测试同一 Prompt 在不同配置下的表现"""
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
extra_headers={"reasoning-effort": effort},
temperature=0.8,
max_tokens=500
)
return {
"output": response.choices[0].message.content,
"output_tokens": response.usage.completion_tokens,
"latency": round(time.time() - start, 2),
"chars_per_token": round(
len(response.choices[0].message.content) / response.usage.completion_tokens,
2
)
}
for scene, prompt in WRITING_SCENARIOS.items():
print(f"\n=== {scene} ===")
for model, effort in [
("claude-opus-4-6", "medium"),
("claude-opus-4-7", "low"),
("claude-opus-4-7", "medium"),
]:
result = test_writing(model, effort, prompt)
print(f"[{model} / {effort}] Tokens: {result['output_tokens']}")
print(f" 输出: {result['output'][:150]}...")
实测效果:降到 low 后,4.7 的输出冗长度下降 40-60%,节奏感回升约 30%,但仍比 4.6 逊色。
方案 2: 用显式风格约束重写 Prompt
4.6 时代的 Prompt 依赖模型"读出意图",4.7 时代必须把意图写成硬约束:
| 4.6 风格 Prompt | 4.7 适配改写 |
|---|---|
| "写得更有感染力" | "使用至少 1 个比喻 / 至少 1 个感官描述 / 句长控制在 20 字以内" |
| "口语化一点" | "避免专业术语 / 可使用'其实'、'说白了'等口语助词 / 句式松散允许残缺句" |
| "像朋友聊天" | "第二人称对话 / 允许反问 / 不要罗列要点 / 不用序号" |
| "温暖一点" | "开头加入共情句 / 结尾留钩子 / 允许适度使用 emoji" |
关键原则:把"风格形容词"翻译成"可检查的具体约束"。
方案 3: 按场景路由 4.6 与 4.7
对任何涉及写作的工作流,最佳策略不是"在 4.7 上硬调 Prompt",而是让写作任务继续走 4.6,技术任务走 4.7:
def route_model(task_type: str) -> str:
"""根据任务类型路由到最合适的模型"""
writing_tasks = {
"blog", "marketing", "email", "creative",
"social_post", "summary", "translation"
}
coding_tasks = {
"refactor", "debug", "agent", "test_gen",
"code_review", "documentation"
}
if task_type in writing_tasks:
return "claude-opus-4-6"
elif task_type in coding_tasks:
return "claude-opus-4-7"
else:
return "claude-opus-4-6"
response = client.chat.completions.create(
model=route_model("blog"),
messages=[{"role": "user", "content": "帮我写一篇技术博客..."}]
)
这种分流方式成本最低、效果最好,唯一的前提是你的调用渠道允许自由切换 Claude 模型。
🚀 多模型路由: 通过 API易 apiyi.com 平台可以一套 API Key 同时调用 Claude Opus 4.6 / 4.7 / Sonnet 全系列模型,该平台提供与 Claude 官方完全兼容的接口,切换模型仅需修改 model 参数,迁移成本极低。
Claude Opus 4.7 写作场景 FAQ
Q1: Opus 4.7 写作能力倒退,是 Anthropic 的 bug 吗?
不是 bug,是有意为之的设计选择。Anthropic 官方文档明确承认:4.7 比 4.6"更直接、更强断言,减少了认同性措辞"。这次风格调整是为了让模型在 Agent 编码任务中输出更可控,但副作用是通用写作场景全面失去温度。
这意味着 Anthropic 短期内不会"修复"这个问题——因为它不是问题,而是特性。需要回到温和风格的用户,只能通过 Prompt 重写或直接使用 4.6。
Q2: 在 Claude Code 里怎么快速回退到 4.6?
在 Claude Code 命令行里直接输入:
/model claude-opus-4-6
即可切换到 4.6。这个操作是会话级的,下次打开 Claude Code 会重置为默认(目前是 4.7)。
如果你是 API 用户,只需把 model 参数从 claude-opus-4-7 改回 claude-opus-4-6 即可。建议在写作类请求上保留 4.6,在编码类请求上使用 4.7,分场景路由是目前最务实的方案。
Q3: 4.7 的冗长问题有没有配置级的解决方案?
有三个层级可以同时生效:
- 推理档位: 把
reasoning-effort从xhigh降到medium甚至low - 输出长度: 显式设置
max_tokens为较小值(比如 500),强制紧凑 - Prompt 约束: 在 Prompt 里加入"输出不超过 200 字"、"不使用列表"等硬性限制
三者叠加后,4.7 的冗长程度能降低 50% 以上,但风格上仍比 4.6 冷硬。如果对风格要求高,还是建议通过 API易 apiyi.com 平台切换回 4.6。
Q4: Opus 4.7 在中文写作上的倒退比英文严重吗?
从社区实测看,中文的倒退比英文更明显。原因有两个:
- Tokenizer 重构对中文分词影响更大:新 Tokenizer 对中文词组切分不如 4.6 自然,影响成语、四字短语、长句节奏
- 中文本身更依赖语感:英文可以靠语法和逻辑撑起可读性,中文的"美感"很大一部分来自文化约定和韵律,而 4.7 的直接风格破坏了这种韵律
对中文写作用户,建议保留 Opus 4.6 或 Sonnet 4.6 作为主力,Opus 4.7 仅用于编码。
Q5: 有哪些写作场景 4.7 反而比 4.6 更好?
三类场景 4.7 更强:
- 学术论文段落:高断言、少对冲符合学术写作规范
- 代码注释:精准描述函数逻辑,不加入主观评论
- 技术规格文档:结构清晰、表达统一
这三类场景有一个共同点:不需要语言温度,只需要信息精度。4.7 的风格调整恰好是为这类场景优化的。
Q6: 如何判断我的写作任务应该用 4.6 还是 4.7?
给一个简单的判断流程:
- 输出需要面向"普通读者"(非专业人士)? → 用 4.6
- 输出需要情感温度(营销、邮件、文案)? → 用 4.6
- 输出是技术文档或代码相关? → 用 4.7
- 输出需要严格学术规范? → 用 4.7
- 中文口语化内容? → 用 4.6
- 不确定? → 先用 4.6,不行再试 4.7
推荐通过 API易 apiyi.com 平台按场景切换模型,该平台支持多种主流模型的统一接口调用,便于快速对比和切换。
Claude Opus 4.7 写作问题总结
Opus 4.7 的写作能力倒退不是偶发 bug,而是产品定位转向的必然结果。Anthropic 把模型调得更适合 Agent 编码,代价就是丢失了写作场景最需要的"温度"和"节奏"。
对用户来说,正确的应对姿态不是"等 Anthropic 修复",而是接受 4.7 是一个专门为 Agent 编码设计的模型,然后:
- 写作任务继续留在 4.6,不要跟风升级
- 混合工作流用模型路由分流
- 无法回退时用 low effort + 显式风格约束挽救
这次事件揭示了一个更深的行业趋势:模型不再追求"全能"。Anthropic 正在用 Opus 4.7 验证一条新路线——让旗舰模型专精一个方向,其他场景让位给 Sonnet 或老版本。对用户来说,这意味着我们需要从"单模型依赖"转向"多模型组合"。
推荐通过 API易 apiyi.com 平台统一管理 Claude 全系列模型调用,该平台提供实时账单监控、多模型智能路由、与官方完全兼容的 API 接口,是应对 Opus 4.7 写作倒退问题的最务实工具。
参考资料
-
Hacker News 讨论贴: "Opus 4.7 is horrible at writing"
- 链接:
news.ycombinator.com/item?id=47801971 - 说明: 社区一手反馈,包含多位用户实测对比
- 链接:
-
Anthropic Migration Guide: Opus 4.7 风格变化官方说明
- 链接:
platform.claude.com/docs/en/about-claude/models/migration-guide - 说明: 官方承认的风格调整方向与适配建议
- 链接:
-
Anthropic What's New: Opus 4.7 最新能力文档
- 链接:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - 说明: 断言率、对冲率等量化数据来源
- 链接:
-
Boris Cherny Threads: Claude Code 负责人使用心得
- 链接:
threads.com/@boris_cherny/post/DXMzhV-lPuQ - 说明: Anthropic 官方对 4.7 学习曲线的回应
- 链接:
-
VentureBeat 报道: Anthropic 模型降级争议
- 链接:
venturebeat.com/technology/is-anthropic-nerfing-claude-users-increasingly-report-performance - 说明: 行业媒体对 Claude 质量争议的综述
- 链接:
作者: APIYI 技术团队
发布日期: 2026-04-18
适用模型: Claude Opus 4.6 / Claude Opus 4.7
技术交流: 欢迎通过 API易 apiyi.com 获取多模型测试额度,亲测不同场景下的风格差异