
"为什么我的 Claude Code 每次请求都有 40 万输入 Token?账单怎么这么高?"——这是很多 Claude Code 用户在查看用量统计时的第一反应。实际上,这 40 万 Token 中的绝大部分可能已经被缓存命中,真实成本可能只有表面数字的 1/10。但如果缓存没命中,那账单确实会让人心疼。
核心价值: 读完本文,你将理解 Claude Code 的自动缓存机制、导致缓存失效的 8 种常见原因,以及 6 个将输入 Token 从 40 万降到 5 万的实战技巧。

Claude Code 的 Prompt Caching 自动缓存机制详解
Claude Code 会自动命中缓存吗?
会的。 Claude Code 在每次 API 请求中都会自动启用 Anthropic 的 Prompt Caching,无需任何配置。这是内置行为,不是可选功能。
每次你在 Claude Code 中发送一条消息,实际发送给 API 的内容按以下顺序组装:
| 组装顺序 | 内容 | 大小估算 | 缓存行为 |
|---|---|---|---|
| 第 1 层 | Tool 定义(Read/Edit/Bash 等) | ~5,000 Token | 几乎不变,高命中率 |
| 第 2 层 | 系统提示 + CLAUDE.md | ~3,000-10,000 Token | 会话内不变,高命中率 |
| 第 3 层 | 对话历史(所有之前的消息) | 持续增长 | 前缀匹配,逐步累积缓存 |
| 第 4 层 | 当前新消息 | 可变 | 永远不会命中缓存 |
关键机制: 缓存是基于前缀匹配的——只要请求的前 N 个 Token 与之前缓存的内容完全一致,这 N 个 Token 就会命中缓存。在一个持续对话中,到第 20 轮时,95%+ 的输入 Token 通常来自缓存命中。
缓存价格:为什么缓存命中如此重要
| 操作类型 | 相对基础输入价格 | Sonnet 4 实际价格/MTok | Opus 4 实际价格/MTok |
|---|---|---|---|
| 普通输入(无缓存) | 1x | $3.00 | $15.00 |
| 5分钟缓存写入 | 1.25x | $3.75 | $18.75 |
| 1小时缓存写入 | 2x | $6.00 | $30.00 |
| 缓存命中/读取 | 0.1x | $0.30 | $1.50 |
| 输出 | — | $15.00 | $75.00 |
举个具体例子:如果你的请求有 40 万输入 Token:
场景 A:完全无缓存
├── 40万 Token × $3/MTok (Sonnet) = $1.20 每次请求
场景 B:95% 缓存命中(典型 Claude Code 会话)
├── 缓存命中 38万 Token × $0.30/MTok = $0.114
├── 缓存写入 1万 Token × $3.75/MTok = $0.0375
├── 新输入 1万 Token × $3/MTok = $0.03
├── 合计 = $0.18 每次请求
└── 实际成本仅为无缓存的 15%
🎯 技术提示: 通过 API易 apiyi.com 调用 Claude API 同样支持 Prompt Caching 机制,
缓存命中时输入成本降低 90%。如果你的项目通过 API 集成 Claude,
建议合理设计 Prompt 结构以最大化缓存命中率。
缓存 TTL:Max 用户的隐藏福利
| 订阅方案 | 缓存 TTL | 写入成本 | 说明 |
|---|---|---|---|
| API 按量付费 | 5 分钟 | 1.25x | 超过 5 分钟不操作,缓存过期 |
| Pro / Team | 5 分钟 | 1.25x | 同上 |
| Max 5x / 20x | 1 小时 | 2x | 写入贵但命中窗口大 12 倍 |
Max 用户虽然缓存写入价格是 2x(比标准的 1.25x 高),但 1 小时 TTL 意味着你去喝杯咖啡回来缓存还在。对于间歇性使用的开发者,这个差异非常显著。
每次缓存命中都会重置 TTL 计时器,所以只要你保持活跃使用,缓存基本不会过期。
缓存没命中?8 种常见原因及解决方案

缓存失效的根本原因只有一个:请求的前缀与缓存内容不匹配。具体到 Claude Code 中,以下 8 种情况会导致缓存失效:
第一类:TTL 过期
| 原因 | 触发条件 | 影响范围 | 解决方案 |
|---|---|---|---|
| 1. 空闲超时 | API 用户 >5分钟无操作,Max 用户 >1小时 | 全部缓存失效 | 保持活跃或接受重建成本 |
这是最常见的缓存失效原因。如果你在编码过程中离开超过 5 分钟(API 用户)或 1 小时(Max 用户),下一次请求会触发完整的缓存重建。
第二类:内容变更导致的级联失效
缓存遵循严格的层级结构:Tool 定义 → 系统提示 → 对话历史。上层变更会导致下层全部失效。
| 原因 | 触发条件 | 影响范围 | 严重程度 |
|---|---|---|---|
| 2. 切换模型 | 使用 /model 命令 |
全部缓存(缓存按模型隔离) | ⚠️ 高 |
| 3. 添加/删除 MCP 工具 | 安装或卸载 MCP Server | Tool 层 + 下游全部失效 | ⚠️ 高 |
| 4. 切换 Web Search | 开启或关闭联网搜索 | 系统层 + 下游全部失效 | ⚠️ 中 |
| 5. 修改 CLAUDE.md | 编辑项目配置文件后重启 | 系统层 + 下游全部失效 | ⚠️ 中 |
第三类:操作触发的失效
| 原因 | 触发条件 | 影响范围 | 严重程度 |
|---|---|---|---|
| 6. 开新对话 | /clear 或新建会话 |
全部缓存(对话历史清空) | ⚠️ 高 |
| 7. 使用 /compact | 主动压缩对话历史 | 对话历史层缓存失效 | ⚠️ 中 |
| 8. 使用 /rewind | 撤销之前的消息 | 对话历史前缀改变 | ⚠️ 中 |
一个容易忽略的技术限制:最小缓存长度
如果你的 Prompt 低于以下 Token 数量,缓存会静默跳过,不会有任何报错:
| 模型 | 最小可缓存长度 |
|---|---|
| Claude Opus 4.6 / Haiku 4.5 | 4,096 Token |
| Claude Sonnet 4.6 | 2,048 Token |
| Claude Sonnet 4.5 / 4 | 1,024 Token |
对于 Claude Code 来说,由于 Tool 定义 + 系统提示就已经超过 5,000 Token,这个限制几乎不会触发。但如果你自己通过 API 构建应用,需要注意这个下限。
💡 建议: 如果你通过 API易 apiyi.com 自建应用调用 Claude API,
确保系统提示词长度超过模型对应的最小缓存阈值,否则缓存不会生效。
为什么你看到 40 万输入 Token:Claude Code 的上下文构成
理解了缓存机制后,我们来拆解一下那个让你震惊的"40 万输入 Token"到底由什么构成。
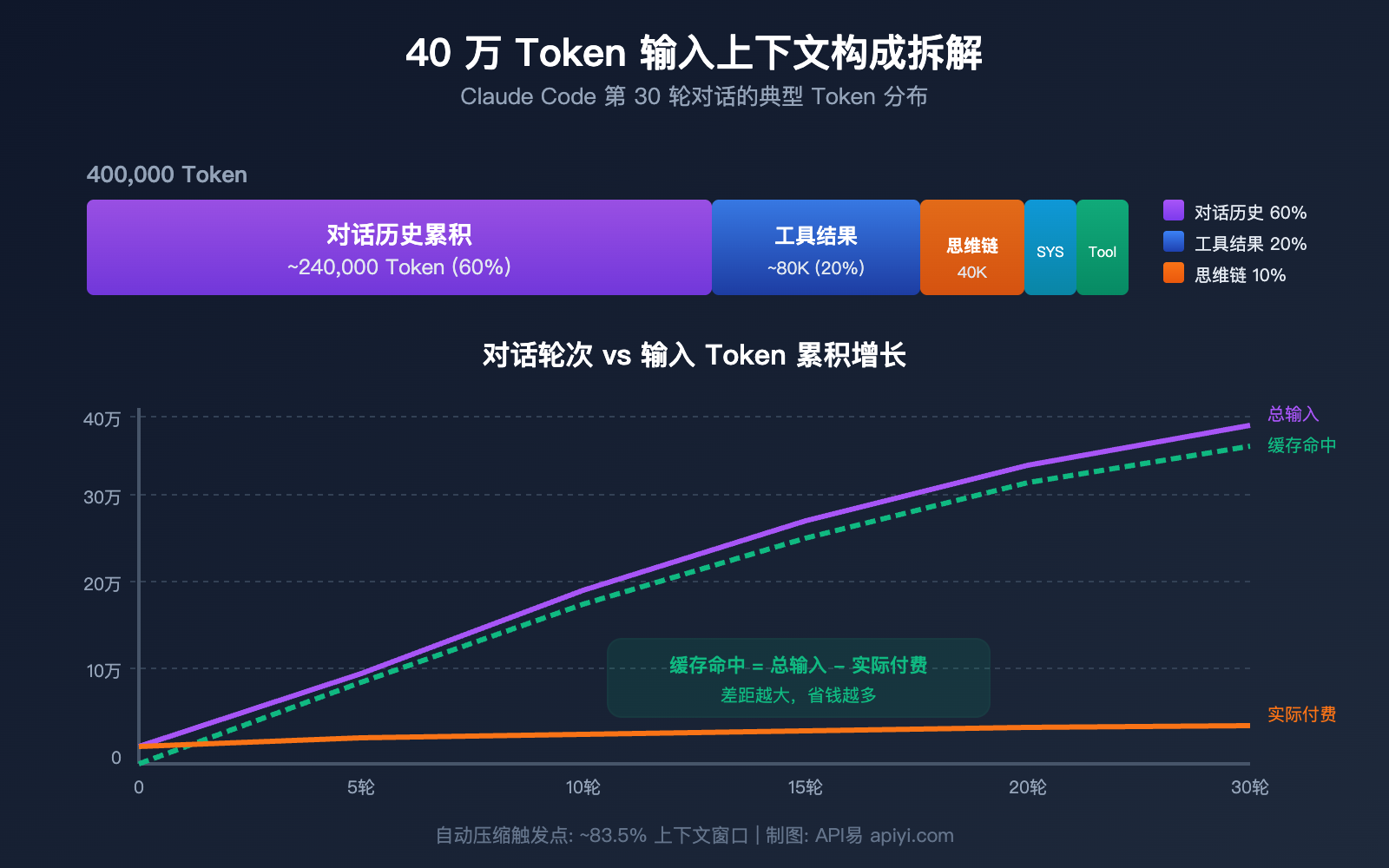
Token 消耗的 5 大来源
| 来源 | 占比 | 40万中约占 | 特点 |
|---|---|---|---|
| 对话历史累积 | ~60% | ~24万 | 每轮对话都重新发送全部历史 |
| 工具调用结果 | ~20% | ~8万 | 文件读取、grep 搜索结果驻留上下文 |
| 扩展思维链 | ~10% | ~4万 | 前几轮的 thinking block 变为输入 |
| 系统提示 + CLAUDE.md | ~5% | ~2万 | 每条消息都携带 |
| Tool 定义 | ~5% | ~2万 | 所有可用工具的 schema |
核心真相:对话越长,输入越大
Claude Code 的工作方式是每次请求都重新发送完整对话历史。这意味着:
- 第 1 轮:输入 ~2万 Token(系统提示 + Tool 定义 + 你的问题)
- 第 5 轮:输入 ~10万 Token(累积了 4 轮的对话历史)
- 第 15 轮:输入 ~25万 Token(包含大量文件读取结果)
- 第 30 轮:输入 ~40万+ Token(接近自动压缩阈值)
但请注意:这些输入中的绝大部分都是缓存命中的。第 30 轮的 40 万 Token 中,可能只有 1-2 万是新增的非缓存内容。
大代码库的特殊问题
Claude Code 不会自动加载整个代码库到上下文中。它按需读取文件。但在大型代码库中:
- 一次
grep搜索可能返回大量结果,全部进入上下文 - 探索性地读取多个文件,每个文件内容都驻留在对话历史中
- Agent 模式自主执行多步操作,每步的工具调用结果都累积
你的客户每次 40 万 Token 的情况,很可能是以下原因叠加:
- 代码库很大,Claude Code 读取了大量文件进行分析
- 对话轮次较多,历史累积
- 可能没有及时使用
/compact或/clear - CLAUDE.md 文件可能较长
6 个实战技巧:将输入 Token 从 40 万降到 5 万
技巧一:精准指令,避免全局扫描
这是最重要也最容易执行的优化。
❌ 模糊指令(触发大范围文件扫描):
"帮我优化这个项目的性能"
"检查代码中的bug"
"重构这个模块"
✅ 精准指令(只读取必要文件):
"优化 src/api/handler.ts 中 processRequest 函数的响应时间"
"修复 src/auth/login.ts 第 45 行的空指针异常"
"将 src/utils/format.ts 中的 formatDate 函数从 moment 迁移到 dayjs"
模糊指令会导致 Claude Code 使用 Glob + Grep + Read 大量文件来"理解"你的需求,每个文件的内容都会永久驻留在对话历史中。精准指令可以让它只读取 1-2 个相关文件。
Token 节省效果:减少 60-80% 的工具调用结果 Token
技巧二:及时使用 /clear 和 /compact
# 切换到不相关的任务时,清空对话
/clear
# 对话较长但任务还没结束时,压缩历史
/compact
# 带指令的压缩,保留特定信息
/compact 保留代码示例和 API 接口定义,其他可以精简
| 命令 | 效果 | 适用场景 | 注意事项 |
|---|---|---|---|
/clear |
清空全部对话历史 | 切换到完全不同的任务 | 缓存全部失效 |
/compact |
AI 总结历史,替换原文 | 长对话中间阶段 | 缓存部分失效,但上下文大幅缩小 |
实际效果:一个 40 万 Token 的对话,/compact 后通常可以压缩到 5-8 万 Token。
技巧三:优化 CLAUDE.md 文件
CLAUDE.md 会在每条消息中加载。一个 10,000 Token 的 CLAUDE.md,在 30 轮对话中会被发送 30 次(虽然缓存命中后只收 0.1x 费用,但仍然占据宝贵的上下文空间)。
优化建议:
├── CLAUDE.md 控制在 500 行以内(核心规则)
├── 把详细的工作流说明移到 Skills 中(按需加载)
├── 把参考文档放到 knowledge-base/ 中(需要时 Read)
└── 避免在 CLAUDE.md 中放大段示例代码
🚀 实践建议: 精简 CLAUDE.md 不仅减少 Token 消耗,
还能让 Claude Code 更专注于核心规则。
如果你在用 API易 apiyi.com 构建类似的 AI 编码助手,
同样建议控制系统提示词长度。
技巧四:善用 Subagent 隔离冗长输出
当需要执行会产生大量输出的操作时,用 Subagent 代替直接执行:
❌ 直接在主对话中执行(输出全部进入主上下文):
"运行测试套件并分析失败原因"
→ 测试输出可能有 50,000+ Token,永久驻留在对话历史中
✅ 让 Claude Code 使用 Subagent(输出隔离在子进程中):
"用一个子任务运行测试套件,只把失败的测试名和原因总结给我"
→ 主上下文只增加 ~500 Token 的总结
Token 节省效果:单次操作可减少 10,000-50,000 Token 进入主上下文
技巧五:选择合适的模型和 effort 级别
| 任务类型 | 推荐模型 | effort 级别 | 说明 |
|---|---|---|---|
| 简单修改/格式化 | Sonnet | low | 不需要深度思考 |
| 常规开发 | Sonnet | medium | 性价比最高 |
| 复杂架构设计 | Opus | high | 需要深度推理 |
| 代码审查 | Sonnet | medium | 性价比优于 Opus |
# 降低思考深度,减少 thinking Token(后续会变为输入)
# 在简单任务中设置更低的 effort
/effort low
# 或通过环境变量控制思维 Token 上限
MAX_THINKING_TOKENS=8000
扩展思维链 (thinking) 会在后续轮次变成输入 Token 的一部分。降低 effort 级别可以显著减少后续轮次的累积 Token。
技巧六:使用 /context 命令监控 Token 分布
# 查看当前 Token 使用分布
/context
/context 命令会展示当前上下文中各部分的 Token 占比,帮你定位到底是什么在消耗空间。常见发现:
- 某次 grep 搜索返回了 20,000 Token 的结果但只有 5% 有用
- 之前读取的某个大文件已经不需要了但还在上下文中
- CLAUDE.md 占了意外多的空间
发现问题后,有针对性地使用 /compact 或 /clear 处理。
💰 成本建议: 对于 API 按量付费用户,这些优化技巧可以直接降低账单。
通过 API易 apiyi.com 平台的用量统计功能,可以清晰看到每次请求的 Token 分布,
帮助你定位成本热点。
实战案例:从日均 $60 降到 $8
以下是一个真实的优化过程:
优化前(大型 Python 项目,重度 Claude Code 用户)
日均使用情况:
├── 对话轮次:~50 轮/天
├── 平均输入 Token:35-45 万/轮
├── 缓存命中率:~70%(频繁 /clear 和切换模型导致)
├── 日均 API 成本(Opus 4):~$60
└── 月均:~$1,320
优化后(应用 6 个技巧)
日均使用情况:
├── 对话轮次:~40 轮/天(更精准,不需要那么多轮)
├── 平均输入 Token:8-12 万/轮(精准指令 + 定期 compact)
├── 缓存命中率:~92%(减少不必要的缓存打断)
├── 日均 API 成本(Sonnet 4 为主,Opus 仅用于复杂任务):~$8
└── 月均:~$176
| 优化项 | 节省占比 | 说明 |
|---|---|---|
| 精准指令替代模糊扫描 | ~35% | 最大收益项 |
| 及时 /compact 和 /clear | ~25% | 控制累积膨胀 |
| Sonnet 替代 Opus(80% 任务) | ~20% | 模型降级零感知 |
| 精简 CLAUDE.md | ~8% | 减少每轮固定开销 |
| Subagent 隔离冗长输出 | ~7% | 避免大块结果污染上下文 |
| 降低 effort 级别 | ~5% | 减少 thinking Token 累积 |
常见问题
Q1: Claude Code 显示的 40 万 Token 是实际收费 40 万吗?
不是。Claude Code 会自动启用 Prompt Caching,在一个活跃会话中,95%+ 的输入 Token 通常是缓存命中,收费仅为基础价格的 0.1x。40 万 Token 中,可能只有 2-4 万 Token 按完整价格计费。你可以用 /context 查看实际的缓存命中率。通过 API易 apiyi.com 调用 API 同样支持缓存机制。
Q2: 我用 Max 包月方案还需要关心 Token 消耗吗?
需要关心,但原因不同。Max 包月不按 Token 计费,但有每周用量上限。过高的 Token 消耗会让你更快触达用量限制。精简上下文既能延长可用时间,也能让 Claude Code 更准确地理解你的需求(上下文越精准,回答越好)。
Q3: /compact 和 /clear 哪个更好?
取决于场景。如果你即将开始一个完全不同的任务,用 /clear 彻底清空更好。如果你还在同一个任务中但对话变得很长,用 /compact 保留关键上下文同时压缩体积。/compact 支持自定义指令,比如 /compact 保留所有代码修改记录和API接口定义。
Q4: 升级到最新版 Claude Code 会自动优化 Token 使用吗?
是的,建议始终保持最新版本。Anthropic 持续优化 Claude Code 的上下文管理策略,包括自动压缩触发时机(当前约 83.5% 上下文占用时触发)、MCP 工具定义延迟加载(只加载工具名,用到时才加载完整 schema)等。新版本通常会带来更好的缓存命中率和更智能的上下文管理。

总结:理解缓存 + 精准使用 = 成本可控
Claude Code 的 Prompt Caching 是一个非常强大的自动优化机制——你不需要做任何配置,它就在替你省钱。但理解它的工作原理和失效条件,能帮你把省钱效果从"自动 70%"提升到"主动 95%"。
记住这 3 个核心原则:
- 保持缓存活跃: 避免不必要的操作打断缓存(频繁切换模型、随意 /clear)
- 控制上下文膨胀: 精准指令 + 定期 /compact,不让对话历史无限增长
- 选对工具和模型: 80% 的任务用 Sonnet 就够,把 Opus 留给真正需要的场景
对于 API 按量付费用户,推荐通过 API易 apiyi.com 统一管理 Claude API 调用,利用平台的用量监控功能持续优化 Token 消耗。对于交互式重度用户,建议直接上 Claude Max 包月方案,配合本文的优化技巧获得最佳性价比。
📝 本文作者: APIYI 技术团队 | API易 apiyi.com – 300+ AI 大模型 API 统一接入平台
参考资料
-
Anthropic Prompt Caching 文档: 官方缓存机制详解
- 链接:
docs.anthropic.com/en/docs/build-with-claude/prompt-caching - 说明: 缓存 TTL、定价倍率和最小长度要求
- 链接:
-
Claude Code 成本管理指南: 官方 Token 优化建议
- 链接:
code.claude.com/docs/en/costs - 说明: Anthropic 官方推荐的成本控制策略
- 链接:
-
Claude Code 最佳实践: 上下文管理和效率优化
- 链接:
anthropic.com/engineering/claude-code-best-practices - 说明: 包含精准指令、compact 使用等实战建议
- 链接: