
O confronto entre o GPT-5.5 e o Claude Opus 4.7 é um dos debates mais importantes para desenvolvedores no primeiro semestre de 2026.
Ambos não são apenas modelos de chat.
O GPT-5.5 foca mais em agentic coding (codificação autônoma), uso de computador, trabalho de conhecimento e análise de pesquisa científica.
Já o Claude Opus 4.7 destaca-se pelo raciocínio complexo, tarefas de agente de longo prazo, visão de alta resolução, capacidades de memória e um seguimento de instruções mais rigoroso.
Se você perguntar apenas "qual é o mais forte", a resposta será muito superficial.
Uma pergunta mais prática seria: sua tarefa envolve correção de código, perguntas e respostas em bases de conhecimento, análise de contexto longo, compreensão visual, agentes automatizados ou chamadas de API de produção de alto custo?
Dependendo da tarefa, a escolha entre GPT-5.5 e Claude Opus 4.7 será bem diferente.
Quando a OpenAI lançou oficialmente o GPT-5.5, ela incluiu diretamente o Claude Opus 4.7 em várias tabelas de avaliação.
A Anthropic também posicionou o Claude Opus 4.7 como seu modelo de uso geral mais poderoso até o momento, enfatizando suas melhorias em agentic coding, trabalho de conhecimento, tarefas visuais e de memória.
Este artigo foi organizado com base em materiais oficiais em inglês, sem citar fontes secundárias em chinês.
Vale ressaltar que o "Claude 4.7" discutido aqui refere-se especificamente ao Claude Opus 4.7.
Até o momento da redação deste artigo, os materiais oficiais da Anthropic não indicam que o Claude Sonnet 4.7 tenha sido lançado.

Conclusões principais: GPT-5.5 vs Claude Opus 4.7
A primeira diferença fundamental entre o GPT-5.5 e o Claude Opus 4.7 reside no posicionamento do modelo.
A OpenAI define o GPT-5.5 como um modelo mais adequado para fluxos de trabalho reais. Ele enfatiza a codificação, depuração, pesquisa online, análise de dados, geração de documentos e tabelas, além da execução de tarefas entre ferramentas.
A Anthropic define o Claude Opus 4.7 como seu modelo de uso geral mais poderoso. Ele enfatiza o raciocínio complexo, agentic coding, tarefas de longo prazo, compreensão visual, memória e autoverificação.
Se sua tarefa envolve projetos de engenharia complexos no Codex, modificações entre arquivos, chamadas de ferramentas e trabalho de conhecimento, o GPT-5.5 geralmente merece prioridade nos testes.
Se sua tarefa envolve agentes de longa duração no Claude Code, compreensão de capturas de tela, verificação de formatação de documentos, memória do sistema de arquivos e seguimento rigoroso de instruções, o Claude Opus 4.7 merece prioridade.
Se você precisa integrar ambos os modelos, recomendamos usar o serviço proxy de API da APIYI (apiyi.com) para roteamento e avaliação de múltiplos modelos, evitando fixar a escolha do modelo diretamente no código da sua aplicação.
Comparação rápida: GPT-5.5 vs Claude Opus 4.7
| Dimensão | GPT-5.5 | Claude Opus 4.7 | Recomendação |
|---|---|---|---|
| Posicionamento oficial | Fluxo de trabalho real e IA agentic | Modelo Claude de uso geral mais forte | Escolha pelo tipo de tarefa |
| Capacidade de código | Desempenho forte no Terminal-Bench 2.0 | Melhoria significativa em agentic coding | Ambos devem ser testados |
| Contexto longo | 1M de janela de contexto via API | 1M de janela de contexto | Ambos são adequados |
| Capacidade visual | Colaboração multimodal e ferramentas | Suporte a imagens de alta resolução | Claude para tarefas visuais pesadas |
| Controle de raciocínio | reasoning_effort | effort / adaptive thinking | Sistemas de parâmetros diferentes |
| Custo de API | $5 entrada / $30 saída por milhão de tokens | $5 entrada / $25 saída por milhão de tokens | Claude tem saída mais barata |
| Ecossistema | ChatGPT, Codex, API | Claude, Claude Code, API | Depende do fluxo de trabalho |
Recomendação: Se você não tem certeza de qual modelo é mais adequado, recomendamos preparar de 30 a 50 amostras de negócios reais e executar ambos os modelos simultaneamente via APIYI (apiyi.com), comparando a taxa de sucesso, tempo de resposta, custo e avaliação humana.
Comparativo de Capacidades de Codificação: GPT-5.5 vs Claude Opus 4.7
A codificação é o cenário de comparação mais central entre o GPT-5.5 e o Claude Opus 4.7.
Dados oficiais da OpenAI mostram que o GPT-5.5 atinge 82,7% no Terminal-Bench 2.0.
Na mesma tabela, o Claude Opus 4.7 registra 69,4%.
Já no benchmark público SWE-Bench Pro, o GPT-5.5 marca 58,6%, enquanto o Claude Opus 4.7 alcança 64,3%.
Isso demonstra que nenhum dos modelos vence de forma unilateral.
O GPT-5.5 se destaca em fluxos de trabalho complexos via linha de comando, planejamento, iteração e coordenação de ferramentas.
O Claude Opus 4.7 também é altamente competitivo em tarefas de resolução de issues do GitHub.
Materiais oficiais da Anthropic enfatizam que o Claude Opus 4.7 obteve um ganho de 13% em relação ao Opus 4.6 em seu benchmark de codificação de 93 tarefas.
Isso significa que a evolução na codificação do Claude Opus 4.7 em relação à geração anterior é clara.
No entanto, ao comparar o GPT-5.5 com o Claude Opus 4.7, não se pode tomar um único benchmark como conclusão definitiva.
O trabalho real de codificação inclui: ler códigos legados, identificar riscos, controlar o escopo de alterações, completar testes, executar comandos, tratar falhas, explicar mudanças e gerar notas de revisão.
No cenário Codex, o GPT-5.5 enfatiza a execução entre ferramentas e a conclusão de tarefas com menos tokens.
No cenário Claude Code, o Claude Opus 4.7 enfatiza agentes de longo prazo, xhigh effort (alto esforço) e um seguimento de instruções mais rigoroso.
Sugestões para cenários de codificação: GPT-5.5 vs Claude Opus 4.7
| Tarefa de Codificação | Recomendação de Teste | Motivo |
|---|---|---|
| Fluxos complexos via CLI | GPT-5.5 | Pontuação oficial superior no Terminal-Bench 2.0 |
| Correção de issues no GitHub | Testar ambos | Claude melhor no SWE-Bench Pro, GPT-5.5 com ecossistema forte |
| Compreensão de grandes bases de código | GPT-5.5 | Cenário Codex focado em contexto entre sistemas |
| Tarefas de agentes de longa duração | Claude Opus 4.7 | xhigh effort e melhor alinhamento com orçamento de tarefas |
| Revisão e validação de código | Ambos adequados | Focar no ciclo de testes |
| Correções em lote sensíveis a custo | Teste necessário | Grandes diferenças no uso de tokens |
Dica de escolha: Não olhe apenas para os rankings. Recomendamos que você insira suas issues reais, testes com falha, revisões de PR e tarefas de refatoração no APIYI (apiyi.com) para realizar um teste comparativo, registrando se cada modelo realmente executou os testes, se alterou arquivos irrelevantes por engano e se conseguiu explicar os riscos.

Trabalho de Conhecimento e Capacidade de Pesquisa: GPT-5.5 vs Claude Opus 4.7
A comparação entre o GPT-5.5 e o Claude Opus 4.7 no trabalho de conhecimento também é fundamental.
Materiais oficiais da OpenAI mostram que o GPT-5.5 atinge 84,9% no GDPval.
O Claude Opus 4.7 registra 80,3% na mesma tabela.
O GPT-5.5 Pro atinge 82,3%.
Isso indica que, nas avaliações de trabalho de conhecimento profissional listadas pela OpenAI, o GPT-5.5 apresenta um desempenho muito forte.
A OpenAI também destaca que o GPT-5.5 teve melhorias significativas na geração de documentos, planilhas, apresentações, processamento de pesquisas operacionais e entradas comerciais.
Do lado da Anthropic, o material oficial do Claude Opus 4.7 enfatiza seu desempenho notável em trabalho de conhecimento, memória, visão e trabalho de agente de longo prazo.
Uma característica importante do Claude Opus 4.7 é uma disciplina de dados mais rigorosa.
A página da Anthropic cita a avaliação da Hex, sugerindo que o modelo está mais disposto a declarar quando dados estão ausentes, em vez de fornecer alternativas que parecem plausíveis, mas estão incorretas.
Isso é crucial para análise financeira, relatórios de pesquisa, revisões de conformidade e processamento de planilhas de dados.
Se a sua tarefa de conhecimento exige que o modelo escreva documentos de negócios bonitos, completos e com estrutura clara, o GPT-5.5 vale muito a pena ser testado.
Se a sua tarefa exige que o modelo permaneça cauteloso diante de dados ausentes, dados conflitantes e contextos longos, o Claude Opus 4.7 também é extremamente competitivo.
Escolha de Trabalho de Conhecimento: GPT-5.5 vs Claude Opus 4.7
| Cenário | Vantagem do GPT-5.5 | Vantagem do Claude Opus 4.7 | Sugestão |
|---|---|---|---|
| Relatórios comerciais | Geração estruturada forte | Disciplina de dados forte | Comparar ambos |
| Análise de planilhas | Capacidade de tabelas Codex forte | Validação visual e análise de gráficos forte | Depende do formato de entrada |
| Pesquisa financeira | Desempenho forte no GDPval | Melhoria no módulo de Finanças Gerais | Testar com amostras reais |
| Revisão de conformidade | Capacidade abrangente forte | Cautela no tratamento de dados ausentes | Priorizar teste com Claude |
| Resumo de múltiplos documentos | Contexto longo forte | Memória e instruções rigorosas | Escolher pela qualidade da citação |
Dica de escolha: O maior medo no trabalho de conhecimento é o conteúdo que "parece completo, mas contém alucinações". Ao realizar a comparação entre GPT-5.5 e Claude Opus 4.7 no APIYI (apiyi.com), sugerimos dividir a avaliação humana em 5 dimensões: precisão factual, consistência das citações, taxa de omissão, qualidade da estrutura e exequibilidade.
GPT-5.5 vs Claude Opus 4.7: Capacidades Visuais e de Longo Contexto
Tanto o GPT-5.5 quanto o Claude Opus 4.7 suportam contextos longos, mas com diferenças importantes nos detalhes.
De acordo com o material oficial da OpenAI, a API do GPT-5.5 possui uma janela de contexto de 1M.
Já a visão geral dos modelos da Anthropic indica que o Claude Opus 4.7 também suporta uma janela de contexto de 1M tokens, com um limite de saída de 128k.
Em tarefas de longo contexto, ambos entraram no patamar de processamento de documentos extensos, bases de código e pacotes de dados complexos.
No entanto, em tarefas visuais, as mudanças no Claude Opus 4.7 são mais significativas.
A documentação da Anthropic mostra que o Claude Opus 4.7 é o primeiro modelo Claude a suportar imagens de alta resolução, com a resolução máxima aumentada para 2576px / 3.75MP.
Isso é fundamental para a compreensão de capturas de tela, imagens de documentos, verificação de slides, análise de gráficos e uso de computador (computer use).
A Anthropic também mencionou que as coordenadas das imagens agora correspondem a 1:1 com os pixels reais, reduzindo a necessidade de conversões de escala.
O GPT-5.5 também possui capacidades multimodais e de uso de computador muito fortes, mas se o foco da sua entrada for capturas de tela de alta resolução, gráficos, layout de documentos ou coordenadas de interface, o Claude Opus 4.7 merece ser testado primeiro.
Se a sua entrada for composta por textos longos, bases de código, documentos de negócios, dados estruturados e resultados de cadeias de ferramentas, tanto o GPT-5.5 quanto o Claude Opus 4.7 devem ser avaliados com o mesmo conjunto de amostras.
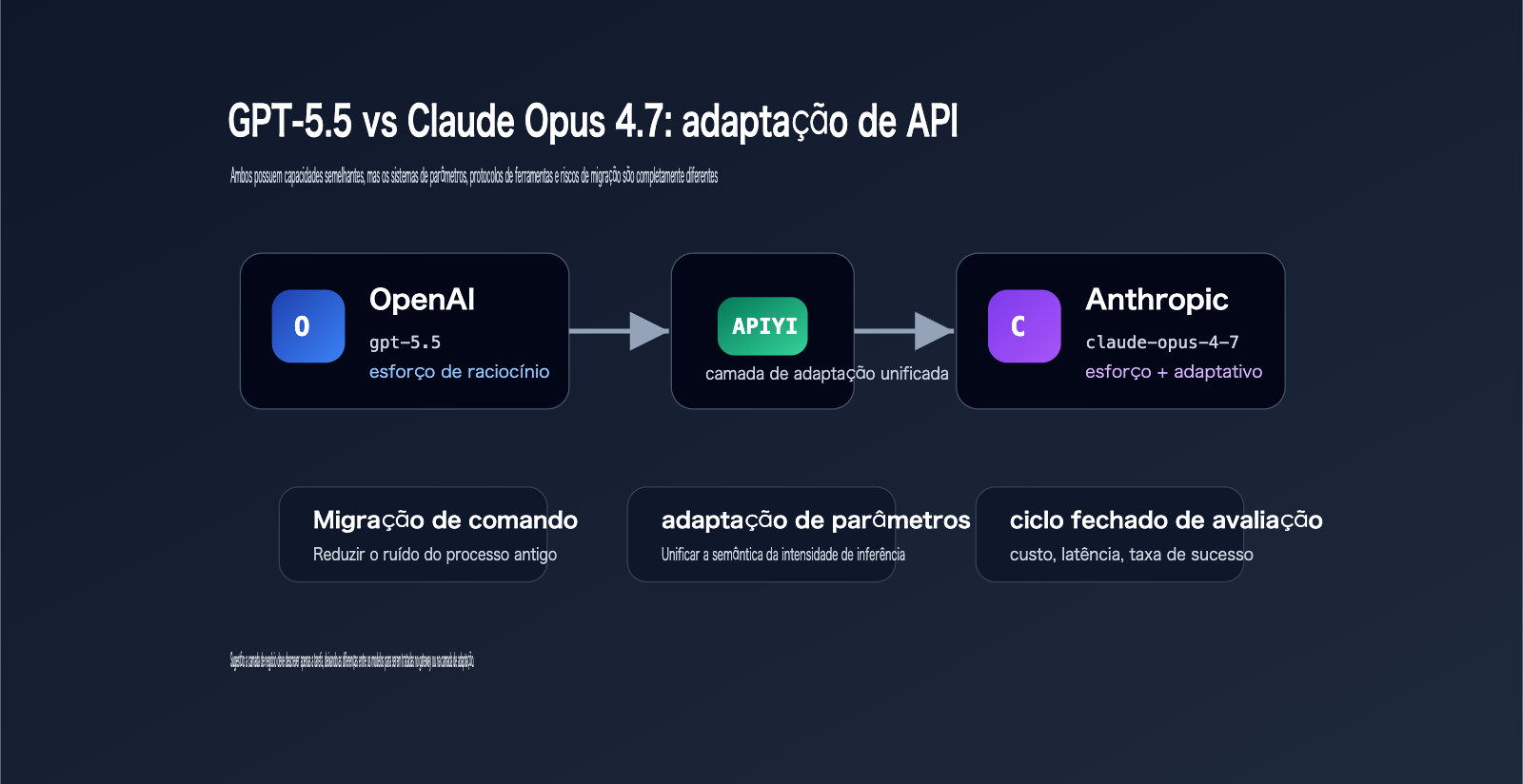
GPT-5.5 vs Claude Opus 4.7: Parâmetros de API e Diferenças de Migração
As diferenças de migração de API entre o GPT-5.5 e o Claude Opus 4.7 são consideráveis.
O GPT-5.5 pertence ao ecossistema de modelos da OpenAI, com parâmetros principais incluindo model, reasoning_effort, chamadas de ferramentas da API de Respostas e controle de formato de saída.
O Claude Opus 4.7 pertence ao ecossistema da API de Mensagens da Anthropic, com parâmetros principais incluindo adaptive thinking, effort, task budget, max_tokens e chamadas de ferramentas.
A documentação oficial da Anthropic mostra que o Claude Opus 4.7 removeu os orçamentos de pensamento estendido (extended thinking budgets).
A sintaxe antiga thinking: {"type": "enabled", "budget_tokens": N} retornará um erro 400.
A nova sintaxe deve usar thinking: {"type": "adaptive"}, configurando o effort através do output_config.
A Anthropic também esclareceu que, a partir do Claude Opus 4.7, definir temperature, top_p ou top_k fora dos valores padrão resultará em erro 400.
Este é um ponto de migração importante para muitos projetos legados.
Se você dependia anteriormente de temperature=0 para obter uma saída determinística, saiba que o temperature=0 nunca garantiu consistência total.
Em comparação, o foco da migração para o GPT-5.5 está mais na reconstrução de comandos, avaliação de reasoning_effort, fluxos de trabalho de ferramentas e comandos focados em resultados.
Principais pontos de migração de API: GPT-5.5 vs Claude Opus 4.7
| Item de Migração | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| ID do Modelo | gpt-5.5 |
claude-opus-4-7 |
| Controle de Raciocínio | reasoning_effort | effort + adaptive thinking |
| Longo Contexto | 1M context window | 1M context window |
| Limite de Saída | Conforme especificação da API OpenAI | 128k max output |
| Parâmetros de Temperatura | Configurado conforme suporte da API OpenAI | Erro se temperature/top_p/top_k não forem padrão |
| Fluxo de Ferramentas | Sistema de ferramentas da API de Respostas | Sistema de ferramentas da API de Mensagens |
| Riscos de Migração | Especificação excessiva em comandos antigos | Orçamento de pensamento e parâmetros de amostragem antigos |
Sugestão: Se você precisa integrar tanto o GPT-5.5 quanto o Claude Opus 4.7, não recomendamos que o código de negócio escreva duas lógicas de chamada separadas. Você pode usar o serviço proxy de API da APIYI (apiyi.com) para criar uma entrada compatível com OpenAI, gerenciando as diferenças de modelo, parâmetros e tratamento de erros na camada de gateway ou de adaptação.
GPT-5.5 vs Claude Opus 4.7: Escolhendo entre custo e desempenho
O custo entre o GPT-5.5 e o Claude Opus 4.7 não deve ser avaliado apenas pelo preço unitário.
De acordo com os dados oficiais da OpenAI, o preço da API do GPT-5.5 é de US$ 5 por milhão de tokens de entrada e US$ 30 por milhão de tokens de saída.
Já na visão geral dos modelos da Anthropic, o Claude Opus 4.7 custa US$ 5 por milhão de tokens de entrada e US$ 25 por milhão de tokens de saída.
Olhando apenas para o preço de saída, o Claude Opus 4.7 é mais barato.
No entanto, a OpenAI destaca que o GPT-5.5 é mais eficiente em termos de tokens no Codex do que o GPT-5.4.
A Anthropic também enfatiza que o Claude Opus 4.7 controla os custos através de esforço (effort), orçamento de tarefa (task budget) e raciocínio adaptativo (adaptive thinking).
Portanto, o custo real depende do tipo de tarefa.
Se o GPT-5.5 concluir a tarefa com menos rodadas, seu custo total não será necessariamente maior.
Se o Claude Opus 4.7 consumir muitos tokens de saída em níveis de esforço "xhigh" ou "max", seu custo total também pode aumentar.
A avaliação de custos deve focar no "custo total para concluir uma tarefa qualificada", e não apenas no preço por milhão de tokens.
Dimensões de avaliação de custo: GPT-5.5 vs Claude Opus 4.7
| Dimensão de Custo | O que registrar | Por que é importante |
|---|---|---|
| Token de entrada | Comando, contexto, resultados de ferramentas | A diferença de custo é grande em tarefas de contexto longo |
| Token de saída | Resposta final, parâmetros de ferramentas, saída de raciocínio | O preço de saída geralmente é mais caro |
| Rodadas | Quantas rodadas são necessárias para concluir a tarefa | Múltiplas rodadas amplificam o custo |
| Taxa de sucesso | Conclusão na primeira tentativa ou correções repetidas | Falhas e novas tentativas são custos ocultos |
| Latência | Tempo de espera do usuário | Níveis altos de esforço aumentam a espera |
| Revisão humana | É necessária correção humana? | A baixa qualidade transfere custos para o humano |
Sugestão de escolha: Para aplicações corporativas, a otimização de custos de modelos não é apenas escolher o modelo mais barato. Recomendamos usar a APIYI (apiyi.com) para registrar a entrada, saída, latência, modelo, parâmetros e pontuação humana de cada invocação, utilizando o "custo por tarefa qualificada" como métrica final.
Decisão de cenários de uso: GPT-5.5 vs Claude Opus 4.7
Se você é um desenvolvedor individual, pode escolher entre o GPT-5.5 e o Claude Opus 4.7 com base no ecossistema de ferramentas.
Se você usa muito o Codex, teste primeiro o GPT-5.5.
Se você usa muito o Claude Code, teste primeiro o Claude Opus 4.7.
Se você é um líder técnico corporativo, não recomendamos tomar decisões baseadas apenas na experiência pessoal.
Você deve criar um conjunto de tarefas e comparar ambos dentro do mesmo sistema de entrada, saída, pontuação e registro de custos.
Se você é uma equipe de conteúdo, o GPT-5.5 vale a pena ser testado prioritariamente em conteúdos estruturados, organização de pesquisas, tabelas e trabalhos com múltiplas ferramentas.
O Claude Opus 4.7 merece prioridade em testes de expressão cautelosa, contexto longo, materiais visuais e verificação de documentos.
Se você possui uma plataforma de API ou produto SaaS, recomendamos implementar o roteamento de modelos.
Por exemplo, perguntas e respostas simples podem usar modelos de menor custo, enquanto códigos complexos e tarefas de agentes longas podem ser escaladas para o GPT-5.5 ou Claude Opus 4.7.
Isso evita que todas as solicitações sejam enviadas para os modelos topo de linha.
Lista de verificação para migração: GPT-5.5 vs Claude Opus 4.7
Não se limite a uma experiência subjetiva antes de colocar em produção.
Recomendo preparar pelo menos 5 tipos de amostras:
- Amostras de sucesso.
- Amostras de borda (casos fáceis de gerar erros).
- Amostras com contexto longo.
- Amostras de invocação de ferramentas.
- Amostras de recuperação de falhas.
Para cada amostra, registre o modelo, parâmetros, tokens de entrada, tokens de saída, tempo de execução, se foi bem-sucedido na primeira tentativa e a avaliação humana.
Ao mesmo tempo, teste separadamente os níveis de baixo custo e de alta capacidade.
No lado do GPT-5.5, você pode testar diferentes reasoning_effort.
No lado do Claude Opus 4.7, você pode testar os níveis medium, high, xhigh e max effort.
Não assuma que ambos os modelos devem ser configurados no nível máximo por padrão.
A configuração máxima indica apenas o limite superior, não o custo-benefício em produção.
Como interpretar os dados de avaliação do GPT-5.5 vs Claude Opus 4.7?
Os benchmarks públicos de GPT-5.5 vs Claude Opus 4.7 são valiosos como referência, mas não equivalem diretamente aos resultados do seu negócio.
O motivo é simples: as avaliações públicas geralmente possuem conjuntos de tarefas fixos, comandos fixos, ambientes de execução fixos e regras de pontuação fixas.
O seu sistema de negócios encontrará dados sujos, falta de contexto, expressões instáveis dos usuários, falhas nas ferramentas, restrições de permissão e o peso de comandos (Prompts) históricos.
Portanto, ver o GPT-5.5 liderando em um determinado benchmark não significa que todas as tarefas devam ser migradas para o GPT-5.5.
Ver o Claude Opus 4.7 liderando em outro benchmark também não significa que todas as tarefas devam ser migradas para o Claude.
Uma abordagem mais segura é tratar os benchmarks oficiais como dicas sobre a direção da capacidade do modelo.
Por exemplo, o Terminal-Bench 2.0 é mais indicativo da capacidade de fluxos de trabalho complexos de linha de comando.
O SWE-Bench Pro está mais próximo da capacidade real de correção de problemas no GitHub.
O GDPval está mais próximo da capacidade de entrega de conhecimento profissional.
Já os benchmarks visuais e o suporte a imagens de alta resolução são mais adequados para avaliar tarefas relacionadas a capturas de tela, gráficos, interface de usuário, documentos e layout.
Ao implementar, você precisa mapear essas dimensões para os cenários do seu próprio produto.
Se o produto for um assistente de codificação IDE, priorize a taxa de sucesso na correção de código, taxa de aprovação em testes, taxa de alterações irrelevantes e qualidade da explicação.
Se o produto for uma base de conhecimento corporativa, priorize a precisão das citações, taxa de omissão de fatos, tratamento de conflitos e limites de recusa.
Se o produto for um agente de automação, priorize o número de invocações de ferramentas, recuperação de falhas, taxa de conclusão de tarefas e custo total.
Se o produto for processamento de documentos visuais, priorize o reconhecimento de coordenadas, transcrição de gráficos, compreensão de layout e custo de correção humana.
O valor da APIYI (apiyi.com) reside justamente em executar esses testes de modelo sob uma interface unificada.
A mesma entrada, as mesmas dimensões de pontuação e os mesmos campos de log permitem que as conclusões sobre GPT-5.5 vs Claude Opus 4.7 sejam verdadeiramente reutilizáveis.

FAQ: GPT-5.5 vs Claude Opus 4.7
Qual é o melhor para escrever código: GPT-5.5 ou Claude Opus 4.7?
Ambos são excelentes.
O GPT-5.5 apresenta um desempenho superior no Terminal-Bench 2.0, sendo ideal para fluxos complexos de linha de comando e fluxos de trabalho Codex.
O Claude Opus 4.7 tem uma performance muito forte no SWE-Bench Pro e é altamente recomendado para tarefas de agente de longa duração com o Claude Code.
Para projetos reais, a recomendação é realizar testes comparativos usando o mesmo conjunto de issues e comandos de teste.
Qual é o melhor para perguntas e respostas em bases de conhecimento?
Se o foco for a geração estruturada e a organização com múltiplas ferramentas, teste primeiro o GPT-5.5.
Se o foco for a identificação de dados ausentes, cautela na expressão e disciplina em janelas de contexto longas, priorize o Claude Opus 4.7.
No final, a decisão deve ser baseada na precisão das citações e no custo de revisão humana.
Qual é o melhor para tarefas visuais?
O Claude Opus 4.7 traz suporte explícito a imagens de alta resolução em sua documentação oficial.
Se a sua tarefa envolve capturas de tela, coordenadas, layout de documentos e validação visual, o Claude Opus 4.7 merece ser testado primeiro.
O GPT-5.5 também é adequado para fluxos de trabalho multimodais, mas tarefas que dependem intensamente de visão exigem uma avaliação dedicada.
Qual é o mais barato?
De acordo com os preços oficiais, ambos custam 5 dólares por milhão de tokens na entrada (input).
O preço de saída (output) do Claude Opus 4.7 é de 25 dólares por milhão de tokens, enquanto o do GPT-5.5 é de 30 dólares por milhão de tokens.
No entanto, o custo real depende do número de rodadas necessárias para concluir a tarefa, do tamanho da saída, da taxa de falha e do custo de correção humana.
Resumo: GPT-5.5 vs Claude Opus 4.7
Não existe uma resposta única para todos os cenários no comparativo entre GPT-5.5 e Claude Opus 4.7.
O GPT-5.5 é mais adequado para fluxos de produção com múltiplas ferramentas, codificação Codex, geração de tabelas em documentos, trabalho intelectual e execução de tarefas complexas.
O Claude Opus 4.7 é mais indicado para visão de alta resolução, tarefas de agente de longo prazo, seguimento rigoroso de comandos, memória de arquivos e processamento cauteloso de dados.
Se você é um usuário individual, escolha com base no ecossistema de ferramentas que você já utiliza.
Se você é um usuário corporativo, é indispensável realizar testes com amostras reais.
Se você é um desenvolvedor de API, a recomendação é gerenciar as diferenças entre os modelos na camada de adaptação, evitando vincular o GPT-5.5 ou o Claude Opus 4.7 diretamente à sua lógica de negócio.
O APIYI (apiyi.com) é ideal para atuar como um ponto de entrada unificado para modelos, registrando invocações, monitorando custos e permitindo a alternância entre diferentes modelos.
A recomendação final é: utilize o GPT-5.5 para tarefas de alta complexidade com múltiplas ferramentas, o Claude Opus 4.7 para visão de alta precisão e agentes de longa duração, e modelos de baixo custo para solicitações simples, ajustando o roteamento continuamente com base nos dados de avaliação.
Referências:
- OpenAI Introducing GPT-5.5: openai.com/index/introducing-gpt-5-5
- Anthropic Introducing Claude Opus 4.7: anthropic.com/news/claude-opus-4-7
- Anthropic Claude Opus 4.7 API docs: platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7
- Anthropic Models overview: platform.claude.com/docs/en/about-claude/models/overview
- Anthropic Effort docs: platform.claude.com/docs/en/build-with-claude/effort