
O gpt-image-2, lançado pela OpenAI em abril de 2026, tornou-se o modelo mais aguardado no campo da geração de imagens — com 99% de precisão na renderização de textos, saída em 4K, suporte nativo a chinês/CJK e integração com as capacidades de raciocínio da série O. No entanto, a primeira pergunta que muitos desenvolvedores fazem ao obter o modelo é: como integrar o gpt-image-2 à API oficial? Quais parâmetros são obrigatórios? Como configurar a base_url? Como utilizar o b64_json na resposta?
Este artigo é um guia prático de ponta a ponta para a integração do gpt-image-2 com a API oficial, cobrindo todos os detalhes técnicos, desde a instalação do SDK e configuração da base_url até a geração de imagens, edição, inpainting e tratamento de erros. Todo o código é baseado no SDK oficial da OpenAI e no serviço proxy de API da APIYI (100% compatível com os campos oficiais). Após seguir este guia, seu projeto estará pronto para utilizar o gpt-image-2 em ambiente de produção.
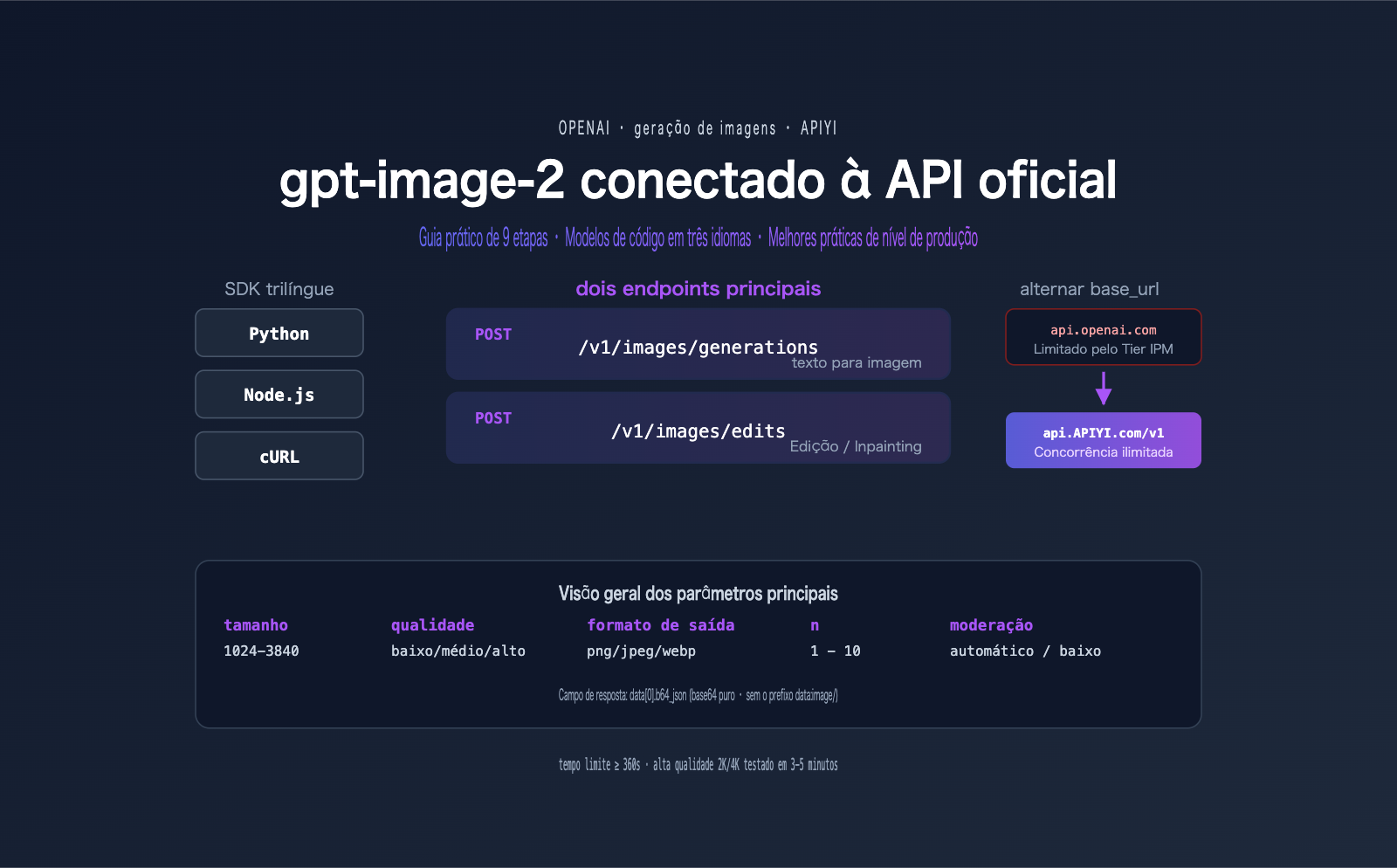
Lista de verificação para a integração do gpt-image-2 com a API oficial
Antes de escrever a primeira linha de código, é necessário preparar o ambiente. A lista abaixo cobre os 4 pré-requisitos essenciais para a integração do gpt-image-2 com a API oficial.
Lista de ambiente para a integração do gpt-image-2
| Item de preparação | Requisito | Descrição |
|---|---|---|
| Chave API | Bearer Token válido | Solicite via painel da APIYI; o crédito de teste é obtido no registro |
| SDK Python | openai >= 1.50.0 |
Versões antigas não suportam os novos parâmetros de images.generate() |
| SDK Node.js | openai >= 4.50.0 |
Tipos TypeScript sincronizados com o oficial |
| Timeout HTTP | ≥ 360 segundos | Qualidade high + 2K/4K levam de 3 a 5 minutos |
| Requisitos de rede | Acesso direto | api.apiyi.com acessível via redes domésticas ou nós internacionais |
Instalação do SDK para a integração do gpt-image-2
Independentemente da linguagem escolhida, basta instalar o SDK oficial da OpenAI — o canal de proxy da APIYI é totalmente consistente com os campos oficiais, não sendo necessárias bibliotecas de cliente adicionais.
# Python
pip install --upgrade openai
# Node.js
npm install openai@latest
# Se usar yarn / pnpm
yarn add openai
pnpm add openai
Fluxo de obtenção da Chave API para o gpt-image-2
Os passos para obter a chave API são simples:
- Acesse o painel da APIYI em
api.apiyi.com - Após registrar a conta, entre na página "Tokens de API"
- Crie um novo Token (recomendamos usar um Token independente para cada projeto para facilitar a auditoria)
- Salve o Token em variáveis de ambiente (não recomendamos fortemente o hardcoding no código)
🚀 Dica para começar rápido: Ao integrar o gpt-image-2 pela primeira vez, recomendamos começar com baixa qualidade + 1024×1024 para validar o fluxo, antes de mudar para a qualidade high e grandes dimensões. Sugerimos resgatar o crédito de teste na plataforma APIYI (apiyi.com); o crédito gratuito é suficiente para concluir todo o processo de validação PoC.
# Adicione ao seu ~/.zshrc ou ~/.bashrc
export APIYI_KEY="sk-seu-token-aqui"
Configuração do base_url para integração da API oficial do gpt-image-2
Em todo o processo de integração da API oficial do gpt-image-2, a única diferença em relação ao SDK nativo da OpenAI é o base_url. Basta substituí-lo de api.openai.com por api.apiyi.com, mantendo todo o restante do código exatamente igual.
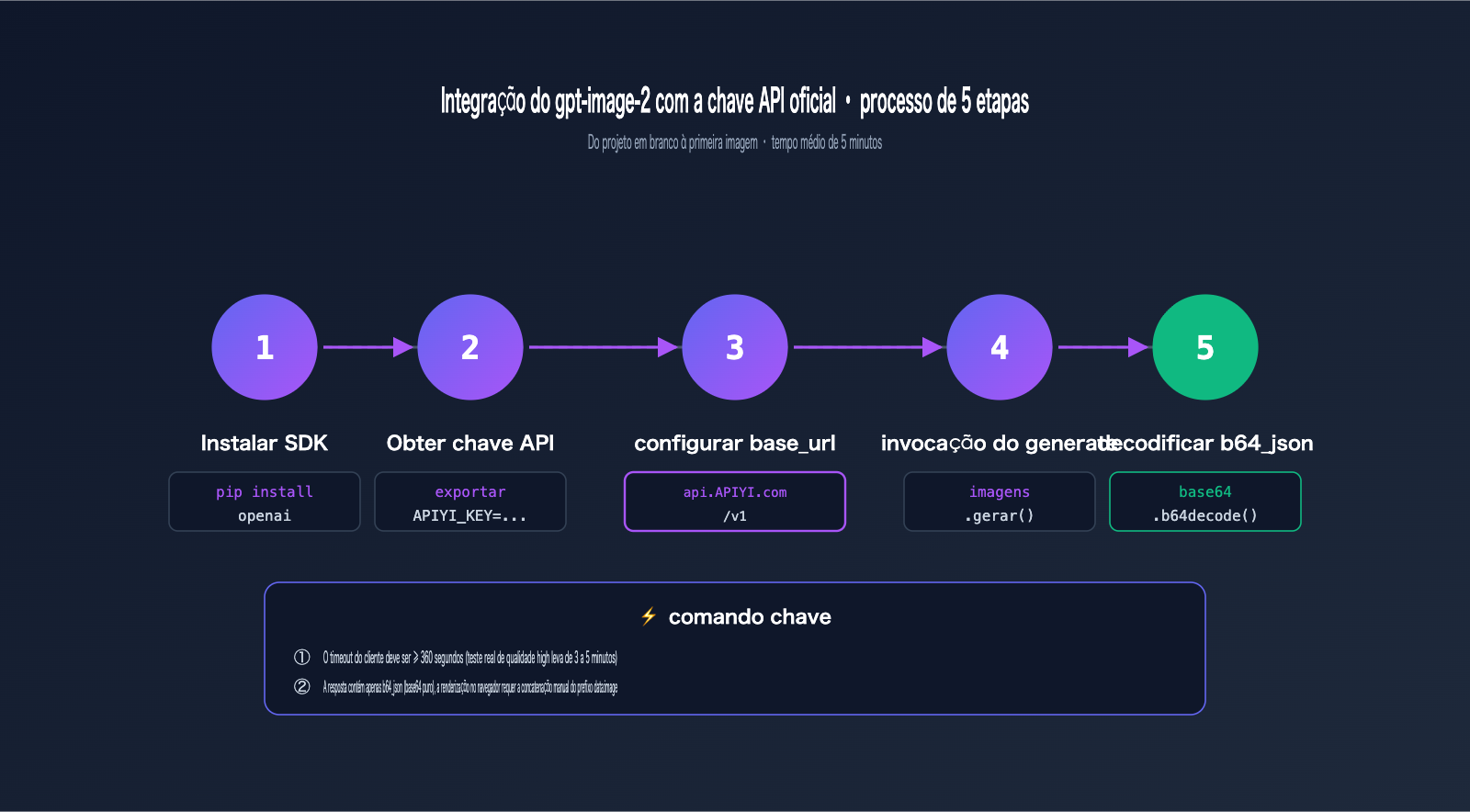
Dois endpoints para integração da API oficial do gpt-image-2
A APIYI oferece dois endpoints de imagem totalmente compatíveis com a OpenAI:
| Endpoint | Uso | Parâmetros necessários |
|---|---|---|
POST /v1/images/generations |
Geração de imagens (apenas com comando) | model, prompt |
POST /v1/images/edits |
Edição de imagem, fusão de múltiplas imagens, repintura com máscara | model, prompt, image |
Inicialização do cliente para integração da API oficial do gpt-image-2
Abaixo, apresentamos o código de inicialização do cliente em Python e Node.js. Lembre-se de definir o tempo limite (timeout) para pelo menos 360 segundos.
# Python
import os
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("APIYI_KEY"),
base_url="https://api.apiyi.com/v1", # Mude para o canal de proxy da APIYI
timeout=600.0, # Necessário aumentar para cenários de alta qualidade
max_retries=2
)
// Node.js
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.APIYI_KEY,
baseURL: "https://api.apiyi.com/v1", // Note que é baseURL (camelCase)
timeout: 600 * 1000, // Em milissegundos
maxRetries: 2
});
💡 Lembrete sobre o tempo limite: O tempo limite padrão de 60 segundos certamente falhará em cenários de alta qualidade (high) + 2K/4K. Recomendamos que, ao integrar via APIYI (apiyi.com), todos os clientes em ambiente de produção definam o tempo limite de solicitação entre 360 e 600 segundos para evitar que solicitações longas sejam interrompidas incorretamente.
Chamada de geração de imagens para integração da API oficial do gpt-image-2
Vamos à prática. Abaixo, mostramos como realizar a primeira chamada de geração de imagens do gpt-image-2 em três linguagens diferentes.
Geração de imagens com Python para o gpt-image-2
import base64
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("APIYI_KEY"),
base_url="https://api.apiyi.com/v1",
timeout=600.0
)
response = client.images.generate(
model="gpt-image-2",
prompt="A modern minimalist office desk with a vintage typewriter, soft morning light from the window, photorealistic, 8K",
size="1536x1024",
quality="high",
output_format="jpeg",
output_compression=92,
n=1
)
# Chave: A APIYI retorna uma string base64 pura, sem o prefixo data:image/...
b64 = response.data[0].b64_json
with open("output.jpg", "wb") as f:
f.write(base64.b64decode(b64))
print("✓ Imagem salva em output.jpg")
Geração de imagens com Node.js para o gpt-image-2
import fs from "node:fs/promises";
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.APIYI_KEY,
baseURL: "https://api.apiyi.com/v1",
timeout: 600_000
});
const response = await client.images.generate({
model: "gpt-image-2",
prompt: "An e-commerce product photo of a leather backpack on a marble desk, studio lighting",
size: "1024x1024",
quality: "high",
output_format: "png",
n: 1
});
const b64 = response.data[0].b64_json;
await fs.writeFile("output.png", Buffer.from(b64, "base64"));
console.log("✓ Imagem salva");
Geração de imagens com cURL para o gpt-image-2
O cURL é ideal para verificar rapidamente a disponibilidade da chave API e testar novas combinações de parâmetros.
curl https://api.apiyi.com/v1/images/generations \
-H "Authorization: Bearer $APIYI_KEY" \
-H "Content-Type: application/json" \
--max-time 600 \
-d '{
"model": "gpt-image-2",
"prompt": "A futuristic cyberpunk city at night, neon signs in mixed Chinese and English",
"size": "2048x1152",
"quality": "high",
"output_format": "jpeg",
"output_compression": 90,
"n": 1
}' | jq -r '.data[0].b64_json' | base64 -d > output.jpg
Note que --max-time 600 é obrigatório — o cURL não possui tempo limite por padrão, mas muitos wrappers de shell impõem uma interrupção forçada de 60 segundos.
Pontos importantes sobre o processamento da resposta
Muitos desenvolvedores travam na análise do base64 na primeira integração. Aqui estão alguns erros comuns:
# ✗ Erro: A APIYI não retorna o campo url
url = response.data[0].url # AttributeError
# ✓ Correto: Use b64_json
b64 = response.data[0].b64_json
# ✗ Erro: O navegador renderiza diretamente a string b64 pura
<img src="{b64}"> # Não será exibido
# ✓ Correto: A renderização no navegador exige a concatenação manual do prefixo
data_uri = f"data:image/jpeg;base64,{b64}"
# <img src="{{ data_uri }}">
# ✓ Correto: Salvar no disco pelo servidor
with open("output.jpg", "wb") as f:
f.write(base64.b64decode(b64))
Detalhamento completo dos parâmetros da API oficial do gpt-image-2
Dominar a faixa de valores e os cenários de aplicação de cada parâmetro é fundamental para colocar o gpt-image-2 em produção através da API oficial.

Tabela de parâmetros principais para integração da API oficial do gpt-image-2
| Parâmetro | Valor | Padrão | Descrição |
|---|---|---|---|
model |
"gpt-image-2" |
Obrigatório | ID do modelo |
prompt |
String | Obrigatório | Comando, suporta mistura de chinês e inglês |
size |
8 predefinições + personalizado | auto |
Veja a tabela abaixo |
quality |
auto / low / medium / high |
auto |
Afeta custo e tempo de processamento |
output_format |
png / jpeg / webp |
png |
Recomendado jpeg + compressão 90 |
output_compression |
1-100 | 100 | Válido apenas para jpeg/webp |
moderation |
auto / low |
auto |
low reduz a sensibilidade da moderação |
n |
1-10 | 1 | Quantidade de geração por vez |
Opções completas do parâmetro size para a API oficial do gpt-image-2
# 8 predefinições oficiais
size = "1024x1024" # 1:1 Quadrado padrão
size = "1536x1024" # 3:2 Paisagem
size = "1024x1536" # 2:3 Retrato
size = "2048x2048" # 2K Quadrado
size = "2048x1152" # 16:9 Paisagem (ideal para papéis de parede/posters)
size = "3840x2160" # 4K Paisagem
size = "2160x3840" # 4K Retrato (ideal para papéis de parede de celular)
size = "auto" # Seleção automática pelo modelo
Se precisar de tamanhos personalizados, você deve atender às seguintes restrições:
✓ O comprimento do lado deve ser múltiplo de 16
✓ Comprimento máximo do lado ≤ 3840px
✓ Proporção entre lados ≤ 3:1
✓ Pixels totais entre 655.360 e 8.294.400
Por exemplo, 1280x720 (720P) é permitido, enquanto 3840x1080 (ultrawide) será rejeitado por exceder a proporção de 3:1.
Comparação de qualidade e custo da API oficial do gpt-image-2
O parâmetro quality é o que mais impacta o custo. Abaixo está a tabela de preços completa (por imagem).
| Qualidade | 1024×1024 | 1024×1536 | 1536×1024 | Cenário de uso |
|---|---|---|---|---|
low |
$0.006 | $0.005 | $0.005 | Rascunhos, miniaturas, iteração rápida |
medium |
$0.053 | $0.041 | $0.041 | Sites de conteúdo, imagens para redes sociais |
high |
$0.211 | $0.165 | $0.165 | Imagens de produtos, posters, materiais publicitários |
💰 Otimização de custos: Equipes de conteúdo que geram 100 imagens por dia economizam 75% usando a qualidade
mediumem vez dahigh. Recomendamos usar a plataforma APIYI (apiyi.com) para ajustar os comandos com a qualidadelowprimeiro e, após a aprovação, subir paramedium/highpara a imagem final, o que pode reduzir o orçamento mensal de geração de imagens em 30-50%.
Escolha do output_format na API oficial do gpt-image-2
O formato de saída impacta diretamente o custo de armazenamento e a velocidade de carregamento:
# Precisa de fundo transparente? O gpt-image-2 não suporta, retornará erro 400
# ✗ output_format="png", background="transparent" → 400 Bad Request
# Exibição em sites/apps: jpeg + compressão 90
output_format="jpeg", output_compression=90
# Arquivamento de alta fidelidade: png (sem perdas)
output_format="png"
# Aplicações Web modernas: webp tem o menor tamanho
output_format="webp", output_compression=85
Além da geração de imagens (texto para imagem), o gpt-image-2 também suporta três cenários principais de edição: edição de imagens, fusão de múltiplas imagens e repintura local (inpainting/outpainting).
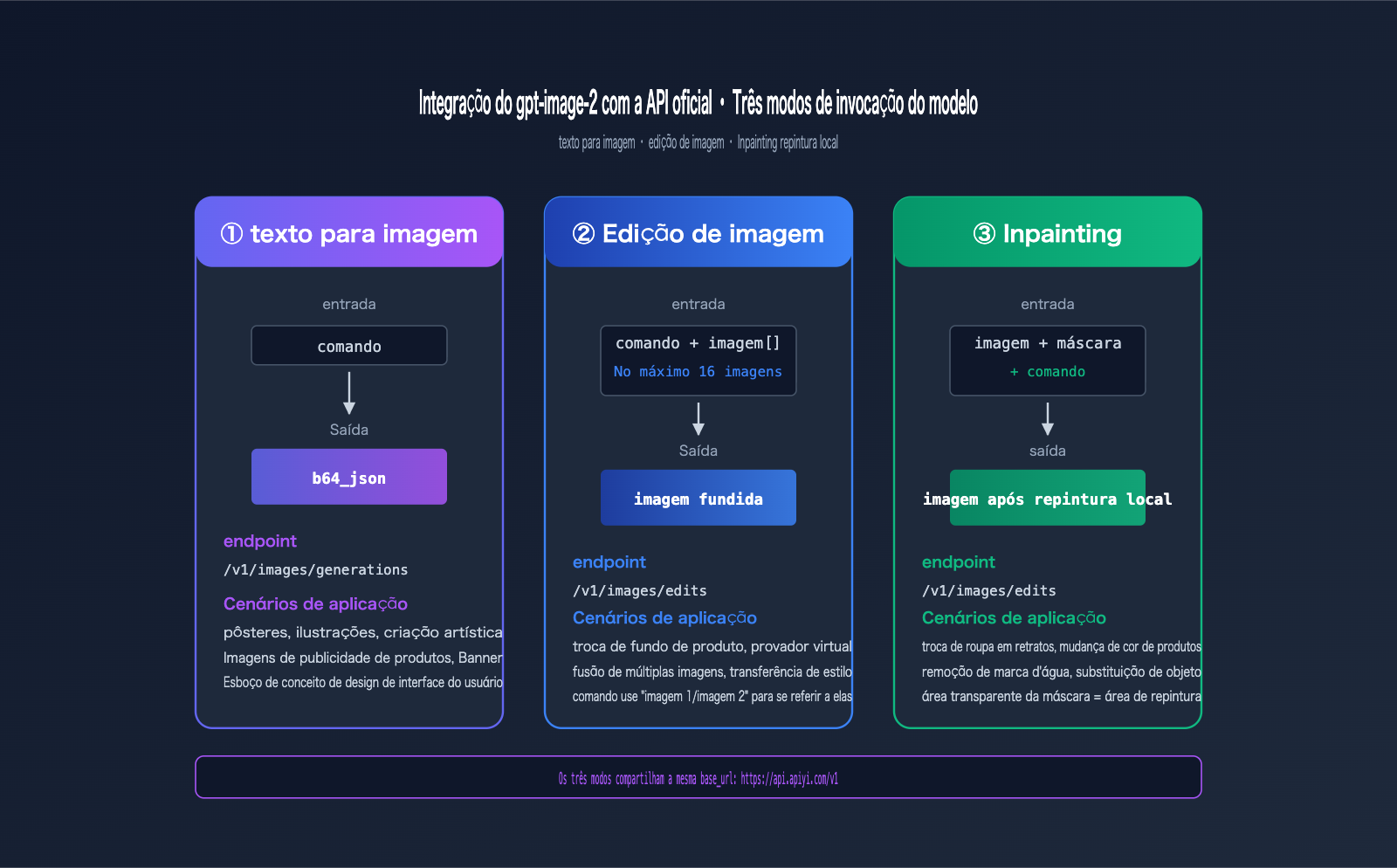
Edição de imagem com gpt-image-2 via API oficial (modo de imagem de referência)
A edição com imagem de referência ativa automaticamente o modo high-fidelity — portanto, não envie o parâmetro input_fidelity (ele será rejeitado).
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("APIYI_KEY"),
base_url="https://api.apiyi.com/v1"
)
# Edição de uma única imagem de referência
with open("source.jpg", "rb") as img:
response = client.images.edit(
model="gpt-image-2",
image=img,
prompt="Mude o fundo para uma praia ao pôr do sol, mantendo a postura e as roupas da pessoa em primeiro plano",
size="1024x1024",
quality="high"
)
Fusão de múltiplas imagens com gpt-image-2 via API oficial (até 16 imagens)
O endpoint /images/edits suporta a entrada de até 16 imagens de referência simultaneamente; no comando, utilize "imagem1/imagem2/imagem3" para se referir a elas.
images = [
open("character.jpg", "rb"), # Imagem 1: Personagem
open("background.jpg", "rb"), # Imagem 2: Fundo
open("outfit.jpg", "rb"), # Imagem 3: Referência de vestuário
]
response = client.images.edit(
model="gpt-image-2",
image=images,
prompt="Coloque o personagem da imagem 1 no fundo da imagem 2, fazendo com que o personagem vista o estilo de roupa da imagem 3, mantendo uma qualidade cinematográfica",
size="2048x1152",
quality="high"
)
Essa capacidade é extremamente poderosa para cenários como troca de fundo em produtos de e-commerce, provadores virtuais e geração de storyboards para quadrinhos.
Inpainting (repintura local) com gpt-image-2 via API oficial
O Inpainting especifica a área a ser repintada através do parâmetro mask. Regras fundamentais:
- A máscara deve ter a mesma dimensão da primeira imagem de referência.
- A máscara deve ser um PNG com canal alfa.
- Área transparente = área a ser repintada.
- Área opaca = manter a imagem original.
with open("photo.png", "rb") as img, open("mask.png", "rb") as msk:
response = client.images.edit(
model="gpt-image-2",
image=img,
mask=msk,
prompt="Substitua a área do quadro vermelho por um gato laranja",
size="1024x1024",
quality="high"
)
Se você precisar gerar a máscara programaticamente em Python, pode usar a biblioteca PIL:
from PIL import Image
# Cria uma máscara com as mesmas dimensões da imagem original, padrão toda preta (opaca = manter)
mask = Image.new("RGBA", (1024, 1024), (0, 0, 0, 255))
# Torna a área a ser repintada transparente (alfa=0)
for x in range(400, 700):
for y in range(300, 600):
mask.putpixel((x, y), (0, 0, 0, 0))
mask.save("mask.png")
Práticas de tratamento de erros e produção para a integração da API oficial do gpt-image-2
Ao colocar o gpt-image-2 em produção via API oficial, é fundamental lidar bem com três pilares: códigos de erro, concorrência e timeouts.
Tabela completa de códigos de erro para a API oficial do gpt-image-2
| Código HTTP | Significado | Tratamento recomendado |
|---|---|---|
400 |
Parâmetros inválidos (tamanho fora do limite, campos não suportados) | Valide a entrada; não envie input_fidelity ou background:transparent |
401 |
Token inválido | Verifique o Bearer Token e confirme se não expirou |
403 |
Bloqueio por moderação de conteúdo | Ajuste o comando ou adicione moderation: "low" |
429 |
Limite de taxa excedido / saldo insuficiente | Tente novamente com recuo exponencial + verifique o saldo |
5xx |
Erro no gateway ou backend | Tente novamente 1-2 vezes; se falhar, emita um alerta |
| Timeout | Requisição demorada sem resposta | Defina o timeout do cliente para ≥ 360 segundos |
Recuo exponencial para a API oficial do gpt-image-2
Abaixo, um exemplo de implementação de nível de produção para lidar com erros 429 e 5xx:
import time
import random
from openai import OpenAI, RateLimitError, APIStatusError
client = OpenAI(
api_key=os.getenv("APIYI_KEY"),
base_url="https://api.apiyi.com/v1",
timeout=600.0
)
def generate_with_retry(prompt: str, max_retries: int = 5):
delay = 1.0
for attempt in range(max_retries):
try:
return client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1024",
quality="high"
)
except RateLimitError:
sleep = delay + random.uniform(0, 0.5)
print(f"429 Limite de taxa, tentando novamente em {sleep:.1f}s ({attempt+1}/{max_retries})")
time.sleep(sleep)
delay *= 2
except APIStatusError as e:
if 500 <= e.status_code < 600 and attempt < max_retries - 1:
time.sleep(delay)
delay *= 2
continue
raise
raise RuntimeError("Número máximo de tentativas excedido")
Controle de concorrência para a API oficial do gpt-image-2
Para tarefas em lote, utilize asyncio.Semaphore para limitar a concorrência e evitar sobrecarregar o serviço:
import asyncio
from openai import AsyncOpenAI
aclient = AsyncOpenAI(
api_key=os.getenv("APIYI_KEY"),
base_url="https://api.apiyi.com/v1",
timeout=600.0
)
async def gen_one(prompt: str, sem: asyncio.Semaphore):
async with sem:
return await aclient.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1024",
quality="medium"
)
async def batch(prompts: list[str], concurrency: int = 30):
sem = asyncio.Semaphore(concurrency)
return await asyncio.gather(*[gen_one(p, sem) for p in prompts])
# Gerar 200 imagens, com 30 conexões simultâneas
prompts = [f"Variante de imagem de produto #{i}" for i in range(200)]
results = asyncio.run(batch(prompts))
Estimativa de custos para a API oficial do gpt-image-2
Faça uma estimativa de custos antes de ir para a produção. Abaixo, exemplos de cenários típicos:
| Cenário de negócio | Volume diário | Qualidade | Custo mensal estimado |
|---|---|---|---|
| Imagens para redes sociais | 30 imagens | medium | ~$48 |
| Imagens de produtos (e-commerce) | 200 imagens | high | ~$1266 |
| Geração de imagens para usuários SaaS | 1000 vezes | medium | ~$1590 |
| Frames-chave para jogos | 500 imagens | high | ~$3165 |
🎯 Dica de implantação: Recomendamos solicitar tokens de API independentes para diferentes linhas de negócio para facilitar a atribuição de custos e o isolamento de limites. Sugerimos configurar alertas de fatura no painel da APIYI (apiyi.com) para notificar automaticamente quando o consumo mensal atingir o limite, evitando estouros de orçamento.
Observabilidade para a API oficial do gpt-image-2
Em ambiente de produção, registre indicadores críticos de cada requisição:
import time
import logging
logger = logging.getLogger("gpt-image-2")
def call_with_metrics(prompt: str, **params):
start = time.perf_counter()
try:
resp = client.images.generate(model="gpt-image-2", prompt=prompt, **params)
latency = time.perf_counter() - start
logger.info(
"gpt-image-2 ok",
extra={
"latency_ms": int(latency * 1000),
"size": params.get("size"),
"quality": params.get("quality"),
"n": params.get("n", 1)
}
)
return resp
except Exception as e:
logger.error(f"gpt-image-2 falhou: {type(e).__name__}: {e}")
raise
FAQ: Perguntas frequentes sobre a integração da API oficial do gpt-image-2
P1: Por que recebo erro 400 ao usar input_fidelity no gpt-image-2?
O gpt-image-2 ativa automaticamente o high-fidelity em todos os cenários de edição, portanto o parâmetro input_fidelity é rejeitado. Basta removê-lo. Se o seu código veio de uma migração do gpt-image-1, faça uma busca global para removê-lo. Recomendamos comparar as diferenças de parâmetros entre os modelos na documentação da APIYI: docs.apiyi.com.
P2: Por que a invocação do modelo gpt-image-2 frequentemente apresenta timeout?
Qualidade high + imagens 2K/4K levam de 3 a 5 minutos para processar. Se o timeout padrão do seu cliente for de 60 segundos, ele falhará. Solução: defina o timeout para 360-600 segundos. No SDK Python, use OpenAI(timeout=600), no Node.js use timeout: 600_000 e no cURL use --max-time 600.
P3: Como exibir o b64_json retornado pela API diretamente na página web?
A API retorna uma string base64 pura sem prefixo, que o navegador não consegue renderizar diretamente. Você precisa concatenar:
const dataUri = `data:image/${format};base64,${b64}`;
imgElement.src = dataUri;
Se for um serviço de backend, recomendamos decodificar o base64 e salvar em um OSS/CDN, enviando apenas a URL para o frontend, evitando que strings base64 pesadas afetem o tempo de carregamento da página. Recomendamos testar via cURL + decodificação base64 localmente na plataforma APIYI (apiyi.com) antes de implementar a arquitetura completa de armazenamento.
P4: O gpt-image-2 suporta fundo transparente?
Atualmente, o gpt-image-2 não suporta fundo transparente; enviar background: "transparent" resultará em um erro 400. Solução alternativa: gere uma imagem com fundo branco/verde e use uma biblioteca de cliente (como rembg) para remover o fundo.
P5: Como usar o parâmetro thinking no gpt-image-2?
thinking é um parâmetro de raciocínio introduzido no gpt-image-2 (off / low / medium / high). Ao ativar, o modelo planeja o layout antes de gerar, resultando em maior qualidade, mas com custo significativamente maior (o modo high custa cerca de 4-5 vezes o valor base). Sugestão: use medium apenas para pôsteres com muito texto ou composições complexas; em cenários comuns, mantenha off. Recomendamos realizar testes A/B via interface da APIYI antes de ativar permanentemente.
P6: O que fazer ao encontrar erro 403 de moderação de conteúdo?
Tente adicionar moderation: "low" na requisição para reduzir a sensibilidade. Se ainda for bloqueado, significa que o comando disparou políticas de segurança centrais (violência, conteúdo impróprio para menores, retratos de figuras públicas, etc.), sendo necessário reescrever o comando. Nota: moderation: "low" não desativa a moderação, apenas a flexibiliza.
P7: O que acontece se o base_url estiver incorreto?
Se você escrever https://api.apiyi.com (sem o /v1), o SDK concatenará para api.apiyi.com/images/generations, resultando em um erro 404. O correto é https://api.apiyi.com/v1. No Python, use base_url; no Node.js, use baseURL (atenção às maiúsculas).
P8: Qual a melhor prática para fusão de múltiplas imagens no gpt-image-2?
É possível usar até 16 imagens de referência, referenciando-as no comando como "Imagem 1/Imagem 2". Dicas essenciais:
- A primeira imagem de referência geralmente atua como o "sujeito", e o modelo priorizará a preservação de sua estrutura.
- Comandos complexos podem ser divididos: primeiro defina "use a Imagem 1 como sujeito", depois "mescle com o tom da Imagem 2".
- A edição de múltiplas imagens custa 1,5 a 2 vezes mais que a geração de texto para imagem; use com cautela em cenários sensíveis a custos.
- Recomendamos validar a lógica com 2-3 imagens antes de expandir para mais referências.
Resumo: Revisão da jornada completa de integração do gpt-image-2 com a API oficial
Ao percorrer os 9 capítulos deste guia, você deve ter dominado o método de engenharia completo para a integração do gpt-image-2 com a API oficial:
- ✅ Preparação —— Atualize o SDK para a versão mais recente e defina o tempo limite (timeout) para ≥ 360 segundos.
- ✅ Configuração da base_url —— Substitua por
https://api.apiyi.com/v1; o restante do código permanece idêntico ao oficial. - ✅ Invocação de texto para imagem —— Modelos em três linguagens: Python, Node.js e cURL.
- ✅ Detalhes dos parâmetros —— 8 predefinições de tamanho + customização, 3 níveis de qualidade e 3 opções de formato de saída.
- ✅ Edição de imagens —— Até 16 imagens de referência, usando "img1/img2" no comando para identificação.
- ✅ Inpainting (Repintura) —— Uso do canal alfa da máscara para repintar áreas transparentes.
- ✅ Tratamento de erros —— Soluções completas para códigos 400/401/403/429/5xx.
- ✅ Prática de produção —— Backoff exponencial, controle de concorrência, estimativa de custos e observabilidade.
Por fim, uma sugestão prática: comece executando um "hello world" com qualidade low e resolução 1024×1024 antes de aumentar a complexidade. Isso permite identificar rapidamente problemas básicos como versão do SDK, timeout ou chave API, evitando desperdiçar tempo de depuração em requisições complexas de alta qualidade (high + 4K).
Se sua equipe está avaliando a solução de integração do gpt-image-2 ou já está escrevendo a primeira versão do código e encontrou erros de parâmetros ou timeout, recomendo solicitar uma chave de teste através do APIYI (apiyi.com) e rodar os modelos de código deste artigo. Todos os exemplos são baseados no SDK oficial + serviço proxy de API da APIYI (campos 100% compatíveis), oferecendo alta versatilidade para reutilização direta em seus próprios projetos.
Referências
-
Documentação do modelo OpenAI gpt-image-2: Informações oficiais sobre capacidades, parâmetros e preços.
- Link:
developers.openai.com/api/docs/models/gpt-image-2 - Descrição: Inclui recursos principais como renderização 4K, texto em nível de caractere e integração de raciocínio.
- Link:
-
Guia de Geração de Imagens da OpenAI: Fluxo de trabalho completo para texto para imagem, edição e inpainting.
- Link:
developers.openai.com/api/docs/guides/image-generation - Descrição: Abrange a explicação detalhada de todos os parâmetros de tamanho/qualidade/formato.
- Link:
-
Referência da API Create Image da OpenAI: Campos completos do endpoint
/v1/images/generations.- Link:
developers.openai.com/api/reference/resources/images/methods/generate - Descrição: Referência oficial para campos de solicitação e resposta.
- Link:
-
Documentação oficial de integração da APIYI: Guia completo de integração do gpt-image-2.
- Link:
docs.apiyi.com/api-capabilities/gpt-image-2/overview - Descrição: Contém exemplos em cURL/Python/Node.js e tratamento de códigos de erro.
- Link:
-
OpenAI Cookbook · Rate Limits: Estratégias de backoff exponencial para erros 429.
- Link:
developers.openai.com/cookbook/examples/how_to_handle_rate_limits - Descrição: Modelo de código recomendado oficialmente para lidar com limites de taxa.
- Link:
Autor: Equipe Técnica da APIYI
Data de publicação: 27 de abril de 2026
Palavras-chave: integração gpt-image-2 com API oficial, base_url, texto para imagem, edição de imagem, inpainting, APIYI, SDK OpenAI