
작성자 주: 추론, 코딩, 멀티모달, 가격 등 13가지 항목을 통해 Gemini 3.1 Pro와 Claude Opus 4.6을 심층 비교하고, 상황별 모델 선택 제안과 API 연동 가이드를 제공합니다.
2026년 2월, AI 모델 경쟁 구도는 진정한 '분열'의 시대를 맞이했습니다. 이제 더 이상 모든 분야에서 압도적인 1위란 존재하지 않습니다. Google이 2월 19일에 발표한 Gemini 3.1 Pro는 추론과 멀티모달 분야에서 신기록을 세웠고, Anthropic이 2월 5일에 선보인 Claude Opus 4.6은 전문가급 작업과 도구 호출(Tool Calling)에서 여전히 선두를 지키고 있습니다.
핵심 가치: 이 글을 읽고 나면, 두 최정상급 모델이 각각 어떤 상황에 강점을 가졌는지, 그리고 여러분의 필요에 가장 적합한 모델은 무엇인지 확실히 알게 될 것입니다.

Gemini 3.1 Pro vs Claude Opus 4.6 핵심 파라미터 비교
먼저 하드웨어 사양부터 살펴볼까요? 두 모델 모두 현재 AI 기술의 정점을 보여주지만, 설계 철학에서는 뚜렷한 차이를 보입니다.
| 비교 항목 | Gemini 3.1 Pro | Claude Opus 4.6 | 상세 비교 |
|---|---|---|---|
| 출시일 | 2026년 2월 19일 | 2026년 2월 5일 | Opus가 2주 먼저 출시됨 |
| 컨텍스트 윈도우 | 100만 토큰 (표준) | 100만 토큰 (Beta) | Gemini는 기본 지원, Opus는 베타에서 지원 |
| 최대 출력 | 64K 토큰 | 128K 토큰 | ✅ Opus가 2배 더 김 |
| 입력 모달리티 | 텍스트, 이미지, 오디오, 비디오, PDF | 텍스트, 이미지, PDF | ✅ Gemini의 멀티모달 지원이 더 광범위함 |
| 비디오 처리 | 최대 1시간 영상 | ❌ 미지원 | Gemini 독점 기능 |
| 오디오 처리 | 최대 8.4시간 음성 | ❌ 미지원 | Gemini 독점 기능 |
| 추론 모드 | 3단계 사고 (Low/Medium/High) | 적응형 사고 (동적 조절) | 설계 개념의 차이 |
| 입력 가격 | $2/백만 토큰 | $5/백만 토큰 | ✅ Gemini가 약 2.5배 저렴 |
| 출력 가격 | $12/백만 토큰 | $25/백만 토큰 | ✅ Gemini가 약 2배 저렴 |
🎯 사양 측면: Gemini 3.1 Pro는 멀티모달 능력과 가격 면에서 확실한 우위를 점하고 있으며, Claude Opus 4.6은 출력 길이(128K vs 64K)에서 앞서고 있습니다. 하지만 사양은 참고용일 뿐입니다. 진짜 차이는 벤치마크 데이터에서 드러나죠.
Gemini 3.1 Pro와 Opus 4.6 벤치마크 심층 비교
이번 포스팅의 가장 핵심적인 부분입니다. 추론, 코딩, 에이전트(Agent) 능력, 지식 작업의 네 가지 차원에서 항목별로 두 모델을 꼼꼼히 비교해 보겠습니다.
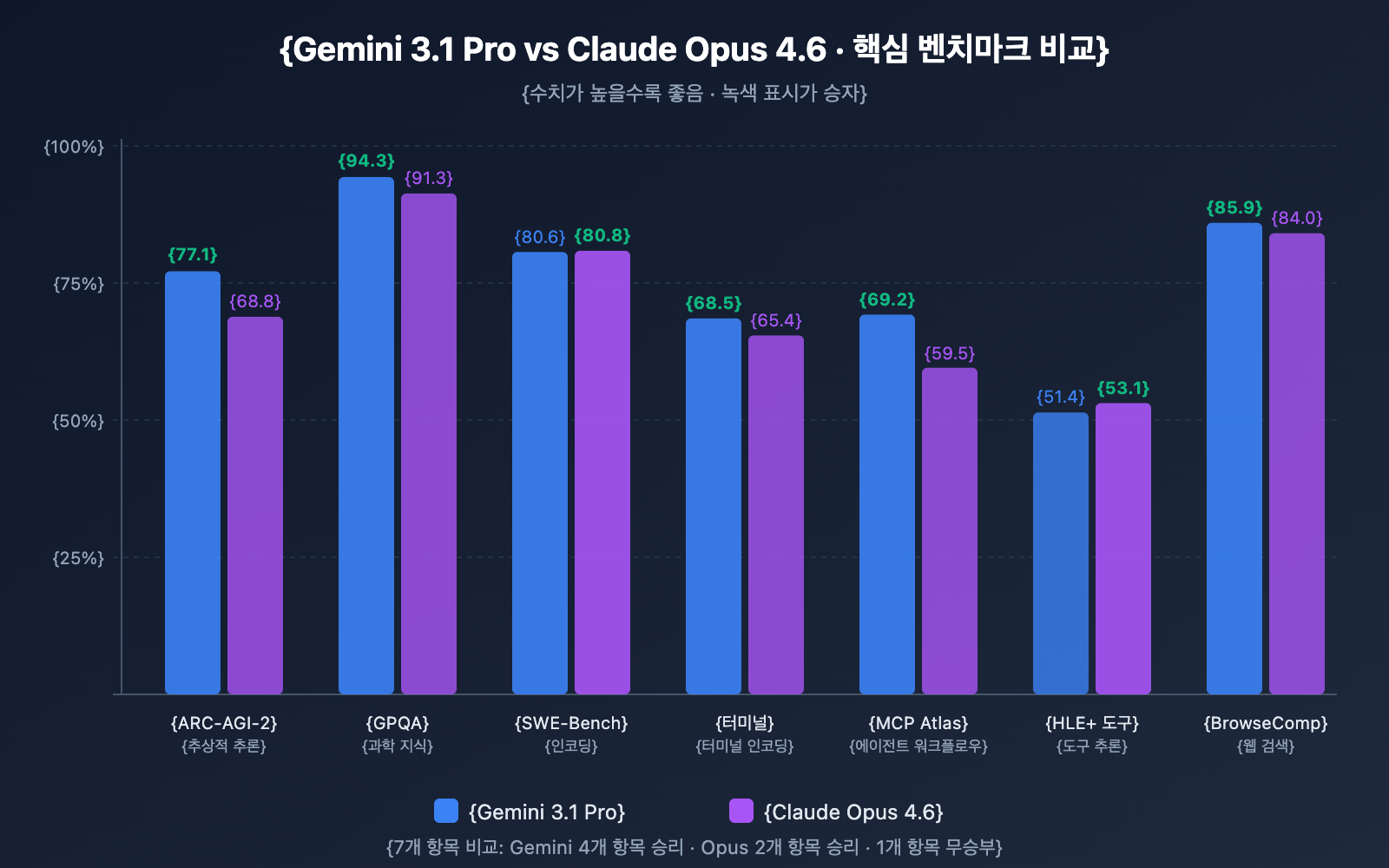
추론 능력 대비
| 추론 테스트 | Gemini 3.1 Pro | Claude Opus 4.6 | 승자 |
|---|---|---|---|
| ARC-AGI-2 (추상 추론) | 77.1% | 68.8% | ✅ Gemini 8.3점 우세 |
| GPQA Diamond (과학 지식) | 94.3% | 91.3% | ✅ Gemini 3.0점 우세 |
| HLE 도구 미사용 (최종 추론) | 44.4% | 40.0% | ✅ Gemini 4.4점 우세 |
| HLE 도구 사용 (도구 보조 추론) | 51.4% | 53.1% | ✅ Opus 1.7점 우세 |
분석: Gemini 3.1 Pro는 순수 추론 작업에서 전반적으로 앞서고 있습니다. 특히 ARC-AGI-2의 77.1%는 이전 세대인 Gemini 3.0 Pro(31.1%)보다 무려 2.5배나 향상된 수치입니다. 하지만 도구 사용이 허용될 경우 Opus 4.6이 역전하는데, 이는 Opus가 도구를 추론의 확장 도구로 활용하는 데 더 능숙하다는 것을 보여줍니다.
코딩 능력 대비
| 코딩 테스트 | Gemini 3.1 Pro | Claude Opus 4.6 | 승자 |
|---|---|---|---|
| SWE-Bench Verified | 80.6% | 80.8% | ✅ Opus 미세 우세 |
| Terminal-Bench 2.0 | 68.5% | 65.4% | ✅ Gemini 3.1점 우세 |
분석: 코딩 분야에서 두 모델은 막상막하입니다. SWE-Bench Verified에서는 거의 차이가 없지만(0.2% 차이), 터미널 환경 코딩을 평가하는 Terminal-Bench 2.0에서는 Gemini 3.1 Pro가 3.1점 앞섰습니다. 참고로 OpenAI의 GPT-5.3-Codex는 Terminal-Bench에서 77.3%를 기록하며 두 모델을 모두 앞질렀습니다.
에이전트 및 도구 호출 능력 대비
| 에이전트 테스트 | Gemini 3.1 Pro | Claude Opus 4.6 | 승자 |
|---|---|---|---|
| MCP Atlas (멀티스텝 워크플로) | 69.2% | 59.5% | ✅ Gemini 9.7점 우세 |
| BrowseComp (웹 검색) | 85.9% | 84.0% | ✅ Gemini 1.9점 우세 |
| tau2-bench Retail (도구 호출) | – | 91.9% | Opus 데이터 우수 |
| OSWorld (운영체제 제어) | – | 72.7% | Opus 데이터 우수 |
분석: 멀티스텝 에이전트 워크플로를 평가하는 MCP Atlas에서 Gemini 3.1 Pro가 9.7점 차이로 앞선 것은 Model Context Protocol을 사용하는 개발자들에게 매우 중요한 신호입니다. 반면, Opus 4.6은 tau2-bench 도구 호출과 OSWorld 운영체제 제어에서 더 두드러진 성과를 보여주었습니다.
지식 작업 능력 대비
| 지식 테스트 | Gemini 3.1 Pro | Claude Opus 4.6 | 승자 |
|---|---|---|---|
| GDPval-AA Elo | 1317 | 1606 | ✅ Opus 289점 우세 |
분석: 실제 전문가 수준의 지식 작업 시나리오를 시뮬레이션하는 GDPval-AA에서 Opus 4.6은 1606 Elo를 기록하며 Gemini 3.1 Pro(1317점)를 압도했습니다. 289점의 차이는 체스나 바둑에서 프로와 아마추어의 차이만큼이나 큽니다. 이는 연구 분석, 보고서 작성, 금융 분석 등 고부가가치 지식 작업 환경에서 Opus 4.6이 질적으로 훨씬 우수하다는 것을 의미합니다.
Gemini 3.1 Pro와 Opus 4.6 시나리오별 선택 가이드
위 데이터를 바탕으로 두 모델의 적합한 사용 시나리오가 매우 명확해졌습니다.

Gemini 3.1 Pro를 선택해야 하는 5가지 시나리오
- 복잡한 추론 및 수학: ARC-AGI-2 점수 77.1%(8.3점 리드)를 기록했습니다. 3단계 사고 시스템을 통해 필요에 따라 추론 깊이를 조절할 수 있습니다.
- 멀티모달 처리: 비디오(1시간), 오디오(8.4시간)를 네이티브로 지원합니다. 비디오 분석이나 음성 전사 업무가 포함된다면 Gemini가 유일한 선택입니다.
- MCP 다단계 워크플로우: MCP Atlas 69.2%(9.7점 리드)를 기록했습니다. Model Context Protocol 기반의 에이전트 시스템을 구축한다면 Gemini가 더 안정적입니다.
- 비용 민감 시나리오: 입력 가격 $2 vs $5, 출력 가격 $12 vs $25로, 동일한 품질 대비 Gemini의 비용은 Opus의 약 40%~48% 수준에 불과합니다.
- 과학 및 학술 연구: GPQA Diamond 94.3%로, 전문가 수준의 과학 지식 문답에서 최고의 성능을 보여줍니다.
Claude Opus 4.6을 선택해야 하는 5가지 시나리오
- 전문가급 지식 작업: GDPval-AA 1606 Elo로 압도적인 우위를 점하고 있습니다. 연구 보고서, 금융 분석, 법률 문서 등 고부가가치 결과물 생성에 적합합니다.
- 긴 텍스트 생성: 최대 출력 128K 토큰(Gemini는 64K)을 지원합니다. 전체 문서나 긴 코드를 한 번에 생성해야 할 때 Opus가 더 유리합니다.
- 도구 강화 추론: HLE 도구 테스트 53.1%(1.7점 리드)를 기록했습니다. 외부 도구를 추론 체인의 확장으로 활용하는 능력이 뛰어납니다.
- 정확한 도구 호출: tau2-bench Retail 91.9%를 기록했습니다. 높은 정밀도의 함수 호출이 필요한 에이전트 시나리오(예: OpenClaw)에서 더 안정적입니다.
- 안전 중심 시나리오: Anthropic의 안전 정렬 기술은 최첨단 모델 중 가장 성숙해 있습니다. 민감한 콘텐츠를 처리할 때 제어력이 뛰어납니다.
Gemini 3.1 Pro 및 Opus 4.6 API 빠른 연동
간편 예시
APIYI 플랫폼을 이용하면 두 모델을 하나의 인터페이스로 사용할 수 있습니다. model 파라미터만 변경하면 됩니다.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Gemini 3.1 Pro 사용 (추론 및 멀티모달 성능 우수)
response = client.chat.completions.create(
model="gemini-3.1-pro",
messages=[{"role": "user", "content": "양자 얽힘의 물리적 원리를 설명해줘"}]
)
print(response.choices[0].message.content)
Claude Opus 4.6 호출 예시 및 다중 모델 전환 코드 보기
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Claude Opus 4.6 사용 (지식 작업 및 도구 호출 성능 우수)
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[{"role": "user", "content": "1분기 매출 분석 보고서를 작성해줘"}]
)
print(response.choices[0].message.content)
# 동적 모델 선택을 위한 래퍼 함수
def smart_call(prompt, task_type="general"):
model_map = {
"reasoning": "gemini-3.1-pro",
"multimodal": "gemini-3.1-pro",
"knowledge": "claude-opus-4-6",
"coding": "claude-opus-4-6",
"general": "gemini-3.1-pro", # 기본적으로 더 저렴한 모델 사용
}
return client.chat.completions.create(
model=model_map.get(task_type, "gemini-3.1-pro"),
messages=[{"role": "user", "content": prompt}]
)
팁: APIYI(apiyi.com) 플랫폼을 통해 Gemini 3.1 Pro와 Claude Opus 4.6을 동시에 연동하고, 하나의 API 키로 필요에 따라 전환하며 사용할 수 있습니다. 플랫폼에서 제공하는 무료 테스트 크레딧을 활용해 실제 사용 환경에서 두 모델의 효과를 직접 비교해 보시고 결정하세요.
Gemini 3.1 Pro와 Opus 4.6 비용 비교 분석
가격 차이는 많은 개발자가 모델을 선택할 때 가장 중요하게 고려하는 요소입니다. 월평균 1,000만 입력 토큰과 200만 출력 토큰을 사용하는 경우를 예로 들어 비교해 보겠습니다.
| 비용 항목 | Gemini 3.1 Pro | Claude Opus 4.6 | 차액 |
|---|---|---|---|
| 입력 비용 | $20 | $50 | Gemini $30 절감 |
| 출력 비용 | $24 | $50 | Gemini $26 절감 |
| 월 총비용 | $44 | $100 | Gemini 56% 절감 |
| 연 총비용 | $528 | $1,200 | Gemini $672 절감 |
추론과 멀티모달 위주의 시나리오라면, Gemini 3.1 Pro는 품질 저하를 거의 겪지 않으면서도 비용을 절반 이상 아낄 수 있습니다. 하지만 핵심 시나리오가 전문가 수준의 지식 작업(GDPval-AA 점수 차이 289점)이라면, Opus 4.6에 매달 $56를 더 투자하여 얻는 품질 향상은 충분히 가치가 있습니다.
🎯 절약 팁: APIYI(apiyi.com) 플랫폼을 통해 접속하면 할인된 가격으로 이용할 수 있습니다. 추천 전략은 Gemini 3.1 Pro를 기본 모델로 설정해 일상적인 요청을 처리하고, 지식 작업이나 정밀한 도구 호출이 필요한 시나리오에서만 Opus 4.6으로 전환하는 것입니다.
자주 묻는 질문 (FAQ)
Q1: Gemini 3.1 Pro의 ‘3단계 사고’와 Opus 4.6의 ‘적응형 사고’는 어떤 차이가 있나요?
Gemini 3.1 Pro는 개발자가 Low/Medium/High 세 가지 추론 레벨을 수동으로 설정하여 모델이 추론에 투입할 계산량을 제어할 수 있게 해줍니다. Medium 레벨은 이번에 새로 추가되었으며, 구글은 이를 '적당한 깊이의 사고'라고 부릅니다. 반면 Claude Opus 4.6의 적응형 사고는 모델이 작업에 필요한 추론 깊이를 스스로 판단하며, 개발자는 effort 파라미터를 통해 수동으로 개입할 수 있습니다. 두 방식 모두 개념은 비슷하지만 구현 방식이 다릅니다. Gemini는 수동 변속기, Opus는 자동 변속기에 가깝다고 볼 수 있습니다.
Q2: 두 모델을 동시에 사용할 수 있나요?
네, 가능합니다. APIYI(apiyi.com) 플랫폼을 통해 연동하는 것을 추천하며, 하나의 API 키로 두 모델을 모두 호출할 수 있습니다. 작업 유형에 따라 동적으로 라우팅해 보세요. 추론 및 멀티모달 작업은 Gemini 3.1 Pro(더 저렴함)로, 지식 작업 및 정밀한 도구 호출은 Claude Opus 4.6(더 강력함)으로 보내는 식입니다. 본문의 코드 예시에 있는 smart_call 함수가 바로 이런 패턴을 보여줍니다.
Q3: 코딩 시나리오에서는 어떤 모델을 선택해야 할까요?
두 모델의 코딩 능력은 거의 비슷합니다(SWE-Bench 차이 단 0.2%). 주로 터미널 환경에서의 코딩(CI/CD 스크립트, 명령줄 도구 등)이 목적이라면 Gemini 3.1 Pro가 Terminal-Bench에서 3.1점 앞서 있습니다. 만약 64K 토큰을 초과하는 긴 코드 파일을 생성해야 한다면, 128K 출력을 지원하는 Claude Opus 4.6이 더 적합합니다. 예산이 한정적이라면 Gemini 3.1 Pro의 코딩 능력만으로도 충분하며 비용은 절반 수준입니다. APIYI(apiyi.com)에서 두 모델을 언제든 테스트하고 비교해 보세요.
요약
Gemini 3.1 Pro와 Claude Opus 4.6의 비교 핵심 결론은 다음과 같습니다.
- 추론과 멀티모달은 Gemini 3.1 Pro: ARC-AGI-2에서 8.3점 앞서며, 비디오와 오디오를 네이티브로 지원합니다. 가격 또한 Opus의 40~48% 수준으로 경제적입니다.
- 지식 작업과 도구 호출은 Claude Opus 4.6: GDPval-AA에서 289점 앞서며, tau2-bench 도구 호출 성공률 91.9%, 최대 128K 출력을 지원하여 복잡한 업무에 유리합니다.
- 코딩 능력은 막상막하: SWE-Bench 점수 차이가 0.2%에 불과합니다. 예산이 한정적이라면 Gemini를 우선적으로 추천합니다.
2026년 2월 현재, AI 모델 시장은 각 모델의 '강점'이 뚜렷한 시대로 접어들었습니다. 가장 좋은 전략은 하나만 고집하는 것이 아니라, 상황에 맞춰 혼합해서 사용하는 것입니다. **APIYI(apiyi.com)**를 통해 두 모델을 동시에 연결하고, 필요에 따라 교체하며 사용하면 품질과 비용의 최적의 균형을 찾을 수 있습니다.
📚 참고 자료
-
Gemini 3.1 Pro 공식 블로그: Google의 발표 공지 및 기술 세부 사항
- 링크:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - 설명: Gemini 3.1 Pro의 전체 기능 소개와 3단계 사고 시스템을 확인할 수 있습니다.
- 링크:
-
Claude Opus 4.6 출시 공지: Anthropic 공식 기술 블로그
- 링크:
anthropic.com/news/claude-opus-4-6 - 설명: Opus 4.6의 전체 벤치마크 데이터와 적응형 사고(Adaptive Thinking) 기능을 확인할 수 있습니다.
- 링크:
-
Artificial Analysis 모델 비교: 제3자 독립 평가 플랫폼
- 링크:
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-claude-opus-4-6-adaptive - 설명: 성능, 속도, 가격에 대한 객관적인 횡적 비교 데이터를 제공합니다.
- 링크:
-
Google AI 개발자 문서: Gemini API 가격 및 연동 가이드
- 링크:
ai.google.dev/gemini-api/docs/pricing - 설명: Gemini 3.1 Pro의 최신 API 가격 정책과 무료 할당량을 확인할 수 있습니다.
- 링크:
작성자: 기술 팀
기술 교류: 댓글을 통해 두 모델을 사용해 본 경험을 자유롭게 공유해 주세요. 더 많은 AI 모델 정보는 **APIYI(apiyi.com)**에서 확인하실 수 있습니다.