
作者注:Qwen3.5-35B-A3B は、わずか 3B のアクティブパラメータで SWE-bench Verified において 69.2 点を記録しました。これは前世代の Qwen3-235B を凌駕するスコアであり、r/LocalLLaMA コミュニティではオープンソースがクローズドソースに追いついたマイルストーンとして注目されています。本記事では、その技術アーキテクチャと実用的な価値を深く分析します。
r/LocalLLaMA コミュニティで今、大きな話題になっていることがあります。それは、Qwen3.5-35B-A3B がわずか 3B のアクティブパラメータで SWE-bench Verified において 69.2 点を叩き出したことです。これは前世代の 235B パラメータを持つ Qwen3 を超えただけでなく、ローカル環境で実行可能なモデルとしてプログラミング能力の記録を塗り替えました。コミュニティでは、これをオープンソースモデルがクローズドソースに追いつく重要な兆候と捉えています。コンシューマー向けハードウェアで動作する 35B モデルが、GPT-5 mini レベルのプログラミング能力を備えているのです。
コアバリュー: 本記事を読めば、なぜ Qwen3.5-35B がオープンソースコミュニティでこれほど騒がれているのか、その MoE アーキテクチャがどのようにして「小さな体で大きな力」を実現しているのか、そしてローカルやクラウドでどのように活用できるのかが分かります。

Qwen3.5-35B 核心要点
| 要点 | 説明 | 意義 |
|---|---|---|
| 総パラメータ | 350億 (35B) | MoE アーキテクチャ |
| アクティブパラメータ | わずか 30億 (3B) | 究極の効率性 |
| SWE-bench Verified | 69.2 点 | Qwen3-235B を凌駕 |
| GPQA Diamond | 84.2 点 | 大学院レベルの推論 |
| コンテキストウィンドウ | ネイティブ 256K / 拡張 1M+ | YaRN 拡張 |
| 実行要件 | 22GB メモリ/VRAM | コンシューマー環境で利用可能 |
| オープンソースライセンス | Apache 2.0 | 完全オープン |
なぜ r/LocalLLaMA コミュニティで Qwen3.5-35B が議論されているのか
r/LocalLLaMA は Reddit 上で最も活発なローカル大規模言語モデルコミュニティであり、メンバーが注目している核心的な問いは「自分のハードウェアで動作し、かつ十分に強力なモデルはどれか?」という点です。
Qwen3.5-35B-A3B は、まさにこのニーズを射抜いています。
- 35B の総パラメータを持ちながら、推論ごとにアクティブになるのは 3B のみ。つまり、22GB メモリの Mac や GPU でスムーズに動作します。
- プログラミング能力(SWE-bench 69.2)は、パラメータ数が 7 倍の旧世代 Qwen3-235B を上回っています。
- Apache 2.0 で完全オープンソース化されており、商用利用の制限もありません。
コミュニティの評価は「Run Qwen 35B. It's a great chatbot, good enough for task automation.(Qwen 35B を動かしてみろ。素晴らしいチャットボットであり、タスク自動化には十分だ)」というものです。これは、ローカル環境でモデルを運用するユーザーの核心的な要求である「十分な性能、十分な速度、そして低コスト」を体現しています。
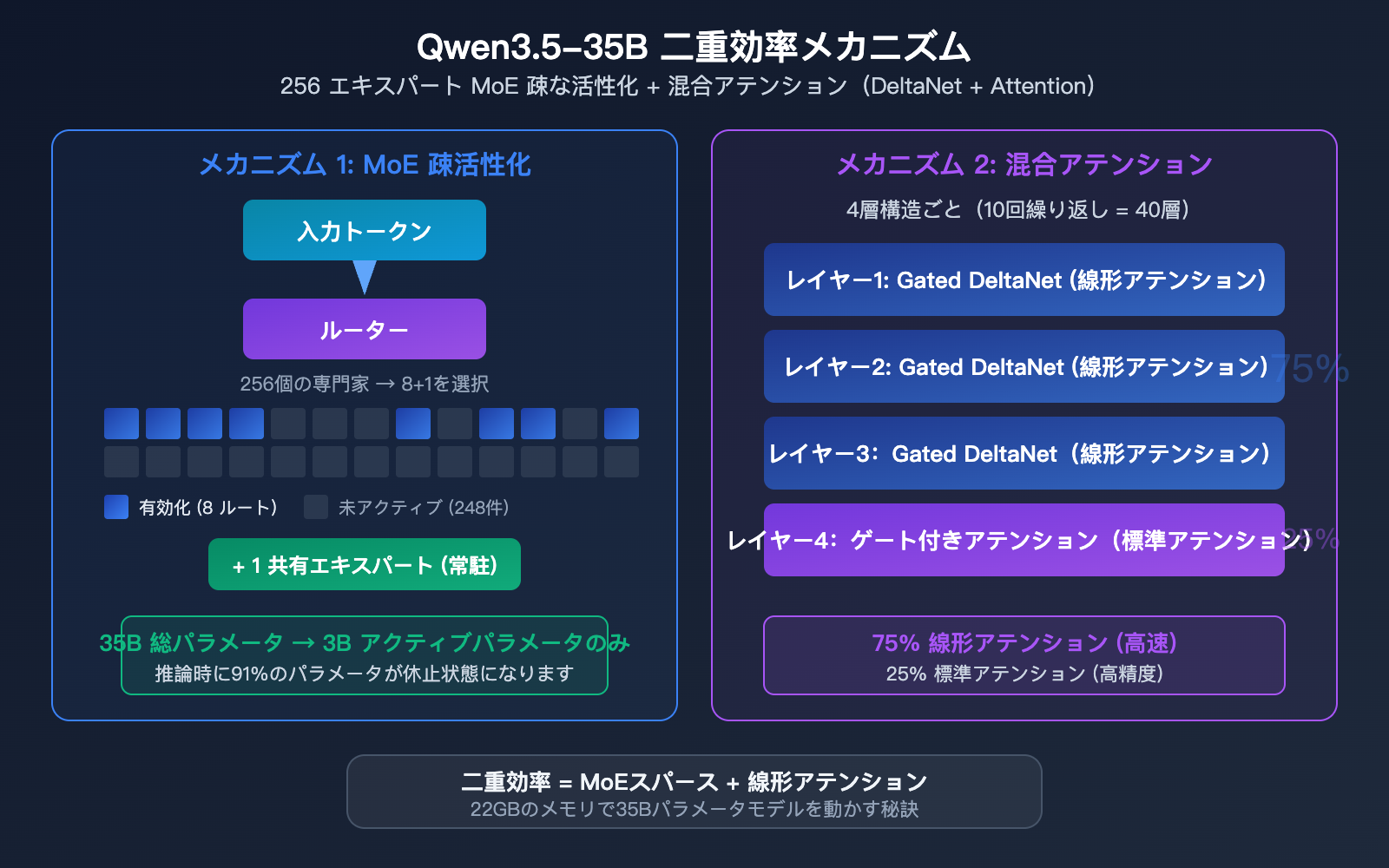
Qwen3.5-35B アーキテクチャ詳細解説
256個の専門家によるMoEアーキテクチャ
Qwen3.5-35B-A3Bは、非常に精密な混合専門家(MoE)アーキテクチャを採用しています。
| アーキテクチャパラメータ | 数値 | 説明 |
|---|---|---|
| 総パラメータ数 | 35B | 全専門家パラメータの合計 |
| アクティブパラメータ数 | 3B | 推論ごとにアクティブ化 |
| 専門家の総数 | 256個 | 超微細粒度の分業 |
| アクティブな専門家 | 8ルーティング + 1共有 | 毎回9個の専門家を選択 |
| 層数 | 40層 | 深層ネットワーク |
| 隠れ層の次元数 | 2048 | コンパクトな設計 |
混合アテンションメカニズム
Qwen3.5-35Bは純粋なTransformerではなく、混合アテンション設計を採用しています。
4層ごとの構造は、3層のGated DeltaNet(線形アテンション)+ 1層のGated Attention(標準アテンション)となっています。
| アテンションの種類 | 層の割合 | 特徴 |
|---|---|---|
| Gated DeltaNet | 75% | 線形アテンション、推論が高速 |
| Gated Attention | 25% | 標準アテンション、精度が高い |
この混合設計の巧妙な点は、計算の大部分を効率的な線形アテンションで処理し、重要な層でのみ計算量の多い標準アテンションを使用していることです。これが、35Bパラメータでありながらわずか22GBのメモリで動作する秘密です。専門家のスパース(疎)アクティベーションだけでなく、アテンションメカニズム自体も最適化されています。
🎯 技術的洞察: Qwen3.5-35Bのアーキテクチャ設計は、2026年のMoEモデルの最新トレンドである「256個の専門家による超微細粒度 + 混合アテンション」を象徴しています。このアーキテクチャによる効率向上を体験したい場合は、APIYI (apiyi.com) を通じてQwen3.5シリーズのAPIを直接呼び出すことができ、ローカル環境へのデプロイは不要です。
Qwen3.5-35B 評価データ徹底解説
Qwen3.5-35B プログラミング評価
| 評価ベンチマーク | Qwen3.5 35B-A3B | 比較参考 | 説明 |
|---|---|---|---|
| SWE-bench Verified | 69.2 | Qwen3-235B: <69 | 7倍の規模を持つ前世代を凌駕 |
| LiveCodeBench v6 | 74.6 | – | リアルタイムプログラミングに強み |
| CodeForces | 2,028 | – | 競技プログラミングレベル |
Qwen3.5-35B 推論・知識評価
| 評価ベンチマーク | Qwen3.5 35B-A3B | 説明 |
|---|---|---|
| GPQA Diamond | 84.2 | 大学院レベルの科学的推論 |
| MMLU-Pro | 85.3 | 多分野の知識 |
| MMLU-Redux | 93.3 | 知識理解 |
| HMMT Feb 2025 | 89.0 | 数学オリンピックレベル |
| IFEval | 91.9 | 指示追従能力 |
Qwen3.5-35B マルチモーダル評価
| 評価ベンチマーク | Qwen3.5 35B-A3B | 説明 |
|---|---|---|
| MMMU | 81.4 | マルチモーダル理解(Claude Sonnet 4.5の79.6に迫る) |
| MMMU-Pro | 75.1 | 高難易度マルチモーダル |
| MathVision | 83.9 | 視覚的数学推論 |
| VideoMME | 86.6 | 動画理解 |
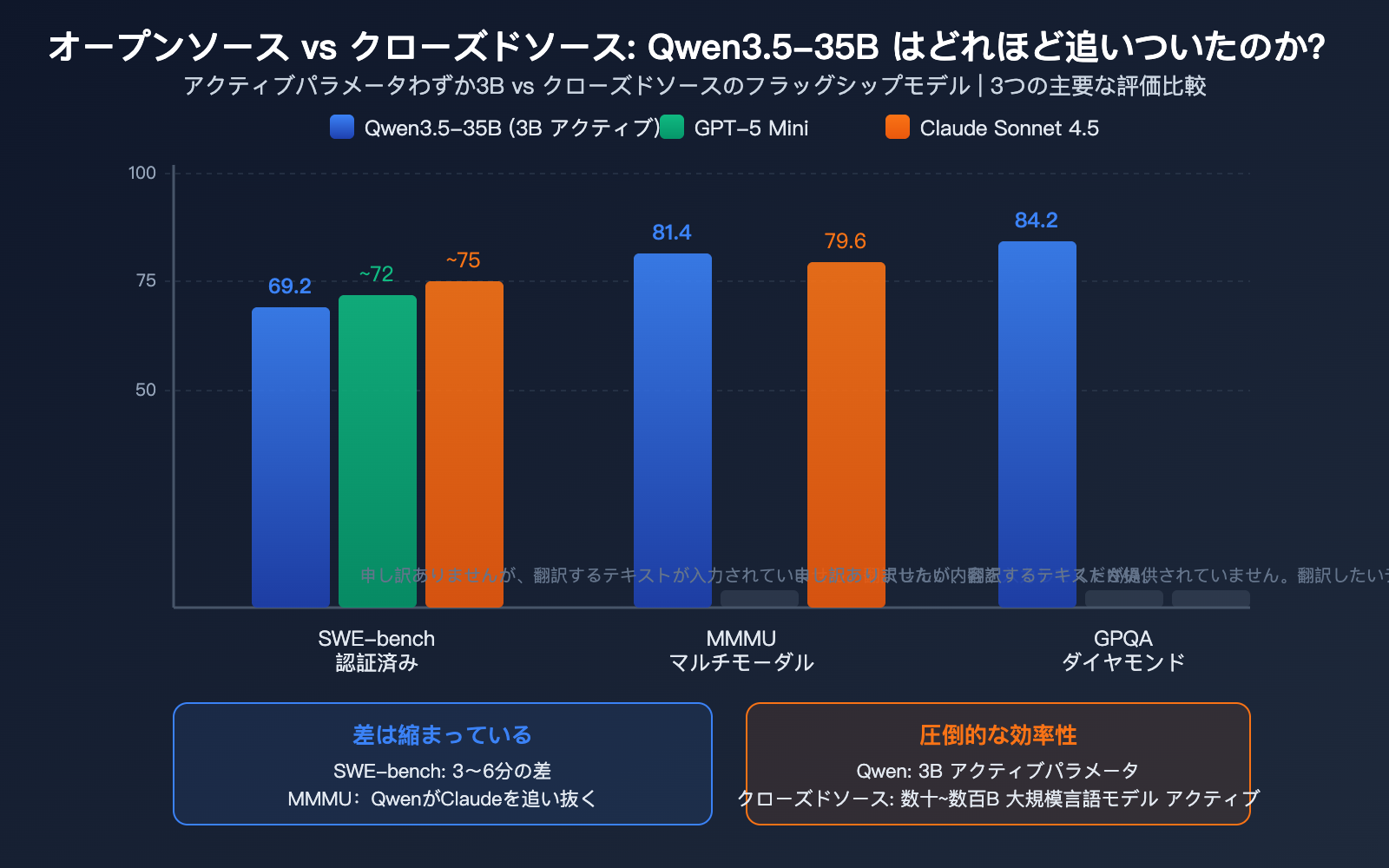
Qwen3.5-35B とクローズドモデルの比較
コミュニティで最も関心が高いのは、「35Bのオープンソースモデルが、どこまでクローズドモデルに追いつけるのか?」という点です。
| 次元 | Qwen3.5 35B | GPT-5 Mini | Claude Sonnet 4.5 | 差分 |
|---|---|---|---|---|
| SWE-bench | 69.2 | ~72 | ~75 | 3-6ポイント差 |
| MMMU | 81.4 | – | 79.6 | 逆転 |
| GPQA Diamond | 84.2 | – | – | トップクラス |
| アクティブパラメータ | 3B | ~数十B | 不明 | 圧倒的な効率 |
| ローカル実行 | 可能 (22GB) | 不可 | 不可 | 独自の強み |
コミュニティの核心的な見解: Qwen3.5-35B はプログラミングにおいて GPT-5 Mini クラスのモデルとの差を 3-6 ポイントまで縮めており、マルチモーダル分野では Claude Sonnet 4.5 を上回っています。わずか 3B のアクティブパラメータでローカル実行も可能であることを考えると、効率と能力の比率は公開されている全モデルの中で最高クラスと言えるでしょう。
💡 活用アドバイス: Qwen3.5-35B とクローズドモデルの実際の性能差を比較したい場合は、APIYI (apiyi.com) を通じて Qwen3.5、Claude、GPT を同時に呼び出し、自身のタスクで A/B テストを行うのがおすすめです。
Qwen3.5-35B ローカルデプロイガイド
ハードウェア要件とデプロイ方法
| デプロイ方法 | ハードウェア要件 | 推奨シーン |
|---|---|---|
| Ollama | 22GB+ RAM/VRAM | 最も簡単、ワンクリックで実行 |
| vLLM | GPU + 24GB+ VRAM | 本番環境レベルのスループット |
| SGLang | GPU + 24GB+ VRAM | 高スループット推奨 |
| KTransformers | CPU + GPU 混合 | 低スペックハードウェア |
| LM Studio | 22GB+ RAM | グラフィカルなUIで使いやすい |
Ollama によるワンクリックデプロイ
# インストール後、以下のコマンド1行で実行可能です
ollama run qwen3.5:35b
API 呼び出し(ローカルデプロイ不要)
ローカル環境の構築が面倒な場合は、API 経由での呼び出しが最も簡単です:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{
"role": "user",
"content": "このPythonコードをレビューして、パフォーマンスのボトルネックを見つけてください"
}],
temperature=0.6, # プログラミングタスクには 0.6 を推奨
max_tokens=32768
)
print(response.choices[0].message.content)
Thinking モードと非 Thinking モードの切り替え
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Thinking モード (高度な推論、複雑なタスクに適しています)
response_thinking = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{"role": "user", "content": "このアルゴリズムの時間計算量を分析してください"}],
temperature=1.0,
top_p=0.95,
max_tokens=32768
)
# 非 Thinking モード (高速な回答)
response_fast = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{"role": "user", "content": "クイックソートの関数を書いてください"}],
temperature=0.7,
top_p=0.8,
max_tokens=32768,
extra_body={"chat_template_kwargs": {"enable_thinking": False}}
)
🚀 デプロイのアドバイス: ローカルデプロイは、プライバシーが重要視される環境やオフライン環境に適しています。日常的な開発には、APIYI (apiyi.com) を通じた API 呼び出しをおすすめします。高速かつハードウェアのメンテナンスが不要で、Qwen3.5 と Claude、GPT を自由に切り替えて利用できます。
Qwen3.5 全モデルラインナップ一覧
Qwen3.5 シリーズのスペック比較
| モデル | 総パラメータ数 | アクティブパラメータ数 | SWE-bench | 最低メモリ | 特徴 |
|---|---|---|---|---|---|
| Qwen3.5-4B | 4B | 4B (Dense) | – | 8GB | 軽量・入門用 |
| Qwen3.5-9B | 9B | 9B (Dense) | – | 12GB | 高効率・日常用 |
| Qwen3.5-27B | 27B | 27B (Dense) | 72.4 | 22GB | 高密度・高精度 |
| Qwen3.5-35B-A3B | 35B | 3B (MoE) | 69.2 | 22GB | 効率の王様 |
| Qwen3.5-122B-A10B | 122B | 10B (MoE) | – | – | 中〜上位モデル |
| Qwen3.5-397B-A17B | 397B | 17B (MoE) | 76.4 | – | フラッグシップ |
選定のアドバイス:
- 22GB デバイス: 35B-A3B(MoE、高速だが精度はやや控えめ)または 27B(Dense、少し遅いがより高精度)
- 究極のコストパフォーマンス: 35B-A3B(推論ごとにわずか 3B パラメータを使用)
- 最高精度を追求: 27B Dense(MoE を使用しない高精度モデル)
🎯 API の選定: APIYI (apiyi.com) を通じて Qwen3.5 全シリーズを呼び出せます。4B から 397B まで、必要に応じて選択可能です。一つの API キーで、さまざまな規模の Qwen モデルや、Claude、GPT といったクローズドソースモデルを柔軟に切り替えられます。
よくある質問
Q1: Qwen3.5-35B と 27B、どちらを選ぶべきですか?
どちらも約 22GB のメモリが必要です。35B-A3B は MoE アーキテクチャ(3〜5倍高速ですが精度はわずかに劣ります)、27B は Dense アーキテクチャ(より高精度ですが低速)です。プログラミングタスクでは両者に大きな差はありません(SWE-bench で 69.2 対 72.4)。日常的な会話には 35B(高速)、精緻なタスクには 27B(高精度)をおすすめします。APIYI (apiyi.com) を通じて両方を呼び出し、比較することも可能です。
Q2: オープンソースモデルは本当にクローズドモデルに追いついていますか?
はい、ただし条件付きです。Qwen3.5-35B は MMMU において Claude Sonnet 4.5 を上回り(81.4 対 79.6)、SWE-bench では GPT-5 Mini との差をわずか 3 ポイントに縮めました。しかし、最高難度のプログラミングタスクや複雑な推論においては、クローズドモデルのフラッグシップ(Claude Opus 4.5、GPT-5.4)が依然として明確な優位性を持っています。オープンソースは差を縮めていますが、トップクラスのクローズドモデルに完全に並んだわけではありません。
Q3: 22GB メモリの Mac で Qwen3.5-35B は動かせますか?
可能です。Qwen3.5-35B-A3B は推論時に 3B のパラメータのみをアクティブにするため、22GB のユニファイドメモリを搭載した Mac(M2/M3/M4 のベース構成など)でスムーズに動作します。Ollama(ollama run qwen3.5:35b)を使用したワンクリック起動がおすすめです。ローカル環境へのデプロイが難しい場合は、APIYI (apiyi.com) を経由したクラウド呼び出しがより便利です。
まとめ
Qwen3.5-35B がオープンソースのプログラミング分野で新記録を打ち立てた 5 つのポイント:
- 効率の革命: 総パラメータ 35B に対してアクティブパラメータはわずか 3B。22GB で動作し、前世代の 235B モデルを超えるプログラミング能力を実現。
- プログラミングの実力: SWE-bench 69.2、CodeForces 2028、LiveCodeBench 74.6 を記録し、ローカルモデルの新たな基準に。
- アーキテクチャの革新: 256 エキスパートの MoE とハイブリッドアテンション(DeltaNet + 標準 Attention)を組み合わせ、効率と能力のベストバランスを実現。
- オープンソースの躍進: MMMU で Claude Sonnet 4.5 を超え、SWE-bench では GPT-5 Mini に肉薄するなど、差が着実に縮小。
- 完全オープン: Apache 2.0 ライセンスで商用利用の制限がなく、ローカルデプロイのコストはゼロ。
Qwen3.5-35B は一つの事実を証明しました。それは、オープンソースモデルはもはやクローズドモデルの廉価版ではなく、より高い効率で追いつき、追い越そうとしているということです。APIYI (apiyi.com) を通じて Qwen3.5 シリーズとクローズドモデルの両方にアクセスし、一つの API キーで実際のタスクにおけるパフォーマンスの違いを比較してみてください。
📚 参考資料
-
Qwen3.5-35B-A3B モデルカード – Hugging Face: 技術パラメータと評価データの詳細
- リンク:
huggingface.co/Qwen/Qwen3.5-35B-A3B - 説明: アーキテクチャの詳細、評価スコア、推奨される推論パラメータを掲載
- リンク:
-
Qwen3.5 GitHub リポジトリ: オープンソースコードとデプロイガイド
- リンク:
github.com/QwenLM/Qwen3.5 - 説明: モデルの重みデータのダウンロードおよびデプロイ用ドキュメント
- リンク:
-
Qwen3.5 完全ガイド: 全シリーズの評価とアーキテクチャ分析
- リンク:
techie007.substack.com/p/qwen-35-the-complete-guide-benchmarks - 説明: ファミリーモデルの比較およびクローズドソースモデルとの横並び評価
- リンク:
-
Ollama – Qwen3.5:35B: ローカル環境へのワンクリックデプロイ
- リンク:
ollama.com/library/qwen3.5:35b - 説明: 最も手軽なローカル実行方法
- リンク:
著者: APIYI 技術チーム
技術交流: Qwen3.5 のローカルデプロイ体験をぜひコメント欄でシェアしてください。その他の AI モデル接続に関する資料は、APIYI ドキュメントセンター(docs.apiyi.com)をご覧ください。