
Note de l'auteur : Détails sur la façon de construire un pipeline de contrôle qualité pour les problèmes de physique avec les trois grands modèles de langage Gemini 3.1 Pro, Claude Sonnet 4.6 et GPT-5.4, incluant des modèles de prompts complets et des exemples de code.
L'utilisation de grands modèles de langage pour le contrôle qualité des problèmes de physique est une direction de plus en plus suivie par les institutions éducatives et les plateformes d'apprentissage en ligne. La correction manuelle traditionnelle est non seulement inefficace, mais aussi limitée par les différences subjectives entre les correcteurs. Cet article explique comment utiliser les trois modèles de raisonnement les plus puissants de 2026 — Gemini 3.1 Pro Preview, Claude Sonnet 4.6 et GPT-5.4 — pour construire un système automatisé de contrôle qualité des problèmes de physique avec un taux de précision élevé.
Valeur clé : Après avoir lu cet article, vous maîtriserez le flux de travail complet du contrôle qualité des problèmes de physique par les grands modèles — de la conception du prompt à la validation croisée multi-modèles, pour établir une solution automatisée avec un taux de précision supérieur à 90 %.
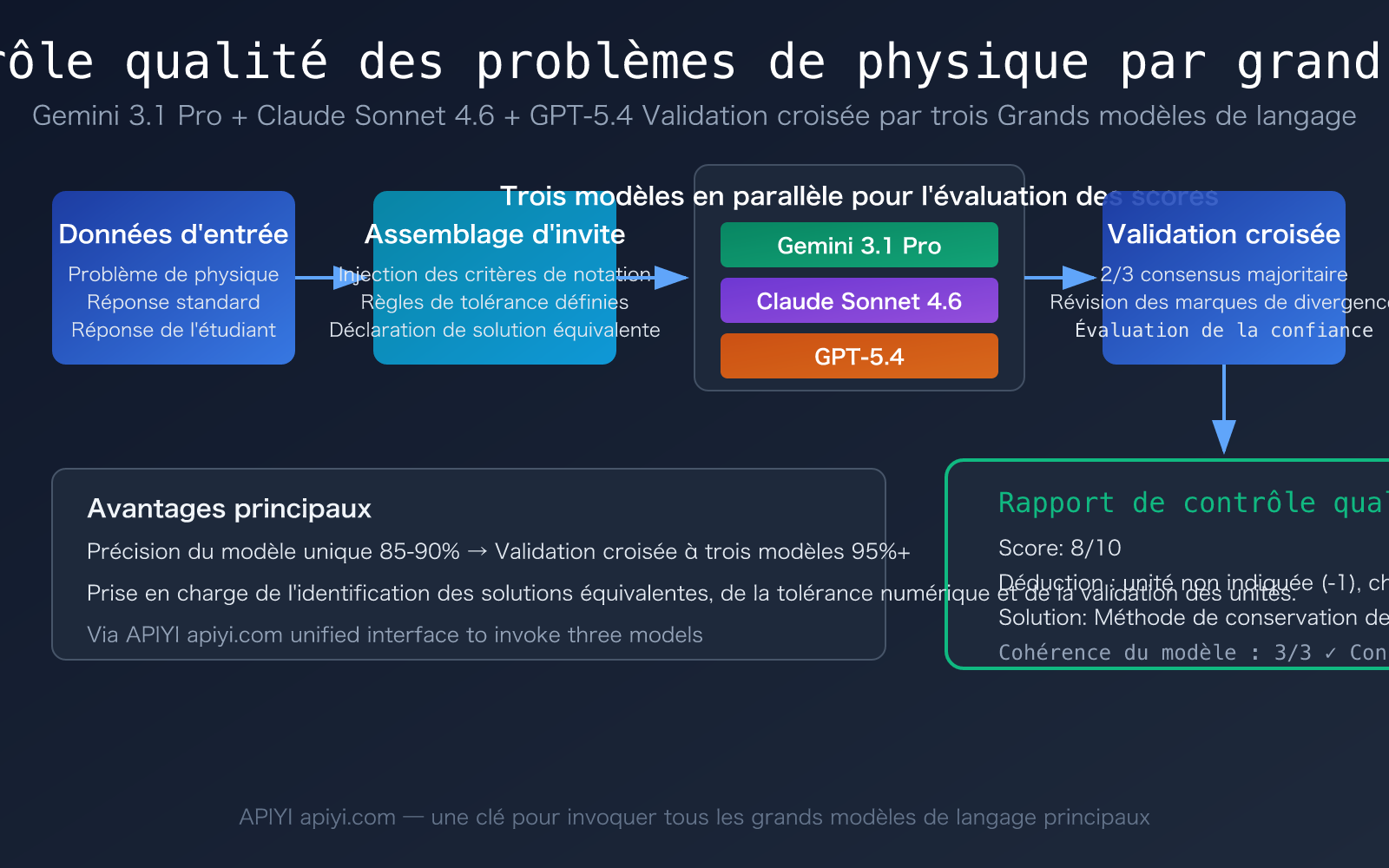
Points clés du contrôle qualité des problèmes de physique par les grands modèles
Le contrôle qualité des problèmes de physique diffère fondamentalement de la correction de texte ordinaire — il exige que le modèle possède simultanément des capacités de raisonnement mathématique, une compréhension des concepts physiques et une cohérence dans la notation. Voici une comparaison des capacités clés des 3 modèles recommandés :
| Point | Description | Valeur pratique |
|---|---|---|
| Capacité de raisonnement de Gemini 3.1 Pro en tête | Score MATH de 95,1 %, ARC-AGI-2 atteint 77,1 %, classé premier dans les évaluations de raisonnement physique | Taux de précision le plus élevé pour traiter les problèmes de calcul en mécanique et électromagnétisme avec dérivation de formules |
| Processus de résolution clair de Claude Sonnet 4.6 | Prend en charge le mode de réflexion adaptatif, les capacités mathématiques augmentent de 27 points de pourcentage pour atteindre 89 % | Peut produire une justification complète de la notation et des raisons de déduction de points, adapté à la génération de rapports de contrôle qualité |
| Performance exceptionnelle de GPT-5.4 sur les problèmes de compétition | Score parfait à l'AIME 2025, prend en charge un contexte de 1 million de tokens | Chaîne de raisonnement la plus complète lors du traitement de problèmes de compétition de physique et de problèmes complexes |
| Validation croisée multi-modèles | Notation indépendante par 3 modèles, puis recherche d'un consensus | Améliore la précision d'un seul modèle de 85-90 % à plus de 95 % |
Les 3 défis clés du contrôle qualité des problèmes de physique par les grands modèles
Défi 1 : Évaluation de l'équivalence des dérivations de formules. Pour un même problème de mécanique, un étudiant peut le résoudre par la conservation de l'énergie, un autre par la deuxième loi de Newton. Les processus de dérivation des deux méthodes sont complètement différents, mais les résultats sont équivalents. Des études montrent que si le prompt n'exige pas explicitement que le modèle accepte les solutions équivalentes, le modèle évaluera de manière rigide en suivant le chemin de résolution de la réponse standard, entraînant un taux d'erreur pouvant atteindre 30 %. C'est le point de perte le plus courant dans le contrôle qualité des problèmes de physique par les grands modèles.
Défi 2 : Traitement de la tolérance pour les unités physiques et les chiffres significatifs. Dans les calculs physiques, les résultats avec 2 chiffres significatifs et 3 chiffres significatifs sont différents, mais généralement tous deux doivent être acceptés. Définir une plage de tolérance numérique raisonnable (par exemple ±5 %) dans le prompt est la clé pour garantir la précision du contrôle qualité.
Défi 3 : Compréhension des problèmes avec diagrammes et expériences. Les problèmes contenant des schémas de circuits ou des illustrations de mécanique nécessitent que le modèle possède des capacités de compréhension multimodale. Gemini 3.1 Pro et GPT-5.4 sont meilleurs dans ce domaine, tandis que Claude Sonnet 4.6 est plus stable pour le raisonnement purement textuel et formel.
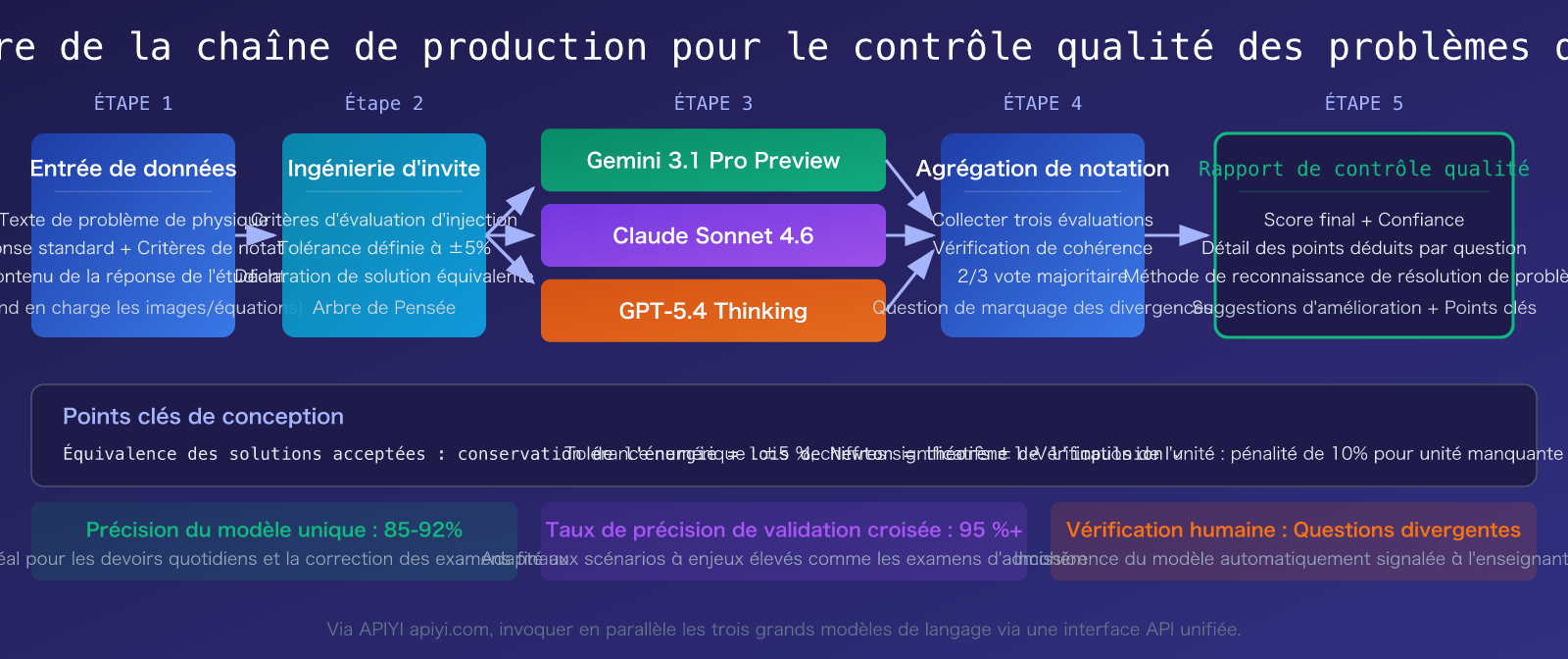
Détails des 3 modèles recommandés pour le contrôle qualité des exercices de physique par grands modèles de langage
Gemini 3.1 Pro Preview : Le choix privilégié pour le raisonnement physique
Gemini 3.1 Pro est le modèle phare publié par Google DeepMind en février 2026. Dans le scénario du contrôle qualité des exercices de physique, il présente trois avantages principaux :
- Meilleure capacité de raisonnement STEM : Classé premier dans l'évaluation CritPt (raisonnement physique de niveau recherche), atteignant 95,1 % sur le benchmark MATH.
- Profondeur de réflexion ajustable : Nouveau paramètre
thinking_level(supportant LOW/MEDIUM/HIGH). Utilisez LOW pour les QCM simples afin de réduire les coûts, et HIGH pour les problèmes de calcul complexes afin de garantir la précision. - Rapport qualité-prix exceptionnel : Le coût est d'environ 1/7,5 de celui de Claude Opus 4.6, ce qui le rend adapté aux tâches de contrôle qualité en grande quantité.
Claude Sonnet 4.6 : Le meilleur pour la génération de rapports de contrôle qualité
Claude Sonnet 4.6, publié le 17 février 2026, présente des avantages uniques pour le contrôle qualité des exercices de physique :
- Mode de réflexion adaptatif : Le modèle décide automatiquement de la profondeur de raisonnement en fonction de la difficulté de la question : jugement rapide pour les questions simples, raisonnement approfondi pour les questions complexes.
- Fenêtre de contexte de 1 million de tokens : Permet de soumettre en une seule fois toutes les questions d'un examen complet ainsi que les réponses standards, assurant ainsi une cohérence dans les critères de notation.
- Structure de sortie robuste : Excellente capacité à générer des rapports de contrôle qualité au format standardisé, incluant la note, les points de déduction et les suggestions d'amélioration.
GPT-5.4 : L'outil idéal pour les problèmes de niveau compétition
GPT-5.4, publié le 5 mars 2026, est le dernier modèle phare d'OpenAI :
- Score parfait en mathématiques de compétition : A obtenu un taux de réussite de 100 % à l'AIME 2025, avec une capacité remarquable à traiter des problèmes physiques complexes et intégrés de haut niveau.
- Capacité de planification préalable : La version "Thinking" de GPT-5.4 prend en charge le "Upfront Planning", affichant d'abord le raisonnement avant de donner la note.
- Efficacité optimale des tokens : Par rapport à GPT-5.2, la consommation de tokens pour le raisonnement est considérablement réduite, ce qui entraîne des coûts d'utilisation à long terme plus bas.
| Modèle | Capacité de raisonnement physique | Qualité de génération des rapports | Support multimodal | Coût par million de tokens | Scénario recommandé |
|---|---|---|---|---|---|
| Gemini 3.1 Pro | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Le plus bas | Contrôle qualité quotidien en grande quantité, questions incluant des graphiques |
| Claude Sonnet 4.6 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Moyen ($3/$15) | Rapports de contrôle qualité détaillés, notation d'examens complets |
| GPT-5.4 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Élevé | Questions de compétition, problèmes complexes, contrôle qualité de haute difficulté |
🎯 Conseil de choix : Pour le contrôle qualité quotidien, privilégiez Gemini 3.1 Pro (meilleur rapport qualité-prix). Pour des rapports détaillés, choisissez Claude Sonnet 4.6. Pour les questions difficiles de compétition, utilisez GPT-5.4. La plateforme APIYI apiyi.com permet d'invoquer ces trois modèles via une interface unifiée, facilitant ainsi la commutation rapide et la comparaison.
Démarrage rapide pour le contrôle qualité des exercices de physique avec les grands modèles de langage
Exemple minimaliste : Notation automatique d'un exercice de physique en 10 lignes de code
L'exemple suivant montre comment utiliser un grand modèle de langage pour noter automatiquement un problème de calcul en physique :
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[
{"role": "system", "content": "Vous êtes un expert en contrôle qualité d'exercices de physique. Évaluez la réponse de l'étudiant par rapport à la réponse standard. Sortie au format JSON : {score, max_score, deductions: [{reason, points}], comment}"},
{"role": "user", "content": """
【Énoncé】Un objet de masse 2kg tombe en chute libre d'une hauteur de 10m. Trouvez la vitesse à l'impact (g=10m/s²)
【Réponse standard】v=√(2gh)=√(2×10×10)=√200≈14.1m/s
【Réponse de l'étudiant】Utilisation de la conservation de l'énergie : mgh=½mv², v=√(2gh)=√200=14.14m/s
"""}
]
)
print(response.choices[0].message.content)
Voir le code complet du pipeline de contrôle qualité (incluant la validation croisée multi-modèles)
import openai
import json
from typing import Optional
def physics_quality_check(
question: str,
standard_answer: str,
student_answer: str,
models: list = None,
tolerance: float = 0.05
) -> dict:
"""
Contrôle qualité multi-modèles avec validation croisée pour les exercices de physique
Args:
question: Contenu de la question
standard_answer: Réponse standard
student_answer: Réponse de l'étudiant
models: Liste des modèles à utiliser
tolerance: Tolérance numérique (5% par défaut)
Returns:
Dictionnaire contenant les notes de chaque modèle et la conclusion finale
"""
if models is None:
models = ["gemini-3.1-pro-preview", "claude-sonnet-4-6", "gpt-5.4"]
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
system_prompt = f"""Vous êtes un enseignant de physique expérimenté et un expert en correction de copies. Veuillez noter strictement selon les règles suivantes :
1. Acceptez les méthodes de résolution équivalentes à la réponse standard (par exemple, conservation de l'énergie, lois de Newton, etc.)
2. Plage de tolérance pour les résultats numériques : ±{tolerance*100}%
3. Chiffres significatifs : acceptez une différence de ±1 chiffre
4. Les unités physiques doivent être correctes, l'absence d'unité entraîne une pénalité de 10%
Sortie au format JSON strict :
{{
"score": score_obtenu,
"max_score": score_maximum,
"is_correct": true/false,
"deductions": [{{"reason": "raison de la déduction", "points": points_déduits}}],
"solution_method": "méthode de résolution utilisée par l'étudiant",
"comment": "évaluation globale et suggestions d'amélioration"
}}"""
user_prompt = f"""【Énoncé】{question}
【Réponse standard】{standard_answer}
【Réponse de l'étudiant】{student_answer}"""
results = {}
for model in models:
try:
resp = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
temperature=0.1
)
results[model] = json.loads(resp.choices[0].message.content)
except Exception as e:
results[model] = {"error": str(e)}
# Validation croisée : prendre la conclusion consensuelle de la majorité des modèles
scores = [r["score"] for r in results.values() if "score" in r]
consensus = {
"model_results": results,
"avg_score": sum(scores) / len(scores) if scores else 0,
"consensus": all(r.get("is_correct") for r in results.values() if "is_correct" in r)
}
return consensus
# Exemple d'utilisation
result = physics_quality_check(
question="Un objet de masse 2kg tombe en chute libre d'une hauteur de 10m. Trouvez la vitesse à l'impact (g=10m/s²)",
standard_answer="v=√(2gh)=√(2×10×10)=√200≈14.1m/s",
student_answer="mgh=½mv²,v=√(2×10×10)=14.14m/s"
)
print(json.dumps(result, ensure_ascii=False, indent=2))
Conseil : Obtenez un crédit de test gratuit via APIYI apiyi.com. Une seule clé API vous permet d'invoquer les trois modèles (Gemini, Claude, GPT), sans avoir besoin de créer des comptes séparés sur les trois plateformes.
Pratiques d'ingénierie de Prompt pour le contrôle qualité des exercices de physique avec les grands modèles de langage
Une conception efficace des invites est au cœur de la précision du contrôle qualité. Voici des modèles de prompt testés en pratique et des stratégies d'optimisation :
Modèle de Prompt pour le contrôle qualité des exercices de physique
Selon des recherches académiques (plusieurs articles publiés entre 2024 et 2026), la stratégie de prompt Tree of Thought (Arbre de pensée) obtient les meilleurs résultats pour l'évaluation des exercices de calcul en physique, avec une précision ≥ 0,9 et un coefficient Kappa de Cohen > 0,8. Voici la structure de prompt que nous recommandons :
| Stratégie de Prompt | Type d'exercice adapté | Précision | Modèle recommandé |
|---|---|---|---|
| Tree of Thought | Exercices de calcul complexes, problèmes de dérivation | ≥ 90% | Gemini 3.1 Pro |
| Chain of Thought | Questions d'analyse conceptuelle, réponses courtes | 85-90% | Claude Sonnet 4.6 |
| Few-Shot | Questions à choix multiples, exercices à trous | 80-85% | GPT-5.4 (coût inférieur) |
| Vote multi-tours | Tous types (exigences élevées) | 92-95% | Combinaison de trois modèles |
Techniques clés d'optimisation des Prompts
Technique 1 : Définir clairement les règles d'acceptation des méthodes équivalentes. Lister dans le System Prompt toutes les méthodes de résolution acceptables pour un exercice donné. Par exemple, pour un problème de mécanique, il faut préciser : « Accepte les méthodes équivalentes : conservation de l'énergie, lois du mouvement de Newton, théorème de l'impulsion, etc. ». Cette règle seule peut réduire le taux d'erreur de jugement de 30% à moins de 5%.
Technique 2 : Définir une tolérance numérique plutôt qu'une correspondance exacte. Les arrondis dans les calculs intermédiaires en physique peuvent entraîner de légères différences dans le résultat final. Nous recommandons de définir une tolérance de ±5%, tout en exigeant que les unités physiques soient correctes.
Technique 3 : Demander au modèle de résoudre d'abord, puis de noter. Faites d'abord résoudre l'exercice de manière indépendante par le modèle, puis comparez avec la réponse de l'élève. Cette approche est 15 à 20% plus précise que de demander directement au modèle de « noter en comparant avec la réponse standard ». Le mode thinking_level: HIGH de Gemini 3.1 Pro et le mode Extended Thinking de Claude Sonnet 4.6 sont tous deux adaptés à cette utilisation.
Technique 4 : Exécutions multiples et prise de la valeur modale. Exécutez la notation 3 à 5 fois pour le même exercice et prenez le résultat le plus fréquent. L'écart-type peut servir d'indicateur de confiance. Un écart-type > 1 point suggère une vérification manuelle.
🎯 Conseil pratique : Lors de la mise en place initiale d'un système de contrôle qualité, il est recommandé d'utiliser un jeu de test de 50 à 100 exercices de physique déjà corrigés manuellement. Testez ensuite la précision de trois modèles différents sur APIYI apiyi.com pour trouver la combinaison de modèles la plus adaptée aux caractéristiques de votre base d'exercices.

Solutions contextuelles pour le contrôle qualité des exercices de physique avec les grands modèles de langage
Différents types d'exercices de physique nécessitent des stratégies de contrôle qualité différentes. Voici les configurations recommandées pour 4 scénarios typiques :
Scénario 1 : Contrôle qualité par lots pour les devoirs quotidiens
Adapté aux devoirs quotidiens de physique au lycée/université, volume important (100+ exercices/jour), difficulté moyenne.
- Modèle recommandé : Gemini 3.1 Pro Preview (
thinking_level: MEDIUM) - Stratégie d'invite : Few-Shot + grille de notation standard
- Avantage coût : Environ 2 millions de tokens consommés pour 1000 exercices, coût de Gemini 3.1 Pro bien inférieur aux autres modèles
- Taux de précision : 85-90% (modèle unique), peut atteindre 95%+ avec un échantillonnage manuel
Scénario 2 : Notation détaillée pour les examens finaux
Adapté à la correction d'examens officiels, nécessitant une justification détaillée des points et des motifs de déduction.
- Modèle recommandé : Claude Sonnet 4.6 (mode Extended Thinking)
- Stratégie d'invite : Tree of Thought + grille de notation détaillée
- Avantage principal : Le rapport de contrôle qualité généré est structuré clairement et peut être archivé directement comme procès-verbal de correction.
- Taux de précision : 88-92% (modèle unique)
Scénario 3 : Contrôle qualité pour les olympiades de physique
Adapté à la préparation aux olympiades de physique au lycée, exercices complexes et de haute difficulté.
- Modèle recommandé : GPT-5.4 Thinking (mode Upfront Planning)
- Stratégie d'invite : Tree of Thought + résolution avant notation
- Avantage principal : Niveau AIME parfait, capable de gérer des déductions à plusieurs étapes et des opérations mathématiques avancées.
- Taux de précision : 80-85% (performance d'un modèle unique pour un niveau de compétition)
Scénario 4 : Validation croisée multi-modèles (précision maximale)
Adapté aux examens à enjeux élevés (ex : examens d'entrée), nécessitant la précision maximale.
- Solution recommandée : 3 modèles notent indépendamment → consensus majoritaire 2/3 → relecture manuelle des exercices en désaccord
- Coût de mise en œuvre : Coût par exercice environ 3 fois celui d'un modèle unique, mais la précision augmente à 95%+
- Échelle d'application : Adapté aux scénarios avec un volume d'exercices réduit (< 500) mais des exigences de qualité extrêmement élevées.
| Scénario | Modèle recommandé | Stratégie d'invite | Précision | Coût (1000 ex.) |
|---|---|---|---|---|
| Devoirs quotidiens | Gemini 3.1 Pro | Few-Shot | 85-90% | Faible |
| Examens finaux | Claude Sonnet 4.6 | Tree of Thought | 88-92% | Moyen |
| Olympiades | GPT-5.4 Thinking | ToT + résolution d'abord | 80-85% | Élevé |
| Validation croisée | Combinaison de 3 modèles | Vote multi-tours | 95%+ | Très élevé (3×) |
🎯 Conseil pour changer de modèle : Les exigences varient considérablement selon les scénarios. APIYI apiyi.com permet de changer de modèle simplement en modifiant un paramètre
model, facilitant ainsi la sélection dynamique du modèle optimal en fonction du type d'exercice.
Questions fréquentes
Q1 : Le contrôle qualité des exercices de physique par les grands modèles peut-il remplacer complètement la correction manuelle ?
Pas encore complètement. La recherche académique montre que les grands modèles peuvent atteindre une précision de 90%+ pour les exercices de calcul standardisés, mais seulement 8.3% pour les problèmes mal définis (under-specified problems). Solution recommandée : le grand modèle s'occupe de la correction de 80% des exercices standard, et un humain se charge de la relecture des 20% d'exercices complexes et litigieux.
Q2 : Quelle est la complexité d’intégration des API pour ces trois modèles ?
Ces trois modèles proviennent de trois plateformes différentes (Google, Anthropic, OpenAI). S'inscrire et s'interfacer avec chacune individuellement entraîne des coûts de développement élevés. Il est recommandé de les appeler via l'interface unifiée d'APIYI apiyi.com. Tous les modèles utilisent le même format SDK OpenAI, il suffit de modifier le paramètre model pour changer de modèle, réduisant ainsi considérablement les coûts d'intégration.
Q3 : Comment évaluer la précision du système de contrôle qualité ?
Il est recommandé d'utiliser le coefficient de Kappa de Cohen pour mesurer la concordance entre la notation du modèle et celle de l'humain :
- Préparer un jeu de test de 50 à 100 exercices de physique déjà corrigés manuellement.
- Appeler les trois modèles via APIYI apiyi.com pour qu'ils notent séparément.
- Calculer la valeur Kappa entre chaque modèle et la notation humaine.
- Un Kappa > 0,8 indique une concordance élevée, le système peut être déployé.
Résumé
Les points clés du contrôle qualité des problèmes de physique par les grands modèles de langage :
- Gemini 3.1 Pro Preview en premier choix : Meilleures capacités de raisonnement STEM et meilleur rapport qualité-prix, idéal pour le contrôle qualité quotidien à grande échelle des problèmes de physique.
- Claude Sonnet 4.6 adapté pour les rapports : Mode de pensée adaptatif + sortie structurée, parfait pour les examens officiels nécessitant des justifications de notation détaillées.
- GPT-5.4 pour les problèmes de compétition difficiles : Capacités de raisonnement de niveau AIME parfait, le plus fiable pour traiter les problèmes de physique complexes et de haut niveau.
- Validation croisée multi-modèles pour atteindre 95%+ : Notation indépendante par trois modèles et recherche d'un consensus, c'est actuellement la solution d'automatisation la plus fiable.
Le choix du modèle dépend des caractéristiques de vos types d'exercices et de vos exigences en matière de précision. Nous recommandons de tester et de comparer rapidement via APIYI apiyi.com. La plateforme offre des crédits gratuits et une interface unifiée, une seule clé API suffit pour invoquer tous les principaux modèles.
📚 Références
-
MDPI Sciences de l'éducation – Recherche sur l'évaluation intelligente des problèmes de physique basée sur les grands modèles : Comparaison des performances de quatre stratégies d'invite dans l'évaluation des problèmes de physique.
- Lien :
mdpi.com/2227-7102/15/2/116 - Explication : Source des données expérimentales montrant une précision ≥ 0.9 avec la stratégie Tree of Thought.
- Lien :
-
Physical Review – Évaluation des LLM sur les problèmes des Olympiades de physique : Évaluation systématique des modèles GPT et de raisonnement sur les problèmes de compétition de physique.
- Lien :
link.aps.org/doi/10.1103/6fmx-bsnl - Explication : Argument clé selon lequel les capacités de raisonnement physique des grands modèles dépassent désormais la moyenne humaine.
- Lien :
-
Google DeepMind – Blog technique Gemini 3.1 Pro : Détails sur l'architecture du modèle et les tests de référence STEM.
- Lien :
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - Explication : Source officielle des données d'évaluation du raisonnement physique de Gemini 3.1 Pro.
- Lien :
-
Anthropic – Annonce de sortie de Claude Sonnet 4.6 : Détails sur le mode de pensée adaptatif et l'amélioration des capacités mathématiques.
- Lien :
anthropic.com/news/claude-sonnet-4.6 - Explication : Détails techniques sur l'amélioration de 27% des capacités mathématiques de Claude Sonnet 4.6.
- Lien :
-
OpenAI – Annonce de sortie de GPT-5.4 : Améliorations de la planification préalable (Upfront Planning) et de l'efficacité du raisonnement.
- Lien :
openai.com/index/introducing-gpt-5-4/ - Explication : Données officielles sur le score parfait d'GPT-5.4 à l'AIME et l'optimisation de l'efficacité des Tokens.
- Lien :
Auteur : Équipe technique APIYI
Échanges techniques : Bienvenue dans les commentaires pour discuter des expériences pratiques sur le contrôle qualité des problèmes de physique par les grands modèles. Pour plus de tutoriels sur l'invocation des modèles, visitez le centre de documentation APIYI docs.apiyi.com.