
Le modèle gpt-image-2, lancé par OpenAI en avril 2026, est devenu la référence absolue dans le domaine de la génération d'images. Avec un taux de précision de 99 % pour le rendu de texte au niveau des caractères, une sortie haute définition 4K, une prise en charge native du chinois/CJK et l'intégration des capacités de raisonnement de la série O, il impressionne. Pourtant, la première question que se posent les développeurs est : comment intégrer concrètement gpt-image-2 via l'API officielle ? Quels sont les paramètres requis ? Comment configurer base_url ? Et comment exploiter le b64_json reçu dans la réponse ?
Cet article est un guide pratique de bout en bout pour l'intégration de l'API officielle de gpt-image-2, couvrant tous les détails techniques, de l'installation du SDK et la configuration de base_url à la génération d'images, l'édition, l'inpainting et la gestion des erreurs. Tout le code est basé sur le SDK officiel d'OpenAI et le canal de transfert officiel d'APIYI (100 % compatible avec les champs officiels). Une fois cet article parcouru, votre projet sera prêt pour une utilisation en production avec gpt-image-2.
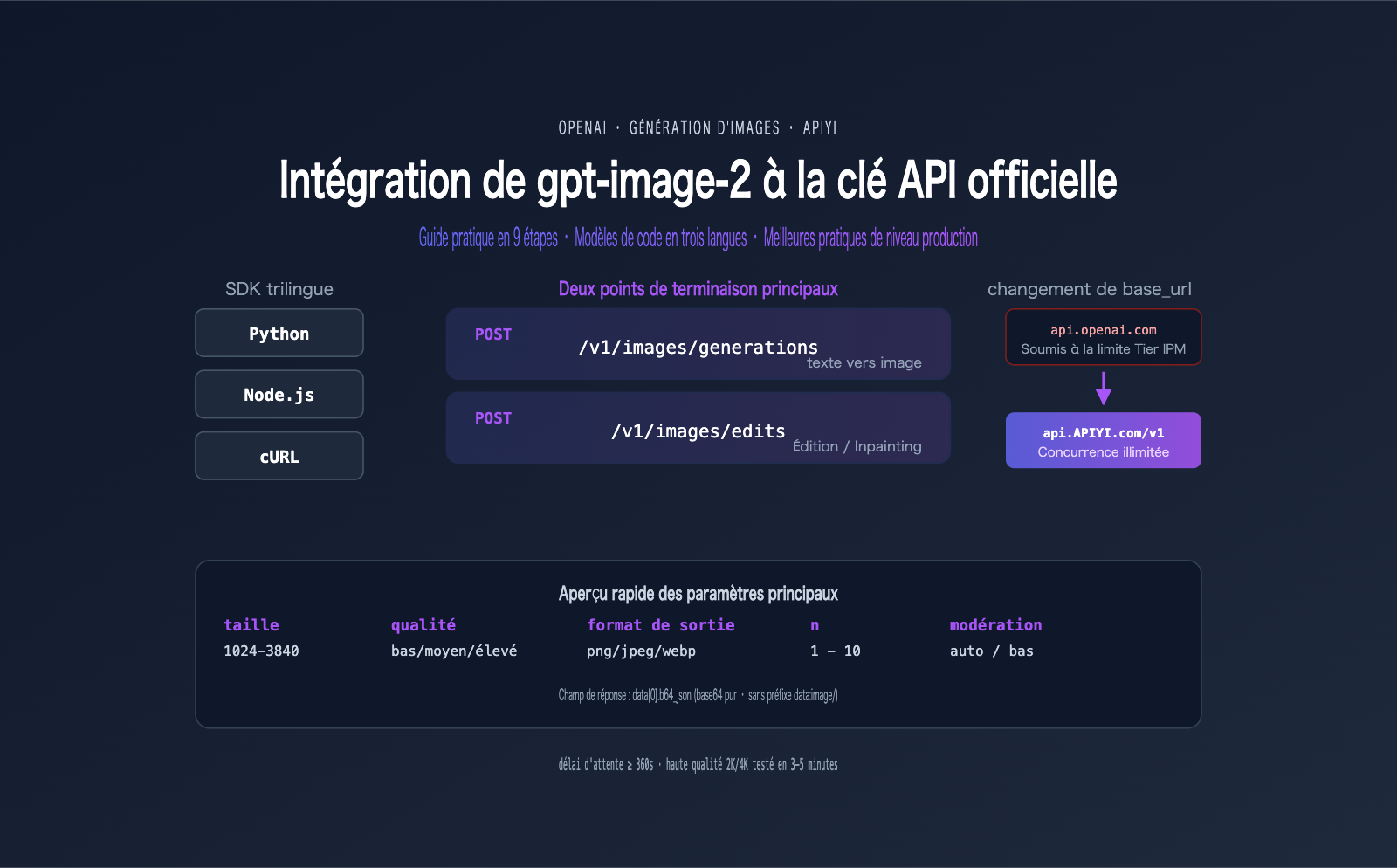
Liste de contrôle pour l'intégration de l'API officielle de gpt-image-2
Avant d'écrire la première ligne de code, vous devez préparer votre environnement. La liste suivante couvre les 4 conditions préalables nécessaires à l'intégration de gpt-image-2.
Liste de contrôle de l'environnement pour gpt-image-2
| Élément | Exigence | Note |
|---|---|---|
| Clé API | Jeton Bearer valide | À demander via la console APIYI, crédit de test disponible dès l'inscription |
| SDK Python | openai >= 1.50.0 |
Les anciennes versions ne supportent pas les nouveaux paramètres de images.generate() |
| SDK Node.js | openai >= 4.50.0 |
Les types TypeScript sont synchronisés avec l'officiel |
| Timeout HTTP | ≥ 360 secondes | Qualité élevée + 2K/4K : temps de traitement réel de 3 à 5 minutes |
| Réseau | Accès direct | api.apiyi.com est accessible depuis le monde entier |
Installation du SDK pour gpt-image-2
Peu importe le langage choisi, installez simplement le SDK officiel d'OpenAI — le canal de transfert APIYI est strictement identique aux champs officiels, aucune bibliothèque cliente supplémentaire n'est requise.
# Python
pip install --upgrade openai
# Node.js
npm install openai@latest
# Si vous utilisez yarn / pnpm
yarn add openai
pnpm add openai
Processus d'obtention de la clé API pour gpt-image-2
Les étapes pour obtenir votre clé API sont très simples :
- Visitez la console APIYI sur
api.apiyi.com - Après l'inscription, accédez à la page « Jetons API »
- Créez un nouveau jeton (il est conseillé d'utiliser un jeton distinct par projet pour faciliter l'audit)
- Enregistrez le jeton dans vos variables d'environnement (il est fortement déconseillé de le coder en dur dans votre application)
🚀 Conseil pour bien démarrer : lors de votre première intégration de l'API
gpt-image-2, nous vous recommandons de commencer par une basse résolution (1024×1024) pour valider la chaîne de traitement, avant de passer à la haute qualité et aux grandes dimensions. Nous vous suggérons d'utiliser la plateforme APIYI (apiyi.com) pour obtenir des crédits de test ; le quota gratuit est suffisant pour valider l'ensemble du processus PoC.
# Ajoutez ceci à votre ~/.zshrc ou ~/.bashrc
export APIYI_KEY="sk-votre-jeton-ici"
Configuration du base_url pour l'intégration de l'API officielle dans gpt-image-2
Dans tout le processus d'intégration de l'API officielle pour gpt-image-2, le seul élément qui diffère du SDK OpenAI natif est le base_url. Il suffit de remplacer api.openai.com par api.apiyi.com, et tout le reste du code demeure identique.
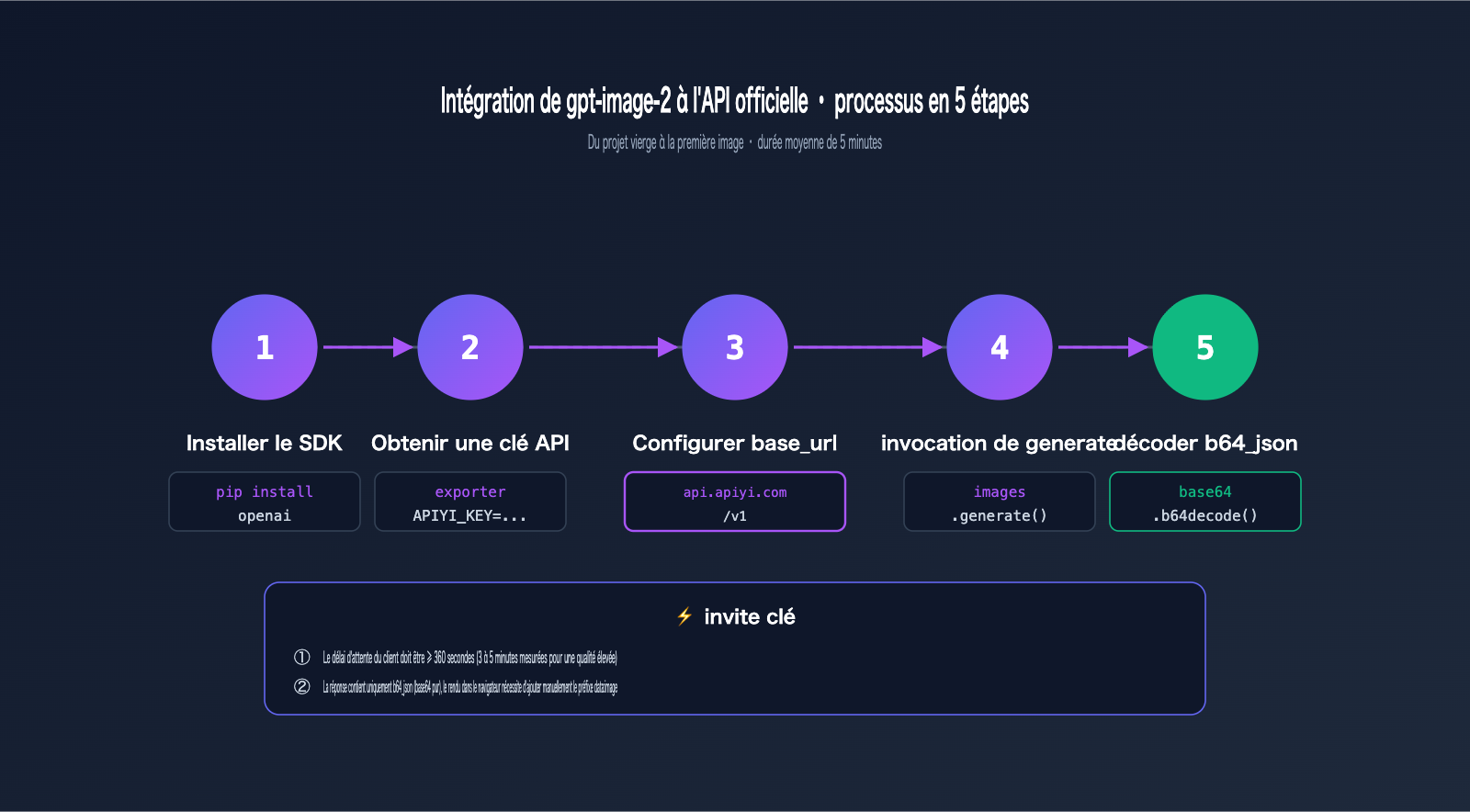
Les deux points de terminaison pour l'API officielle dans gpt-image-2
APIYI propose deux points de terminaison pour la génération d'images, strictement identiques à ceux d'OpenAI :
| Point de terminaison | Usage | Paramètres requis |
|---|---|---|
POST /v1/images/generations |
Texte vers image (génération via prompt pur) | model, prompt |
POST /v1/images/edits |
Édition d'image, fusion, inpainting avec masque | model, prompt, image |
Initialisation du client pour gpt-image-2
Voici le code d'initialisation du client pour Python et Node.js. N'oubliez surtout pas de régler le délai d'expiration (timeout) à au moins 360 secondes.
# Python
import os
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("APIYI_KEY"),
base_url="https://api.apiyi.com/v1", # Passage par le service proxy API d'APIYI
timeout=600.0, # Indispensable pour la haute définition
max_retries=2
)
// Node.js
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.APIYI_KEY,
baseURL: "https://api.apiyi.com/v1", # Attention à la casse (camelCase)
timeout: 600 * 1000, # En millisecondes
maxRetries: 2
});
💡 Rappel sur le délai d'expiration : Le timeout par défaut de 60 secondes échouera systématiquement dans les scénarios de haute qualité (high) avec du 2K/4K. Nous recommandons, lors de l'utilisation du service proxy API APIYI (apiyi.com), de configurer le timeout de tous vos clients en environnement de production entre 360 et 600 secondes, afin d'éviter que les requêtes longues ne soient interrompues prématurément.
Passons à la pratique. Voici comment effectuer votre première invocation du modèle de génération d'images gpt-image-2 via l'API officielle, en utilisant trois langages différents.
Invocation de gpt-image-2 en Python
import base64
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("APIYI_KEY"),
base_url="https://api.apiyi.com/v1",
timeout=600.0
)
response = client.images.generate(
model="gpt-image-2",
prompt="A modern minimalist office desk with a vintage typewriter, soft morning light from the window, photorealistic, 8K",
size="1536x1024",
quality="high",
output_format="jpeg",
output_compression=92,
n=1
)
# Important : APIYI renvoie une chaîne base64 brute, sans le préfixe data:image/...
b64 = response.data[0].b64_json
with open("output.jpg", "wb") as f:
f.write(base64.b64decode(b64))
print("✓ Image enregistrée sous output.jpg")
Invocation de gpt-image-2 en Node.js
import fs from "node:fs/promises";
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.APIYI_KEY,
baseURL: "https://api.apiyi.com/v1",
timeout: 600_000
});
const response = await client.images.generate({
model: "gpt-image-2",
prompt: "An e-commerce product photo of a leather backpack on a marble desk, studio lighting",
size: "1024x1024",
quality: "high",
output_format: "png",
n: 1
});
const b64 = response.data[0].b64_json;
await fs.writeFile("output.png", Buffer.from(b64, "base64"));
console.log("✓ Image enregistrée");
Invocation de gpt-image-2 via cURL
cURL est idéal pour vérifier rapidement la validité de votre clé API ou tester de nouvelles combinaisons de paramètres.
curl https://api.apiyi.com/v1/images/generations \
-H "Authorization: Bearer $APIYI_KEY" \
-H "Content-Type: application/json" \
--max-time 600 \
-d '{
"model": "gpt-image-2",
"prompt": "A futuristic cyberpunk city at night, neon signs in mixed Chinese and English",
"size": "2048x1152",
"quality": "high",
"output_format": "jpeg",
"output_compression": 90,
"n": 1
}' | jq -r '.data[0].b64_json' | base64 -d > output.jpg
Attention : l'option --max-time 600 est indispensable, car cURL n'a pas de délai d'attente par défaut, mais de nombreux wrappers shell imposent une interruption forcée après 60 secondes.
Points clés pour le traitement des réponses
De nombreux développeurs bloquent lors de l'analyse du base64. Voici les erreurs classiques à éviter :
# ✗ Erreur : APIYI ne renvoie pas de champ url
url = response.data[0].url # AttributeError
# ✓ Correct : utilisez b64_json
b64 = response.data[0].b64_json
# ✗ Erreur : rendu direct de la chaîne b64 brute dans un navigateur
<img src="{b64}"> # Ne s'affichera pas
# ✓ Correct : concaténation manuelle du préfixe pour le navigateur
data_uri = f"data:image/jpeg;base64,{b64}"
# <img src="{{ data_uri }}">
# ✓ Correct : enregistrement côté serveur
with open("output.jpg", "wb") as f:
f.write(base64.b64decode(b64))
Paramètres complets pour gpt-image-2
Maîtriser les plages de valeurs et les cas d'usage de chaque paramètre est essentiel pour passer en production.

Tableau des paramètres essentiels
| Paramètre | Valeur | Défaut | Description |
|---|---|---|---|
model |
"gpt-image-2" |
Requis | ID du modèle |
prompt |
Chaîne | Requis | Invite, supporte le mélange chinois/anglais |
size |
8 préréglages + perso | auto |
Voir tableau ci-dessous |
quality |
auto / low / medium / high |
auto |
Impacte le coût et le temps |
output_format |
png / jpeg / webp |
png |
Recommandé : jpeg + 90 compression |
output_compression |
1-100 | 100 | Valide uniquement pour jpeg/webp |
moderation |
auto / low |
auto |
low réduit la sensibilité de la modération |
n |
1-10 | 1 | Nombre d'images par génération |
Options de taille (size) pour gpt-image-2
# 8 préréglages officiels
size = "1024x1024" # 1:1 Carré standard
size = "1536x1024" # 3:2 Paysage
size = "1024x1536" # 2:3 Portrait
size = "2048x2048" # 2K Carré
size = "2048x1152" # 16:9 Paysage (fond d'écran/affiche)
size = "3840x2160" # 4K Paysage
size = "2160x3840" # 4K Portrait (fond d'écran mobile)
size = "auto" # Sélection automatique par le modèle
Pour des dimensions personnalisées, les contraintes suivantes s'appliquent :
✓ Longueur des côtés multiple de 16
✓ Côté max ≤ 3840px
✓ Ratio hauteur/largeur ≤ 3:1
✓ Nombre total de pixels entre 655 360 et 8 294 400
Par exemple, 1280x720 (720P) est valide, tandis que 3840x1080 (ultra-large) sera rejeté car le ratio dépasse 3:1.
Comparatif qualité et coût
Le paramètre quality est le principal levier de coût. Voici la grille tarifaire (par image) :
| Qualité | 1024×1024 | 1024×1536 | 1536×1024 | Cas d'usage |
|---|---|---|---|---|
low |
0,006 $ | 0,005 $ | 0,005 $ | Esquisses, miniatures, itération rapide |
medium |
0,053 $ | 0,041 $ | 0,041 $ | Contenu web, illustrations médias |
high |
0,211 $ | 0,165 $ | 0,165 $ | Photos produits, affiches, publicité |
💰 Optimisation des coûts : Pour les équipes générant 100 images par jour, passer de
highàmediumpermet d'économiser 75 % sur les coûts. Nous recommandons d'utiliser la plateforme APIYI (apiyi.com) pour tester vos invites avec la qualitélow, puis de passer àmedium/highpour la production finale, ce qui peut réduire votre budget mensuel de 30 à 50 %.
Choix du format de sortie (output_format)
Le format impacte directement le stockage et la vitesse de chargement :
# Besoin de transparence ? gpt-image-2 ne le supporte pas (erreur 400)
# ✗ output_format="png", background="transparent" → 400 Bad Request
# Affichage web/mini-app : jpeg + compression 90
output_format="jpeg", output_compression=90
# Archivage haute fidélité : png (sans perte)
output_format="png"
# Applications web modernes : webp (poids minimal)
output_format="webp", output_compression=85
En plus de la génération d'images (texte vers image), gpt-image-2 prend également en charge trois scénarios d'édition majeurs : l'édition d'images, la fusion multi-images et la retouche locale (inpainting/outpainting).

Édition d'images avec gpt-image-2 via l'API officielle (mode image de référence)
L'édition avec image de référence active automatiquement le mode haute fidélité — ne transmettez donc pas le paramètre input_fidelity (il sera rejeté).
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("APIYI_KEY"),
base_url="https://api.apiyi.com/v1"
)
# Édition avec une seule image de référence
with open("source.jpg", "rb") as img:
response = client.images.edit(
model="gpt-image-2",
image=img,
prompt="Remplace l'arrière-plan par une plage au coucher du soleil, tout en conservant la pose et les vêtements du personnage au premier plan",
size="1024x1024",
quality="high"
)
Fusion multi-images avec gpt-image-2 via l'API officielle (jusqu'à 16 images)
Le point de terminaison /images/edits prend en charge jusqu'à 16 images de référence en entrée simultanée. Dans l'invite, utilisez « image1/image2/image3 » pour les désigner.
images = [
open("character.jpg", "rb"), # Image 1 : personnage
open("background.jpg", "rb"), # Image 2 : arrière-plan
open("outfit.jpg", "rb"), # Image 3 : référence vestimentaire
]
response = client.images.edit(
model="gpt-image-2",
image=images,
prompt="Place le personnage de l'image 1 dans l'arrière-plan de l'image 2, fais en sorte que le personnage porte le style vestimentaire de l'image 3, tout en conservant un rendu cinématographique",
size="2048x1152",
quality="high"
)
Cette capacité est extrêmement puissante pour des scénarios tels que le changement d'arrière-plan de produits e-commerce, l'essayage virtuel ou la génération de storyboards de mangas.
Inpainting (retouche locale) avec gpt-image-2 via l'API officielle
L'inpainting utilise le paramètre mask pour spécifier la zone à retoucher. Règles clés :
- Le masque doit avoir la même dimension que la première image de référence.
- Le masque doit être un fichier PNG avec un canal alpha.
- Zone transparente = zone à retoucher.
- Zone opaque = zone à conserver.
with open("photo.png", "rb") as img, open("mask.png", "rb") as msk:
response = client.images.edit(
model="gpt-image-2",
image=img,
mask=msk,
prompt="Remplace la zone encadrée en rouge par un chat orange",
size="1024x1024",
quality="high"
)
Si vous avez besoin de générer un masque par programmation en Python, vous pouvez utiliser PIL :
from PIL import Image
# Créer un masque de la même taille que l'image originale, noir par défaut (opaque = conserver)
mask = Image.new("RGBA", (1024, 1024), (0, 0, 0, 255))
# Rendre transparente la zone à retoucher (alpha=0)
for x in range(400, 700):
for y in range(300, 600):
mask.putpixel((x, y), (0, 0, 0, 0))
mask.save("mask.png")
Pratiques de production et gestion des erreurs pour l'API gpt-image-2
Pour mettre en production l'API gpt-image-2, il est crucial de maîtriser trois piliers : la gestion des codes d'erreur, la concurrence et les délais d'attente (timeouts).
Tableau complet des codes d'erreur pour l'API gpt-image-2
| Code HTTP | Signification | Action recommandée |
|---|---|---|
400 |
Paramètre invalide (taille hors limites, champ non supporté) | Vérifiez les entrées ; ne transmettez pas input_fidelity ou background:transparent |
401 |
Jeton invalide | Vérifiez le Bearer Token et sa validité |
403 |
Blocage par la modération de contenu | Ajustez l'invite ou ajoutez moderation: "low" |
429 |
Limitation de débit / Solde insuffisant | Réessai avec backoff exponentiel + vérification du solde |
5xx |
Erreur de passerelle ou serveur | Réessayez 1 à 2 fois, puis déclenchez une alerte en cas d'échec |
| Timeout | Requête trop longue sans réponse | Réglez le timeout client sur ≥ 360 secondes |
Réessai avec backoff exponentiel pour l'API gpt-image-2
Voici une implémentation de niveau production pour gérer les erreurs 429 et 5xx :
import time
import random
from openai import OpenAI, RateLimitError, APIStatusError
client = OpenAI(
api_key=os.getenv("APIYI_KEY"),
base_url="https://api.apiyi.com/v1",
timeout=600.0
)
def generate_with_retry(prompt: str, max_retries: int = 5):
delay = 1.0
for attempt in range(max_retries):
try:
return client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1024",
quality="high"
)
except RateLimitError:
sleep = delay + random.uniform(0, 0.5)
print(f"429 Limitation de débit, réessai dans {sleep:.1f}s ({attempt+1}/{max_retries})")
time.sleep(sleep)
delay *= 2
except APIStatusError as e:
if 500 <= e.status_code < 600 and attempt < max_retries - 1:
time.sleep(delay)
delay *= 2
continue
raise
raise RuntimeError("Nombre maximal de tentatives atteint")
Contrôle de la concurrence pour l'API gpt-image-2
Pour les tâches par lots, utilisez asyncio.Semaphore afin de limiter la concurrence et éviter de surcharger le service :
import asyncio
from openai import AsyncOpenAI
aclient = AsyncOpenAI(
api_key=os.getenv("APIYI_KEY"),
base_url="https://api.apiyi.com/v1",
timeout=600.0
)
async def gen_one(prompt: str, sem: asyncio.Semaphore):
async with sem:
return await aclient.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1024",
quality="medium"
)
async def batch(prompts: list[str], concurrency: int = 30):
sem = asyncio.Semaphore(concurrency)
return await asyncio.gather(*[gen_one(p, sem) for p in prompts])
# Génération de 200 images avec 30 requêtes simultanées
prompts = [f"Variante d'image produit #{i}" for i in range(200)]
results = asyncio.run(batch(prompts))
Estimation des coûts pour l'API gpt-image-2
Estimez vos coûts avant de passer en production. Voici quelques scénarios types :
| Cas d'usage | Volume quotidien | Qualité | Coût mensuel estimé |
|---|---|---|---|
| Illustrations médias | 30 images | medium | ~48 $ |
| Photos produits e-commerce | 200 images | high | ~1266 $ |
| Génération SaaS utilisateur | 1000 fois | medium | ~1590 $ |
| Frames clés de jeu vidéo | 500 images | high | ~3165 $ |
🎯 Conseil de déploiement : Utilisez des clés API distinctes par service pour faciliter le suivi des coûts et l'isolation des limites. Nous recommandons d'activer les alertes de facturation sur la console APIYI (apiyi.com) pour éviter tout dépassement budgétaire.
Observabilité pour l'API gpt-image-2
En production, enregistrez systématiquement les métriques clés de chaque requête :
import time
import logging
logger = logging.getLogger("gpt-image-2")
def call_with_metrics(prompt: str, **params):
start = time.perf_counter()
try:
resp = client.images.generate(model="gpt-image-2", prompt=prompt, **params)
latency = time.perf_counter() - start
logger.info(
"gpt-image-2 ok",
extra={
"latency_ms": int(latency * 1000),
"size": params.get("size"),
"quality": params.get("quality"),
"n": params.get("n", 1)
}
)
return resp
except Exception as e:
logger.error(f"gpt-image-2 échec: {type(e).__name__}: {e}")
raise
FAQ sur l'intégration de l'API gpt-image-2
Q1 : Pourquoi input_fidelity génère-t-il une erreur 400 ?
gpt-image-2 active automatiquement la haute fidélité pour toutes les éditions, rendant le paramètre input_fidelity obsolète. Supprimez-le simplement. Si vous migrez depuis gpt-image-1, effectuez une recherche globale dans votre code. Consultez la documentation sur docs.apiyi.com pour comparer les paramètres.
Q2 : Pourquoi les appels à l'API gpt-image-2 expirent-ils souvent ?
La génération en haute qualité (2K/4K) prend entre 3 et 5 minutes. Si votre timeout client est de 60 secondes, l'échec est garanti. Solution : réglez le timeout entre 360 et 600 secondes.
Q3 : Comment afficher le b64_json retourné par l'API sur une page web ?
L'API renvoie une chaîne base64 brute sans préfixe. Vous devez la concaténer :
const dataUri = `data:image/${format};base64,${b64}`;
imgElement.src = dataUri;
Pour un service backend, il est préférable de décoder le base64 et de stocker l'image sur un CDN/OSS pour optimiser le chargement.
Q4 : L'arrière-plan transparent est-il possible ?
Non, gpt-image-2 ne supporte pas nativement la transparence. Utilisez une bibliothèque comme rembg après la génération pour détourer l'image.
Q5 : Comment utiliser le paramètre thinking ?
thinking (valeurs : off, low, medium, high) permet au modèle de planifier sa mise en page. La qualité augmente, mais le coût aussi (le mode high coûte 4 à 5 fois plus cher). Conseil : utilisez medium uniquement pour des compositions complexes, sinon gardez off.
Q6 : Que faire face à une erreur 403 (modération) ?
Essayez d'ajouter moderation: "low" dans votre requête. Si le blocage persiste, votre prompt enfreint probablement les politiques de sécurité (violence, personnages publics, etc.). Notez que moderation: "low" ne désactive pas la modération, il l'assouplit simplement.
Q7 : Que se passe-t-il si base_url est mal configuré ?
Si vous oubliez /v1 dans https://api.apiyi.com/v1, vous recevrez une erreur 404. Assurez-vous de respecter la casse (Python : base_url, Node.js : baseURL).
Q8 : Meilleures pratiques pour la fusion d'images ?
Vous pouvez utiliser jusqu'à 16 images de référence.
- La première image sert de structure principale.
- Pour des instructions complexes, procédez par étapes (ex: "Utiliser l'image 1 comme sujet, appliquer le ton de l'image 2").
- Le coût est 1,5 à 2 fois supérieur à une génération classique.
Résumé : Retour sur le parcours complet d'intégration de l'API officielle pour gpt-image-2
Après avoir parcouru ces 9 chapitres, vous maîtrisez désormais la méthode technique complète pour intégrer l'API officielle de gpt-image-2 :
- ✅ Préparation — Mise à jour du SDK vers la dernière version et réglage du délai d'expiration (timeout) à ≥ 360 secondes.
- ✅ Configuration de base_url — Remplacement par
https://api.apiyi.com/v1, le reste du code étant identique à l'officiel. - ✅ Invocation du modèle (texte vers image) — Modèles disponibles en Python, Node.js et cURL.
- ✅ Détails des paramètres — 8 préréglages de taille + personnalisation, 3 niveaux de qualité et 3 formats de sortie.
- ✅ Édition d'image — Jusqu'à 16 images de référence, avec des invites utilisant des références comme « image1/image2 ».
- ✅ Inpainting (retouche) — Utilisation du canal alpha du masque pour redessiner les zones transparentes.
- ✅ Gestion des erreurs — Solutions complètes pour les codes 400/401/403/429/5xx.
- ✅ Pratique en production — Backoff exponentiel, contrôle de la concurrence, estimation des coûts et observabilité.
Un dernier conseil pour la mise en œuvre : commencez par un « hello world » avec une qualité low et une résolution 1024×1024, puis augmentez progressivement la complexité. Cela permet d'identifier rapidement les problèmes de base liés à la version du SDK, au timeout ou à la clé API, évitant ainsi de perdre du temps sur des requêtes complexes en high + 4K lors de la phase de débogage.
Si votre équipe évalue actuellement une solution d'intégration pour gpt-image-2, ou si vous rencontrez des erreurs de paramètres ou de timeout lors de l'écriture de votre première version, nous vous recommandons de demander une clé de test sur APIYI (apiyi.com) pour exécuter les modèles de code de cet article. Tous les exemples sont basés sur le SDK officiel et le service proxy API d'APIYI (champs 100 % compatibles), garantissant une excellente portabilité vers vos propres projets.
Références
-
Documentation du modèle OpenAI gpt-image-2 : Informations faisant autorité sur les capacités, les paramètres et la tarification du modèle.
- Lien :
developers.openai.com/api/docs/models/gpt-image-2 - Note : Inclut les fonctionnalités clés telles que le rendu 4K, le texte au niveau des caractères et l'intégration du raisonnement.
- Lien :
-
Guide OpenAI sur la génération d'images : Flux de travail complet pour le texte vers image, l'édition et l'inpainting.
- Lien :
developers.openai.com/api/docs/guides/image-generation - Note : Couvre en détail tous les paramètres de taille, de qualité et de format.
- Lien :
-
Référence de l'API OpenAI Create Image : Champs complets du point de terminaison
/v1/images/generations.- Lien :
developers.openai.com/api/reference/resources/images/methods/generate - Note : Référence faisant autorité pour les champs de requête et de réponse.
- Lien :
-
Documentation officielle d'intégration APIYI : Guide complet d'intégration de gpt-image-2.
- Lien :
docs.apiyi.com/api-capabilities/gpt-image-2/overview - Note : Contient des exemples cURL/Python/Node.js et la gestion des codes d'erreur.
- Lien :
-
OpenAI Cookbook · Limites de débit : Stratégie de backoff exponentiel pour les erreurs 429.
- Lien :
developers.openai.com/cookbook/examples/how_to_handle_rate_limits - Note : Modèle de code recommandé officiellement pour gérer la limitation de débit.
- Lien :
Auteur : Équipe technique APIYI
Date de publication : 27 avril 2026
Mots-clés : intégration API officielle gpt-image-2, base_url, texte vers image, édition d'image, inpainting, APIYI, SDK OpenAI