
作者注:详解如何用 Gemini 3.1 Pro、Claude Sonnet 4.6、GPT-5.4 三款大模型搭建物理题质检流水线,附完整 Prompt 模板和代码示例
用大模型做物理题质检,是教育机构和在线学习平台越来越关注的方向。传统的人工批改不仅效率低,还受限于阅卷教师的主观判断差异。本文将介绍如何利用 Gemini 3.1 Pro Preview、Claude Sonnet 4.6、GPT-5.4 这三款 2026 年最强推理模型,搭建一套高准确率的物理题自动质检系统。
核心价值: 读完本文,你将掌握大模型物理题质检的完整工作流——从 Prompt 设计到多模型交叉验证,建立一套准确率超过 90% 的自动化质检方案。
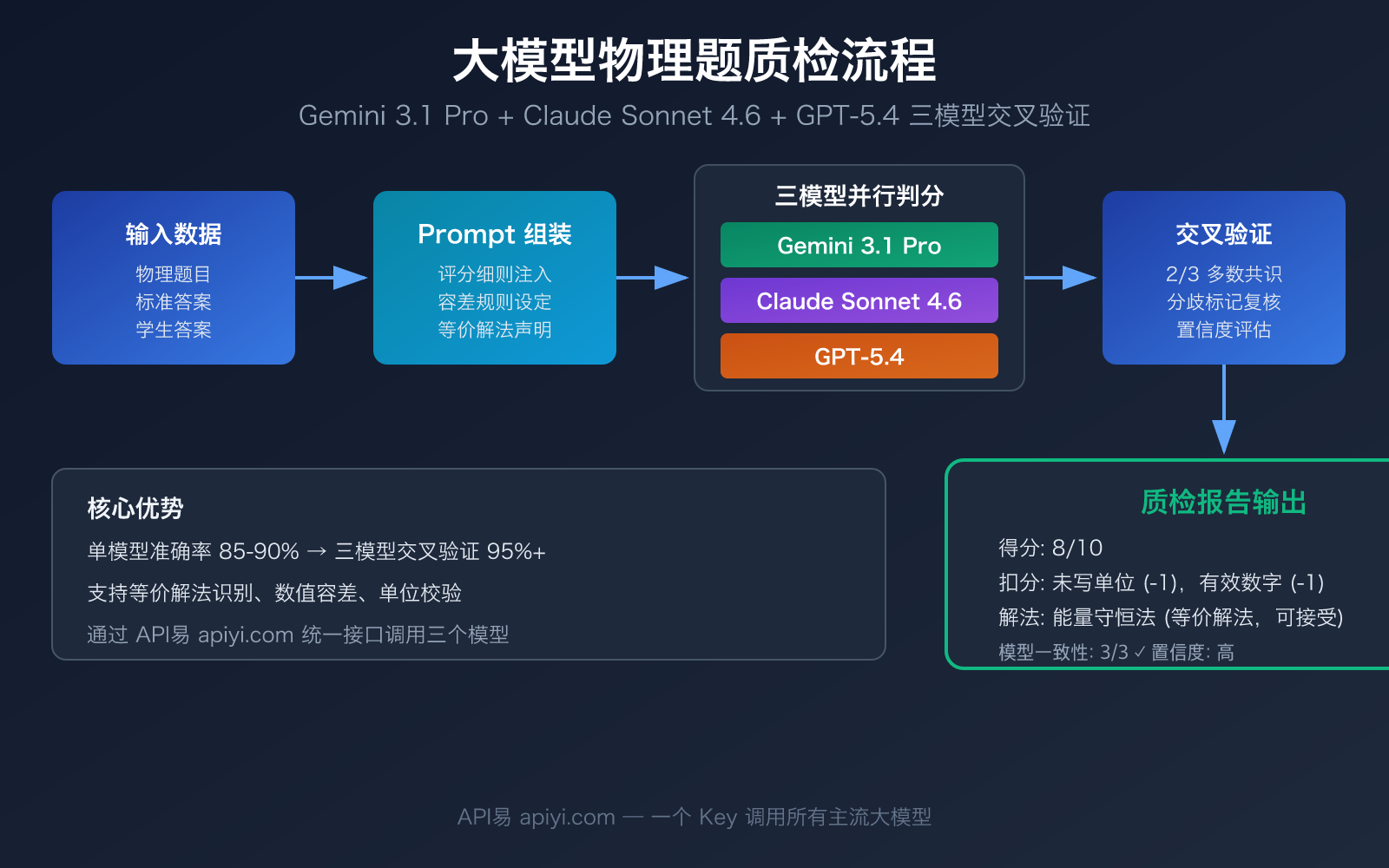
大模型物理题质检的核心要点
物理题质检与普通文本批改有本质区别——它要求模型同时具备数学推导能力、物理概念理解和评分一致性。以下是 3 款推荐模型的核心能力对比:
| 要点 | 说明 | 实际价值 |
|---|---|---|
| Gemini 3.1 Pro 推理能力领先 | MATH 基准 95.1%,ARC-AGI-2 达 77.1%,物理推理评测排名第一 | 处理含公式推导的力学、电磁学计算题准确率最高 |
| Claude Sonnet 4.6 解题过程清晰 | 支持自适应思考模式,数学能力跃升 27 个百分点至 89% | 能输出完整的评分依据和扣分理由,适合生成质检报告 |
| GPT-5.4 竞赛级难题表现突出 | AIME 2025 满分,支持 100 万 Token 上下文 | 处理物理竞赛题和综合大题时推理链最完整 |
| 多模型交叉验证 | 3 个模型独立判分后取共识 | 将单模型 85-90% 准确率提升至 95%+ |
大模型物理题质检的 3 个关键挑战
挑战一:公式推导的等价判定。 同一道力学题,学生可能用能量守恒解题,也可能用牛顿第二定律解题。两种方法的推导过程完全不同,但结果等价。研究表明,如果不在 Prompt 中明确要求模型接受等价解法,模型会僵化地按照标准答案的解题路径评分,导致误判率高达 30%。这是大模型物理题质检中最常见的失分点。
挑战二:物理单位和有效数字的容差处理。 物理计算中,保留 2 位有效数字和 3 位有效数字的结果不同,但通常都应被接受。在 Prompt 中设定合理的数值容差范围(如 ±5%)是质检准确率的关键保障。
挑战三:图表和实验题的理解。 包含电路图、力学示意图的题目,需要模型具备多模态理解能力。Gemini 3.1 Pro 和 GPT-5.4 在这方面表现较好,Claude Sonnet 4.6 则在纯文本和公式推理上更加稳定。
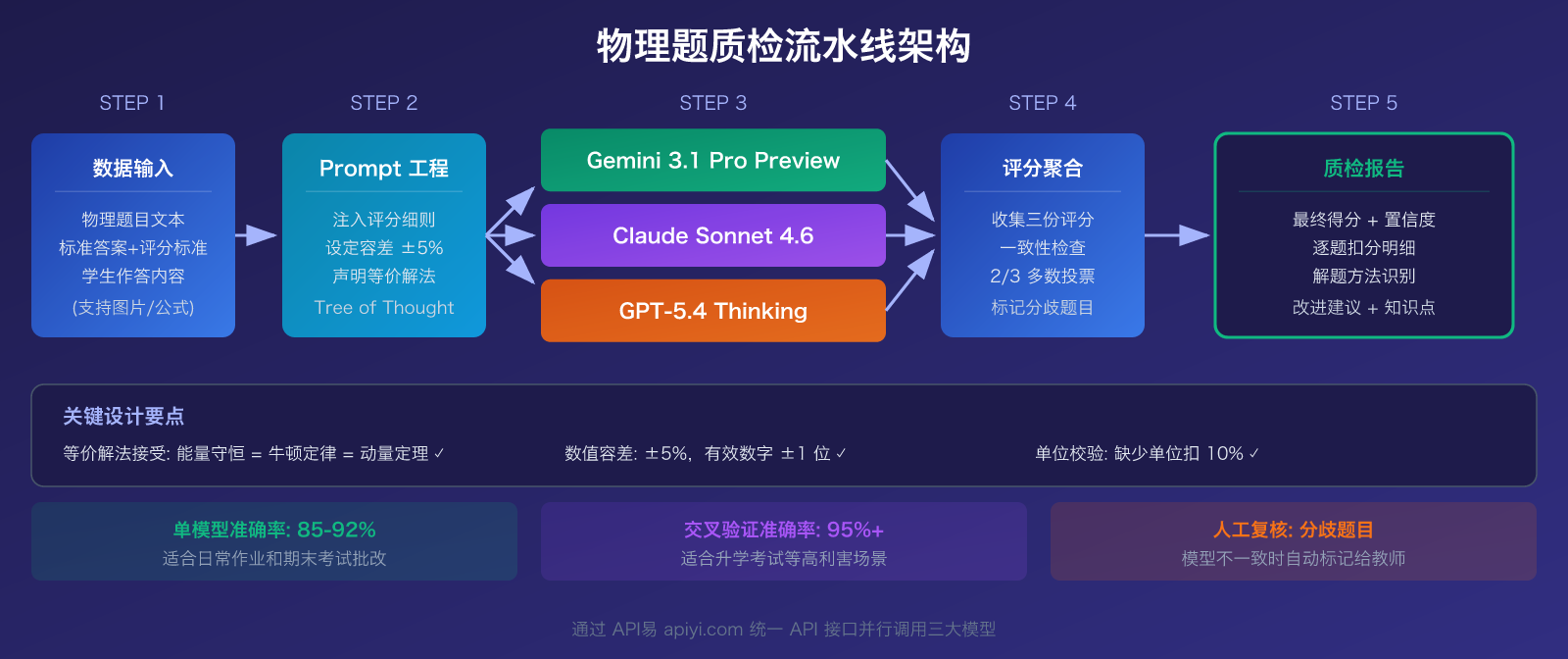
大模型物理题质检的 3 款推荐模型详解
Gemini 3.1 Pro Preview:物理推理首选
Gemini 3.1 Pro 是 Google DeepMind 于 2026 年 2 月发布的旗舰模型。在物理题质检场景中,它有三个核心优势:
- STEM 推理能力最强: 在 CritPt(研究级物理推理)评测中排名第一,MATH 基准达到 95.1%
- 思考深度可调: 新增
thinking_level参数(支持 LOW/MEDIUM/HIGH),简单选择题用 LOW 降低成本,综合计算题用 HIGH 保证准确率 - 性价比极高: 成本仅为 Claude Opus 4.6 的约 1/7.5,适合大批量质检任务
Claude Sonnet 4.6:质检报告生成最佳
Claude Sonnet 4.6 于 2026 年 2 月 17 日发布,在物理题质检中的独特优势在于:
- 自适应思考模式: 模型会根据题目难度自动决定推理深度,简单题快速判定,复杂题深度推理
- 100 万 Token 上下文窗口: 可以一次性传入整套试卷的所有题目和标准答案,保持评分标准一致
- 输出结构化强: 特别擅长生成格式规范的质检报告,包含评分、扣分点、改进建议
GPT-5.4:竞赛级难题利器
GPT-5.4 于 2026 年 3 月 5 日发布,是 OpenAI 最新旗舰模型:
- 竞赛数学满分: 在 AIME 2025 中取得 100% 正确率,处理高难度物理综合题能力突出
- 前置规划能力: GPT-5.4 Thinking 版本支持「Upfront Planning」,先展示推理思路再给出评分
- Token 效率最优: 相比 GPT-5.2,推理消耗的 Token 大幅减少,长期使用成本更低
| 模型 | 物理推理能力 | 报告生成质量 | 多模态支持 | 每百万 Token 成本 | 推荐场景 |
|---|---|---|---|---|---|
| Gemini 3.1 Pro | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 最低 | 大批量日常质检,含图表的题目 |
| Claude Sonnet 4.6 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 中等($3/$15) | 需要详细质检报告,整套试卷评分 |
| GPT-5.4 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 较高 | 竞赛题、综合大题、高难度质检 |
🎯 选择建议: 日常质检首选 Gemini 3.1 Pro(性价比最高),需要详细报告选 Claude Sonnet 4.6,高难度竞赛题用 GPT-5.4。通过 API易 apiyi.com 平台可以用统一接口调用这三个模型,方便快速切换和对比。
大模型物理题质检快速上手
极简示例:10 行代码实现物理题判分
以下示例展示如何用大模型对一道物理计算题进行自动评分:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[
{"role": "system", "content": "你是物理题质检专家。根据标准答案评判学生答案,输出JSON格式:{score, max_score, deductions: [{reason, points}], comment}"},
{"role": "user", "content": """
【题目】一个质量为2kg的物体从10m高处自由落下,求落地速度(g=10m/s²)
【标准答案】v=√(2gh)=√(2×10×10)=√200≈14.1m/s
【学生答案】用能量守恒:mgh=½mv²,v=√(2gh)=√200=14.14m/s
"""}
]
)
print(response.choices[0].message.content)
查看完整质检流水线代码(含多模型交叉验证)
import openai
import json
from typing import Optional
def physics_quality_check(
question: str,
standard_answer: str,
student_answer: str,
models: list = None,
tolerance: float = 0.05
) -> dict:
"""
物理题多模型交叉质检
Args:
question: 题目内容
standard_answer: 标准答案
student_answer: 学生答案
models: 使用的模型列表
tolerance: 数值容差(默认5%)
Returns:
包含各模型评分和最终结论的字典
"""
if models is None:
models = ["gemini-3.1-pro-preview", "claude-sonnet-4-6", "gpt-5.4"]
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
system_prompt = f"""你是资深物理教师和阅卷专家。请严格按以下规则评分:
1. 接受与标准答案等价的解题方法(如能量守恒、牛顿定律等不同路径)
2. 数值结果容差范围:±{tolerance*100}%
3. 有效数字:接受±1位的差异
4. 物理单位必须正确,缺少单位扣10%
输出严格JSON格式:
{{
"score": 得分,
"max_score": 满分,
"is_correct": true/false,
"deductions": [{{"reason": "扣分原因", "points": 扣分值}}],
"solution_method": "学生使用的解题方法",
"comment": "综合评价和改进建议"
}}"""
user_prompt = f"""【题目】{question}
【标准答案】{standard_answer}
【学生答案】{student_answer}"""
results = {}
for model in models:
try:
resp = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
temperature=0.1
)
results[model] = json.loads(resp.choices[0].message.content)
except Exception as e:
results[model] = {"error": str(e)}
# 交叉验证:取多数模型的共识结论
scores = [r["score"] for r in results.values() if "score" in r]
consensus = {
"model_results": results,
"avg_score": sum(scores) / len(scores) if scores else 0,
"consensus": all(r.get("is_correct") for r in results.values() if "is_correct" in r)
}
return consensus
# 使用示例
result = physics_quality_check(
question="一个质量为2kg的物体从10m高处自由落下,求落地速度(g=10m/s²)",
standard_answer="v=√(2gh)=√(2×10×10)=√200≈14.1m/s",
student_answer="mgh=½mv²,v=√(2×10×10)=14.14m/s"
)
print(json.dumps(result, ensure_ascii=False, indent=2))
建议: 通过 API易 apiyi.com 获取免费测试额度,一个 API Key 即可调用 Gemini、Claude、GPT 三个模型,无需分别注册三家平台账号。
大模型物理题质检的 Prompt 工程实践
好的 Prompt 设计是质检准确率的核心。以下是经过实测验证的 Prompt 模板和优化策略:
物理题质检 Prompt 模板
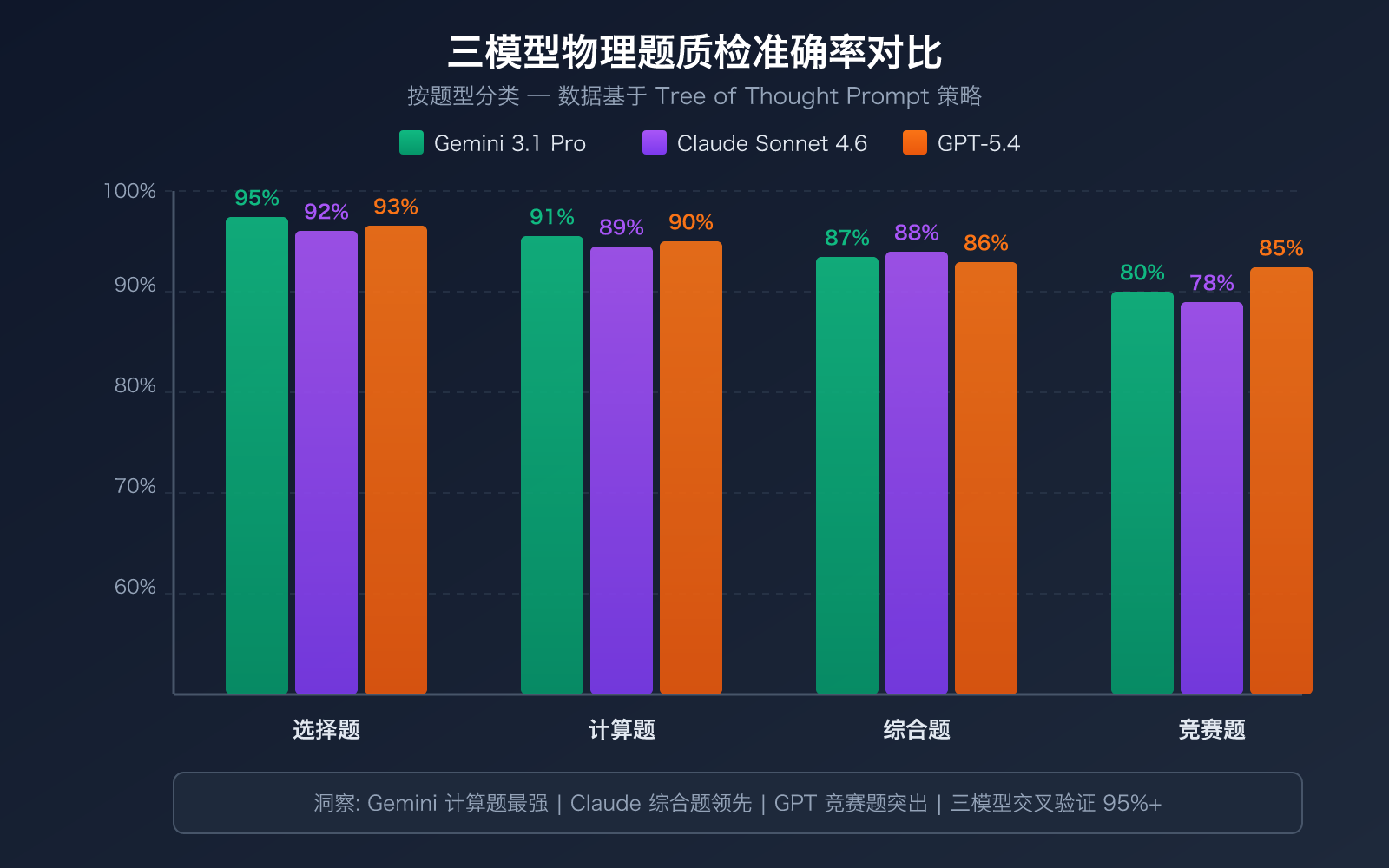
根据学术研究(2024-2026 年多篇发表论文),Tree of Thought(思维树)提示策略 在物理计算题评分中表现最佳,准确率 ≥ 0.9,Cohen's Kappa > 0.8。以下是我们推荐的 Prompt 结构:
| Prompt 策略 | 适用题型 | 准确率 | 推荐模型 |
|---|---|---|---|
| Tree of Thought | 综合计算题、推导题 | ≥ 90% | Gemini 3.1 Pro |
| Chain of Thought | 概念分析题、简答题 | 85-90% | Claude Sonnet 4.6 |
| Few-Shot | 选择题、填空题 | 80-85% | GPT-5.4(成本更低) |
| 多轮投票 | 所有题型(高要求) | 92-95% | 三模型组合 |
关键 Prompt 优化技巧
技巧一:明确等价解法接受规则。 在 System Prompt 中列出该题可接受的所有解题方法。例如力学题需声明:「接受能量守恒法、牛顿运动定律法、动量定理法等等价方法」。这一条规则可将误判率从 30% 降至 5% 以下。
技巧二:设定数值容差而非精确匹配。 物理计算中中间过程的四舍五入会导致最终结果有微小差异。推荐设置 ±5% 的容差,同时要求物理单位必须正确。
技巧三:要求模型先解题再评分。 让模型先独立求解,再对比学生答案。这种方式比直接让模型「对照标准答案评分」准确率高 15-20%。Gemini 3.1 Pro 的 thinking_level: HIGH 模式和 Claude Sonnet 4.6 的 Extended Thinking 都适合这种用法。
技巧四:多次运行取众数。 对同一道题运行 3-5 次评分取最常见结果,标准差可作为置信度指标。标准差 > 1 分时建议人工复核。
🎯 实战建议: 初次搭建质检系统时,建议先用 50-100 道已人工批改的物理题作为测试集,在 API易 apiyi.com 上分别测试三个模型的准确率,找到最适合你题库特点的模型组合。
大模型物理题质检的场景化方案
不同物理题类型需要不同的质检策略。以下是 4 种典型场景的推荐配置:
场景一:日常作业批量质检
适用于高中/大学物理的日常作业,题量大(100+ 题/天),难度中等。
- 推荐模型: Gemini 3.1 Pro Preview(
thinking_level: MEDIUM) - Prompt 策略: Few-Shot + 标准评分表
- 成本优势: 1000 道题约消耗 200 万 Token,Gemini 3.1 Pro 成本远低于其他模型
- 准确率: 85-90%(单模型),搭配人工抽检可达 95%+
场景二:期末考试精细评分
适用于正式考试阅卷,需要详细的评分依据和扣分理由。
- 推荐模型: Claude Sonnet 4.6(Extended Thinking 模式)
- Prompt 策略: Tree of Thought + 详细评分细则
- 核心优势: 输出的质检报告结构清晰,可直接作为阅卷记录存档
- 准确率: 88-92%(单模型)
场景三:物理竞赛题质检
适用于高中物理竞赛培训,题目综合性强、难度高。
- 推荐模型: GPT-5.4 Thinking(Upfront Planning 模式)
- Prompt 策略: Tree of Thought + 先解题再评分
- 核心优势: AIME 满分水平,能处理多步骤推导和高阶数学运算
- 准确率: 80-85%(竞赛难度下的单模型表现)
场景四:多模型交叉验证(最高准确率)
适用于高利害考试(如升学考试),需要最高准确率。
- 推荐方案: 3 个模型独立评分 → 取 2/3 多数共识 → 分歧题人工复核
- 实施成本: 单题成本约为单模型的 3 倍,但准确率提升至 95%+
- 适用规模: 适合题量较小(< 500 题)但质量要求极高的场景
| 场景 | 推荐模型 | Prompt 策略 | 准确率 | 成本(千题) |
|---|---|---|---|---|
| 日常作业 | Gemini 3.1 Pro | Few-Shot | 85-90% | 低 |
| 期末考试 | Claude Sonnet 4.6 | Tree of Thought | 88-92% | 中 |
| 竞赛题 | GPT-5.4 Thinking | ToT + 先解题 | 80-85% | 较高 |
| 交叉验证 | 三模型组合 | 多轮投票 | 95%+ | 高(3×) |
🎯 模型切换建议: 不同场景对模型的要求差异很大。API易 apiyi.com 支持通过修改一个
model参数即可切换模型,方便根据题型动态选择最优模型。
常见问题
Q1: 大模型物理题质检能完全替代人工阅卷吗?
目前还不能完全替代。学术研究显示,大模型在处理规范化的计算题时准确率可达 90%+,但在欠定义问题(under-specified problems)上准确率仅 8.3%。推荐方案:大模型负责 80% 的标准题批改,人工负责 20% 的复杂题和争议题复核。
Q2: 三款模型的 API 接入复杂度如何?
三款模型分别来自 Google、Anthropic、OpenAI 三家平台,如果逐个注册和对接,开发成本较高。推荐通过 API易 apiyi.com 的统一接口调用,所有模型使用相同的 OpenAI SDK 格式,只需修改 model 参数即可切换,大幅降低接入成本。
Q3: 如何评估质检系统的准确率?
推荐使用 Cohen's Kappa 系数衡量模型与人工评分的一致性:
- 准备 50-100 道已人工批改的物理题作为测试集
- 通过 API易 apiyi.com 分别调用三个模型评分
- 计算每个模型与人工评分的 Kappa 值
- Kappa > 0.8 表示高度一致,可投入使用
总结
大模型物理题质检的核心要点:
- 首选 Gemini 3.1 Pro Preview: STEM 推理能力最强、性价比最高,适合大批量日常物理题质检
- Claude Sonnet 4.6 适合出报告: 自适应思考模式 + 结构化输出,适合需要详细评分依据的正式考试
- GPT-5.4 处理竞赛难题: AIME 满分水平的推理能力,处理高难度综合物理题最可靠
- 多模型交叉验证提升至 95%+: 三模型独立评分取共识,是当前最可靠的自动化质检方案
选择哪个模型取决于你的题型特点和准确率要求。推荐通过 API易 apiyi.com 快速测试对比,平台提供免费额度和统一接口,一个 API Key 即可调用所有主流模型。
📚 参考资料
-
MDPI 教育科学 – 基于大模型的物理题智能评分研究: 对比四种 Prompt 策略在物理题评分中的表现
- 链接:
mdpi.com/2227-7102/15/2/116 - 说明: Tree of Thought 策略准确率 ≥ 0.9 的实验数据来源
- 链接:
-
Physical Review – LLM 在物理奥赛题上的评测: GPT 和推理模型在物理竞赛题上的系统评估
- 链接:
link.aps.org/doi/10.1103/6fmx-bsnl - 说明: 大模型物理推理能力已超越人类平均水平的关键论据
- 链接:
-
Google DeepMind – Gemini 3.1 Pro 技术博客: 模型架构和 STEM 基准测试详情
- 链接:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - 说明: Gemini 3.1 Pro 物理推理评测数据的官方来源
- 链接:
-
Anthropic – Claude Sonnet 4.6 发布公告: 自适应思考模式和数学能力提升详情
- 链接:
anthropic.com/news/claude-sonnet-4-6 - 说明: Claude Sonnet 4.6 数学能力跃升 27% 的技术细节
- 链接:
-
OpenAI – GPT-5.4 发布公告: Upfront Planning 和推理效率提升
- 链接:
openai.com/index/introducing-gpt-5-4/ - 说明: GPT-5.4 AIME 满分和 Token 效率优化的官方数据
- 链接:
作者: APIYI 技术团队
技术交流: 欢迎在评论区讨论大模型物理题质检的实践经验,更多模型调用教程可访问 API易 docs.apiyi.com 文档中心