
Nota del autor: Análisis detallado de la causa raíz del problema de limitación 429 en la generación de imágenes con Gemini 3.1 Flash Image Preview, comparación de las políticas de limitación de AI Studio, Vertex AI y plataformas de terceros, y 4 soluciones efectivas probadas.
Al generar imágenes con Gemini 3.1 Flash Image Preview, lo más frustrante no es la calidad de la generación, sino que apenas comienzas te bloquea el límite 429. Ya sea usando AI Studio o Vertex AI, las restricciones de RPD (Requests Per Day) y RPM (Requests Per Minute) son muy estrictas, lo que hace que la generación por lotes sea prácticamente imposible.
Este artículo, basado en la experiencia práctica, analizará en detalle la causa raíz del límite 429, comparará las diferencias en las políticas de limitación entre plataformas y ofrecerá 4 soluciones validadas, incluida una sin límite de concurrencia y con un precio tan bajo como $0.045 por imagen.
Valor central: Después de leer este artículo, comprenderás completamente la lógica subyacente del error 429 en la generación de imágenes de Gemini y encontrarás la solución más adecuada para tu caso.
¿Qué es el error 429 de Gemini 3.1 Flash Image Preview?
Primero, veamos cómo se ve este error:
{
"error": {
"code": 429,
"message": "Resource has been exhausted (e.g. check quota).",
"status": "RESOURCE_EXHAUSTED",
"details": [
{
"reason": "RATE_LIMIT_EXCEEDED",
"metadata": {
"quota_limit": "GenerateContentRequestsPerDayPerProjectPerModel",
"quota_limit_value": "1500"
}
}
]
}
}
Traducción simple: Has agotado tus solicitudes de hoy, o estás haciendo solicitudes demasiado frecuentes por minuto.
A diferencia del error 503, el 429 no significa que el servidor no pueda manejar la carga, sino que Google te ha establecido un límite de cuota activamente. No importa si el servidor tiene capacidad de cómputo disponible, una vez que alcanzas el límite, simplemente se rechaza.
Diferencia entre los errores 429 y 503 en la generación de imágenes de Gemini
| Elemento de comparación | 429 RESOURCE_EXHAUSTED | 503 UNAVAILABLE |
|---|---|---|
| Causa raíz | Has agotado tu cuota | Capacidad de cómputo del servidor insuficiente |
| Condición de activación | Exceder límites de RPD/RPM/TPM | Carga global alta |
| Alcance del impacto | Solo tu proyecto | Todos los usuarios |
| ¿Se puede resolver esperando? | RPM: esperar 1 minuto, RPD: esperar al día siguiente | Normalmente minutos a horas |
| ¿Se puede resolver pagando? | Vertex AI permite aumentar la cuota | No se puede resolver directamente |
| Solución fundamental | Cambiar de plataforma / Aumentar cuota | Esperar o cambiar de plataforma |
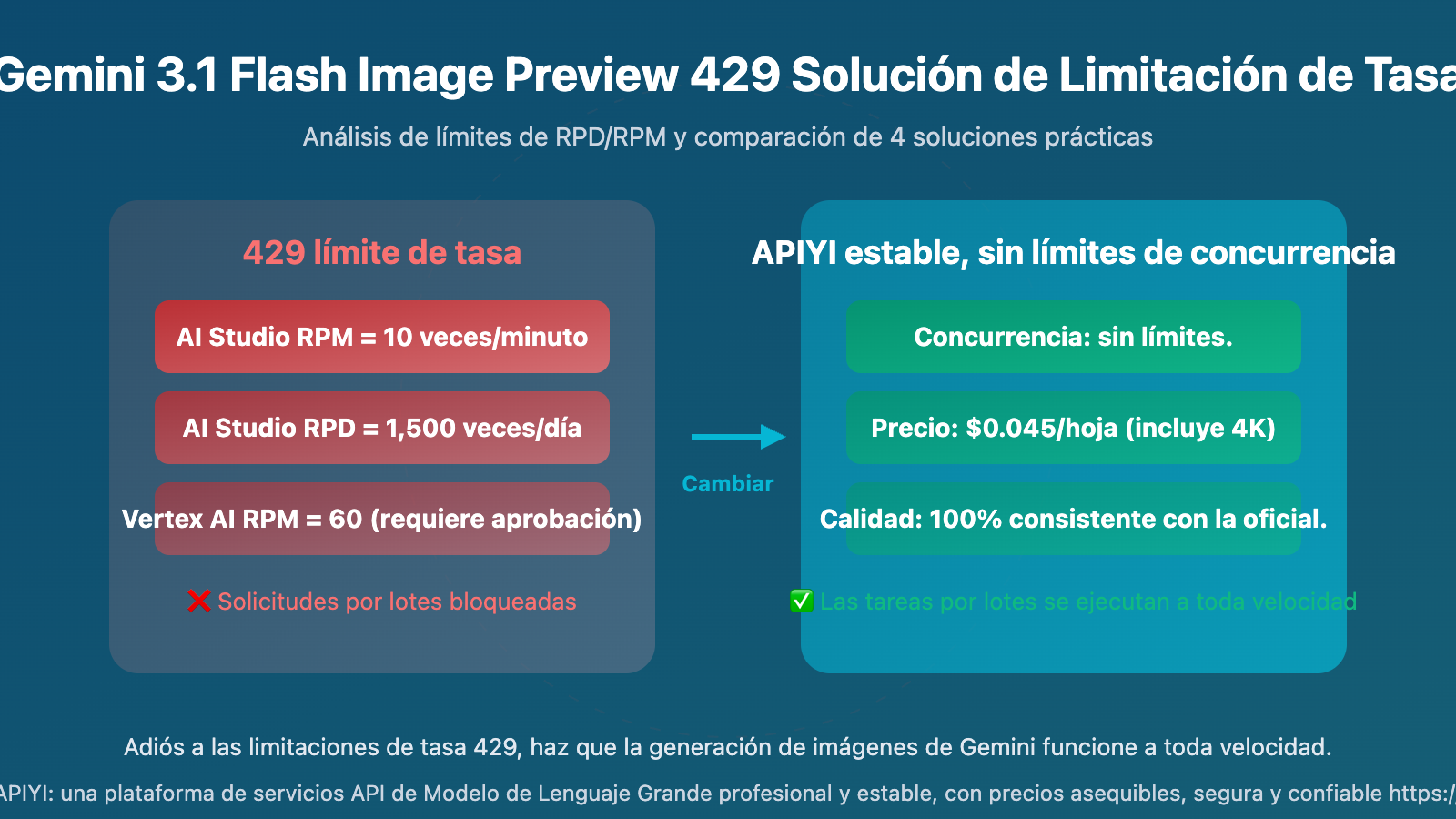
Comparativa de Estrategias de Limitación de Gemini 3.1 Flash Image Preview en Diferentes Plataformas
Ahí está el meollo del asunto: las diferencias en los límites entre plataformas son enormes.
Parámetros de Limitación de Gemini Image Generation en AI Studio
AI Studio es la primera opción para la mayoría de desarrolladores, es gratis y funciona bien. Pero los límites para la generación de imágenes son extremadamente estrictos:
| Dimensión de Límite | Valor Límite | Conversión |
|---|---|---|
| RPM (Solicitudes por minuto) | 10 | 1 solicitud cada 6 segundos |
| RPD (Solicitudes por día) | 1,500 | Se alcanza el límite en ~2.5 horas |
| TPM (Tokens por minuto) | 4,000,000 | Normalmente no es un cuello de botella |
| TPM de Salida de Imagen | 12,000 tokens/min | ~10 imágenes/minuto |
Experiencia real: Si necesitas generar 500 imágenes por lotes, con RPM=10, el tiempo teórico más rápido es de 50 minutos. Pero considerando la latencia de red, reintentos, etc., en realidad toma 1-2 horas. Si necesitas generar más de 1,500 imágenes al día, el límite RPD te bloquea directamente.
Parámetros de Limitación de Gemini Image Generation en Vertex AI
Vertex AI es la solución empresarial de Google Cloud, con cuotas más altas pero también con límites:
| Dimensión de Límite | Valor por Defecto | ¿Se puede aumentar? |
|---|---|---|
| RPM | 60 | Sí, requiere aprobación |
| RPD | Sin límite fijo | Pero está sujeto a RPM y TPM |
| TPM | 4,000,000 | Se puede solicitar |
| TPM de Salida de Imagen | 24,000 tokens/min | Se puede solicitar |
Experiencia real: RPM aumenta de 10 a 60, lo que parece mucho mejor, pero solicitar el aumento requiere pasar por el proceso de tickets de Google Cloud, que normalmente toma 1-3 días hábiles. Además, la configuración de Vertex AI es mucho más compleja que la de AI Studio (necesitas crear un proyecto de GCP, configurar una cuenta de servicio, permisos IAM, etc.), lo que hace que muchos desarrolladores individuales y equipos pequeños directamente la descarten.
Comparativa de Limitaciones de Gemini Image Generation en Plataformas de Terceros
| Plataforma | Límite de Concurrencia | Límite RPD | Precio por Imagen (1K) | Notas |
|---|---|---|---|---|
| AI Studio | RPM=10 | 1,500/día | Gratis (con límite) | El más estricto |
| Vertex AI | RPM=60 | Sin límite fijo | ~$0.067 | Requiere configuración GCP |
| OpenRouter | Depende del plan | Depende del plan | ~$0.06-0.08 | Plataforma genérica |
| Wentuo API | Sin límite de concurrencia | Sin límite | $0.045 | Pago por uso, sin límite de resolución |
4 Soluciones para el Límite 429 de Gemini 3.1 Flash Image Preview
Opción 1: Regulación de Solicitudes + Reintento Automático
La solución más básica, no requiere cambiar de plataforma, pero es ineficiente.
import time
import random
import requests
def generate_with_retry(prompt, max_retries=5):
"""Solicitud de generación de imágenes con reintento y retroceso exponencial"""
for attempt in range(max_retries):
try:
response = requests.post(endpoint, json=payload, headers=headers, timeout=120)
if response.status_code == 200:
return response.json()
elif response.status_code == 429:
# Retroceso exponencial + variación aleatoria
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"Límite 429, esperando {wait_time:.1f}s antes de reintentar ({attempt+1}/{max_retries})")
time.sleep(wait_time)
else:
response.raise_for_status()
except Exception as e:
print(f"Excepción en la solicitud: {e}")
time.sleep(2)
raise Exception("Se superó el número máximo de reintentos")
Ver script completo de generación por lotes (con control de velocidad)
import time
import random
import requests
import base64
from pathlib import Path
from concurrent.futures import ThreadPoolExecutor
class RateLimitedGenerator:
"""Generador por lotes que respeta el límite RPM=10 de AI Studio"""
def __init__(self, api_key, rpm_limit=10):
self.api_key = api_key
self.interval = 60.0 / rpm_limit # Intervalo mínimo entre solicitudes
self.last_request_time = 0
self.endpoint = "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent"
def _wait_for_rate_limit(self):
elapsed = time.time() - self.last_request_time
if elapsed < self.interval:
time.sleep(self.interval - elapsed)
self.last_request_time = time.time()
def generate(self, prompt, output_path, retries=3):
for attempt in range(retries):
self._wait_for_rate_limit()
try:
response = requests.post(
f"{self.endpoint}?key={self.api_key}",
json={
"contents": [{"parts": [{"text": prompt}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"imageConfig": {"aspectRatio": "1:1", "imageSize": "1K"}
}
},
timeout=120
)
if response.status_code == 200:
data = response.json()
img = data["candidates"][0]["content"]["parts"][0]["inlineData"]["data"]
Path(output_path).write_bytes(base64.b64decode(img))
return True
elif response.status_code == 429:
wait = (2 ** attempt) + random.uniform(0, 2)
print(f"[429] Esperando {wait:.1f}s ...")
time.sleep(wait)
except Exception as e:
print(f"Excepción: {e}")
time.sleep(2)
return False
# Ejemplo de uso
gen = RateLimitedGenerator("TU_CLAVE_AISTUDIO", rpm_limit=10)
prompts = ["una puesta de sol sobre montañas", "un gato en el espacio", "ciudad futurista"]
for i, p in enumerate(prompts):
success = gen.generate(p, f"salida_{i}.png")
print(f"{'✅' if success else '❌'} {p}")
Ventajas: Costo cero, adecuado para pequeñas cantidades de solicitudes.
Desventajas: Lento, no se puede superar el límite duro de RPD=1,500.
Opción 2: Migrar a Vertex AI para Aumentar la Cuota
Adecuado para usuarios empresariales con cuenta de Google Cloud.
Pasos a seguir:
- Crear un proyecto de GCP y habilitar la API de Vertex AI.
- Configurar una cuenta de servicio y permisos IAM.
- Solicitar el aumento de RPM en Google Cloud Console → IAM → Cuotas.
- Cambiar el endpoint en el código de AI Studio a Vertex AI.
Ventajas: RPM aumenta de 10 a 60+, utilizable en escenarios empresariales.
Desventajas: Configuración compleja, ciclo de aprobación de 1-3 días, tarifas según la facturación estándar de Google Cloud.
Opción 3: Rotación entre Múltiples Proyectos
Crear múltiples proyectos de GCP o claves API de AI Studio para rotar las solicitudes y evitar los límites RPD/RPM de un solo proyecto.
import itertools
api_keys = ["CLAVE_1", "CLAVE_2", "CLAVE_3", "CLAVE_4", "CLAVE_5"]
key_pool = itertools.cycle(api_keys)
def generate_with_rotation(prompt):
"""Generar imagen usando rotación de claves"""
key = next(key_pool)
# ... Enviar solicitud con la clave actual
return send_request(prompt, api_key=key)
Ventajas: Teóricamente, N claves proporcionan N veces el rendimiento.
Desventajas: Viola los Términos de Servicio (TOS) de Google, riesgo de suspensión de cuenta; aumenta la complejidad de gestión de múltiples claves.
Opción 4: Usar una Plataforma de Terceros sin Límites de Concurrencia
Esta es la solución que finalmente adopté. Después de comparar múltiples plataformas de terceros, elegí Wentuo API wentuo.ai, la razón es directa:
| Dimensión de Comparación | AI Studio | Vertex AI | Wentuo API |
|---|---|---|---|
| Límite de Concurrencia | RPM=10 | RPM=60 | Sin límite |
| Límite Diario | 1,500/día | Sujeto a RPM | Sin límite |
| Precio por Imagen (incl. 4K) | Gratis pero limitado | $0.067-$0.151 | $0.045 |
| Pago por Uso (1K) | – | $0.067 | ~$0.025 |
| Complejidad de Configuración | Simple | Compleja | Simple |
| ¿Requiere VPN? | Sí | Sí | No |
En la práctica, el pago por uso de $0.045 por imagen incluye resolución 4K, y si se paga por Tokens el costo está entre $0.02 y $0.05, dependiendo de la resolución. Lo más importante es que no hay límite de concurrencia, las tareas por lotes pueden ejecutarse a toda velocidad, sin quedar bloqueadas por el error 429.
La forma de invocación también es sencilla, solo hay que cambiar el endpoint:
import requests
import base64
API_KEY = "tu-clave-api-wentuo"
ENDPOINT = "https://api.wentuo.ai/v1beta/models/gemini-3.1-flash-image-preview:generateContent"
headers = {
"Content-Type": "application/json",
"x-goog-api-key": API_KEY
}
payload = {
"contents": [{"parts": [{"text": "Un gato lindo con un casco espacial"}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"imageConfig": {"aspectRatio": "1:1", "imageSize": "2K"}
}
}
response = requests.post(ENDPOINT, headers=headers, json=payload, timeout=120)
result = response.json()
image_data = result["candidates"][0]["content"]["parts"][0]["inlineData"]["data"]
with open("salida.png", "wb") as f:
f.write(base64.b64decode(image_data))
💡 Recomendación de uso: Si tu volumen diario de generación supera las 500 imágenes, o si necesitas alta velocidad de concurrencia, te sugiero usar directamente la solución sin límites de concurrencia de Wentuo API wentuo.ai. Pago por uso $0.045/imagen (sin límite de resolución), pago por volumen desde $0.018/imagen (512px), ahorrando entre un 33% y un 70% respecto a Google oficial.
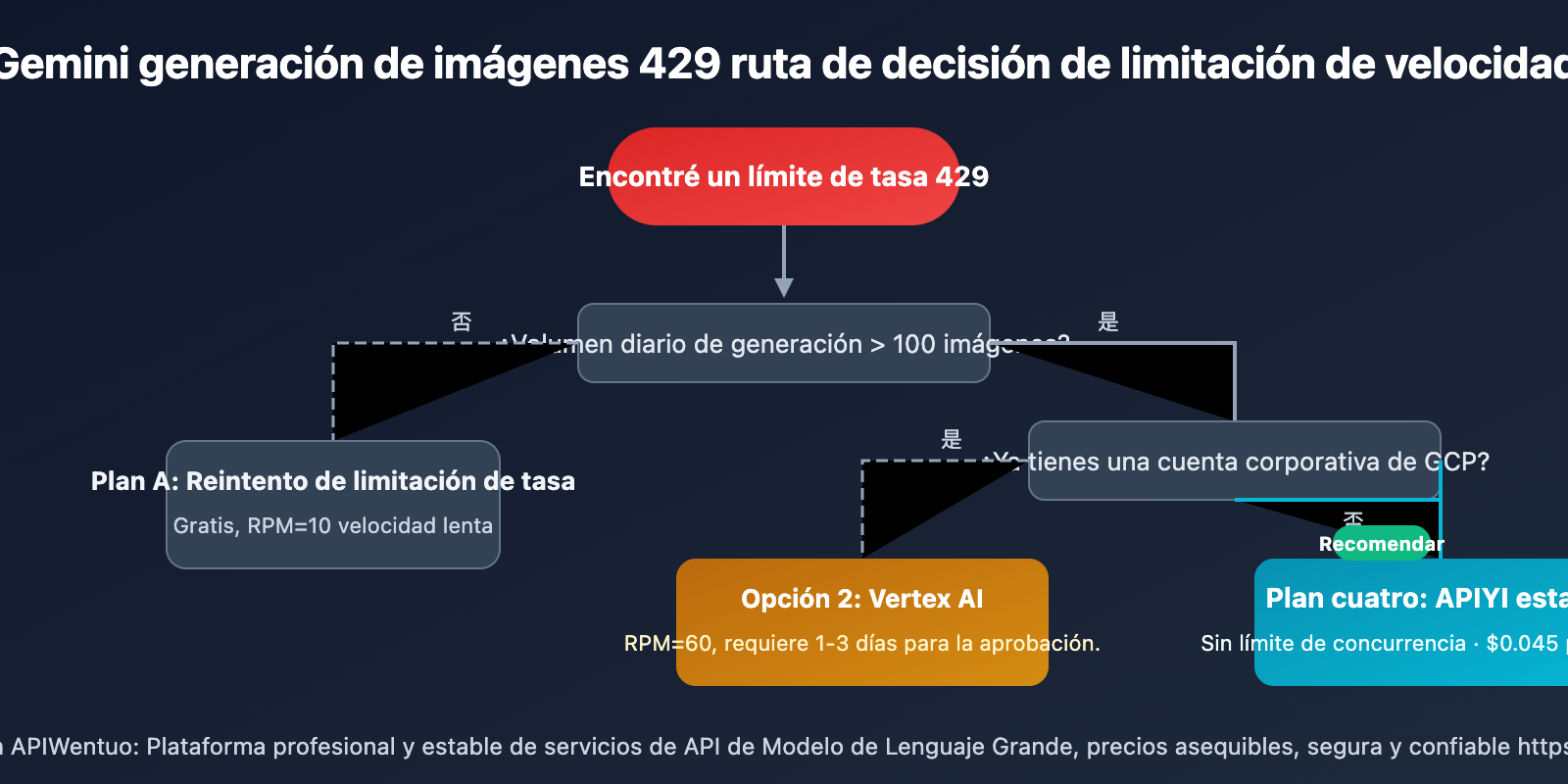
4 Recomendaciones de Soluciones para el Límite 429 de Gemini 3.1 Flash Image Preview
Diferentes escenarios requieren diferentes soluciones:
| Escenario de Uso | Solución Recomendada | Razón |
|---|---|---|
| 🎨 Aprendizaje personal/Pruebas | Solución 1 (Reintento con Throttling) | Gratuita, el volumen pequeño no afecta |
| 🏢 Empresa con GCP existente | Solución 2 (Vertex AI) | Cumple normativas, se puede solicitar cuota alta |
| 🔬 Pruebas masivas temporales | Solución 3 (Múltiples Claves) | Útil a corto plazo, atención al riesgo |
| 🚀 Entorno de producción/Generación por lotes | Solución 4 (API Estable) | Sin límite de concurrencia, costo más bajo |
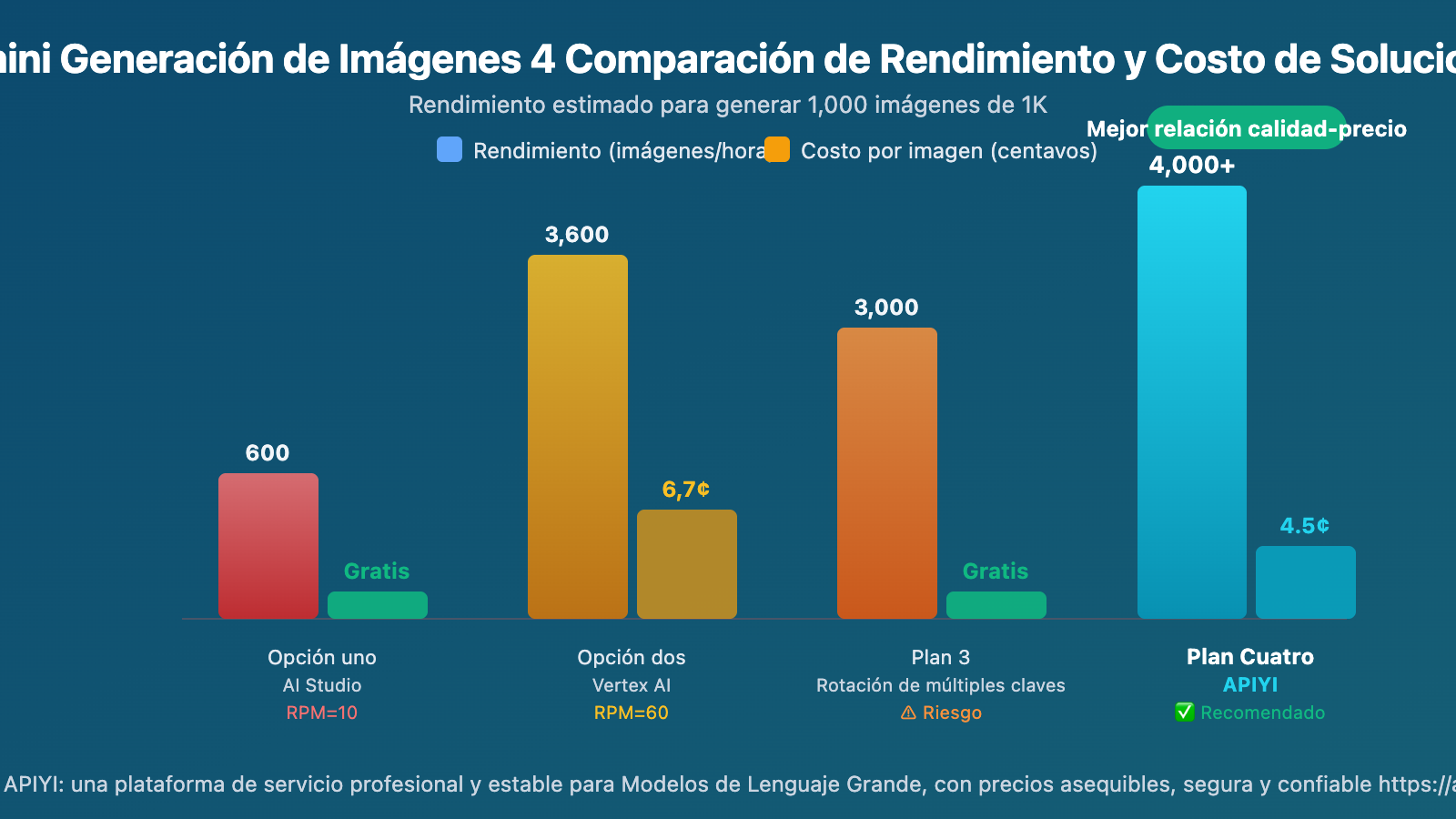
Comparación del Rendimiento de Diferentes Soluciones para Generación de Imágenes con Gemini
Suponiendo la generación de 1,000 imágenes de 1K:
| Solución | Tiempo Estimado | Costo Total | Viabilidad |
|---|---|---|---|
| AI Studio (RPM=10) | ~100 minutos + las limitaciones RPD pueden requerir esperar al día siguiente | Gratis | ⚠️ Sujeto a límites RPD |
| Vertex AI (RPM=60) | ~17 minutos | ~$67 | ✅ Requiere GCP |
| Rotación con Múltiples Claves (5 claves) | ~20 minutos | Gratis | ⚠️ Riesgo de suspensión de cuenta |
| API Estable (sin límite de concurrencia) | ~10-15 minutos | $45 (por uso) / ~$25 (por volumen) | ✅ Recomendado |
Preguntas Frecuentes
P1: ¿Cuánto tiempo tarda en recuperarse el error 429 de Gemini 3.1 Flash Image Preview?
Depende de qué tipo de límite se haya activado:
- Límite RPM: Se recupera automáticamente después de esperar 1 minuto.
- Límite RPD: Se restablece al día siguiente (a las 0:00 UTC).
- Límite TPM: Se recupera después de esperar 1 minuto.
Se recomienda que en el código se determine el tipo específico de límite según el valor del campo quota_limit en details y se aplique la estrategia correspondiente.
P2: ¿La calidad de generación de imágenes de la API Estable es igual a la oficial de Google?
Sí, la API Estable de wentuo.ai llama directamente al modelo oficial de Google Gemini 3.1 Flash Image Preview, por lo que la calidad de generación es exactamente la misma. Las diferencias son solo:
- Elimina las limitaciones RPD/RPM.
- Admite concurrencia ilimitada.
- Precio más favorable ($0.045/imagen vs $0.067/imagen oficial @1K).
P3: ¿Cómo elegir entre facturación por uso y por volumen?
Lógica de selección simple:
- Uso fijo de resolución 2K/4K → Elige facturación por uso ($0.045/uso, más rentable sin límite de resolución).
- Uso principal de 512px/1K → Elige facturación por volumen (512px solo $0.018/uso, ahorra un 60% vs por uso).
- Resoluciones mixtas → Calcula el costo promedio, generalmente la facturación por volumen es más rentable.
La API Estable de wentuo.ai admite el cambio flexible entre ambos métodos de facturación.
🎯 Resumen
El problema de limitación 429 en Gemini 3.1 Flash Image Preview se debe esencialmente a las estrictas cuotas de uso (RPD/RPM) que Google establece para AI Studio y Vertex AI. Los puntos clave son:
- Comprender el tipo de limitación: El error 429 indica una limitación de cuota (tu problema), mientras que el 503 significa sobrecarga del servidor (problema de Google). Las soluciones son completamente diferentes.
- Evaluar tu volumen de uso: AI Studio es suficiente para menos de 100 imágenes diarias. Para más de 500 imágenes, se recomienda considerar una plataforma de terceros.
- Elegir la solución adecuada: Para entornos de producción, se recomienda una solución sin límite de concurrencia para evitar que la limitación afecte tu negocio.
- La comparación de costos es crucial: La API de APIYI cuesta $0.045 por imagen (incluye 4K) en pago por uso, y puede bajar hasta $0.018 por imagen en pago por volumen, ahorrando entre un 33% y un 70% frente a la opción oficial.
Para desarrolladores que necesitan generar imágenes en lotes, la API de APIYI (wentuo.ai) es actualmente la opción con mejor experiencia integral: sin límite de concurrencia, precios más bajos, sin necesidad de VPN y con interfaz totalmente compatible.
📚 Referencias
-
Documentación oficial de Google Gemini API: Explicación de cuotas y limitación para generación de imágenes.
- Enlace:
ai.google.dev/gemini-api/docs/image-generation - Descripción: Parámetros de cuota oficiales y mejores prácticas.
- Enlace:
-
Gestión de cuotas de Google Cloud: Proceso para solicitar aumento de cuotas en Vertex AI.
- Enlace:
cloud.google.com/vertex-ai/docs/quotas - Descripción: Vía oficial para que usuarios empresariales aumenten sus cuotas.
- Enlace:
-
Documentación de APIYI Nano Banana 2: Guía de integración para generación de imágenes sin límite de concurrencia.
- Enlace:
docs.wentuo.ai - Descripción: Explicación detallada y ejemplos de código para los dos planes de facturación (por uso y por volumen).
- Enlace:
📝 Sobre el autor: Equipo de creación de contenido técnico, especializado en generación de imágenes con IA y en compartir conocimientos sobre APIs. Para más contenido técnico y recursos, visita APIYI wentuo.ai.
📋 Aclaración sobre el contenido: Este artículo se basa en experiencias de uso real. Los parámetros de limitación específicos pueden cambiar según los ajustes en las políticas de Google. Para soporte técnico, puedes obtener ayuda a través de APIYI wentuo.ai.